Amazon EMR sin servidor proporciona un entorno de ejecución sin servidor que simplifica el funcionamiento de aplicaciones de análisis que utilizan los últimos marcos de código abierto, como Apache Spark y Apache Hive. Con EMR Serverless, no es necesario configurar, optimizar, proteger ni operar clústeres para ejecutar aplicaciones con estos marcos. Puede ejecutar cargas de trabajo de análisis a cualquier escala con escalado automático que cambia el tamaño de los recursos en segundos para satisfacer los cambios en los volúmenes de datos y los requisitos de procesamiento. EMR Serverless aumenta y reduce automáticamente los recursos para proporcionar la cantidad justa de capacidad para su aplicación, y usted solo paga por lo que usa.
Funciones de paso de AWS es un servicio de orquestación sin servidor que permite a los desarrolladores crear flujos de trabajo visuales para aplicaciones como una serie de pasos controlados por eventos. Step Functions garantiza que los pasos del flujo de trabajo sin servidor se sigan de manera confiable, que la información pase entre etapas y que los errores se manejen automáticamente.
La integración entre AWS Step Functions y Amazon EMR Serverless facilita la administración y orquestación de flujos de trabajo de big data. Antes de esta integración, había que sondear manualmente los estados de los trabajos o implementar mecanismos de espera a través de llamadas API. Ahora, con la compatibilidad con la integración "Ejecutar un trabajo (.sync)", puede administrar de manera más eficiente sus trabajos EMR Serverless. El uso de .sync permite que su flujo de trabajo de Step Functions espere a que se complete el trabajo de EMR Serverless antes de pasar al siguiente paso, lo que efectivamente hace que la ejecución del trabajo forme parte de su máquina de estado. De manera similar, el patrón "Solicitar respuesta" puede ser útil para activar un trabajo y obtener una respuesta inmediatamente, todo dentro del límites de su flujo de trabajo de Step Functions. Esta integración simplifica su arquitectura al eliminar la necesidad de pasos adicionales para monitorear el estado del trabajo, lo que hace que todo el sistema sea más eficiente y más fácil de administrar.
En esta publicación, explicamos cómo puede orquestar una aplicación PySpark usando Amazon EMR sin servidor y Funciones de paso de AWS. Ejecutamos un trabajo de Spark en EMR Serverless que procesa Conjunto de datos de bicicletas Citi datos en un Servicio de almacenamiento simple de Amazon (Amazon S3) y almacena los resultados agregados en Amazon S3.
Descripción general de la solución
Demostramos esta solución con un ejemplo usando el Conjunto de datos de bicicletas Citi. Este conjunto de datos incluye numerosos parámetros, como tipo de recorrido, estación de inicio, inicio en, estación final, finalización en y varios otros elementos sobre el recorrido de Citi Bikers. Nuestro objetivo es encontrar la duración mínima, máxima y media del viaje en bicicleta en un mes determinado.
En esta solución, los datos de entrada se leen desde la ruta de entrada de S3, se aplican transformaciones y agregaciones con el código PySpark y la salida resumida se escribe en la ruta de salida de S3. s3://<bucket-name>/serverlessout/.
La solución se implementa de la siguiente manera:
- Crea una aplicación EMR Serverless con Spark runtime. Una vez creada la aplicación, puede enviar los trabajos de procesamiento de datos a esa aplicación. Este paso de API espera a que se complete la creación de la aplicación.
- Envía el trabajo de PySpark y espera a que se complete con el
StartJobRun(.sincronización) API. Esto le permite enviar un trabajo a una aplicación sin servidor de Amazon EMR y esperar hasta que se complete el trabajo. - Una vez que se completa el trabajo de PySpark, el resultado resumido está disponible en el directorio de resultados de S3.
- Si el trabajo encuentra un error, el flujo de trabajo de la máquina de estado indicará una falla. Puede inspeccionar el error específico dentro de la máquina de estado. Para obtener un análisis más detallado, también puede consultar los registros de fallas del trabajo de EMR en la consola de EMR Studio.
Requisitos previos
Antes de comenzar, asegúrese de tener los siguientes requisitos previos:
- An Cuenta de AWS
- Un usuario de IAM con acceso de administrador
- Un cubo S3
Arquitectura de soluciones
Para automatizar el proceso completo, utilizamos la siguiente arquitectura, que integra Step Functions para la orquestación y Amazon EMR Serverless para las transformaciones de datos. Luego, el resultado resumido se escribe en el depósito de Amazon S3.
