En los últimos años, los modelos de lenguajes grandes (LLM) han cobrado importancia como herramientas excepcionales capaces de comprender, generar y manipular texto con una competencia sin precedentes. Sus aplicaciones potenciales abarcan desde agentes conversacionales hasta generación de contenido y recuperación de información, y prometen revolucionar todas las industrias. Sin embargo, aprovechar este potencial y al mismo tiempo garantizar el uso responsable y eficaz de estos modelos depende del proceso crítico de evaluación del LLM. Una evaluación es una tarea que se utiliza para medir la calidad y la responsabilidad del resultado de un LLM o un servicio de IA generativa. La evaluación de los LLM no solo está motivada por el deseo de comprender el desempeño de un modelo, sino también por la necesidad de implementar una IA responsable y por la necesidad de mitigar el riesgo de proporcionar información errónea o contenido sesgado y minimizar la generación de información dañina, insegura, maliciosa y poco ética. contenido. Además, evaluar los LLM también puede ayudar a mitigar los riesgos de seguridad, particularmente en el contexto de una rápida manipulación de datos. Para las aplicaciones basadas en LLM, es crucial identificar vulnerabilidades e implementar salvaguardas que protejan contra posibles infracciones y manipulaciones no autorizadas de datos.
Al proporcionar herramientas esenciales para evaluar LLM con una configuración sencilla y un enfoque de un solo clic, Amazon SageMaker aclarar Las capacidades de evaluación de LLM otorgan a los clientes acceso a la mayoría de los beneficios antes mencionados. Con estas herramientas en mano, el próximo desafío es integrar la evaluación LLM en el ciclo de vida de Operación y Aprendizaje Automático (MLOps) para lograr la automatización y escalabilidad en el proceso. En esta publicación, le mostramos cómo integrar la evaluación LLM de Amazon SageMaker Clarify con Amazon SageMaker Pipelines para permitir la evaluación LLM a escala. Además, proporcionamos un ejemplo de código en este GitHub repositorio para permitir a los usuarios realizar evaluaciones paralelas de múltiples modelos a escala, utilizando ejemplos como Llama2-7b-f, Falcon-7b y modelos Llama2-7b ajustados.
¿Quién necesita realizar la evaluación LLM?
Cualquiera que capacite, ajuste o simplemente utilice un LLM previamente capacitado debe evaluarlo con precisión para evaluar el comportamiento de la aplicación impulsada por ese LLM. Según este principio, podemos clasificar a los usuarios de IA generativa que necesitan capacidades de evaluación de LLM en 3 grupos, como se muestra en la siguiente figura: proveedores de modelos, optimizadores y consumidores.

- Proveedores del modelo fundamental (FM) entrenar modelos que sean de uso general. Estos modelos se pueden utilizar para muchas tareas posteriores, como la extracción de funciones o la generación de contenido. Cada modelo entrenado debe compararse con muchas tareas no solo para evaluar su desempeño sino también para compararlo con otros modelos existentes, para identificar áreas que necesitan mejoras y, finalmente, para realizar un seguimiento de los avances en el campo. Los proveedores de modelos también deben verificar la presencia de sesgos para garantizar la calidad del conjunto de datos inicial y el comportamiento correcto de su modelo. La recopilación de datos de evaluación es vital para los proveedores de modelos. Además, estos datos y métricas deben recopilarse para cumplir con las próximas regulaciones. ISO 42001, el Orden ejecutiva de la administración Bideny Ley de IA de la UE Desarrollar estándares, herramientas y pruebas para ayudar a garantizar que los sistemas de IA sean seguros y confiables. Por ejemplo, la Ley de IA de la UE tiene la tarea de proporcionar información sobre qué conjuntos de datos se utilizan para el entrenamiento, qué potencia de cálculo se requiere para ejecutar el modelo, informar los resultados del modelo frente a puntos de referencia públicos/estándares de la industria y compartir los resultados de las pruebas internas y externas.
- Modelo afinadores desea resolver tareas específicas (por ejemplo, clasificación de sentimientos, resúmenes, respuesta a preguntas), así como modelos previamente entrenados para adoptar tareas específicas de dominio. Necesitan métricas de evaluación generadas por los proveedores de modelos para seleccionar el modelo previamente entrenado adecuado como punto de partida.
Necesitan evaluar sus modelos ajustados en comparación con el caso de uso deseado con conjuntos de datos específicos de una tarea o de un dominio. Con frecuencia, deben seleccionar y crear sus conjuntos de datos privados, ya que los conjuntos de datos disponibles públicamente, incluso aquellos diseñados para una tarea específica, pueden no capturar adecuadamente los matices necesarios para su caso de uso particular.
El ajuste es más rápido y económico que una capacitación completa y requiere una iteración operativa más rápida para la implementación y las pruebas porque generalmente se generan muchos modelos candidatos. La evaluación de estos modelos permite la mejora, calibración y depuración continua del modelo. Tenga en cuenta que los perfeccionadores pueden convertirse en consumidores de sus propios modelos cuando desarrollan aplicaciones del mundo real. - Modelo CONSUMIDORES o los implementadores de modelos sirven y monitorean modelos de propósito general o ajustados en producción, con el objetivo de mejorar sus aplicaciones o servicios mediante la adopción de LLM. El primer desafío que tienen es garantizar que el LLM elegido se alinee con sus necesidades, costos y expectativas de desempeño específicos. Interpretar y comprender los resultados del modelo es una preocupación persistente, especialmente cuando están involucradas la privacidad y la seguridad de los datos (por ejemplo, para auditar el riesgo y el cumplimiento en industrias reguladas, como el sector financiero). La evaluación continua del modelo es fundamental para evitar la propagación de sesgos o contenido dañino. Al implementar un marco sólido de monitoreo y evaluación, los consumidores de modelos pueden identificar y abordar de manera proactiva la regresión en los LLM, asegurando que estos modelos mantengan su efectividad y confiabilidad a lo largo del tiempo.
