Las aplicaciones de aprendizaje automático (ML) son complejas de implementar y, a menudo, requieren la capacidad de hiperescala, y tienen requisitos de latencia ultrabaja y presupuestos de costos estrictos. Los casos de uso, como la detección de fraudes, las recomendaciones de productos y la predicción del tráfico, son ejemplos en los que los milisegundos importan y son fundamentales para el éxito comercial. Se deben cumplir estrictos acuerdos de nivel de servicio (SLA), y una solicitud típica puede requerir varios pasos, como preprocesamiento, transformación de datos, ingeniería de funciones, lógica de selección de modelos, agregación de modelos y posprocesamiento.
La implementación de modelos ML a escala con costos optimizados y eficiencias informáticas puede ser una tarea abrumadora y engorrosa. Cada modelo tiene sus propios méritos y dependencias en función de las fuentes de datos externas, así como del entorno de tiempo de ejecución, como la potencia de CPU/GPU de los recursos informáticos subyacentes. Una aplicación puede requerir múltiples modelos de ML para atender una sola solicitud de inferencia. En ciertos escenarios, una solicitud puede fluir a través de múltiples modelos. No existe un enfoque único para todos, y es importante que los profesionales de ML busquen métodos probados para abordar los desafíos recurrentes de alojamiento de ML. Esto ha llevado a la evolución de los patrones de diseño para el alojamiento de modelos ML.
En esta publicación, exploramos patrones de diseño comunes para crear aplicaciones ML en Amazon SageMaker.
Patrones de diseño para crear aplicaciones de aprendizaje automático
Veamos los siguientes patrones de diseño para usar para hospedar aplicaciones ML.
Aplicaciones de aprendizaje automático basadas en un único modelo
Esta es una excelente opción cuando su caso de uso de ML requiere un solo modelo para atender una solicitud. El modelo se implementa en una infraestructura informática dedicada con la capacidad de escalar en función del tráfico de entrada. Esta opción también es ideal cuando la aplicación cliente tiene un requisito de inferencia de baja latencia (del orden de milisegundos o segundos).
Aplicaciones de ML basadas en modelos múltiples
Para que el hospedaje sea más rentable, este patrón de diseño le permite hospedar varios modelos en la misma infraestructura de inquilino. Múltiples modelos de ML pueden compartir los recursos del host o del contenedor, incluido el almacenamiento en caché de los modelos de ML más utilizados en la memoria, lo que da como resultado una mejor utilización de la memoria y los recursos informáticos. Según los tipos de modelos que elija implementar, el cohospedaje de modelos puede usar los siguientes métodos:
- Alojamiento multimodelo – Esta opción le permite alojar varios modelos utilizando un contenedor de servicio compartido en un solo punto final. Esta característica es ideal cuando tiene una gran cantidad de modelos similares que puede servir a través de un contenedor de servicio compartido y no necesita acceder a todos los modelos al mismo tiempo.
- Alojamiento multicontenedor – Esta opción es ideal cuando tiene varios modelos que se ejecutan en diferentes pilas de servicio con necesidades de recursos similares y cuando los modelos individuales no tienen suficiente tráfico para utilizar la capacidad total de las instancias de punto final. El alojamiento de múltiples contenedores le permite implementar múltiples contenedores que usan diferentes modelos o marcos en un único punto final. Los modelos pueden ser completamente heterogéneos, con su propia pila de servicio independiente.
- Conjuntos de modelos – En muchos casos de uso de producción, a menudo puede haber muchos modelos ascendentes que alimentan entradas a un modelo descendente dado. Aquí es donde los conjuntos son útiles. Los patrones de conjunto implican mezclar la salida de uno o más modelos base para reducir el error de generalización de la predicción. Los modelos base pueden ser diversos y entrenados por diferentes algoritmos. Los conjuntos de modelos pueden superar a los modelos individuales porque el error de predicción del modelo disminuye cuando se utiliza el enfoque de conjunto.
Los siguientes son casos de uso comunes de patrones de conjuntos y sus correspondientes diagramas de patrones de diseño:
- Dispersión-reunión – En un patrón de dispersión y recopilación, una solicitud de inferencia se enruta a una serie de modelos. A continuación, se utiliza un agregador para recopilar las respuestas y destilarlas en una sola respuesta de inferencia. Por ejemplo, un caso de uso de clasificación de imágenes puede usar tres modelos diferentes para realizar la tarea. El patrón de dispersión y recopilación le permite combinar resultados de inferencias ejecutadas en tres modelos diferentes y elegir el modelo de clasificación más probable.

- Modelo agregado – En un patrón de agregación, se promedian los resultados de varios modelos. Para los modelos de clasificación, se evalúan las predicciones de varios modelos para determinar la clase que recibió la mayor cantidad de votos y se trata como el resultado final del conjunto. Por ejemplo, en un problema de clasificación de dos clases para clasificar un conjunto de frutas como naranjas o manzanas, si dos modelos votan por una naranja y un modelo vota por una manzana, la salida agregada será una naranja. La agregación ayuda a combatir la imprecisión en modelos individuales y hace que la salida sea más precisa.

- Selección dinámica – Otro patrón para los modelos de conjunto es realizar dinámicamente la selección del modelo para los atributos de entrada dados. Por ejemplo, en una entrada dada de imágenes de frutas, si la entrada contiene una naranja, se utilizará el modelo A porque está especializado en naranjas. Si la entrada contiene una manzana, se usará el modelo B porque está especializado para manzanas.

- Aplicaciones de ML de inferencia en serie – Con un patrón de inferencia en serie, también conocido como canalización de inferencia, los casos de uso tienen requisitos para preprocesar los datos entrantes antes de invocar un modelo de ML preentrenado para generar inferencias. Además, en algunos casos, es posible que las inferencias generadas deban procesarse aún más, de modo que las aplicaciones posteriores puedan consumirlas fácilmente. Una canalización de inferencia le permite reutilizar el mismo código de preprocesamiento utilizado durante el entrenamiento del modelo para procesar los datos de solicitud de inferencia utilizados para las predicciones.

- Lógica de negocios – La producción de ML siempre involucra la lógica comercial. Los patrones de lógica empresarial involucran todo lo que se necesita para realizar una tarea de ML que no es una inferencia de modelo de ML. Esto incluye cargar el modelo desde Servicio de almacenamiento simple de Amazon (Amazon S3), por ejemplo, búsquedas en la base de datos para validar la entrada, obtener funciones precalculadas del almacén de funciones, etc. Una vez que se completan estos pasos de lógica comercial, las entradas se pasan a los modelos ML.

Opciones de inferencia de ML
Para la implementación del modelo, es importante trabajar hacia atrás desde su caso de uso. ¿Cuál es la frecuencia de la predicción? ¿Espera tráfico en vivo a su aplicación y respuesta en tiempo real a sus clientes? ¿Tiene muchos modelos entrenados para diferentes subconjuntos de datos para el mismo caso de uso? ¿El tráfico de predicción fluctúa? ¿Es la latencia de la inferencia una preocupación? Según estos detalles, todos los patrones de diseño anteriores se pueden implementar mediante las siguientes opciones de implementación:
- Inferencia en tiempo real – La inferencia en tiempo real es ideal para cargas de trabajo de inferencia en las que tiene requisitos de baja latencia, interactivos y en tiempo real. Las cargas de trabajo de inferencia de ML en tiempo real pueden incluir una aplicación de ML basada en un solo modelo, donde una aplicación requiere solo un modelo de ML para atender una sola solicitud, o una aplicación de ML basada en varios modelos, donde una aplicación requiere múltiples modelos de ML para atender una sola solicitud. solicitud.
- Inferencia casi en tiempo real (asincrónica) – Con inferencia casi en tiempo real, puede poner en cola las solicitudes entrantes. Esto se puede utilizar para ejecutar inferencias en entradas que son cientos de MB. Funciona casi en tiempo real y permite a los usuarios usar la entrada para la inferencia y leer la salida desde el punto final desde un depósito S3. Puede ser especialmente útil en casos con NLP y visión por computadora, donde hay grandes cargas útiles que requieren tiempos de preprocesamiento más prolongados.
- Inferencia por lotes – La inferencia por lotes se puede utilizar para ejecutar la inferencia fuera de línea en un gran conjunto de datos. Debido a que se ejecuta sin conexión, la inferencia por lotes no ofrece la latencia más baja. Aquí, la solicitud de inferencia se procesa con un activador programado o basado en eventos de un trabajo de inferencia por lotes.
- Inferencia sin servidor – La inferencia sin servidor es ideal para cargas de trabajo que tienen períodos de inactividad entre picos de tráfico y pueden tolerar algunos segundos adicionales de latencia (inicio en frío) para la primera invocación después de un período de inactividad. Por ejemplo, un servicio de chatbot o una aplicación para procesar formularios o analizar datos de documentos. En este caso, es posible que desee una opción de inferencia en línea que pueda aprovisionar y escalar automáticamente la capacidad informática en función del volumen de solicitudes de inferencia. Y durante el tiempo de inactividad, debería poder apagar completamente la capacidad informática para que no se le cobre. La inferencia sin servidor elimina el trabajo pesado indiferenciado de seleccionar y administrar servidores al iniciar automáticamente los recursos informáticos y escalarlos hacia adentro y hacia afuera según el tráfico.
