En su centro, LangChain es un marco innovador diseñado para crear aplicaciones que aprovechan las capacidades de los modelos de lenguaje. Es un conjunto de herramientas diseñado para que los desarrolladores creen aplicaciones que tengan en cuenta el contexto y sean capaces de realizar un razonamiento sofisticado.
Esto significa que las aplicaciones de LangChain pueden comprender el contexto, como instrucciones rápidas o respuestas que fundamentan el contenido, y utilizar modelos de lenguaje para tareas de razonamiento complejas, como decidir cómo responder o qué acciones tomar. LangChain representa un enfoque unificado para desarrollar aplicaciones inteligentes, simplificando el viaje desde el concepto hasta la ejecución con sus diversos componentes.
Entendiendo LangChain
LangChain es mucho más que un simple marco; es un ecosistema completo que comprende varias partes integrales.
- En primer lugar, están las bibliotecas LangChain, disponibles tanto en Python como en JavaScript. Estas bibliotecas son la columna vertebral de LangChain y ofrecen interfaces e integraciones para varios componentes. Proporcionan un tiempo de ejecución básico para combinar estos componentes en cadenas y agentes cohesivos, junto con implementaciones listas para usar para uso inmediato.
- A continuación, tenemos las plantillas LangChain. Se trata de una colección de arquitecturas de referencia implementables diseñadas para una amplia gama de tareas. Ya sea que esté creando un chatbot o una herramienta analítica compleja, estas plantillas ofrecen un sólido punto de partida.
- LangServe interviene como una biblioteca versátil para implementar cadenas LangChain como API REST. Esta herramienta es esencial para convertir sus proyectos LangChain en servicios web accesibles y escalables.
- Por último, LangSmith sirve como plataforma de desarrollo. Está diseñado para depurar, probar, evaluar y monitorear cadenas creadas en cualquier marco LLM. La perfecta integración con LangChain la convierte en una herramienta indispensable para los desarrolladores que buscan refinar y perfeccionar sus aplicaciones.
Juntos, estos componentes le permiten desarrollar, producir e implementar aplicaciones con facilidad. Con LangChain, comienza escribiendo sus aplicaciones utilizando las bibliotecas y haciendo referencia a las plantillas como guía. Luego, LangSmith lo ayuda a inspeccionar, probar y monitorear sus cadenas, asegurando que sus aplicaciones mejoren constantemente y estén listas para su implementación. Finalmente, con LangServe, puedes transformar fácilmente cualquier cadena en una API, haciendo que la implementación sea muy sencilla.
En las siguientes secciones, profundizaremos en cómo configurar LangChain y comenzaremos su viaje hacia la creación de aplicaciones inteligentes basadas en modelos de lenguaje.
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
Instalación y configuración
¿Estás listo para sumergirte en el mundo de LangChain? Configurarlo es sencillo y esta guía lo guiará a través del proceso paso a paso.
El primer paso en su viaje a LangChain es instalarlo. Puedes hacer esto fácilmente usando pip o conda. Ejecute el siguiente comando en su terminal:
pip install langchain
Para aquellos que prefieren las últimas funciones y se sienten cómodos con un poco más de aventura, pueden instalar LangChain directamente desde la fuente. Clona el repositorio y navega hasta el langchain/libs/langchain directorio. Entonces corre:
pip install -e .
Para funciones experimentales, considere instalar langchain-experimental. Es un paquete que contiene código de vanguardia y está destinado a fines experimentales y de investigación. Instálalo usando:
pip install langchain-experimental
LangChain CLI es una herramienta útil para trabajar con plantillas de LangChain y proyectos de LangServe. Para instalar la CLI de LangChain, utilice:
pip install langchain-cli
LangServe es esencial para implementar sus cadenas LangChain como API REST. Se instala junto con la CLI de LangChain.
LangChain a menudo requiere integraciones con proveedores de modelos, almacenes de datos, API, etc. Para este ejemplo, usaremos las API modelo de OpenAI. Instale el paquete OpenAI Python usando:
pip install openai
Para acceder a la API, configure su clave API de OpenAI como una variable de entorno:
export OPENAI_API_KEY="your_api_key"
Alternativamente, pase la clave directamente en su entorno Python:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain permite la creación de aplicaciones de modelos de lenguaje a través de módulos. Estos módulos pueden ser independientes o estar compuestos para casos de uso complejos. Estos módulos son –
- Modelo de E / S: Facilita la interacción con varios modelos de lenguaje, manejando sus entradas y salidas de manera eficiente.
- Recuperación: permite el acceso y la interacción con datos específicos de la aplicación, crucial para la utilización dinámica de datos.
- Agentes: Permita que las aplicaciones seleccionen herramientas apropiadas basadas en directivas de alto nivel, mejorando las capacidades de toma de decisiones.
- Cadenas: Ofrece composiciones predefinidas y reutilizables que sirven como componentes básicos para el desarrollo de aplicaciones.
- Salud Cerebral: Mantiene el estado de la aplicación a lo largo de múltiples ejecuciones en cadena, lo que es esencial para las interacciones sensibles al contexto.
Cada módulo se dirige a necesidades de desarrollo específicas, lo que convierte a LangChain en un conjunto de herramientas integral para crear aplicaciones de modelos de lenguaje avanzados.
Junto con los componentes anteriores, también tenemos Lenguaje de expresión LangChain (LCEL), que es una forma declarativa de componer módulos juntos fácilmente, y esto permite el encadenamiento de componentes utilizando una interfaz Runnable universal.
LCEL se parece a esto:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Ahora que hemos cubierto los conceptos básicos, continuaremos con:
- Profundice en cada módulo de Langchain en detalle.
- Aprenda a utilizar el lenguaje de expresión LangChain.
- Explore casos de uso comunes e impleméntelos.
- Implemente una aplicación de un extremo a otro con LangServe.
- Consulte LangSmith para depurar, probar y monitorear.
¡Vamos a empezar!
Módulo I: Modelo de E/S
En LangChain, el elemento central de cualquier aplicación gira en torno al modelo de lenguaje. Este módulo proporciona los componentes básicos esenciales para interactuar de forma eficaz con cualquier modelo de lenguaje, garantizando una integración y comunicación perfectas.
Componentes clave del modelo de E/S
- LLM y modelos de chat (usados indistintamente):
- LLM:
- Definición: Modelos de finalización de texto puro.
- Entrada / Salida: toma una cadena de texto como entrada y devuelve una cadena de texto como salida.
- Modelos de chat
- LLM:
- Definición: Modelos que utilizan un modelo de lenguaje como base pero difieren en los formatos de entrada y salida.
- Entrada / Salida: acepte una lista de mensajes de chat como entrada y devuelva un mensaje de chat.
- Mensajes del sistema: cree plantillas, seleccione dinámicamente y administre entradas del modelo. Permite la creación de indicaciones flexibles y específicas del contexto que guían las respuestas del modelo de lenguaje.
- Analizadores de salida: Extrae y formatea información de los resultados del modelo. Útil para convertir la salida sin procesar de modelos de lenguaje en datos estructurados o formatos específicos necesarios para la aplicación.
LLM
La integración de LangChain con modelos de lenguajes grandes (LLM) como OpenAI, Cohere y Hugging Face es un aspecto fundamental de su funcionalidad. LangChain en sí no alberga LLM, pero ofrece una interfaz uniforme para interactuar con varios LLM.
Esta sección proporciona una descripción general del uso del contenedor OpenAI LLM en LangChain, aplicable también a otros tipos de LLM. Ya lo hemos instalado en la sección "Comenzando". Inicialicemos el LLM.
from langchain.llms import OpenAI
llm = OpenAI()
- Los LLM implementan el Interfaz ejecutable, el componente básico de la Lenguaje de expresión LangChain (LCEL). Esto significa que apoyan
invoke,ainvoke,stream,astream,batch,abatch,astream_logllamadas. - Los LLM aceptan instrumentos de cuerda como entradas u objetos que pueden ser obligados a encadenar mensajes, incluidos
List[BaseMessage]yPromptValue. (más sobre esto más adelante)
Veamos algunos ejemplos.
response = llm.invoke("List the seven wonders of the world.")
print(response)

Alternativamente, puede llamar al método de transmisión para transmitir la respuesta de texto.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

Modelos de chat
La integración de LangChain con modelos de chat, una variación especializada de modelos de lenguaje, es esencial para crear aplicaciones de chat interactivas. Si bien utilizan modelos de lenguaje internamente, los modelos de chat presentan una interfaz distinta centrada en los mensajes de chat como entradas y salidas. Esta sección proporciona una descripción detallada del uso del modelo de chat de OpenAI en LangChain.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
Los modelos de chat en LangChain funcionan con diferentes tipos de mensajes, como AIMessage, HumanMessage, SystemMessage, FunctionMessagey ChatMessage (con un parámetro de rol arbitrario). Generalmente, HumanMessage, AIMessagey SystemMessage son los más utilizados.
Los modelos de chat aceptan principalmente List[BaseMessage] como entradas. Las cadenas se pueden convertir a HumanMessagey PromptValue también es compatible.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)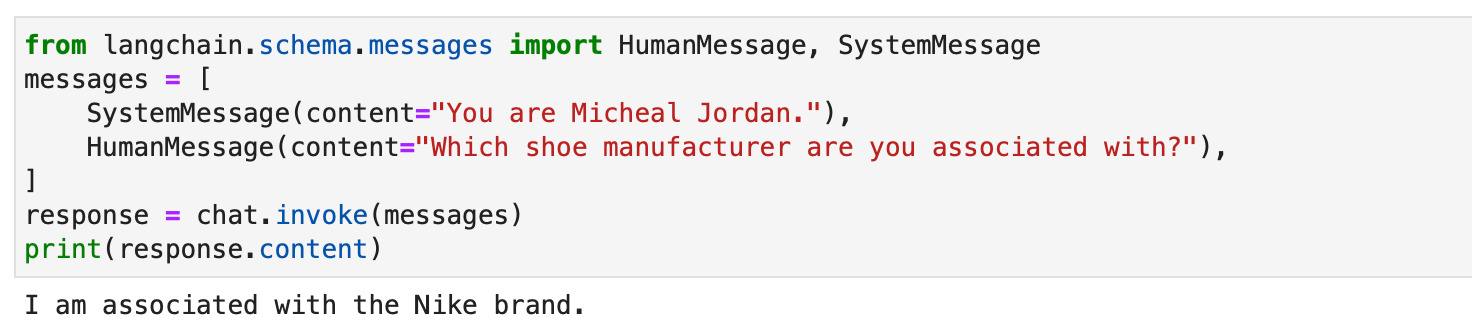
Mensajes del sistema
Las indicaciones son esenciales para guiar los modelos lingüísticos a fin de generar resultados relevantes y coherentes. Pueden variar desde instrucciones simples hasta ejemplos complejos de pocas tomas. En LangChain, manejar avisos puede ser un proceso muy simplificado, gracias a varias clases y funciones dedicadas.
LangChain de PromptTemplate class es una herramienta versátil para crear mensajes de cadena. Utiliza Python str.format sintaxis, lo que permite la generación dinámica de mensajes. Puede definir una plantilla con marcadores de posición y completarlos con valores específicos según sea necesario.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)Para los modelos de chat, las indicaciones están más estructuradas e incluyen mensajes con roles específicos. LangChain ofrece ChatPromptTemplate para este propósito.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
Este enfoque permite la creación de chatbots interactivos y atractivos con respuestas dinámicas.
Ambos PromptTemplate y ChatPromptTemplate integrarse perfectamente con LangChain Expression Language (LCEL), lo que les permite formar parte de flujos de trabajo más grandes y complejos. Hablaremos más sobre esto más adelante.
Las plantillas de mensajes personalizados a veces son esenciales para tareas que requieren un formato único o instrucciones específicas. La creación de una plantilla de solicitud personalizada implica definir variables de entrada y un método de formato personalizado. Esta flexibilidad permite a LangChain atender una amplia gama de requisitos específicos de aplicaciones. Lea más aquí.
LangChain también admite indicaciones breves, lo que permite que el modelo aprenda de ejemplos. Esta característica es vital para tareas que requieren comprensión contextual o patrones específicos. Se pueden crear plantillas de mensajes breves a partir de un conjunto de ejemplos o utilizando un objeto Selector de ejemplo. Lea más aquí.
Analizadores de salida
Los analizadores de resultados desempeñan un papel crucial en Langchain, ya que permiten a los usuarios estructurar las respuestas generadas por los modelos de lenguaje. En esta sección, exploraremos el concepto de analizadores de salida y proporcionaremos ejemplos de código utilizando PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser y XMLOutputParser de Langchain.
