Servicio Amazon OpenSearch recientemente introducido Multi-AZ con modo de espera, una opción de implementación diseñada para brindar a las empresas una disponibilidad mejorada y un rendimiento consistente para cargas de trabajo críticas. Con esta característica, los clústeres administrados pueden alcanzar una disponibilidad del 99.99 % y, al mismo tiempo, seguir siendo resistentes a las fallas de la infraestructura zonal.
En esta publicación, exploramos cómo funcionan la búsqueda y la indexación con Multi-AZ con Standby y profundizamos en los mecanismos subyacentes que contribuyen a su confiabilidad, simplicidad y tolerancia a fallas.
Antecedentes
Multi-AZ con Standby implementa instancias de dominio de OpenSearch Service en tres zonas de disponibilidad, con dos zonas designadas como activas y una como en espera. Esta configuración garantiza un rendimiento constante, incluso en caso de fallas zonales, al mantener la misma capacidad en todas las zonas. Es importante destacar que esta zona de espera sigue un diseño estáticamente estable, eliminando la necesidad de aprovisionamiento de capacidad o movimiento de datos durante fallas.
Durante las operaciones normales, la zona activa maneja el tráfico del coordinador para solicitudes de lectura y escritura, así como el tráfico de consultas de fragmentos. La zona de espera, por otro lado, sólo recibe tráfico de replicación. OpenSearch Service utiliza un protocolo de replicación sincrónica para solicitudes de escritura. Esto permite que el servicio promueva rápidamente una zona en espera al estado activo en caso de una falla (tiempo medio de conmutación por error <= 1 minuto), conocido como conmutación por error zonal. La zona previamente activa pasa al modo de espera y comienzan las operaciones de recuperación para restaurar su estado saludable.
Busque enrutamiento del tráfico y conmutación por error para garantizar una alta disponibilidad
En un dominio del servicio OpenSearch, un coordinador es cualquier nodo que maneja solicitudes HTTP(S), especialmente solicitudes de indexación y búsqueda. En un dominio Multi-AZ con Standby, los nodos de datos en la zona activa actúan como coordinadores para las solicitudes de búsqueda.
Durante la fase de consulta de una solicitud de búsqueda, el coordinador determina los fragmentos que se consultarán y envía una solicitud al nodo de datos que aloja la copia del fragmento. La consulta se ejecuta localmente en cada fragmento y los documentos coincidentes se devuelven al nodo coordinador. El nodo coordinador, que es responsable de enviar la solicitud a los nodos que contienen copias fragmentadas, ejecuta el proceso en dos pasos. Primero, crea un iterador que define el orden en el que se debe consultar a los nodos para obtener una copia de fragmentos para que el tráfico se distribuya uniformemente entre las copias de fragmentos. Posteriormente, la solicitud se envía a los nodos correspondientes.
Para crear una lista ordenada de nodos a los que se les solicitará una copia fragmentada, el nodo coordinador utiliza varios algoritmos. Estos algoritmos incluyen selección por turnos, selección de réplicas adaptativas, enrutamiento de fragmentos basado en preferencias y round-robin ponderado.
Para Multi-AZ con Standby, se utiliza el algoritmo de operación por turnos ponderado para la selección de copias de fragmentos. En este enfoque, a las zonas activas se les asigna un peso de 1 y a la zona en espera se les asigna un peso de 0. Esto garantiza que no se envíe tráfico de lectura a los nodos de datos en la zona de disponibilidad en espera.
Los pesos se almacenan en metadatos del estado del clúster como un objeto JSON:
Como se muestra en la siguiente captura de pantalla, el us-east-1b La región tiene su estatus de zona como StandBy, lo que indica que los nodos de datos en esta zona de disponibilidad están en estado de espera y no reciben solicitudes de búsqueda o indexación del balanceador de carga.

Para mantener operaciones estables, la zona de disponibilidad en espera se rota cada 30 minutos, lo que garantiza que todas las partes de la red estén cubiertas en todas las zonas de disponibilidad. Este enfoque proactivo verifica la disponibilidad de rutas de lectura, mejorando aún más la resiliencia del sistema durante posibles fallas. El siguiente diagrama ilustra esta arquitectura.

