Hoy, la NFL continúa su viaje para aumentar la cantidad de estadísticas proporcionadas por la Plataforma de estadísticas de última generación a los 32 equipos y aficionados por igual. Con análisis avanzados derivados del aprendizaje automático (ML), la NFL está creando nuevas formas de cuantificar el fútbol y brindar a los fanáticos las herramientas necesarias para aumentar su conocimiento del fútbol. juegos dentro del juego de fútbol Para la temporada 2022, la NFL se propuso aprovechar los datos de seguimiento de los jugadores y las nuevas técnicas de análisis avanzado. para entender mejor los equipos especiales.
El objetivo del proyecto era predecir cuántas yardas ganaría un devolvedor en una jugada de despeje o patada inicial. Uno de los desafíos al crear modelos predictivos para la devolución de patadas de despeje y patadas es la disponibilidad de eventos muy raros, como touchdowns, que tienen una importancia significativa en la dinámica de un juego. Una distribución de datos con colas gruesas es común en las aplicaciones del mundo real, donde los eventos raros tienen un impacto significativo en el rendimiento general de los modelos. El uso de un método robusto para modelar con precisión la distribución de eventos extremos es crucial para un mejor rendimiento general.
En esta publicación, demostramos cómo usar la distribución Spliced Binned-Pareto implementada en GluonTS para modelar de manera robusta tales distribuciones de cola gruesa.
Primero describimos el conjunto de datos utilizado. A continuación, presentamos el preprocesamiento de datos y otros métodos de transformación aplicados al conjunto de datos. Luego explicamos los detalles de la metodología ML y los procedimientos de entrenamiento del modelo. Finalmente, presentamos los resultados del rendimiento del modelo.
Conjunto de datos
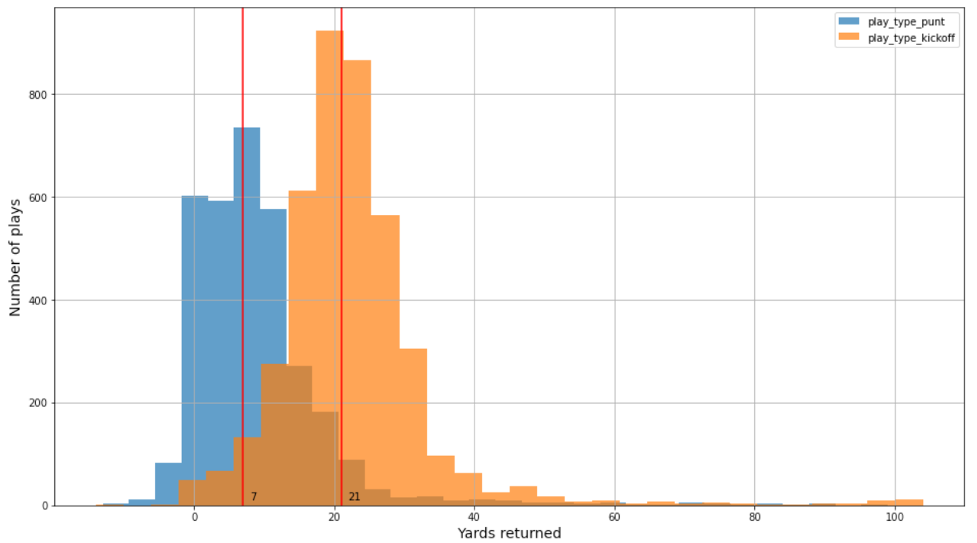
En esta publicación, usamos dos conjuntos de datos para construir modelos separados para las devoluciones de despejes y patadas iniciales. Los datos de seguimiento del jugador contienen la posición, dirección, aceleración y más del jugador (en coordenadas x, y). Hay alrededor de 3,000 y 4,000 jugadas de cuatro temporadas de la NFL (2018-2021) para jugadas de despeje y patada inicial, respectivamente. Además, hay muy pocos touchdowns relacionados con despejes y patadas iniciales en los conjuntos de datos: solo 0.23 % y 0.8 %, respectivamente. La distribución de datos para despeje y patada inicial es diferente. Por ejemplo, la verdadera distribución de yardas para patadas iniciales y despejes es similar pero cambiada, como se muestra en la siguiente figura.
