Imagen del autor
Este tutorial discutirá cómo aprovechar la capacidad de Python para ejecutar tareas de multiproceso y multiprogramación. Ofrecen una puerta de enlace para realizar operaciones simultáneas dentro de un solo proceso o entre múltiples procesos. La ejecución paralela y concurrente aumenta la velocidad y eficiencia de los sistemas. Después de discutir los conceptos básicos de multiproceso y multiprogramación, también discutiremos su implementación práctica utilizando bibliotecas de Python. Primero analicemos brevemente los beneficios de los sistemas paralelos.
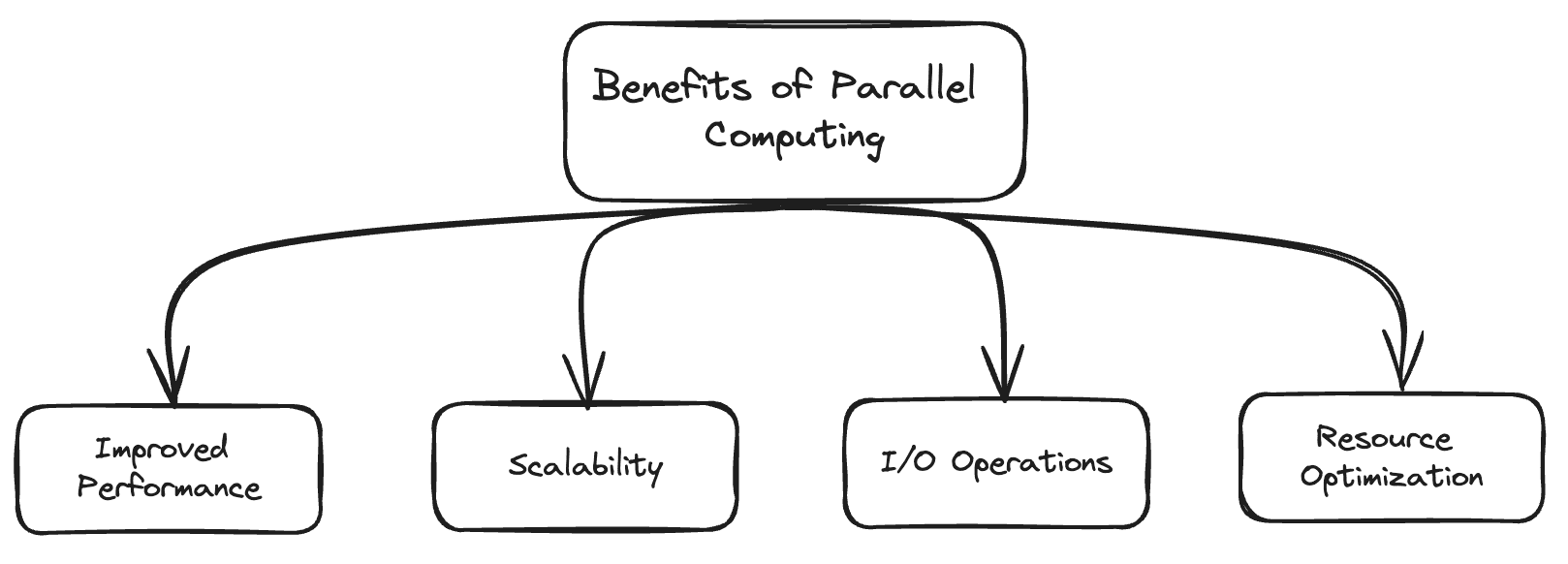
- Desempeño mejorado: Con la capacidad de realizar tareas simultáneamente, podemos reducir el tiempo de ejecución y mejorar el rendimiento general del sistema.
- Escalabilidad: Podemos dividir una tarea grande en varias subtareas más pequeñas y asignarles un núcleo o hilo separado para su ejecución independiente. Puede resultar útil en sistemas a gran escala.
- Operaciones de E/S eficientes: Con la ayuda de la concurrencia, la CPU no tiene que esperar a que un proceso complete sus operaciones de E/S. La CPU puede comenzar inmediatamente a ejecutar el siguiente proceso hasta que el proceso anterior esté ocupado con su E/S.
