Introducción
Hace unos meses, cuando comencé a trabajar en Office People, desarrollé un interés en los modelos de lenguaje, particularmente en Word2Vec. Siendo un usuario nativo de Python, naturalmente me concentré en la implementación de Word2Vec de Gensim y busqué documentos y tutoriales en línea. Apliqué y dupliqué directamente fragmentos de código de múltiples fuentes, como lo haría cualquier buen científico de datos. Profundicé más y más para intentar comprender qué salió mal con mi método, leyendo las conversaciones de Stackoverflow, los grupos de Google de Gensim y la documentación de la biblioteca.

Sin embargo, siempre pensé que uno de los aspectos más importantes de crear un Palabra2Vec faltaba el modelo. Durante mis experimentos, descubrí que lematizar las oraciones o buscar frases/bigramas en ellas tenía un impacto significativo en los resultados y el rendimiento de mis modelos. Aunque el impacto del preprocesamiento varía según el conjunto de datos y la aplicación, decidí incluir los pasos de preparación de datos en este artículo y utilizar el fantástico biblioteca spaCy junto a él.
Algunos de estos temas me irritan, así que decidí escribir mi propio artículo. No prometo que sea perfecto o que sea la mejor manera de implementar Word2Vec, solo que es mejor que muchos de los que existen.
Objetivos de aprendizaje
- Comprender las incrustaciones de palabras y su papel en la captura de relaciones semánticas.
- Implemente modelos de Word2Vec utilizando bibliotecas populares como Gensim o TensorFlow.
- Mida la similitud de palabras y calcule distancias utilizando incrustaciones de Word2Vec.
- Explore analogías de palabras y relaciones semánticas capturadas por Word2Vec.
- Aplique Word2Vec en varias tareas de NLP, como el análisis de sentimientos y la traducción automática.
- Aprenda técnicas para ajustar los modelos de Word2Vec para tareas o dominios específicos.
- Manejar palabras fuera del vocabulario usando información de subpalabras o incrustaciones previamente entrenadas.
- Comprender las limitaciones y compensaciones de Word2Vec, como la desambiguación del sentido de las palabras y la semántica a nivel de oraciones.
- Sumérjase en temas avanzados como incrustaciones de subpalabras y optimización de modelos con Word2Vec.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Breve acerca de Word2Vec
Un equipo de investigadores de Google presentó Word2Vec en dos artículos entre septiembre y octubre de 2013. Los investigadores también publicaron su implementación de C junto con los artículos. Gensim completó la implementación de Python poco después del primer artículo.
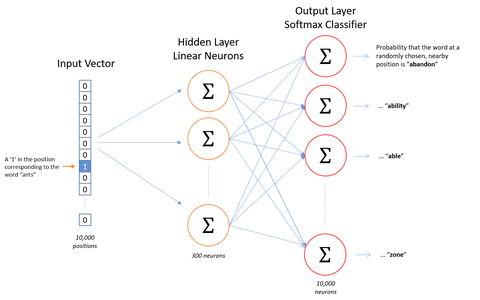
La suposición subyacente de Word2Vec es que dos palabras con contextos similares tienen significados similares y, como resultado, una representación vectorial similar del modelo. Por ejemplo, "perro", "cachorro" y "cachorro" se usan con frecuencia en contextos similares, con palabras circundantes similares como "bueno", "esponjoso" o "lindo" y, por lo tanto, tienen una representación vectorial similar según Word2Vec.
Basado en esta suposición, Word2Vec se puede utilizar para descubrir las relaciones entre las palabras en un datos, calcule su similitud o use la representación vectorial de esas palabras como entrada para otras aplicaciones como clasificación de texto o agrupación.
Implementación de Word2vec
La idea detrás de Word2Vec es bastante simple. Estamos asumiendo que el significado de una palabra puede ser inferido por la compañía que mantiene. Esto es análogo al dicho: “Muéstrame a tus amigos y te diré quién eres”. Aquí hay una implementación de word2vec.