El siguiente diagrama ilustra la arquitectura para este caso de uso.

Pasos de implementación
Antes de comenzar este tutorial, asegúrese de que el rol que se utiliza para la implementación tenga todos los permisos relevantes para crear los recursos necesarios como parte de la solución. Los roles con los permisos adecuados se crearán a través de una plantilla de CloudFormation siguiendo los siguientes pasos.
Paso 1: crear una máquina de estado de Step Functions
Puede crear un flujo de trabajo de Step Functions State Machine de dos maneras: ya sea a través del código directamente o mediante la interfaz gráfica de Step Functions Studio. Para crear una máquina de estados, puede seguir los pasos de la opción 1 o la opción 2 a continuación.
Opción 1: crear la máquina de estados directamente mediante código
Para crear una máquina de estado de Step Functions junto con los roles de IAM necesarios, complete los siguientes pasos:
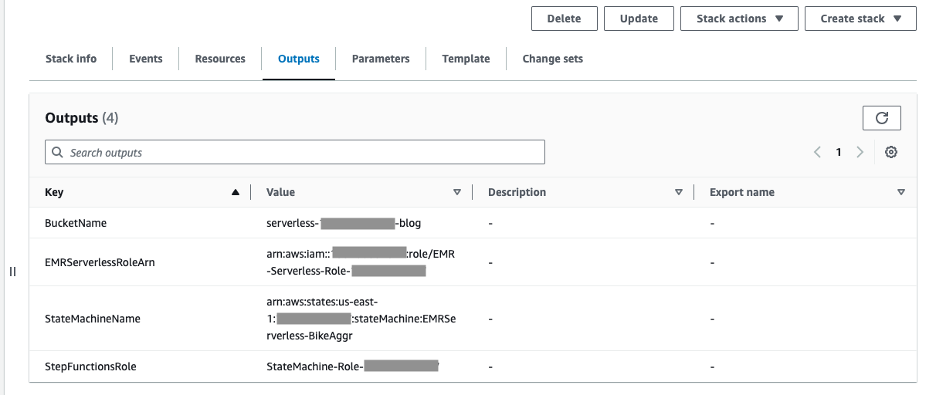
- Inicie la pila de CloudFormation usando esto liga. En la consola de Cloud Formation, proporcione un nombre de pila y acepte los valores predeterminados para crear la pila. Una vez el Formación de nubes Cuando se completa la implementación, se crean los siguientes recursos, además Rol vinculado al servicio EMR Esta pila de CloudFormation creará automáticamente para acceder a EMR Serverless:
- Depósito S3 para cargar el script PySpark y escribir datos de salida del trabajo EMR Serverless. Recomendamos habilitar el cifrado predeterminado en su depósito S3 para cifrar nuevos objetos, así como habilitar el registro de acceso para registrar todas las solicitudes realizadas al depósito. Seguir estas recomendaciones mejorará la seguridad y proporcionará visibilidad del acceso al depósito.
- Función de EMR Serverless Runtime que proporciona permisos granulares a recursos específicos que se requieren cuando se ejecutan trabajos de EMR Serverless.
- Función de Step Functions para otorgar permisos a AWS Step Functions para acceder a los recursos de AWS que utilizarán sus máquinas de estado.
- Máquina de estados con pasos EMR Serverless.
- Para preparar el depósito S3 con el script PySpark, abra Cáscara de nube de AWS desde la barra de herramientas en la esquina superior derecha de la consola de AWS y ejecute el siguiente comando de AWS CLI en CloudShell (asegúrese de reemplazar < > con su ID de cuenta de AWS):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- Para preparar el depósito S3 con datos de entrada, ejecute el siguiente comando de AWS CLI en CloudShell (asegúrese de reemplazar < > con su ID de cuenta de AWS):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

Opción 2: crear la máquina de estado de Step Functions a través de Workflow Studio
Requisitos previos
Antes de crear State Machine a través de Workshop Studio, asegúrese de que todos los roles y recursos relevantes se creen como parte de la solución.
