
Imagen generada con el modelo Segmind SSD-1B
¿Estás emocionado de comenzar a analizar datos usando SQL? Bueno, quizás tengas que esperar un poco. ¿Pero por qué?
Los datos de las tablas de bases de datos a menudo pueden ser confusos. Sus datos pueden contener valores faltantes, registros duplicados, valores atípicos, entradas de datos inconsistentes y más. Por lo tanto, es muy importante limpiar los datos antes de poder analizarlos usando SQL.
Cuando estás aprendiendo SQL, puedes activar tablas de bases de datos, modificarlas, actualizar y eliminar registros como quieras. Pero en la práctica esto casi nunca ocurre. Es posible que no tenga permiso para modificar tablas, actualizar y eliminar registros. Pero tendrá acceso de lectura a la base de datos y podrá ejecutar un montón de consultas SELECT.
En este tutorial, crearemos una tabla de base de datos, la llenaremos con registros y veremos cómo podemos limpiar los datos con SQL. ¡Empecemos a codificar!
Para este tutorial, creemos un employees mesa así:
-- Create the employees table
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
salary DECIMAL(10, 2),
hire_date VARCHAR(20),
department VARCHAR(50)
);
A continuación, insertemos algunos registros de muestra ficticios en la tabla:
-- Insert 20 sample records
INSERT INTO employees (employee_id, employee_name, salary, hire_date, department) VALUES
(1, 'Amy West', 60000.00, '2021-01-15', 'HR'),
(2, 'Ivy Lee', 75000.50, '2020-05-22', 'Sales'),
(3, 'joe smith', 80000.75, '2019-08-10', 'Marketing'),
(4, 'John White', 90000.00, '2020-11-05', 'Finance'),
(5, 'Jane Hill', 55000.25, '2022-02-28', 'IT'),
(6, 'Dave West', 72000.00, '2020-03-12', 'Marketing'),
(7, 'Fanny Lee', 85000.50, '2018-06-25', 'Sales'),
(8, 'Amy Smith', 95000.25, '2019-11-30', 'Finance'),
(9, 'Ivy Hill', 62000.75, '2021-07-18', 'IT'),
(10, 'Joe White', 78000.00, '2022-04-05', 'Marketing'),
(11, 'John Lee', 68000.50, '2018-12-10', 'HR'),
(12, 'Jane West', 89000.25, '2017-09-15', 'Sales'),
(13, 'Dave Smith', 60000.75, '2022-01-08', NULL),
(14, 'Fanny White', 72000.00, '2019-04-22', 'IT'),
(15, 'Amy Hill', 84000.50, '2020-08-17', 'Marketing'),
(16, 'Ivy West', 92000.25, '2021-02-03', 'Finance'),
(17, 'Joe Lee', 58000.75, '2018-05-28', 'IT'),
(18, 'John Smith', 77000.00, '2019-10-10', 'HR'),
(19, 'Jane Hill', 81000.50, '2022-03-15', 'Sales'),
(20, 'Dave White', 70000.25, '2017-12-20', 'Marketing');
Si puede darse cuenta, he utilizado un pequeño conjunto de nombres y apellidos para tomar muestras y construir el campo de nombre para los registros. Sin embargo, puedes ser más creativo con los discos.
Note: Todas las consultas en este tutorial son para MySQL. Pero eres libre de utilizar el RDBMS de tu elección.
Los valores faltantes en los registros de datos siempre son un problema. Entonces tienes que manejarlos en consecuencia.
Un enfoque ingenuo es descartar todos los registros que contengan valores faltantes para uno o más campos. Sin embargo, no deberías hacer esto a menos que estés seguro de que no hay otra forma mejor de manejar los valores faltantes.