Configurar el entorno
pitón==3.6.3
Bibliotecas utilizadas:
- xlrd==1.1.0:
- spaCy==2.0.12:
- gensim==3.4.0:
- scikit-aprende==0.19.1:
- nacido en el mar == 0.8:
import re # For preprocessing
import pandas as pd # For data handling
from time import time # To time our operations
from collections import defaultdict # For word frequency import spacy # For preprocessing import logging # Setting up the loggings to monitor gensim
logging.basicConfig(format="%(levelname)s - %(asctime)s: %(message)s", datefmt= '%H:%M:%S', level=logging.INFO)Conjunto de datos
Este conjunto de datos contiene información sobre los personajes, las ubicaciones, los detalles de los episodios y los guiones de más de 600 episodios de Los Simpson que datan de 1989. Está disponible en Kaggle. (~25 MB)
preprocesamiento
Al realizar el preprocesamiento, solo se mantendrán dos columnas de un conjunto de datos, que son raw_character_text y speech_words.
- raw_character_text: el personaje que habla (útil para rastrear los pasos de preprocesamiento).
- palabras_habladas: el texto sin procesar de la línea de diálogo
Como queremos hacer nuestro propio preprocesamiento, no mantenemos el texto normalizado.
df = pd.read_csv('../input/simpsons_dataset.csv')
df.shape
df.head()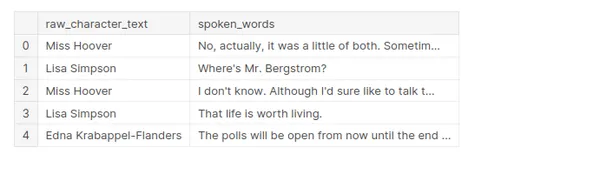
Los valores que faltan son de una sección del guión donde sucede algo pero no hay diálogo. “(Springfield Elementary School: EXT. PRIMARIA – PATIO DE JUEGOS DE LA ESCUELA – TARDE)” es un ejemplo.
df.isnull().sum()
Limpieza
Para cada línea de diálogo, estamos lematizando y eliminando palabras vacías y caracteres no alfabéticos.
nlp = spacy.load('en', disable=['ner', 'parser']) def cleaning(doc): # Lemmatizes and removes stopwords # doc needs to be a spacy Doc object txt = [token.lemma_ for token in doc if not token.is_stop] if len(txt) > 2: return ' '.join(txt)Elimina caracteres no alfabéticos:
brief_cleaning = (re.sub("[^A-Za-z']+", ' ', str(row)).lower() for row in df['spoken_words'])Usando el atributo spaCy.pipe() para acelerar el proceso de limpieza:
t = time() txt = [cleaning(doc) for doc in nlp.pipe(brief_cleaning, batch_size=5000, n_threads=-1)] print('Time to clean up everything: {} mins'.format(round((time() - t) / 60, 2)))

Para eliminar valores faltantes y duplicados, coloque los resultados en un DataFrame:
df_clean = pd.DataFrame({'clean': txt})
df_clean = df_clean.dropna().drop_duplicates()
df_clean.shape

bigramas
Los bigramas son un concepto utilizado en el procesamiento del lenguaje natural y el análisis de textos. Se refieren a pares consecutivos de palabras o caracteres que aparecen en una secuencia de texto. Mediante el análisis de bigramas, podemos obtener información sobre las relaciones entre palabras o caracteres en un texto determinado.
Tomemos una oración de ejemplo: "Me encanta el helado". Para identificar los bigramas en esta oración, miramos pares de palabras consecutivas:
"Amo"
"amor hielo"
"helado"
Cada uno de estos pares representa un bigrama. Los bigramas pueden ser útiles en varias tareas de procesamiento de lenguaje. Por ejemplo, en el modelado del lenguaje, podemos usar bigramas para predecir la siguiente palabra en una oración en función de la palabra anterior.
Los bigramas se pueden extender a secuencias más grandes llamadas trigramas (tríos consecutivos) o n-gramas (secuencias consecutivas de n palabras o caracteres). La elección de n depende del análisis específico o de la tarea en cuestión.
