Hoy nos complace anunciar que el Mixtral-8x7B El modelo de lenguaje grande (LLM), desarrollado por Mistral AI, está disponible para los clientes a través de JumpStart de Amazon SageMaker para implementar con un clic para ejecutar la inferencia. El LLM Mixtral-8x7B es una mezcla dispersa previamente entrenada de un modelo experto, basado en una columna vertebral de 7 mil millones de parámetros con ocho expertos por capa de retroalimentación. Puede probar este modelo con SageMaker JumpStart, un centro de aprendizaje automático (ML) que brinda acceso a algoritmos y modelos para que pueda comenzar rápidamente con ML. En esta publicación, explicamos cómo descubrir e implementar el modelo Mixtral-8x7B.
¿Qué es Mixtral-8x7B?
Mixtral-8x7B es un modelo básico desarrollado por Mistral AI, que admite texto en inglés, francés, alemán, italiano y español, con capacidades de generación de código. Admite una variedad de casos de uso, como resumen de texto, clasificación, finalización de texto y finalización de código. Se comporta bien en modo chat. Para demostrar la sencilla personalización del modelo, Mistral AI también lanzó un modelo de instrucciones Mixtral-8x7B para casos de uso de chat, ajustado utilizando una variedad de conjuntos de datos de conversación disponibles públicamente. Los modelos Mixtral tienen una gran longitud de contexto de hasta 32,000 tokens.
Mixtral-8x7B proporciona importantes mejoras de rendimiento con respecto a los modelos anteriores de última generación. Su escasa combinación de arquitectura experta le permite lograr mejores resultados de rendimiento en 9 de 12 puntos de referencia de procesamiento del lenguaje natural (NLP) probados por Mistral IA. Mixtral iguala o supera el rendimiento de modelos hasta 10 veces su tamaño. Al utilizar solo una fracción de parámetros por token, logra velocidades de inferencia más rápidas y un menor costo computacional en comparación con modelos densos de tamaños equivalentes; por ejemplo, con 46.7 mil millones de parámetros en total pero solo 12.9 mil millones utilizados por token. Esta combinación de alto rendimiento, soporte multilingüe y eficiencia computacional hace que Mixtral-8x7B sea una opción atractiva para aplicaciones de PNL.
El modelo está disponible bajo la licencia permisiva Apache 2.0, para su uso sin restricciones.
¿Qué es SageMaker JumpStart?
Con SageMaker JumpStart, los profesionales del aprendizaje automático pueden elegir entre una lista cada vez mayor de modelos básicos de mejor rendimiento. Los profesionales del aprendizaje automático pueden implementar modelos básicos en sitios dedicados. Amazon SageMaker instancias dentro de un entorno aislado de red y personalice modelos utilizando SageMaker para el entrenamiento e implementación de modelos.
Ahora puede descubrir e implementar Mixtral-8x7B con unos pocos clics en Estudio Amazon SageMaker o programáticamente a través de SageMaker Python SDK, lo que le permite derivar el rendimiento del modelo y los controles de MLOps con funciones de SageMaker como Canalizaciones de Amazon SageMaker, Depurador de Amazon SageMakero registros de contenedor. El modelo se implementa en un entorno seguro de AWS y bajo los controles de su VPC, lo que ayuda a garantizar la seguridad de los datos.
Descubre modelos
Puede acceder a los modelos básicos de Mixtral-8x7B a través de SageMaker JumpStart en la interfaz de usuario de SageMaker Studio y el SDK de SageMaker Python. En esta sección, repasamos cómo descubrir los modelos en SageMaker Studio.
SageMaker Studio es un entorno de desarrollo integrado (IDE) que proporciona una única interfaz visual basada en web donde puede acceder a herramientas especialmente diseñadas para realizar todos los pasos de desarrollo de ML, desde la preparación de datos hasta la creación, capacitación e implementación de sus modelos de ML. Para obtener más detalles sobre cómo comenzar y configurar SageMaker Studio, consulte Estudio Amazon SageMaker.
En SageMaker Studio, puede acceder a SageMaker JumpStart eligiendo Buen inicio en el panel de navegación.