En employees tabla, vemos que hay un valor NULL en la columna 'departamento' (ver fila de Employee_id 13) que indica que falta el campo:
SELECT * FROM employees;
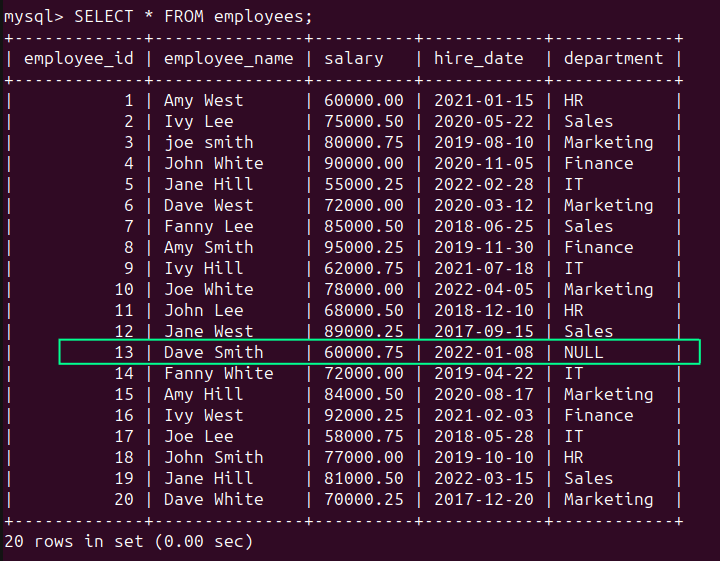
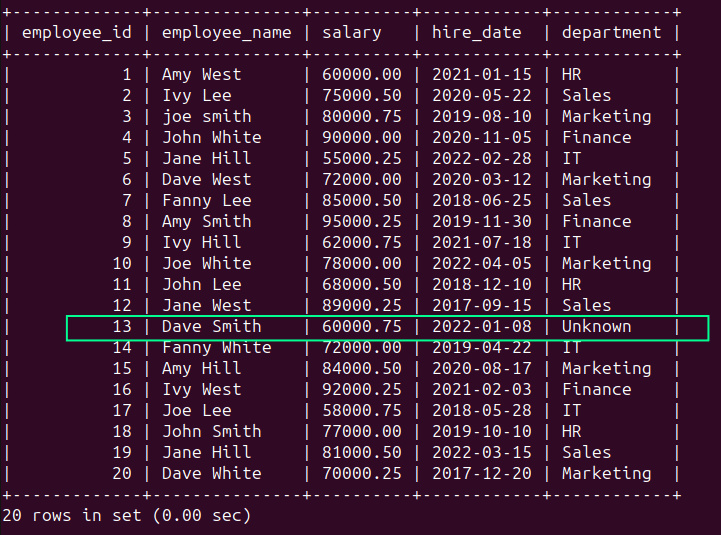
Puede utilizar el Función FUSIONAR() para usar la cadena 'Desconocida' para el valor NULL:
SELECT
employee_id,
employee_name,
salary,
hire_date,
COALESCE(department, 'Unknown') AS department
FROM employees;
Al ejecutar la consulta anterior debería obtener el siguiente resultado:
Los registros duplicados en una tabla de base de datos pueden distorsionar los resultados del análisis. Hemos elegido Employee_id como clave principal en nuestra tabla de base de datos. Por lo tanto, no tendremos registros de empleados repetidos en el employee_data mesa.
