La creación de una plataforma de operaciones de aprendizaje automático (MLOps) en el panorama en rápida evolución de la inteligencia artificial (IA) y el aprendizaje automático (ML) para las organizaciones es esencial para cerrar sin problemas la brecha entre la experimentación y la implementación de la ciencia de datos y, al mismo tiempo, cumplir con los requisitos relacionados con el rendimiento del modelo. seguridad y cumplimiento.
Para cumplir con los requisitos reglamentarios y de cumplimiento, los requisitos clave al diseñar dicha plataforma son:
- Desviación de datos de dirección
- Supervisar el rendimiento del modelo
- Facilitar el reentrenamiento automático del modelo.
- Proporcionar un proceso para la aprobación del modelo.
- Mantenga los modelos en un entorno seguro
En esta publicación, mostramos cómo crear un marco MLOps para abordar estas necesidades utilizando una combinación de servicios de AWS y conjuntos de herramientas de terceros. La solución implica una configuración multientorno con reentrenamiento automatizado de modelos, inferencia por lotes y monitoreo con Monitor de modelo de Amazon SageMaker, versionado del modelo con Registro de modelos de SageMakery una canalización de CI/CD para facilitar la promoción del código y las canalizaciones de ML en todos los entornos mediante el uso Amazon SageMaker, Puente de eventos de Amazon, Servicio de notificación simple de Amazon (Amazon S3), Terraformación de HashiCorp, GitHuby Jenkins CI/CD. Construimos un modelo para predecir la gravedad (benigna o maligna) de una lesión masiva mamográfica entrenada con el Algoritmo XGBoost utilizando el disponible públicamente Masa de mamografía UCI conjunto de datos e implementarlo utilizando el marco MLOps. Las instrucciones completas con código están disponibles en el Repositorio GitHub.
Resumen de la solución
El siguiente diagrama de arquitectura muestra una descripción general del marco MLOps con los siguientes componentes clave:
- Estrategia multicuenta – Se configuran dos entornos diferentes (dev y prod) en dos cuentas de AWS diferentes siguiendo las mejores prácticas de buena arquitectura de AWS, y se configura una tercera cuenta en el registro de modelo central:
- entorno de desarrollo – Donde un Dominio de estudio de Amazon SageMaker está configurado para permitir el desarrollo de modelos, el entrenamiento de modelos y las pruebas de canalizaciones de aprendizaje automático (entrenamiento e inferencia), antes de que un modelo esté listo para promocionarse a entornos superiores.
- entorno de producción – Donde se promueven las canalizaciones de ML desde el desarrollo como primer paso y se programan y monitorean a lo largo del tiempo.
- registro modelo central – Registro de modelos de Amazon SageMaker se configura en una cuenta de AWS separada para realizar un seguimiento de las versiones de modelos generadas en los entornos de desarrollo y producción.
- CI/CD y control de fuente – La implementación de canalizaciones de ML en distintos entornos se gestiona mediante CI/CD configurado con Jenkins, junto con el control de versiones gestionado a través de GitHub. Los cambios de código combinados en la rama git del entorno correspondiente desencadenan un flujo de trabajo de CI/CD para realizar los cambios apropiados en el entorno de destino determinado.
- Predicciones por lotes con seguimiento de modelo – El canal de inferencia construido con Canalizaciones de Amazon SageMaker se ejecuta de forma programada para generar predicciones junto con el monitoreo del modelo utilizando SageMaker Model Monitor para detectar la desviación de datos.
- Mecanismo de reentrenamiento automatizado – El canal de capacitación creado con SageMaker Pipelines se activa cada vez que se detecta una desviación de datos en el canal de inferencia. Una vez entrenado, el modelo se registra en el registro central de modelos para ser aprobado por un aprobador de modelos. Cuando se aprueba, la versión actualizada del modelo se utiliza para generar predicciones a través del proceso de inferencia.