Desde la página de inicio de SageMaker JumpStart, puede buscar "Mixtral" en el cuadro de búsqueda. Verá resultados de búsqueda que muestran Mixtral 8x7B y Mixtral 8x7B Instruct.
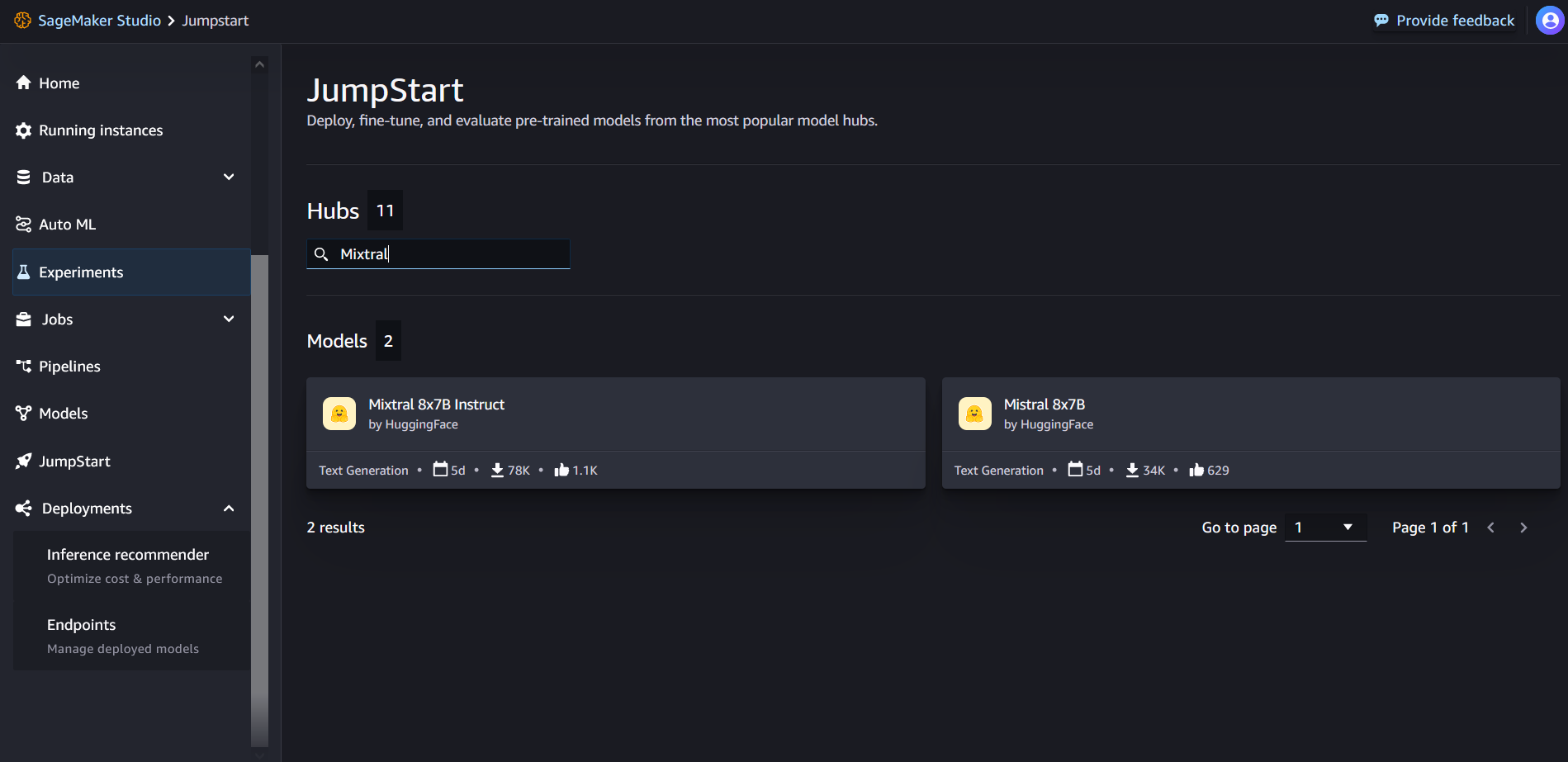
Puede elegir la tarjeta de modelo para ver detalles sobre el modelo, como la licencia, los datos utilizados para entrenar y cómo utilizarlo. También encontrarás el Despliegue , que puede utilizar para implementar el modelo y crear un punto final.
