Introducción
La búsqueda constante de precisión y confiabilidad en el campo de Inteligencia artificial (IA) ha aportado innovaciones revolucionarias. Estas estrategias son fundamentales para liderar modelos generativos que ofrezcan respuestas relevantes a una variedad de preguntas. Una de las mayores barreras para el uso de la IA generativa en diferentes aplicaciones sofisticadas son las alucinaciones. El artículo reciente publicado por Meta AI Research titulado “La cadena de verificación reduce las alucinaciones en modelos de lenguaje grandes” analiza una técnica simple para reducir directamente las alucinaciones al generar texto.
En este artículo, aprenderemos sobre los problemas de alucinaciones y exploraremos los conceptos de CoVe mencionados en el artículo y cómo implementarlo utilizando LLM, LangChain Framework y LangChain Expression Language (LCEL) para crear cadenas personalizadas.
OBJETIVOS DE APRENDIZAJE
- Comprender el problema de las alucinaciones en los LLM.
- Conozca el mecanismo de la Cadena de Verificación (CoVe) para mitigar las alucinaciones.
- Conozca las ventajas y desventajas de CoVe.
- Aprenda a implementar CoVe utilizando LangChain y comprenda el lenguaje de expresión LangChain.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Índice del contenido
¿Cuál es el problema de las alucinaciones en los LLM?
Primero intentemos aprender sobre el tema de las alucinaciones en LLM. Utilizando el enfoque de generación autorregresiva, el modelo LLM predice la siguiente palabra dado el contexto anterior. Para temas frecuentes, el modelo ha visto suficientes ejemplos para asignar con seguridad una alta probabilidad de corregir los tokens. Sin embargo, debido a que el modelo no ha sido entrenado en temas inusuales o desconocidos, puede generar tokens inexactos con un alto nivel de confianza. Esto da lugar a alucinaciones de información que suena plausible pero errónea.
A continuación se muestra un ejemplo de alucinación en ChatGPT de Open AI donde pregunté sobre el libro “Economía de las pequeñas cosas”, publicado en 2020 por un autor indio, pero el modelo escupió la respuesta incorrecta con total confianza y la confundió con el libro de otro. El premio Nobel Abhijit Banerjee, titulado “Economía pobre”.

Técnica de cadena de verificación (CoVe)
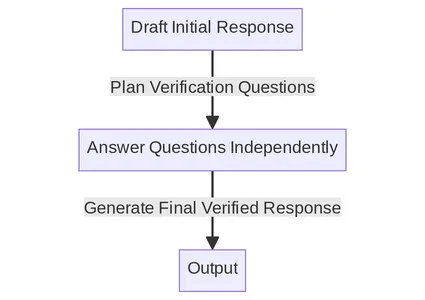
El mecanismo CoVe combina indicaciones y controles de coherencia para crear un sistema de autoverificación para los LLM. A continuación se detallan los pasos principales enumerados en el documento. Intentaremos comprender cada paso en detalle uno por uno.
Descripción general del proceso de la cadena
- Generar respuesta de referencia: Dada una consulta, genere la respuesta utilizando el LLM.
- Verificaciones de planes: Dadas tanto la consulta como la respuesta inicial, genere una lista de preguntas de verificación que podrían ayudar a autoanalizar si hay algún error en la respuesta original.
- Ejecutar verificaciones: Responda cada pregunta de verificación por turno y, por lo tanto, compare la respuesta con la respuesta original para comprobar si hay inconsistencias o errores.
- Generar respuesta final verificada: Dadas las inconsistencias descubiertas (si las hay), genere una respuesta revisada que incorpore los resultados de la verificación.
Comprender el proceso de la cadena mediante un ejemplo detallado
Generar respuesta inicial
Primero pasamos nuestra consulta a LLM sin ningún aviso especial para generar una respuesta inicial. Esto sirve como punto de partida para el proceso CoVe. Debido a que reacciones iniciales como estas suelen ser propensas a alucinaciones, la técnica CoVe busca descubrir y corregir estos errores en fases posteriores.
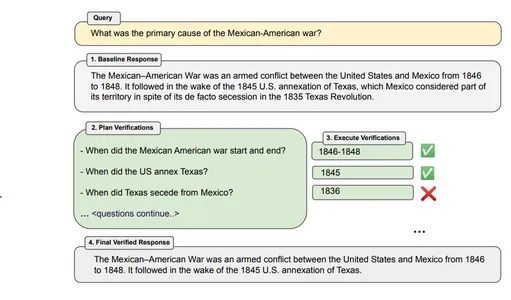
Ejemplo “¿Cuál es la causa principal de la guerra entre México y Estados Unidos?”