- Infraestructura como código – La infraestructura como código (IaC), creada utilizando Terraformación de HashiCorp, admite la programación del canal de inferencia con EventBridge, la activación del canal del tren en función de un Regla de EventBridge y enviar notificaciones usando Servicio de notificación simple de Amazon (red social de Amazon) temas.
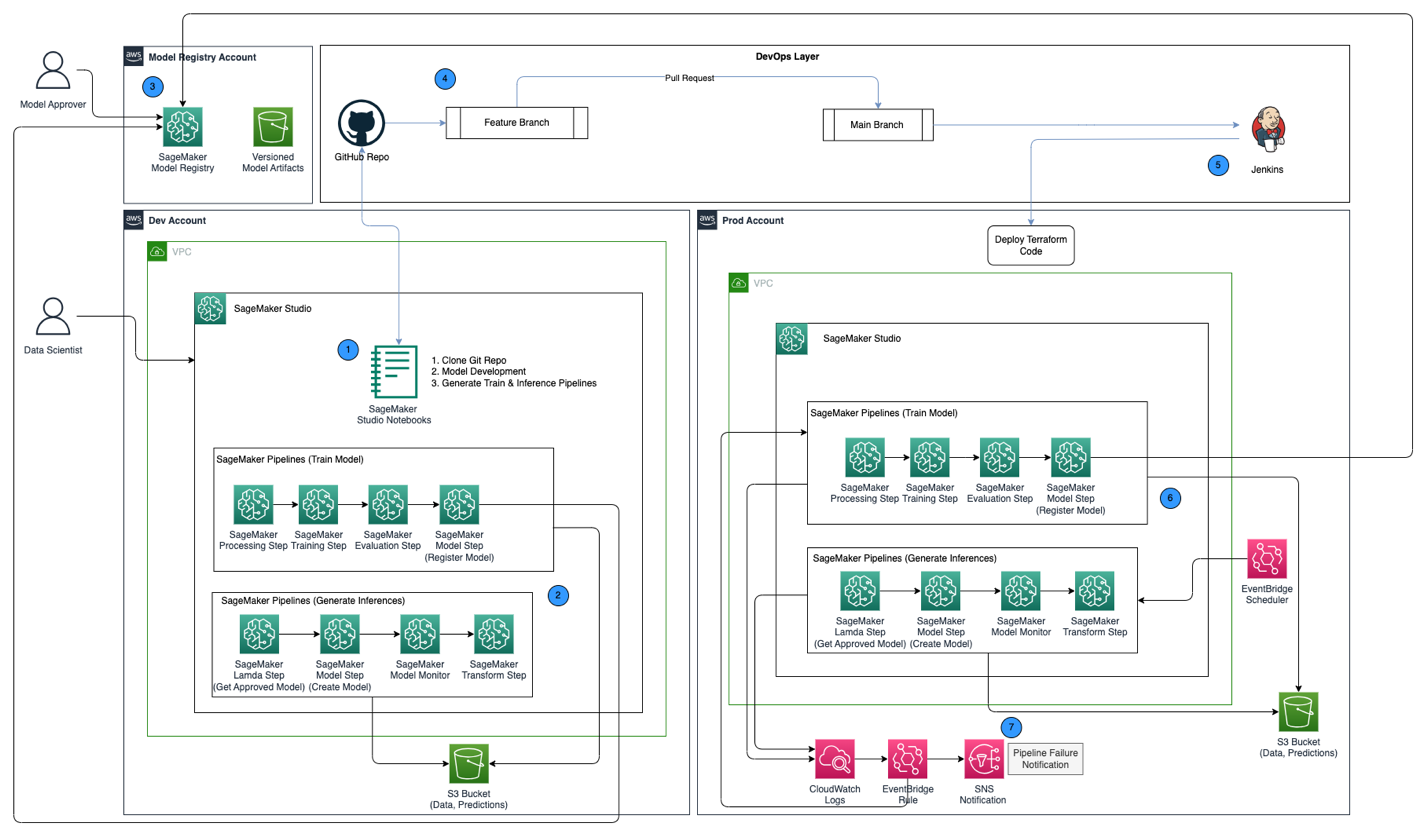
El flujo de trabajo de MLOps incluye los siguientes pasos:
- Acceda al dominio de SageMaker Studio en la cuenta de desarrollo, clone el repositorio de GitHub, realice el proceso de desarrollo del modelo utilizando el modelo de muestra proporcionado y genere el tren y los canales de inferencia.
