A pesar de la adopción aparentemente imparable de los LLM en todas las industrias, son un componente de un ecosistema tecnológico más amplio que está impulsando la nueva ola de IA. Muchos casos de uso de IA conversacional requieren LLM como Llama 2, Flan T5 y Bloom para responder a las consultas de los usuarios. Estos modelos se basan en conocimientos paramétricos para responder preguntas. El modelo aprende este conocimiento durante el entrenamiento y lo codifica en los parámetros del modelo. Para actualizar este conocimiento, debemos volver a capacitar al LLM, lo que requiere mucho tiempo y dinero.
Afortunadamente, también podemos utilizar el conocimiento fuente para informar a nuestros LLM. El conocimiento fuente es información que se introduce en el LLM a través de un mensaje de entrada. Un enfoque popular para proporcionar conocimiento fuente es la generación aumentada de recuperación (RAG). Al utilizar RAG, recuperamos información relevante de una fuente de datos externa y la introducimos en el LLM.
En esta publicación de blog, exploraremos cómo implementar LLM como Llama-2 usando Amazon Sagemaker JumpStart y mantener nuestros LLM actualizados con información relevante a través de Retrieval Augmented Generation (RAG) usando la base de datos vectorial Pinecone para prevenir las alucinaciones por IA. .
Recuperación de generación aumentada (RAG) en Amazon SageMaker
Pinecone manejará el componente de recuperación de RAG, pero necesita dos componentes críticos más: algún lugar para ejecutar la inferencia LLM y algún lugar para ejecutar el modelo de incrustación.
Amazon SageMaker Studio es un entorno de desarrollo integrado (IDE) que proporciona una única interfaz visual basada en web donde puede acceder a herramientas diseñadas específicamente para realizar todo el desarrollo de aprendizaje automático (ML). Proporciona SageMaker JumpStart, que es un centro de modelos donde los usuarios pueden ubicar, obtener una vista previa e iniciar un modelo en particular en su propia cuenta de SageMaker. Proporciona modelos propietarios, previamente entrenados y disponibles públicamente para una amplia gama de tipos de problemas, incluidos los modelos básicos.
Amazon SageMaker Studio proporciona el entorno ideal para desarrollar canalizaciones de LLM habilitadas para RAG. Primero, usando la consola de AWS, vaya a Amazon SageMaker, cree un dominio de SageMaker Studio y abra una libreta de Jupyter Studio.
Requisitos previos
Complete los siguientes pasos de requisitos previos:
- Configure Amazon SageMaker Studio.
- Incorporación a un dominio de Amazon SageMaker.
- Regístrese para obtener una base de datos de vectores de piña de nivel gratuito.
- Bibliotecas de requisitos previos: SageMaker Python SDK, Pinecone Client
Tutorial de la solución
Al utilizar el cuaderno SageMaker Studio, primero necesitamos instalar las bibliotecas de requisitos previos:
Implementación de un LLM
En esta publicación, analizamos dos enfoques para implementar un LLM. La primera es a través del HuggingFaceModel objeto. Puede usar esto al implementar LLM (e incorporar modelos) directamente desde el centro de modelos de Hugging Face.
Por ejemplo, puede crear una configuración implementable para el google/flan-t5-xl modelo como se muestra en la siguiente captura de pantalla:
Al implementar modelos directamente desde Hugging Face, inicialice el my_model_configuration con lo siguiente:
- An
envconfig nos dice qué modelo queremos usar y para qué tarea. - Nuestra ejecución de SageMaker
rolenos da permisos para implementar nuestro modelo. - An
image_uries una configuración de imagen específica para implementar LLM de Hugging Face.
Alternativamente, SageMaker tiene un conjunto de modelos directamente compatibles con un sistema más simple. JumpStartModel objeto. Este modelo admite muchos LLM populares como Llama 2, que se puede inicializar como se muestra en la siguiente captura de pantalla:
Para ambas versiones de my_model, impleméntelos como se muestra en la siguiente captura de pantalla:
Con nuestro punto final LLM inicializado, puede comenzar a realizar consultas. El formato de nuestras consultas puede variar (particularmente entre LLM conversacionales y no conversacionales), pero el proceso es generalmente el mismo. Para el modelo Hugging Face, haga lo siguiente:
Puedes encontrar la solución en el Repositorio GitHub.