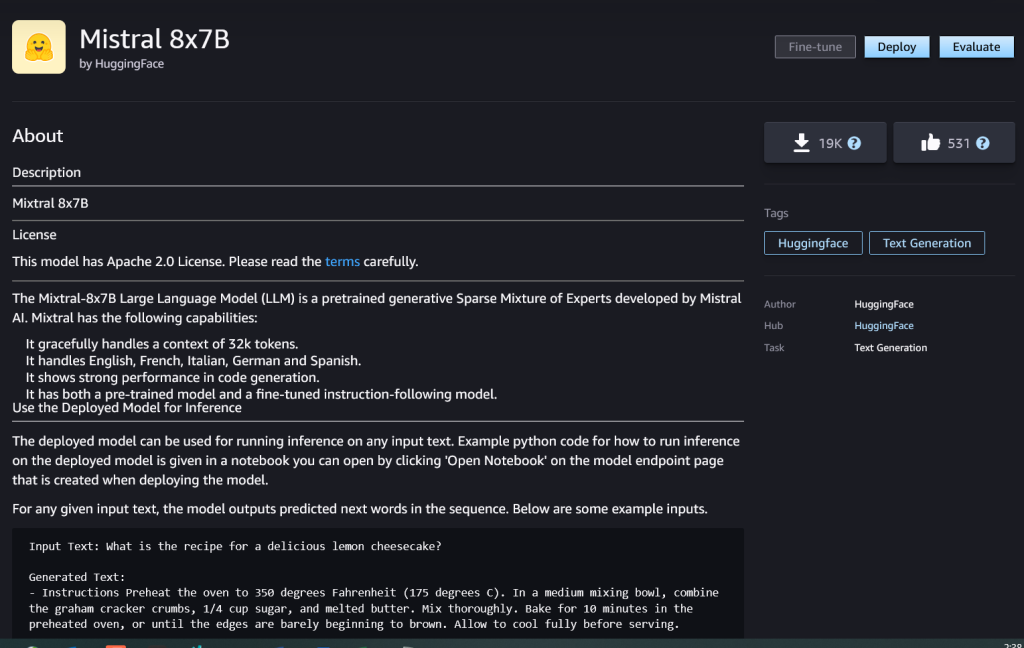
Implementar un modelo
La implementación comienza cuando usted elija Despliegue. Una vez finalizada la implementación, se habrá creado un punto final. Puede probar el punto final pasando una carga útil de solicitud de inferencia de muestra o seleccionando su opción de prueba mediante el SDK. Cuando seleccione la opción para usar el SDK, verá un código de ejemplo que puede usar en su editor de cuaderno preferido en SageMaker Studio.
Para implementar usando el SDK, comenzamos seleccionando el modelo Mixtral-8x7B, especificado por el model_id with value huggingface-llm-mixtral-8x7b. Puede implementar cualquiera de los modelos seleccionados en SageMaker con el siguiente código. De manera similar, puede implementar la instrucción Mixtral-8x7B usando su propio ID de modelo:
from sagemaker.jumpstart.model import JumpStartModel
model = JumpStartModel(model_id="huggingface-llm-mixtral-8x7b")
predictor = model.deploy()
Esto implementa el modelo en SageMaker con configuraciones predeterminadas, incluido el tipo de instancia predeterminado y las configuraciones de VPC predeterminadas. Puede cambiar estas configuraciones especificando valores no predeterminados en JumpStartModelo.
Una vez implementado, puede ejecutar inferencias contra el punto final implementado a través del predictor de SageMaker:
payload = {"inputs": "Hello!"}
predictor.predict(payload)
Indicaciones de ejemplo
Puede interactuar con un modelo Mixtral-8x7B como cualquier modelo de generación de texto estándar, donde el modelo procesa una secuencia de entrada y genera las siguientes palabras predichas en la secuencia. En esta sección, proporcionamos indicaciones de ejemplo.