- Ejecute la canalización de tren en la cuenta de desarrollo, que genera los artefactos del modelo para la versión del modelo entrenado y registra el modelo en SageMaker Model Registry en la cuenta de registro de modelo central.
- Apruebe el modelo en el Registro de modelos de SageMaker en la cuenta de registro de modelos central.
- Inserte el código (canalizaciones de entrenamiento e inferencia, y el código Terraform IaC para crear la programación de EventBridge, la regla de EventBridge y el tema de SNS) en una rama de funciones del repositorio de GitHub. Cree una solicitud de extracción para fusionar el código en la rama principal del repositorio de GitHub.
- Active la canalización de CI/CD de Jenkins, que está configurada con el repositorio de GitHub. La canalización de CI/CD implementa el código en la cuenta de producción para crear las canalizaciones de tren y de inferencia junto con el código de Terraform para aprovisionar la programación de EventBridge, la regla de EventBridge y el tema de SNS.
- El canal de inferencia está programado para funcionar diariamente, mientras que el canal del tren está configurado para funcionar cada vez que se detecta una desviación de datos en el canal de inferencia.
- Las notificaciones se envían a través del tema SNS cada vez que hay una falla en el tren o en el canal de inferencia.
Requisitos previos
Para esta solución, debe tener los siguientes requisitos previos:
- Tres cuentas de AWS (cuentas de desarrollo, producción y registro de modelo central)
- Un dominio de SageMaker Studio configurado en cada una de las tres cuentas de AWS (consulte Incorporado a Amazon SageMaker Studio o mira el video Incorporación rápida a Amazon SageMaker Studio para instrucciones de configuración)
- Jenkins (usamos Jenkins 2.401.1) con privilegios administrativos instalado en AWS
- Terraform versión 1.5.5 o posterior instalada en el servidor Jenkins
Para este post trabajamos en el us-east-1 Región para implementar la solución.
Aprovisionar claves KMS en cuentas de desarrollo y producción
Nuestro primer paso es crear Servicio de administración de claves de AWS (AWS KMS) en las cuentas de desarrollo y producción.
Cree una clave KMS en la cuenta de desarrollo y otorgue acceso a la cuenta de producción
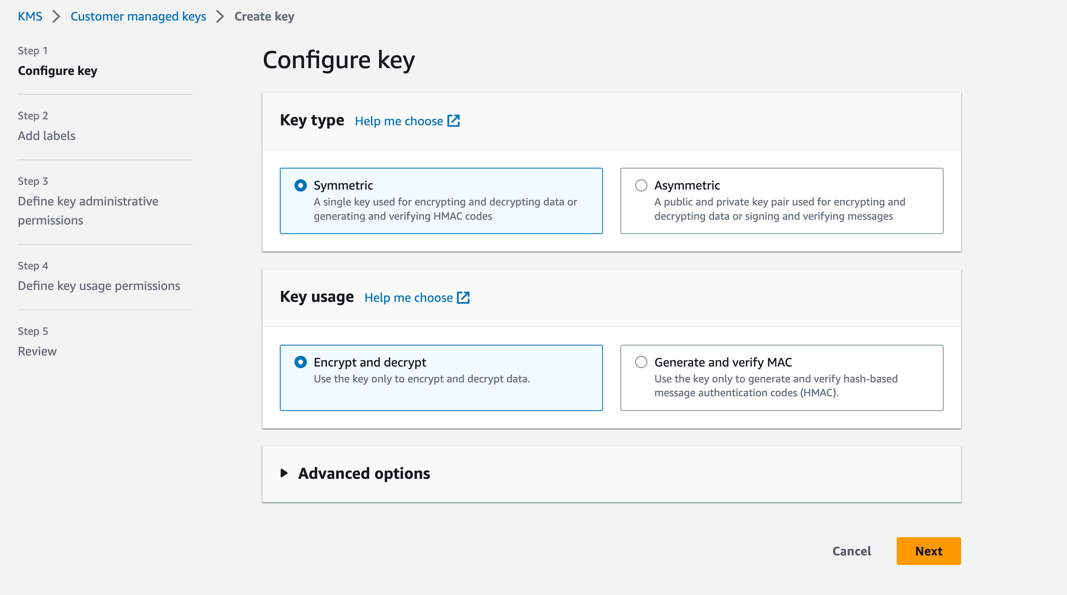
Complete los siguientes pasos para crear una clave KMS en la cuenta de desarrollo:
- En la consola de AWS KMS, elija Claves administradas por el cliente en el panel de navegación.