Use las funciones de fitness para seleccionar la opción de inferencia ML correcta
Decidir cuál es la opción de hospedaje adecuada es importante porque afecta a los usuarios finales representados por sus aplicaciones. Para este propósito, estamos tomando prestado el concepto de funciones de fitness, que fue acuñado por Neal Ford y sus colegas de AWS Partner ThoughtWorks en su trabajo Construcción de arquitecturas evolutivas. Las funciones de aptitud brindan una evaluación prescriptiva de varias opciones de alojamiento en función de los objetivos del cliente. Las funciones de fitness le ayudan a obtener los datos necesarios para permitir la evolución planificada de su arquitectura. Establecen valores medibles para evaluar qué tan cerca está su solución de lograr sus objetivos establecidos. Las funciones de fitness pueden y deben adaptarse a medida que la arquitectura evoluciona para guiar el proceso de cambio deseado. Esto proporciona a los arquitectos una herramienta para guiar a sus equipos mientras mantienen la autonomía del equipo.
Hay cinco funciones principales de aptitud que preocupan a los clientes cuando se trata de seleccionar la opción de inferencia de ML adecuada para alojar sus modelos y aplicaciones de ML.
| Función de la aptitud | Descripción |
| Cost |
Implementar y mantener un modelo ML y una aplicación ML en un marco escalable es un proceso comercial crítico, y los costos pueden variar mucho según las elecciones realizadas sobre la infraestructura de alojamiento del modelo, la opción de alojamiento, los marcos ML, las características del modelo ML, las optimizaciones, la política de escalado, y más. Las cargas de trabajo deben utilizar la infraestructura de hardware de manera óptima para garantizar que el costo se mantenga bajo control. Esta función de aptitud se refiere específicamente al costo de la infraestructura, que forma parte del costo total de propiedad (TCO) general. Los costos de infraestructura son los costos combinados de almacenamiento, red y computación. También es fundamental comprender otros componentes del TCO, incluidos los costos operativos y los costos de seguridad y cumplimiento. Los costos operativos son los costos combinados de operar, monitorear y mantener la infraestructura de ML. Los costos operativos se calculan como la cantidad de ingenieros necesarios en función de cada escenario y el salario anual de los ingenieros, agregado durante un período específico. Clientes que utilizan soluciones de aprendizaje automático autogestionadas en Nube informática elástica de Amazon (Amazon EC2), Servicio de contenedor elástico de Amazon (Amazon ECS), y Servicio Amazon Elastic Kubernetes (Amazon EKS) necesitan construir herramientas operativas ellos mismos. Los clientes que utilizan SageMaker incurren en un TCO significativamente menor. La inferencia de SageMaker es un servicio completamente administrado y proporciona capacidades listas para usar para implementar modelos de aprendizaje automático para la inferencia. No necesita aprovisionar instancias, monitorear el estado de las instancias, administrar actualizaciones o parches de seguridad, emitir métricas operativas o crear monitoreo para sus cargas de trabajo de inferencia de ML. Tiene capacidades integradas para garantizar una alta disponibilidad y resiliencia. SageMaker admite seguridad con cifrado de extremo a extremo en reposo y en tránsito, incluido el cifrado del volumen raíz y Tienda de bloques elásticos de Amazon (Amazon EBS) volumen, Nube privada virtual de Amazon (Amazon VPC) soporte, Enlace privado de AWS, claves administradas por el cliente, Gestión de identidades y accesos de AWS (IAM) control de acceso detallado, Seguimiento de la nube de AWS auditorías, cifrado de entrenudos para capacitación, control de acceso basado en etiquetas, aislamiento de red y proxy de aplicación interactivo. Todas estas funciones de seguridad se proporcionan listas para usar en SageMaker y pueden ahorrarles a las empresas decenas de meses de desarrollo de esfuerzo de ingeniería durante un período de 3 años. SageMaker es un servicio elegible para HIPAA y está certificado por PCI, SOC, GDPR e ISO. SageMaker también admite terminales FIPS. Para obtener más información sobre TCO, consulte El costo total de propiedad de Amazon SageMaker. |
| latencia de inferencia | Muchos modelos y aplicaciones de ML son críticos para la latencia, en los que la latencia de inferencia debe estar dentro de los límites especificados por un objetivo de nivel de servicio. La latencia de inferencia depende de una multitud de factores, incluidos el tamaño y la complejidad del modelo, la plataforma de hardware, el entorno de software y la arquitectura de red. Por ejemplo, los modelos más grandes y complejos pueden tardar más en ejecutar la inferencia. |
| Rendimiento (transacciones por segundo) | Para la inferencia de modelos, la optimización del rendimiento es crucial para ajustar el rendimiento y lograr el objetivo comercial de la aplicación ML. A medida que avanzamos rápidamente en todos los aspectos de ML, incluidas las implementaciones de operaciones matemáticas de bajo nivel en el diseño de chips, las bibliotecas específicas de hardware desempeñan un papel más importante en la optimización del rendimiento. Varios factores, como el tamaño de la carga útil, los saltos de red, la naturaleza de los saltos, las características del gráfico del modelo, los operadores en el modelo y la CPU, la GPU y el perfil de memoria de las instancias de alojamiento del modelo afectan el rendimiento del modelo ML. |
| Complejidad de configuración escalable | Es crucial que los modelos o aplicaciones de ML se ejecuten en un marco escalable que pueda manejar la demanda de tráfico variable. También permite la máxima utilización de los recursos de CPU y GPU y evita el aprovisionamiento excesivo de recursos informáticos. |
| Patrón de tráfico esperado | Los modelos o aplicaciones de ML pueden tener diferentes patrones de tráfico, que van desde tráfico en vivo continuo en tiempo real hasta picos periódicos de miles de solicitudes por segundo, y desde patrones de solicitud poco frecuentes e impredecibles hasta solicitudes por lotes fuera de línea en conjuntos de datos más grandes. Se recomienda trabajar hacia atrás a partir del patrón de tráfico esperado para seleccionar la opción de hospedaje adecuada para su modelo de aprendizaje automático. |
Implementación de modelos con SageMaker
SageMaker es un servicio de AWS totalmente administrado que brinda a todos los desarrolladores y científicos de datos la capacidad de crear, entrenar e implementar rápidamente modelos de aprendizaje automático a escala. Con la inferencia de SageMaker, puede implementar sus modelos ML en puntos finales alojados y obtener resultados de inferencia. SageMaker ofrece una amplia selección de hardware y funciones para satisfacer sus requisitos de carga de trabajo, lo que le permite seleccionar más de 70 tipos de instancias con aceleración de hardware. SageMaker también puede proporcionar recomendaciones de tipos de instancias de inferencia mediante una nueva característica llamada SageMaker Inference Recommender, en caso de que no esté seguro de cuál sería la más óptima para su carga de trabajo.
Puede elegir las opciones de implementación que mejor se adapten a sus casos de uso, como inferencia en tiempo real, asíncrono, por lotes e incluso puntos finales sin servidor. Además, SageMaker ofrece varias estrategias de implementación como canary, azul / verde, sombra, y pruebas A/B para la implementación de modelos, junto con una implementación rentable con múltiples modelos, puntos finales de múltiples contenedores y escalabilidad elástica. Con la inferencia de SageMaker, puede ver las métricas de rendimiento de sus terminales en Reloj en la nube de Amazon, escalar puntos finales automáticamente en función del tráfico y actualice sus modelos en producción sin perder disponibilidad.
SageMaker ofrece cuatro opciones para implementar su modelo para que pueda comenzar a hacer predicciones:
- Inferencia en tiempo real – Esto es adecuado para cargas de trabajo con requisitos de latencia de milisegundos, tamaños de carga útil de hasta 6 MB y tiempos de procesamiento de hasta 60 segundos.
- Transformación por lotes – Esto es ideal para predicciones fuera de línea en grandes lotes de datos que están disponibles por adelantado.
- inferencia asíncrona – Esto está diseñado para cargas de trabajo que no tienen requisitos de latencia inferiores a un segundo, tamaños de carga útil de hasta 1 GB y tiempos de procesamiento de hasta 15 minutos.
- Inferencia sin servidor – Con la inferencia sin servidor, puede implementar rápidamente modelos ML para la inferencia sin tener que configurar o administrar la infraestructura subyacente. Además, solo paga por la capacidad informática utilizada para procesar solicitudes de inferencia, lo que es ideal para cargas de trabajo intermitentes.
El siguiente diagrama puede ayudarlo a comprender las opciones de implementación del modelo de hospedaje de SageMaker junto con las evaluaciones de funciones de aptitud asociadas.

Exploremos cada una de las opciones de implementación con más detalle.