En el diagrama anterior, la Zona C tiene un peso de operación por turnos ponderado establecido en cero. Esto garantiza que los nodos de datos en la zona de espera no reciban ningún tráfico de indexación o búsqueda. Cuando el coordinador consulta los nodos de datos en busca de copias fragmentadas, utiliza un peso ponderado por turnos para decidir el orden en el que se consultarán los nodos. Dado que el peso es cero para la zona de disponibilidad en espera, las solicitudes de coordinador no se envían.
En un clúster de OpenSearch Service, las zonas activa y en espera se pueden verificar en cualquier momento utilizando métricas de rotación de zonas de disponibilidad, como se muestra en la siguiente captura de pantalla.
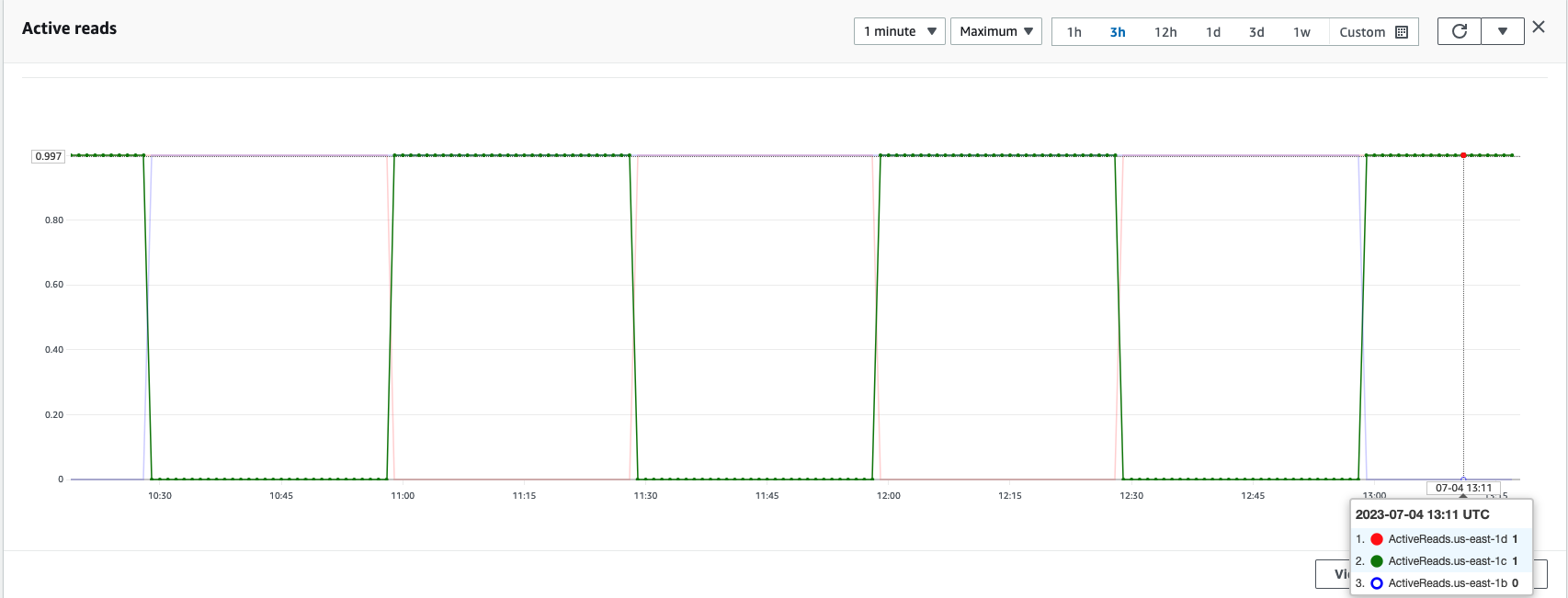
Durante las interrupciones zonales, la zona de disponibilidad en espera cambia sin problemas al modo de falla de apertura para solicitudes de búsqueda. Esto significa que el tráfico de consulta de fragmentos se enruta a todas las zonas de disponibilidad, incluso aquellas en espera, cuando una copia de fragmentos en buen estado no está disponible en la zona de disponibilidad activa. Este enfoque de apertura en caso de fallo protege las solicitudes de búsqueda contra interrupciones durante los fallos, lo que garantiza un servicio continuo. El siguiente diagrama ilustra esta arquitectura.