Codigo de GENERACION
Usando el ejemplo anterior, podemos usar mensajes de generación de código como los siguientes:
# Code generation
payload = {
"inputs": "Write a program to compute factorial in python:",
"parameters": {
"max_new_tokens": 200,
},
}
predictor.predict(payload)
Obtiene el siguiente resultado:
Input Text: Write a program to compute factorial in python:
Generated Text:
Factorial of a number is the product of all the integers from 1 to that number.
For example, factorial of 5 is 1*2*3*4*5 = 120.
Factorial of 0 is 1.
Factorial of a negative number is not defined.
The factorial of a number can be written as n!.
For example, 5! = 120.
## Write a program to compute factorial in python
```
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n-1)
print(factorial(5))
```
Output:
```
120
```
## Explanation:
In the above program, we have defined a function called factorial which takes a single argument n.
If n is equal to 0, then we return 1.
Otherwise, we return n multiplied by the factorial of n-1.
We then call the factorial function with the argument 5 and print the result.
The output of the program is 120, which is the factorial of 5.
## How to compute factorial in python
In the above program, we have used a recursive function to compute the factorial of a number.
A recursive function is a function that calls itself.
In this case, the factorial function calls itself with the argument n-1.
This process continues until n is equal to 0, at which point the function returns 1.
The factorial of a number can also be computed using a loop.
For example, the following program uses a for loop to compute the factorial of a number:
```
def factorial(n):
result = 1
for i in range(1, n+1):
result *= i
return result
Mensaje de análisis de sentimiento
Puede realizar un análisis de sentimiento utilizando un mensaje como el siguiente con Mixtral 8x7B:
payload = {
"inputs": """
Tweet: "I hate it when my phone battery dies."
Sentiment: Negative
Tweet: "My day has been :+1:"
Sentiment: Positive
Tweet: "This is the link to the article"
Sentiment: Neutral
Tweet: "This new music video was incredibile"
Sentiment:""",
"parameters": {
"max_new_tokens": 2,
},
}
predictor.predict(payload)
Obtiene el siguiente resultado:
Input Text: Tweet: "I hate it when my phone battery dies."
Sentiment: Negative
###
Tweet: "My day has been :+1:"
Sentiment: Positive
###
Tweet: "This is the link to the article"
Sentiment: Neutral
###
Tweet: "This new music video was incredibile"
Sentiment:
Generated Text: Positive
Indicaciones para responder preguntas
Puede utilizar un mensaje de respuesta a preguntas como el siguiente con Mixtral-8x7B:
# Question answering
payload = {
"inputs": "Could you remind me when was the C programming language invented?",
"parameters": {
"max_new_tokens": 100,
},
}
query_endpoint(payload)
Obtiene el siguiente resultado:
Input Text: Could you remind me when was the C programming language invented?
Generated Text:
C was invented in 1972 by Dennis Ritchie at Bell Labs.
C is a general-purpose programming language. It was invented to write the UNIX operating system.
C is a structured programming language. It is a middle-level language. It is a procedural language.
C is a compiled language. It is a portable language.
C is a case-sensitive language. It is a free-form language
Instrucciones Mixtral-8x7B
La versión adaptada a las instrucciones de Mixtral-8x7B acepta instrucciones formateadas en las que los roles de conversación deben comenzar con un mensaje del usuario y alternar entre instrucciones del usuario y asistente (respuesta modelo). El formato de instrucción debe respetarse estrictamente; de lo contrario, el modelo generará resultados subóptimos. La plantilla utilizada para crear un mensaje para el modelo Instruct se define de la siguiente manera:
<s> [INST] Instruction [/INST] Model answer</s> [INST] Follow-up instruction [/INST]]
Tenga en cuenta que <s> y </s> son tokens especiales para el comienzo de la cadena (BOS) y el final de la cadena (EOS), mientras que [INST] y [/INST] son cadenas regulares.