El paquete Gensim Phrases se utiliza para detectar automáticamente frases comunes (bigramas) de una lista de oraciones. https://radimrehurek.com/gensim/models/phrases.html
¡Hacemos esto principalmente para capturar palabras como "mr_burns" y "bart_simpson"!
from gensim.models.phrases import Phrases, Phraser
sent = [row.split() for row in df_clean['clean']]Las siguientes frases se generan a partir de la lista de oraciones:
phrases = Phrases(sent, min_count=30, progress_per=10000)
El objetivo de Phraser() es reducir el consumo de memoria de Phrases() descartando el estado del modelo que no es estrictamente necesario para la tarea de detección de bigramas:
bigram = Phraser(phrases)
Transformar el corpus en base a los bigramas detectados:
sentences = bigram[sent]Palabras más frecuentes
Principalmente, una verificación de cordura sobre la efectividad de la lematización, la eliminación de palabras vacías y la adición de bigramas.
word_freq = defaultdict(int)
for sent in sentences: for i in sent: word_freq[i] += 1
len(word_freq)

sorted(word_freq, key=word_freq.get, reverse=True)[:10]
Separar el Entrenamiento del Modelo en 3 Pasos
Para mayor claridad y seguimiento, prefiero dividir la capacitación en tres pasos distintos.
- Palabra2Vec():
- En este primer paso, configuré los parámetros del modelo uno por uno.
- Intencionalmente dejo el modelo sin inicializar al no proporcionar las oraciones de parámetros.
- construir_vocab():
- Inicializa el modelo construyendo el vocabulario a partir de una secuencia de oraciones.
- Puedo seguir el progreso y, lo que es más importante, el efecto de min_count y sample en el corpus de palabras usando los registros. Descubrí que estos dos parámetros, particularmente la muestra, tienen un impacto significativo en el rendimiento del modelo. Mostrar ambos permite una gestión más precisa y sencilla de su influencia.
- .tren():
- Finalmente, el modelo es entrenado.
- Los registros en esta página son en su mayoría útiles.
import multiprocessing from gensim.models import Word2Vec cores = multiprocessing.cpu_count() # Count the number of cores in a computer w2v_model = Word2Vec(min_count=20, window=2, size=300, sample=6e-5, alpha=0.03, min_alpha=0.0007, negative=20, workers=cores-1)Gensim implementación de word2vec: https://radimrehurek.com/gensim/models/word2vec.html
Construcción de la tabla de vocabulario
Word2Vec requiere que creemos la tabla de vocabulario (digiriendo todas las palabras, filtrando las palabras únicas y realizando algunos conteos básicos sobre ellas):
t = time() w2v_model.build_vocab(sentences, progress_per=10000) print('Time to build vocab: {} mins'.format(round((time() - t) / 60, 2))) 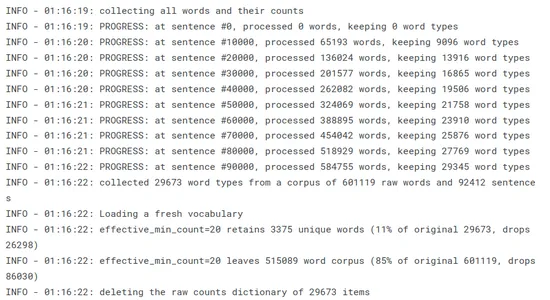
La tabla de vocabulario es crucial para codificar palabras como índices y buscar sus incrustaciones de palabras correspondientes durante el entrenamiento o la inferencia. Forma la base para entrenar modelos Word2Vec y permite una representación eficiente de palabras en el espacio vectorial continuo.
Entrenamiento del Modelo
Entrenar un modelo de Word2Vec implica introducir un corpus de datos de texto en el algoritmo y optimizar los parámetros del modelo para aprender incrustaciones de palabras. Los parámetros de entrenamiento para Word2Vec incluyen varios hiperparámetros y configuraciones que afectan el proceso de entrenamiento y la calidad de las incrustaciones de palabras resultantes. Aquí hay algunos parámetros de entrenamiento de uso común para Word2Vec:
- total_examples = int – El número de oraciones;
- épocas = int – El número de iteraciones (épocas) sobre el corpus – [10, 20, 30]
t = time() w2v_model.train(sentences, total_examples=w2v_model.corpus_count, epochs=30, report_delay=1) print('Time to train the model: {} mins'.format(round((time() - t) / 60, 2)))
Estamos llamando a init_sims() para hacer que el modelo sea mucho más eficiente en memoria, ya que no tenemos la intención de entrenarlo más:
w2v_model.init_sims(replace=True)
Estos parámetros controlan aspectos como el tamaño de la ventana de contexto, el equilibrio entre palabras frecuentes y raras, la tasa de aprendizaje, el algoritmo de entrenamiento y el número de muestras negativas para el muestreo negativo. El ajuste de estos parámetros puede afectar la calidad, la eficiencia y los requisitos de memoria del proceso de capacitación de Word2Vec.