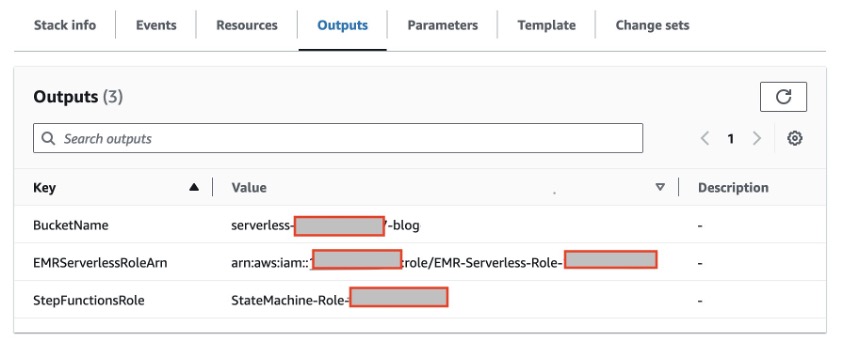
- Para implementar los roles de IAM necesarios y el depósito S3 en su cuenta de AWS, inicie la pila de CloudFormation usando esto liga. Una vez que el Formación de nubes Cuando se completa la implementación, se crean los siguientes recursos:
- Depósito S3 para cargar el script PySpark y escribir datos de salida. Recomendamos habilitar el cifrado predeterminado en su depósito S3 para cifrar nuevos objetos, así como habilitar el registro de acceso para registrar todas las solicitudes realizadas al depósito. Seguir estas recomendaciones mejorará la seguridad y proporcionará visibilidad del acceso al depósito.
- Función de EMR Serverless Runtime que proporciona permisos granulares a recursos específicos que se requieren cuando se ejecutan trabajos de EMR Serverless.
- Función de Step Functions para otorgar permisos a AWS Step Functions para acceder a los recursos de AWS que utilizarán sus máquinas de estado.
- Para preparar el depósito S3 con el script PySpark, abra Cáscara de nube de AWS desde la barra de herramientas en la parte superior derecha de la consola de AWS y ejecute el siguiente comando de AWS CLI en CloudShell (asegúrese de reemplazar < > con su ID de cuenta de AWS):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- Para preparar el depósito S3 con datos de entrada, ejecute el siguiente comando de AWS CLI en CloudShell (asegúrese de reemplazar < > con su ID de cuenta de AWS):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

Para crear una máquina de estado de Step Functions, complete los siguientes pasos:
- En Consola Step Functions, escoger Crea una máquina de estado.
- Mantenga el Blanco plantilla seleccionada y haga clic en Seleccione.
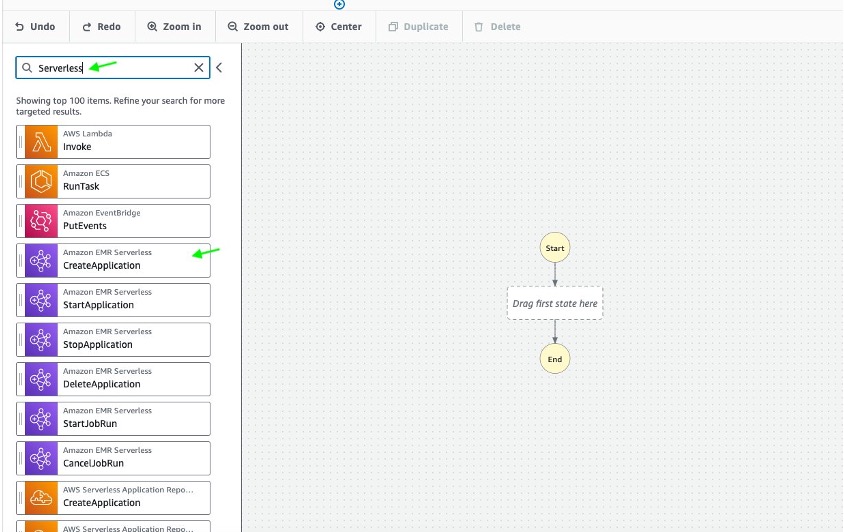
- En Menú de acciones a la izquierda, Step Functions proporciona una lista de API de servicios de AWS que puede arrastrar y soltar en su gráfico de flujo de trabajo en el lienzo de diseño. Tipo EMR Sin servidor existentes Buscar y arrastre el Aplicación de creación sin servidor de Amazon EMR estado al gráfico de flujo de trabajo:
- En el lienzo, seleccione Aplicación de creación sin servidor de Amazon EMR state para configurar sus propiedades. El Inspector El panel de la derecha muestra las opciones de configuración. Proporcione los siguientes valores de configuración:
- Cambie el Nombre del Estado a Crear una aplicación sin servidor EMR
- Proporcione los siguientes valores al Parámetros API. Esto crea una aplicación sin servidor EMR con Apache Spark basada en la versión 6.12.0 de Amazon EMR utilizando la configuración predeterminada.