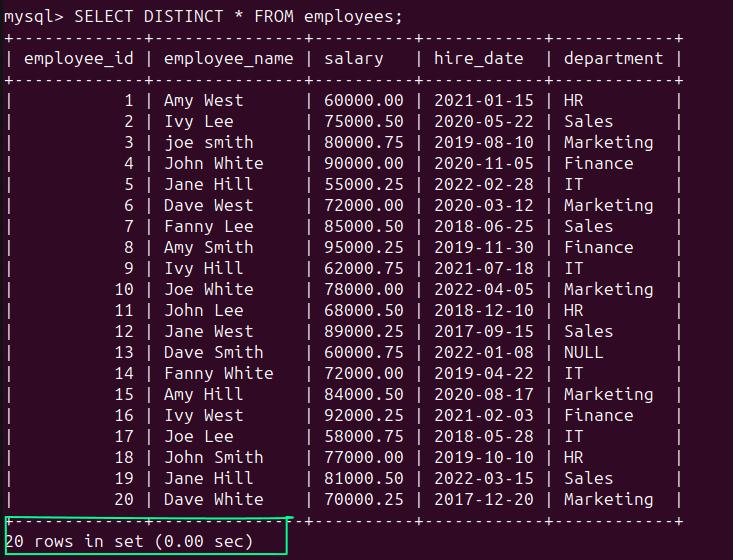
Aún puede usar la instrucción SELECT DISTINCT:
SELECT DISTINCT * FROM employees;
Como era de esperar, el conjunto de resultados contiene los 20 registros:
Si lo observa, la columna 'hire_date' actualmente es VARCHAR y no un tipo de fecha. Para que sea más fácil trabajar con fechas, es útil utilizar el STR_TO_DATE () funcionar así:
SELECT
employee_id,
employee_name,
salary,
STR_TO_DATE(hire_date, '%Y-%m-%d') AS hire_date,
department
FROM employees;
Aquí, solo seleccionamos la columna 'hire_date' entre otras y no realizamos ninguna operación con los valores de fecha. Por lo tanto, el resultado de la consulta debe ser el mismo que el de la consulta anterior.
Pero si desea realizar operaciones como agregar una fecha de compensación a los valores, esta función puede resultar útil.
Los valores atípicos en uno o más campos numéricos pueden sesgar el análisis. Por lo tanto, debemos buscar y eliminar valores atípicos para filtrar los datos que no son relevantes.
Pero decidir qué valores constituyen valores atípicos requiere conocimiento del dominio y datos que utilicen el conocimiento tanto del dominio como de los datos históricos.
En nuestro ejemplo, digamos que sabes qué que la columna "salario" tiene un límite superior de 100000. Por lo tanto, cualquier entrada en la columna "salario" puede ser como máximo 100000. Y las entradas mayores que este valor son valores atípicos.
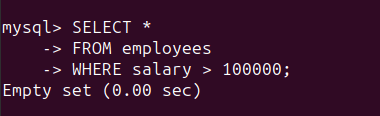
Podemos verificar dichos registros ejecutando la siguiente consulta:
SELECT *
FROM employees
WHERE salary > 100000;
Como se ve, todas las entradas en la columna "salario" son válidas. Entonces el conjunto de resultados está vacío:
Las entradas de datos y el formato inconsistentes son bastante comunes, especialmente en las columnas de fecha y cadena.
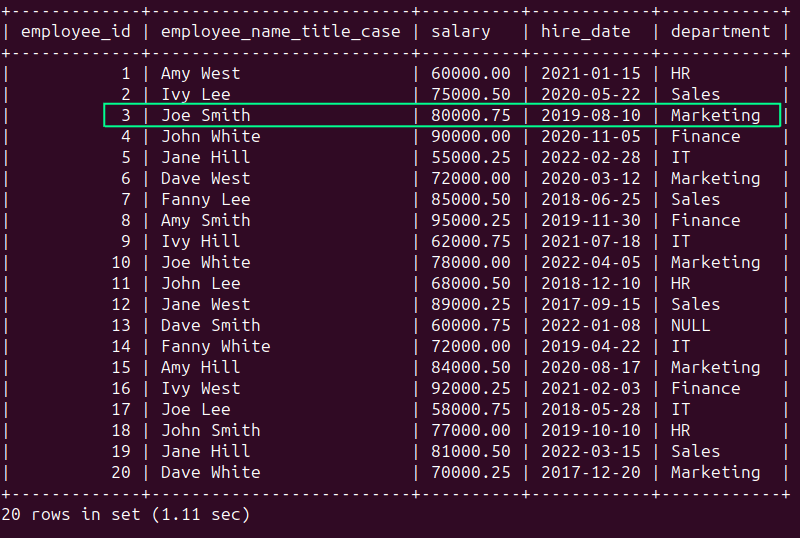
En employees En la tabla, vemos que el registro correspondiente al empleado ‘bob johnson’ no está en el título en mayúsculas y minúsculas.
