Análisis de datos de Amazon Kinesis facilita la transformación y el análisis de datos de transmisión en tiempo real.
En esta publicación, analizamos por qué AWS recomienda pasar de Kinesis Data Analytics for SQL Applications a Análisis de datos de Amazon Kinesis para Apache Flink para aprovechar las capacidades avanzadas de transmisión de Apache Flink. También mostramos cómo usar Kinesis Data Analytics Studio para probar y ajustar su análisis antes de implementar sus aplicaciones migradas. Si no tiene Kinesis Data Analytics para aplicaciones SQL, esta publicación aún proporciona antecedentes sobre muchos de los casos de uso que verá en su carrera de análisis de datos y cómo los servicios de Amazon Data Analytics pueden ayudarlo a lograr sus objetivos.
Kinesis Data Analytics para Apache Flink es un servicio de Apache Flink completamente administrado. Solo necesita cargar su aplicación JAR o ejecutable, y AWS administrará la infraestructura y la orquestación de trabajos de Flink. Para simplificar las cosas, Kinesis Data Analytics Studio es un entorno de notebook que usa Apache Flink y le permite consultar flujos de datos y desarrollar consultas SQL o cargas de trabajo de prueba de concepto antes de escalar su aplicación a producción en minutos.
Le recomendamos que utilice Kinesis Data Analytics para Apache Flink o Kinesis Data Analytics Studio en lugar de Kinesis Data Analytics para SQL. Esto se debe a que Kinesis Data Analytics para Apache Flink y Kinesis Data Analytics Studio ofrecen funciones avanzadas de procesamiento de flujo de datos, que incluyen semántica de procesamiento exactamente una vez, ventanas de tiempo de eventos, extensibilidad mediante funciones definidas por el usuario (UDF) e integraciones personalizadas, soporte de lenguaje imperativo, estado de la aplicación, escalado horizontal, soporte para múltiples fuentes de datos y más. Estos son fundamentales para garantizar la precisión, la integridad, la coherencia y la confiabilidad del procesamiento del flujo de datos y no están disponibles con Kinesis Data Analytics for SQL.
Resumen de la solución
Para nuestro caso de uso, usamos varios servicios de AWS para transmitir, ingerir, transformar y analizar datos de sensores automotrices de muestra en tiempo real mediante Kinesis Data Analytics Studio. Kinesis Data Analytics Studio nos permite crear un cuaderno, que es un entorno de desarrollo basado en web. Con los portátiles, obtiene una experiencia de desarrollo interactivo simple combinada con las capacidades avanzadas proporcionadas por Apache Flink. Usos de Kinesis Data Analytics Studio Zepelín apache como el cuaderno, y utiliza Apache Flink como el motor de procesamiento de flujo. Los portátiles Kinesis Data Analytics Studio combinan a la perfección estas tecnologías para hacer que los análisis avanzados de flujos de datos sean accesibles para los desarrolladores de todos los conjuntos de habilidades. Las computadoras portátiles se aprovisionan rápidamente y le brindan una forma de ver y analizar instantáneamente sus datos de transmisión. Apache Zeppelin proporciona a sus portátiles Studio un conjunto completo de herramientas de análisis, incluidas las siguientes:
- Visualización de datos
- Exportación de datos a archivos
- Controlar el formato de salida para facilitar el análisis
- Capacidad de convertir la notebook en una aplicación de producción escalable
A diferencia de Kinesis Data Analytics para aplicaciones SQL, Kinesis Data Analytics para Apache Flink agrega la siguiendo el soporte de SQL:
- Unir datos de flujo entre varios flujos de datos de Kinesis, o entre un flujo de datos de Kinesis y un Streaming administrado por Amazon para Apache Kafka (Amazon MSK) tema
- Visualización en tiempo real de datos transformados en un flujo de datos
- Usando scripts Python o programas Scala dentro de la misma aplicación
- Cambio de compensaciones de la capa de transmisión
Otro beneficio de Kinesis Data Analytics para Apache Flink es la escalabilidad mejorada de la solución una vez implementada, porque puede escalar los recursos subyacentes para satisfacer la demanda. En Kinesis Data Analytics for SQL Applications, el escalado se realiza agregando más bombas para convencer a la aplicación de que agregue más recursos.
En nuestra solución, creamos un cuaderno para acceder a datos de sensores automotrices, enriquecer los datos y enviar la salida enriquecida del cuaderno Kinesis Data Analytics Studio a un Manguera de bomberos de datos de Amazon Kinesis flujo de entrega para la entrega a un Servicio de almacenamiento simple de Amazon (Amazon S3) lago de datos. Esta canalización podría utilizarse además para enviar datos a Servicio Amazon OpenSearch u otros objetivos para procesamiento y visualización adicionales.