- Optimización de recursos: Al dividir los recursos, podemos evitar que un solo proceso consuma todos los recursos. Esto puede evitar el problema de Hambre para procesos más pequeños.
Beneficios de la computación paralela | Imagen por autor
Estas son algunas razones comunes por las que necesita ejecuciones simultáneas o paralelas. Ahora, regresemos a los temas principales, es decir, multiproceso y multiprogramación, y analicemos sus principales diferencias.
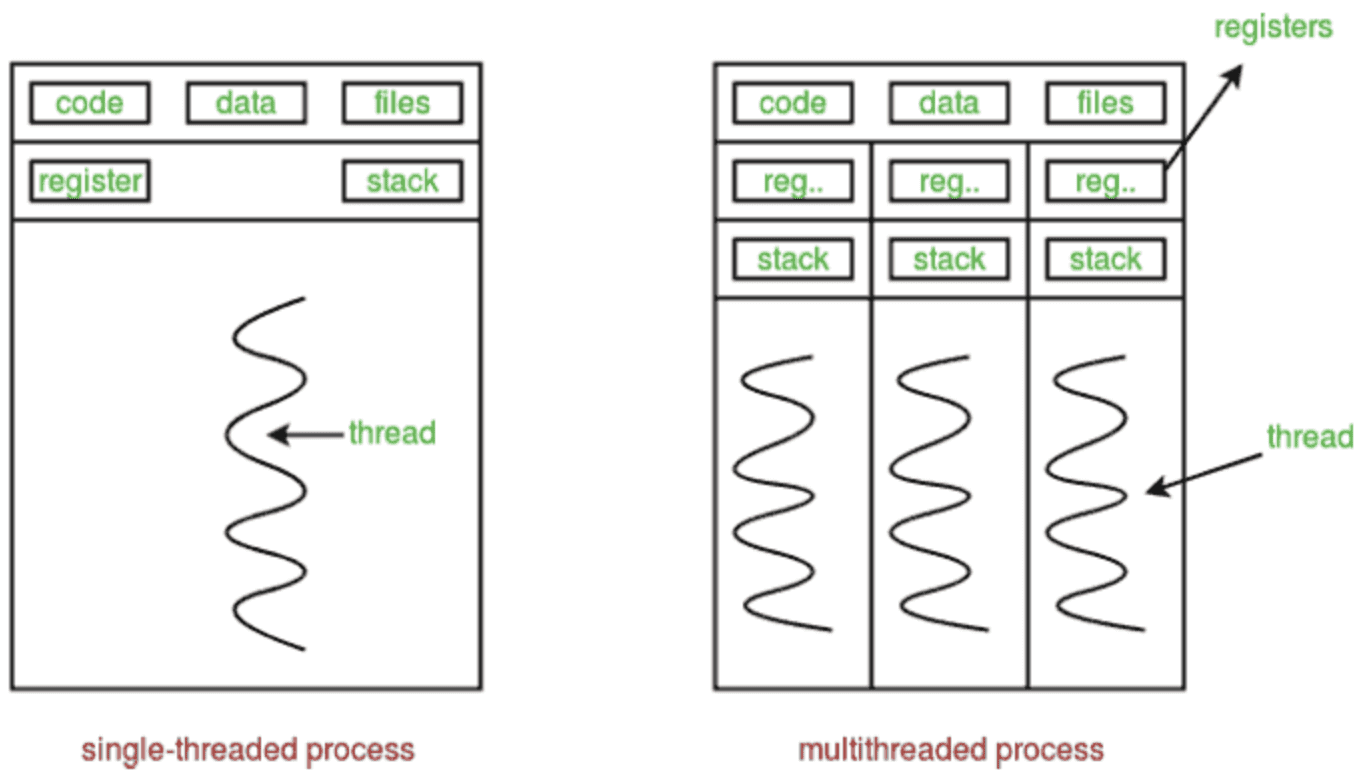
El multithreading es una de las formas de lograr el paralelismo en un solo proceso y poder ejecutar tareas simultáneas. Se pueden crear varios subprocesos dentro de un solo proceso y realizar tareas más pequeñas en paralelo dentro de ese proceso.
Los subprocesos presentes dentro de un único proceso comparten un espacio de memoria común, pero sus registros y seguimientos de pila están separados. Son menos costosos computacionalmente debido a esta memoria compartida.