Preprocesamiento de datos e ingeniería de funciones
Primero, los datos de seguimiento se filtraron solo para los datos relacionados con los despejes y las devoluciones de patadas iniciales. Los datos del jugador se usaron para derivar características para el desarrollo del modelo:
- X – Posición del jugador a lo largo del eje largo del campo
- Y – Posición del jugador a lo largo del eje corto del campo
- S – Velocidad en yardas/segundo; reemplazado por Dis*10 para hacerlo más preciso (Dis es la distancia en los últimos 0.1 segundos)
- Usted – Ángulo de movimiento del jugador (grados)
A partir de los datos anteriores, cada jugada se transformó en 10X11X14 de datos con 10 jugadores ofensivos (excluyendo el portador de la pelota), 11 defensores y 14 características derivadas:
- sX – x velocidad de un jugador
- sY – y velocidad de un jugador
- s – Velocidad de un jugador
- aX – x aceleración de un jugador
- aY – y aceleración de un jugador
- relajarse – x distancia del jugador relativa al portador de la pelota
- confiar – y distancia del jugador relativa al portador de la pelota
- relSx – x velocidad del jugador relativa al portador de la pelota
- relSy – y velocidad del jugador relativa al portador de la pelota
- Distrel – Distancia euclidiana del jugador con respecto al portador de la pelota
- oppx – x distancia del jugador ofensivo en relación con el jugador defensivo
- oppY – y distancia del jugador ofensivo en relación con el jugador defensivo
- oppSx –x velocidad del jugador ofensivo en relación con el jugador defensivo
- OppSy – y velocidad del jugador ofensivo en relación con el jugador defensivo
Para aumentar los datos y tener en cuenta las posiciones derecha e izquierda, los valores de las posiciones X e Y también se reflejaron para tener en cuenta las posiciones de los campos derecho e izquierdo. El preprocesamiento de datos y la ingeniería de funciones se adaptaron del ganador del Cuenco de Big Data de la NFL competencia en Kaggle.
Metodología ML y entrenamiento de modelos
Debido a que estamos interesados en todos los resultados posibles de la jugada, incluida la probabilidad de un touchdown, no podemos simplemente predecir el promedio de yardas ganadas como un problema de regresión. Necesitamos predecir la distribución de probabilidad completa de todas las posibles ganancias de jardín, por lo que enmarcamos el problema como una predicción probabilística.
Una forma de implementar predicciones probabilísticas es asignar las yardas ganadas a varios intervalos (como menos de 0, de 0 a 1, de 1 a 2,..., de 14 a 15, más de 15) y predecir el intervalo como una clasificación. problema. La desventaja de este enfoque es que queremos que los contenedores pequeños tengan una imagen de alta definición de la distribución, pero los contenedores pequeños significan menos puntos de datos por contenedor y nuestra distribución, especialmente las colas, puede ser mal estimada e irregular.
Otra forma de implementar predicciones probabilísticas es modelar la salida como una distribución de probabilidad continua con un número limitado de parámetros (por ejemplo, una distribución gaussiana o gamma) y predecir los parámetros. Este enfoque brinda una definición muy alta y una imagen regular de la distribución, pero es demasiado rígido para ajustarse a la distribución real de las yardas ganadas, que es multimodal y con colas pesadas.
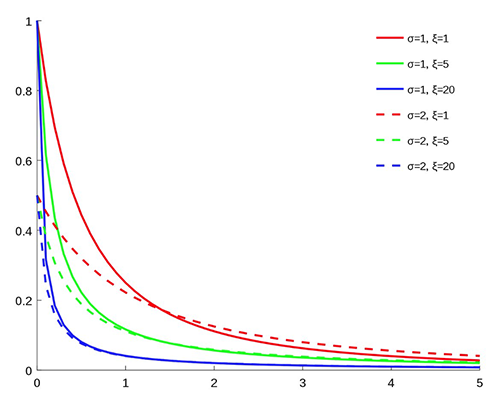
Para obtener lo mejor de ambos métodos, usamos Distribución Binned-Pareto empalmada (SBP), que tiene contenedores para el centro de la distribución donde hay una gran cantidad de datos disponibles, y Distribución generalizada de Pareto (GPD) en ambos extremos, donde pueden ocurrir eventos raros pero importantes, como un touchdown. El GPD tiene dos parámetros: uno para la escala y otro para la pesadez de la cola, como se ve en el siguiente gráfico (fuente: Wikipedia).