Cómo realizar la evaluación LLM
La evaluación eficaz de un modelo implica tres componentes fundamentales: uno o más FM o modelos ajustados para evaluar los conjuntos de datos de entrada (indicaciones, conversaciones o entradas regulares) y la lógica de evaluación.
Para seleccionar los modelos para la evaluación, se deben considerar diferentes factores, incluidas las características de los datos, la complejidad del problema, los recursos computacionales disponibles y el resultado deseado. El almacén de datos de entrada proporciona los datos necesarios para entrenar, ajustar y probar el modelo seleccionado. Es vital que este almacén de datos esté bien estructurado, sea representativo y de alta calidad, ya que el rendimiento del modelo depende en gran medida de los datos de los que aprende. Por último, las lógicas de evaluación definen los criterios y métricas utilizadas para evaluar el desempeño del modelo.
Juntos, estos tres componentes forman un marco cohesivo que garantiza la evaluación rigurosa y sistemática de los modelos de aprendizaje automático, lo que en última instancia conduce a decisiones informadas y mejoras en la efectividad del modelo.
Las técnicas de evaluación de modelos siguen siendo un campo activo de investigación. La comunidad de investigadores creó muchos puntos de referencia y marcos públicos en los últimos años para cubrir una amplia gama de tareas y escenarios, como COLA, Super pegamento, TIMÓN, MMLU y BIG-banco. Estos puntos de referencia tienen tablas de clasificación que se pueden utilizar para comparar y contrastar los modelos evaluados. Los puntos de referencia, como HELM, también tienen como objetivo evaluar métricas más allá de las medidas de precisión, como la precisión o la puntuación F1. El punto de referencia HELM incluye métricas de equidad, sesgo y toxicidad que tienen una importancia igualmente significativa en la puntuación general de la evaluación del modelo.
Todos estos puntos de referencia incluyen un conjunto de métricas que miden cómo se desempeña el modelo en una determinada tarea. Las métricas más famosas y comunes son ROUGE (Estudio suplente orientado al recuerdo para la evaluación de Gisting), AZUL (Estudiante de evaluación bilingüe), o METEOR (Métrica de Evaluación de Traducción con Ordenamiento Explícito). Esas métricas sirven como una herramienta útil para la evaluación automatizada, proporcionando medidas cuantitativas de similitud léxica entre el texto generado y el de referencia. Sin embargo, no capturan toda la amplitud de la generación del lenguaje humano, que incluye la comprensión semántica, el contexto o los matices estilísticos. Por ejemplo, HELM no proporciona detalles de evaluación relevantes para casos de uso específicos, soluciones para probar indicaciones personalizadas y resultados fácilmente interpretables utilizados por no expertos, porque el proceso puede ser costoso, no fácil de escalar y solo para tareas específicas.
Además, lograr la generación de un lenguaje similar al humano a menudo requiere la incorporación de personas involucradas para brindar evaluaciones cualitativas y juicios humanos para complementar las métricas de precisión automatizadas. La evaluación humana es un método valioso para evaluar los resultados del LLM, pero también puede ser subjetiva y propensa a sesgos porque diferentes evaluadores humanos pueden tener diversas opiniones e interpretaciones de la calidad del texto. Además, la evaluación humana puede consumir muchos recursos y ser costosa, y puede exigir mucho tiempo y esfuerzo.
Profundicemos en cómo Amazon SageMaker Clarify conecta los puntos a la perfección, ayudando a los clientes a realizar una evaluación y selección exhaustivas de modelos.
Evaluación de LLM con Amazon SageMaker Clarify
Amazon SageMaker Clarify ayuda a los clientes a automatizar las métricas, incluidas, entre otras, la precisión, la solidez, la toxicidad, los estereotipos y el conocimiento fáctico para la automatización, así como el estilo, la coherencia y la relevancia para la evaluación basada en humanos y los métodos de evaluación al proporcionar un marco para evaluar los LLM. y servicios basados en LLM como Amazon Bedrock. Como servicio totalmente administrado, SageMaker Clarify simplifica el uso de marcos de evaluación de código abierto dentro de Amazon SageMaker. Los clientes pueden seleccionar conjuntos de datos de evaluación y métricas relevantes para sus escenarios y ampliarlos con sus propios conjuntos de datos y algoritmos de evaluación. SageMaker Clarify ofrece resultados de evaluación en múltiples formatos para admitir diferentes roles en el flujo de trabajo de LLM. Los científicos de datos pueden analizar resultados detallados con visualizaciones de SageMaker Clarify en cuadernos, tarjetas modelo de SageMaker e informes en PDF. Mientras tanto, los equipos de operaciones pueden utilizar Amazon SageMaker GroundTruth para revisar y anotar elementos de alto riesgo que SageMaker Clarify identifica. Por ejemplo, mediante estereotipos, toxicidad, PII fugada o baja precisión.
Posteriormente se emplean anotaciones y aprendizaje por refuerzo para mitigar los riesgos potenciales. Las explicaciones amigables para los humanos de los riesgos identificados aceleran el proceso de revisión manual, reduciendo así los costos. Los informes resumidos ofrecen a las partes interesadas del negocio puntos de referencia comparativos entre diferentes modelos y versiones, lo que facilita la toma de decisiones informadas.
