El aprendizaje por refuerzo (RL) abarca una clase de técnicas de aprendizaje automático (ML) que se pueden utilizar para resolver problemas de toma de decisiones secuenciales. Las técnicas de RL han encontrado aplicaciones generalizadas en numerosos dominios, incluidos los servicios financieros, la navegación autónoma, el control industrial y el comercio electrónico. El objetivo de un problema de RL es entrenar a un agente que, dada una observación de su entorno, elegirá la acción óptima que maximice la recompensa acumulada. Resolver un problema comercial con RL implica especificar el entorno del agente, el espacio de acciones, la estructura de las observaciones y la función de recompensa adecuada para el resultado comercial objetivo. En los métodos de RL basados en políticas, el resultado del entrenamiento del modelo suele ser una política, que define una distribución de probabilidad sobre las acciones dada una observación. La política óptima maximizará los rendimientos acumulados obtenidos por el agente.
En los problemas de toma de decisiones con restricciones, el agente tiene la tarea de elegir las acciones óptimas bajo restricciones. Existe una clase distinta de tales problemas en los que, según el estado, al agente solo se le puede permitir elegir entre un subconjunto de todas las acciones. Las demás acciones son inadmisibles.
Por ejemplo, considere un automóvil autónomo que tiene 10 niveles de velocidad posibles. Es posible que este automóvil solo pueda elegir entre un subconjunto de sus niveles de velocidad cuando atraviesa un vecindario residencial. Aquí, la restricción sobre los niveles de velocidad está determinada por la ubicación del automóvil. Tales restricciones parametrizadas sobre las acciones son comunes en muchos problemas del mundo real. Resolver tales problemas con RL requiere incorporar las restricciones en el proceso de capacitación. Enmascaramiento de acción es un enfoque para resolver problemas de RL que involucran restricciones de inadmisibilidad de una manera eficiente. Como sugiere el nombre, implica enmascarar cualquier acción inadmisible al establecer su probabilidad de muestreo en cero. La siguiente figura muestra el ciclo RL con enmascaramiento de acción. Consiste en un agente, las restricciones que determinan las máscaras de acción, las máscaras, las transiciones de estado y las recompensas observadas.
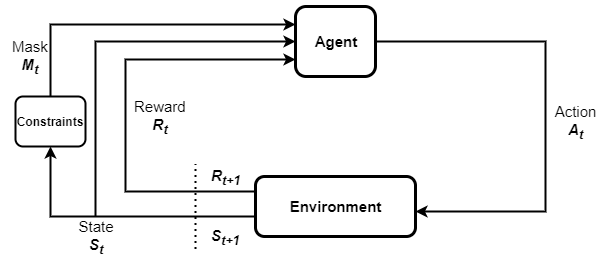
En esta publicación, describimos cómo implementar el enmascaramiento de acciones con Amazon SageMaker RL utilizando espacios de acción paramétricos en Ray RLlib. Describimos un problema de ejemplo que involucra espacios de acción multidimensionales discretos y múltiples restricciones. Para acceder al cuaderno completo de esta publicación, consulte el Ejemplo de cuaderno SageMaker en GitHub.
Resumen del caso de uso
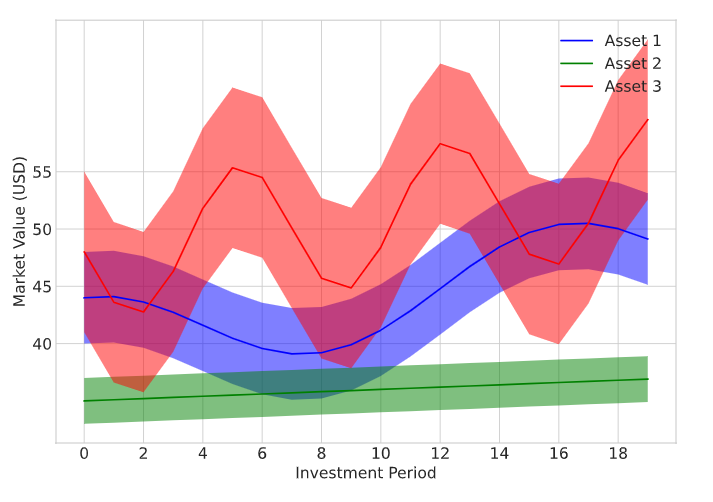
Consideramos un problema de optimización de cartera de ejemplo en el que un inversor negocia múltiples tipos de activos para maximizar el valor total de su cartera. La cartera consta de tres tipos de activos diferentes y un saldo de efectivo que simplemente se refiere al dinero que tiene en su cuenta bancaria. Durante cada período de inversión, el agente debe elegir la cantidad de cada tipo de activo que compra o vende. El agente utiliza el saldo de efectivo disponible para financiar cualquier compra de activos. También hay costos de transacción asociados con cada acción de compra/venta de activos. Se supone que el precio de mercado de cada activo varía a lo largo del tiempo. Los precios se muestrean aleatoriamente pero se modelan para mostrar un comportamiento distinto con diferentes niveles de volatilidad. Los rangos de precios para las tres clases de activos se muestran en la siguiente figura.
