Miles de desarrolladores utilizan Apache Flink para crear aplicaciones de transmisión para transformar y analizar datos en tiempo real. Apache Flink es un marco y motor de código abierto para procesar flujos de datos. Es altamente disponible y escalable, y ofrece alto rendimiento y baja latencia para las aplicaciones de procesamiento de flujo más exigentes. Monitorear y escalar sus aplicaciones es fundamental para mantenerlas ejecutándose exitosamente en un entorno de producción.
Servicio administrado de Amazon para Apache Flink es un servicio totalmente administrado que reduce la complejidad de crear y administrar aplicaciones Apache Flink. Amazon Managed Service para Apache Flink administra los componentes subyacentes de Apache Flink que proporcionan estados de aplicaciones, métricas, registros duraderos y más.
En esta publicación, mostramos una forma simplificada de aumentar y reducir automáticamente la cantidad de KPU (Unidades de procesamiento Kinesis; 1 KPU es 1 vCPU y 4 GB de memoria) de sus aplicaciones Apache Flink con Amazon Managed Service para Apache Flink. Le mostramos cómo escalar utilizando métricas como CPU, memoria, contrapresión o cualquier métrica personalizada de su elección. Además, mostramos cómo realizar un escalado programado, lo que le permite ajustar la capacidad de su aplicación en momentos específicos, particularmente cuando se trata de cargas de trabajo predecibles. También compartimos un Formación en la nube de AWS utilidad para ayudarle a implementar el escalado automático rápidamente con su servicio administrado de Amazon para aplicaciones Apache Flink.
Escalado basado en métricas
Esta sección describe cómo implementar una solución de escalado para Amazon Managed Service para Apache Flink basada en Reloj en la nube de Amazon métrica. Amazon Managed Service para Apache Flink viene con una escalado automático Opción lista para usar que se escala cuando la utilización de la CPU del contenedor es superior al 75% durante 15 minutos. Esto funciona bien para muchos casos de uso; sin embargo, para algunas aplicaciones, es posible que necesite escalar en función de una métrica diferente o activar la acción de escala en un momento determinado o mediante un factor diferente. Puede personalizar sus políticas de escalado y ahorrar costos ajustando el tamaño adecuado de sus aplicaciones Amazon Managed Apache Flink al implementar esta solución.
Para realizar un escalado basado en métricas, utilizamos alarmas de CloudWatch, Puente de eventos de Amazon, Funciones de paso de AWSy AWS Lambda. Puede elegir entre métricas provenientes de la fuente, como Secuencias de datos de Amazon Kinesis or Streaming administrado por Amazon para Apache Kafka (Amazon MSK) o métricas de la aplicación Amazon Managed Service para Apache Flink. Puede encontrar estos componentes en la plantilla de CloudFormation en el Repositorio GitHub.
El siguiente diagrama muestra cómo escalar una aplicación Amazon Managed Service para Apache Flink en respuesta a una alarma de CloudWatch.

Esta solución utiliza la métrica seleccionada y crea dos alarmas de CloudWatch que, según el umbral que utilice, activan una regla en EventBridge para comenzar a ejecutar una máquina de estado de Step Functions. El siguiente diagrama ilustra el flujo de trabajo de la máquina de estados.