PydanticOutputParser
Langchain proporciona PydanticOutputParser para analizar respuestas en estructuras de datos de Pydantic. A continuación se muestra un ejemplo paso a paso de cómo utilizarlo:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
La salida será:

SimpleJsonOutputParser
SimpleJsonOutputParser de Langchain se utiliza cuando desea analizar salidas tipo JSON. He aquí un ejemplo:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)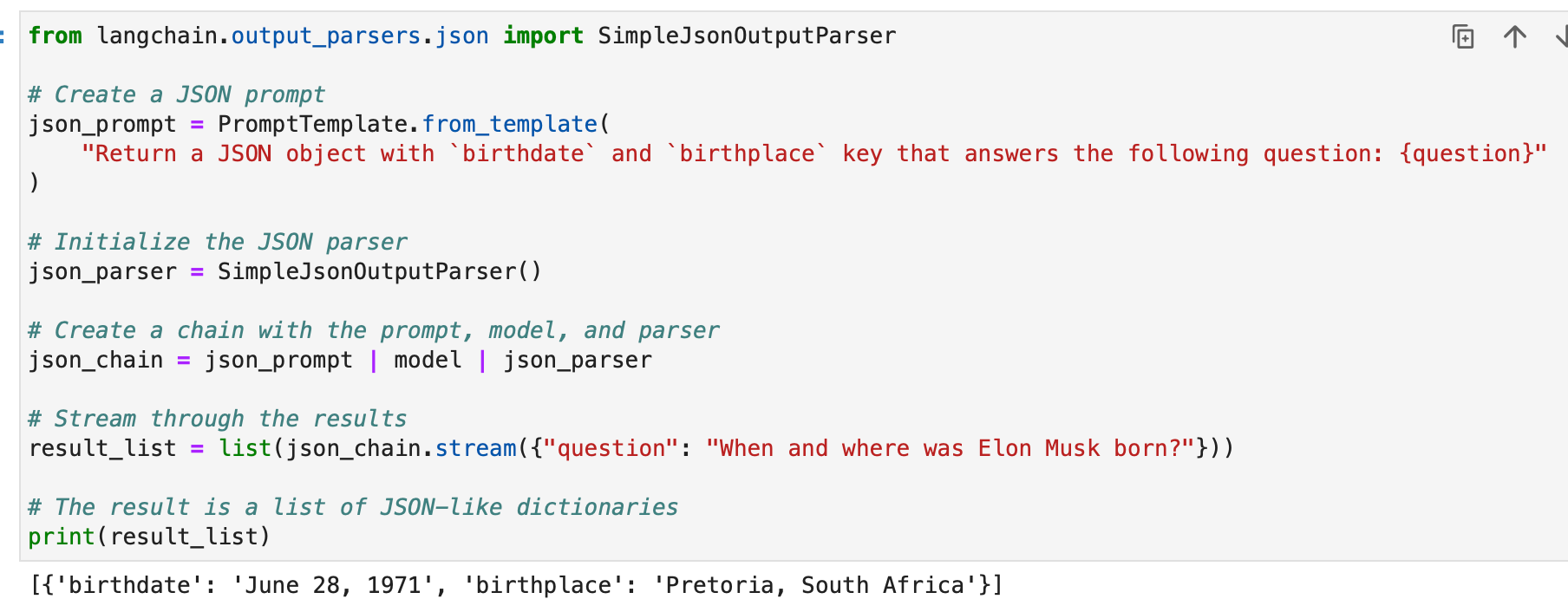
CommaSeparatedListOutputParser
CommaSeparatedListOutputParser es útil cuando desea extraer listas separadas por comas de las respuestas del modelo. He aquí un ejemplo:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)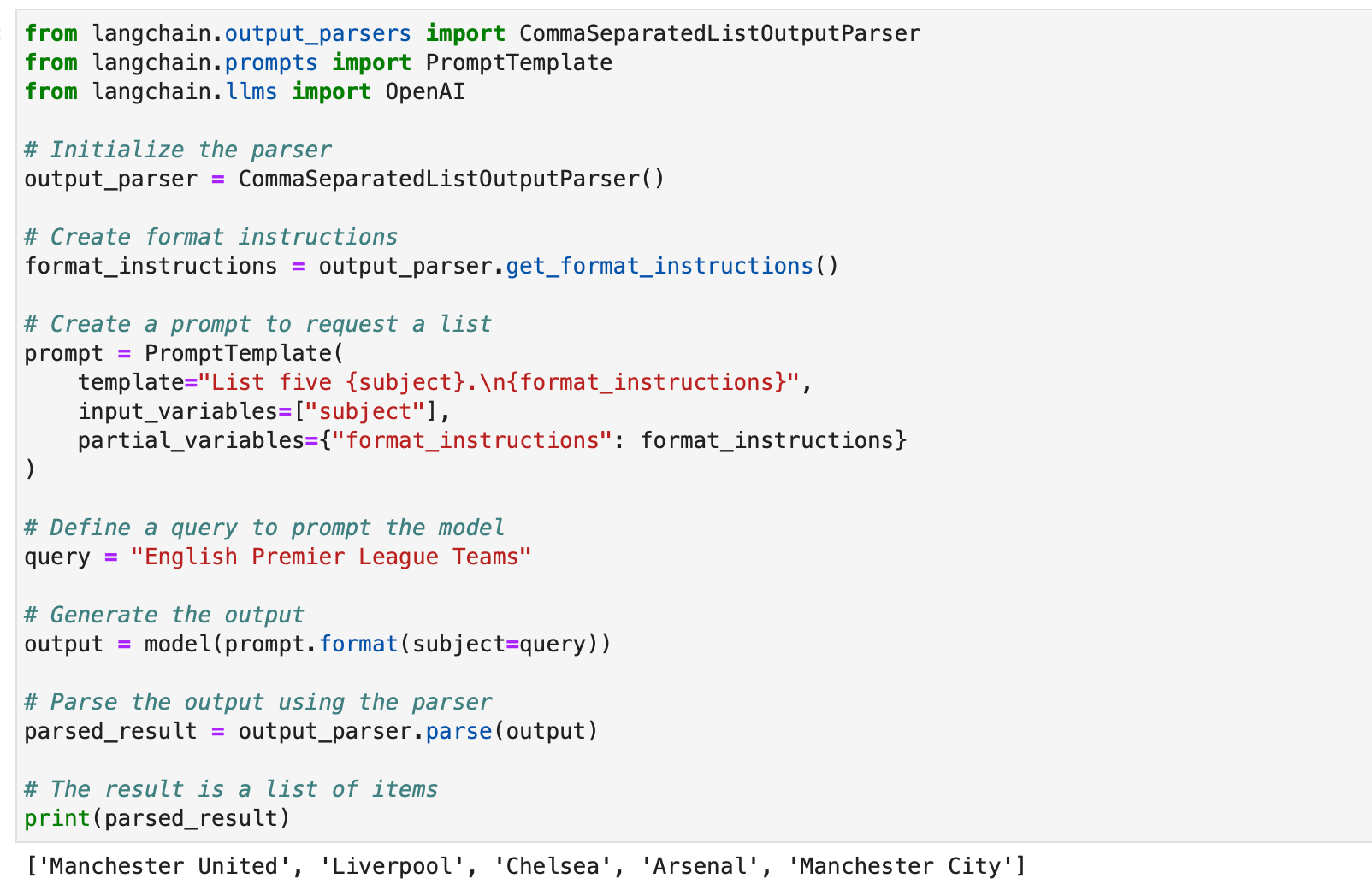
Analizador de salida de fecha y hora
DatetimeOutputParser de Langchain está diseñado para analizar información de fecha y hora. Aquí se explica cómo usarlo:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
Estos ejemplos muestran cómo se pueden utilizar los analizadores de salida de Langchain para estructurar varios tipos de respuestas de modelos, haciéndolos adecuados para diferentes aplicaciones y formatos. Los analizadores de resultados son una herramienta valiosa para mejorar la usabilidad y la interpretabilidad de los resultados del modelo de lenguaje en Langchain.
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
Módulo II: Recuperación
La recuperación en LangChain juega un papel crucial en aplicaciones que requieren datos específicos del usuario, no incluidos en el conjunto de entrenamiento del modelo. Este proceso, conocido como generación aumentada de recuperación (RAG), implica recuperar datos externos e integrarlos en el proceso de generación del modelo de lenguaje. LangChain proporciona un conjunto completo de herramientas y funcionalidades para facilitar este proceso, atendiendo tanto a aplicaciones simples como complejas.
LangChain logra la recuperación a través de una serie de componentes que discutiremos uno por uno.
Cargadores de documentos
Los cargadores de documentos en LangChain permiten la extracción de datos de diversas fuentes. Con más de 100 cargadores disponibles, admiten una variedad de tipos de documentos, aplicaciones y fuentes (depósitos S3 privados, sitios web públicos, bases de datos).
Puede elegir un cargador de documentos según sus requisitos esta página.
Todos estos cargadores ingieren datos en Documento clases. Más adelante aprenderemos a utilizar los datos ingeridos en las clases de Documentos.
Cargador de archivos de texto: Cargar un sencillo .txt archivar en un documento.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
Cargador CSV: Cargue un archivo CSV en un documento.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
Podemos optar por personalizar el análisis especificando nombres de campos:
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
Cargadores de PDF: Los cargadores de PDF en LangChain ofrecen varios métodos para analizar y extraer contenido de archivos PDF. Cada cargador satisface diferentes requisitos y utiliza diferentes bibliotecas subyacentes. A continuación se muestran ejemplos detallados para cada cargador.
PyPDFLoader se utiliza para el análisis básico de PDF.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader es ideal para extraer diagramas y contenido matemático.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader es rápido e incluye extracción detallada de metadatos.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader se utiliza para un control más granular sobre la extracción de texto.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser utiliza AWS Textract para OCR y otras funciones avanzadas de análisis de PDF.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader genera HTML a partir de PDF para análisis semántico.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader proporciona metadatos detallados y admite un documento por página.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
Cargadores integrados: LangChain ofrece una amplia variedad de cargadores personalizados para cargar datos directamente desde sus aplicaciones (como Slack, Sigma, Notion, Confluence, Google Drive y muchas más) y bases de datos y utilizarlos en aplicaciones LLM.
La lista completa es esta página.
A continuación se muestran un par de ejemplos para ilustrar esto:
Ejemplo I: holgura
Slack, una plataforma de mensajería instantánea ampliamente utilizada, se puede integrar en aplicaciones y flujos de trabajo de LLM.
- Vaya a la página de Gestión del espacio de trabajo de Slack.
- Navegue hasta
{your_slack_domain}.slack.com/services/export. - Seleccione el rango de fechas deseado e inicie la exportación.
- Slack notifica por correo electrónico y DM una vez que la exportación está lista.
- La exportación resulta en un
.ziparchivo ubicado en su carpeta de Descargas o en la ruta de descarga designada. - Asigna la ruta del archivo descargado.
.zippresentar a laLOCAL_ZIPFILE. - Ingrese al
SlackDirectoryLoaderdel desplegablelangchain.document_loaderspaquete.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Ejemplo II – Figma
Figma, una herramienta popular para el diseño de interfaces, ofrece una API REST para la integración de datos.
- Obtenga la clave del archivo Figma del formato URL:
https://www.figma.com/file/{filekey}/sampleFilename. - Los ID de nodo se encuentran en el parámetro URL
?node-id={node_id}. - Genere un token de acceso siguiendo las instrucciones en el Centro de ayuda de Figma.
- El
FigmaFileLoaderclase delangchain.document_loaders.figmase utiliza para cargar datos de Figma. - Varios módulos LangChain como
CharacterTextSplitter,ChatOpenAI, etc., se emplean para el procesamiento.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- El
generate_codeLa función utiliza los datos de Figma para crear código HTML/CSS. - Emplea una conversación basada en plantilla con un modelo basado en GPT.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- El
generate_codeLa función, cuando se ejecuta, devuelve código HTML/CSS basado en la entrada de diseño de Figma.
Usemos ahora nuestro conocimiento para crear algunos conjuntos de documentos.
Primero cargamos un PDF, el informe anual de sostenibilidad de BCG.

Usamos PyPDFLoader para esto.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
ingeriremos datos de Airtable ahora. Tenemos un Airtable que contiene información sobre varios modelos de extracción de datos y OCR:
Usemos para esto el AirtableLoader, que se encuentra en la lista de cargadores integrados.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Procedamos ahora y aprendamos a utilizar estas clases de documentos.
Transformadores de documentos
Los transformadores de documentos en LangChain son herramientas esenciales diseñadas para manipular documentos, que creamos en nuestra subsección anterior.
Se utilizan para tareas como dividir documentos largos en fragmentos más pequeños, combinarlos y filtrarlos, que son cruciales para adaptar documentos a la ventana contextual de un modelo o satisfacer necesidades de aplicaciones específicas.
Una de esas herramientas es RecursiveCharacterTextSplitter, un divisor de texto versátil que utiliza una lista de caracteres para dividir. Permite parámetros como tamaño de fragmento, superposición e índice inicial. Aquí hay un ejemplo de cómo se usa en Python:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
Otra herramienta es CharacterTextSplitter, que divide el texto según un carácter específico e incluye controles para el tamaño de los fragmentos y la superposición:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
HTMLHeaderTextSplitter está diseñado para dividir el contenido HTML en función de las etiquetas de encabezado, conservando la estructura semántica:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
Se puede lograr una manipulación más compleja combinando HTMLHeaderTextSplitter con otro divisor, como Pipelined Splitter:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain también ofrece divisores específicos para diferentes lenguajes de programación, como Python Code Splitter y JavaScript Code Splitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
Para dividir texto según el recuento de tokens, lo cual es útil para modelos de lenguaje con límites de tokens, se utiliza TokenTextSplitter:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Finalmente, LongContextReorder reordena los documentos para evitar la degradación del rendimiento en los modelos debido a contextos largos:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
Estas herramientas demuestran varias formas de transformar documentos en LangChain, desde una simple división de texto hasta una reordenación compleja y una división específica del idioma. Para casos de uso más detallados y específicos, se debe consultar la sección Integraciones y documentación de LangChain.
En nuestros ejemplos, los cargadores ya han creado documentos fragmentados para nosotros y esta parte ya está manejada.
Modelos de incrustación de texto
Los modelos de incrustación de texto en LangChain proporcionan una interfaz estandarizada para varios proveedores de modelos de incrustación como OpenAI, Cohere y Hugging Face. Estos modelos transforman el texto en representaciones vectoriales, permitiendo operaciones como la búsqueda semántica a través de similitud de texto en el espacio vectorial.
Para comenzar con los modelos de incrustación de texto, normalmente necesita instalar paquetes específicos y configurar claves API. Ya hemos hecho esto para OpenAI
En LangChain, el embed_documents El método se utiliza para incrustar múltiples textos, proporcionando una lista de representaciones vectoriales. Por ejemplo:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
Para incrustar un solo texto, como una consulta de búsqueda, el embed_query Se utiliza el método. Esto es útil para comparar una consulta con un conjunto de incrustaciones de documentos. Por ejemplo:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
Comprender estas incorporaciones es crucial. Cada fragmento de texto se convierte en un vector, cuya dimensión depende del modelo utilizado. Por ejemplo, los modelos OpenAI suelen producir vectores de 1536 dimensiones. Estas incrustaciones se utilizan luego para recuperar información relevante.
La funcionalidad de integración de LangChain no se limita a OpenAI, sino que está diseñada para funcionar con varios proveedores. La configuración y el uso pueden diferir ligeramente según el proveedor, pero el concepto central de incrustar textos en el espacio vectorial sigue siendo el mismo. Para un uso detallado, incluidas configuraciones e integraciones avanzadas con diferentes proveedores de modelos de integración, la documentación de LangChain en la sección Integraciones es un recurso valioso.
Tiendas de vectores
Las tiendas de vectores en LangChain admiten el almacenamiento y la búsqueda eficientes de incrustaciones de texto. LangChain se integra con más de 50 tiendas de vectores, proporcionando una interfaz estandarizada para facilitar su uso.
Ejemplo: almacenamiento y búsqueda de incrustaciones
Después de incrustar textos, podemos almacenarlos en una tienda de vectores como Chroma y realizar búsquedas de similitud:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
Alternativamente, usemos el almacén de vectores FAISS para crear índices para nuestros documentos.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

Perros perdigueros
Los recuperadores en LangChain son interfaces que devuelven documentos en respuesta a una consulta no estructurada. Son más generales que los almacenes de vectores y se centran en la recuperación más que en el almacenamiento. Aunque los almacenes de vectores se pueden utilizar como columna vertebral de un perro perdiguero, también existen otros tipos de perros perdigueros.
Para configurar un Chroma Retriever, primero instálelo usando pip install chromadb. Luego, carga, divide, incrusta y recupera documentos utilizando una serie de comandos de Python. Aquí hay un ejemplo de código para configurar un Chroma retriever:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
MultiQueryRetriever automatiza el ajuste rápido generando múltiples consultas para una consulta ingresada por el usuario y combina los resultados. Aquí hay un ejemplo de su uso simple:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
La compresión contextual en LangChain comprime los documentos recuperados utilizando el contexto de la consulta, asegurando que solo se devuelva información relevante. Esto implica la reducción de contenido y el filtrado de documentos menos relevantes. El siguiente ejemplo de código muestra cómo utilizar el recuperador de compresión contextual:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
El EnsembleRetriever combina diferentes algoritmos de recuperación para lograr un mejor rendimiento. En el siguiente código se muestra un ejemplo de combinación de BM25 y FAISS Retrievers:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
MultiVector Retriever en LangChain permite consultar documentos con múltiples vectores por documento, lo cual es útil para capturar diferentes aspectos semánticos dentro de un documento. Los métodos para crear múltiples vectores incluyen dividirlos en partes más pequeñas, resumir o generar preguntas hipotéticas. Para dividir documentos en partes más pequeñas, se puede utilizar el siguiente código Python:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Otro método es generar resúmenes para una mejor recuperación debido a una representación del contenido más enfocada. A continuación se muestra un ejemplo de generación de resúmenes:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Generar preguntas hipotéticas relevantes para cada documento utilizando LLM es otro enfoque. Esto se puede hacer con el siguiente código:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
El Parent Document Retriever es otro recuperador que logra un equilibrio entre la precisión de la incrustación y la retención del contexto al almacenar pequeños fragmentos y recuperar sus documentos principales más grandes. Su implementación es la siguiente:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
Un recuperador de consultas automáticas construye consultas estructuradas a partir de entradas de lenguaje natural y las aplica a su VectorStore subyacente. Su implementación se muestra en el siguiente código:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
WebResearchRetriever realiza una investigación web basada en una consulta determinada:
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
Para nuestros ejemplos, también podemos usar el recuperador estándar ya implementado como parte de nuestro objeto de tienda de vectores de la siguiente manera:

Ahora podemos consultar a los perros perdigueros. El resultado de nuestra consulta serán objetos de documento relevantes para la consulta. En última instancia, se utilizarán para crear respuestas relevantes en secciones posteriores.


Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
Módulo III: Agentes
LangChain presenta un poderoso concepto llamado "Agentes" que lleva la idea de cadenas a un nivel completamente nuevo. Los agentes aprovechan los modelos de lenguaje para determinar dinámicamente secuencias de acciones a realizar, lo que los hace increíblemente versátiles y adaptables. A diferencia de las cadenas tradicionales, donde las acciones están codificadas en código, los agentes emplean modelos de lenguaje como motores de razonamiento para decidir qué acciones tomar y en qué orden.
El agente es el componente central responsable de la toma de decisiones. Aprovecha el poder de un modelo de lenguaje y un mensaje para determinar los siguientes pasos para lograr un objetivo específico. Las entradas a un agente normalmente incluyen:
- Herramientas: Descripciones de herramientas disponibles (más sobre esto más adelante).
- Entrada del usuario: El objetivo de alto nivel o consulta del usuario.
- Pasos intermedios: Un historial de pares (acción, salida de herramienta) ejecutados para alcanzar la entrada actual del usuario.
La salida de un agente puede ser la siguiente. DE ACTUAR! tomar acciones (AgenteAcciones) o la final respuesta para enviar al usuario (AgenteFinalizar) Un DE ACTUAR! especifica un del IRS y del Las opciones de entrada para esa herramienta.
Herramientas
Las herramientas son interfaces que un agente puede utilizar para interactuar con el mundo. Permiten a los agentes realizar diversas tareas, como buscar en la web, ejecutar comandos de shell o acceder a API externas. En LangChain, las herramientas son esenciales para ampliar las capacidades de los agentes y permitirles realizar diversas tareas.
Para usar herramientas en LangChain, puede cargarlas usando el siguiente fragmento:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
Algunas herramientas pueden requerir un modelo de lenguaje base (LLM) para inicializarse. En tales casos, también puedes aprobar un LLM:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
Esta configuración le permite acceder a una variedad de herramientas e integrarlas en los flujos de trabajo de su agente. La lista completa de herramientas con documentación de uso es esta página.
Veamos algunos ejemplos de herramientas.
Pato Pato a ganar
La herramienta DuckDuckGo le permite realizar búsquedas web utilizando su motor de búsqueda. Aquí se explica cómo usarlo:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

DatosParaSeo
El kit de herramientas DataForSeo le permite obtener resultados de motores de búsqueda utilizando la API DataForSeo. Para utilizar este kit de herramientas, deberá configurar sus credenciales de API. A continuación se explica cómo configurar las credenciales:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
Una vez configuradas sus credenciales, puede crear una DataForSeoAPIWrapper herramienta para acceder a la API:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
El DataForSeoAPIWrapper La herramienta recupera resultados del motor de búsqueda de varias fuentes.
Puede personalizar el tipo de resultados y campos devueltos en la respuesta JSON. Por ejemplo, puede especificar los tipos de resultados, los campos y establecer un recuento máximo para la cantidad de resultados principales que se devolverán:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
Este ejemplo personaliza la respuesta JSON especificando tipos de resultados, campos y limitando la cantidad de resultados.
También puede especificar la ubicación y el idioma de los resultados de su búsqueda pasando parámetros adicionales al contenedor API:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
Al proporcionar parámetros de ubicación e idioma, puede adaptar los resultados de su búsqueda a regiones e idiomas específicos.
Tiene la flexibilidad de elegir el motor de búsqueda que desea utilizar. Simplemente especifique el motor de búsqueda deseado:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
En este ejemplo, la búsqueda está personalizada para utilizar Bing como motor de búsqueda.
El contenedor API también le permite especificar el tipo de búsqueda que desea realizar. Por ejemplo, puedes realizar una búsqueda de mapas:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
Esto personaliza la búsqueda para recuperar información relacionada con mapas.
Shell (golpe)
El kit de herramientas de Shell proporciona a los agentes acceso al entorno de Shell, permitiéndoles ejecutar comandos de Shell. Esta característica es poderosa pero debe usarse con precaución, especialmente en entornos aislados. Así es como puede utilizar la herramienta Shell:
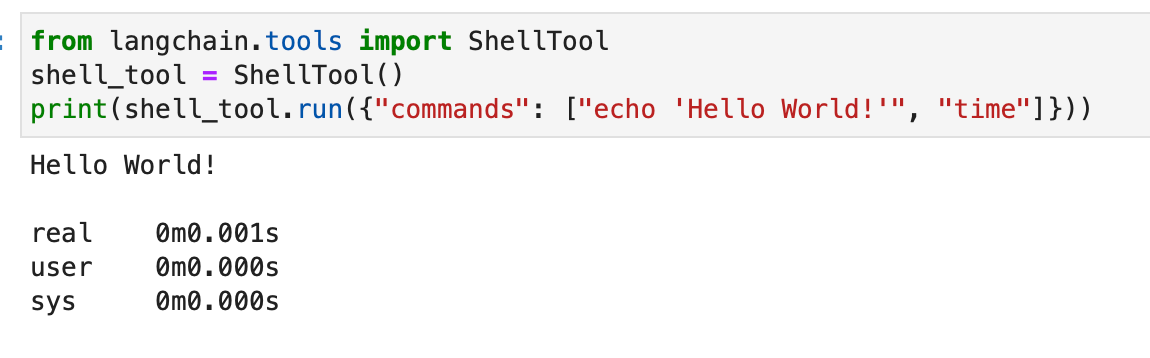
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
En este ejemplo, la herramienta Shell ejecuta dos comandos de Shell: haciendo eco de "¡Hola mundo!" y mostrando la hora actual.
Puede proporcionar la herramienta Shell a un agente para que realice tareas más complejas. A continuación se muestra un ejemplo de un agente que obtiene enlaces de una página web utilizando la herramienta Shell:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
En este escenario, el agente utiliza la herramienta Shell para ejecutar una secuencia de comandos para buscar, filtrar y ordenar URL de una página web.
Los ejemplos proporcionados demuestran algunas de las herramientas disponibles en LangChain. En última instancia, estas herramientas amplían las capacidades de los agentes (que se exploran en la siguiente subsección) y les permiten realizar diversas tareas de manera eficiente. Dependiendo de sus requisitos, puede elegir las herramientas y kits de herramientas que mejor se adapten a las necesidades de su proyecto e integrarlos en los flujos de trabajo de su agente.
Volver a Agentes
Pasemos ahora a los agentes.
AgentExecutor es el entorno de ejecución de un agente. Es responsable de llamar al agente, ejecutar las acciones que selecciona, pasar los resultados de la acción al agente y repetir el proceso hasta que el agente finalice. En pseudocódigo, AgentExecutor podría verse así:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
AgentExecutor maneja diversas complejidades, como lidiar con casos en los que el agente selecciona una herramienta inexistente, manejar errores de herramientas, administrar resultados producidos por el agente y proporcionar registro y observabilidad en todos los niveles.
Si bien la clase AgentExecutor es el tiempo de ejecución del agente principal en LangChain, se admiten otros tiempos de ejecución más experimentales, que incluyen:
- Agente de planificación y ejecución
- Bebé AGI
- GPT automático
Para comprender mejor el marco del agente, creemos un agente básico desde cero y luego pasemos a explorar los agentes prediseñados.
Antes de sumergirnos en la creación del agente, es esencial revisar algunos esquemas y terminología clave:
- Acción del agente: Esta es una clase de datos que representa la acción que debe realizar un agente. Consiste en un
toolpropiedad (el nombre de la herramienta a invocar) y untool_inputpropiedad (la entrada para esa herramienta). - AgenteFinalizar: Esta clase de datos indica que el agente ha finalizado su tarea y debe devolver una respuesta al usuario. Por lo general, incluye un diccionario de valores de retorno, a menudo con una "salida" clave que contiene el texto de respuesta.
- Pasos intermedios: Estos son los registros de acciones anteriores de los agentes y sus resultados correspondientes. Son cruciales para pasar contexto a futuras iteraciones del agente.
En nuestro ejemplo, usaremos llamadas a funciones OpenAI para crear nuestro agente. Este enfoque es confiable para la creación de agentes. Comenzaremos creando una herramienta sencilla que calcula la longitud de una palabra. Esta herramienta es útil porque los modelos de lenguaje a veces pueden cometer errores debido a la tokenización al contar la longitud de las palabras.
Primero, carguemos el modelo de lenguaje que usaremos para controlar el agente:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
Probemos el modelo con un cálculo de la longitud de la palabra:
llm.invoke("how many letters in the word educa?")
La respuesta debe indicar el número de letras de la palabra “educa”.
A continuación, definiremos una función Python simple para calcular la longitud de una palabra:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
Hemos creado una herramienta llamada get_word_length que toma una palabra como entrada y devuelve su longitud.
Ahora, creemos el mensaje para el agente. El mensaje indica al agente cómo razonar y formatear la salida. En nuestro caso, utilizamos OpenAI Function Calling, que requiere instrucciones mínimas. Definiremos el mensaje con marcadores de posición para la entrada del usuario y el bloc de notas del agente:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Ahora bien, ¿cómo sabe el agente qué herramientas puede utilizar? Nos basamos en los modelos de lenguaje de llamada de funciones de OpenAI, que requieren que las funciones se pasen por separado. Para proporcionar nuestras herramientas al agente, las formatearemos como llamadas a funciones de OpenAI:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
Ahora podemos crear el agente definiendo asignaciones de entrada y conectando los componentes:
Este es el lenguaje LCEL. Discutiremos esto más adelante en detalle.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Hemos creado nuestro agente, que comprende las entradas del usuario, utiliza las herramientas disponibles y formatea la salida. Ahora, interactuemos con él:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
El agente debe responder con una AgentAction, indicando la siguiente acción a realizar.
Hemos creado el agente, pero ahora necesitamos escribir un tiempo de ejecución para él. El tiempo de ejecución más simple es aquel que llama continuamente al agente, ejecuta acciones y repite hasta que el agente finaliza. He aquí un ejemplo:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
En este bucle, llamamos repetidamente al agente, ejecutamos acciones y actualizamos los pasos intermedios hasta que el agente finaliza. También manejamos interacciones de herramientas dentro del bucle.

Para simplificar este proceso, LangChain proporciona la clase AgentExecutor, que encapsula la ejecución del agente y ofrece manejo de errores, detención anticipada, seguimiento y otras mejoras. Usemos AgentExecutor para interactuar con el agente:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor simplifica el proceso de ejecución y proporciona una forma conveniente de interactuar con el agente.
La memoria también se analiza en detalle más adelante.
El agente que hemos creado hasta ahora no tiene estado, lo que significa que no recuerda interacciones anteriores. Para habilitar preguntas y conversaciones de seguimiento, necesitamos agregar memoria al agente. Esto implica dos pasos:
- Agregue una variable de memoria en el mensaje para almacenar el historial de chat.
- Realice un seguimiento del historial de chat durante las interacciones.
Comencemos agregando un marcador de posición de memoria en el mensaje:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Ahora, crea una lista para rastrear el historial de chat:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
En el paso de creación del agente, también incluiremos la memoria:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Ahora, cuando ejecute el agente, asegúrese de actualizar el historial de chat:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Esto permite al agente mantener un historial de conversaciones y responder preguntas de seguimiento basadas en interacciones anteriores.
¡Felicidades! Ha creado y ejecutado con éxito su primer agente de un extremo a otro en LangChain. Para profundizar en las capacidades de LangChain, puede explorar:
- Se admiten diferentes tipos de agentes.
- Agentes prediseñados
- Cómo trabajar con herramientas e integraciones de herramientas.
Tipos de agentes
LangChain ofrece varios tipos de agentes, cada uno de ellos adecuado para casos de uso específicos. Éstos son algunos de los agentes disponibles:
- Reacción de disparo cero: Este agente utiliza el marco ReAct para elegir herramientas basándose únicamente en sus descripciones. Requiere descripciones para cada herramienta y es muy versátil.
- Entrada estructurada ReAct: Este agente maneja herramientas de entrada múltiple y es adecuado para tareas complejas como navegar en un navegador web. Utiliza un esquema de argumentos de herramientas para entradas estructuradas.
- Funciones de OpenAI: Diseñado específicamente para modelos optimizados para llamadas de funciones, este agente es compatible con modelos como gpt-3.5-turbo-0613 y gpt-4-0613. Usamos esto para crear nuestro primer agente arriba.
- Conversacional: Diseñado para entornos conversacionales, este agente utiliza ReAct para seleccionar herramientas y utiliza la memoria para recordar interacciones anteriores.
- Autopregunta con búsqueda: Este agente se basa en una única herramienta, "Respuesta intermedia", que busca respuestas objetivas a las preguntas. Es equivalente a la autopregunta original con papel de búsqueda.
- Almacén de documentos ReAct: Este agente interactúa con un almacén de documentos utilizando el marco ReAct. Requiere herramientas de “búsqueda” y “búsqueda” y es similar al ejemplo de Wikipedia del artículo original de ReAct.
Explore estos tipos de agentes para encontrar el que mejor se adapte a sus necesidades en LangChain. Estos agentes le permiten vincular un conjunto de herramientas dentro de ellos para manejar acciones y generar respuestas. Más información en cómo construir tu propio agente con herramientas aquí.
Agentes prediseñados
Continuaremos nuestra exploración de agentes, centrándonos en los agentes prediseñados disponibles en LangChain.
gmail
LangChain ofrece un conjunto de herramientas de Gmail que le permite conectar su correo electrónico de LangChain a la API de Gmail. Para comenzar, deberá configurar sus credenciales, que se explican en la documentación de la API de Gmail. Una vez que haya descargado el credentials.json archivo, puede continuar usando la API de Gmail. Además, necesitarás instalar algunas bibliotecas requeridas usando los siguientes comandos:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
Puede crear el kit de herramientas de Gmail de la siguiente manera:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
También puede personalizar la autenticación según sus necesidades. Detrás de escena, se crea un recurso googleapi utilizando los siguientes métodos:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
El kit de herramientas ofrece varias herramientas que se pueden utilizar dentro de un agente, que incluyen:
GmailCreateDraft: cree un borrador de correo electrónico con campos de mensaje específicos.GmailSendMessage: envía mensajes de correo electrónico.GmailSearch: busca mensajes de correo electrónico o hilos.GmailGetMessage: recupera un correo electrónico por ID de mensaje.GmailGetThread: busca mensajes de correo electrónico.