Env. de rosca única y rosca múltiple. | Imagen por GeeksParaGeeks
El subproceso múltiple se utiliza principalmente para realizar operaciones de E/S, es decir, si alguna parte del programa está ocupada en operaciones de E/S, entonces el programa restante puede responder. Sin embargo, en la implementación de Python, el subproceso múltiple no puede lograr un verdadero paralelismo debido al bloqueo global de intérprete (GIL).
En resumen, GIL es un bloqueo mutex que permite que solo un subproceso a la vez interactúe con el código de bytes de Python, es decir, incluso en el modo multiproceso, solo un subproceso puede ejecutar el código de bytes a la vez.
Se hace para mantener la seguridad de los subprocesos en CPython, pero esto limita los beneficios de rendimiento del subproceso múltiple. Para solucionar este problema, Python tiene una biblioteca de multiprocesamiento independiente, que analizaremos más adelante.
¿Qué son los hilos demoníacos?
Los hilos que se ejecutan constantemente en segundo plano se denominan hilos demoníacos. Su trabajo principal es soportar el hilo principal o los hilos que no son demonios. El hilo del demonio no bloquea la ejecución del hilo principal e incluso continúa ejecutándose si ha completado su ejecución.
En Python, los subprocesos del demonio se utilizan principalmente como recolector de basura. Destruirá todos los objetos inútiles y liberará la memoria de forma predeterminada para que el hilo principal pueda usarse y ejecutarse correctamente.
El multiprocesamiento se utiliza para realizar la ejecución paralela de múltiples procesos. Nos ayuda a lograr un verdadero paralelismo, ya que ejecutamos procesos separados simultáneamente, teniendo su propio espacio de memoria. Utiliza núcleos separados de la CPU y también es útil para realizar comunicaciones entre procesos para intercambiar datos entre múltiples procesos.
El multiprocesamiento es más costoso computacionalmente en comparación con el multiproceso, ya que no utilizamos un espacio de memoria compartido. Aún así, nos permite la ejecución independiente y supera las limitaciones de Global Interpreter Lock.
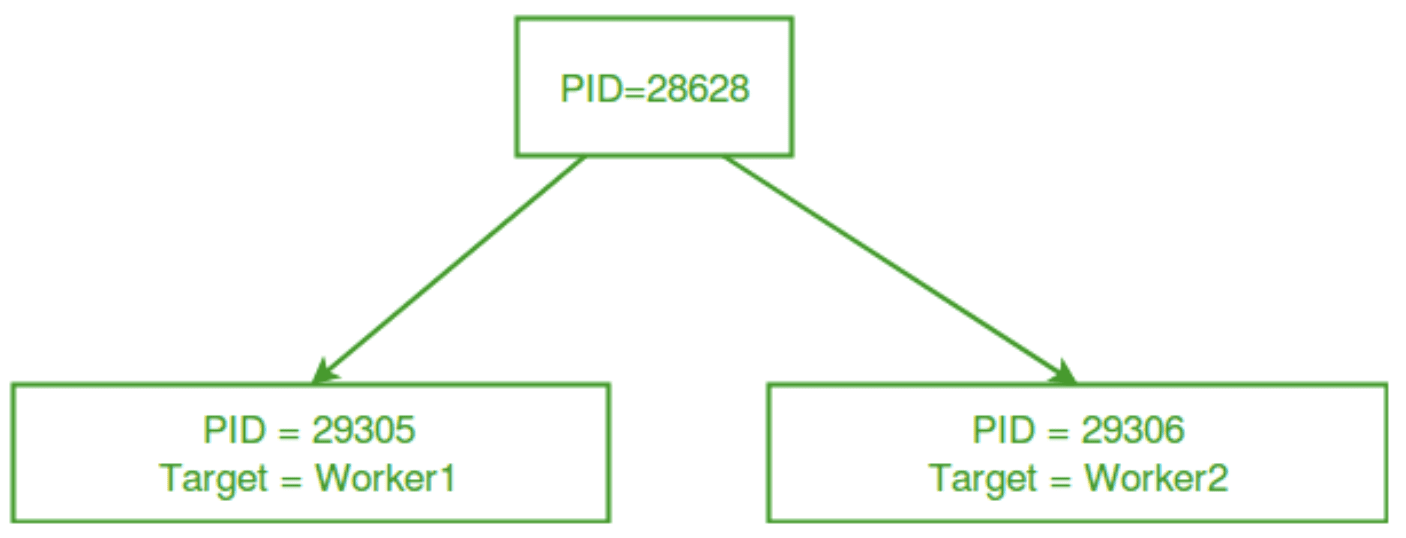
Entorno multiprocesamiento | Imagen por GeeksParaGeeks
La figura anterior demuestra un entorno de multiprocesamiento en el que un proceso principal crea dos procesos separados y les asigna trabajo por separado.