Inferencia en tiempo real en SageMaker
Se recomienda la inferencia en tiempo real de SageMaker si tiene un tráfico constante y necesita una latencia más baja y constante para sus solicitudes con tamaños de carga útil de hasta 6 MB y tiempos de procesamiento de hasta 60 segundos. Implementa su modelo en los servicios de alojamiento de SageMaker y obtiene un punto final que se puede usar para la inferencia. Estos puntos finales están totalmente administrados y admiten el escalado automático. La inferencia en tiempo real es popular para casos de uso en los que espera una respuesta sincrónica de baja latencia con patrones de tráfico predecibles, como recomendaciones personalizadas para productos y servicios o casos de uso de detección de fraude transaccional.
Por lo general, una aplicación cliente envía solicitudes al extremo HTTPS de SageMaker para obtener inferencias de un modelo implementado. Puede implementar varias variantes de un modelo en el mismo punto final HTTPS de SageMaker. Esto es útil para probar variaciones de un modelo en producción. El escalado automático le permite ajustar dinámicamente la cantidad de instancias aprovisionadas para un modelo en respuesta a los cambios en su carga de trabajo.
La siguiente tabla proporciona orientación sobre cómo evaluar la inferencia en tiempo real de SageMaker en función de las funciones de aptitud.
| Función de la aptitud | Descripción |
| Cost |
Los puntos finales en tiempo real ofrecen una respuesta síncrona a las solicitudes de inferencia. Debido a que el punto final siempre se está ejecutando y disponible para proporcionar una respuesta de inferencia síncrona en tiempo real, usted paga por usar la instancia. Los costos pueden acumularse rápidamente cuando implementa múltiples puntos finales, especialmente si los puntos finales no utilizan completamente las instancias subyacentes. Elegir la instancia correcta para su modelo ayuda a garantizar que tenga la instancia de mayor rendimiento al menor costo para sus modelos. Se recomienda el escalado automático para ajustar dinámicamente la capacidad según el tráfico para mantener un rendimiento constante y predecible al menor costo posible. SageMaker amplía el acceso a las familias de instancias de aprendizaje automático basadas en Graviton2 y Graviton3. Gravitón de AWS Los procesadores están personalizados por Amazon Web Services utilizando núcleos Arm Neoverse de 64 bits para ofrecer el mejor rendimiento de precio para sus cargas de trabajo en la nube que se ejecutan en Amazon EC2. Con las instancias basadas en Graviton, tiene más opciones para optimizar el costo y el rendimiento al implementar sus modelos ML en SageMaker. SageMaker también admite Instancias inf1, proporcionando inferencia de ML rentable y de alto rendimiento. Con 1–16 Chips de inferencia de AWS por instancia, las instancias Inf1 pueden escalar en rendimiento y ofrecer un rendimiento hasta tres veces mayor y hasta un 50 % menos de costo por inferencia en comparación con las instancias basadas en GPU de AWS. Para usar instancias Inf1 en SageMaker, puede compilar sus modelos entrenados usando Amazon SageMaker Neo y seleccione las instancias Inf1 para implementar el modelo compilado en SageMaker. También puedes explorar Planes de ahorro para SageMaker para beneficiarse de un ahorro de costes de hasta un 64 % en comparación con el precio bajo demanda. Cuando crea un punto final, SageMaker adjunta un volumen de almacenamiento de EBS a cada instancia informática de ML que aloja el punto final. El tamaño del volumen de almacenamiento depende del tipo de instancia. El costo adicional para puntos finales en tiempo real incluye el costo de GB-mes de almacenamiento aprovisionado, más GB de datos procesados dentro y fuera de la instancia del punto final. |
| latencia de inferencia | La inferencia en tiempo real es ideal cuando necesita un punto final persistente con requisitos de latencia de milisegundos. Admite tamaños de carga útil de hasta 6 MB y tiempos de procesamiento de hasta 60 segundos. |
| rendimiento |
Un valor ideal de rendimiento de inferencia depende de factores como el modelo, el tamaño de entrada del modelo, el tamaño del lote y el tipo de instancia de punto final. Como práctica recomendada, revise las métricas de CloudWatch para las solicitudes de entrada y la utilización de recursos, y seleccione el tipo de instancia adecuado para lograr un rendimiento óptimo. Una aplicación de negocios puede ser optimizada para el rendimiento o para la latencia. Por ejemplo, el procesamiento por lotes dinámico puede ayudar a aumentar el rendimiento de las aplicaciones sensibles a la latencia mediante la inferencia en tiempo real. Sin embargo, existen límites para el tamaño del lote, sin los cuales la latencia de inferencia podría verse afectada. La latencia de inferencia aumentará a medida que aumente el tamaño del lote para mejorar el rendimiento. Por lo tanto, la inferencia en tiempo real es una opción ideal para aplicaciones sensibles a la latencia. SageMaker ofrece opciones de inferencia asíncrona y transformación por lotes, que están optimizadas para brindar un mayor rendimiento en comparación con la inferencia en tiempo real si las aplicaciones comerciales pueden tolerar una latencia ligeramente mayor. |
| Complejidad de configuración escalable |
Compatibilidad con terminales en tiempo real de SageMaker escalado automático fuera de la caja. Cuando aumenta la carga de trabajo, el escalado automático pone más instancias en línea. Cuando la carga de trabajo disminuye, el escalado automático elimina las instancias innecesarias, lo que lo ayuda a reducir el costo de cómputo. Sin el escalado automático, debe aprovisionarse para el tráfico máximo o la indisponibilidad del modelo de riesgo. A menos que el tráfico a su modelo sea constante a lo largo del día, habrá un exceso de capacidad no utilizada. Esto conduce a una baja utilización y desperdicio de recursos. Con SageMaker, puede configurar diferentes opciones de escala según el patrón de tráfico esperado. El escalado simple o el escalado de seguimiento de objetivos es ideal cuando desea escalar en función de una métrica de CloudWatch específica. Puede hacerlo eligiendo una métrica específica y estableciendo valores de umbral. Las métricas recomendadas para esta opción son promedio Si necesita una configuración avanzada, puede establecer una política de escalado por pasos para ajustar dinámicamente la cantidad de instancias para escalar en función del tamaño de la infracción de alarma. Esto le ayuda a configurar una respuesta más agresiva cuando la demanda alcanza cierto nivel. Puede usar una opción de escalado programado cuando sabe que la demanda sigue un programa particular en el día, la semana, el mes o el año. Esto lo ayuda a especificar una programación única o recurrente o expresiones cron junto con las horas de inicio y finalización, que forman los límites de cuándo se inicia y se detiene la acción de escalado automático. Para más detalles, consulte Configuración de puntos de enlace de inferencia de ajuste de escala automático en Amazon SageMaker y Realice pruebas de carga y optimice un punto de enlace de Amazon SageMaker mediante el escalado automático. |
| Patrón de tráfico | La inferencia en tiempo real es ideal para cargas de trabajo con un patrón de tráfico continuo o regular. |
Inferencia asíncrona en SageMaker
La inferencia asíncrona de SageMaker es una nueva capacidad de SageMaker que pone en cola las solicitudes entrantes y las procesa de forma asíncrona. Esta opción es ideal para solicitudes con grandes tamaños de carga útil (hasta 1 GB), largos tiempos de procesamiento (hasta 15 minutos) y requisitos de latencia casi en tiempo real. Las cargas de trabajo de ejemplo para la inferencia asincrónica incluyen empresas de atención médica que procesan imágenes biomédicas de alta resolución o videos como ecocardiogramas para detectar anomalías. Estas aplicaciones reciben ráfagas de tráfico entrante en diferentes momentos del día y requieren procesamiento casi en tiempo real a bajo costo. Los tiempos de procesamiento de estas solicitudes pueden oscilar en el orden de los minutos, lo que elimina la necesidad de ejecutar inferencias en tiempo real. En su lugar, las cargas útiles de entrada se pueden procesar de forma asíncrona desde un almacén de objetos como Amazon S3 con colas automáticas y un umbral de simultaneidad predefinido. Tras el procesamiento, SageMaker coloca la respuesta de inferencia en la ubicación de Amazon S3 devuelta anteriormente. Opcionalmente, puede optar por recibir notificaciones de éxito o error a través de Servicio de notificación simple de Amazon (red social de Amazon).