Respuesta del Bot: La Guerra México-Estadounidense fue un conflicto armado entre Estados Unidos y México de 1846 a 1848. Fue seguido a raíz de la anexión estadounidense de Texas en 1845, que se consideraba parte de su territorio a pesar de su ocupación de facto. secesión en la Revolución de Texas de 1835.
Verificaciones de planes
Cree preguntas de verificación basadas en la consulta y la respuesta inicial que nos permitan examinar las afirmaciones fácticas de la respuesta inicial. Para implementar esto, podemos solicitar un modelo de una serie de preguntas de verificación basadas tanto en la consulta como en la respuesta inicial. Las preguntas de verificación pueden ser flexibles y no es necesario que coincidan exactamente con el texto original.
Ejemplo – ¿Cuándo comenzó y terminó la guerra entre México y Estados Unidos? ¿Cuándo Estados Unidos anexó Texas? ¿Cuándo se separó Texas de México?
Ejecutar verificaciones
Una vez que hayamos planificado las preguntas de verificación, podremos responderlas individualmente. El documento analiza 4 métodos diferentes para ejecutar verificaciones:
1. Conjunto – En esto, la planificación y ejecución de las preguntas de verificación se realizan en un solo mensaje. Las preguntas y sus respuestas se proporcionan en el mismo mensaje de LLM. Generalmente no se recomienda este método ya que la respuesta de verificación puede generar alucinaciones.
2. 2 pasos – La planificación y ejecución se realizan por separado en dos pasos con indicaciones de LLM separadas. Primero, generamos preguntas de verificación y luego las respondemos.
3. Factorizado – Aquí, cada pregunta de verificación se responde de forma independiente en lugar de con la misma gran respuesta, y no se incluye la respuesta original de referencia. Puede ayudar a evitar confusiones entre diferentes preguntas de verificación y también puede manejar una mayor cantidad de preguntas.
4. Factorizado + Revisar – Se agrega un paso adicional en este método. Después de responder cada pregunta de verificación, el mecanismo CoVe verifica si las respuestas coinciden con la respuesta inicial original. Esto se hace en un paso separado mediante un mensaje adicional.
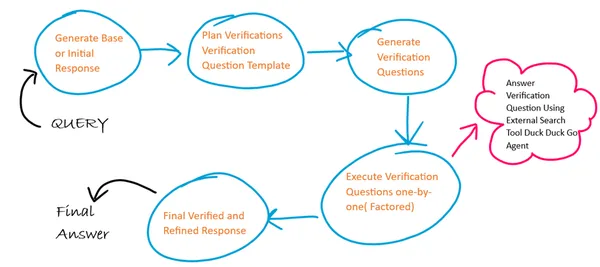
Herramientas externas o Self LLM: Necesitamos una herramienta que verifique nuestras respuestas y dé respuestas de verificación. Esto se puede realizar utilizando el propio LLM o una herramienta externa. Si queremos una mayor precisión, en lugar de depender de LLM, podemos utilizar herramientas externas como un motor de búsqueda de Internet, cualquier documento de referencia o cualquier sitio web, según nuestro caso de uso.
Respuesta final verificada
En este paso final se genera una respuesta mejorada y verificada. Se utiliza un mensaje de algunas tomas y se incluye todo el contexto previo de la respuesta de referencia y las respuestas a las preguntas de verificación. Si se utilizó el método “Factor+Revisar”, también se proporciona el resultado de la inconsistencia cruzada.
Limitaciones de la técnica CoVe
Aunque la Cadena de Verificación parece una técnica simple pero efectiva, todavía tiene algunas limitaciones:
- Alucinación no eliminada por completo: No garantiza la eliminación completa de las alucinaciones de la respuesta y, por tanto, puede producir información engañosa.
- Computación intensiva: Generar y ejecutar verificaciones junto con la generación de respuestas puede aumentar la sobrecarga y el costo computacional. Por tanto, puede ralentizar el proceso o aumentar el coste informático.
- Limitación específica del modelo: El éxito de este método CoVe depende en gran medida de las capacidades del modelo y de su capacidad para identificar y rectificar sus errores.
Implementación LangChain de CoVe
Esquema básico del algoritmo
Aquí usaremos 4 plantillas de mensajes diferentes para cada uno de los 4 pasos en CoVe y en cada paso la salida del paso anterior actúa como entrada para el siguiente paso. Además, seguimos un enfoque factorizado para la ejecución de las preguntas de verificación. Utilizamos un agente externo de herramienta de búsqueda en Internet para generar respuestas a nuestras preguntas de verificación.