La siguiente figura muestra el marco para evaluar LLM y servicios basados en LLM:
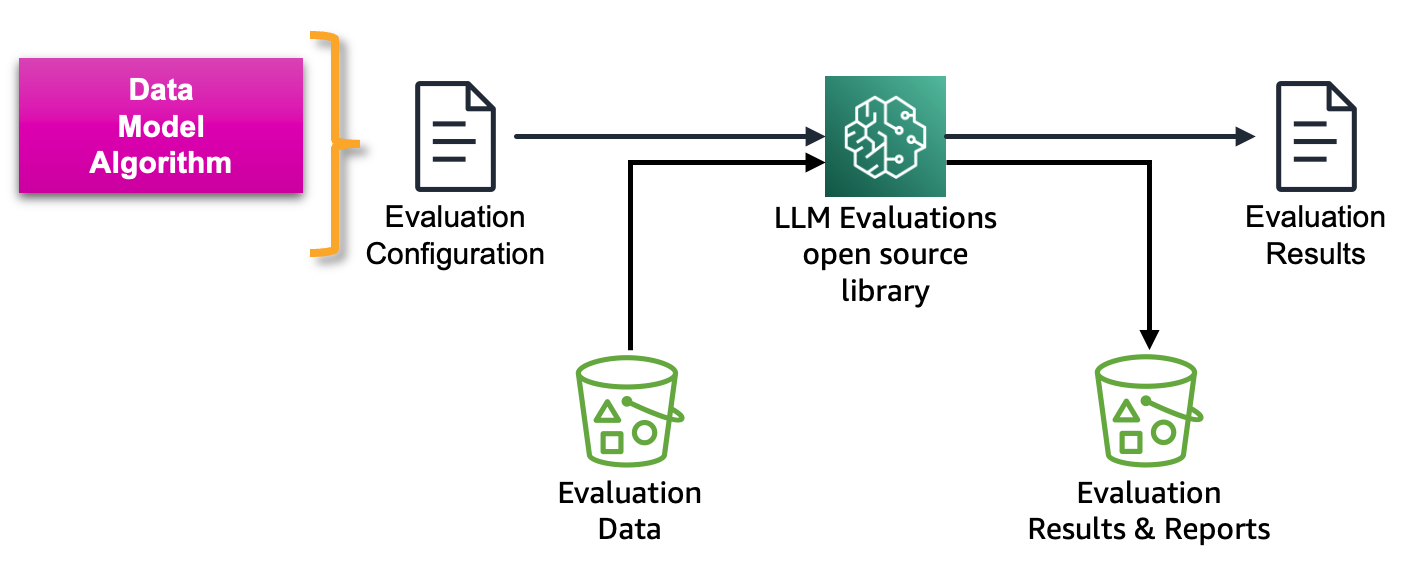
La evaluación de Amazon SageMaker Clarify LLM es una biblioteca de evaluación de modelos básicos (FMEval) de código abierto desarrollada por AWS para ayudar a los clientes a evaluar fácilmente los LLM. Todas las funcionalidades también se han incorporado a Amazon SageMaker Studio para permitir la evaluación de LLM para sus usuarios. En las siguientes secciones, presentamos la integración de las capacidades de evaluación de LLM de Amazon SageMaker Clarify con SageMaker Pipelines para permitir la evaluación de LLM a escala mediante el uso de principios de MLOps.
Ciclo de vida de Amazon SageMaker MLOps
Como la publicación “Hoja de ruta básica de MLOps para empresas con Amazon SageMaker” describe, MLOps es la combinación de procesos, personas y tecnología para producir casos de uso de ML de manera eficiente.
La siguiente figura muestra el ciclo de vida de MLOps de un extremo a otro:

Un viaje típico comienza con un científico de datos que crea un cuaderno de prueba de concepto (PoC) para demostrar que el aprendizaje automático puede resolver un problema empresarial. A lo largo del desarrollo de la prueba de concepto (PoC), le corresponde al científico de datos convertir los indicadores clave de rendimiento (KPI) del negocio en métricas del modelo de aprendizaje automático, como la precisión o la tasa de falsos positivos, y utilizar un conjunto de datos de prueba limitado para evaluarlos. métrica. Los científicos de datos colaboran con ingenieros de ML para realizar la transición de código de cuadernos a repositorios, creando canalizaciones de ML utilizando Amazon SageMaker Pipelines, que conectan varios pasos y tareas de procesamiento, incluido el preprocesamiento, la capacitación, la evaluación y el posprocesamiento, todo mientras incorporan continuamente nueva producción. datos. La implementación de Amazon SageMaker Pipelines depende de las interacciones del repositorio y de la activación de la canalización de CI/CD. La canalización de ML mantiene modelos de alto rendimiento, imágenes de contenedores, resultados de evaluación e información de estado en un registro de modelos, donde las partes interesadas del modelo evalúan el rendimiento y deciden la progresión hacia la producción en función de los resultados de rendimiento y los puntos de referencia, seguido de la activación de otra canalización de CI/CD. para puesta en escena y despliegue de producción. Una vez en producción, los consumidores de ML utilizan el modelo a través de inferencia activada por la aplicación mediante invocación directa o llamadas API, con ciclos de retroalimentación a los propietarios del modelo para una evaluación continua del desempeño.
Integración de Amazon SageMaker Clarify y MLOps
Siguiendo el ciclo de vida de MLOps, los optimizadores o usuarios de modelos de código abierto producen modelos ajustados o FM utilizando los servicios Amazon SageMaker Jumpstart y MLOps, como se describe en Implementación de prácticas de MLOps con modelos preentrenados de Amazon SageMaker JumpStart. Esto condujo a un nuevo dominio para operaciones de modelo básico (FMOps) y operaciones LLM (LLMOps). FMOps/LLMOps: operacionalizar la IA generativa y las diferencias con MLOps.