La siguiente tabla proporciona orientación sobre cómo evaluar la inferencia asincrónica de SageMaker en función de las funciones de aptitud.
| Función de la aptitud | Descripción |
| Cost | La inferencia asíncrona es una excelente opción para cargas de trabajo sensibles a los costos con grandes cargas útiles y tráfico de ráfagas. La inferencia asincrónica le permite ahorrar costos al escalar automáticamente el recuento de instancias a cero cuando no hay solicitudes para procesar, por lo que solo paga cuando su punto final procesa solicitudes. Las solicitudes que se reciben cuando no hay instancias se ponen en cola para su procesamiento después de que el punto final se amplía. |
| latencia de inferencia | La inferencia asíncrona es ideal para los requisitos de latencia casi en tiempo real. Las solicitudes se colocan en una cola y se procesan tan pronto como el cálculo esté disponible. Esto normalmente resulta en decenas de milisegundos en latencia. |
| rendimiento | La inferencia asíncrona es ideal para casos de uso sensibles a la latencia, porque las aplicaciones no tienen que comprometer el rendimiento. Las solicitudes no se descartan durante los picos de tráfico porque el extremo de inferencia asincrónica pone en cola las solicitudes en lugar de descartarlas. |
| Complejidad de configuración escalable |
SageMaker admite escalado automático para punto final asíncrono. A diferencia de los puntos finales alojados en tiempo real, los puntos finales de inferencia asíncrona admiten la reducción de instancias a cero al establecer la capacidad mínima en cero. Para puntos finales asincrónicos, SageMaker recomienda enfáticamente que cree una configuración de política para escalar el seguimiento de destino para un modelo implementado (variante). Para los casos de uso que pueden tolerar una penalización de inicio en frío de unos pocos minutos, opcionalmente puede reducir el recuento de instancias del punto final a cero cuando no haya solicitudes pendientes y escalar de nuevo a medida que lleguen nuevas solicitudes para que solo pague por la duración que el los puntos finales están procesando activamente las solicitudes. |
| Patrón de tráfico | Los puntos finales asíncronos ponen en cola las solicitudes entrantes y las procesan de forma asíncrona. Son una buena opción para patrones de tráfico intermitentes o poco frecuentes. |
Inferencia por lotes en SageMaker
La transformación por lotes de SageMaker es ideal para predicciones fuera de línea en grandes lotes de datos que están disponibles por adelantado. La característica de transformación por lotes es un método de alto rendimiento y alto rendimiento para transformar datos y generar inferencias. Es ideal para escenarios en los que maneja grandes lotes de datos, no necesita una latencia inferior a un segundo o necesita preprocesar y transformar los datos de entrenamiento. Los clientes en ciertos dominios, como la publicidad y el marketing o la atención médica, a menudo necesitan hacer predicciones fuera de línea en conjuntos de datos de hiperescala donde el alto rendimiento suele ser el objetivo del caso de uso y la latencia no es una preocupación.
Cuando se inicia un trabajo de transformación por lotes, SageMaker inicializa las instancias informáticas y distribuye la carga de trabajo de inferencia entre ellas. Libera los recursos cuando se completan los trabajos, por lo que solo paga por lo que se utilizó durante la ejecución de su trabajo. Cuando se completa el trabajo, SageMaker guarda los resultados de la predicción en un depósito de S3 que usted especifique. Las tareas de inferencia por lotes suelen ser buenas candidatas para el escalado horizontal. Cada trabajador dentro de un clúster puede operar en un subconjunto diferente de datos sin necesidad de intercambiar información con otros trabajadores. AWS ofrece varias opciones de almacenamiento y computación que permiten el escalado horizontal. Las cargas de trabajo de ejemplo para la transformación por lotes de SageMaker incluyen aplicaciones fuera de línea, como aplicaciones bancarias para predecir la rotación de clientes, donde se puede programar un trabajo fuera de línea para que se ejecute periódicamente.
La siguiente tabla proporciona orientación sobre cómo evaluar la transformación por lotes de SageMaker en función de las funciones de aptitud.
| Función de la aptitud | Descripción |
| Cost | La transformación por lotes de SageMaker le permite ejecutar predicciones en conjuntos de datos de lotes grandes o pequeños. Se le cobra por el tipo de instancia que elija, según la duración del uso. SageMaker administra el aprovisionamiento de recursos al comienzo del trabajo y los libera cuando finaliza el trabajo. No hay costo adicional de procesamiento de datos. |
| latencia de inferencia | Puede utilizar invocaciones programadas o basadas en eventos. La latencia puede variar según el tamaño de los datos de inferencia, la simultaneidad del trabajo, la complejidad del modelo y la capacidad de la instancia informática. |
| rendimiento |
Los trabajos de transformación por lotes se pueden realizar en una variedad de conjuntos de datos, desde petabytes de datos hasta conjuntos de datos muy pequeños. No es necesario cambiar el tamaño de conjuntos de datos más grandes en pequeños fragmentos de datos. Puede acelerar los trabajos de transformación por lotes utilizando valores óptimos para parámetros como Carga máxima en MB, MaxConcurrentTransformsMaxConcurrentTransformso Estrategia por lotes. El valor ideal para El procesamiento por lotes puede aumentar el rendimiento y optimizar sus recursos porque ayuda a completar una mayor cantidad de inferencias en un cierto período de tiempo a expensas de la latencia. Para optimizar la implementación del modelo para un mayor rendimiento, la pauta general es aumentar el tamaño del lote hasta que el rendimiento disminuya. |
| Complejidad de configuración escalable | La transformación por lotes de SageMaker se utiliza para la inferencia fuera de línea que no es sensible a la latencia. |
| Patrón de tráfico | Para la inferencia fuera de línea, se programa o inicia un trabajo de transformación por lotes mediante un desencadenador basado en eventos. |
Inferencia sin servidor en SageMaker
La inferencia sin servidor de SageMaker le permite implementar modelos ML para la inferencia sin tener que configurar o administrar la infraestructura subyacente. Según el volumen de solicitudes de inferencia que recibe su modelo, la inferencia sin servidor de SageMaker aprovisiona, escala y desactiva automáticamente la capacidad informática. Como resultado, solo paga por el tiempo de cómputo para ejecutar su código de inferencia y la cantidad de datos procesados, no por el tiempo de inactividad. Puede usar los algoritmos integrados de SageMaker y los contenedores de servicio del marco de ML para implementar su modelo en un punto final de inferencia sin servidor o elegir traer su propio contenedor. Si el tráfico se vuelve predecible y estable, puede actualizar fácilmente desde un punto final de inferencia sin servidor a un punto final en tiempo real de SageMaker sin necesidad de realizar cambios en la imagen de su contenedor. Con la inferencia sin servidor, también se beneficia de otras funciones de SageMaker, incluidas las métricas integradas, como el recuento de invocaciones, las fallas, la latencia, las métricas de host y los errores en CloudWatch.
La siguiente tabla proporciona orientación sobre cómo evaluar la inferencia sin servidor de SageMaker en función de las funciones de aptitud.
| Función de la aptitud | Descripción |
| Cost | Con un modelo de pago por uso, la inferencia sin servidor es una opción rentable si tiene patrones de tráfico poco frecuentes o intermitentes. Solo paga por la duración durante la cual el punto final procesa la solicitud y, por lo tanto, puede ahorrar costos si el patrón de tráfico es intermitente. |
| latencia de inferencia |
Los puntos finales sin servidor ofrecen una latencia de inferencia baja (del orden de milisegundos a segundos), con la capacidad de escalar instantáneamente de decenas a miles de inferencias en segundos según los patrones de uso, lo que lo hace ideal para aplicaciones ML con tráfico intermitente o impredecible. Debido a que los puntos finales sin servidor aprovisionan recursos informáticos a pedido, su punto final puede experimentar algunos segundos adicionales de latencia (inicio en frío) para la primera invocación después de un período de inactividad. El tiempo de inicio en frío depende del tamaño de su modelo, cuánto tiempo lleva descargar su modelo y el tiempo de inicio de su contenedor. |
| rendimiento | Al configurar su punto final sin servidor, puede especificar el tamaño de la memoria y la cantidad máxima de invocaciones simultáneas. La inferencia sin servidor de SageMaker asigna automáticamente recursos informáticos proporcionales a la memoria que seleccione. Si elige un tamaño de memoria más grande, su contenedor tiene acceso a más vCPU. Como regla general, el tamaño de la memoria debe ser al menos tan grande como el tamaño de su modelo. Los tamaños de memoria que puede elegir son 1024 MB, 2048 MB, 3072 MB, 4096 MB, 5120 MB y 6144 MB. Independientemente del tamaño de memoria que elija, los puntos finales sin servidor tienen 5 GB de almacenamiento en disco efímero disponible. |
| Complejidad de configuración escalable | Los puntos finales sin servidor inician automáticamente los recursos informáticos y los escalan hacia adentro y hacia afuera según el tráfico, lo que elimina la necesidad de elegir tipos de instancias o administrar políticas de escalado. Esto elimina el trabajo pesado indiferenciado de seleccionar y administrar servidores. |
| Patrón de tráfico | La inferencia sin servidor es ideal para cargas de trabajo con patrones de tráfico poco frecuentes o intermitentes. |
Patrones de diseño de hospedaje de modelos en SageMaker
Los extremos de inferencia de SageMaker usan contenedores Docker para hospedar modelos de aprendizaje automático. Los contenedores le permiten empaquetar software en unidades estandarizadas que se ejecutan de manera uniforme en cualquier plataforma compatible con Docker. Esto garantiza la portabilidad entre plataformas, implementaciones de infraestructura inmutable y una administración de cambios e implementaciones de CI/CD más sencillas. SageMaker proporciona contenedores administrados preconstruidos para marcos populares como Apache MXNet, TensorFlow, PyTorch, Sklearn y Hugging Face. Para obtener una lista completa de las imágenes de contenedor de SageMaker disponibles, consulte Imágenes de contenedores de aprendizaje profundo disponibles. En el caso de que SageMaker no tenga un contenedor compatible, también puede crear su propio contenedor (BYOC) y enviar su propia imagen personalizada, instalando las dependencias necesarias para su modelo.