El conjunto de acciones admisibles para el agente está determinado por parámetros tales como el valor total actual de la cartera, el saldo de efectivo actual, la cantidad de cada tipo de activos mantenidos y su valor de mercado actual. Para este problema, aplicamos las siguientes restricciones a las posibles acciones:
- C1 – El agente no puede vender más unidades de ningún tipo de activo que las que posee actualmente. Por ejemplo, si el agente tiene 100 unidades del Activo 3 en el momento k en su cartera, entonces no puede vender 120 unidades de ese activo en ese momento.
- C2 – Los inversores consideran que el activo 3 es muy volátil. El agente no puede comprar el Activo 3 si el valor total de sus tenencias en el Activo 3 es superior a un tercio del valor total de su cartera.
- C3 – Los consumidores del modelo RL tienen una preferencia de riesgo moderada y consideran el Activo 2 una compra conservadora. Como resultado, el agente no puede comprar el Activo 2 cuando el valor total de las tenencias del Activo 2 supera las dos terceras partes del valor total de la cartera.
- C4 – El agente no puede comprar ningún activo si su saldo de efectivo actual es inferior a $1 USD.
Configurar el entorno
Para comenzar, aprovisione una instancia de notebook de SageMaker a través de Estudio Amazon SageMaker. Para más información, consulte la Usar instancias de cuadernos de Amazon SageMaker.
A continuación, implementamos el problema de negociación de cartera en una forma personalizada. Gimnasio abierto de IA y capacite a un agente de RL con SageMaker RL. Un entorno de gimnasio proporciona una interfaz para que el agente de RL interactúe con su entorno y genere recompensas y observaciones. El entorno para la negociación de la cartera se encuentra en el trading.py módulo. usamos el __init__ método para definir e inicializar algunos parámetros del entorno. Esto incluye los costos de transacción asociados con las acciones de compra/venta de activos, el valor medio de los precios de los activos, las variaciones de precios y más. También definimos los espacios de observación y acción en el __init__ método. Vea el siguiente código:
Debido a que el agente comercia con tres activos en un momento dado, las acciones realizadas por el agente se representan mediante un vector de acción tridimensional. Las tres acciones discretas que componen el vector de acción representan las transacciones en cada clase de activos y cada una puede tomar 11 valores posibles. Los 11 valores discretos codifican diferentes acciones de venta, compra y retención, como se muestra en la siguiente figura. Por ejemplo, elegir un1=3 se traduce en que el agente vende 20 unidades del tipo de activo 1. Los activos se compran y venden en múltiplos de 10.
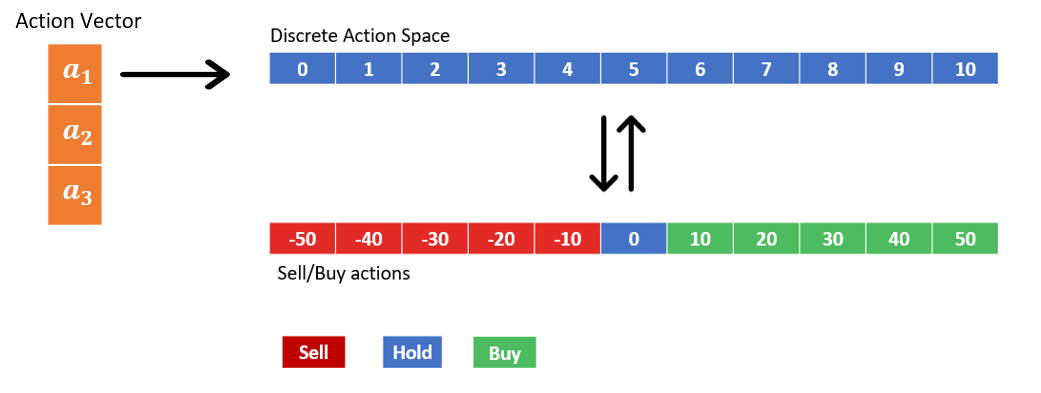
El espacio de observación tiene una estructura de diccionario con dos elementos. Estos representan el estado comercial actual y los valores de máscara de acción actuales. El estado comercial es un vector de 7 × 1 que consta de las cantidades de cada activo actualmente en poder del agente, el saldo de efectivo actual y el valor de mercado actual de cada uno de los tres activos. La máscara de acción es una matriz de 3×11 con valores de máscara correspondientes a cada acción posible. El entorno calcula los valores de la máscara en cada momento mediante un update_mask() método. A las acciones que violan cualquiera de las restricciones C1:C4 se les asigna una máscara cero. El valor de la máscara se establece en 1 para las acciones admisibles. Ver el siguiente código:
Al principio de cada episodio, un reset() Se llama al método para reinicializar el estado comercial, las observaciones y otros parámetros. El agente comienza cada episodio de capacitación con $1,000 USD en efectivo y cero tenencias en activos. Cada episodio consta de 20 períodos de inversión.