- Elige Crear clave.
- Tipo de llave, seleccione Simétrico .
- Uso de claves, seleccione Cifrar y descifrar.
- Elige Siguiente.
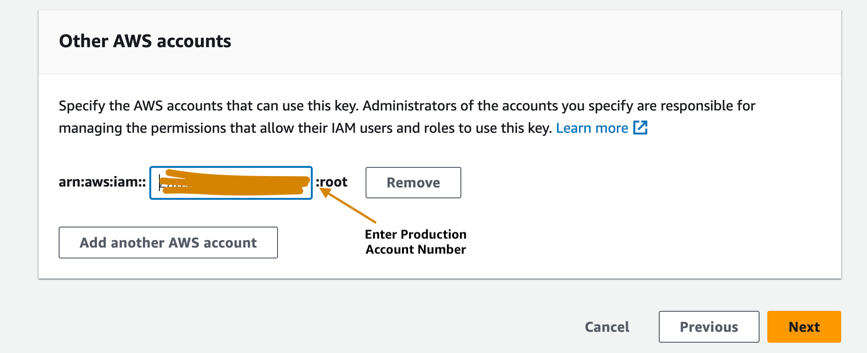
- Ingrese el número de cuenta de producción para otorgarle acceso a la clave KMS proporcionada en la cuenta de desarrollo. Este es un paso necesario porque la primera vez que se entrena el modelo en la cuenta de desarrollo, los artefactos del modelo se cifran con la clave KMS antes de escribirse en el depósito S3 en la cuenta de registro central del modelo. La cuenta de producción necesita acceso a la clave KMS para poder descifrar los artefactos del modelo y ejecutar la canalización de inferencia.
- Elige Siguiente y termine de crear su clave.
Una vez suministrada la clave, debería estar visible en la consola de AWS KMS.
Cree una clave KMS en la cuenta de producción
Siga los mismos pasos en la sección anterior para crear una clave KMS administrada por el cliente en la cuenta de producción. Puede omitir el paso para compartir la clave KMS con otra cuenta.
Configure un depósito S3 de artefactos de modelo en la cuenta de registro de modelo central
Cree un depósito S3 de su elección con la cadena sagemaker en la convención de nomenclatura como parte del nombre del depósito en la cuenta de registro del modelo central, y actualice la política del depósito en el depósito de S3 para otorgar permisos tanto a las cuentas de desarrollo como a las de producción para leer y escribir artefactos del modelo en el depósito de S3.
El siguiente código es la política del depósito que se actualizará en el depósito S3:
Configure roles de IAM en sus cuentas de AWS
El siguiente paso es configurar Gestión de identidades y accesos de AWS (IAM) en sus cuentas de AWS con permisos para AWS Lambda, SageMaker y Jenkins.