Para utilizar estas herramientas dentro de un agente, puede inicializar el agente de la siguiente manera:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
A continuación se muestran un par de ejemplos de cómo se pueden utilizar estas herramientas:
- Crea un borrador de Gmail para editarlo:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- Busque el último correo electrónico en sus borradores:
agent.run("Could you search in my drafts for the latest email?")
Estos ejemplos demuestran las capacidades del kit de herramientas de Gmail de LangChain dentro de un agente, lo que le permite interactuar con Gmail mediante programación.
Agente de base de datos SQL
Esta sección proporciona una descripción general de un agente diseñado para interactuar con bases de datos SQL, particularmente la base de datos Chinook. Este agente puede responder preguntas generales sobre una base de datos y recuperarse de errores. Tenga en cuenta que todavía está en desarrollo activo y es posible que no todas las respuestas sean correctas. Tenga cuidado al ejecutarlo con datos confidenciales, ya que puede realizar declaraciones DML en su base de datos.
Para utilizar este agente, puede inicializarlo de la siguiente manera:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Este agente se puede inicializar utilizando el ZERO_SHOT_REACT_DESCRIPTION tipo de agente. Está diseñado para responder preguntas y proporcionar descripciones. Alternativamente, puede inicializar el agente usando el OPENAI_FUNCTIONS tipo de agente con el modelo GPT-3.5-turbo de OpenAI, que utilizamos en nuestro cliente anterior.
Observación
- La cadena de consultas puede generar consultas de inserción/actualización/eliminación. Tenga cuidado y utilice un mensaje personalizado o cree un usuario de SQL sin permisos de escritura si es necesario.
- Tenga en cuenta que ejecutar determinadas consultas, como "ejecutar la consulta más grande posible", podría sobrecargar su base de datos SQL, especialmente si contiene millones de filas.
- Las bases de datos orientadas al almacén de datos a menudo admiten cuotas a nivel de usuario para limitar el uso de recursos.
Puede pedirle al agente que describa una tabla, como la tabla "playlisttrack". Aquí tienes un ejemplo de cómo hacerlo:
agent_executor.run("Describe the playlisttrack table")
El agente proporcionará información sobre el esquema de la tabla y las filas de muestra.
Si pregunta por error sobre una tabla que no existe, el agente puede recuperarla y proporcionar información sobre la tabla coincidente más cercana. Por ejemplo:
agent_executor.run("Describe the playlistsong table")
El agente encontrará la mesa coincidente más cercana y le proporcionará información al respecto.
También puede pedirle al agente que ejecute consultas en la base de datos. Por ejemplo:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
El agente ejecutará la consulta y proporcionará el resultado, como el país con mayores ventas totales.
Para obtener el número total de pistas en cada lista de reproducción, puede utilizar la siguiente consulta:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
El agente devolverá los nombres de las listas de reproducción junto con el recuento total de pistas correspondiente.
En los casos en que el agente encuentre errores, puede recuperarlos y brindar respuestas precisas. Por ejemplo:
agent_executor.run("Who are the top 3 best selling artists?")
Incluso después de encontrar un error inicial, el agente se ajustará y proporcionará la respuesta correcta, que, en este caso, son los 3 artistas más vendidos.
Agente Pandas DataFrame
Esta sección presenta un agente diseñado para interactuar con Pandas DataFrames con el fin de responder preguntas. Tenga en cuenta que este agente utiliza el agente Python interno para ejecutar el código Python generado por un modelo de lenguaje (LLM). Tenga cuidado al utilizar este agente para evitar posibles daños causados por el código Python malicioso generado por el LLM.
Puede inicializar el agente Pandas DataFrame de la siguiente manera:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
Puede pedirle al agente que cuente el número de filas en el DataFrame:
agent.run("how many rows are there?")
El agente ejecutará el código. df.shape[0] y proporcione la respuesta, como "Hay 891 filas en el marco de datos".
También puede pedirle al agente que filtre filas según criterios específicos, como encontrar la cantidad de personas con más de 3 hermanos:
agent.run("how many people have more than 3 siblings")
El agente ejecutará el código. df[df['SibSp'] > 3].shape[0] y proporcione la respuesta, como “30 personas tienen más de 3 hermanos”.
Si quieres calcular la raíz cuadrada de la edad promedio, puedes preguntarle al agente:
agent.run("whats the square root of the average age?")
El agente calculará la edad promedio usando df['Age'].mean() y luego calcula la raíz cuadrada usando math.sqrt(). Proporcionará la respuesta, como por ejemplo "La raíz cuadrada de la edad promedio es 5.449689683556195".
Creemos una copia del DataFrame y los valores de edad que faltan se completan con la edad media:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
Luego, puede inicializar el agente con ambos DataFrames y hacerle una pregunta:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
El agente comparará las columnas de edad en ambos DataFrames y proporcionará la respuesta, como "177 filas en la columna de edad son diferentes".
Kit de herramientas de Jira
Esta sección explica cómo utilizar el kit de herramientas de Jira, que permite a los agentes interactuar con una instancia de Jira. Puede realizar varias acciones, como buscar problemas y crear problemas, utilizando este kit de herramientas. Utiliza la biblioteca atlassian-python-api. Para utilizar este kit de herramientas, debe configurar variables de entorno para su instancia de Jira, incluidas JIRA_API_TOKEN, JIRA_USERNAME y JIRA_INSTANCE_URL. Además, es posible que deba configurar su clave API de OpenAI como una variable de entorno.
Para comenzar, instale la biblioteca atlassian-python-api y configure las variables de entorno requeridas:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
Puede indicarle al agente que cree una nueva incidencia en un proyecto específico con un resumen y una descripción:
agent.run("make a new issue in project PW to remind me to make more fried rice")
El agente ejecutará las acciones necesarias para crear el problema y brindar una respuesta, como por ejemplo "Se ha creado un nuevo problema en el proyecto PW con el resumen 'Hacer más arroz frito' y la descripción 'Recordatorio para hacer más arroz frito'".
Esto le permite interactuar con su instancia de Jira utilizando instrucciones en lenguaje natural y el kit de herramientas de Jira.
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
Módulo IV: Cadenas
LangChain es una herramienta diseñada para utilizar modelos de lenguaje grande (LLM) en aplicaciones complejas. Proporciona marcos para crear cadenas de componentes, incluidos LLM y otros tipos de componentes. Dos marcos principales
- El lenguaje de expresión LangChain (LCEL)
- Interfaz de cadena heredada
LangChain Expression Language (LCEL) es una sintaxis que permite la composición intuitiva de cadenas. Admite funciones avanzadas como transmisión, llamadas asincrónicas, procesamiento por lotes, paralelización, reintentos, respaldos y seguimiento. Por ejemplo, puede componer un analizador de mensajes, modelos y resultados en LCEL como se muestra en el siguiente código:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)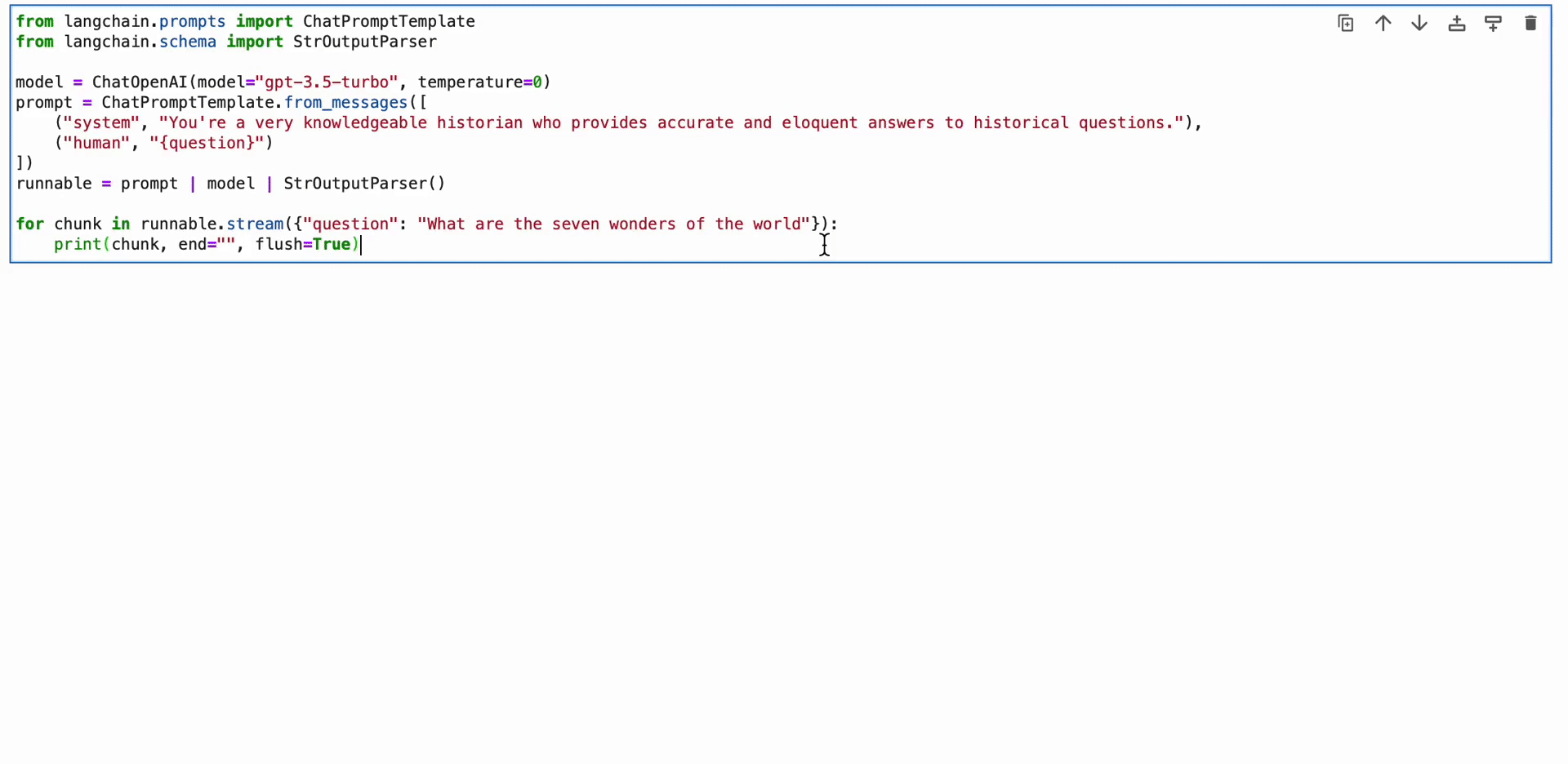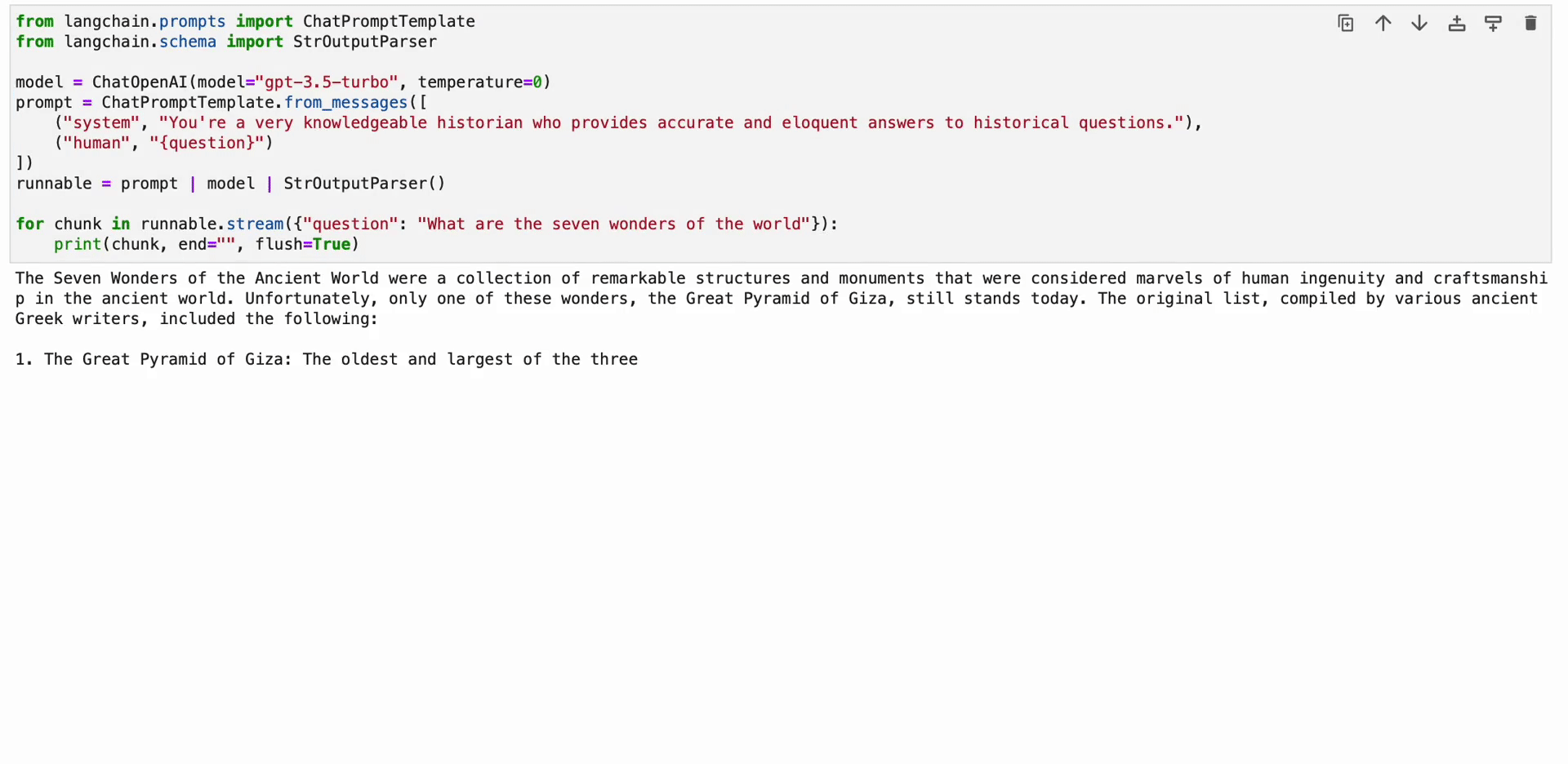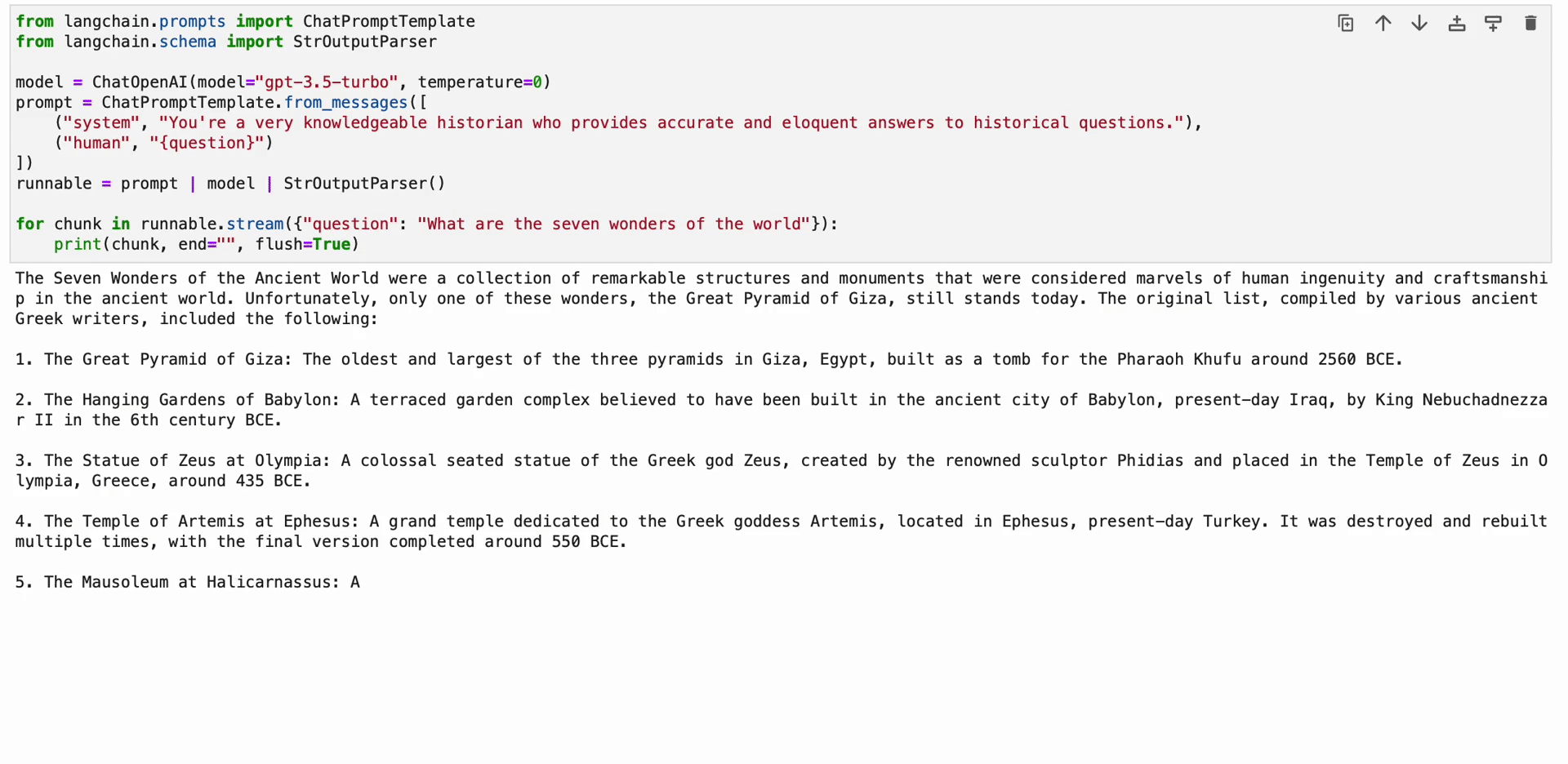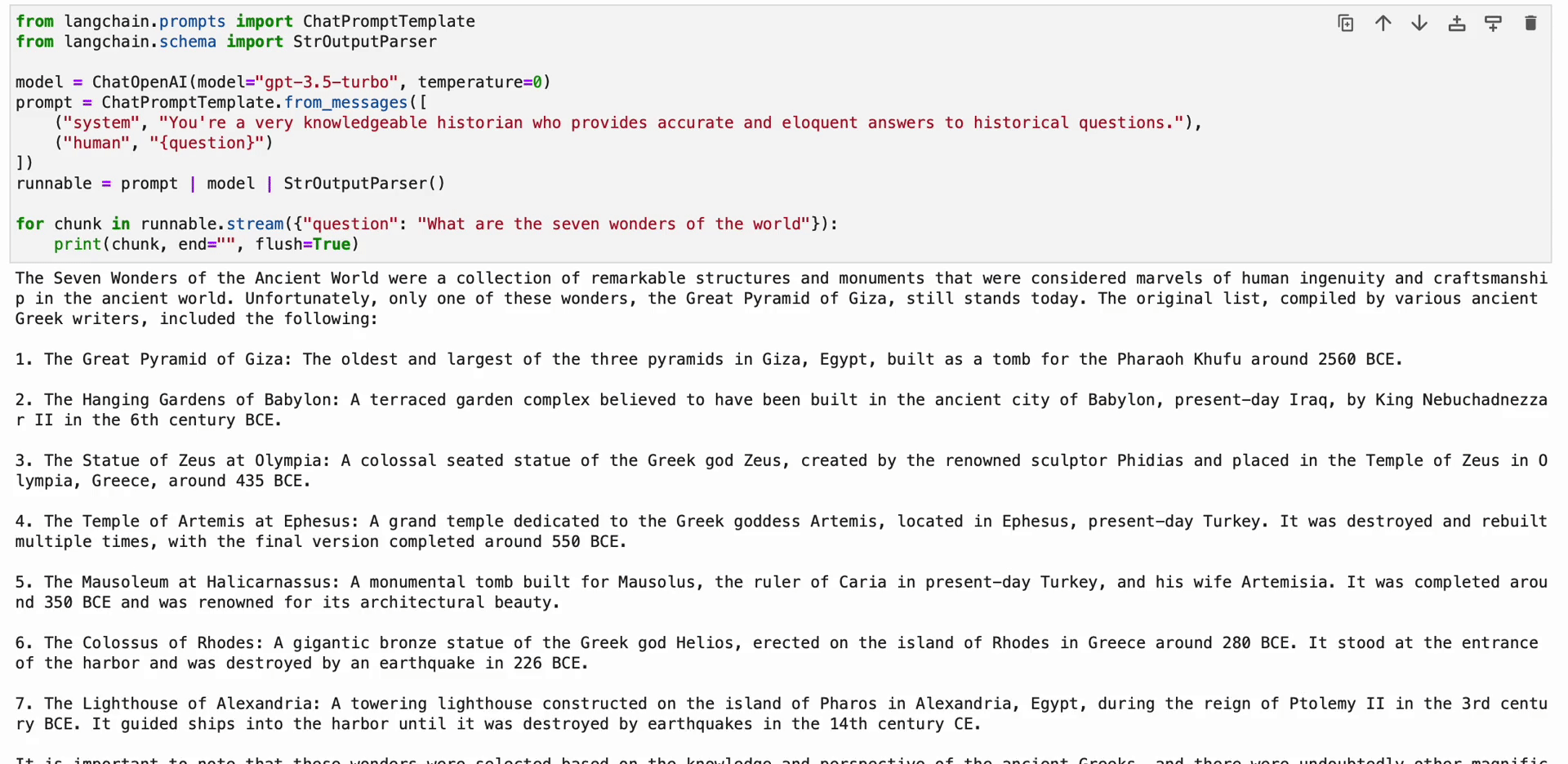