Al comienzo de cada período de inversión, el agente muestra una acción basada en las últimas observaciones que registró y actualiza su cartera. Esto se modela usando un step() método. Después de actualizar la cartera, volvemos a calcular el estado. La máscara de acción también se actualiza llamando al update_mask() método.
La función de recompensa se define como el valor total final de la cartera y se calcula al final de cada episodio, lo que sucede después de 20 períodos de inversión.
modelo de enmascaramiento
En cada paso de tiempo, el entorno devuelve el estado del diccionario y el modelo de ML que representa la política muestra una acción basada en este estado. Un modelo de acción paramétrico facilita el muestreo solo de las acciones no enmascaradas (máscara ≠ 0). Aquí describimos el modelo de acciones paramétricas que permite el enmascaramiento de acciones:
Las acciones son muestreadas por el modelo a través de una función Softmax utilizando los logits proporcionados por un modelo de incrustación de acciones. Este modelo se define en el __init__ método. El comportamiento de enmascaramiento en sí mismo se implementa en el forward() método. Aquí, separamos las máscaras de acciones y el estado comercial del estado del diccionario recuperado del entorno. Las incrustaciones de acciones se obtienen luego pasando el estado comercial a la red de incrustaciones de acciones. A continuación, modificamos el valor de incrustaciones de cada acción agregando logit_mod a los logitos. Darse cuenta de logit_mod es una función del logaritmo de la máscara de acción. Para acciones con máscara = 1, el logaritmo de máscara será cero, lo que deja intactas sus incrustaciones. Por otro lado, cuando mask=0, el logaritmo de mask → −∞. Porque Softmax(x) →0 como x→ −∞, esto garantiza que el agente no muestree las acciones enmascaradas.
Probemos si la máscara funciona como se esperaba. Iniciamos un objeto de entrenador de rayos y enmascaramos algunas de las acciones y vemos si el entrenador está muestreando solo las acciones no enmascaradas:
El resultado de la siguiente captura de pantalla muestra la matriz de máscara de acción inicial.

Ahora modificamos los vectores de máscara para que para un1, todas las opciones excepto la acción 8 (comprar 30 unidades del Activo 1); para2 todo excepto la acción 5 (mantener el Activo 2 en los números actuales); y por un3, se enmascara todo excepto las acciones 1 y 2 (vender 40 o 30 unidades del Activo 3):
Ahora que hemos modificado la matriz de máscaras de acción, intentamos probar una nueva acción.

El agente muestra solo aquellas acciones que están desenmascaradas. Esto verifica que el enmascaramiento de acciones funciona como se esperaba.