Para implementar un modelo en SageMaker, necesita un contenedor (contenedores de marco administrado de SageMaker o BYOC) y una instancia informática para alojar el contenedor. SageMaker admite varias opciones avanzadas para patrones de diseño de hospedaje de modelos de aprendizaje automático comunes en los que los modelos se pueden hospedar en un solo contenedor o cohospedar en un contenedor compartido.
Una aplicación de ML en tiempo real puede usar un solo modelo o varios modelos para atender una sola solicitud de predicción. El siguiente diagrama muestra varios escenarios de inferencia para una aplicación ML.

Exploremos una opción de alojamiento de SageMaker adecuada para cada uno de los escenarios de inferencia anteriores. Puede consultar las funciones de aptitud para evaluar si es la opción correcta para el caso de uso dado.
Hospedaje de una aplicación de aprendizaje automático basada en un solo modelo
Hay varias opciones para hospedar aplicaciones de aprendizaje automático basadas en un solo modelo mediante los servicios de hospedaje de SageMaker, según el escenario de implementación.
Endpoint de modelo único
Los extremos de un solo modelo de SageMaker le permiten alojar un modelo en un contenedor alojado en instancias dedicadas para lograr una baja latencia y un alto rendimiento. Estos puntos finales están totalmente administrados y admiten el escalado automático. Puede configurar el punto final de modelo único como un punto final aprovisionado en el que pasa la configuración de la infraestructura del punto final, como el tipo y el recuento de instancias, o un punto final sin servidor en el que SageMaker inicia automáticamente los recursos informáticos y los escala hacia adentro y hacia afuera según el tráfico, eliminando la necesidad para elegir tipos de instancias o administrar políticas de escalado. Los puntos finales sin servidor son para aplicaciones con tráfico intermitente o impredecible.
El siguiente diagrama muestra escenarios de inferencia de punto final de modelo único.

La siguiente tabla proporciona orientación sobre la evaluación de las funciones de aptitud para un punto final de modelo único aprovisionado. Para las evaluaciones de la función de aptitud de los puntos finales sin servidor, consulte la sección de puntos finales sin servidor en esta publicación.
| Función de la aptitud | Descripción |
| Cost | Se le cobra por el uso del tipo de instancia que elija. Debido a que el punto final siempre está en funcionamiento y disponible, los costos pueden acumularse rápidamente. Elegir la instancia correcta para su modelo ayuda a garantizar que tenga la instancia de mayor rendimiento al menor costo para sus modelos. Se recomienda el escalado automático para ajustar dinámicamente la capacidad según el tráfico para mantener un rendimiento constante y predecible al menor costo posible. |
| latencia de inferencia | Un punto final de modelo único proporciona inferencia síncrona, interactiva y en tiempo real con requisitos de latencia de milisegundos. |
| rendimiento | El rendimiento puede verse afectado por varios factores, como el tamaño de entrada del modelo, el tamaño del lote, el tipo de instancia de punto final, etc. Se recomienda revisar las métricas de CloudWatch para las solicitudes de entrada y la utilización de recursos, y seleccionar el tipo de instancia adecuado para lograr un rendimiento óptimo. SageMaker proporciona funciones para administrar recursos y optimizar el rendimiento de la inferencia al implementar modelos de ML. Usted puede optimizar el rendimiento del modelo con Neoo utilice instancias Inf1 para mejorar el rendimiento de sus modelos alojados en SageMaker mediante una instancia de GPU para su terminal. |
| Complejidad de configuración escalable | El escalado automático es compatible de fábrica. SageMaker recomienda elegir un adecuado configuración de escalado mediante la realización de pruebas de carga. |
| Patrón de tráfico | Un punto final de modelo único es ideal para cargas de trabajo con patrones de tráfico predecibles. |
Co-anfitrión de múltiples modelos
Cuando se trata de una gran cantidad de modelos, implementar cada uno en un punto final individual con un contenedor e instancia dedicados puede generar un aumento significativo en el costo. Además, también se vuelve difícil administrar tantos modelos en producción, específicamente cuando no necesita invocar todos los modelos al mismo tiempo, pero aún necesita que estén disponibles en todo momento. El alojamiento conjunto de varios modelos en los mismos recursos informáticos subyacentes facilita la gestión de las implementaciones de ML a escala y reduce los costos de alojamiento mediante un mayor uso del punto final y sus recursos informáticos subyacentes. SageMaker es compatible con opciones avanzadas de cohospedaje de modelos, como punto final multimodelo (MME) para modelos homogéneos y punto final multicontenedor (MCE) para modelos heterogéneos. Los modelos homogéneos usan el mismo marco de ML en un contenedor de servicio compartido, mientras que los modelos heterogéneos le permiten implementar múltiples contenedores de servicio que usan diferentes modelos o marcos en un único punto final.
El siguiente diagrama muestra las opciones de alojamiento compartido de modelos mediante SageMaker.
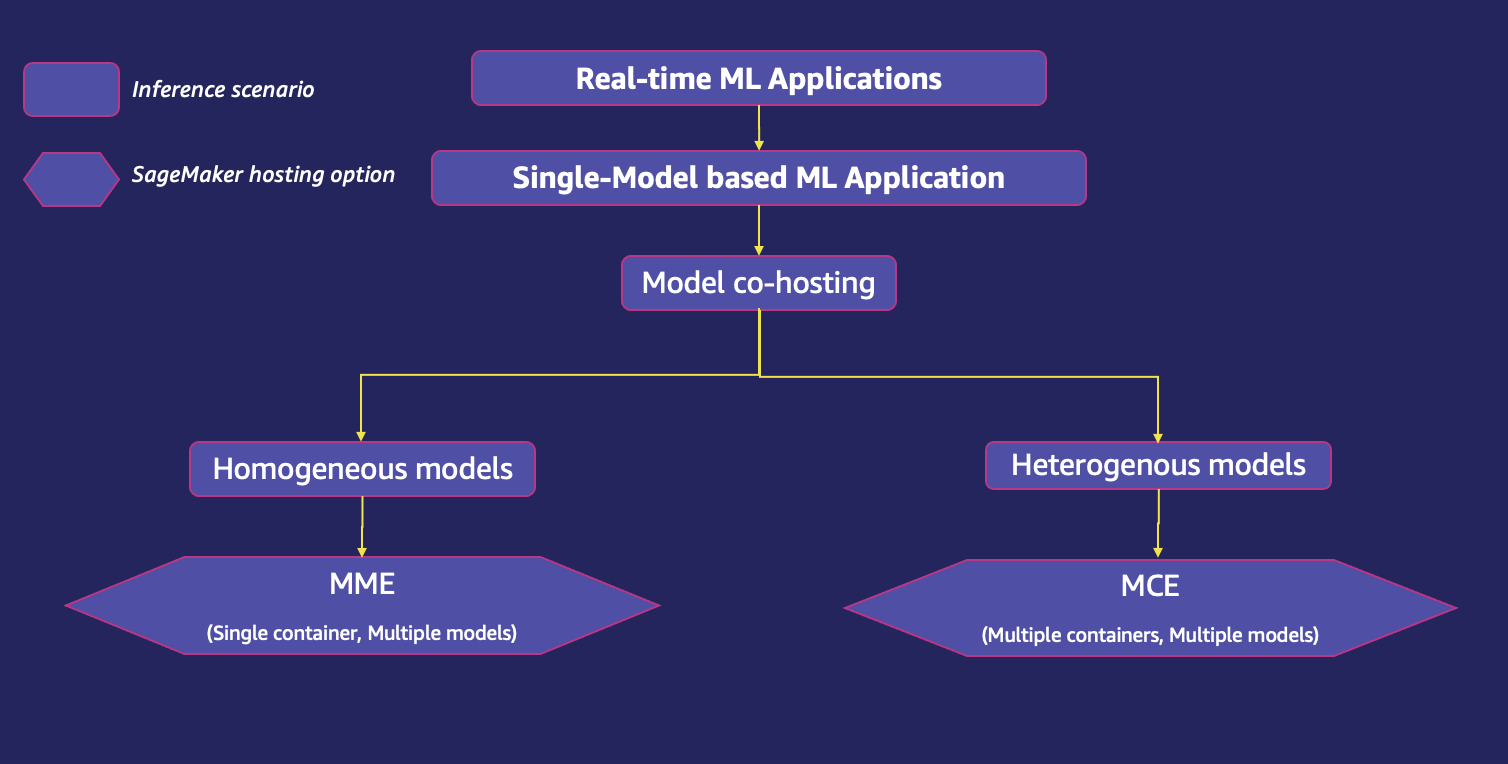
Puntos finales de varios modelos de SageMaker
SageMaker MME le permite alojar múltiples modelos utilizando un contenedor de servicio compartido en un solo punto final. Esta es una solución escalable y rentable para implementar una gran cantidad de modelos que se adaptan al mismo caso de uso, marco o lógica de inferencia. Los MME pueden atender solicitudes dinámicamente según el modelo invocado por la persona que llama. También reduce la sobrecarga de implementación porque SageMaker administra la carga de modelos en la memoria y los escala en función de los patrones de tráfico hacia ellos. Esta característica es ideal cuando tiene una gran cantidad de modelos similares que puede servir a través de un contenedor de servicio compartido y no necesita acceder a todos los modelos al mismo tiempo. Los puntos finales de varios modelos también permiten el uso compartido de recursos de memoria en todos sus modelos. Esto funciona mejor cuando los modelos son bastante similares en tamaño y latencia de invocación, lo que permite que las MME utilicen las instancias de manera efectiva en todos los modelos. Los MME de SageMaker admiten el alojamiento de modelos respaldados por CPU y GPU. Mediante el uso de modelos respaldados por GPU, puede reducir los costos de implementación de su modelo a través de un mayor uso del punto final y sus instancias informáticas aceleradas subyacentes. Para un caso de uso real de MME, consulte Cómo escalar la inferencia de aprendizaje automático para casos de uso de SaaS multiinquilino.