La respuesta generada que estamos recibiendo aquí no tiene mucho sentido: es una alucinación.
Proporcionar contexto adicional al LLM
Llama 2 intenta responder a nuestra pregunta basándose únicamente en el conocimiento paramétrico interno. Claramente, los parámetros del modelo no almacenan conocimiento de qué instancias podemos con el entrenamiento puntual administrado en SageMaker.
Para responder correctamente a esta pregunta, debemos utilizar el conocimiento fuente. Es decir, brindamos información adicional al LLM a través del mensaje. Agreguemos esa información directamente como contexto adicional para el modelo.
Ahora vemos la respuesta correcta a la pregunta; ¡eso fue fácil! Sin embargo, es poco probable que un usuario inserte contextos en sus indicaciones; ya sabría la respuesta a su pregunta.
En lugar de insertar manualmente un único contexto, identifique automáticamente la información relevante de una base de datos de información más extensa. Para eso, necesitará recuperación de generación aumentada.
Recuperación Generación Aumentada
Con Retrieval Augmented Generation, puede codificar una base de datos de información en un espacio vectorial donde la proximidad entre vectores representa su relevancia/similitud semántica. Con este espacio vectorial como base de conocimiento, puede convertir una nueva consulta de usuario, codificarla en el mismo espacio vectorial y recuperar los registros más relevantes previamente indexados.
Después de recuperar estos registros relevantes, seleccione algunos de ellos e inclúyalos en el mensaje del LLM como contexto adicional, proporcionando al LLM conocimientos fuente muy relevantes. Este es un proceso de dos pasos donde:
- La indexación completa el índice vectorial con información de un conjunto de datos.
- La recuperación ocurre durante una consulta y es donde recuperamos información relevante del índice del vector.
Ambos pasos requieren un modelo de incrustación para traducir nuestro texto plano legible por humanos al espacio vectorial semántico. Utilice el transformador de oraciones MiniLM altamente eficiente de Hugging Face como se muestra en la siguiente captura de pantalla. Este modelo no es un LLM y por lo tanto no se inicializa de la misma manera que nuestro modelo Llama 2.
En hub_config, especifique la ID del modelo como se muestra en la captura de pantalla anterior, pero para la tarea, use la extracción de características porque estamos generando incrustaciones de vectores, no texto como nuestro LLM. Después de esto, inicialice la configuración del modelo con HuggingFaceModel como antes, pero esta vez sin la imagen LLM y con algunos parámetros de versión.
Puede implementar el modelo nuevamente con deploy, utilizando la instancia más pequeña (solo CPU) de ml.t2.large. El modelo MiniLM es pequeño, por lo que no requiere mucha memoria y no necesita una GPU porque puede crear incrustaciones rápidamente incluso en una CPU. Si lo prefiere, puede ejecutar el modelo más rápido en la GPU.
Para crear incrustaciones, utilice el predict método y pasar una lista de contextos para codificar a través del inputs clave como se muestra:
Se pasan dos contextos de entrada y se devuelven dos incrustaciones de vectores de contexto como se muestra:
len(out)
2
La dimensionalidad de incrustación del modelo MiniLM es 384 lo que significa que cada vector que incorpora salidas MiniLM debe tener una dimensionalidad de 384. Sin embargo, si observa la longitud de nuestras incrustaciones, verá lo siguiente:
len(out[0]), len(out[1])
(8, 8)
Dos listas contienen ocho elementos cada una. MiniLM primero procesa el texto en un paso de tokenización. Esta tokenización transforma nuestro texto sin formato legible por humanos en una lista de ID de token legibles por modelos. En las características de salida del modelo, puede ver las incorporaciones a nivel de token. una de estas incrustaciones muestra la dimensionalidad esperada de 384 como se muestra:
len(out[0][0])
384
Transforme estas incrustaciones a nivel de token en incrustaciones a nivel de documento utilizando los valores medios en cada dimensión vectorial, como se muestra en la siguiente ilustración.