Pero para mantener la coherencia, seleccionemos todos los nombres formateados en mayúsculas y minúsculas. Tienes que usar el CONCAT () función en conjunto con SUPERIOR() y SUBSTRING () al igual que:
SELECT
employee_id,
CONCAT(
UPPER(SUBSTRING(employee_name, 1, 1)), -- Capitalize the first letter of the first name
LOWER(SUBSTRING(employee_name, 2, LOCATE(' ', employee_name) - 2)), -- Make the rest of the first name lowercase
' ',
UPPER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 1, 1)), -- Capitalize the first letter of the last name
LOWER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 2)) -- Make the rest of the last name lowercase
) AS employee_name_title_case,
salary,
hire_date,
department
FROM employees;
Cuando hablamos de valores atípicos, mencionamos que nos gustaría que el límite superior en la columna "salario" fuera 100000 100000 y consideramos cualquier entrada de salario superior a XNUMX XNUMX como un valor atípico.
Pero también es cierto que no desea ningún valor negativo en la columna "salario". Entonces puede ejecutar la siguiente consulta para validar que todos los registros de empleados contengan valores entre 0 y 100000:
SELECT
employee_id,
employee_name,
salary,
hire_date,
department
FROM employees
WHERE salary 0 OR salary > 100000;
Como se ve, el conjunto de resultados está vacío:

Derivar nuevas columnas no es esencialmente un paso de limpieza de datos. Sin embargo, en la práctica, es posible que necesite utilizar columnas existentes para derivar columnas nuevas que sean más útiles en el análisis.
Por ejemplo, la directriz employees La tabla contiene una columna "fecha_contratación". Un campo más útil es, quizás, una columna "años_de_servicio" que indica cuánto tiempo lleva un empleado en la empresa.
La siguiente consulta encuentra la diferencia entre el año actual y el valor del año en "fecha_contratación" para calcular los "años_de_servicio":
SELECT
employee_id,
employee_name,
salary,
hire_date,
department,
YEAR(CURDATE()) - YEAR(hire_date) AS years_of_service
FROM employees;
Debería ver el siguiente resultado:

Al igual que con otras consultas que hemos ejecutado, esto no modifica la tabla original. Para agregar nuevas columnas a la tabla original, debe tener permisos para ALTERAR la tabla de la base de datos.
Espero que comprenda cómo las tareas de limpieza de datos relevantes pueden mejorar la calidad de los datos y facilitar análisis más relevantes. Ha aprendido a comprobar si faltan valores, registros duplicados, formatos inconsistentes, valores atípicos y más.
Intente crear su propia tabla de base de datos relacional y ejecute algunas consultas para realizar tareas comunes de limpieza de datos. A continuación, aprenda sobre SQL para visualización de datos.
Bala Priya C. es un desarrollador y escritor técnico de la India. Le gusta trabajar en la intersección de matemáticas, programación, ciencia de datos y creación de contenido. Sus áreas de interés y experiencia incluyen DevOps, ciencia de datos y procesamiento de lenguaje natural. ¡Le gusta leer, escribir, codificar y tomar café! Actualmente, está trabajando para aprender y compartir su conocimiento con la comunidad de desarrolladores mediante la creación de tutoriales, guías prácticas, artículos de opinión y más.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/data-cleaning-in-sql-how-to-prepare-messy-data-for-analysis?utm_source=rss&utm_medium=rss&utm_campaign=data-cleaning-in-sql-how-to-prepare-messy-data-for-analysis