La siguiente tabla proporciona orientación sobre la evaluación de las funciones de aptitud para las MME.
| Función de la aptitud | Descripción |
| Cost |
Los MME permiten usar un contenedor de servicio compartido para alojar miles de modelos en un solo punto final. Esto reduce significativamente los costos de hospedaje al mejorar la utilización de puntos finales en comparación con el uso de puntos finales de modelo único. Por ejemplo, si tiene 10 modelos para implementar usando una instancia ml.c5.large, según Precios de SageMaker, el costo de tener 10 puntos de conexión persistentes de un solo modelo es: 10 * 0.102 USD = 1.02 USD por hora. Mientras que con un MME que aloja los 10 modelos, logramos un ahorro de costos 10 veces mayor: 1 * $0.102 = $0.102 por hora. |
| latencia de inferencia |
De forma predeterminada, los MME almacenan en caché los modelos de uso frecuente en la memoria y en el disco para proporcionar una inferencia de baja latencia. Los modelos almacenados en caché se descargan o eliminan del disco solo cuando un contenedor se queda sin memoria o espacio en disco para acomodar un nuevo modelo de destino. Los MME permiten la carga diferida de modelos, lo que significa que los modelos se cargan en la memoria cuando se invocan por primera vez. Esto optimiza la utilización de la memoria; sin embargo, provoca picos de tiempo de respuesta en la primera carga, lo que genera un problema de arranque en frío. Por lo tanto, los MME también se adaptan bien a escenarios que pueden tolerar penalizaciones de latencia relacionadas con el arranque en frío ocasionales que ocurren cuando se invocan modelos que se usan con poca frecuencia. Para cumplir con los objetivos de latencia y rendimiento de las aplicaciones de ML, se prefieren las instancias de GPU a las instancias de CPU (dada la potencia computacional que ofrecen las GPU). Con la compatibilidad con MME para GPU, puede implementar miles de modelos de aprendizaje profundo detrás de un punto final de SageMaker. Los MME pueden ejecutar varios modelos en un núcleo de GPU, compartir instancias de GPU detrás de un punto final en varios modelos y cargar y descargar dinámicamente modelos en función del tráfico entrante. Con esto, puede ahorrar costos significativamente y lograr la mejor relación precio-rendimiento. Si su caso de uso exige transacciones por segundo (TPS) o requisitos de latencia significativamente más altos, le recomendamos que aloje los modelos en puntos finales dedicados. |
| rendimiento |
Un valor ideal del rendimiento de inferencia de MME depende de factores como el modelo, el tamaño de la carga útil y el tipo de instancia de punto final. Una mayor cantidad de memoria de instancia le permite tener más modelos cargados y listos para atender solicitudes de inferencia. No necesita perder tiempo cargando el modelo. Una mayor cantidad de vCPU le permite invocar más modelos únicos al mismo tiempo. Los MME cargan y descargan dinámicamente el modelo hacia y desde la memoria de la instancia, lo que puede afectar el rendimiento de E/S. Los MME de SageMaker con GPU funcionan con Servidor de inferencia NVIDIA Triton, que es un software de servicio de inferencia de código abierto que simplifica el proceso de servicio de inferencia y proporciona un alto rendimiento de inferencia. SageMaker carga el modelo en la memoria del contenedor NVIDIA Triton en una instancia acelerada por GPU y atiende la solicitud de inferencia. El núcleo de GPU es compartido por todos los modelos en una instancia. Si el modelo ya está cargado en la memoria del contenedor, las solicitudes posteriores se atienden más rápido porque SageMaker no necesita descargarlo y cargarlo nuevamente. Se recomienda realizar pruebas y análisis de rendimiento adecuados en implementaciones de producción exitosas. SageMaker proporciona métricas de CloudWatch para puntos finales de varios modelos para que pueda determinar el uso del punto final y la tasa de aciertos de caché para ayudar a optimizar su punto final. |
| Complejidad de configuración escalable | Los terminales multimodelo de SageMaker son totalmente compatibles con el escalado automático, que administra réplicas de modelos para garantizar que los modelos se escalen en función de los patrones de tráfico. Sin embargo, se recomienda una prueba de carga adecuada para determinar el tamaño óptimo de las instancias para escalar automáticamente el punto final. Es importante dimensionar correctamente la flota de MME para evitar la descarga de demasiados modelos. Cargar cientos de modelos en unas pocas instancias más grandes puede conducir a la limitación en algunos casos, y podría ser preferible usar más instancias y más pequeñas. Para aprovechar el escalado automático de modelos en SageMaker, asegúrese de tener configuración de escalado automático de instancias para aprovisionar capacidad de instancia adicional. Configure su política de escalado a nivel de punto final con parámetros personalizados o invocaciones por minuto (recomendado) para agregar más instancias a la flota de puntos finales. Las tasas de invocación utilizadas para desencadenar un evento de escalado automático se basan en el conjunto agregado de predicciones en el conjunto completo de modelos servidos por el punto final. |
| Patrón de tráfico | Los MME son ideales cuando tiene una gran cantidad de modelos de tamaño similar que puede servir a través de un contenedor de servicio compartido y no necesita acceder a todos los modelos al mismo tiempo. |
Puntos finales de varios contenedores de SageMaker
SageMaker MCE Admite la implementación de hasta 15 contenedores que usan diferentes modelos o marcos en un único punto final, y los invoca de forma independiente o en secuencia para lograr inferencias de baja latencia y ahorrar costos. Los modelos pueden ser completamente heterogéneos, con su propia pila de servicio independiente. Alojar de forma segura varios modelos de diferentes marcos en una sola instancia podría ahorrarle hasta un 90 % en costos.
Los patrones de invocación de MCE son los siguientes:
- Canalizaciones de inferencia – Los contenedores en un MME se pueden invocar en una secuencia lineal, también conocida como canalización de inferencia en serie. Por lo general, se utilizan para separar el preprocesamiento, la inferencia de modelos y el posprocesamiento en contenedores independientes. La salida del contenedor actual se pasa como entrada al siguiente. Se representan como un único modelo de canalización en SageMaker. Una canalización de inferencia se puede implementar como un MME, donde uno de los contenedores de la canalización puede atender solicitudes de forma dinámica en función del modelo que se invoque.
- Invocación directa - Con invocación directa, se puede enviar una solicitud a un contenedor de inferencia específico alojado en un MCE.
La siguiente tabla proporciona orientación sobre la evaluación de las funciones de aptitud para los MCE.