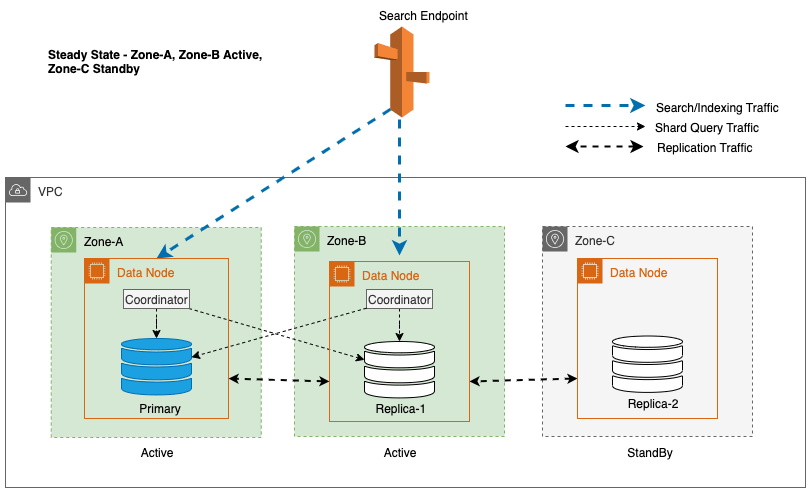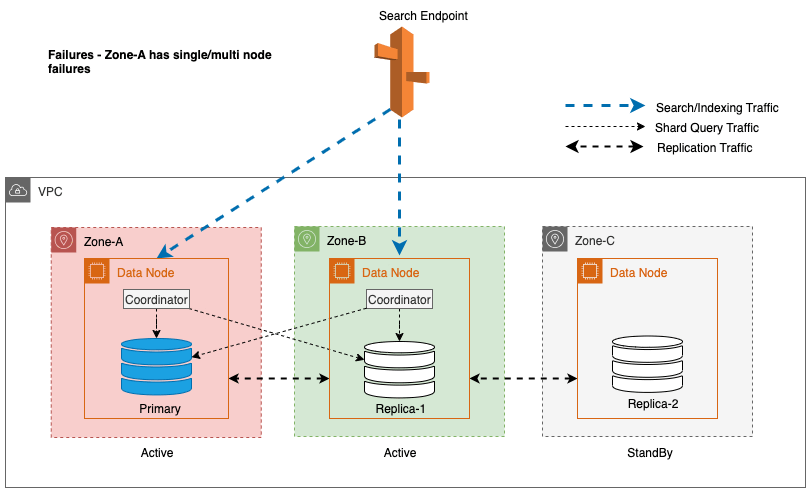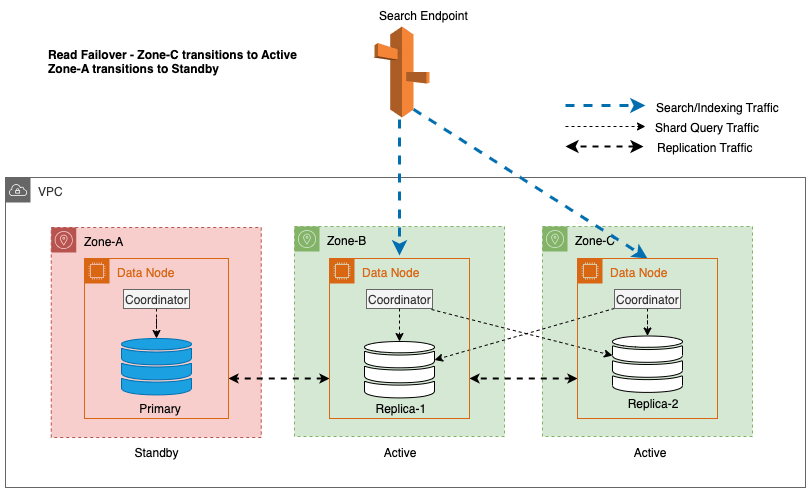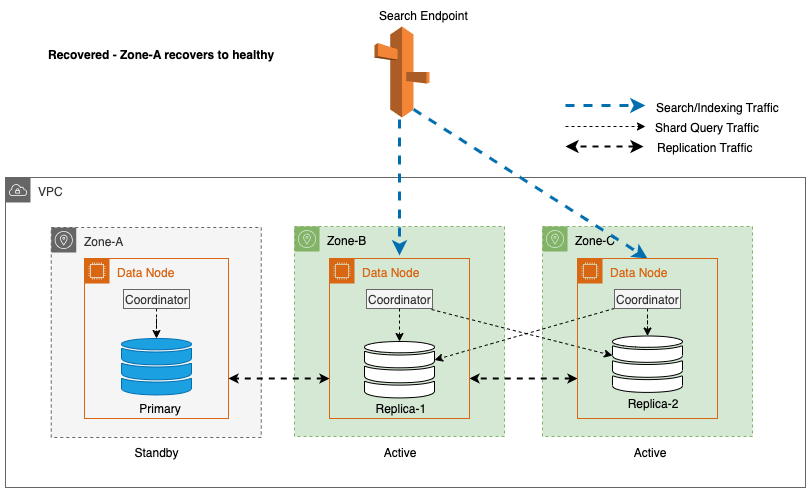
En el diagrama anterior, durante el estado estable, el tráfico de consulta de fragmentos se envía al nodo de datos en las zonas de disponibilidad activas (Zona A y Zona B). Debido a fallas en los nodos en la Zona A, la zona de disponibilidad en espera (Zona C) no se abre para recibir el tráfico de consultas de fragmentos, por lo que no hay ningún impacto en las solicitudes de búsqueda. Finalmente, se detecta que la Zona A no está en buen estado y la conmutación por error de lectura cambia el modo de espera a la Zona A.
Cómo la conmutación por error garantiza una alta disponibilidad durante el deterioro de la escritura
El modelo de replicación del servicio OpenSearch sigue un modelo de respaldo primario, caracterizado por su naturaleza sincrónica, donde es necesario el reconocimiento de todas las copias de fragmentos antes de que se pueda reconocer una solicitud de escritura al usuario. Un inconveniente notable de este modelo de replicación es su susceptibilidad a ralentizaciones en caso de cualquier deterioro en la ruta de escritura. Estos sistemas dependen de un nodo líder activo para identificar fallas o retrasos y luego transmitir esta información a todos los nodos. El tiempo que lleva detectar estos problemas (tiempo