Paso 1: instalar y cargar bibliotecas
!pip install langchain duckduckgo-searchPaso 2: crear e inicializar la instancia LLM
Aquí estoy usando Google Palm LLM en Langchain ya que está disponible gratuitamente. Se puede generar la clave API para Google Palm usando esto liga e inicie sesión con su cuenta de Google.
from langchain import PromptTemplate
from langchain.llms import GooglePalm
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
API_KEY='Generated API KEY'
llm=GooglePalm(google_api_key=API_KEY)
llm.temperature=0.4
llm.model_name = 'models/text-bison-001'
llm.max_output_tokens=2048
Paso 3: Generar una respuesta inicial inicial
Ahora crearemos una plantilla de solicitud para generar la respuesta de referencia inicial y el uso de esta plantilla creará la cadena LLM de respuesta de referencia.
Una cadena LLM utilizará el lenguaje de expresión LangChain para componer la cadena. Aquí le damos la plantilla de aviso encadenada (|) con el modelo LLM (|) y luego, finalmente, el analizador de salida.
BASELINE_PROMPT = """Answer the below question which is asking for a concise factual answer. NO ADDITIONAL DETAILS.
Question: {query}
Answer:"""
# Chain to generate initial response
baseline_response_prompt_template = PromptTemplate.from_template(BASELINE_PROMPT)
baseline_response_chain = baseline_response_prompt_template | llm | StrOutputParser()Paso 4: Generar plantilla de pregunta para pregunta de verificación
Ahora construiremos una plantilla de preguntas de verificación que luego ayudará a generar las preguntas de verificación en el siguiente paso.
VERIFICATION_QUESTION_TEMPLATE = """Your task is to create a verification question based on the below question provided.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things] ?
Explanation: In the above example the verification question focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (book name).
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and generate verification question.
Actual Question: {query}
Final Verification Question:"""
# Chain to generate a question template for verification answers
verification_question_template_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_TEMPLATE)
verification_question_template_chain = verification_question_template_prompt_template | llm | StrOutputParser()Paso 5: Generar pregunta de verificación
Ahora generaremos preguntas de verificación utilizando la plantilla de preguntas de verificación definida anteriormente:
VERIFICATION_QUESTION_PROMPT= """Your task is to create a series of verification questions based on the below question, the verfication question template and baseline response.
Example Question: Who wrote the book 'God of Small Things' ?
Example Verification Question Template: Was book [God of Small Things] written by [writer]? If not who wrote [God of Small Things]?
Example Baseline Response: Jhumpa Lahiri
Example Verification Question: 1. Was God of Small Things written by Jhumpa Lahiri? If not who wrote God of Small Things ?
Explanation: In the above example the verification questions focused only on the ANSWER_ENTITY (name of the writer) and QUESTION_ENTITY (name of book) based on the template and substitutes entity values from the baseline response.
Similarly you need to focus on the ANSWER_ENTITY and QUESTION_ENTITY from the actual question and substitute the entity values from the baseline response to generate verification questions.
Actual Question: {query}
Baseline Response: {base_response}
Verification Question Template: {verification_question_template}
Final Verification Questions:"""
# Chain to generate the verification questions
verification_question_generation_prompt_template = PromptTemplate.from_template(VERIFICATION_QUESTION_PROMPT)
verification_question_generation_chain = verification_question_generation_prompt_template | llm | StrOutputParser()
Paso 6: ejecutar la pregunta de verificación
Aquí utilizaremos el agente de la herramienta de búsqueda externa para ejecutar la pregunta de verificación. Este agente se construye utilizando el módulo Agente y herramientas de LangChain y el módulo de búsqueda DuckDuckGo.
Nota: existen restricciones de tiempo en los agentes de búsqueda que se deben utilizar con cuidado, ya que varias solicitudes pueden generar un error debido a restricciones de tiempo entre solicitudes.
from langchain.agents import ConversationalChatAgent, AgentExecutor
from langchain.tools import DuckDuckGoSearchResults
#create search agent
search = DuckDuckGoSearchResults()
tools = [search]
custom_system_message = "Assistant assumes no knowledge & relies on internet search to answer user's queries."
max_agent_iterations = 5
max_execution_time = 10
chat_agent = ConversationalChatAgent.from_llm_and_tools(
llm=llm, tools=tools, system_message=custom_system_message
)
search_executor = AgentExecutor.from_agent_and_tools(
agent=chat_agent,
tools=tools,
return_intermediate_steps=True,
handle_parsing_errors=True,
max_iterations=max_agent_iterations,
max_execution_time = max_execution_time
)
# chain to execute verification questions
verification_chain = RunnablePassthrough.assign(
split_questions=lambda x: x['verification_questions'].split("n"), # each verification question is passed one by one factored approach
) | RunnablePassthrough.assign(
answers = (lambda x: [{"input": q,"chat_history": []} for q in x['split_questions']])| search_executor.map() # search executed for each question independently
) | (lambda x: "n".join(["Question: {} Answer: {}n".format(question, answer['output']) for question, answer in zip(x['split_questions'], x['answers'])]))# Create final refined response
Paso 7: Generar una respuesta final refinada
Ahora generaremos la respuesta refinada final para la cual definimos la plantilla de mensaje y la cadena de llm.