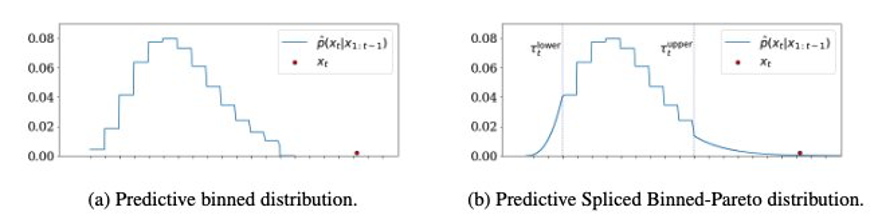
Empalmando el GPD con la distribución binned (ver el siguiente gráfico de la izquierda) en ambos lados, obtenemos el siguiente SBP a la derecha. Los umbrales inferior y superior donde se realiza el empalme son hiperparámetros.
Como referencia, utilizamos el modelo que ganó nuestra Cuenco de Big Data de la NFL competencia en Kaggle. Este modelo utiliza capas CNN para extraer características de los datos preparados y predice el resultado como un problema de clasificación de "1 yarda por contenedor". Para nuestro modelo, mantuvimos las capas de extracción de características desde la línea de base y solo modificamos la última capa para generar parámetros de SBP en lugar de probabilidades para cada contenedor, como se muestra en la siguiente figura (imagen editada de la publicación 1er lugar solución El Zoológico).

Utilizamos la distribución de PAS proporcionada por Gluones. GluonTS es un paquete de Python para el modelado de series temporales probabilísticas, pero la distribución SBP no es específica de las series temporales y pudimos reutilizarla para la regresión. Para obtener más información sobre cómo usar GluonTS SBP, consulte la siguiente demostración cuaderno.
Los modelos se entrenaron y validaron de forma cruzada en las temporadas 2018, 2019 y 2020 y se probaron en la temporada 2021. Para evitar fugas durante la validación cruzada, agrupamos todas las jugadas del mismo juego en el mismo pliegue.
Para la evaluación, mantuvimos la métrica utilizada en la competencia de Kaggle, la puntuación de probabilidad clasificada continua (CRPS), que puede verse como una alternativa al logaritmo de verosimilitud que es más resistente a los valores atípicos. También usamos el Coeficiente de correlación de Pearson y del RMSE como métricas de precisión generales e interpretables. Además, analizamos la probabilidad de un touchdown y gráficos de probabilidad para evaluar la calibración.
El modelo fue entrenado en la pérdida CRPS usando Promedio de peso estocástico y parada temprana.
Para hacer frente a la irregularidad de la parte agrupada de las distribuciones de salida, utilizamos dos técnicas:
- Una penalización de suavidad proporcional a la diferencia al cuadrado entre dos contenedores consecutivos
- Modelos de ensamblaje entrenados durante la validación cruzada
Resultados de rendimiento del modelo
Para cada conjunto de datos, realizamos una búsqueda en cuadrícula sobre las siguientes opciones:
- Modelos probabilísticos
- La línea de base era una probabilidad por yarda
- PAS fue una probabilidad por yarda en el centro, PAS generalizada en las colas
- Suavizado de distribución
- Sin suavizado (penalización de suavidad = 0)
- Penalización de suavidad = 5
- Penalización de suavidad = 10
- Procedimiento de entrenamiento e inferencia
- Validación cruzada de 10 pliegues e inferencia de conjunto (k10)
- Entrenamiento en tren y datos de validación para 10 épocas o 20 épocas
Luego analizamos las métricas de los cinco modelos principales ordenados por CRPS (más bajo es mejor).