Alternativamente, LLMChain es una opción similar a LCEL para componer componentes. El ejemplo de LLMChain es el siguiente:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
Las cadenas en LangChain también pueden tener estado incorporando un objeto Memory. Esto permite la persistencia de datos entre llamadas, como se muestra en este ejemplo:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain también admite la integración con las API de llamada de funciones de OpenAI, lo cual es útil para obtener resultados estructurados y ejecutar funciones dentro de una cadena. Para obtener resultados estructurados, puede especificarlos usando clases de Pydantic o JsonSchema, como se ilustra a continuación:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
Para resultados estructurados, también está disponible un enfoque heredado que utiliza LLMChain:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")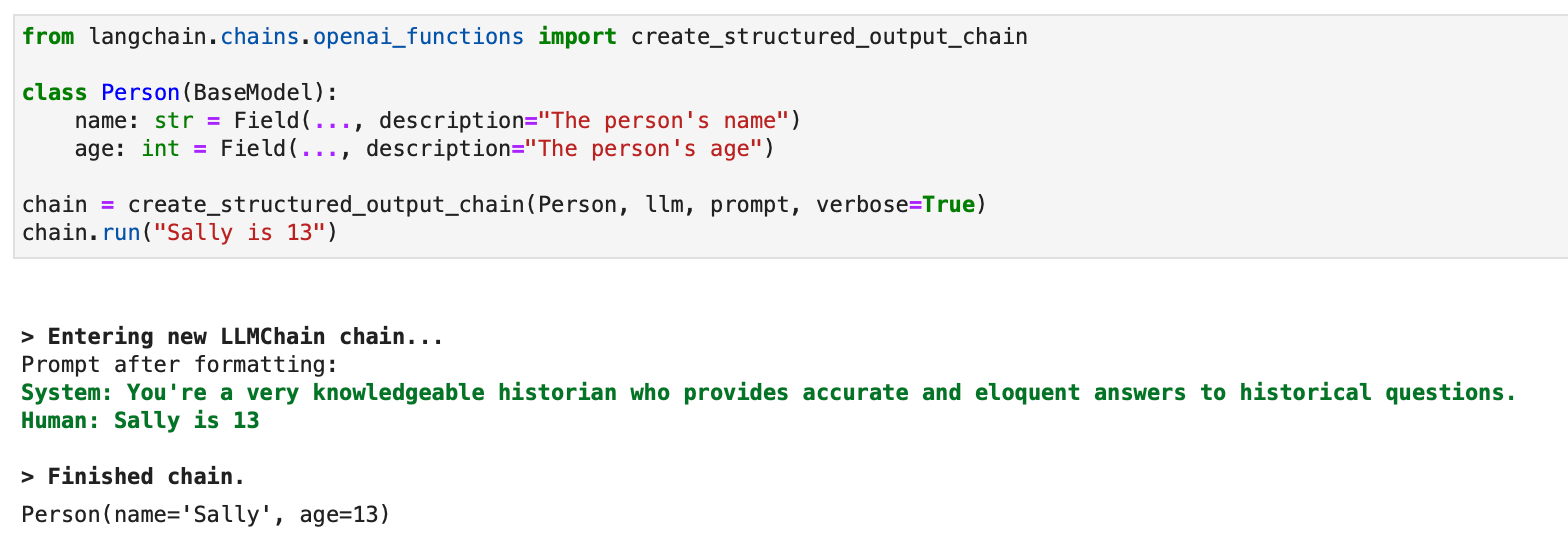
LangChain aprovecha las funciones de OpenAI para crear varias cadenas específicas para diferentes propósitos. Estos incluyen cadenas de extracción, etiquetado, OpenAPI y control de calidad con citas.
En el contexto de la extracción, el proceso es similar a la cadena de producción estructurada pero se centra en la extracción de información o entidades. Para etiquetar, la idea es etiquetar un documento con clases como sentimiento, lenguaje, estilo, temas tratados o tendencia política.
Se puede demostrar un ejemplo de cómo funciona el etiquetado en LangChain con un código Python. El proceso comienza con la instalación de los paquetes necesarios y la configuración del entorno:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
Se define el esquema de etiquetado, especificando las propiedades y sus tipos esperados:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Ejemplos de ejecución de la cadena de etiquetado con diferentes entradas muestran la capacidad del modelo para interpretar sentimientos, lenguajes y agresividad:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
Para un control más preciso, el esquema se puede definir de manera más específica, incluidos posibles valores, descripciones y propiedades requeridas. A continuación se muestra un ejemplo de este control mejorado:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Los esquemas Pydantic también se pueden usar para definir criterios de etiquetado, proporcionando una forma Pythonic de especificar las propiedades y tipos requeridos:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
Además, el transformador de documentos de etiquetado de metadatos de LangChain se puede utilizar para extraer metadatos de documentos de LangChain, ofreciendo una funcionalidad similar a la cadena de etiquetado pero aplicada a un documento de LangChain.
Citar fuentes de recuperación es otra característica de LangChain, que utiliza funciones de OpenAI para extraer citas del texto. Esto se demuestra en el siguiente código:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
En LangChain, el encadenamiento en aplicaciones de modelo de lenguaje grande (LLM) generalmente implica combinar una plantilla de solicitud con un LLM y, opcionalmente, un analizador de salida. La forma recomendada de hacerlo es a través del lenguaje de expresión LangChain (LCEL), aunque también se admite el enfoque heredado de LLMChain.
Al utilizar LCEL, BasePromptTemplate, BaseLanguageModel y BaseOutputParser implementan la interfaz Runnable y se pueden interconectar fácilmente entre sí. Aquí hay un ejemplo que demuestra esto:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
El enrutamiento en LangChain permite crear cadenas no deterministas donde el resultado de un paso anterior determina el siguiente. Esto ayuda a estructurar y mantener la coherencia en las interacciones con los LLM. Por ejemplo, si tiene dos plantillas optimizadas para diferentes tipos de preguntas, puede elegir la plantilla según la entrada del usuario.
Así es como puede lograr esto usando LCEL con RunnableBranch, que se inicializa con una lista de pares (condición, ejecutables) y un ejecutable predeterminado:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
Luego, la cadena final se construye utilizando varios componentes, como un clasificador de temas, una rama de solicitud y un analizador de salida, para determinar el flujo según el tema de la entrada:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
Este enfoque ejemplifica la flexibilidad y el poder de LangChain para manejar consultas complejas y enrutarlas adecuadamente en función de la entrada.
En el ámbito de los modelos de lenguaje, una práctica común es seguir una llamada inicial con una serie de llamadas posteriores, utilizando el resultado de una llamada como entrada para la siguiente. Este enfoque secuencial es especialmente beneficioso cuando se desea aprovechar la información generada en interacciones anteriores. Si bien el lenguaje de expresión LangChain (LCEL) es el método recomendado para crear estas secuencias, el método SequentialChain todavía está documentado por su compatibilidad con versiones anteriores.
Para ilustrar esto, consideremos un escenario en el que primero generamos una sinopsis de una obra y luego una reseña basada en esa sinopsis. Usando Python langchain.prompts, creamos dos PromptTemplate instancias: una para la sinopsis y otra para la reseña. Aquí está el código para configurar estas plantillas:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
En el enfoque LCEL, encadenamos estas indicaciones con ChatOpenAI y StrOutputParser para crear una secuencia que genere primero una sinopsis y luego una reseña. El fragmento de código es el siguiente:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Si necesitamos tanto la sinopsis como la reseña, podemos utilizar RunnablePassthrough para crear una cadena separada para cada uno y luego combinarlos:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Para escenarios que involucran secuencias más complejas, el SequentialChain El método entra en juego. Esto permite múltiples entradas y salidas. Considere un caso en el que necesitamos una sinopsis basada en el título y la época de una obra. Así es como podríamos configurarlo:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
En escenarios en los que desea mantener el contexto a lo largo de una cadena o para una parte posterior de la cadena, SimpleMemory puede ser usado. Esto es particularmente útil para gestionar relaciones complejas de entrada/salida. Por ejemplo, en un escenario en el que queremos generar publicaciones en las redes sociales basadas en el título, la época, la sinopsis y la reseña de una obra, SimpleMemory puede ayudar a gestionar estas variables:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Además de las cadenas secuenciales, existen cadenas especializadas para trabajar con documentos. Cada una de estas cadenas tiene un propósito diferente, desde combinar documentos hasta refinar las respuestas basándose en un análisis iterativo de documentos, hasta mapear y reducir el contenido del documento para resumirlo o reclasificarlo según las respuestas calificadas. Estas cadenas se pueden recrear con LCEL para mayor flexibilidad y personalización.