Es hora de implementar un ejemplo básico de subprocesos múltiples usando Python. Python tiene un módulo incorporado threading utilizado para la implementación de subprocesos múltiples.
- Importación de bibliotecas:
import threading
import os
- Función para calcular los cuadrados:
Esta es una función simple que se utiliza para encontrar el cuadrado de números. Se proporciona una lista de números como entrada y genera el cuadrado de cada número de la lista junto con el nombre del subproceso utilizado y el ID del proceso asociado con ese subproceso.
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | Thread Name {threading.current_thread().name} | PID of the process {os.getpid()}"
)
- Función Principal:
Tenemos una lista de números y la dividiremos en partes iguales y los nombraremos fisrt_half y second_half respectivamente. Ahora asignaremos dos hilos separados. t1 y t2 a estas listas.
Thread La función crea un nuevo hilo, que toma una función con una lista de argumentos para esa función. También puedes asignar un nombre separado a un hilo.
.start() La función comenzará a ejecutar estos subprocesos y .join() La función bloqueará la ejecución del hilo principal hasta que el hilo dado no se ejecute por completo.
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
t1 = threading.Thread(target=calculate_squares, name="t1", args=(first_half,))
t2 = threading.Thread(target=calculate_squares, name="t2", args=(second_half,))
t1.start()
t2.start()
t1.join()
t2.join()
Salida:
Square of the number 1 is 1 | Thread Name t1 | PID of the process 345
Square of the number 2 is 4 | Thread Name t1 | PID of the process 345
Square of the number 5 is 25 | Thread Name t2 | PID of the process 345
Square of the number 3 is 9 | Thread Name t1 | PID of the process 345
Square of the number 6 is 36 | Thread Name t2 | PID of the process 345
Square of the number 4 is 16 | Thread Name t1 | PID of the process 345
Square of the number 7 is 49 | Thread Name t2 | PID of the process 345
Square of the number 8 is 64 | Thread Name t2 | PID of the process 345
Nota: Todos los hilos creados anteriormente son hilos que no son demonios. Para crear un hilo de demonio, necesitas escribir
t1.setDaemon(True)para hacer el hilot1un hilo de demonio.
Ahora, entenderemos el resultado generado por el código anterior. Podemos observar que el ID del proceso (es decir, PID) seguirá siendo el mismo para ambos subprocesos, lo que significa que estos dos subprocesos son parte del mismo proceso.
También puede observar que la salida no se genera secuencialmente. En la primera línea, verá la salida generada por el subproceso1, luego en la tercera línea, la salida generada por el subproceso3, luego nuevamente por el subproceso2 en la cuarta línea. Esto significa claramente que estos hilos trabajan juntos al mismo tiempo.
La concurrencia no significa que estos dos subprocesos se ejecuten en paralelo, ya que solo se ejecuta un subproceso a la vez. No reduce el tiempo de ejecución. Lleva el mismo tiempo que la ejecución secuencial. La CPU comienza a ejecutar un hilo pero lo deja a mitad de camino y pasa a otro hilo, y después de un tiempo, regresa al hilo principal y comienza su ejecución desde el mismo punto donde salió la última vez.
Espero que tenga un conocimiento básico de subprocesos múltiples con su implementación y sus limitaciones. Ahora es el momento de aprender sobre la implementación del multiprocesamiento y cómo podemos superar esas limitaciones.
Seguiremos el mismo ejemplo, pero en lugar de crear dos hilos separados, crearemos dos procesos independientes y discutiremos las observaciones.