| Función de la aptitud | Descripción |
| Cost | Los MCE le permiten ejecutar hasta 15 contenedores ML diferentes en un solo punto final e invocarlos de forma independiente, lo que ahorra costos. Esta opción es ideal cuando tiene varios modelos que se ejecutan en diferentes pilas de servicio con necesidades de recursos similares y cuando los modelos individuales no tienen suficiente tráfico para utilizar la capacidad total de las instancias de punto final. Por lo tanto, los MCE son más rentables que un punto final de modelo único. Los MCE ofrecen una respuesta de inferencia síncrona, lo que significa que el punto final siempre está disponible y usted paga por el tiempo de actividad de la instancia. El costo puede aumentar según el número y el tipo de instancias. |
| latencia de inferencia | Los MCE son ideales para ejecutar aplicaciones de ML con diferentes marcos y algoritmos de ML para cada modelo a los que se accede con poca frecuencia pero que aún requieren una inferencia de baja latencia. Los modelos siempre están disponibles para la inferencia de baja latencia y no hay problema de arranque en frío. |
| rendimiento | Los MCE están limitados a un máximo de 15 contenedores en un punto final de varios contenedores, y la inferencia de GPU no se admite debido a la contención de recursos. Para puntos finales de varios contenedores que utilizan el modo de invocación directa, SageMaker no solo proporciona métricas a nivel de instancia como lo hace con otros puntos finales comunes, sino que también admite métricas por contenedor. Como práctica recomendada, revise las métricas de CloudWatch para las solicitudes de entrada y la utilización de recursos, y seleccione el tipo de instancia adecuado para lograr un rendimiento óptimo. |
| Complejidad de configuración escalable | Los MCE admiten el escalado automático. Sin embargo, para configurar el escalado automático, se recomienda que el modelo en cada contenedor muestre una latencia y una utilización de CPU similares en cada solicitud de inferencia. Esto se recomienda porque si el tráfico al punto final de varios contenedores cambia de un modelo de uso bajo de la CPU a un modelo de uso alto de la CPU, pero el volumen general de llamadas sigue siendo el mismo, el punto final no escala horizontalmente y es posible que no haya suficientes instancias. para manejar todas las solicitudes al modelo de alta utilización de CPU. |
| Patrón de tráfico | Los MCE son ideales para cargas de trabajo con patrones de tráfico continuos o regulares, para alojar modelos en diferentes marcos (como TensorFlow, PyTorch o Sklearn) que pueden no tener suficiente tráfico para saturar la capacidad total de una instancia de punto final. |
Hospedaje de una aplicación de aprendizaje automático basada en varios modelos
Muchas aplicaciones comerciales necesitan usar múltiples modelos de ML para atender una sola solicitud de predicción a sus consumidores. Por ejemplo, una empresa minorista que quiere brindar recomendaciones a sus usuarios. La aplicación ML en este caso de uso puede querer usar diferentes modelos personalizados para recomendar diferentes categorías de productos. Si la empresa desea agregar personalización a las recomendaciones mediante el uso de información de usuario individual, la cantidad de modelos personalizados aumenta aún más. Hospedar cada modelo personalizado en una instancia informática distinta no solo tiene un costo prohibitivo, sino que también genera una infrautilización de los recursos de hospedaje si no se usan todos los modelos con frecuencia. SageMaker ofrece opciones de hospedaje eficientes para aplicaciones de aprendizaje automático basadas en varios modelos.
El siguiente diagrama muestra opciones de hospedaje de varios modelos para un único punto de conexión con SageMaker.

Canalización de inferencia en serie
Una canalización de inferencia es un modelo de SageMaker que se compone de una secuencia lineal de 2 a 15 contenedores que procesan solicitudes de inferencias sobre datos. Utiliza una canalización de inferencia para definir e implementar cualquier combinación de algoritmos integrados de SageMaker entrenados previamente y sus propios algoritmos personalizados empaquetados en contenedores de Docker. Puede usar una canalización de inferencia para combinar tareas de ciencia de datos de preprocesamiento, predicciones y posprocesamiento. La salida de un contenedor se pasa como entrada al siguiente. Al definir los contenedores para un modelo de canalización, también especifica el orden en que se ejecutan los contenedores. Se representan como un único modelo de canalización en SageMaker. La canalización de inferencia se puede implementar como un MME, donde uno de los contenedores de la canalización puede atender solicitudes de forma dinámica en función del modelo que se invoque. También puede ejecutar un transformación por lotes trabajo con una canalización de inferencia. Las canalizaciones de inferencia están completamente administradas.
La siguiente tabla proporciona orientación sobre cómo evaluar las funciones de adecuación para el hospedaje de modelos de ML mediante una canalización de inferencia en serie.
| Función de la aptitud | Descripción |
| Cost | La canalización de inferencia en serie le permite ejecutar hasta 15 contenedores de ML diferentes en un único punto de conexión, lo que genera rentabilidad al hospedar los contenedores de inferencia. No hay costos adicionales por usar esta función. Solo paga por las instancias que se ejecutan en un punto final. El costo puede aumentar según el número y el tipo de instancias. |
| latencia de inferencia | Cuando una aplicación de ML se implementa como canalización de inferencia, los datos entre diferentes modelos no abandonan el espacio del contenedor. El procesamiento de características y las inferencias se ejecutan con baja latencia porque los contenedores están ubicados en las mismas instancias EC2. |
| rendimiento | Dentro de un modelo de canalización de inferencia, SageMaker maneja las invocaciones como una secuencia de solicitudes HTTP. El primer contenedor de la canalización maneja la solicitud inicial, luego la respuesta intermedia se envía como una solicitud al segundo contenedor, y así sucesivamente, para cada contenedor de la canalización. SageMaker devuelve la respuesta final al cliente. El rendimiento depende de factores como el modelo, el tamaño de entrada del modelo, el tamaño del lote y el tipo de instancia de punto final. Como práctica recomendada, revise las métricas de CloudWatch para las solicitudes de entrada y la utilización de recursos, y seleccione el tipo de instancia adecuado para lograr un rendimiento óptimo. |
| Complejidad de configuración escalable | Las canalizaciones de inferencia en serie admiten el escalado automático. Sin embargo, para configurar el escalado automático, se recomienda que el modelo en cada contenedor muestre una latencia y una utilización de CPU similares en cada solicitud de inferencia. Esto se recomienda porque si el tráfico al punto final de varios contenedores cambia de un modelo de uso bajo de la CPU a un modelo de uso alto de la CPU, pero el volumen general de llamadas sigue siendo el mismo, el punto final no escala y es posible que no haya suficientes instancias para manejar todas las solicitudes al modelo de alta utilización de CPU. |
Patrón de tráfico |
Las canalizaciones de inferencia en serie son ideales para patrones de tráfico predecibles con modelos que se ejecutan secuencialmente en el mismo punto final. |
Implementación de conjuntos de modelos (Triton DAG):
SageMaker ofrece integración con Servidor de inferencia NVIDIA Triton a Contenedores del servidor de inferencia Triton. Estos contenedores incluyen NVIDIA Triton Inference Server, soporte para marcos de ML comunes y variables de entorno útiles que le permiten optimizar el rendimiento en SageMaker. Con las imágenes de contenedor de NVIDIA Triton, puede servir fácilmente modelos ML y beneficiarse de las optimizaciones de rendimiento, el procesamiento por lotes dinámico y la compatibilidad con varios marcos que proporciona NVIDIA Triton. Triton ayuda a maximizar la utilización de GPU y CPU, lo que reduce aún más el costo de la inferencia.
En los casos de uso comercial donde las aplicaciones de ML usan varios modelos para atender una solicitud de predicción, si cada modelo usa un marco diferente o está alojado en una instancia separada, puede generar una mayor carga de trabajo y costos, así como un aumento en la latencia general. SageMaker NVIDIA Triton Inference Server admite la implementación de modelos de todos los marcos principales, como TensorFlow GraphDef, TensorFlow SavedModel, ONNX, PyTorch TorchScript, TensorRT y Python/C++, formatos de modelo y más. El conjunto de modelos Triton representa una canalización de uno o más modelos o lógica de preprocesamiento y posprocesamiento, y la conexión de los tensores de entrada y salida entre ellos. Una única solicitud de inferencia a un conjunto desencadena la ejecución de toda la canalización. Triton también tiene varios algoritmos de programación y procesamiento por lotes integrados que combinan solicitudes de inferencia individuales para mejorar el rendimiento de la inferencia. Estas decisiones de programación y procesamiento por lotes son transparentes para el cliente que solicita la inferencia. Los modelos se pueden ejecutar en CPU o GPU para obtener la máxima flexibilidad y admitir requisitos informáticos heterogéneos.
El alojamiento de múltiples modelos respaldados por GPU en puntos finales de múltiples modelos es compatible a través de la Servidor de inferencia SageMaker Triton. El servidor de inferencia NVIDIA Triton se ha ampliado para implementar un Contrato API MME, para integrarse con las MME. Puede usar NVIDIA Triton Inference Server, que crea una configuración de repositorio de modelos para diferentes backends de marco, para implementar un MME con escalado automático. Esta característica le permite escalar cientos de modelos hiperpersonalizados que están ajustados para satisfacer las experiencias únicas del usuario final en aplicaciones de IA. También puede usar esta característica para lograr el rendimiento de precio necesario para su aplicación de inferencia usando GPU fraccionarias. Para obtener más información, consulte Ejecute varios modelos de aprendizaje profundo en GPU con puntos de enlace de varios modelos de Amazon SageMaker.