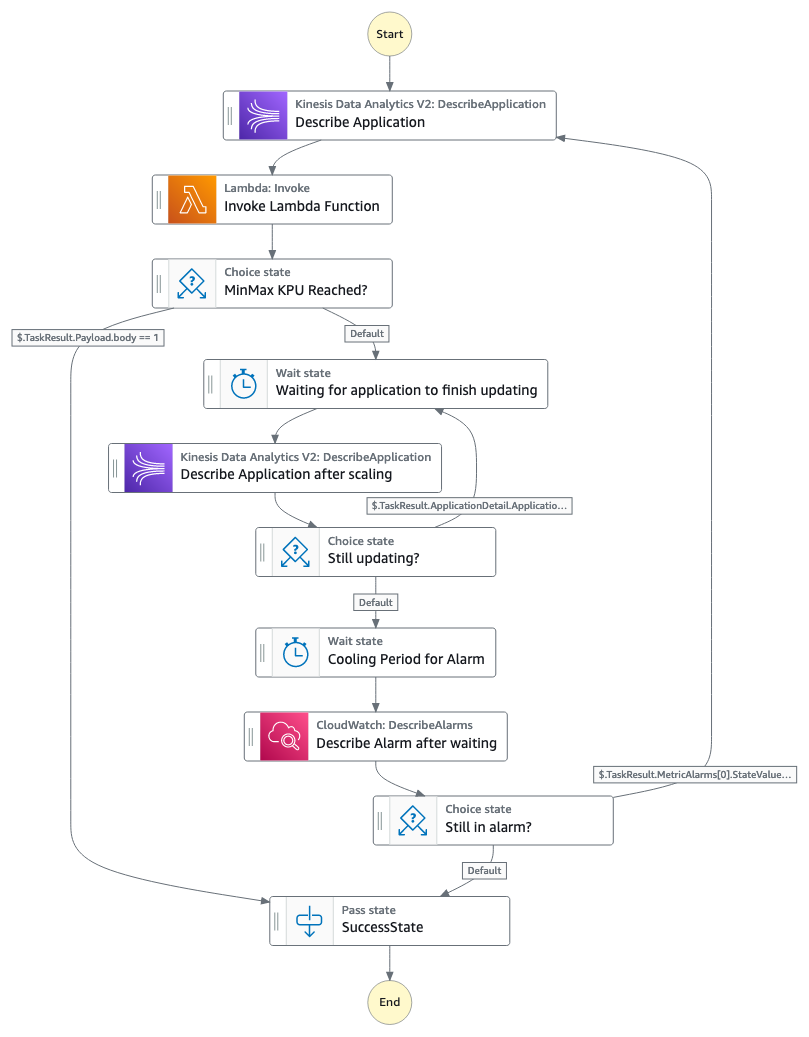
Nota: Amazon Kinesis Data Analytics pasó a llamarse Amazon Managed Service para Apache Flink en agosto de 2023
El flujo de trabajo de Step Functions consta de los siguientes pasos:
- La máquina de estado describe la aplicación Amazon Managed Service para Apache Flink, que proporcionará información relacionada con la cantidad actual de KPU en la aplicación, así como si la aplicación se está actualizando o se está ejecutando.
- La máquina de estado invoca una función Lambda que, según la alarma que se activó, aumentará o reducirá la aplicación, siguiendo los parámetros establecidos en la plantilla de CloudFormation. Al escalar la aplicación, utilizará el factor de aumento (ya sea sumar/restar o multiplicar/dividir según ese factor) definido en la plantilla de CloudFormation. Puede tener diferentes factores para ampliar o reducir. Si desea adoptar un enfoque más cauteloso al escalar, puede usar sumar/restar y usar un factor de aumento para aumentar/reducir de 1.
- Si la aplicación ha alcanzado el número máximo o mínimo de KPU establecido en los parámetros de la plantilla de CloudFormation, el flujo de trabajo se detiene. Tenga en cuenta que las aplicaciones de Amazon Managed Service para Apache Flink tienen un máximo predeterminado de 64 KPU (puede solicitar aumentar este límite). No especifique un valor máximo superior a 64 KPU si no ha solicitado aumentar la cuota, porque la solución de escalado se atascará al no actualizarse.
- Si el flujo de trabajo continúa, porque las KPU asignadas no han alcanzado los valores máximo o mínimo, el flujo de trabajo esperará durante un período de tiempo que usted especifique y luego describirá la aplicación y verá si ha terminado de actualizarse.
- El flujo de trabajo seguirá esperando hasta que la aplicación haya terminado de actualizarse. Cuando se actualiza la aplicación, el flujo de trabajo esperará un período de tiempo que usted especifique en la plantilla de CloudFormation, para permitir que la métrica caiga dentro del umbral y que la regla de CloudWatch cambie del estado de ALARMA a OK.
- Si la métrica todavía está en estado de ALARMA, el flujo de trabajo comenzará nuevamente y continuará escalando la aplicación hacia arriba o hacia abajo. Si la métrica está en estado OK, el flujo de trabajo se detendrá.
Para aplicaciones que leen desde una fuente de Kinesis Data Streams, puede usar la métrica millisDetrásÚltimo. Si usa una fuente Kafka, puede usar registros de retraso máximo para escalar eventos. Estas métricas capturan qué tan lejos está su aplicación del inicio de la transmisión. También puede utilizar una métrica personalizada que haya registrado en sus aplicaciones Apache Flink.