-
StuffDocumentsChaincombina una lista de documentos en un solo mensaje pasado a un LLM. -
RefineDocumentsChainactualiza su respuesta de forma iterativa para cada documento, lo que es adecuado para tareas en las que los documentos exceden la capacidad de contexto del modelo. -
MapReduceDocumentsChainaplica una cadena a cada documento individualmente y luego combina los resultados. -
MapRerankDocumentsChaincalifica cada respuesta basada en documentos y selecciona la de mayor puntuación.
A continuación se muestra un ejemplo de cómo podría configurar un MapReduceDocumentsChain usando LCEL:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
Esta configuración permite un análisis detallado y completo del contenido del documento, aprovechando las fortalezas de LCEL y el modelo de lenguaje subyacente.
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
Módulo V: Memoria
En LangChain, la memoria es un aspecto fundamental de las interfaces conversacionales, ya que permite a los sistemas hacer referencia a interacciones pasadas. Esto se logra mediante el almacenamiento y consulta de información, con dos acciones principales: lectura y escritura. El sistema de memoria interactúa con una cadena dos veces durante una ejecución, aumentando las entradas del usuario y almacenando las entradas y salidas para referencia futura.
Construyendo memoria en un sistema
- Almacenamiento de mensajes de chat: El módulo de memoria LangChain integra varios métodos para almacenar mensajes de chat, desde listas en memoria hasta bases de datos. Esto garantiza que todas las interacciones de chat se registren para referencia futura.
- Consultar mensajes de chat: Más allá de almacenar mensajes de chat, LangChain emplea estructuras de datos y algoritmos para crear una vista útil de estos mensajes. Los sistemas de memoria simples podrían devolver mensajes recientes, mientras que los sistemas más avanzados podrían resumir interacciones pasadas o centrarse en entidades mencionadas en la interacción actual.
Para demostrar el uso de la memoria en LangChain, considere el ConversationBufferMemory clase, una forma de memoria simple que almacena mensajes de chat en un búfer. He aquí un ejemplo:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
Al integrar la memoria en una cadena, es fundamental comprender las variables devueltas por la memoria y cómo se utilizan en la cadena. Por ejemplo, el load_memory_variables El método ayuda a alinear las variables leídas de la memoria con las expectativas de la cadena.
Ejemplo de extremo a extremo con LangChain
Considera usar ConversationBufferMemory en una LLMChain. La cadena, combinada con una plantilla de indicaciones adecuada y la memoria, proporciona una experiencia de conversación fluida. Aquí hay un ejemplo simplificado:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
Este ejemplo ilustra cómo el sistema de memoria de LangChain se integra con sus cadenas para proporcionar una experiencia conversacional coherente y contextualmente consciente.
Tipos de memoria en Langchain
Langchain ofrece varios tipos de memoria que se pueden utilizar para mejorar las interacciones con los modelos de IA. Cada tipo de memoria tiene sus propios parámetros y tipos de retorno, lo que los hace adecuados para diferentes escenarios. Exploremos algunos de los tipos de memoria disponibles en Langchain junto con ejemplos de código.
1. Memoria intermedia de conversación
Este tipo de memoria le permite almacenar y extraer mensajes de conversaciones. Puede extraer el historial como una cadena o como una lista de mensajes.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
También puede utilizar la memoria intermedia de conversación en cadena para interacciones similares a las de un chat.
2. Memoria de la ventana del búfer de conversación
Este tipo de memoria mantiene una lista de interacciones recientes y utiliza las últimas K interacciones, evitando que el búfer crezca demasiado.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Al igual que la memoria intermedia de conversación, también puedes utilizar este tipo de memoria en cadena para interacciones similares a las de un chat.
3. Memoria de entidad de conversación
Este tipo de memoria recuerda hechos sobre entidades específicas en una conversación y extrae información mediante un LLM.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. Memoria del gráfico de conocimiento de la conversación
Este tipo de memoria utiliza un gráfico de conocimiento para recrear la memoria. Puede extraer entidades actuales y tripletes de conocimientos de los mensajes.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
También puede utilizar este tipo de memoria en una cadena para la recuperación de conocimientos basada en conversaciones.
5. Memoria de resumen de conversación
Este tipo de memoria crea un resumen de la conversación a lo largo del tiempo, útil para condensar información de conversaciones más largas.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. Memoria intermedia de resumen de conversación
Este tipo de memoria combina el resumen de la conversación y el búfer, manteniendo un equilibrio entre las interacciones recientes y un resumen. Utiliza la longitud del token para determinar cuándo eliminar las interacciones.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
Puede utilizar estos tipos de memoria para mejorar sus interacciones con modelos de IA en Langchain. Cada tipo de memoria tiene un propósito específico y se puede seleccionar según sus requisitos.
7. Memoria intermedia del token de conversación
ConversationTokenBufferMemory es otro tipo de memoria que mantiene un búfer de interacciones recientes en la memoria. A diferencia de los tipos de memoria anteriores que se centran en la cantidad de interacciones, este utiliza la longitud del token para determinar cuándo eliminar las interacciones.
Usando memoria con LLM:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
En este ejemplo, la memoria está configurada para limitar las interacciones según la longitud del token en lugar del número de interacciones.
También puede obtener el historial como una lista de mensajes cuando utiliza este tipo de memoria.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Usando en cadena:
Puede utilizar ConversationTokenBufferMemory en una cadena para mejorar las interacciones con el modelo de IA.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
En este ejemplo, ConversationTokenBufferMemory se usa en ConversationChain para administrar la conversación y limitar las interacciones según la longitud del token.
8. Memoria VectorStoreRetriever
VectorStoreRetrieverMemory almacena recuerdos en un almacén de vectores y consulta los documentos más "destacados" cada vez que se llama. Este tipo de memoria no rastrea explícitamente el orden de las interacciones, pero utiliza la recuperación de vectores para recuperar recuerdos relevantes.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
En este ejemplo, VectorStoreRetrieverMemory se utiliza para almacenar y recuperar información relevante de una conversación basada en la recuperación de vectores.
También puede utilizar VectorStoreRetrieverMemory en una cadena para la recuperación de conocimientos basada en conversaciones, como se muestra en los ejemplos anteriores.
Estos diferentes tipos de memoria en Langchain brindan varias formas de administrar y recuperar información de las conversaciones, mejorando las capacidades de los modelos de IA para comprender y responder a las consultas y el contexto de los usuarios. Cada tipo de memoria se puede seleccionar según los requisitos específicos de su aplicación.
Ahora aprenderemos cómo usar la memoria con una LLMChain. La memoria en una LLMChain permite que el modelo recuerde interacciones y contexto anteriores para proporcionar respuestas más coherentes y conscientes del contexto.
Para configurar la memoria en LLMChain, necesita crear una clase de memoria, como ConversationBufferMemory. Así es como puedes configurarlo:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
En este ejemplo, ConversationBufferMemory se utiliza para almacenar el historial de conversaciones. El memory_key El parámetro especifica la clave utilizada para almacenar el historial de conversaciones.
Si está utilizando un modelo de chat en lugar de un modelo de estilo de finalización, puede estructurar sus indicaciones de manera diferente para utilizar mejor la memoria. A continuación se muestra un ejemplo de cómo configurar un LLMChain basado en un modelo de chat con memoria:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
En este ejemplo, ChatPromptTemplate se usa para estructurar el mensaje y ConversationBufferMemory se usa para almacenar y recuperar el historial de conversaciones. Este enfoque es particularmente útil para conversaciones estilo chat donde el contexto y la historia juegan un papel crucial.
La memoria también se puede agregar a una cadena con múltiples entradas, como una cadena de preguntas/respuestas. A continuación se muestra un ejemplo de cómo configurar la memoria en una cadena de preguntas/respuestas:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
En este ejemplo, se responde una pregunta utilizando un documento dividido en partes más pequeñas. ConversationBufferMemory se utiliza para almacenar y recuperar el historial de conversaciones, lo que permite que el modelo proporcione respuestas contextuales.
Agregar memoria a un agente le permite recordar y utilizar interacciones previas para responder preguntas y proporcionar respuestas contextuales. A continuación se explica cómo puede configurar la memoria en un agente:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
En este ejemplo, se agrega memoria a un agente, lo que le permite recordar el historial de conversaciones anteriores y proporcionar respuestas contextuales. Esto permite al agente responder preguntas de seguimiento con precisión basándose en la información almacenada en la memoria.
Lenguaje de expresión LangChain
En el mundo del procesamiento del lenguaje natural y el aprendizaje automático, componer cadenas complejas de operaciones puede ser una tarea desalentadora. Afortunadamente, LangChain Expression Language (LCEL) viene al rescate, proporcionando una forma declarativa y eficiente de construir e implementar canales de procesamiento de lenguaje sofisticados. LCEL está diseñado para simplificar el proceso de composición de cadenas, permitiendo pasar de la creación de prototipos a la producción con facilidad. En este blog, exploraremos qué es LCEL y por qué es posible que desee utilizarlo, junto con ejemplos de código prácticos para ilustrar sus capacidades.
LCEL, o LangChain Expression Language, es una poderosa herramienta para componer cadenas de procesamiento de lenguaje. Fue diseñado específicamente para respaldar la transición de la creación de prototipos a la producción sin problemas, sin requerir grandes cambios de código. Ya sea que esté creando una cadena simple “prompt + LLM” o un proceso complejo con cientos de pasos, LCEL lo tiene cubierto.
A continuación se presentan algunas razones para utilizar LCEL en sus proyectos de procesamiento del lenguaje:
- Transmisión rápida de tokens: LCEL entrega tokens de un modelo de lenguaje a un analizador de salida en tiempo real, lo que mejora la capacidad de respuesta y la eficiencia.
- API versátiles: LCEL admite API síncronas y asíncronas para la creación de prototipos y uso en producción, manejando múltiples solicitudes de manera eficiente.
- Paralelización automática: LCEL optimiza la ejecución paralela cuando es posible, reduciendo la latencia en las interfaces sincronizadas y asíncronas.
- Configuraciones confiables: configure reintentos y alternativas para mejorar la confiabilidad de la cadena a escala, con soporte de transmisión en desarrollo.
- Transmitir resultados intermedios: acceda a resultados intermedios durante el procesamiento para actualizaciones de usuario o fines de depuración.
- Generación de esquemas: LCEL genera esquemas Pydantic y JSONSchema para validación de entrada y salida.
- Seguimiento completo: LangSmith rastrea automáticamente todos los pasos en cadenas complejas para su observabilidad y depuración.
- Implementación sencilla: implemente cadenas creadas por LCEL sin esfuerzo utilizando LangServe.
Ahora, profundicemos en ejemplos de código prácticos que demuestran el poder de LCEL. Exploraremos tareas y escenarios comunes en los que LCEL brilla.
Aviso + LLM
La composición más fundamental implica combinar un mensaje y un modelo de lenguaje para crear una cadena que toma la entrada del usuario, la agrega a un mensaje, la pasa a un modelo y devuelve la salida del modelo sin formato. He aquí un ejemplo:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
En este ejemplo, la cadena genera un chiste sobre los osos.
Puede adjuntar secuencias de parada a su cadena para controlar cómo procesa el texto. Por ejemplo:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
Esta configuración detiene la generación de texto cuando se encuentra un carácter de nueva línea.
LCEL admite adjuntar información de llamada de función a su cadena. He aquí un ejemplo:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
Este ejemplo adjunta información de llamada a función para generar un chiste.
Aviso + LLM + OutputParser
Puede agregar un analizador de salida para transformar la salida del modelo sin formato a un formato más viable. Así es como puedes hacerlo:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
La salida ahora está en formato de cadena, lo que es más conveniente para tareas posteriores.
Al especificar una función para devolver, puede analizarla directamente usando LCEL. Por ejemplo:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
Este ejemplo analiza directamente la salida de la función "broma".
Estos son sólo algunos ejemplos de cómo LCEL simplifica tareas complejas de procesamiento del lenguaje. Ya sea que esté creando chatbots, generando contenido o realizando transformaciones de texto complejas, LCEL puede optimizar su flujo de trabajo y hacer que su código sea más fácil de mantener.
RAG (Generación de recuperación aumentada)
LCEL se puede utilizar para crear cadenas de generación de recuperación aumentada, que combinan pasos de recuperación y generación de lenguaje. He aquí un ejemplo:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
En este ejemplo, la cadena recupera información relevante del contexto y genera una respuesta a la pregunta.
Cadena de recuperación conversacional
Puede agregar fácilmente el historial de conversaciones a sus cadenas. A continuación se muestra un ejemplo de una cadena de recuperación conversacional:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
En este ejemplo, la cadena maneja una pregunta de seguimiento dentro de un contexto conversacional.
Con memoria y devolución de documentos originales
LCEL también admite memoria y devolución de documentos fuente. Así es como puedes usar la memoria en una cadena:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
En este ejemplo, la memoria se utiliza para almacenar y recuperar el historial de conversaciones y los documentos de origen.
Múltiples cadenas
Puedes unir varias cadenas usando Runnables. He aquí un ejemplo:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
En este ejemplo, se combinan dos cadenas para generar información sobre una ciudad y su país en un idioma específico.
Ramificación y fusión
LCEL le permite dividir y fusionar cadenas usando RunnableMaps. A continuación se muestra un ejemplo de ramificación y fusión:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
En este ejemplo, se utiliza una cadena de ramificación y fusión para generar un argumento y evaluar sus pros y sus contras antes de generar una respuesta final.
Escribir código Python con LCEL
Una de las poderosas aplicaciones de LangChain Expression Language (LCEL) es escribir código Python para resolver los problemas de los usuarios. A continuación se muestra un ejemplo de cómo utilizar LCEL para escribir código Python:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
En este ejemplo, un usuario proporciona información y LCEL genera código Python para resolver el problema. Luego, el código se ejecuta utilizando un REPL de Python y el código Python resultante se devuelve en formato Markdown.
Tenga en cuenta que el uso de Python REPL puede ejecutar código arbitrario, así que utilícelo con precaución.
Agregar memoria a una cadena
La memoria es esencial en muchas aplicaciones de IA conversacional. A continuación se explica cómo agregar memoria a una cadena arbitraria:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
En este ejemplo, la memoria se utiliza para almacenar y recuperar el historial de conversaciones, lo que permite que el chatbot mantenga el contexto y responda adecuadamente.
Usar herramientas externas con ejecutables
LCEL le permite integrar perfectamente herramientas externas con Runnables. Aquí hay un ejemplo que utiliza la herramienta de búsqueda DuckDuckGo:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
En este ejemplo, LCEL integra la herramienta DuckDuckGo Search en la cadena, lo que le permite generar una consulta de búsqueda a partir de la entrada del usuario y recuperar resultados de búsqueda.
La flexibilidad de LCEL facilita la incorporación de diversas herramientas y servicios externos en sus procesos de procesamiento de idiomas, mejorando sus capacidades y funcionalidades.
Agregar moderación a una solicitud de LLM
Para garantizar que su solicitud de LLM cumpla con las políticas de contenido e incluya salvaguardas de moderación, puede integrar controles de moderación en su cadena. Aquí se explica cómo agregar moderación usando LangChain:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
En este ejemplo, el OpenAIModerationChain se utiliza para agregar moderación a la respuesta generada por el LLM. La cadena de moderación verifica la respuesta en busca de contenido que viole la política de contenido de OpenAI. Si se encuentra alguna infracción, marcará la respuesta en consecuencia.