Rol de ejecución de Lambda
Preparar Roles de ejecución de Lambda en las cuentas dev y prod, que serán utilizadas por la función Lambda ejecutada como parte del Paso Lambda de SageMaker Pipelines. Este paso se ejecutará desde el proceso de inferencia para obtener el último modelo aprobado, mediante el cual se generan las inferencias. Cree roles de IAM en las cuentas de desarrollo y producción con la convención de nomenclatura arn:aws:iam::<account-id>:role/lambda-sagemaker-role y adjunte las siguientes políticas de IAM:
- Política 1 – Cree una política en línea denominada
cross-account-model-registry-access, que da acceso al paquete de modelos configurado en el registro de modelos en la cuenta central: - Política 2 - Adjuntar AmazonSageMakerFullAccess, que es un Política administrada por AWS que otorga acceso completo a SageMaker. También proporciona acceso selecto a servicios relacionados, como Escalado automático de aplicaciones de AWS, amazon s3, Registro de contenedores elásticos de Amazon (Amazon ECR) y Registros de Amazon CloudWatch.
- Política 3 - Adjuntar AWSLambda_FullAccess, que es una política administrada por AWS que otorga acceso completo a Lambda, las funciones de la consola Lambda y otros servicios de AWS relacionados.
- Política 4 – Utilice la siguiente política de confianza de IAM para la función de IAM:
Rol de ejecución de SageMaker
Los dominios de SageMaker Studio configurados en las cuentas de desarrollo y producción deben tener cada uno una función de ejecución asociada, que se puede encontrar en la página Configuraciones de dominio en la página de detalles del dominio, como se muestra en la siguiente captura de pantalla. Esta función se utiliza para ejecutar trabajos de capacitación, trabajos de procesamiento y más dentro del dominio de SageMaker Studio.
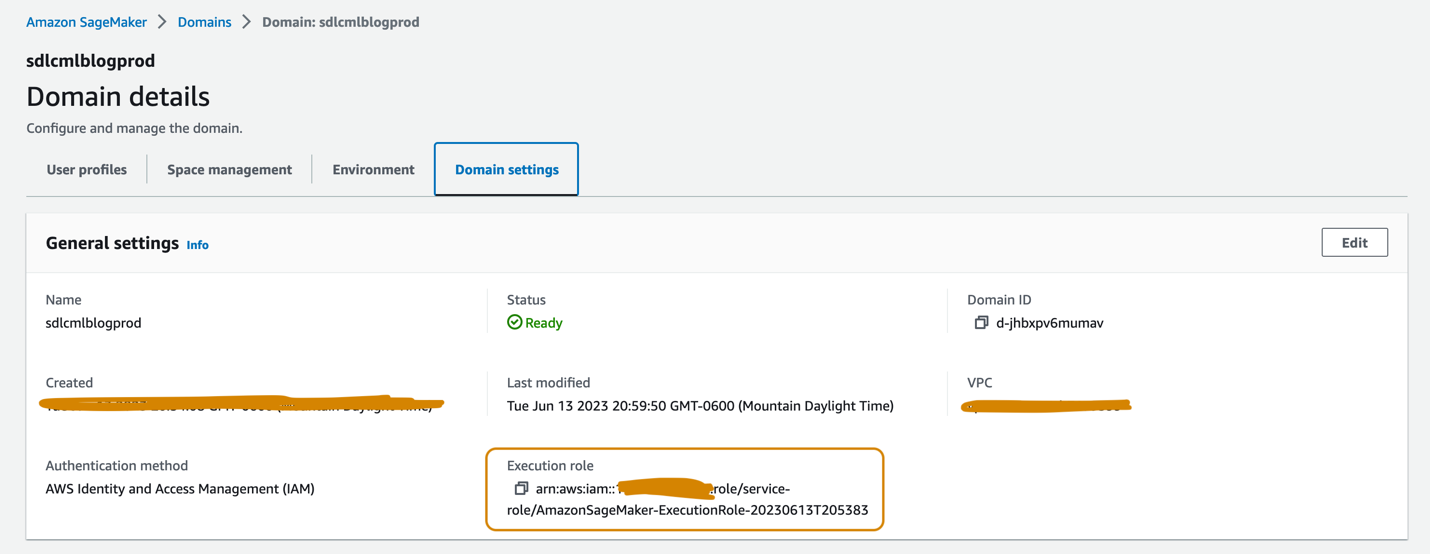
Agregue las siguientes políticas al rol de ejecución de SageMaker en ambas cuentas:
- Política 1 – Cree una política en línea denominada
cross-account-model-artifacts-s3-bucket-access, que brinda acceso al depósito S3 en la cuenta de registro del modelo central, que almacena los artefactos del modelo: - Política 2 – Cree una política en línea denominada
cross-account-model-registry-access, que da acceso al paquete de modelo en el registro de modelo en la cuenta de registro de modelo central: - Política 3 – Cree una política en línea denominada
kms-key-access-policy, que da acceso a la clave KMS creada en el paso anterior. Proporcione el ID de la cuenta en la que se crea la política y el ID de la clave KMS creada en esa cuenta. - Política 4 - Adjuntar AmazonSageMakerFullAccess, que es un Política administrada por AWS que otorga acceso completo a SageMaker y acceso selecto a servicios relacionados.