medio para detectarlos) y posteriormente resolverlos (tiempo medio para repararlos) determina en gran medida cuánto tiempo funcionará el sistema en un estado deteriorado. Además, cualquier evento de red que afecte las comunicaciones entre zonas puede impedir significativamente las solicitudes de escritura debido a la naturaleza sincrónica de la replicación.
OpenSearch Service utiliza un protocolo de comunicación interno de nodo a nodo para replicar el tráfico de escritura y coordinar las actualizaciones de metadatos a través de un líder elegido. En consecuencia, poner la zona que experimenta tensión en espera no solucionaría eficazmente el problema del deterioro de la escritura.
Conmutación por error de escritura zonal: cortar el tráfico de replicación entre zonas
Para Multi-AZ con Standby, para mitigar posibles problemas de rendimiento causados durante eventos imprevistos como fallas zonales y eventos de red, la conmutación por error de escritura zonal es un enfoque eficaz. Este enfoque implica la eliminación cuidadosa de los nodos en la zona afectada del clúster, cortando efectivamente el tráfico de entrada y salida entre zonas. Al cortar el tráfico de replicación entre zonas, el impacto de las fallas zonales se puede contener dentro de la zona afectada. Esto proporciona una experiencia más predecible para los clientes y garantiza que el sistema siga funcionando de forma fiable.