Para los datos de inicio, el modelo SBP tiene un rendimiento ligeramente superior en términos de CRPS pero, lo que es más importante, estima mejor la probabilidad de touchdown (la probabilidad real es del 0.80 % en el conjunto de prueba). Vemos que los mejores modelos usan ensamblaje de 10 pliegues (k10) y ninguna penalización por suavidad, como se muestra en la siguiente tabla.
| Formación | Modelo | Suavidad | CRPS | RMSE | % CORR. | P(aterrizaje)% |
| k10 | PAS | 0 | 4.071 | 9.641 | 47.15 | 0.78 |
| k10 | Base | 0 | 4.074 | 9.62 | 47.585 | 0.306 |
| k10 | Base | 5 | 4.075 | 9.626 | 47.43 | 0.274 |
| k10 | PAS | 5 | 4.079 | 9.656 | 46.977 | 0.682 |
| k10 | Base | 10 | 4.08 | 9.621 | 47.519 | 0.265 |
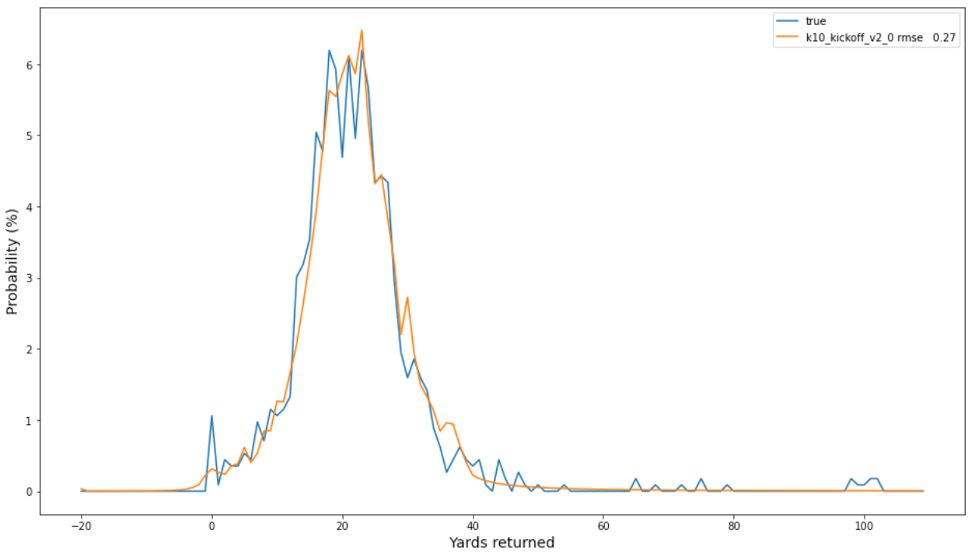
El siguiente gráfico de las frecuencias observadas y las probabilidades previstas indica una buena calibración de nuestro mejor modelo, con un RMSE de 0.27 entre las dos distribuciones. Tenga en cuenta las ocurrencias de yardas altas (por ejemplo, 100) que ocurren en la cola de la distribución empírica verdadera (azul), cuyas probabilidades son más capturables por el SBP que el método de línea de base.
Para los datos de despeje, la línea de base supera al SBP, quizás porque las colas de las yardas extremas tienen menos realizaciones. Por lo tanto, es mejor compensar capturar la modalidad entre picos de 0 a 10 yardas; y, contrariamente a los datos iniciales, el mejor modelo utiliza una penalización por suavidad. La siguiente tabla resume nuestros hallazgos.