- Política 5 - Adjuntar AWSLambda_FullAccess, que es una política administrada por AWS que otorga acceso completo a Lambda, las funciones de la consola Lambda y otros servicios de AWS relacionados.
- Política 6 - Adjuntar CloudWatchEventsFullAccess, que es una política administrada por AWS que otorga acceso completo a CloudWatch Events.
- Política 7 – Agregue la siguiente política de confianza de IAM para la función de ejecución de IAM de SageMaker:
- Política 8 (específica para la función de ejecución de SageMaker en la cuenta de producción) – Cree una política en línea denominada
cross-account-kms-key-access-policy, que brinda acceso a la clave KMS creada en la cuenta de desarrollo. Esto es necesario para que la canalización de inferencia lea los artefactos del modelo almacenados en la cuenta de registro del modelo central, donde los artefactos del modelo se cifran mediante la clave KMS de la cuenta de desarrollo cuando se crea la primera versión del modelo desde la cuenta de desarrollo.
Rol de Jenkins entre cuentas
Configure un rol de IAM llamado cross-account-jenkins-role en la cuenta de producción, que Jenkins asumirá para implementar canalizaciones de ML y la infraestructura correspondiente en la cuenta de producción.
Agregue las siguientes políticas de IAM administradas al rol:
CloudWatchFullAccessAmazonS3FullAccessAmazonSNSFullAccessAmazonSageMakerFullAccessAmazonEventBridgeFullAccessAWSLambda_FullAccess
Actualice la relación de confianza en el rol para otorgar permisos a la cuenta de AWS que aloja el servidor Jenkins:
Actualizar permisos en el rol de IAM asociado con el servidor Jenkins
Suponiendo que Jenkins se haya configurado en AWS, actualice la función de IAM asociada con Jenkins para agregar las siguientes políticas, que le darán a Jenkins acceso para implementar los recursos en la cuenta de producción:
- Política 1 – Cree la siguiente política en línea denominada
assume-production-role-policy: - Política 2 - Adjunta
CloudWatchFullAccesspolítica de IAM administrada.
Configure el grupo de paquetes de modelos en la cuenta de registro de modelos central
Desde el dominio de SageMaker Studio en la cuenta de registro de modelo central, cree un grupo de paquetes de modelo llamado mammo-severity-model-package usando el siguiente fragmento de código (que puede ejecutar usando un cuaderno Jupyter):
Configurar el acceso al paquete modelo para roles de IAM en las cuentas de desarrollo y producción
Proporcione acceso a los roles de ejecución de SageMaker creados en las cuentas de desarrollo y producción para que pueda registrar versiones de modelos dentro del paquete de modelos. mammo-severity-model-package en el registro central de modelos de ambas cuentas. Desde el dominio de SageMaker Studio en la cuenta de registro del modelo central, ejecute el siguiente código en un cuaderno Jupyter:
Configurar Jenkins
En esta sección, configuramos Jenkins para crear las canalizaciones de ML y la infraestructura Terraform correspondiente en la cuenta de producción a través de la canalización de CI/CD de Jenkins.