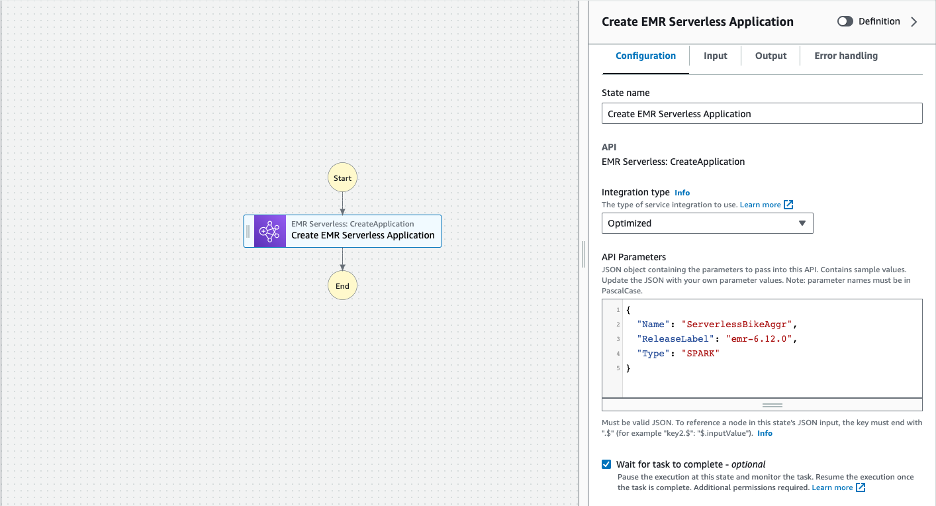
- Haga clic en el Espere a que se complete la tarea (opcional) marque la casilla para esperar a que se complete el estado de creación de la aplicación EMR Serverless antes de ejecutar el siguiente estado.
- under siguiente estado, seleccionar el Agregar nuevo estado opción del menú desplegable.
- Arrastre (Resistencia) StartJobRun sin servidor de EMR estado desde el navegador izquierdo al siguiente estado en el flujo de trabajo.
- rebautizar Nombre del Estado a Enviar trabajo de PySpark
- Proporcione los siguientes valores en el Parámetros de la API y haga clic Espere a que se complete la tarea (opcional) (asegúrese de reemplazar < > con su ID de cuenta de AWS).
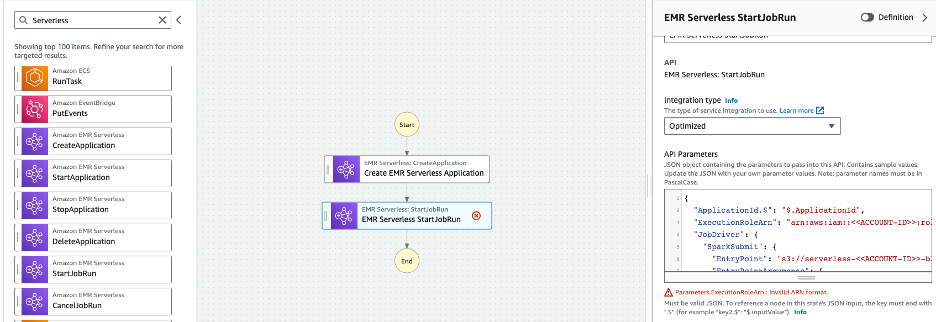
- Seleccione Config pestaña para la máquina de estado desde la parte superior y cambie las siguientes configuraciones:
- Cambios Nombre de la máquina de estado a EMRServerless-BikeAggr encontrado en Detalles.
- En la sección Permisos, seleccione EstadoMáquina-Rol-< > desde el menú desplegable para Rol de ejecución. (Asegúrese de reemplazar < > con su ID de cuenta de AWS).
- Continuar agregando pasos para Verificar el éxito laboral desde el estudio como se muestra en el siguiente diagrama.