Enrutamiento por similitud semántica
LCEL le permite implementar una lógica de enrutamiento personalizada basada en la similitud semántica de la entrada del usuario. A continuación se muestra un ejemplo de cómo determinar dinámicamente la lógica de la cadena en función de la entrada del usuario:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
En este ejemplo, el prompt_router La función calcula la similitud del coseno entre la entrada del usuario y las plantillas de mensajes predefinidas para preguntas de física y matemáticas. Según la puntuación de similitud, la cadena selecciona dinámicamente la plantilla de mensaje más relevante, asegurando que el chatbot responda adecuadamente a la pregunta del usuario.
Uso de agentes y ejecutables
LangChain le permite crear agentes combinando Runnables, indicaciones, modelos y herramientas. A continuación se muestra un ejemplo de cómo crear un agente y usarlo:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
En este ejemplo, se crea un agente combinando un modelo, herramientas, un mensaje y una lógica personalizada para pasos intermedios y conversión de herramientas. Luego se ejecuta el agente, proporcionando una respuesta a la consulta del usuario.
Consultar una base de datos SQL
Puede utilizar LangChain para consultar una base de datos SQL y generar consultas SQL basadas en las preguntas de los usuarios. He aquí un ejemplo:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
En este ejemplo, LangChain se utiliza para generar consultas SQL basadas en preguntas de los usuarios y recuperar respuestas de una base de datos SQL. Las indicaciones y respuestas están formateadas para proporcionar interacciones en lenguaje natural con la base de datos.
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
LangServe y LangSmith
LangServe ayuda a los desarrolladores a implementar cadenas y ejecutables de LangChain como una API REST. Esta biblioteca está integrada con FastAPI y utiliza pydantic para la validación de datos. Además, proporciona un cliente que se puede utilizar para llamar a ejecutables implementados en un servidor, y hay un cliente JavaScript disponible en LangChainJS.
Características
- Los esquemas de entrada y salida se infieren automáticamente a partir de su objeto LangChain y se aplican en cada llamada a la API, con numerosos mensajes de error.
- Está disponible una página de documentos API con JSONSchema y Swagger.
- Puntos finales eficientes /invoke, /batch y /stream con soporte para muchas solicitudes simultáneas en un solo servidor.
- /stream_log punto final para transmitir todos (o algunos) pasos intermedios desde su cadena/agente.
- Página de juegos en /playground con salida de streaming y pasos intermedios.
- Seguimiento integrado (opcional) a LangSmith; simplemente agregue su clave API (consulte las instrucciones).
- Todo creado con bibliotecas Python de código abierto probadas en batalla, como FastAPI, Pydantic, uvloop y asyncio.
Limitaciones
- Las devoluciones de llamada del cliente aún no se admiten para eventos que se originan en el servidor.
- Los documentos OpenAPI no se generarán cuando se utilice Pydantic V2. FastAPI no admite la combinación de espacios de nombres pydantic v1 y v2. Consulte la sección siguiente para obtener más detalles.
Utilice la CLI de LangChain para iniciar un proyecto LangServe rápidamente. Para utilizar la CLI de langchain, asegúrese de tener instalada una versión reciente de langchain-cli. Puedes instalarlo con pip install -U langchain-cli.
langchain app new ../path/to/directory
Inicie su instancia de LangServe rápidamente con LangChain Templates. Para obtener más ejemplos, consulte el índice de plantillas o el directorio de ejemplos.
Aquí hay un servidor que implementa un modelo de chat OpenAI, un modelo de chat Anthropic y una cadena que usa el modelo Anthropic para contar un chiste sobre un tema.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
Una vez que haya implementado el servidor anterior, podrá ver los documentos OpenAPI generados usando:
curl localhost:8000/docs
Asegúrese de agregar el sufijo /docs.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
En TypeScript (requiere LangChain.js versión 0.0.166 o posterior):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `http://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
Python usando solicitudes:
import requests
response = requests.post( "http://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
También puedes usar rizo:
curl --location --request POST 'http://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
El siguiente código:
...
add_routes( app, runnable, path="/my_runnable",
)
Agrega estos puntos finales al servidor:
- POST /my_runnable/invoke – invoca el ejecutable en una sola entrada
- POST /my_runnable/batch: invoca el ejecutable en un lote de entradas
- POST /my_runnable/stream – invocar en una sola entrada y transmitir la salida
- POST /my_runnable/stream_log: invoca en una sola entrada y transmite la salida, incluida la salida de los pasos intermedios a medida que se genera.
- GET /my_runnable/input_schema – esquema json para entrada al ejecutable
- GET /my_runnable/output_schema – esquema json para la salida del ejecutable
- GET /my_runnable/config_schema – esquema json para la configuración del ejecutable
Puede encontrar una página de juegos para su ejecutable en /my_runnable/playground. Esto expone una interfaz de usuario simple para configurar e invocar su ejecutable con salida de transmisión y pasos intermedios.
Tanto para cliente como para servidor:
pip install "langserve[all]"
o pip install “langserve[cliente]” para el código del cliente y pip install “langserve[servidor]” para el código del servidor.
Si necesita agregar autenticación a su servidor, consulte la documentación de seguridad y la documentación de middleware de FastAPI.
Puede implementar en GCP Cloud Run usando el siguiente comando:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe brinda soporte para Pydantic 2 con algunas limitaciones. Los documentos OpenAPI no se generarán para invoke/batch/stream/stream_log cuando se use Pydantic V2. Fast API no admite la combinación de espacios de nombres pydantic v1 y v2. LangChain usa el espacio de nombres v1 en Pydantic v2. Lea las siguientes pautas para garantizar la compatibilidad con LangChain. Excepto por estas limitaciones, esperamos que los puntos finales de la API, el área de juegos y cualquier otra característica funcionen como se espera.
Las aplicaciones de LLM suelen tratar con archivos. Existen diferentes arquitecturas que se pueden crear para implementar el procesamiento de archivos; a un nivel alto:
- El archivo se puede cargar en el servidor a través de un punto final dedicado y procesarse utilizando un punto final separado.
- El archivo se puede cargar por valor (bytes de archivo) o por referencia (por ejemplo, URL s3 al contenido del archivo).
- El punto final de procesamiento puede ser bloqueante o no bloqueante.
- Si se requiere un procesamiento significativo, el procesamiento se puede descargar a un grupo de procesos dedicado.
Debe determinar cuál es la arquitectura adecuada para su aplicación. Actualmente, para cargar archivos por valor en un ejecutable, utilice la codificación base64 para el archivo (aún no se admite multipart/form-data).
He aquí un ejemplo que muestra cómo usar la codificación base64 para enviar un archivo a un ejecutable remoto. Recuerde, siempre puede cargar archivos por referencia (por ejemplo, URL s3) o cargarlos como datos de formulario/multiparte a un punto final dedicado.
Los tipos de entrada y salida se definen en todos los ejecutables. Puede acceder a ellos a través de las propiedades input_schema y output_schema. LangServe utiliza estos tipos para validación y documentación. Si desea anular los tipos inferidos predeterminados, puede utilizar el método with_types.
Aquí hay un ejemplo de juguete para ilustrar la idea:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
Herede de CustomUserType si desea que los datos se deserialicen en un modelo pydantic en lugar de la representación dict equivalente. Por el momento, este tipo sólo funciona en el lado del servidor y se utiliza para especificar el comportamiento de decodificación deseado. Si hereda de este tipo, el servidor mantendrá el tipo decodificado como modelo pydantic en lugar de convertirlo en un dict.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
El área de juegos le permite definir widgets personalizados para su ejecutable desde el backend. Un widget se especifica a nivel de campo y se envía como parte del esquema JSON del tipo de entrada. Un widget debe contener una clave llamada tipo y el valor debe ser uno de una lista conocida de widgets. Otras claves de widget se asociarán con valores que describen rutas en un objeto JSON.
Esquema general:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Permite la creación de una entrada de carga de archivos en el área de juegos de la interfaz de usuario para archivos que se cargan como cadenas codificadas en base64. Aquí está el ejemplo completo.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
Introducción a LangSmith
LangChain facilita la creación de prototipos de agentes y aplicaciones LLM. Sin embargo, entregar aplicaciones LLM a producción puede resultar engañosamente difícil. Probablemente tendrá que personalizar e iterar en gran medida sus indicaciones, cadenas y otros componentes para crear un producto de alta calidad.
Para ayudar en este proceso, se presentó LangSmith, una plataforma unificada para depurar, probar y monitorear sus aplicaciones LLM.
¿Cuándo podría resultar útil esto? Puede resultarle útil cuando desee depurar rápidamente una nueva cadena, agente o conjunto de herramientas, visualizar cómo se relacionan y utilizan los componentes (cadenas, llms, recuperadores, etc.), evaluar diferentes indicaciones y LLM para un solo componente. ejecute una cadena determinada varias veces sobre un conjunto de datos para garantizar que cumpla constantemente con un estándar de calidad, o capture rastros de uso y utilice LLM o procesos de análisis para generar información.
Requisitos previos:
- Cree una cuenta LangSmith y cree una clave API (consulte la esquina inferior izquierda).
- Familiarícese con la plataforma consultando los documentos.
¡Ahora, comencemos!
Primero, configure sus variables de entorno para indicarle a LangChain que registre seguimientos. Esto se hace configurando la variable de entorno LANGCHAIN_TRACING_V2 en verdadero. Puede decirle a LangChain en qué proyecto iniciar sesión configurando la variable de entorno LANGCHAIN_PROJECT (si no está configurada, las ejecuciones se registrarán en el proyecto predeterminado). Esto creará automáticamente el proyecto si no existe. También debe configurar las variables de entorno LANGCHAIN_ENDPOINT y LANGCHAIN_API_KEY.
NOTA: También puede utilizar un administrador de contexto en Python para registrar seguimientos usando:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
Sin embargo, en este ejemplo, usaremos variables de entorno.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
Cree el cliente LangSmith para interactuar con la API:
from langsmith import Client client = Client()
Cree un componente LangChain y registre ejecuciones en la plataforma. En este ejemplo, crearemos un agente estilo ReAct con acceso a una herramienta de búsqueda general (DuckDuckGo). El mensaje del agente se puede ver en el Hub aquí:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
Estamos ejecutando el agente simultáneamente en múltiples entradas para reducir la latencia. Las ejecuciones se registran en LangSmith en segundo plano, por lo que la latencia de ejecución no se ve afectada:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
Suponiendo que haya configurado correctamente su entorno, los seguimientos de su agente deberían aparecer en la sección Proyectos de la aplicación. ¡Felicitaciones!
Sin embargo, parece que el agente no está utilizando las herramientas de forma eficaz. Evaluemos esto para tener una línea de base.
Además de registrar ejecuciones, LangSmith también le permite probar y evaluar sus aplicaciones LLM.
En esta sección, aprovechará LangSmith para crear un conjunto de datos de referencia y ejecutar evaluadores asistidos por IA en un agente. Lo harás en unos pocos pasos:
- Cree un conjunto de datos de LangSmith:
A continuación, utilizamos el cliente LangSmith para crear un conjunto de datos a partir de las preguntas de entrada anteriores y una lista de etiquetas. Los utilizará más adelante para medir el rendimiento de un nuevo agente. Un conjunto de datos es una colección de ejemplos, que no son más que pares de entrada y salida que puedes usar como casos de prueba para tu aplicación:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- Inicialice un nuevo agente para comparar:
LangSmith le permite evaluar cualquier LLM, cadena, agente o incluso una función personalizada. Los agentes conversacionales tienen estado (tienen memoria); Para garantizar que este estado no se comparta entre las ejecuciones del conjunto de datos, pasaremos un chain_factory (
también conocida como constructor) para inicializar para cada llamada:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- Configurar evaluación:
Comparar manualmente los resultados de las cadenas en la interfaz de usuario es eficaz, pero puede llevar mucho tiempo. Puede resultar útil utilizar métricas automatizadas y comentarios asistidos por IA para evaluar el rendimiento de su componente:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- Ejecute el agente y los evaluadores:
Utilice la función run_on_dataset (o asíncrona arun_on_dataset) para evaluar su modelo. Esta voluntad:
- Obtenga filas de ejemplo del conjunto de datos especificado.
- Ejecute su agente (o cualquier función personalizada) en cada ejemplo.
- Aplique evaluadores a los seguimientos de ejecución resultantes y a los ejemplos de referencia correspondientes para generar comentarios automatizados.
Los resultados serán visibles en la aplicación LangSmith:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
Ahora que tenemos los resultados de nuestra prueba, podemos realizar cambios en nuestro agente y compararlos. Intentemos esto nuevamente con un mensaje diferente y veamos los resultados:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
LangSmith le permite exportar datos a formatos comunes como CSV o JSONL directamente en la aplicación web. También puede utilizar el cliente para recuperar ejecuciones para análisis posteriores, almacenarlas en su propia base de datos o compartirlas con otros. Busquemos los rastros de ejecución de la ejecución de evaluación:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
Esta fue una guía rápida para comenzar, pero hay muchas más formas de utilizar LangSmith para acelerar el flujo de desarrolladores y producir mejores resultados.
Para obtener más información sobre cómo aprovechar LangSmith al máximo, consulte la documentación de LangSmith.
Sube de nivel con Nanonets
Si bien LangChain es una herramienta valiosa para integrar modelos de lenguaje (LLM) con sus aplicaciones, puede enfrentar limitaciones cuando se trata de casos de uso empresarial. Exploremos cómo Nanonets va más allá de LangChain para abordar estos desafíos:
1. Conectividad de datos integral:
LangChain ofrece conectores, pero es posible que no cubra todas las aplicaciones de espacio de trabajo y formatos de datos de los que dependen las empresas. Nanonets proporciona conectores de datos para más de 100 aplicaciones de espacio de trabajo ampliamente utilizadas, incluidas Slack, Notion, Google Suite, Salesforce, Zendesk y muchas más. También admite todos los tipos de datos no estructurados como PDF, TXT, imágenes, archivos de audio y archivos de video, así como tipos de datos estructurados como CSV, hojas de cálculo, MongoDB y bases de datos SQL.

2. Automatización de tareas para aplicaciones de Workspace:
Si bien la generación de texto/respuesta funciona muy bien, las capacidades de LangChain son limitadas cuando se trata de utilizar lenguaje natural para realizar tareas en diversas aplicaciones. Nanonets ofrece agentes de activación/acción para las aplicaciones de espacio de trabajo más populares, lo que le permite configurar flujos de trabajo que escuchan eventos y realizan acciones. Por ejemplo, puede automatizar respuestas de correo electrónico, entradas de CRM, consultas SQL y más, todo mediante comandos de lenguaje natural.