FINAL_ANSWER_PROMPT= """Given the below `Original Query` and `Baseline Answer`, analyze the `Verification Questions & Answers` to finally provide the refined answer.
Original Query: {query}
Baseline Answer: {base_response}
Verification Questions & Answer Pairs:
{verification_answers}
Final Refined Answer:"""
# Chain to generate the final answer
final_answer_prompt_template = PromptTemplate.from_template(FINAL_ANSWER_PROMPT)
final_answer_chain = final_answer_prompt_template | llm | StrOutputParser()Paso 8: junta todas las cadenas
Ahora juntamos todas las cadenas que definimos anteriormente para que se ejecuten en secuencia de una sola vez.
chain = RunnablePassthrough.assign(
base_response=baseline_response_chain
) | RunnablePassthrough.assign(
verification_question_template=verification_question_template_chain
) | RunnablePassthrough.assign(
verification_questions=verification_question_generation_chain
) | RunnablePassthrough.assign(
verification_answers=verification_chain
) | RunnablePassthrough.assign(
final_answer=final_answer_chain
)
response = chain.invoke({"query": "Who wrote the book 'Economics of Small Things' ?"})
print(response)#output of response
{'query': "Who wrote the book 'Economics of Small Things' ?", 'base_response': 'Sanjay Jain', 'verification_question_template': 'Was book [Economics of Small Things] written by [writer]? If not who wrote [Economics of Small Things] ?', 'verification_questions': '1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ?', 'verification_answers': 'Question: 1. Was Economics of Small Things written by Sanjay Jain? If not who wrote Economics of Small Things ? Answer: The Economics of Small Things was written by Sudipta Sarangi n', 'final_answer': 'Sudipta Sarangi'}Imagen de salida:
Conclusión
La técnica de Cadena de Verificación (CoVe) propuesta en el estudio es una estrategia que tiene como objetivo construir grandes modelos de lenguaje, pensar de manera más crítica sobre sus respuestas y corregirse a sí mismos si es necesario. Esto se debe a que este método divide la verificación en consultas más pequeñas y manejables. También se ha demostrado que prohibir al modelo revisar sus respuestas anteriores ayuda a evitar que se repitan errores o “alucinaciones”. Simplemente requerir que el modelo verifique dos veces sus respuestas aumenta significativamente sus resultados. Darle a CoVe más capacidades, como permitirle extraer información de fuentes externas, podría ser una forma de aumentar su eficacia.
Puntos clave
- El proceso de Cadena es una herramienta útil con varias combinaciones de técnicas que nos permiten verificar diferentes partes de nuestra respuesta.
- Además de muchas ventajas, existen ciertas limitaciones del proceso de la Cadena que pueden mitigarse utilizando diferentes herramientas y mecanismos.
- Podemos aprovechar el paquete LangChain para implementar este proceso CoVe.
Preguntas frecuentes
R. Hay varias formas de reducir las alucinaciones en diferentes niveles: nivel de indicación (árbol de pensamiento, cadena de pensamiento), nivel de modelo (decodificación DoLa mediante capas contrastantes) y autocomprobación (CoVe).
R. Podemos mejorar el proceso de verificación en CoVe utilizando el soporte de herramientas de búsqueda externas como la API de búsqueda de Google, etc. y para casos de uso personalizados y de dominio podemos usar técnicas de recuperación como RAG.
R. Actualmente no existe ninguna herramienta de código abierto lista para usar que implemente este mecanismo, pero podemos construir una por nuestra cuenta con la ayuda de Serp API, Google Search y Lang Chains.
R. La técnica de recuperación de generación aumentada (RAG) se utiliza para casos de uso de dominios específicos en los que LLM puede producir respuestas objetivamente correctas basadas en la recuperación de datos de estos dominios específicos.
R. El artículo utilizó el modelo Llama 65B como LLM, luego utilizaron ingeniería de indicaciones utilizando ejemplos breves para generar preguntas y brindar orientación al modelo.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/12/chain-of-verification-implementation-using-langchain-expression-language-and-llm/