| Formación | Modelo | Suavidad | CRPS | RMSE | % CORR. | P(aterrizaje)% |
| k10 | Base | 5 | 3.961 | 8.313 | 35.227 | 0.547 |
| k10 | Base | 0 | 3.972 | 8.346 | 34.227 | 0.579 |
| k10 | Base | 10 | 3.978 | 8.351 | 34.079 | 0.555 |
| k10 | PAS | 5 | 3.981 | 8.342 | 34.971 | 0.723 |
| k10 | PAS | 0 | 3.991 | 8.378 | 33.437 | 0.677 |
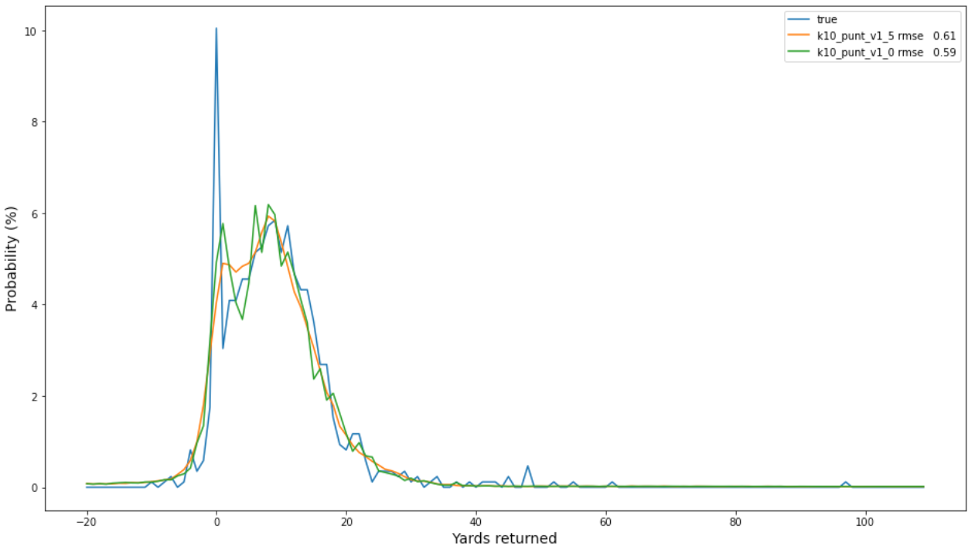
La siguiente gráfica de frecuencias observadas (en azul) y probabilidades predichas para los dos mejores modelos de despeje indica que el modelo no suavizado (en naranja) está ligeramente mejor calibrado que el modelo suavizado (en verde) y puede ser una mejor opción en general.
Conclusión
En esta publicación, mostramos cómo construir modelos predictivos con distribución de datos de cola gruesa. Usamos la distribución Spliced Binned-Pareto, implementada en GluonTS, que puede modelar de manera robusta tales distribuciones de cola gruesa. Usamos esta técnica para construir modelos para devoluciones de despejes y patadas iniciales. Podemos aplicar esta solución a casos de uso similares donde hay muy pocos eventos en los datos, pero esos eventos tienen un impacto significativo en el rendimiento general de los modelos.
Si desea ayuda para acelerar el uso de ML en sus productos y servicios, comuníquese con el Laboratorio de soluciones de Amazon ML .
Acerca de los autores
 Tesfagabir Meharizghi es un científico de datos en el Laboratorio de soluciones de Amazon ML donde ayuda a los clientes de AWS en diversas industrias, como la atención médica y las ciencias de la vida, la fabricación, la automotriz y los deportes y los medios, a acelerar el uso del aprendizaje automático y los servicios en la nube de AWS para resolver sus desafíos comerciales.
Tesfagabir Meharizghi es un científico de datos en el Laboratorio de soluciones de Amazon ML donde ayuda a los clientes de AWS en diversas industrias, como la atención médica y las ciencias de la vida, la fabricación, la automotriz y los deportes y los medios, a acelerar el uso del aprendizaje automático y los servicios en la nube de AWS para resolver sus desafíos comerciales.
 Marc van Oudheusden es científico de datos sénior en el equipo de Amazon ML Solutions Lab en Amazon Web Services. Trabaja con clientes de AWS para resolver problemas comerciales con inteligencia artificial y aprendizaje automático. Fuera del trabajo puedes encontrarlo en la playa, jugando con sus hijos, surfeando o haciendo kitesurf.
Marc van Oudheusden es científico de datos sénior en el equipo de Amazon ML Solutions Lab en Amazon Web Services. Trabaja con clientes de AWS para resolver problemas comerciales con inteligencia artificial y aprendizaje automático. Fuera del trabajo puedes encontrarlo en la playa, jugando con sus hijos, surfeando o haciendo kitesurf.
 Panpan Xu es un científico aplicado sénior y gerente en el laboratorio de soluciones de Amazon ML en AWS. Está trabajando en la investigación y el desarrollo de algoritmos de aprendizaje automático para aplicaciones de clientes de alto impacto en una variedad de verticales industriales para acelerar su adopción de la nube y la inteligencia artificial. Su interés de investigación incluye la interpretabilidad del modelo, el análisis causal, la IA humana en el circuito y la visualización interactiva de datos.