- En la consola de CloudWatch, cree un grupo de registros llamado
jenkins-logdentro de la cuenta de producción a la que Jenkins enviará registros desde la canalización de CI/CD. El grupo de registros debe crearse en la misma región donde está configurado el servidor Jenkins.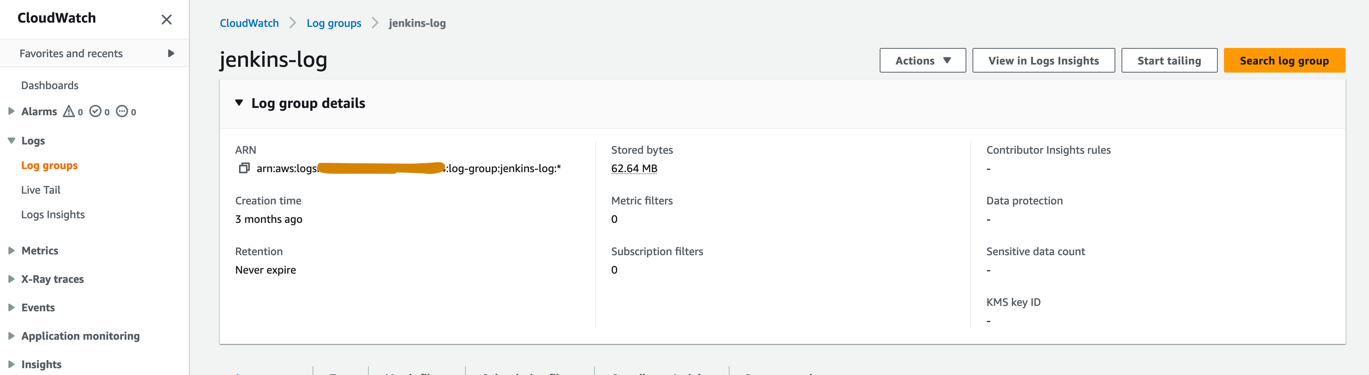
- Instale los siguientes complementos en su servidor Jenkins:
- Configure las credenciales de AWS en Jenkins utilizando el rol de IAM entre cuentas (
cross-account-jenkins-role) provisionado en la cuenta prod.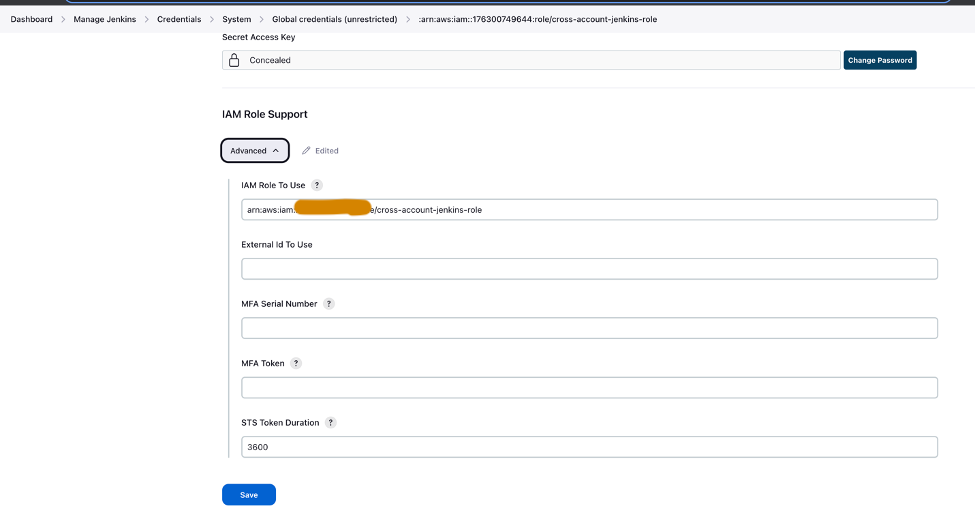
- Configuración del Sistema, escoger AWS.