La siguiente figura muestra el ciclo de vida de LLMOps de un extremo a otro:
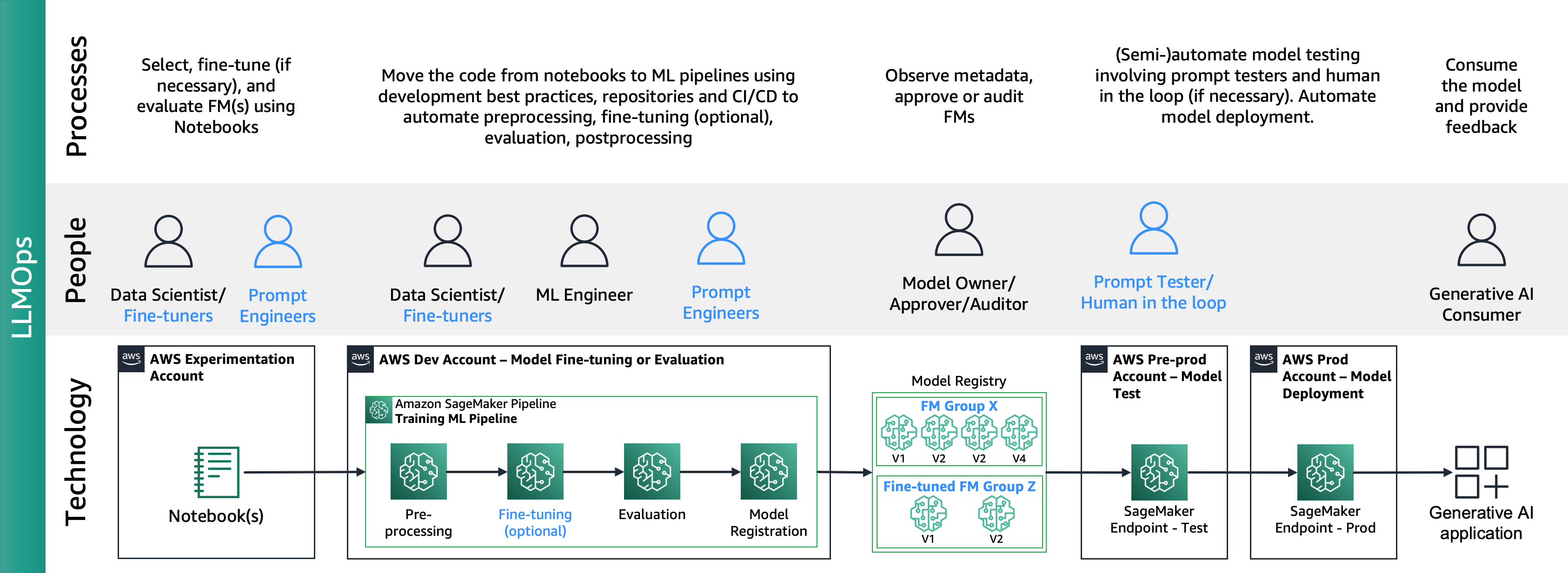
En LLMOps, las principales diferencias en comparación con MLOps son la selección y evaluación de modelos que involucran diferentes procesos y métricas. En la fase de experimentación inicial, los científicos de datos (o afinadores) seleccionan el FM que se utilizará para un caso de uso específico de IA generativa.
Esto a menudo resulta en la prueba y ajuste de múltiples FM, algunos de los cuales pueden producir resultados comparables. Después de la selección de los modelos, los ingenieros de avisos son responsables de preparar los datos de entrada necesarios y el resultado esperado para la evaluación (por ejemplo, avisos de entrada que comprenden datos de entrada y consultas) y definir métricas como similitud y toxicidad. Además de estas métricas, los científicos de datos o los perfeccionadores deben validar los resultados y elegir el FM adecuado no solo en función de las métricas de precisión, sino también de otras capacidades como la latencia y el costo. Luego, pueden implementar un modelo en un punto final de SageMaker y probar su rendimiento a pequeña escala. Si bien la fase de experimentación puede implicar un proceso sencillo, la transición a la producción requiere que los clientes automaticen el proceso y mejoren la solidez de la solución. Por lo tanto, debemos profundizar en cómo automatizar la evaluación, permitiendo a los evaluadores realizar una evaluación eficiente a escala e implementar un monitoreo en tiempo real de la entrada y salida del modelo.