Operación de agrupación media para obtener un único vector de 384 dimensiones.
Con dos incrustaciones de vectores de 384 dimensiones, una para cada texto de entrada. Para hacernos la vida más fácil, envuelva el proceso de codificación en una sola función como se muestra en la siguiente captura de pantalla:
Descargando el conjunto de datos
Descargue las preguntas frecuentes de Amazon SageMaker como base de conocimientos para obtener los datos que contienen columnas de preguntas y respuestas.

Descargue las preguntas frecuentes de Amazon SageMaker
Al realizar la búsqueda, busque solo Respuestas, para poder soltar la columna Pregunta. Ver cuaderno para más detalles..
Nuestro conjunto de datos y el proceso de incorporación están listos. Ahora todo lo que necesitamos es un lugar donde almacenar esas incrustaciones.
Indexación
La base de datos de vectores de Pinecone almacena incrustaciones de vectores y las busca de manera eficiente a escala. Para crear una base de datos, necesitará una clave API gratuita de Pinecone.
Después de conectarse a la base de datos de vectores de Pinecone, cree un índice de vector único (similar a una tabla en las bases de datos tradicionales). Nombra el índice retrieval-augmentation-aws y alinear el índice dimension y metric parámetros con los requeridos por el modelo de incrustación (MiniLM en este caso).
Para comenzar a insertar datos, ejecute lo siguiente:
Puede comenzar a consultar el índice con la pregunta anterior en esta publicación.
El resultado anterior muestra que estamos devolviendo contextos relevantes para ayudarnos a responder nuestra pregunta. Desde que nosotros top_k = 1, index.query devolvió el resultado superior junto con los metadatos que leen Managed Spot Training can be used with all instances supported in Amazon.
Aumentar el aviso
Utilice los contextos recuperados para aumentar el mensaje y decidir la cantidad máxima de contexto para incluir en el LLM. Utilizar el 1000 Límite de caracteres para agregar de forma iterativa cada contexto devuelto al mensaje hasta que exceda la longitud del contenido.
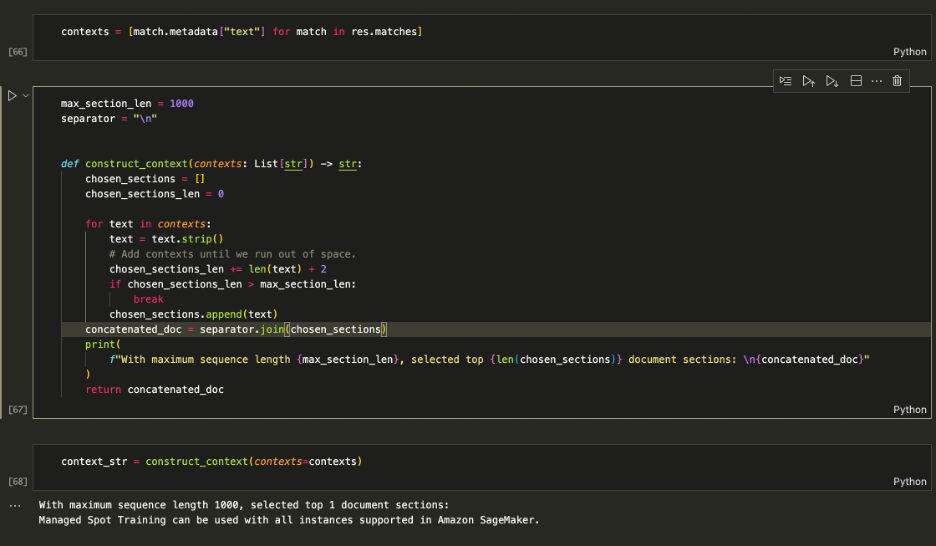
Aumentar el aviso
Alimentar el context_str en el mensaje LLM como se muestra en la siguiente captura de pantalla:
[Entrada]: ¿Qué instancias puedo usar con Managed Spot Training en SageMaker? [Salida]: Según el contexto proporcionado, puede utilizar Managed Spot Training con todas las instancias admitidas en Amazon SageMaker. Por tanto, la respuesta es: Todas las instancias admitidas en Amazon SageMaker.