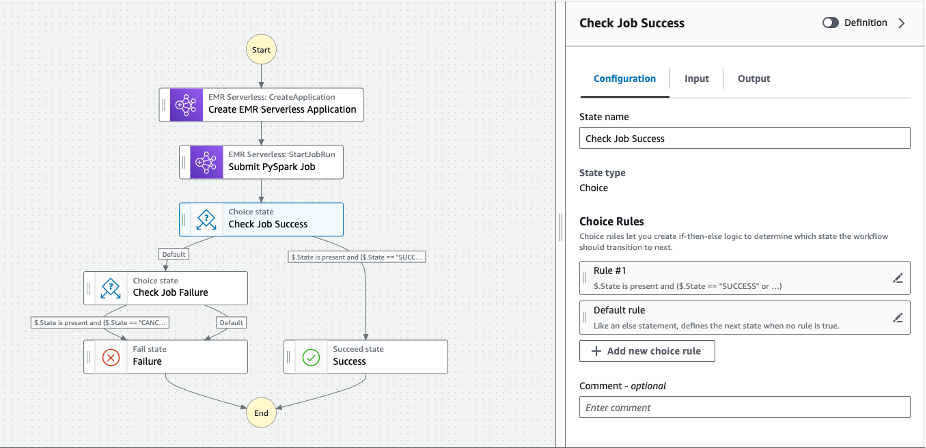
- Haga Clic en Crear para crear la máquina de estado de Step Functions para orquestar los trabajos sin servidor de EMR.
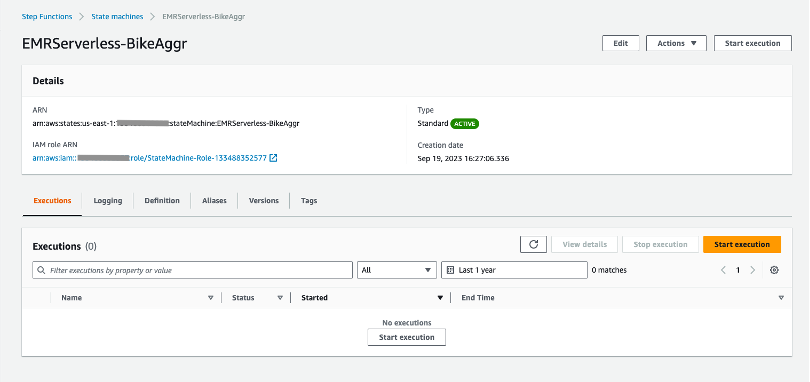
Paso 2: invocar las funciones de paso
Ahora que se crea la función de paso, podemos invocarla haciendo clic en el Iniciar ejecución botón:
Cuando se invoca la función de paso, presenta su flujo de ejecución como se muestra en la siguiente captura de pantalla. porque hemos seleccionado Espere a que se complete la tarea config (API .sync) para este paso, el siguiente paso no comenzaría y esperaría hasta que se cree la aplicación sin servidor EMR (el azul representa la aplicación sin servidor de Amazon EMR que se está creando).

Después de crear con éxito la aplicación EMR Serverless, enviamos un trabajo PySpark a esa aplicación.
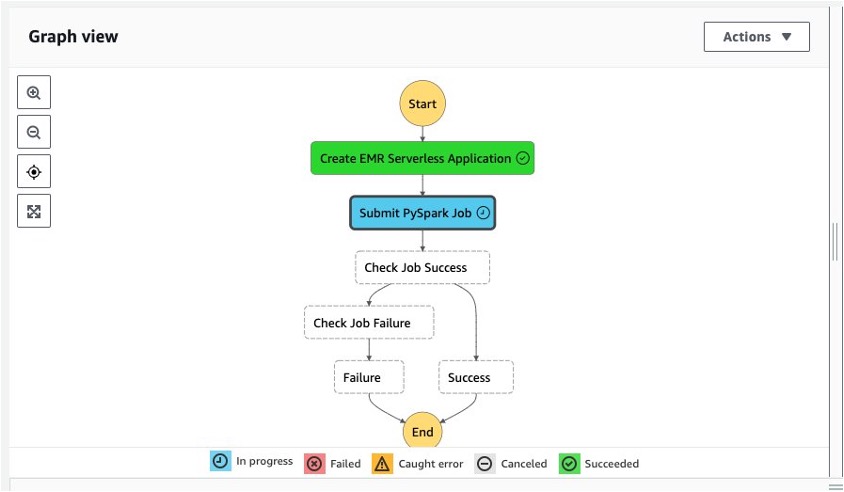
Cuando se completa el trabajo de EMR Serverless, el Enviar PySpark Trabajos el paso cambia a verde. Esto se debe a que hemos seleccionado el Espere a que se complete la tarea configuración (usando la API .sync) para este paso.

El ID de la aplicación sin servidor EMR, así como el ID de ejecución del trabajo PySpark desde Salida pestaña para Enviar trabajo de PySpark paso.