La siguiente tabla proporciona orientación sobre cómo evaluar las funciones de aptitud para el hospedaje de modelos de ML mediante MME con compatibilidad con GPU en contenedores de inferencia Triton. Para obtener información sobre las evaluaciones de la función de aptitud de los puntos finales de modelo único y los puntos finales sin servidor, consulte las secciones anteriores de esta publicación.
| Función de la aptitud | Descripción |
| Cost | Los MME de SageMaker compatibles con GPU que utilizan Triton Inference Server proporcionan una forma escalable y rentable de implementar una gran cantidad de modelos de aprendizaje profundo detrás de un punto final de SageMaker. Con MME, varios modelos comparten la instancia de GPU detrás de un punto final. Esto le permite romper el costo linealmente creciente de hospedar múltiples modelos y reutilizar la infraestructura en todos los modelos. Usted paga por el tiempo de actividad de la instancia. |
| latencia de inferencia |
SageMaker con Triton Inference Server está diseñado específicamente para maximizar el rendimiento y la utilización del hardware con una latencia de inferencia ultrabaja (milisegundos de un solo dígito). Tiene una amplia gama de marcos de ML compatibles (incluidos TensorFlow, PyTorch, ONNX, XGBoost y NVIDIA TensorRT) y backends de infraestructura, que incluyen GPU, CPU y GPU de NVIDIA. Inferencia de AWS. Con la compatibilidad con MME para GPU con SageMaker Triton Inference Server, puede implementar miles de modelos de aprendizaje profundo detrás de un punto final de SageMaker. SageMaker carga el modelo en la memoria del contenedor NVIDIA Triton en una instancia acelerada por GPU y atiende la solicitud de inferencia. El núcleo de GPU es compartido por todos los modelos en una instancia. Si el modelo ya está cargado en la memoria del contenedor, las solicitudes posteriores se atienden más rápido porque SageMaker no necesita descargarlo y cargarlo nuevamente. |
| rendimiento |
Los MME ofrecen capacidades para ejecutar múltiples modelos de aprendizaje profundo o ML en la GPU, al mismo tiempo, con Triton Inference Server. Esto le permite utilizar fácilmente el servicio de inferencia de alto rendimiento y multimarco NVIDIA Triton con la implementación del modelo completamente administrado de SageMaker. Triton es compatible con todas las inferencias basadas en NVIDIA GPU, x86, Arm® CPU y AWS Inferentia. Ofrece procesamiento por lotes dinámico, ejecuciones simultáneas, configuración óptima del modelo, conjunto de modelos y transmisión de entradas de audio y video para maximizar el rendimiento y la utilización. Otros factores, como la red y el tamaño de la carga útil, pueden desempeñar un papel mínimo en la sobrecarga asociada con la inferencia. |
| Complejidad de configuración escalable |
Los MME pueden escalar horizontalmente mediante una política de escalado automático y aprovisionar instancias informáticas de GPU adicionales en función de métricas como Con el servidor de inferencia Triton, puede crear fácilmente un contenedor personalizado que incluya su modelo con Triton y llevarlo a SageMaker. SageMaker Inference manejará las solicitudes y escalará automáticamente el contenedor a medida que aumente el uso, lo que facilitará la implementación del modelo con Triton en AWS. |
| Patrón de tráfico |
Los MME son ideales para patrones de tráfico predecibles con modelos que se ejecutan como DAG en el mismo punto final. SageMaker se ocupa de dar forma al tráfico en el punto final de MME y mantiene copias de modelo óptimas en las instancias de GPU para obtener el mejor rendimiento de precio. Continúa enrutando el tráfico a la instancia donde se carga el modelo. Si los recursos de la instancia alcanzan su capacidad debido a una alta utilización, SageMaker descarga los modelos menos utilizados del contenedor para liberar recursos para cargar modelos de uso más frecuente. |
Mejores prácticas
Considere las siguientes mejores prácticas:
- Alta cohesión y bajo acoplamiento entre modelos – Aloje los modelos en el mismo contenedor que tiene alta cohesión (impulsa la funcionalidad de un solo negocio) y encapsúlelos juntos para facilitar la actualización y la capacidad de administración. Al mismo tiempo, desacople esos modelos entre sí (alójelos en un contenedor diferente) para que pueda actualizar fácilmente un modelo sin afectar a otros modelos. Aloje varios modelos que utilicen diferentes contenedores detrás de un punto final y los invoque de forma independiente o agregue lógica de preprocesamiento y posprocesamiento del modelo como una canalización de inferencia en serie.
- latencia de inferencia – Agrupe los modelos impulsados por la funcionalidad de un solo negocio y alójelos en un solo contenedor para minimizar la cantidad de saltos y, por lo tanto, minimizar la latencia general. Hay otras advertencias, como si los modelos agrupados usan múltiples marcos; también puede optar por hospedar en varios contenedores, pero ejecutarlo en el mismo host para reducir la latencia y minimizar los costos.
- Agrupar lógicamente modelos de ML con alta cohesión – El grupo lógico puede estar formado por modelos que son homogéneos (por ejemplo, todos los modelos XGBoost) o heterogéneos (por ejemplo, algunos XGBoost y algunos BERT). Puede consistir en modelos que se comparten entre múltiples funcionalidades comerciales o puede ser específico para cumplir con una sola funcionalidad comercial.
- Modelos compartidos – Si el grupo lógico consta de modelos compartidos, la facilidad de actualización de los modelos y la latencia jugarán un papel importante en la arquitectura de los puntos finales de SageMaker. Por ejemplo, si la latencia es una prioridad, es mejor colocar todos los modelos en un solo contenedor detrás de un solo punto final de SageMaker para evitar múltiples saltos. La desventaja es que si es necesario actualizar alguno de los modelos, se actualizarán todos los terminales de SageMaker relevantes que alojan este modelo.
- Modelos no compartidos – Si el grupo lógico consta solo de modelos específicos de características empresariales y no se comparte con otros grupos, la complejidad del empaquetado y las dimensiones de latencia serán clave para lograrlo. Es aconsejable alojar estos modelos en un único contenedor detrás de un único punto final de SageMaker.
- Uso eficiente del hardware (CPU, GPU) – Agrupe los modelos basados en CPU y alójelos en el mismo host para que pueda usar la CPU de manera eficiente. Del mismo modo, agrupe los modelos basados en GPU para que pueda usarlos y escalarlos de manera eficiente. Hay cargas de trabajo híbridas que requieren CPU y GPU en el mismo host. El alojamiento de los modelos solo de CPU y solo de GPU en el mismo host debe estar impulsado por requisitos de alta cohesión y latencia de la aplicación. Además, el costo, la capacidad de escalar y el radio de explosión en el impacto en caso de falla son las dimensiones clave a considerar.
- Funciones de fitness – Utilice las funciones de fitness como guía para seleccionar una opción de alojamiento de ML.
Conclusión
Cuando se trata de alojamiento ML, no existe un enfoque único para todos. Los profesionales de ML deben elegir el patrón de diseño correcto para abordar sus desafíos de alojamiento de ML. La evaluación de las funciones de aptitud proporciona una guía prescriptiva para seleccionar la opción de alojamiento de ML adecuada.
Para obtener más detalles sobre cada una de las opciones de alojamiento, consulte las siguientes publicaciones de esta serie:
Sobre los autores
 Patel Dhawal es Arquitecto Principal de Aprendizaje Automático en AWS. Ha trabajado con organizaciones que van desde grandes empresas hasta empresas emergentes medianas en problemas relacionados con la computación distribuida y la inteligencia artificial. Se enfoca en el aprendizaje profundo, incluidos los dominios de NLP y Computer Vision. Ayuda a los clientes a lograr una inferencia de modelos de alto rendimiento en SageMaker.
Patel Dhawal es Arquitecto Principal de Aprendizaje Automático en AWS. Ha trabajado con organizaciones que van desde grandes empresas hasta empresas emergentes medianas en problemas relacionados con la computación distribuida y la inteligencia artificial. Se enfoca en el aprendizaje profundo, incluidos los dominios de NLP y Computer Vision. Ayuda a los clientes a lograr una inferencia de modelos de alto rendimiento en SageMaker.
 Deepali Rajale es Gerente Técnico de Cuentas Especialista en IA/ML en Amazon Web Services. Trabaja con clientes empresariales brindando orientación técnica sobre la implementación de soluciones de aprendizaje automático con las mejores prácticas. En su tiempo libre, le gusta caminar, ir al cine y salir con familiares y amigos.
Deepali Rajale es Gerente Técnico de Cuentas Especialista en IA/ML en Amazon Web Services. Trabaja con clientes empresariales brindando orientación técnica sobre la implementación de soluciones de aprendizaje automático con las mejores prácticas. En su tiempo libre, le gusta caminar, ir al cine y salir con familiares y amigos.
 Saurabh Trikande es gerente sénior de productos para Amazon SageMaker Inference. Le apasiona trabajar con clientes y está motivado por el objetivo de democratizar el aprendizaje automático. Se enfoca en los desafíos principales relacionados con la implementación de aplicaciones de ML complejas, modelos de ML de múltiples inquilinos, optimizaciones de costos y hacer que la implementación de modelos de aprendizaje profundo sea más accesible. En su tiempo libre, a Saurabh le gusta caminar, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
Saurabh Trikande es gerente sénior de productos para Amazon SageMaker Inference. Le apasiona trabajar con clientes y está motivado por el objetivo de democratizar el aprendizaje automático. Se enfoca en los desafíos principales relacionados con la implementación de aplicaciones de ML complejas, modelos de ML de múltiples inquilinos, optimizaciones de costos y hacer que la implementación de modelos de aprendizaje profundo sea más accesible. En su tiempo libre, a Saurabh le gusta caminar, aprender sobre tecnologías innovadoras, seguir TechCrunch y pasar tiempo con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/model-hosting-patterns-in-amazon-sagemaker-part-1-common-design-patterns-for-building-ml-applications-on-amazon-sagemaker/