La plantilla de ejemplo de CloudFormation le permite seleccionar una de las siguientes métricas:
- Métricas de la aplicación Amazon Managed Service para Apache Flink – Requiere un nombre de aplicación:
- Utilización de CPU de contenedor – Porcentaje general de utilización de CPU en los contenedores del administrador de tareas en el clúster de aplicaciones de Flink.
- Utilización de memoria de contenedor – Porcentaje general de utilización de memoria en los contenedores del administrador de tareas en el clúster de aplicaciones de Flink.
- OcupadoTiempoMsPorSegundo – Tiempo en milisegundos que la aplicación está ocupada (ni inactiva ni contraprimida) por segundo.
- EspaldaTiempoPresionadoMsPorSegundo – Tiempo en milisegundos en que la aplicación recibe contrapresión por segundo.
- Duración del último punto de control – Tiempo en milisegundos que tardó en completar el último punto de control.
- Métricas de Kinesis Data Streams – Requiere el nombre del flujo de datos:
- MillisDetrásÚltimo – La cantidad de milisegundos que el consumidor está detrás del encabezado de la transmisión, lo que indica qué tan atrasado está el consumidor con respecto a la hora actual.
- Registros entrantes – La cantidad de registros colocados correctamente en el flujo de datos de Kinesis durante el período de tiempo especificado. Si no llegan registros, esta métrica será nula y no podrá reducirla.
- Métricas de Amazon MSK – Requiere el nombre del clúster, el nombre del tema y el nombre del grupo de consumidores):
- MaxOffsetLag – El retraso de compensación máximo en todas las particiones de un tema.
- SumaCompensaciónRetraso – El retraso de compensación agregado para todas las particiones de un tema.
- EstimadoMaxTimeLag – El tiempo estimado (en segundos) para drenar MaxOffsetLag.
- Métricas personalizadas – Métricas que puede definir como parte de sus aplicaciones Apache Flink. Las métricas más comunes son contadores (aumentan continuamente) o indicadores (se pueden actualizar con el último valor). Para esta solución, debe agregar la dimensión kinesisAnalytics al grupo de métricas. También debe proporcionar el nombre de la métrica personalizada como parámetro en la plantilla de CloudFormation. Si necesita usar más dimensiones en su métrica personalizada, debe modificar la alarma de CloudWatch para que pueda usar su métrica específica. Para obtener más información sobre métricas personalizadas, consulte Uso de métricas personalizadas con Amazon Managed Service para Apache Flink.
La plantilla de CloudFormation implementa los recursos así como el código de escalado automático. Solo necesita especificar el nombre de la aplicación Amazon Managed Service para Apache Flink, la métrica a la que desea ampliar o reducir su aplicación y los umbrales para activar una alarma. La solución de forma predeterminada utilizará la agregación promedio para métricas y una duración de período de 60 segundos para cada punto de datos. Puede configurar los períodos de evaluación y los puntos de datos para alarmar al definir la plantilla de CloudFormation.
Escalado programado
Esta sección describe cómo implementar una solución de escalado para Amazon Managed Service para Apache Flink según un cronograma. Para realizar el escalado programado, utilizamos EventBridge y Lambda, como se ilustra en la siguiente figura.
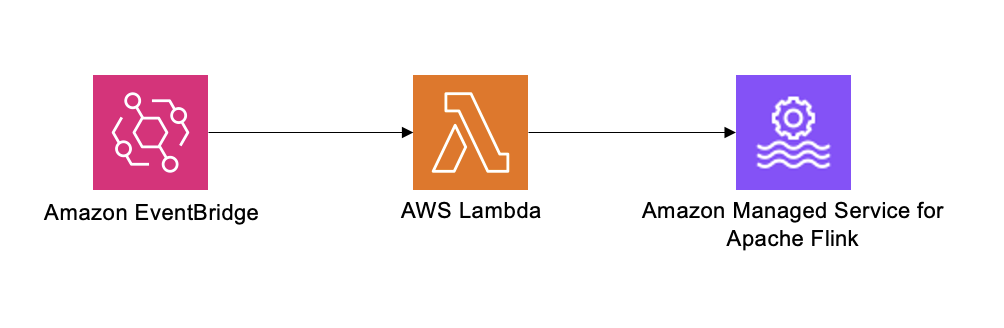
Estos componentes están disponibles en la plantilla de CloudFormation en el Repositorio GitHub.