Kinesis Data Analytics para aplicaciones SQL frente a Kinesis Data Analytics para Apache Flink
En nuestro ejemplo, realizamos las siguientes acciones en los datos de transmisión:
- Conéctese a un Secuencias de datos de Amazon Kinesis flujo de datos.
- Ver los datos de la transmisión.
- Transformar y enriquecer los datos.
- Manipular los datos con Python.
- Vuelva a transmitir los datos a un flujo de entrega de Firehose.
Para comparar Kinesis Data Analytics for SQL Applications con Kinesis Data Analytics for Apache Flink, analicemos primero cómo funciona Kinesis Data Analytics for SQL Applications.
En la raíz de una aplicación de Kinesis Data Analytics para SQL se encuentra el concepto de una secuencia en la aplicación. Puede pensar en la transmisión en la aplicación como una tabla que contiene los datos de transmisión para que pueda realizar acciones en ella. El flujo en la aplicación se asigna a una fuente de transmisión, como un flujo de datos de Kinesis. Para obtener datos en el flujo en la aplicación, primero configure una fuente en la consola de administración para su aplicación Kinesis Data Analytics for SQL. Luego, cree una bomba que lea los datos del flujo de origen y los coloque en la tabla. La consulta de la bomba se ejecuta de forma continua y alimenta los datos de origen en el flujo en la aplicación. Puede crear múltiples bombas de múltiples fuentes para alimentar el flujo en la aplicación. Luego, las consultas se ejecutan en el flujo dentro de la aplicación y los resultados se pueden interpretar o enviar a otros destinos para su posterior procesamiento o almacenamiento.
El siguiente SQL demuestra cómo configurar un flujo y una bomba en la aplicación:
CREATE OR REPLACE STREAM "TEMPSTREAM" ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)); CREATE OR REPLACE PUMP "SAMPLEPUMP" AS INSERT INTO "TEMPSTREAM" ("column1", "column2", "column3") SELECT STREAM inputcolumn1, inputcolumn2, inputcolumn3
FROM "INPUTSTREAM";Los datos se pueden leer desde la secuencia en la aplicación mediante una consulta SQL SELECT:
SELECT *
FROM "TEMPSTREAM"Al crear la misma configuración en Kinesis Data Analytics Studio, utiliza el entorno subyacente de Apache Flink para conectarse a la fuente de transmisión y crea la transmisión de datos en una declaración mediante un conector. El siguiente ejemplo muestra la conexión a la misma fuente que usamos antes, pero usando Apache Flink:
CREATE TABLE `MY_TABLE` ( "column1" BIGINT NOT NULL, "column2" INTEGER, "column3" VARCHAR(64)
) WITH ( 'connector' = 'kinesis', 'stream' = sample-kinesis-stream', 'aws.region' = 'aws-kinesis-region', 'scan.stream.initpos' = 'LATEST', 'format' = 'json' );MY_TABLE ahora es un flujo de datos que recibirá continuamente los datos de nuestro flujo de datos de Kinesis de muestra. Se puede consultar usando una instrucción SQL SELECT:
SELECT column1, column2, column3
FROM MY_TABLE;Aunque Kinesis Data Analytics for SQL Applications utiliza un subconjunto del estándar SQL:2008 con extensiones para habilitar operaciones en transmisión de datos, Soporte SQL de Apache Flink está basado en Calcita Apache, que implementa el estándar SQL.
También es importante mencionar que Kinesis Data Analytics Studio es compatible con PyFlink y Scala junto con SQL dentro del mismo cuaderno. Esto le permite realizar métodos programáticos complejos en sus datos de transmisión que no son posibles con SQL.