Explorando el modelo
Una vez que se entrena un modelo de Word2Vec, puede explorarlo para obtener información sobre las incrustaciones de palabras aprendidas y extraer información útil. Aquí hay algunas formas de explorar el modelo Word2Vec:
Más parecido a
En Word2Vec, puede encontrar las palabras más similares a una palabra dada en función de las incrustaciones de palabras aprendidas. La similitud generalmente se calcula utilizando la similitud del coseno. Aquí hay un ejemplo de cómo encontrar las palabras más similares a una palabra objetivo usando Word2Vec:
Veamos qué obtenemos para el personaje principal del programa:
similar_words = w2v_model.wv.most_similar(positive=["homer"])
for word, similarity in similar_words: print(f"{word}: {similarity}")
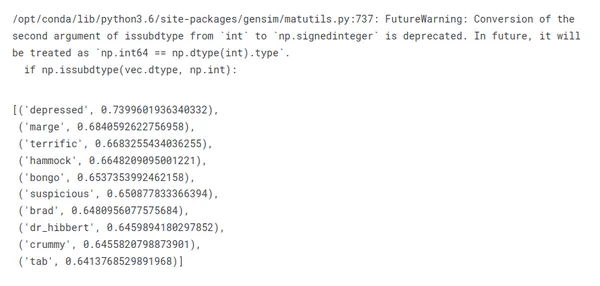
Para ser claros, cuando miramos las palabras que son más similares a "homero", no necesariamente obtenemos los miembros de su familia, los rasgos de personalidad o incluso sus citas más memorables.
Compare eso con lo que devuelve el bigrama "homer_simpson":
w2v_model.wv.most_similar(positive=["homer_simpson"])
¿Qué hay de Marge ahora?
w2v_model.wv.most_similar(positive=["marge"])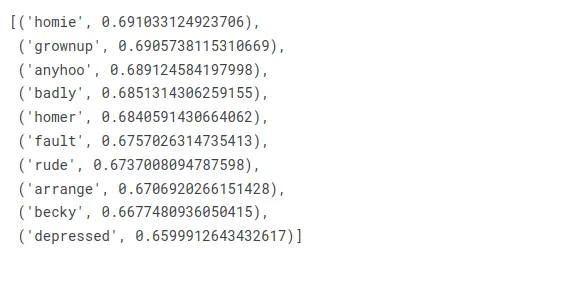
Veamos a Bart ahora:
w2v_model.wv.most_similar(positive=["bart"])
¡Parece que tiene sentido!
Similitudes
Aquí hay un ejemplo de cómo encontrar la similitud del coseno entre dos palabras usando Word2Vec:
Ejemplo: Cálculo de la similitud de coseno entre dos palabras.
w2v_model.wv.similarity("moe_'s", 'tavern')
¿Quién podría olvidar la taberna de Moe? No Barney.
w2v_model.wv.similarity('maggie', 'baby')
¡Maggie es sin duda la bebé más famosa de Los Simpson!
w2v_model.wv.similarity('bart', 'nelson')
Bart y Nelson, aunque son amigos, no son tan cercanos, ¡tiene sentido!
El que no encaja
¡Aquí, le pedimos a nuestro modelo que nos dé la palabra que no pertenece a la lista!
Entre Jimbo, Milhouse y Kearney, ¿quién es el que no es un matón?
w2v_model.wv.doesnt_match(['jimbo', 'milhouse', 'kearney'])
¿Y si comparamos la amistad entre Nelson, Bart y Milhouse?
w2v_model.wv.doesnt_match(["nelson", "bart", "milhouse"])
¡Parece que Nelson es el extraño aquí!
Por último, pero no menos importante, ¿cómo es la relación entre Homer y sus dos cuñadas?
w2v_model.wv.doesnt_match(['homer', 'patty', 'selma'])
¡Maldita sea, realmente no les gustas Homero!
Diferencia de analogía
¿Qué palabra es para la mujer lo que Homer es para Marge?
w2v_model.wv.most_similar(positive=["woman", "homer"], negative=["marge"], topn=3)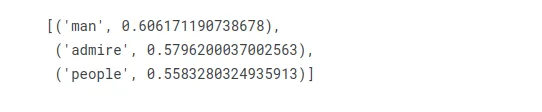
"hombre" viene en la primera posición, ¡eso parece correcto!