El programador de EventBridge se activa según los parámetros establecidos al implementar la plantilla de CloudFormation. Usted define la KPU de las aplicaciones cuando se ejecutan en horas pico, así como la KPU para horas no pico. La aplicación se ejecuta con esos parámetros de KPU según la hora del día.
Al igual que en el ejemplo anterior de escalado basado en métricas, la plantilla de CloudFormation implementa los recursos y el código de escalado necesarios. Solo necesita especificar el nombre de la aplicación Amazon Managed Service para Apache Flink y el cronograma para que el escalador modifique la aplicación al número establecido de KPU.
Consideraciones para escalar aplicaciones de Flink mediante escalado programado o basado en métricas
Tenga en cuenta lo siguiente al considerar estas soluciones:
- Al ampliar o reducir las aplicaciones de Amazon Managed Service para Apache Flink, puede optar por aumentar el paralelismo general de la aplicación o modificar el paralelismo por KPU. Este último le permite establecer la cantidad de tareas paralelas que se pueden programar por KPU. Este ejemplo solo actualiza el paralelismo general, no el paralelismo por KPU.
- Si SnapshotsEnabled se establece en verdadero en ApplicationSnapshotConfiguration, Amazon Managed Service para Apache Flink pausará automáticamente la aplicación, tomará una instantánea y luego restaurará la aplicación con la configuración actualizada cada vez que se actualice o escale. Este proceso puede provocar un tiempo de inactividad para la aplicación, según el tamaño del estado, pero no habrá pérdida de datos. Al utilizar el escalado basado en métricas, debe elegir un umbral mínimo y máximo de KPU que la aplicación puede tener. Dependiendo de cuánto realice el escalado, si la nueva KPU deseada es mayor o menor que sus umbrales, la solución actualizará las KPU para que sean iguales a sus umbrales.
- Al utilizar el escalado basado en métricas, también debe elegir un período de enfriamiento. Esta es la cantidad de tiempo que desea que espere su aplicación después de actualizarse, para ver si la métrica ha pasado del estado de ALARMA al estado OK. Este valor depende de cuánto tiempo esté dispuesto a esperar antes de que ocurra otro evento de escala.
- Con la solución de escalamiento basada en métricas, está limitado a elegir las métricas que se enumeran en la plantilla de CloudFormation. Sin embargo, puede modificar las alarmas para utilizar cualquier métrica disponible en CloudWatch.
- Si es necesario que su aplicación se ejecute sin interrupciones durante períodos de tiempo, le recomendamos utilizar el escalado programado para limitar el escalado a momentos no críticos.
Resumen
En esta publicación, cubrimos cómo puede habilitar el escalado personalizado para aplicaciones Amazon Managed Service para Apache Flink utilizando funciones de monitoreo mejoradas de CloudWatch integradas con Step Functions y Lambda. También mostramos cómo se puede configurar un cronograma para escalar una aplicación usando EventBridge. Ambas muestras y muchas más se pueden encontrar en el Repositorio GitHub.
Acerca de los autores
 Deepthi Mohan es PMT principal en el equipo de Amazon Managed Service para Apache Flink.
Deepthi Mohan es PMT principal en el equipo de Amazon Managed Service para Apache Flink.
 francisco morillo es arquitecto de soluciones de streaming en AWS. Francisco trabaja con clientes de AWS, ayudándolos a diseñar arquitecturas de análisis en tiempo real utilizando los servicios de AWS, brindando soporte a Amazon Managed Streaming para Apache Kafka (Amazon MSK) y Amazon Managed Service para Apache Flink.
francisco morillo es arquitecto de soluciones de streaming en AWS. Francisco trabaja con clientes de AWS, ayudándolos a diseñar arquitecturas de análisis en tiempo real utilizando los servicios de AWS, brindando soporte a Amazon Managed Streaming para Apache Kafka (Amazon MSK) y Amazon Managed Service para Apache Flink.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/enable-metric-based-and-scheduled-scaling-for-amazon-managed-service-for-apache-flink/