Requisitos previos
Durante este ejercicio, configuramos varios recursos de AWS y realizamos consultas de análisis. Para seguir, necesita una cuenta de AWS con acceso de administrador. Si aún no tiene una cuenta de AWS con acceso de administrador, crear una ahora. Los servicios descritos en esta publicación pueden generar cargos en su cuenta de AWS. Asegúrese de seguir las instrucciones de limpieza al final de esta publicación.
Configurar transmisión de datos
En el dominio de la transmisión, a menudo tenemos la tarea de explorar, transformar y enriquecer los datos provenientes de los sensores de Internet de las cosas (IoT). Para generar los datos del sensor en tiempo real, empleamos el Simulador de dispositivos AWS IoT. Este simulador se ejecuta dentro de su cuenta de AWS y proporciona una interfaz web que permite a los usuarios lanzar flotas de dispositivos virtualmente conectados desde una plantilla definida por el usuario y luego simularlos para publicar datos a intervalos regulares para Núcleo de AWS IoT. Esto significa que podemos construir una flota virtual de dispositivos para generar datos de muestra para este ejercicio.
Implementamos el IoT Device Simulator usando lo siguiente Amazon CloudFront plantilla. Maneja la creación de todos los recursos necesarios en su cuenta.
- En Especificar detalles de la pila página, asigne un nombre a su pila de soluciones.
- under parámetros, revise los parámetros de esta plantilla de solución y modifíquelos según sea necesario.
- Correo electrónico del usuario, ingrese un correo electrónico válido para recibir un enlace y una contraseña para iniciar sesión en la interfaz de usuario de IoT Device Simulator.
- Elige Siguiente.
- En Configurar opciones de pila página, elige Siguiente.
- En Revisar página, revise y confirme la configuración. Seleccione las casillas de verificación reconociendo que la plantilla crea Gestión de identidades y accesos de AWS (IAM) recursos.
- Elige Crear pila.
La pila tarda unos 10 minutos en instalarse.
- Cuando reciba su correo electrónico de invitación, elija el enlace de CloudFront e inicie sesión en IoT Device Simulator con las credenciales proporcionadas en el correo electrónico.
La solución contiene una demostración automotriz preconstruida que podemos usar para comenzar a entregar datos de sensores rápidamente a AWS.
- En Tipo de dispositivo página, elige Crear tipo de dispositivo.
- Elige Demostración automotriz.
- La carga útil se completa automáticamente. Ingrese un nombre para su dispositivo e ingrese
automotive-topiccomo el tema.
- Elige Guardar.
Ahora creamos una simulación.
- En Simulaciones página, elige Crear simulación.
- Tipo de simulación, escoger Demostración automotriz.
- Seleccione un tipo de dispositivo, elige el dispositivo de demostración que creaste.
- Intervalo de transmisión de datos y Duración de la transmisión de datos, introduzca los valores deseados.
Puede ingresar cualquier valor que desee, pero use al menos 10 dispositivos que transmitan cada 10 segundos. Querrá establecer la duración de la transmisión de datos en unos pocos minutos, o deberá reiniciar su simulación varias veces durante el laboratorio.
- Elige Guardar.