Conmutación por error de escritura elegante
La orquestación de una conmutación por error de escritura dentro del servicio OpenSearch la lleva a cabo el nodo líder elegido a través de un mecanismo bien definido. Este mecanismo implica un protocolo de consenso para la publicación del estado del clúster, asegurando un acuerdo unánime entre todos los nodos para designar una zona única (en todo momento) para el desmantelamiento. Es importante destacar que los metadatos relacionados con la zona afectada se replican en todos los nodos para garantizar su persistencia, incluso durante un reinicio completo en caso de una interrupción.
Además, el nodo líder garantiza una transición suave y elegante al colocar inicialmente los nodos en las zonas impactadas en espera durante 5 minutos antes de iniciar el cercado de E/S. Este enfoque deliberado evita que cualquier nuevo tráfico de coordinador o tráfico de consulta de fragmentos se dirija a los nodos dentro de la zona afectada. Esto, a su vez, permite que estos nodos completen sus tareas en curso con elegancia y manejen gradualmente cualquier solicitud en vuelo antes de quedar fuera de servicio. El siguiente diagrama ilustra esta arquitectura.
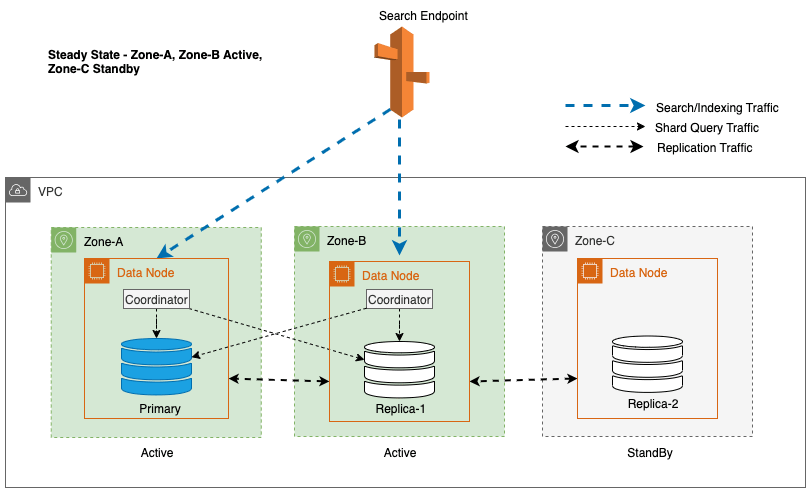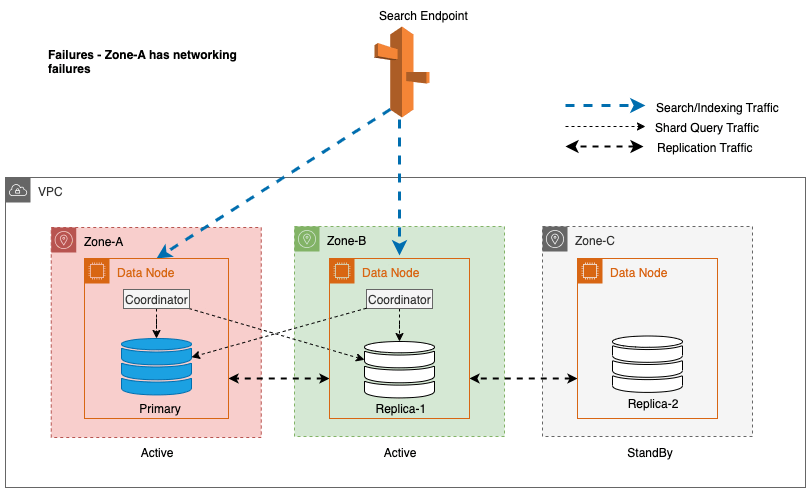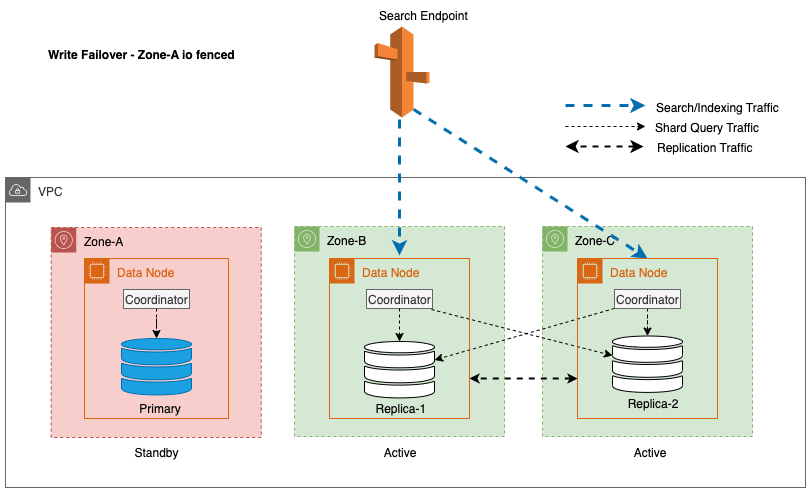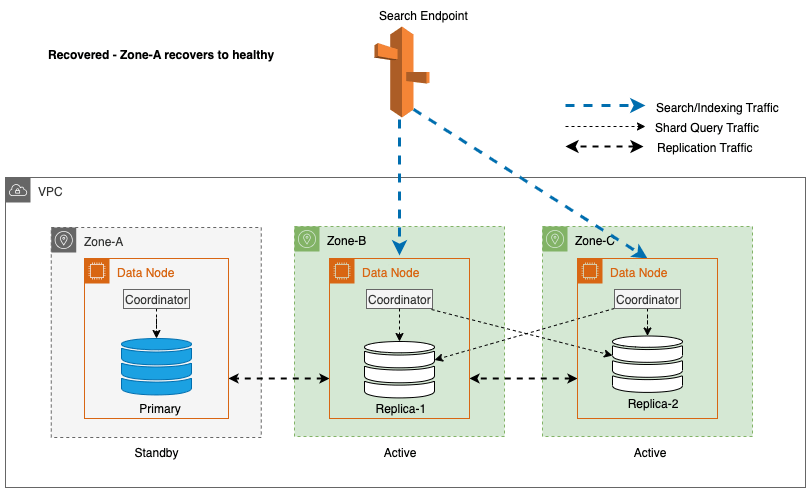
En el proceso de implementación de una conmutación por error de escritura para un nodo líder, OpenSearch Service sigue estos pasos clave:
- Abdicación del líder – Si el nodo líder se encuentra ubicado en una zona programada para conmutación por error de escritura, el sistema garantiza que el nodo líder abandone voluntariamente su función de liderazgo. Esta abdicación se realiza de forma controlada y todo el proceso se entrega a otro nodo elegible, que luego se hace cargo de las acciones requeridas.
- Impedir la reelección del líder que será destituido – Para evitar la reelección de un líder de una zona marcada para conmutación por error de escritura, cuando el nodo líder elegible inicia la acción de conmutación por error de escritura, toma medidas para garantizar que los nodos líderes que serán desmantelados no participen en más elecciones. Esto se logra excluyendo el nodo líder que será desmantelado de la configuración de votación, impidiendo efectivamente que vote durante cualquier fase crítica de la operación del clúster.