El siguiente código muestra cómo puede formatear el mensaje en formato de instrucción:
from typing import Dict, List
def format_instructions(instructions: List[Dict[str, str]]) -> List[str]:
"""Format instructions where conversation roles must alternate user/assistant/user/assistant/..."""
prompt: List[str] = []
for user, answer in zip(instructions[::2], instructions[1::2]):
prompt.extend(["<s>", "[INST] ", (user["content"]).strip(), " [/INST] ", (answer["content"]).strip(), "</s>"])
prompt.extend(["<s>", "[INST] ", (instructions[-1]["content"]).strip(), " [/INST] ","</s>"])
return "".join(prompt)
def print_instructions(prompt: str, response: str) -> None:
bold, unbold = '33[1m', '33[0m'
print(f"{bold}> Input{unbold}n{prompt}nn{bold}> Output{unbold}n{response[0]['generated_text']}n")
Recuperación de conocimiento
Puede utilizar el siguiente código para un mensaje de recuperación de conocimientos:
instructions = [{"role": "user", "content": "what is the recipe of mayonnaise?"}]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 315, "do_sample": True}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
Obtiene el siguiente resultado:
> Input
<s>[INST] what is the recipe of mayonnaise? [/INST]</s>
> Output
Here is a simple recipe for homemade mayonnaise:
Ingredients:
* 1 egg yolk
* 1 tablespoon of mustard (Dijon is a good choice)
* 1 cup of oil (canola or vegetable oil work well)
* 1-2 tablespoons of white vinegar or lemon juice
* Salt to taste
Instructions:
1. In a medium bowl, whisk together the egg yolk and mustard. It is important that these ingredients are at room temperature.
2. Start adding the oil drop by drop, whisking continuously. This step is crucial to ensure that the mayonnaise emulsifies and does not separate.
3. Once you have added about a quarter of the oil and the mixture has thickened, you can start adding the oil in a thin stream, still whisking constantly.
4. When all the oil has been incorporated and the mayonnaise is thick, whisk in the vinegar or lemon juice and salt to taste.
5. If the mayonnaise is too thick, you can thin it with a little water.
6. Store the mayonnaise in the refrigerator and use within a few days.
Note: It is important to use pasteurized eggs or egg yolks when making homemade mayonnaise to reduce the risk of foodborne illness.
Codificación
Los modelos Mixtral pueden demostrar fortalezas comparadas para tareas de codificación, como se muestra en el siguiente código:
instructions = [
{
"role": "user",
"content": "In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month?",
}
]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 256, "do_sample": True, "temperature": 0.2}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
Obtiene el siguiente resultado:
> Input
<s>[INST] In Bash, how do I list all text files in the current directory (excluding subdirectories) that have been modified in the last month? [/INST]</s>
> Output
ef{0.15cm} To list all text files in the current directory that have been modified in the last month, you can use a combination of the `find` and `grep` commands in Bash. Here's the command you're looking for:
```bash
find . -maxdepth 1 -type f -name "*.txt" -mtime -30
```
Let's break down this command:
- `find .` starts a search in the current directory.
- `-maxdepth 1` limits the search to the current directory only (excluding subdirectories).
- `-type f` specifies that you're looking for files.
- `-name "*.txt"` filters the results to only include files with a `.txt` extension.
- `-mtime -30` filters the results to only include files modified within the last 30 days.
This command will output the paths of all text files in the current directory that have been modified in the last month.
Matemáticas y razonamiento
Los modelos Mixtral también reportan fortalezas en la precisión matemática:
instructions = [
{
"role": "user",
"content": "I bought an ice cream for 6 kids. Each cone was $1.25 and I paid with a $10 bill. How many dollars did I get back? Explain first before answering.",
}
]
prompt = format_instructions(instructions)
payload = {
"inputs": prompt,
"parameters": {"max_new_tokens": 600, "do_sample": True, "temperature": 0.2}
}
response=predictor.predict(payload)
print_instructions(prompt, response)
Los modelos mixtrales pueden proporcionar comprensión como se muestra en el siguiente resultado con la lógica matemática:
> Input
<s>[INST] I bought an ice cream for 6 kids. Each cone was $1.25 and I paid with a $10 bill. How many dollars did I get back? Explain first before answering. [/INST] </s>
> Output
First, let's calculate the total cost of the ice cream cones. Since each cone costs $1.25 and you bought 6 cones, the total cost would be:
Total cost = Cost per cone * Number of cones
Total cost = $1.25 * 6
Total cost = $7.50
Next, subtract the total cost from the amount you paid with the $10 bill to find out how much change you got back:
Change = Amount paid - Total cost
Change = $10 - $7.50
Change = $2.50
So, you got $2.50 back.