Ahora podemos ejecutar la simulación.
- En Simulaciones página, seleccione la simulación deseada y elija Iniciar simulaciones.
Alternativamente, elija Ver junto a la simulación que desea ejecutar, luego elija Inicio para ejecutar la simulación.
- Para ver la simulación, seleccione Ver junto a la simulación que desea ver.
Si la simulación se está ejecutando, puede ver un mapa con las ubicaciones de los dispositivos y hasta 100 de los mensajes más recientes enviados al tema de IoT.
Ahora podemos verificar que nuestro simulador envíe los datos del sensor a AWS IoT Core.
- Navegue a la consola de AWS IoT Core.
Asegúrese de estar en la misma región en la que implementó su IoT Device Simulator.
- En el panel de navegación, elija Cliente de prueba MQTT.
- Ingrese al filtro de tema
automotive-topicy elige Suscríbete.
Siempre que tenga la simulación en ejecución, se mostrarán los mensajes que se envían al tema de IoT.

Finalmente, podemos establecer una regla para enrutar los mensajes de IoT a un flujo de datos de Kinesis. Esta transmisión proporcionará nuestros datos de origen para el cuaderno de Kinesis Data Analytics Studio.
- En la consola de AWS IoT Core, elija Enrutamiento de mensajes y Reglas.
- Introduzca un nombre para la regla, como
automotive_route_kinesis, A continuación, elija Siguiente.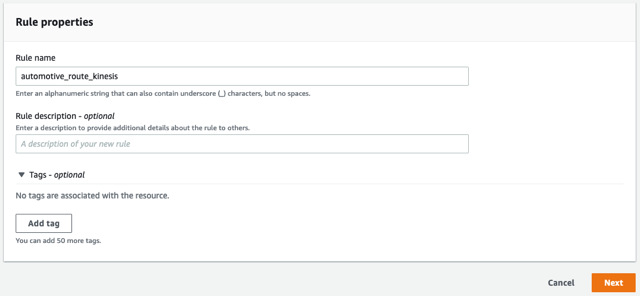
- Proporcione la siguiente instrucción SQL. Este SQL seleccionará todas las columnas de mensajes del
automotive-topicel IoT Device Simulator está publicando:
- Elige Siguiente.
- under Acciones de regla, seleccione Transmisión de Kinesis como fuente.
- Elige Crear nueva transmisión de Kinesis.
Esto abre una nueva ventana.
- Nombre del flujo de datos, introduzca
automotive-data.
Utilizamos un flujo aprovisionado para este ejercicio.
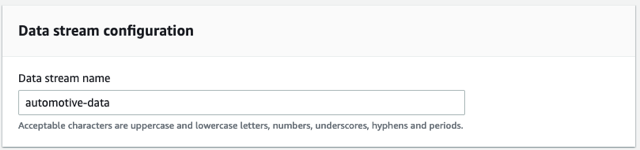
- Elige Crear flujo de datos.
Ahora puede cerrar esta ventana y volver a la consola de AWS IoT Core.
- Elija el botón Actualizar junto a Nombre de la transmisióny elija el
automotive-dataarroyo.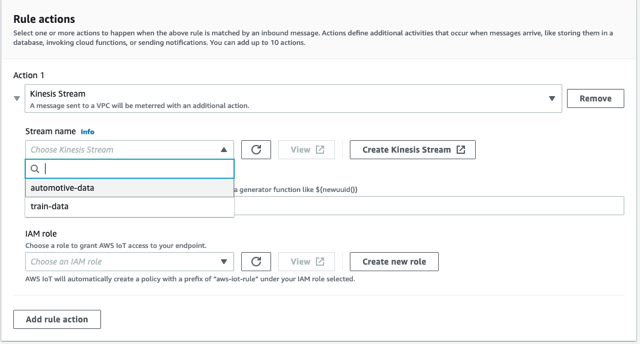
- Elige Crear nuevo rol y nombra el papel
automotive-role. - Elige Siguiente.
- Revise las propiedades de la regla y elija Crear.
La regla comienza a enrutar datos inmediatamente.
Configurar Kinesis Data Analytics Studio
Ahora que tenemos nuestra transmisión de datos a través de AWS IoT Core y en un flujo de datos de Kinesis, podemos crear nuestro cuaderno de Kinesis Data Analytics Studio.
- En la consola de Amazon Kinesis, elija Aplicaciones de análisis en el panel de navegación.
- En creativo pestaña, elegir Crear libreta de Studio.
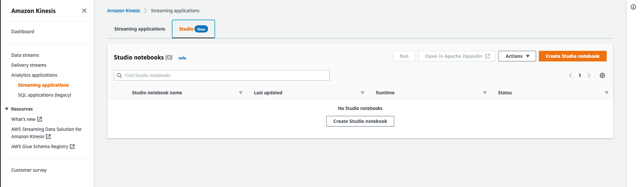
- Abandonar Creación rápida con código de muestra seleccionado.
- Nombra el cuaderno
automotive-data-notebook.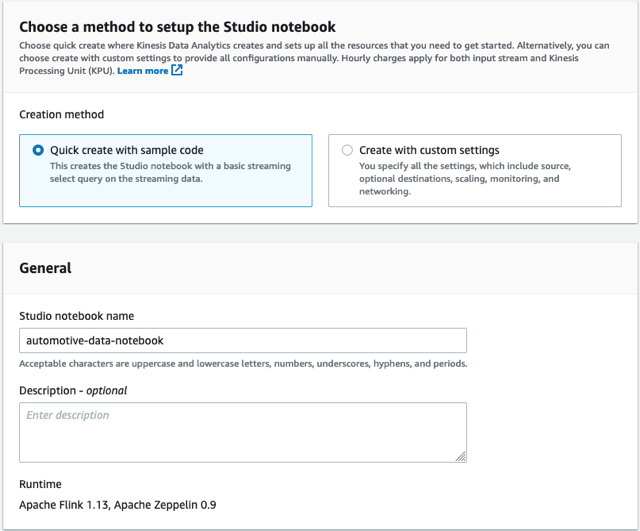
- Elige Crear para crear un nuevo Pegamento AWS base de datos en una nueva ventana.
- Elige Agregar base de datos.