Panpan Xu es un científico aplicado sénior y gerente en el laboratorio de soluciones de Amazon ML en AWS. Está trabajando en la investigación y el desarrollo de algoritmos de aprendizaje automático para aplicaciones de clientes de alto impacto en una variedad de verticales industriales para acelerar su adopción de la nube y la inteligencia artificial. Su interés de investigación incluye la interpretabilidad del modelo, el análisis causal, la IA humana en el circuito y la visualización interactiva de datos.
 Kyeong-hoon (Jonathan) Jung es ingeniero de software sénior en la Liga Nacional de Fútbol. Ha estado con el equipo de Next Gen Stats durante los últimos siete años ayudando a desarrollar la plataforma desde la transmisión de datos sin procesar, la creación de microservicios para procesar los datos, hasta la creación de API que exponen los datos procesados. Ha colaborado con Amazon Machine Learning Solutions Lab para proporcionarles datos limpios con los que trabajar, además de proporcionar conocimientos de dominio sobre los datos en sí. Fuera del trabajo, disfruta andar en bicicleta en Los Ángeles y hacer caminatas en las Sierras.
Kyeong-hoon (Jonathan) Jung es ingeniero de software sénior en la Liga Nacional de Fútbol. Ha estado con el equipo de Next Gen Stats durante los últimos siete años ayudando a desarrollar la plataforma desde la transmisión de datos sin procesar, la creación de microservicios para procesar los datos, hasta la creación de API que exponen los datos procesados. Ha colaborado con Amazon Machine Learning Solutions Lab para proporcionarles datos limpios con los que trabajar, además de proporcionar conocimientos de dominio sobre los datos en sí. Fuera del trabajo, disfruta andar en bicicleta en Los Ángeles y hacer caminatas en las Sierras.
 miguel chi es un director sénior de tecnología que supervisa las estadísticas de próxima generación y la ingeniería de datos en la Liga Nacional de Fútbol Americano. Tiene una licenciatura en Matemáticas y Ciencias de la Computación de la Universidad de Illinois en Urbana Champaign. Michael se unió a la NFL por primera vez en 2007 y se ha centrado principalmente en tecnología y plataformas para estadísticas de fútbol. En su tiempo libre, disfruta pasar tiempo con su familia al aire libre.
miguel chi es un director sénior de tecnología que supervisa las estadísticas de próxima generación y la ingeniería de datos en la Liga Nacional de Fútbol Americano. Tiene una licenciatura en Matemáticas y Ciencias de la Computación de la Universidad de Illinois en Urbana Champaign. Michael se unió a la NFL por primera vez en 2007 y se ha centrado principalmente en tecnología y plataformas para estadísticas de fútbol. En su tiempo libre, disfruta pasar tiempo con su familia al aire libre.
 mike banda es gerente sénior de investigación y análisis para Next Gen Stats en la National Football League. Desde que se unió al equipo en 2018, ha sido responsable de la ideación, el desarrollo y la comunicación de estadísticas e información clave derivadas de los datos de seguimiento de jugadores para fanáticos, socios de transmisión de la NFL y los 32 clubes por igual. Mike aporta una gran cantidad de conocimientos y experiencia al equipo con una maestría en análisis de la Universidad de Chicago, una licenciatura en gestión deportiva de la Universidad de Florida y experiencia tanto en el departamento de exploración de los Minnesota Vikings como en el departamento de reclutamiento. de Fútbol Florida Gator.
mike banda es gerente sénior de investigación y análisis para Next Gen Stats en la National Football League. Desde que se unió al equipo en 2018, ha sido responsable de la ideación, el desarrollo y la comunicación de estadísticas e información clave derivadas de los datos de seguimiento de jugadores para fanáticos, socios de transmisión de la NFL y los 32 clubes por igual. Mike aporta una gran cantidad de conocimientos y experiencia al equipo con una maestría en análisis de la Universidad de Chicago, una licenciatura en gestión deportiva de la Universidad de Florida y experiencia tanto en el departamento de exploración de los Minnesota Vikings como en el departamento de reclutamiento. de Fútbol Florida Gator.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/predict-football-punt-and-kickoff-return-yards-with-fat-tailed-distribution-using-gluonts/