Automatizar la evaluación de FM
Amazon SageMaker Pipelines automatiza todas las fases de preprocesamiento, ajuste de FM (opcional) y evaluación a escala. Dados los modelos seleccionados durante la experimentación, los ingenieros de solicitudes deben cubrir un conjunto más grande de casos preparando muchas solicitudes y almacenándolas en un repositorio de almacenamiento designado llamado catálogo de solicitudes. Para obtener más información, consulte FMOps/LLMOps: operacionalizar la IA generativa y las diferencias con MLOps. Luego, las canalizaciones de Amazon SageMaker se pueden estructurar de la siguiente manera:
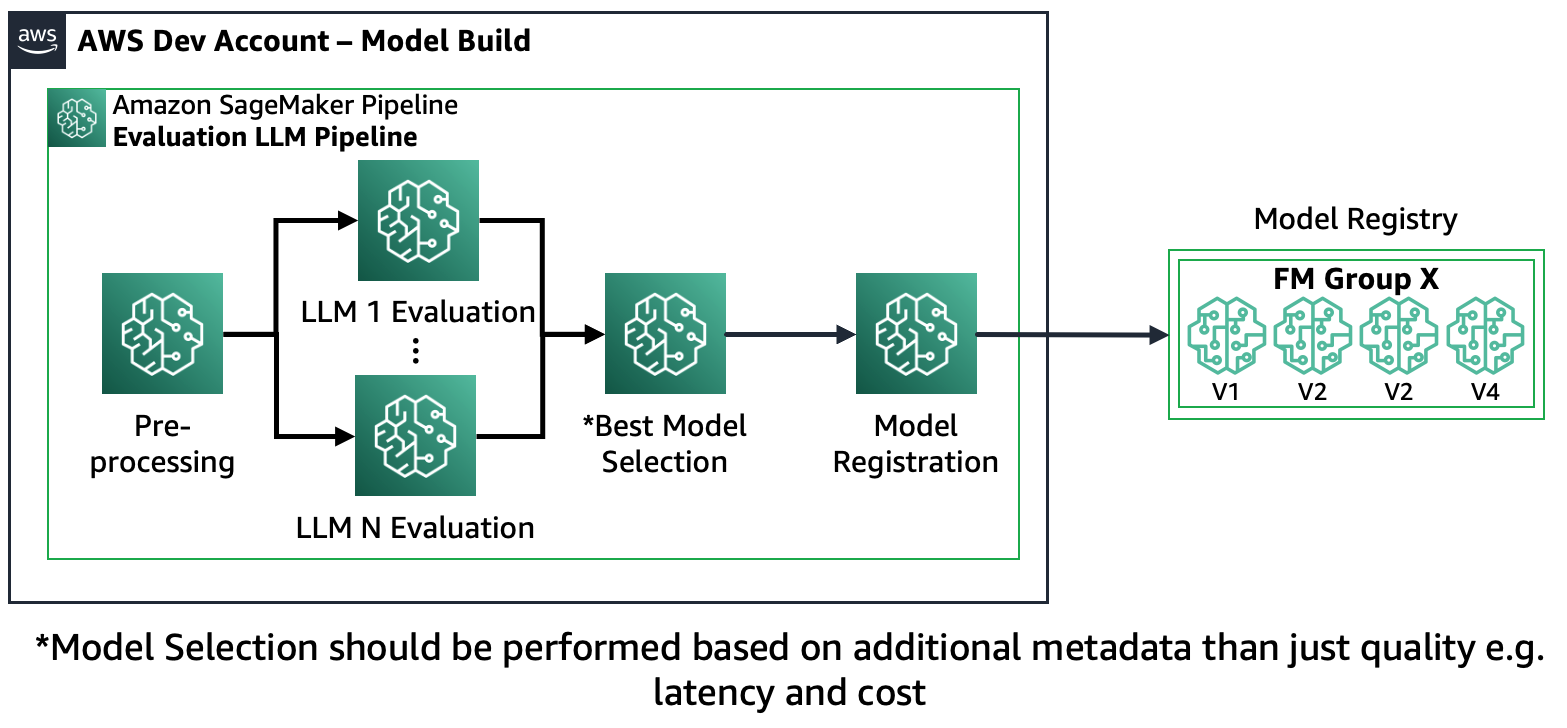
Escenario 1: evaluar varios FM: En este escenario, los FM pueden cubrir el caso de uso empresarial sin realizar ajustes. Amazon SageMaker Pipeline consta de los siguientes pasos: preprocesamiento de datos, evaluación paralela de múltiples FM, comparación y selección de modelos basada en la precisión y otras propiedades como costo o latencia, registro de artefactos de modelo seleccionados y metadatos.
El siguiente diagrama ilustra esta arquitectura.
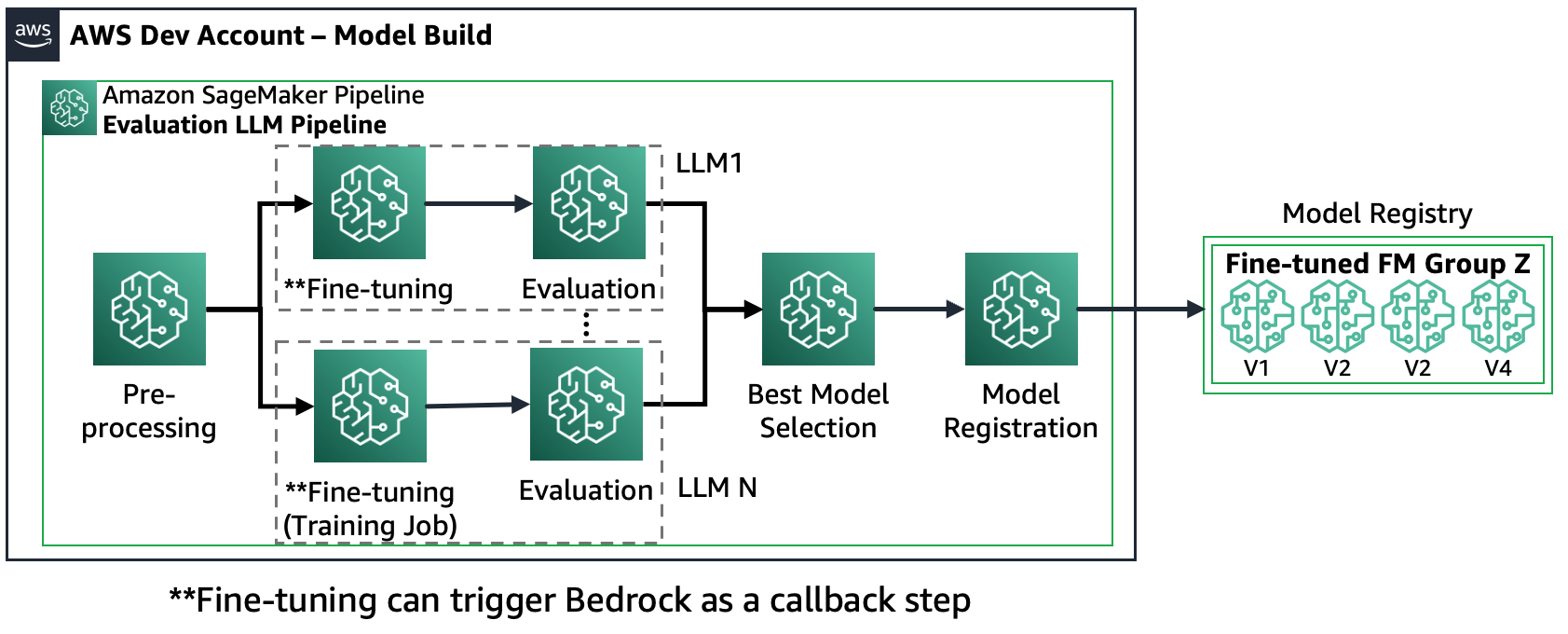
Escenario 2: ajustar y evaluar múltiples FM: En este escenario, Amazon SageMaker Pipeline está estructurado de manera muy similar al Escenario 1, pero se ejecuta en paralelo con los pasos de ajuste y evaluación para cada FM. El modelo mejor ajustado se registrará en el Registro de Modelos.
El siguiente diagrama ilustra esta arquitectura.