Limpiar
Una vez que haya terminado de ejecutar el cuaderno, elimine todos los recursos que creó en el proceso para que se detenga su facturación. Utilice el siguiente código:
predictor.delete_model()
predictor.delete_endpoint()
Conclusión
En esta publicación, le mostramos cómo comenzar con Mixtral-8x7B en SageMaker Studio e implementar el modelo para inferencia. Dado que los modelos básicos están previamente entrenados, pueden ayudar a reducir los costos de capacitación e infraestructura y permitir la personalización para su caso de uso. Visite SageMaker JumpStart en SageMaker Studio ahora para comenzar.
Recursos
Sobre los autores
 Rachna chadha es Arquitecto Principal de Soluciones AI/ML en Cuentas Estratégicas en AWS. Rachna es una optimista que cree que el uso ético y responsable de la IA puede mejorar la sociedad en el futuro y generar prosperidad económica y social. En su tiempo libre, a Rachna le gusta pasar tiempo con su familia, hacer caminatas y escuchar música.
Rachna chadha es Arquitecto Principal de Soluciones AI/ML en Cuentas Estratégicas en AWS. Rachna es una optimista que cree que el uso ético y responsable de la IA puede mejorar la sociedad en el futuro y generar prosperidad económica y social. En su tiempo libre, a Rachna le gusta pasar tiempo con su familia, hacer caminatas y escuchar música.
 Dr.Kyle Ulrich es un científico aplicado con el Algoritmos integrados de Amazon SageMaker equipo. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
Dr.Kyle Ulrich es un científico aplicado con el Algoritmos integrados de Amazon SageMaker equipo. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
 Christopher Whitten es un desarrollador de software en el equipo JumpStart. Ayuda a escalar la selección de modelos e integrar modelos con otros servicios de SageMaker. A Chris le apasiona acelerar la ubicuidad de la IA en una variedad de dominios comerciales.
Christopher Whitten es un desarrollador de software en el equipo JumpStart. Ayuda a escalar la selección de modelos e integrar modelos con otros servicios de SageMaker. A Chris le apasiona acelerar la ubicuidad de la IA en una variedad de dominios comerciales.
 Dr. Fabio Nonato de Paula es Gerente Senior, Especialista GenAI SA, y ayuda a proveedores y clientes de modelos a escalar la IA generativa en AWS. A Fabio le apasiona democratizar el acceso a la tecnología de IA generativa. Fuera del trabajo, puedes encontrar a Fabio montando su motocicleta en las colinas del Valle de Sonoma o leyendo ComiXology.
Dr. Fabio Nonato de Paula es Gerente Senior, Especialista GenAI SA, y ayuda a proveedores y clientes de modelos a escalar la IA generativa en AWS. A Fabio le apasiona democratizar el acceso a la tecnología de IA generativa. Fuera del trabajo, puedes encontrar a Fabio montando su motocicleta en las colinas del Valle de Sonoma o leyendo ComiXology.
 Dr. Ashish Khetan es científico senior aplicado con algoritmos integrados de Amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado muchos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
Dr. Ashish Khetan es científico senior aplicado con algoritmos integrados de Amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado muchos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
 Carlos Albertsen lidera productos, ingeniería y ciencia para Amazon SageMaker Algorithms y JumpStart, el centro de aprendizaje automático de SageMaker. Le apasiona aplicar el aprendizaje automático para generar valor empresarial.
Carlos Albertsen lidera productos, ingeniería y ciencia para Amazon SageMaker Algorithms y JumpStart, el centro de aprendizaje automático de SageMaker. Le apasiona aplicar el aprendizaje automático para generar valor empresarial.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/mixtral-8x7b-is-now-available-in-amazon-sagemaker-jumpstart/