- Nombra la base de datos
automotive-notebook-glue. - Elige Crear.
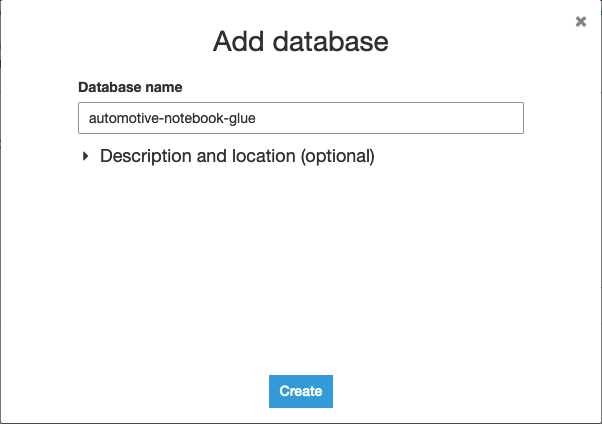
- Volver a la Crear libreta de Studio .
- Elija actualizar y elija su nueva base de datos de AWS Glue.
- Elige Crear libreta de Studio.

- Para iniciar el cuaderno de Studio, elija Ejecutar y confirma.

- Una vez que el cuaderno se esté ejecutando, elija el cuaderno y elija Abrir en Apache Zeppelin.
- Elige Nota de importación.
- Elige Agregar desde URL.

- Ingrese la siguiente URL:
https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/BDB-2461/auto-notebook.ipynb. - Elige Importar nota.

- Abre la nueva nota.
Realizar análisis de flujo
En una aplicación de Kinesis Data Analytics for SQL, agregamos nuestro curso de transmisión a través de la consola de administración y luego definimos una transmisión en la aplicación y bombeamos para transmitir datos desde nuestra transmisión de datos de Kinesis. El flujo en la aplicación funciona como una tabla para contener los datos y ponerlos a disposición para que los consultemos. La bomba toma los datos de nuestra fuente y los transmite a nuestro flujo en la aplicación. Luego, las consultas pueden ejecutarse contra la secuencia en la aplicación usando SQL, tal como consultaríamos cualquier tabla SQL. Ver el siguiente código:
CREATE OR REPLACE STREAM "AUTOSTREAM" ( `trip_id` CHAR(36), `VIN` CHAR(17), `brake` FLOAT, `steeringWheelAngle` FLOAT, `torqueAtTransmission` FLOAT, `engineSpeed` FLOAT, `vehicleSpeed` FLOAT, `acceleration` FLOAT, `parkingBrakeStatus` BOOLEAN, `brakePedalStatus` BOOLEAN, `transmissionGearPosition` VARCHAR(10), `gearLeverPosition` VARCHAR(10), `odometer` FLOAT, `ignitionStatus` VARCHAR(4), `fuelLevel` FLOAT, `fuelConsumedSinceRestart` FLOAT, `oilTemp` FLOAT, `location` VARCHAR(100), `timestamp` TIMESTAMP(3)); CREATE OR REPLACE PUMP "MYPUMP" AS INSERT INTO "AUTOSTREAM" ("trip_id", "VIN", "brake", "steeringWheelAngle", "torqueAtTransmission", "engineSpeed", "vehicleSpeed", "acceleration", "parkingBrakeStatus", "brakePedalStatus", "transmissionGearPosition", "gearLeverPosition", "odometer", "ignitionStatus", "fuelLevel", "fuelConsumedSinceRestart", "oilTemp", "location", "timestamp")
SELECT VIN, brake, steeringWheelAngle, torqueAtTransmission, engineSpeed, vehicleSpeed, acceleration, parkingBrakeStatus, brakePedalStatus, transmissionGearPosition, gearLeverPosition, odometer, ignitionStatus, fuelLevel, fuelConsumedSinceRestart, oilTemp, location, timestamp
FROM "INPUT_STREAM"
Para migrar un flujo y una bomba en la aplicación de nuestra aplicación Kinesis Data Analytics for SQL a Kinesis Data Analytics Studio, convertimos esto en una declaración CREATE única eliminando la definición de la bomba y definiendo un kinesis conector El primer párrafo del cuaderno Zeppelin establece un conector que se presenta como una tabla. Podemos definir columnas para todos los elementos del mensaje entrante o un subconjunto.

Ejecute la declaración y se generará un resultado de éxito en su cuaderno. Ahora podemos consultar esta tabla usando SQL, o podemos realizar operaciones programáticas con estos datos usando PyFlink o Scala.
Antes de realizar análisis en tiempo real en los datos de transmisión, veamos cómo están formateados actualmente los datos. Para hacer esto, ejecutamos una consulta Flink SQL simple en la tabla que acabamos de crear. El SQL que se usa en nuestra aplicación de transmisión es idéntico al que se usa en una aplicación de SQL.