¿Qué palabra es para la mujer lo que Bart es para el hombre?
w2v_model.wv.most_similar(positive=["woman", "bart"], negative=["man"], topn=3)
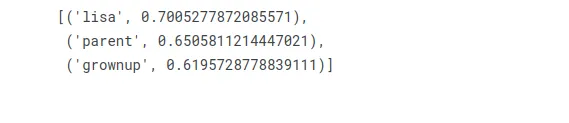
Lisa es la hermana de Bart, ¡su contraparte masculina!
Conclusión
En conclusión, Word2Vec es un algoritmo ampliamente utilizado en el campo del procesamiento del lenguaje natural (NLP) que aprende incrustaciones de palabras representándolas como vectores densos en un espacio vectorial continuo. Captura las relaciones semánticas y sintácticas entre palabras en función de sus patrones de co-ocurrencia en un gran corpus de texto.
Word2Vec funciona utilizando el modelo Continuous Bag-of-Words (CBOW) o Skip-gram, que son arquitecturas de redes neuronales. Las incrustaciones de palabras, generadas por Word2Vec, son representaciones vectoriales densas de palabras que codifican información semántica y sintáctica. Permiten operaciones matemáticas como el cálculo de similitud de palabras y se pueden usar como características en varias tareas de PNL.
Puntos clave
- Word2Vec aprende incrustaciones de palabras, representaciones vectoriales densas de palabras.
- Analiza patrones de co-ocurrencia en un corpus de texto para capturar relaciones semánticas.
- El algoritmo utiliza una red neuronal con modelo CBOW o Skip-gram.
- Las incrustaciones de palabras permiten cálculos de similitud de palabras.
- Se pueden usar como características en varias tareas de PNL.
- Word2Vec requiere un gran corpus de entrenamiento para incrustaciones precisas.
- No captura la desambiguación del sentido de las palabras.
- El orden de las palabras no se considera en Word2Vec.
- Las palabras fuera del vocabulario pueden plantear desafíos.
- A pesar de las limitaciones, Word2Vec tiene importantes aplicaciones en PNL.
Si bien Word2Vec es un algoritmo poderoso, tiene algunas limitaciones. Requiere una gran cantidad de datos de entrenamiento para aprender incrustaciones de palabras precisas. Trata cada palabra como una entidad atómica y no captura la desambiguación del sentido de la palabra. Las palabras fuera del vocabulario pueden representar un desafío, ya que no tienen incrustaciones preexistentes.
Word2Vec ha contribuido significativamente a los avances en NLP y sigue siendo una herramienta valiosa para tareas como la recuperación de información, el análisis de sentimientos, la traducción automática y más.
Preguntas y respuestas frecuentes
R: Word2Vec es un algoritmo popular para tareas de procesamiento de lenguaje natural (NLP). Una red neuronal superficial de dos capas aprende incrustaciones de palabras al representar las palabras como vectores densos en un espacio vectorial continuo. Word2Vec captura las relaciones semánticas y sintácticas entre palabras en función de sus patrones de co-ocurrencia en un gran corpus de texto.
R: Word2Vec usa una técnica llamada "representación distribuida" para aprender incrustaciones de palabras. Emplea una arquitectura de red neuronal, ya sea el modelo Continuous Bag-of-Words (CBOW) o Skip-gram. El modelo CBOW predice la palabra objetivo en función de sus palabras de contexto, mientras que el modelo Skip-gram predice las palabras de contexto dada una palabra objetivo. Durante el entrenamiento, el modelo ajusta los vectores de palabras para maximizar la probabilidad de predecir correctamente las palabras objetivo o de contexto.
R: Las incrustaciones de palabras son representaciones vectoriales densas de palabras en un espacio vectorial continuo. Codifican información semántica y sintáctica sobre palabras, capturando sus relaciones en función de sus propiedades de distribución en el corpus de entrenamiento. Permiten operaciones matemáticas como el cálculo de similitud de palabras y las utilizan como características en varias tareas de PNL, como análisis de sentimientos, traducción automática, etc.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/07/step-by-step-guide-to-word2vec-with-gensim/