Escenario 3: evaluar múltiples FM y FM ajustados: Este escenario es una combinación de evaluación de FM de propósito general y FM optimizados. En este caso, los clientes quieren comprobar si un modelo optimizado puede funcionar mejor que un FM de uso general.
La siguiente figura muestra los pasos resultantes de SageMaker Pipeline.
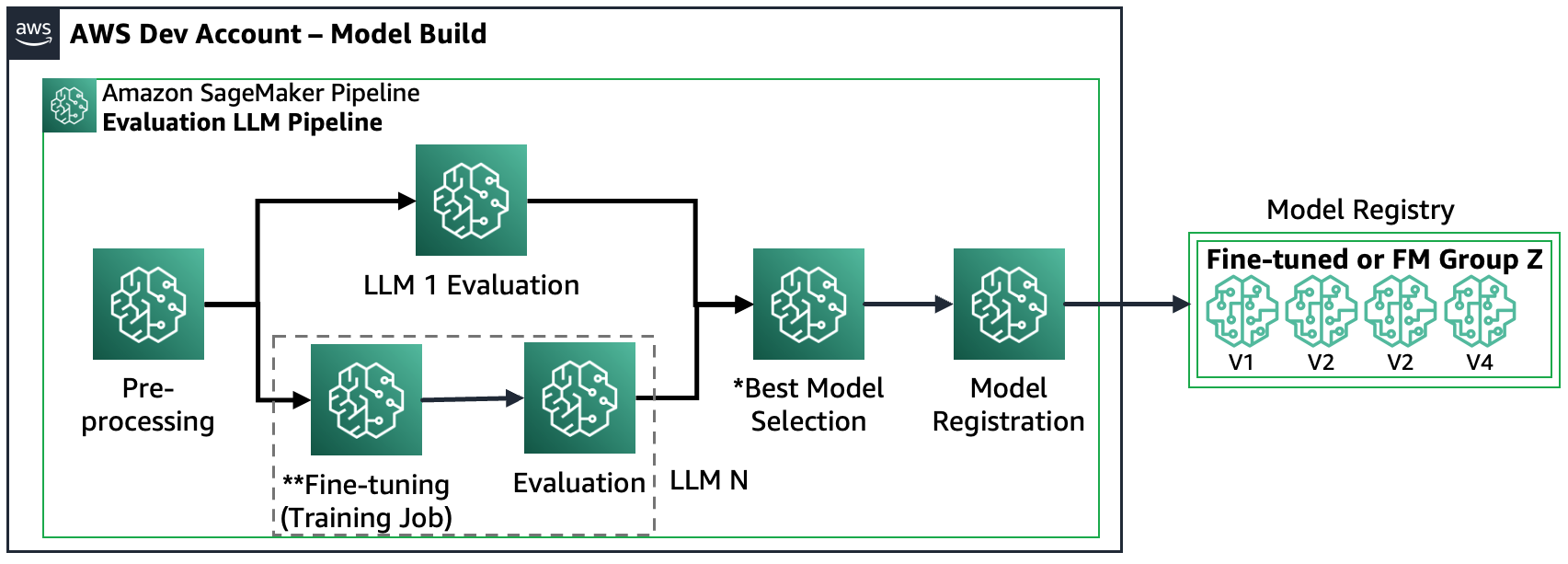
Tenga en cuenta que el registro del modelo sigue dos patrones: (a) almacenar un modelo y artefactos de código abierto o (b) almacenar una referencia a un FM propietario. Para obtener más información, consulte FMOps/LLMOps: operacionalizar la IA generativa y las diferencias con MLOps.
Resumen de la solución
Para acelerar su recorrido hacia la evaluación de LLM a escala, creamos una solución que implementa los escenarios utilizando Amazon SageMaker Clarify y el nuevo SDK de Amazon SageMaker Pipelines. El ejemplo de código, que incluye conjuntos de datos, cuadernos de origen y canalizaciones de SageMaker (pasos y canalización de aprendizaje automático), está disponible en GitHub. Para desarrollar esta solución de ejemplo, hemos utilizado dos FM: Llama2 y Falcon-7B. En esta publicación, nuestro enfoque principal está en los elementos clave de la solución SageMaker Pipeline que pertenecen al proceso de evaluación.
Configuración de evaluación: Con el fin de estandarizar el procedimiento de evaluación, hemos creado un archivo de configuración YAML (evaluación_config.yaml), que contiene los detalles necesarios para el proceso de evaluación, incluido el conjunto de datos, los modelos y los algoritmos que se ejecutarán durante el proceso. paso de evaluación del SageMaker Pipeline. El siguiente ejemplo ilustra el archivo de configuración:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Paso de evaluación: El nuevo SDK de SageMaker Pipeline brinda a los usuarios la flexibilidad de definir pasos personalizados en el flujo de trabajo de ML utilizando el decorador de Python '@step'. Por lo tanto, los usuarios deben crear un script Python básico que realice la evaluación, de la siguiente manera:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultCanalización de SageMaker: Después de crear los pasos necesarios, como el preprocesamiento de datos, la implementación del modelo y la evaluación del modelo, el usuario debe vincular los pasos mediante SageMaker Pipeline SDK. El nuevo SDK genera automáticamente el flujo de trabajo interpretando las dependencias entre diferentes pasos cuando se invoca una API de creación de SageMaker Pipeline, como se muestra en el siguiente ejemplo:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
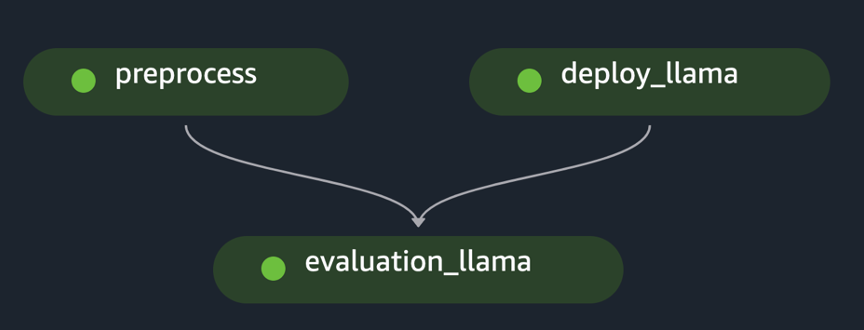
pipeline.start()El ejemplo implementa la evaluación de un único FM procesando previamente el conjunto de datos inicial, implementando el modelo y ejecutando la evaluación. El gráfico acíclico dirigido a la tubería (DAG) generado se muestra en la siguiente figura.