Tenga en cuenta que si no ve registros después de unos segundos, asegúrese de que su IoT Device Simulator aún se esté ejecutando.
Si también está ejecutando Kinesis Data Analytics para código SQL, es posible que vea un conjunto de resultados ligeramente diferente. Este es otro diferenciador clave en Kinesis Data Analytics para Apache Flink, porque este último tiene el concepto de entrega exactamente una vez. Si esta aplicación se implementa en producción y se reinicia o si se producen acciones de escalado, Kinesis Data Analytics para Apache Flink garantiza que solo reciba cada mensaje una vez, mientras que en una aplicación de Kinesis Data Analytics para SQL, debe seguir procesando el flujo entrante para garantizar ignoras los mensajes repetidos que podrían afectar tus resultados.
Puede detener el párrafo actual eligiendo el icono de pausa. Es posible que vea un error en su cuaderno cuando detiene la consulta, pero puede ignorarlo. Solo te está avisando que el proceso fue cancelado.

Flink SQL implementa el estándar SQL y proporciona una manera fácil de realizar cálculos en los datos de flujo tal como lo haría al consultar una tabla de base de datos. Una tarea común mientras se enriquecen los datos es crear un nuevo campo para almacenar un cálculo o una conversión (como de Fahrenheit a Celsius), o crear nuevos datos para proporcionar consultas más simples o visualizaciones mejoradas en sentido descendente. Ejecute el siguiente párrafo para ver cómo podemos agregar un valor booleano llamado accelerating, que podemos usar fácilmente en nuestro fregadero para saber si un automóvil estaba acelerando en ese momento en el momento en que se leyó el sensor. El proceso aquí no difiere entre Kinesis Data Analytics for SQL y Kinesis Data Analytics for Apache Flink.

Puede detener la ejecución del párrafo cuando haya inspeccionado la nueva columna, comparando nuestro nuevo valor booleano con el FLOAT acceleration columna.
Los datos que se envían desde un sensor suelen ser compactos para mejorar la latencia y el rendimiento. Poder enriquecer el flujo de datos con datos externos y enriquecer el flujo, como información adicional del vehículo o datos meteorológicos actuales, puede ser muy útil. En este ejemplo, supongamos que queremos traer datos actualmente almacenados en un CSV en Amazon S3 y agregar una columna llamada color que refleje la banda de velocidad actual del motor.
Apache Flink SQL proporciona varios conectores de fuente para los servicios de AWS y otras fuentes. Crear una nueva tabla como lo hicimos en nuestro primer párrafo, pero en su lugar, usar el conector del sistema de archivos le permite a Flink conectarse directamente a Amazon S3 y leer nuestros datos de origen. Anteriormente, en Kinesis Data Analytics for SQL Applications, no podía agregar nuevas referencias en línea. En cambio, tu datos de referencia S3 definidos y lo agregó a la configuración de su aplicación, que luego podría usar como referencia en un SQL JOIN.
NOTA: Si no está utilizando la región us-east-1, puede descarga el csv y coloque el objeto en su propio cubo S3. Haga referencia al archivo csv como s3a://<bucket-name>/<key-name>

Sobre la base de la última consulta, el siguiente párrafo realiza un SQL JOIN en nuestros datos actuales y la nueva tabla de origen de búsqueda que creamos.

Ahora que tenemos un flujo de datos enriquecido, volvemos a transmitir estos datos. En un escenario del mundo real, tenemos muchas opciones sobre qué hacer con nuestros datos, como enviar los datos a un lago de datos S3, otro flujo de datos de Kinesis para un análisis más detallado o almacenar los datos en OpenSearch Service para su visualización. Para simplificar, enviamos los datos a Kinesis Data Firehose, que transmite los datos a un depósito S3 que actúa como nuestro lago de datos.
Kinesis Data Firehose puede transmitir datos a Amazon S3, OpenSearch Service, Desplazamiento al rojo de Amazon almacenes de datos y Splunk con solo unos pocos clics.
Crear el flujo de entrega de Kinesis Data Firehose
Para crear nuestro flujo de entrega, complete los siguientes pasos:
- En la consola de Kinesis Data Firehose, elija Crear flujo de entrega.
- Elige PUT directa para la fuente de corriente y Amazon S3 como el objetivo

- Asigne a su flujo de entrega el nombre de manguera contra incendios automotriz.