Resultados
Ahora que el entorno y el modelo de acciones paramétricas están definidos, capacitamos a un agente para resolver el problema de optimización de cartera utilizando SageMaker RL. Entrenamos a un agente de RL para aprender la política óptima para maximizar la recompensa bajo las restricciones C1:C4. Usamos el algoritmo de optimización de políticas proximales (PPO) en SageMaker RL para entrenar al agente de RL para 500,000 XNUMX episodios. La siguiente configuración de entrenamiento muestra cómo especificamos el agente para usar el trading_mask como herramienta de edición del custom_model para ser utilizado:
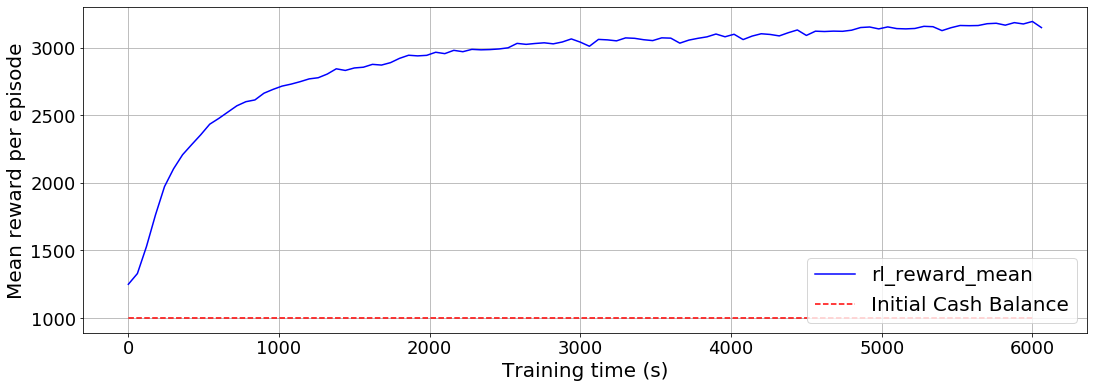
El agente comienza con $ 1,000 USD en saldo de efectivo inicial. La recompensa media por episodio se representa en función del tiempo de entrenamiento, como se muestra en el siguiente gráfico. Recuerde que usamos el valor total final de la cartera como recompensa. Al final de 20 periodos de inversión, observamos que el valor medio de la cartera del agente supera los $3,000 USD.
Limpiar
No aprovisionamos ninguna infraestructura más allá del uso de una instancia de notebook de SageMaker. Si está utilizando una instancia de SageMaker Notebook a través de Studio, puede cerrarla siguiendo las instrucciones de Cerrar un cuaderno abierto.
Conclusión
En esta publicación, discutimos cómo puede implementar el enmascaramiento de acciones para hacer cumplir las restricciones en el entrenamiento del modelo RL. Al enmascarar acciones inadmisibles, permitimos que el agente muestree solo acciones válidas y aprenda la política óptima de una manera eficiente. Introdujimos un problema de optimización de cartera en el que el agente tiene la tarea de maximizar el valor de su cartera mediante el comercio de tres tipos de activos bajo múltiples restricciones. Demostramos cómo implementar el enmascaramiento de acciones multidimensionales para este problema usando Ray RLlib. Capacitamos a un agente de RL para resolver el problema de optimización de cartera restringida utilizando SageMaker RL.
Ahora que sabe cómo realizar el enmascaramiento de acciones con SageMaker RL y Ray RLlib en la optimización de cartera, puede probarlo en otros problemas de RL que impliquen acciones inadmisibles. También puede adaptar el código de enmascaramiento de acción desarrollado en esta publicación para problemas más simples que involucran un espacio de acción unidimensional. Lo alentamos a que aplique el enfoque desarrollado aquí a sus casos de uso de RL y avísenos si tiene alguna pregunta o comentario.
Referencias adicionales
Para obtener información adicional y contenido relacionado, consulte los siguientes recursos:
Acerca de los autores
 Dilshad Raihan Akkam Veettil es científico de datos en los servicios profesionales de AWS, donde interactúa con clientes de todas las industrias para resolver sus desafíos comerciales mediante el uso del aprendizaje automático y la computación en la nube. Tiene un doctorado en Ingeniería Aeroespacial de Texas A&M University, College Station. En su tiempo libre le gusta ver fútbol y leer.
Dilshad Raihan Akkam Veettil es científico de datos en los servicios profesionales de AWS, donde interactúa con clientes de todas las industrias para resolver sus desafíos comerciales mediante el uso del aprendizaje automático y la computación en la nube. Tiene un doctorado en Ingeniería Aeroespacial de Texas A&M University, College Station. En su tiempo libre le gusta ver fútbol y leer.
 Pablo Budnarain es un científico aplicado en el grupo de sistemas de pronóstico de inventario (IFS) de Amazon y tiene su sede en Los Ángeles, California.
Pablo Budnarain es un científico aplicado en el grupo de sistemas de pronóstico de inventario (IFS) de Amazon y tiene su sede en Los Ángeles, California.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/portfolio-optimization-through-multidimensional-action-optimization-using-amazon-sagemaker-rl/