Los metadatos relacionados con la zona de conmutación por error de escritura se almacenan dentro del estado del clúster y esta información se publica en todos los nodos del clúster distribuido del servicio OpenSearch de la siguiente manera:
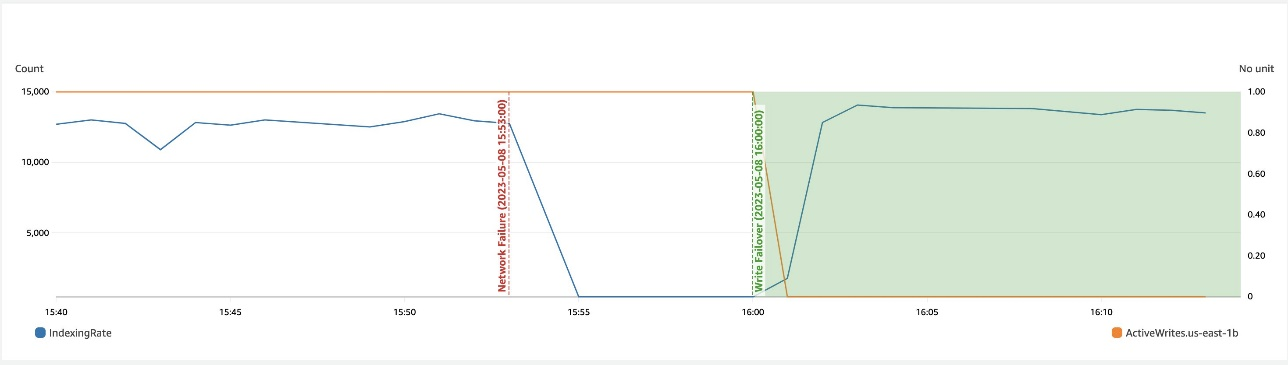
La siguiente captura de pantalla muestra que durante una desaceleración de la red en una zona, la conmutación por error de escritura ayuda a recuperar la disponibilidad.
Recuperación zonal después de la conmutación por error de escritura
El proceso de puesta en servicio zonal desempeña un papel crucial en la fase de recuperación después de una conmutación por error de escritura zonal. Una vez que la zona afectada haya sido restaurada y se considere estable, los nodos que fueron previamente desmantelados volverán a unirse al clúster. Esta nueva puesta en servicio normalmente ocurre dentro de un período de 2 minutos después de que la zona haya sido puesta nuevamente en servicio.
Esto les permite sincronizarse con sus nodos pares e inicia el proceso de recuperación de fragmentos de réplica, restaurando efectivamente el clúster a su estado deseado.
Conclusión
La introducción de OpenSearch Service Multi-AZ con Standby proporciona a las empresas una potente solución para lograr alta disponibilidad y rendimiento constante para cargas de trabajo críticas. Con esta opción de implementación, las empresas pueden mejorar la resiliencia de su infraestructura, simplificar la configuración y administración del clúster y aplicar las mejores prácticas. Con características como selección ponderada de copias de fragmentos por turnos, mecanismos proactivos de conmutación por error y zonas de disponibilidad en espera de apertura fallida, OpenSearch Service Multi-AZ con Standby garantiza una experiencia de búsqueda confiable y eficiente para entornos empresariales exigentes.
Para obtener más información sobre Multi-AZ con Standby, consulte Servicio de Amazon OpenSearch bajo el capó: Multi-AZ con Standby.
Sobre la autora
 Anshu Agarval es un ingeniero de software sénior que trabaja en AWS OpenSearch en Amazon Web Services. Le apasiona resolver problemas relacionados con la construcción de sistemas escalables y altamente confiables.
Anshu Agarval es un ingeniero de software sénior que trabaja en AWS OpenSearch en Amazon Web Services. Le apasiona resolver problemas relacionados con la construcción de sistemas escalables y altamente confiables.
 Rishab Nahata es un ingeniero de software que trabaja en OpenSearch en Amazon Web Services. Le fascina resolver problemas en sistemas distribuidos. Es colaborador activo de OpenSearch.
Rishab Nahata es un ingeniero de software que trabaja en OpenSearch en Amazon Web Services. Le fascina resolver problemas en sistemas distribuidos. Es colaborador activo de OpenSearch.
 Bujtawar Khan es un ingeniero principal que trabaja en Amazon OpenSearch Service. Está interesado en sistemas distribuidos y autónomos. Es un colaborador activo de OpenSearch.
Bujtawar Khan es un ingeniero principal que trabaja en Amazon OpenSearch Service. Está interesado en sistemas distribuidos y autónomos. Es un colaborador activo de OpenSearch.
 Ranjith Ramachandra es un Gerente de ingeniería que trabaja en Amazon OpenSearch Service en Amazon Web Services.
Ranjith Ramachandra es un Gerente de ingeniería que trabaja en Amazon OpenSearch Service en Amazon Web Services.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/