- Importación de bibliotecas:
from multiprocessing import Process
import os
Usaremos el multiprocessing Módulo para crear procesos independientes.
- Función para calcular los cuadrados:
Esa función seguirá siendo la misma. Acabamos de eliminar la declaración impresa de información sobre subprocesos.
def calculate_squares(numbers):
for num in numbers:
square = num * num
print(
f"Square of the number {num} is {square} | PID of the process {os.getpid()}"
)
- Función Principal:
Hay algunas modificaciones en la función principal. Acabamos de crear un proceso separado en lugar de un hilo.
if __name__ == "__main__":
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
p1 = Process(target=calculate_squares, args=(first_half,))
p2 = Process(target=calculate_squares, args=(second_half,))
p1.start()
p2.start()
p1.join()
p2.join()
Salida:
Square of the number 1 is 1 | PID of the process 1125
Square of the number 2 is 4 | PID of the process 1125
Square of the number 3 is 9 | PID of the process 1125
Square of the number 4 is 16 | PID of the process 1125
Square of the number 5 is 25 | PID of the process 1126
Square of the number 6 is 36 | PID of the process 1126
Square of the number 7 is 49 | PID of the process 1126
Square of the number 8 is 64 | PID of the process 1126
Hemos observado que un proceso separado ejecuta cada lista. Ambos tienen diferentes ID de proceso. Para comprobar si nuestros procesos se han ejecutado en paralelo, necesitamos crear un entorno separado, que analizaremos a continuación.
Calcular el tiempo de ejecución con y sin multiprocesamiento
Para comprobar si obtenemos un verdadero paralelismo, calcularemos el tiempo de ejecución del algoritmo con y sin multiprocesamiento.
Para ello, necesitaremos una lista extensa de números enteros que contengan más de 10^6 enteros. Podemos generar una lista usando random biblioteca. Usaremos el time Módulo de Python para calcular el tiempo de ejecución. A continuación se muestra la implementación para esto. El código se explica por sí mismo, aunque siempre puedes mirar los comentarios del código.
from multiprocessing import Process
import os
import time
import random
def calculate_squares(numbers):
for num in numbers:
square = num * num
if __name__ == "__main__":
numbers = [
random.randrange(1, 50, 1) for i in range(10000000)
] # Creating a random list of integers having size 10^7.
half = len(numbers) // 2
first_half = numbers[:half]
second_half = numbers[half:]
# ----------------- Creating Single Process Environment ------------------------#
start_time = time.time() # Start time without multiprocessing
p1 = Process(
target=calculate_squares, args=(numbers,)
) # Single process P1 is executing all list
p1.start()
p1.join()
end_time = time.time() # End time without multiprocessing
print(f"Execution Time Without Multiprocessing: {(end_time-start_time)*10**3}ms")
# ----------------- Creating Multi Process Environment ------------------------#
start_time = time.time() # Start time with multiprocessing
p2 = Process(target=calculate_squares, args=(first_half,))
p3 = Process(target=calculate_squares, args=(second_half,))
p2.start()
p3.start()
p2.join()
p3.join()
end_time = time.time() # End time with multiprocessing
print(f"Execution Time With Multiprocessing: {(end_time-start_time)*10**3}ms")
Salida:
Execution Time Without Multiprocessing: 619.8039054870605ms
Execution Time With Multiprocessing: 321.70287895202637ms
Se puede observar que el tiempo con multiprocesamiento es casi la mitad que sin multiprocesamiento. Esto muestra que estos dos procesos se ejecutan simultáneamente a la vez y muestran un comportamiento de verdadero paralelismo.
También puedes leer este artículo Secuencial vs Concurrente vs Paralelismo de Medium, que le ayudará a comprender la diferencia básica entre estos procesos secuenciales, concurrentes y paralelos.
Garg ario es un B.Tech. Estudiante de Ingeniería Eléctrica, actualmente en el último año de la carrera. Su interés radica en el campo del Desarrollo Web y el Aprendizaje Automático. Ha perseguido este interés y estoy ansioso por trabajar más en estas direcciones.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/introduction-to-multithreading-and-multiprocessing-in-python?utm_source=rss&utm_medium=rss&utm_campaign=introduction-to-multithreading-and-multiprocessing-in-python