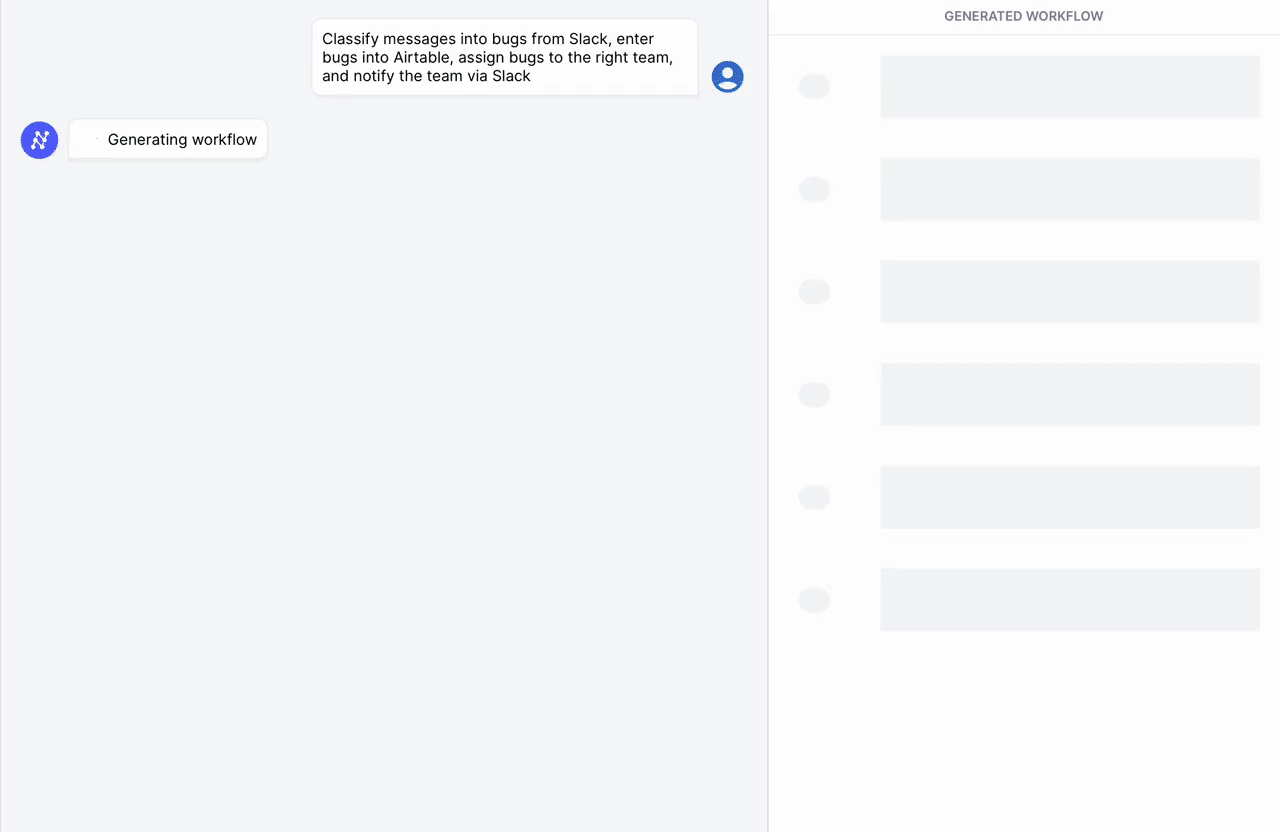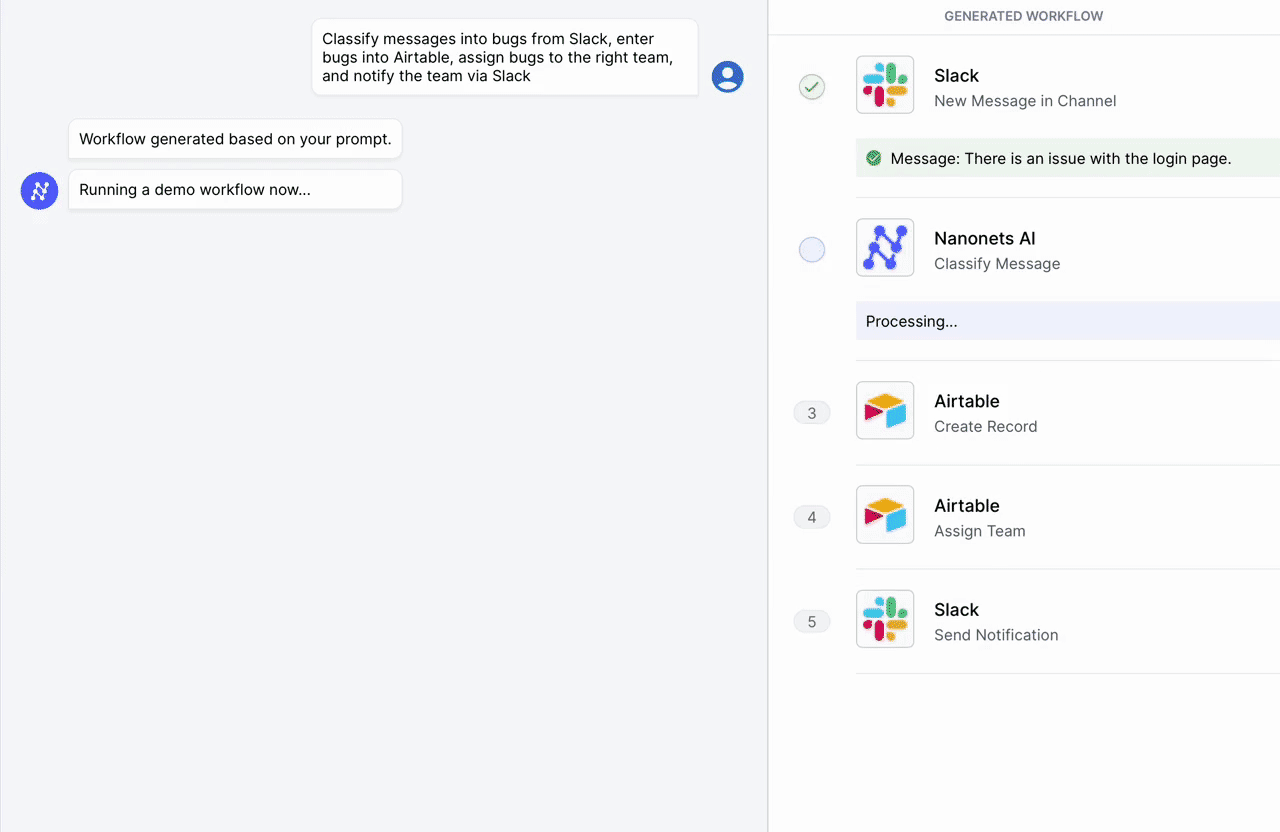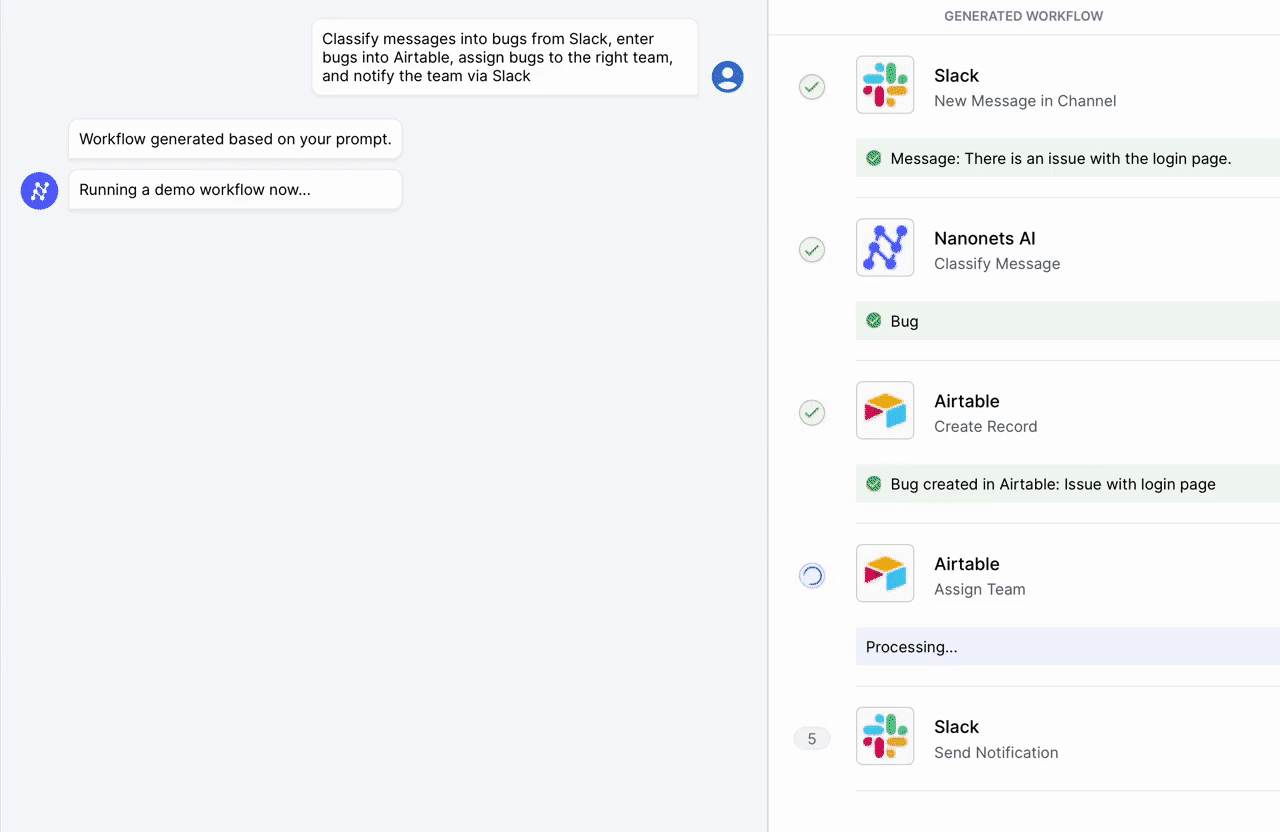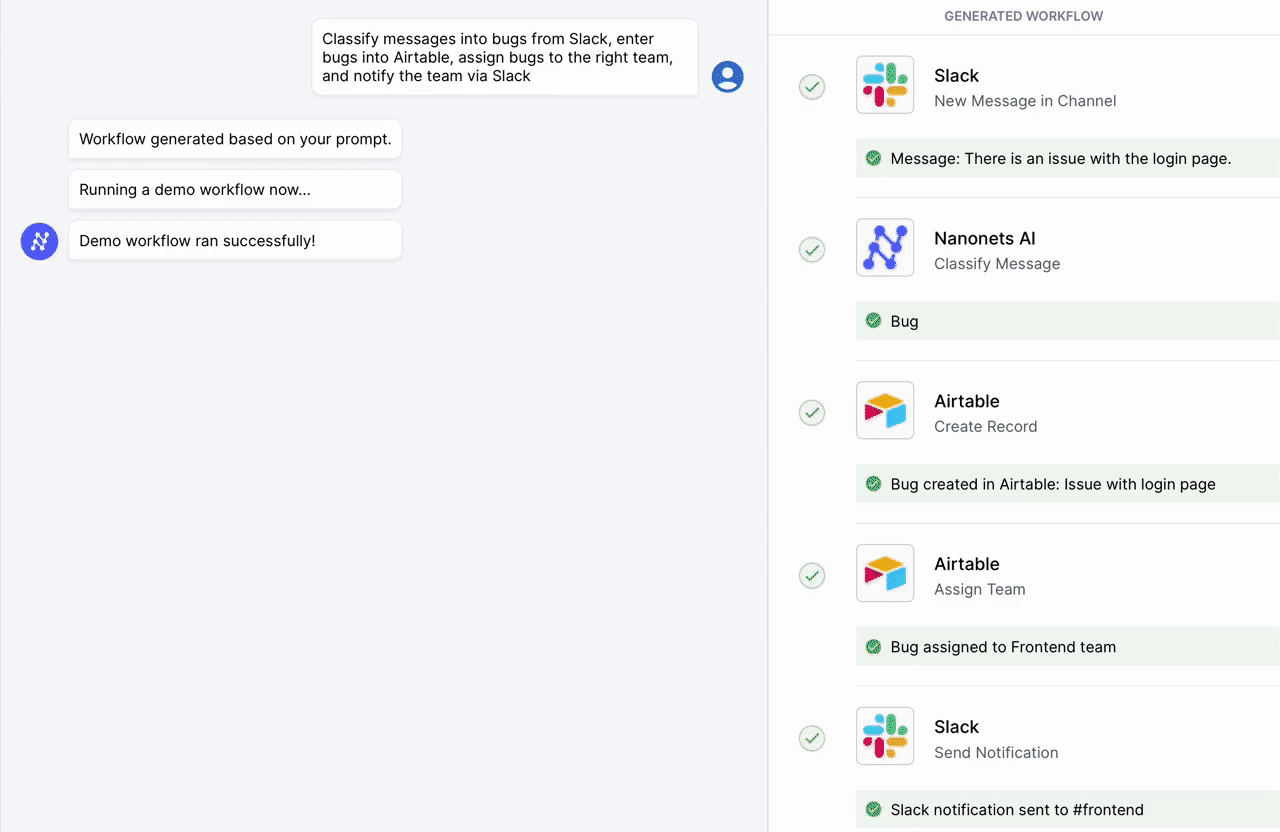
3. Sincronización de datos en tiempo real:
LangChain recupera datos estáticos con conectores de datos, que pueden no mantenerse al día con los cambios de datos en la base de datos de origen. Por el contrario, Nanonets garantiza la sincronización en tiempo real con fuentes de datos, lo que garantiza que siempre esté trabajando con la información más reciente.

3. Configuración simplificada:
Configurar los elementos de la canalización de LangChain, como recuperadores y sintetizadores, puede ser un proceso complejo y que requiere mucho tiempo. Nanonets simplifica esto al proporcionar una ingesta e indexación de datos optimizadas para cada tipo de datos, todo manejado en segundo plano por el Asistente de IA. Esto reduce la carga de realizar ajustes y facilita su configuración y uso.
4. Solución unificada:
A diferencia de LangChain, que puede requerir implementaciones únicas para cada tarea, Nanonets sirve como una solución integral para conectar sus datos con LLM. Ya sea que necesite crear aplicaciones LLM o flujos de trabajo de IA, Nanonets ofrece una plataforma unificada para sus diversas necesidades.
Flujos de trabajo de IA de nanoredes
Nanonets Workflows es un asistente de IA seguro y multipropósito que simplifica la integración de su conocimiento y datos con LLM y facilita la creación de aplicaciones y flujos de trabajo sin código. Ofrece una interfaz de usuario fácil de usar, lo que la hace accesible tanto para individuos como para organizaciones.
Para comenzar, puede programar una llamada con uno de nuestros expertos en IA, quien puede brindarle una demostración personalizada y una prueba de los flujos de trabajo de Nanonets adaptados a su caso de uso específico.
Una vez configurado, puede utilizar el lenguaje natural para diseñar y ejecutar aplicaciones y flujos de trabajo complejos impulsados por LLM, integrándose perfectamente con sus aplicaciones y datos.

Recargue a sus equipos con Nanonets AI para crear aplicaciones e integrar sus datos con aplicaciones y flujos de trabajo impulsados por AI, permitiendo a sus equipos concentrarse en lo que realmente importa.
Automatice tareas manuales y flujos de trabajo con nuestro generador de flujos de trabajo impulsado por IA, diseñado por Nanonets para usted y sus equipos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://nanonets.com/blog/langchain/