La lógica funciona, así que envuélvela en una sola función para mantener todo limpio.
Ahora puede hacer preguntas como las que se muestran a continuación:
Limpiar
Para dejar de incurrir en cargos no deseados, elimine el modelo y el punto final.
Conclusión
En esta publicación, le presentamos RAG con LLM de acceso abierto en SageMaker. También mostramos cómo implementar modelos Jumpstart de Amazon SageMaker con Llama 2, LLM de Hugging Face con Flan T5 y modelos integrados con MiniLM.
Implementamos una canalización RAG completa de extremo a extremo utilizando nuestros modelos de acceso abierto y un índice vectorial Pinecone. Con esto, mostramos cómo minimizar las alucinaciones, mantener actualizado el conocimiento de LLM y, en última instancia, mejorar la experiencia del usuario y la confianza en nuestros sistemas.
Para ejecutar este ejemplo por su cuenta, clone este repositorio de GitHub y siga los pasos anteriores utilizando el Cuaderno de respuesta a preguntas en GitHub.
Sobre los autores
 jainista vedante es un especialista senior en IA/ML que trabaja en iniciativas estratégicas de IA generativa. Antes de unirse a AWS, Vedant ocupó puestos de especialidad en ciencia de datos y aprendizaje automático en varias empresas, como Databricks, Hortonworks (ahora Cloudera) y JP Morgan Chase. Fuera de su trabajo, a Vedant le apasiona hacer música, escalar rocas, utilizar la ciencia para llevar una vida significativa y explorar cocinas de todo el mundo.
jainista vedante es un especialista senior en IA/ML que trabaja en iniciativas estratégicas de IA generativa. Antes de unirse a AWS, Vedant ocupó puestos de especialidad en ciencia de datos y aprendizaje automático en varias empresas, como Databricks, Hortonworks (ahora Cloudera) y JP Morgan Chase. Fuera de su trabajo, a Vedant le apasiona hacer música, escalar rocas, utilizar la ciencia para llevar una vida significativa y explorar cocinas de todo el mundo.
 james briggs es un defensor del personal desarrollador en Pinecone, y se especializa en búsqueda de vectores e IA/ML. Guía a desarrolladores y empresas en el desarrollo de sus propias soluciones GenAI a través de la educación en línea. Antes de Pinecone, James trabajó en inteligencia artificial para pequeñas empresas emergentes de tecnología y corporaciones financieras establecidas. Fuera del trabajo, a James le apasiona viajar y emprender nuevas aventuras, desde surf y buceo hasta muay thai y BJJ.
james briggs es un defensor del personal desarrollador en Pinecone, y se especializa en búsqueda de vectores e IA/ML. Guía a desarrolladores y empresas en el desarrollo de sus propias soluciones GenAI a través de la educación en línea. Antes de Pinecone, James trabajó en inteligencia artificial para pequeñas empresas emergentes de tecnología y corporaciones financieras establecidas. Fuera del trabajo, a James le apasiona viajar y emprender nuevas aventuras, desde surf y buceo hasta muay thai y BJJ.
 XinHuang es un científico senior aplicado para los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado muchos artículos en conferencias ACL, ICDM, KDD y Royal Statistical Society: Serie A.
XinHuang es un científico senior aplicado para los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado muchos artículos en conferencias ACL, ICDM, KDD y Royal Statistical Society: Serie A.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/mitigate-hallucinations-through-retrieval-augmented-generation-using-pinecone-vector-database-llama-2-from-amazon-sagemaker-jumpstart/