Paso 3: Validación
Para confirmar la finalización exitosa del trabajo, navegue hasta Consola sin servidor EMR y busque el ID de la aplicación sin servidor EMR. Haga clic en el ID de la aplicación para encontrar los detalles de ejecución de la ejecución del trabajo de PySpark enviada desde Step Functions.

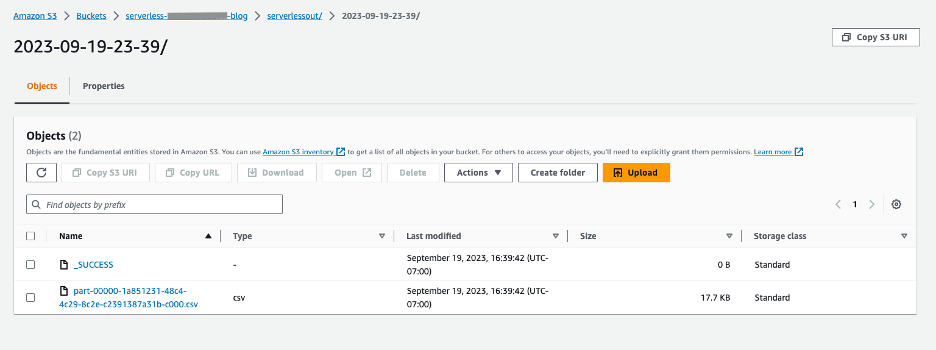
Para verificar el resultado de la ejecución del trabajo, puede verificar el depósito de S3 donde se almacenará el resultado en un archivo .csv como se muestra en el siguiente gráfico.
Limpiar
Inicie sesión en el Consola de administración de AWS y elimine cualquier depósito de S3 creado por esta implementación para evitar cargos no deseados en su cuenta de AWS. Por ejemplo: s3://serverless-<<ACCOUNT-ID>>-blog/
Luego limpie su entorno, elimine la plantilla de CloudFormation que creó en los pasos de configuración de la solución.
Función Eliminar paso que creó como parte de esta solución.
Conclusión
En esta publicación, explicamos cómo lanzar un trabajo de Amazon EMR Serverless Spark con Step Functions utilizando Workflow Studio para implementar una canalización ETL simple que crea resultados agregados a partir del conjunto de datos de Citi Bike y genera informes.
Esperamos que esto le brinde un excelente punto de partida para utilizar esta solución con sus conjuntos de datos y aplicar reglas comerciales más complejas para resolver sus casos de uso de clústeres transitorios.
¿Tiene preguntas o comentarios de seguimiento? Deja un comentario. Nos encantaría escuchar sus pensamientos y sugerencias.
Referencias
Acerca de los autores
 naveen balaraman es arquitecto sénior de aplicaciones en la nube en Amazon Web Services. Le apasionan los contenedores, la tecnología sin servidor, la arquitectura de microservicios y ayudar a los clientes a aprovechar el poder de la nube de AWS.
naveen balaraman es arquitecto sénior de aplicaciones en la nube en Amazon Web Services. Le apasionan los contenedores, la tecnología sin servidor, la arquitectura de microservicios y ayudar a los clientes a aprovechar el poder de la nube de AWS.
 Karthik Prabhakar es arquitecto sénior de soluciones de Big Data para Amazon EMR en AWS. Es un ingeniero de análisis con experiencia que trabaja con clientes de AWS para brindar mejores prácticas y asesoramiento técnico a fin de ayudarlos a tener éxito en su viaje de datos.
Karthik Prabhakar es arquitecto sénior de soluciones de Big Data para Amazon EMR en AWS. Es un ingeniero de análisis con experiencia que trabaja con clientes de AWS para brindar mejores prácticas y asesoramiento técnico a fin de ayudarlos a tener éxito en su viaje de datos.
 Parul Saxena es arquitecta de soluciones especializada en Big Data en Amazon Web Services, centrada en Amazon EMR, Amazon Athena, AWS Glue y AWS Lake Formation, donde brinda orientación arquitectónica a los clientes para ejecutar cargas de trabajo complejas de big data en la plataforma AWS. En su tiempo libre le gusta viajar y pasar tiempo con su familia y amigos.
Parul Saxena es arquitecta de soluciones especializada en Big Data en Amazon Web Services, centrada en Amazon EMR, Amazon Athena, AWS Glue y AWS Lake Formation, donde brinda orientación arquitectónica a los clientes para ejecutar cargas de trabajo complejas de big data en la plataforma AWS. En su tiempo libre le gusta viajar y pasar tiempo con su familia y amigos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-jobs-with-aws-step-functions/