- under Configuración de destino, cree un depósito nuevo o use un depósito existente.
- Tome nota de la URL del depósito de S3.
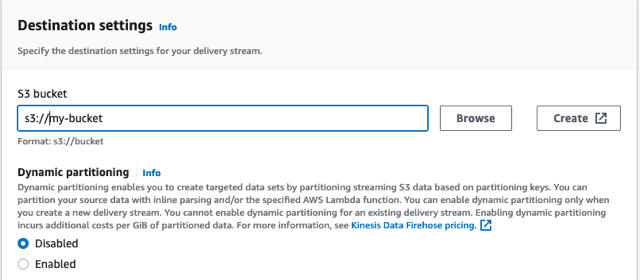
- Elige Crear flujo de entrega.
La secuencia tarda unos segundos en crearse.
- Vuelva a la consola de Kinesis Data Analytics y elija Aplicaciones de transmisión.
- En creativo y elija su notebook Studio.

- Elija el enlace debajo Rol de IAM.

- En la ventana de IAM, seleccione Agregar permisos y Adjuntar políticas.
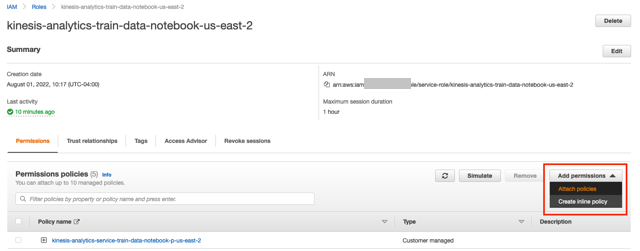
- Busque y seleccione AmazonKinesisFullAccess y CloudWatchFullAccess, luego elija Adjuntar política.
- Puede volver a su cuaderno Zeppelin.
Transmita datos a Kinesis Data Firehose
A partir de Apache Flink v1.15, la creación del conector para el flujo de entrega de Firehose funciona de manera similar a la creación de un conector para cualquier flujo de datos de Kinesis. Tenga en cuenta que hay dos diferencias: el conector es firehose, y el atributo de flujo se convierte en delivery-stream.

Después de crear el conector, podemos escribir en el conector como cualquier tabla SQL.

Para validar que estamos recibiendo datos a través del flujo de entrega, abra la consola de Amazon S3 y confirme que ve los archivos que se están creando. Abra el archivo para inspeccionar los nuevos datos.
En Kinesis Data Analytics for SQL Applications, habríamos creado un nuevo destino en el panel de la aplicación SQL. Para migrar un destino existente, agrega una instrucción SQL a su cuaderno que define el nuevo destino directamente en el código. Puede continuar escribiendo en el nuevo destino como lo hubiera hecho con un INSERTAR mientras hace referencia al nuevo nombre de la tabla.
Datos de tiempo
Otra operación común que puede realizar en los cuadernos de Kinesis Data Analytics Studio es la agregación durante un período de tiempo. Este tipo de datos se puede usar para enviar a otro flujo de datos de Kinesis para identificar anomalías, enviar alertas o almacenarse para su posterior procesamiento. El siguiente párrafo contiene una consulta SQL que utiliza una ventana de cambio y agrega el combustible total consumido por la flota automotriz durante períodos de 30 segundos. Al igual que nuestro último ejemplo, podríamos conectarnos a otro flujo de datos e insertar estos datos para su posterior análisis.

Scala y PyFlink
Hay momentos en que una función que realizaría en su flujo de datos está mejor escrita en un lenguaje de programación en lugar de SQL, tanto por simplicidad como por mantenimiento. Algunos ejemplos incluyen cálculos complejos que las funciones de SQL no admiten de forma nativa, ciertas manipulaciones de cadenas, la división de datos en varios flujos y la interacción con otros servicios de AWS (como la traducción de texto o el análisis de opiniones). Kinesis Data Analytics para Apache Flink tiene la capacidad de usar múltiples Intérpretes de Flink dentro del cuaderno Zeppelin, que no está disponible en Kinesis Data Analytics for SQL Applications.
Si ha estado prestando mucha atención a nuestros datos, verá que el campo de ubicación es una cadena JSON. En Kinesis Data Analytics for SQL, podríamos usar funciones de cadena y definir un Función SQL y separe la cadena JSON. Este es un enfoque frágil que depende de la estabilidad de los datos del mensaje, pero podría mejorarse con varias funciones de SQL. La sintaxis para crear una función en Kinesis Data Analytics for SQL sigue este patrón:
CREATE FUNCTION ''<function_name>'' ( ''<parameter_list>'' ) RETURNS ''<data type>'' LANGUAGE SQL [ SPECIFIC ''<specific_function_name>'' | [NOT] DETERMINISTIC ] CONTAINS SQL [ READS SQL DATA ] [ MODIFIES SQL DATA ] [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ] RETURN ''<SQL-defined function body>''
En Kinesis Data Analytics para Apache Flink, AWS actualizó recientemente el entorno de Apache Flink a la versión 1.15, que amplía la tabla SQL de Apache Flink a añadir funciones JSON que son similares a la sintaxis de JSON Path. Esto nos permite consultar la cadena JSON directamente en nuestro SQL. Ver el siguiente código:
%flink.ssql(type=update)
SELECT JSON_STRING(location, ‘$.latitude) AS latitude,
JSON_STRING(location, ‘$.longitude) AS longitude
FROM my_tableAlternativamente, y requerido antes de Apache Flink v1.15, podemos usar Scala o PyFlink en nuestro cuaderno para convertir el campo y volver a transmitir los datos. Ambos lenguajes proporcionan un manejo robusto de cadenas JSON.
El siguiente código PyFlink define dos funciones definidas por el usuario, que extraen la latitud y longitud del campo de ubicación de nuestro mensaje. Estas UDF se pueden invocar desde el uso de Flink SQL. Hacemos referencia a la variable de entorno st_env. PyFlink crea seis variables para usted en su cuaderno Zeppelin. Zeppelin también expone una contexto para ti como la variable z.