Siguiendo un enfoque similar y utilizando y adaptando el ejemplo en Ajuste los modelos LLaMA 2 en SageMaker JumpStart, creamos la canalización para evaluar un modelo ajustado, como se muestra en la siguiente figura.

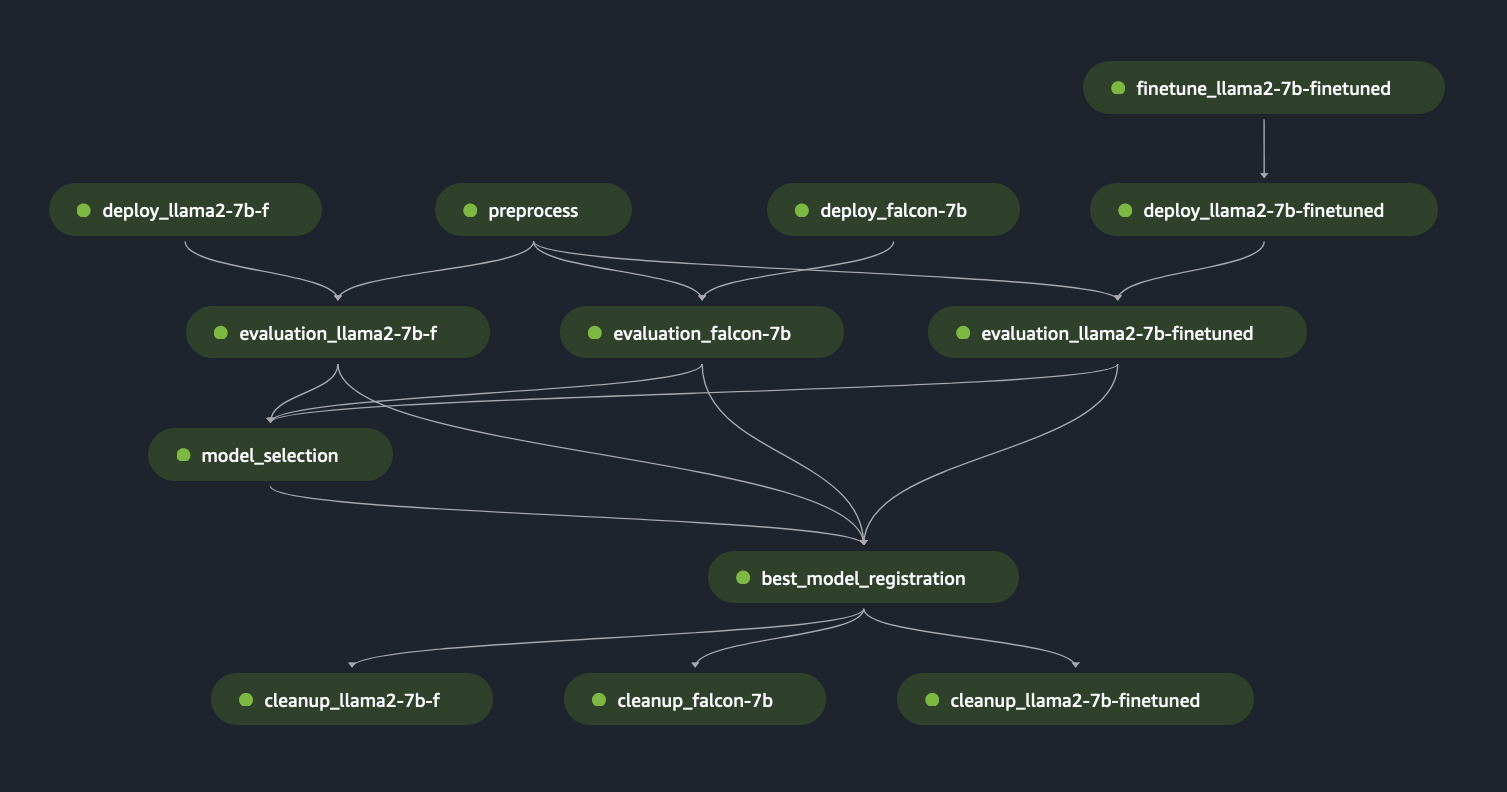
Al utilizar los pasos anteriores de SageMaker Pipeline como bloques "Lego", desarrollamos la solución para el Escenario 1 y el Escenario 3, como se muestra en las siguientes figuras. Específicamente, el GitHub El repositorio permite al usuario evaluar múltiples FM en paralelo o realizar una evaluación más compleja combinando la evaluación de modelos básicos y ajustados.


Las funcionalidades adicionales disponibles en el repositorio incluyen las siguientes:
- Generación de pasos de evaluación dinámica: Nuestra solución genera todos los pasos de evaluación necesarios de forma dinámica en función del archivo de configuración para permitir a los usuarios evaluar cualquier número de modelos. Hemos ampliado la solución para admitir una fácil integración de nuevos tipos de modelos, como Hugging Face o Amazon Bedrock.
- Evitar la reimplementación de endpoints: Si ya existe un punto final, omitimos el proceso de implementación. Esto permite al usuario reutilizar puntos finales con FM para evaluación, lo que genera ahorros de costos y reducción del tiempo de implementación.
- Limpieza del punto final: Después de completar la evaluación, SageMaker Pipeline retira los puntos finales implementados. Esta funcionalidad se puede ampliar para mantener vivo el mejor punto final del modelo.