Los errores también pueden ocurrir cuando los mensajes contienen datos inesperados. Kinesis Data Analytics for SQL Applications proporciona un flujo de errores en la aplicación. Estos errores se pueden procesar por separado y volver a transmitir o descartar. Con PyFlink en las aplicaciones de Streaming de Kinesis Data Analytics, puede escribir estrategias complejas de manejo de errores e inmediatamente recuperar y continuar procesando los datos. Cuando la cadena JSON se pasa a la UDF, puede tener un formato incorrecto, estar incompleta o vacía. Al detectar el error en la UDF, Python siempre devolverá un valor incluso si se hubiera producido un error.
El siguiente código de ejemplo muestra otro fragmento de PyFlink que realiza un cálculo de división en dos campos. Si se encuentra un error de división por cero, proporciona un valor predeterminado para que la transmisión pueda continuar procesando el mensaje.
%flink.pyflink
@udf(input_types=[DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def DivideByZero(price): try: price / 0 except: return -1
st_env.register_function("DivideByZero", DivideByZero)
Próximos pasos
Construir una canalización como lo hemos hecho en esta publicación nos brinda la base para probar servicios adicionales en AWS. Lo animo a continuar con su aprendizaje de análisis de transmisión antes de desmantelar las transmisiones que creó. Considera lo siguiente:
Limpiar
Para limpiar los servicios creados en este ejercicio, complete los siguientes pasos:
- Navegue a la consola de CloudFormation y elimine la pila de IoT Device Simulator.
- En la consola de AWS IoT Core, elija Reglas y enrutamiento de mensajes y elimine la regla.
automotive_route_kinesis. - Eliminar el flujo de datos de Kinesis
automotive-dataen la consola de Kinesis Data Stream. - Eliminar el rol de IAM
automotive-roleen la Consola de IAM. - En la consola de AWS Glue, elimine el
automotive-notebook-gluebase de datos. - Eliminar el cuaderno de Kinesis Data Analytics Studio
automotive-data-notebook. - Eliminar el flujo de entrega de Firehose
automotive-firehose.
Conclusión
Gracias por seguir este tutorial sobre Kinesis Data Analytics Studio. Si actualmente utiliza una aplicación SQL heredada de Kinesis Data Analytics Studio, le recomiendo que se comunique con su administrador técnico de cuentas o arquitecto de soluciones de AWS y analice la migración a Kinesis Data Analytics Studio. Puedes continuar tu camino de aprendizaje en nuestro Guía para desarrolladores de Amazon Kinesis Data Streamsy accede a nuestro ejemplos de código en GitHub.
Sobre la autora
 Nicolás Tunney es arquitecto de soluciones de socios para el sector público mundial en AWS. Trabaja con socios globales de SI para desarrollar arquitecturas en AWS para clientes en los sectores de gobierno, atención médica sin fines de lucro, servicios públicos y educación.
Nicolás Tunney es arquitecto de soluciones de socios para el sector público mundial en AWS. Trabaja con socios globales de SI para desarrollar arquitecturas en AWS para clientes en los sectores de gobierno, atención médica sin fines de lucro, servicios públicos y educación.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/migrate-from-amazon-kinesis-data-analytics-for-sql-applications-to-amazon-kinesis-data-analytics-studio/