- Paso de selección del modelo: Hemos agregado un marcador de posición del paso de selección del modelo que requiere la lógica empresarial de la selección del modelo final, incluidos criterios como el costo o la latencia.
- Paso de registro del modelo: El mejor modelo se puede registrar en el Registro de modelos de Amazon SageMaker como una nueva versión de un grupo de modelos específico.
- Piscina templada: Los grupos cálidos administrados por SageMaker le permiten retener y reutilizar la infraestructura aprovisionada después de completar un trabajo para reducir la latencia de cargas de trabajo repetitivas.
La siguiente figura ilustra estas capacidades y un ejemplo de evaluación multimodelo que los usuarios pueden crear fácil y dinámicamente usando nuestra solución en este GitHub repositorio.
Mantuvimos intencionalmente la preparación de datos fuera de nuestro alcance, ya que se describirá en profundidad en una publicación diferente, incluidos los diseños de catálogos de solicitudes, las plantillas de solicitudes y la optimización de solicitudes. Para obtener más información y definiciones de componentes relacionados, consulte FMOps/LLMOps: operacionalizar la IA generativa y las diferencias con MLOps.
Conclusión
En esta publicación, nos centramos en cómo automatizar y poner en funcionamiento la evaluación de LLM a escala utilizando las capacidades de evaluación de LLM de Amazon SageMaker Clarify y Amazon SageMaker Pipelines. Además de los diseños de arquitectura teórica, tenemos código de ejemplo en este GitHub repositorio (que incluye FM Llama2 y Falcon-7B) para permitir a los clientes desarrollar sus propios mecanismos de evaluación escalables.
La siguiente ilustración muestra la arquitectura de evaluación del modelo.

En esta publicación, nos centramos en poner en práctica la evaluación LLM a escala, como se muestra en el lado izquierdo de la ilustración. En el futuro, nos centraremos en desarrollar ejemplos que cumplan el ciclo de vida de extremo a extremo de los FM hasta la producción siguiendo las pautas descritas en FMOps/LLMOps: operacionalizar la IA generativa y las diferencias con MLOps. Esto incluye el servicio de LLM, el monitoreo, el almacenamiento de la calificación de salida que eventualmente activará la reevaluación y el ajuste automáticos y, por último, el uso de humanos en el circuito para trabajar en datos etiquetados o catálogos de indicaciones.
Sobre los autores
 Dra. Sokratis Kartakis es arquitecto principal de soluciones especialista en operaciones y aprendizaje automático para Amazon Web Services. Sokratis se centra en permitir a los clientes empresariales industrializar sus soluciones de aprendizaje automático (ML) y de IA generativa mediante la explotación de los servicios de AWS y la configuración de su modelo operativo, es decir, las bases MLOps/FMOps/LLMOps y la hoja de ruta de transformación aprovechando las mejores prácticas de desarrollo. Ha dedicado más de 15 años a inventar, diseñar, liderar e implementar soluciones innovadoras de aprendizaje automático e inteligencia artificial de nivel de producción de extremo a extremo en los ámbitos de la energía, el comercio minorista, la salud, las finanzas, los deportes de motor, etc.
Dra. Sokratis Kartakis es arquitecto principal de soluciones especialista en operaciones y aprendizaje automático para Amazon Web Services. Sokratis se centra en permitir a los clientes empresariales industrializar sus soluciones de aprendizaje automático (ML) y de IA generativa mediante la explotación de los servicios de AWS y la configuración de su modelo operativo, es decir, las bases MLOps/FMOps/LLMOps y la hoja de ruta de transformación aprovechando las mejores prácticas de desarrollo. Ha dedicado más de 15 años a inventar, diseñar, liderar e implementar soluciones innovadoras de aprendizaje automático e inteligencia artificial de nivel de producción de extremo a extremo en los ámbitos de la energía, el comercio minorista, la salud, las finanzas, los deportes de motor, etc.
 Jagdeep Singh Soni es un arquitecto de soluciones socio senior en AWS con sede en los Países Bajos. Utiliza su pasión por DevOps, GenAI y las herramientas de creación para ayudar tanto a los integradores de sistemas como a los socios tecnológicos. Jagdeep aplica su experiencia en arquitectura y desarrollo de aplicaciones para impulsar la innovación dentro de su equipo y promover nuevas tecnologías.
Jagdeep Singh Soni es un arquitecto de soluciones socio senior en AWS con sede en los Países Bajos. Utiliza su pasión por DevOps, GenAI y las herramientas de creación para ayudar tanto a los integradores de sistemas como a los socios tecnológicos. Jagdeep aplica su experiencia en arquitectura y desarrollo de aplicaciones para impulsar la innovación dentro de su equipo y promover nuevas tecnologías.
 Dr. Ricardo Gatti es un arquitecto senior de soluciones de startups con sede en Italia. Es asesor técnico de clientes y les ayuda a hacer crecer su negocio seleccionando las herramientas y tecnologías adecuadas para innovar, escalar rápidamente y globalizarse en minutos. Siempre le ha apasionado el aprendizaje automático y la IA generativa, habiendo estudiado y aplicado estas tecnologías en diferentes dominios a lo largo de su carrera laboral. Es presentador y editor del podcast italiano de AWS “Casa Startup”, dedicado a historias de fundadores de startups y nuevas tendencias tecnológicas.
Dr. Ricardo Gatti es un arquitecto senior de soluciones de startups con sede en Italia. Es asesor técnico de clientes y les ayuda a hacer crecer su negocio seleccionando las herramientas y tecnologías adecuadas para innovar, escalar rápidamente y globalizarse en minutos. Siempre le ha apasionado el aprendizaje automático y la IA generativa, habiendo estudiado y aplicado estas tecnologías en diferentes dominios a lo largo de su carrera laboral. Es presentador y editor del podcast italiano de AWS “Casa Startup”, dedicado a historias de fundadores de startups y nuevas tendencias tecnológicas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/