- Proporcione las credenciales y el grupo de registros de CloudWatch que creó anteriormente.

- Configure las credenciales de GitHub dentro de Jenkins.
- Crea un nuevo proyecto en Jenkins.
- Introduce un nombre de proyecto y elige Tubería.
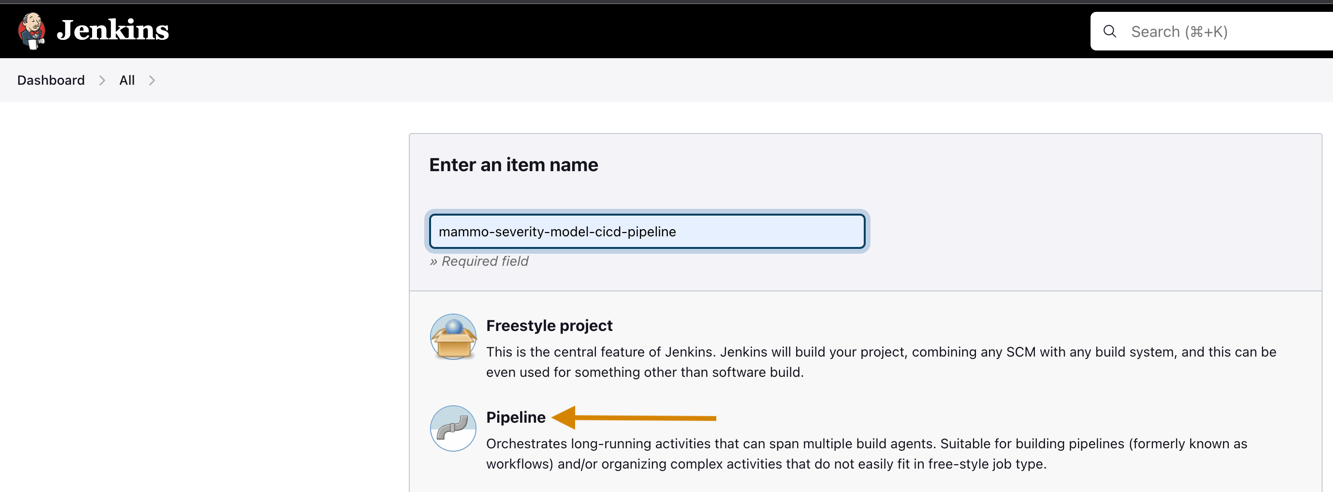
- En General seleccione Proyecto GitHub y entra en la bifurcación Repositorio GitHub URL.
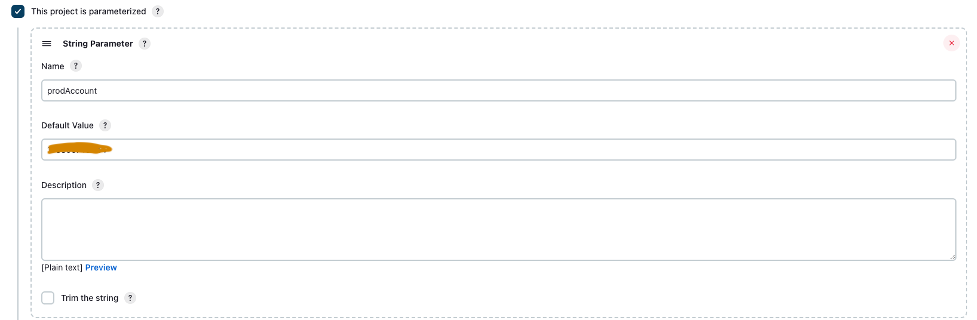
- Seleccione Este proyecto está parametrizado.
- En Agregar parámetro menú, seleccione Parámetro de cadena.

- Nombre, introduzca
prodAccount. - Valor por defecto, ingrese el ID de la cuenta de producción.
- under Opciones de proyecto avanzadas, Para Definición, seleccione Script de canalización de SCM.
- SMC, escoger Git.
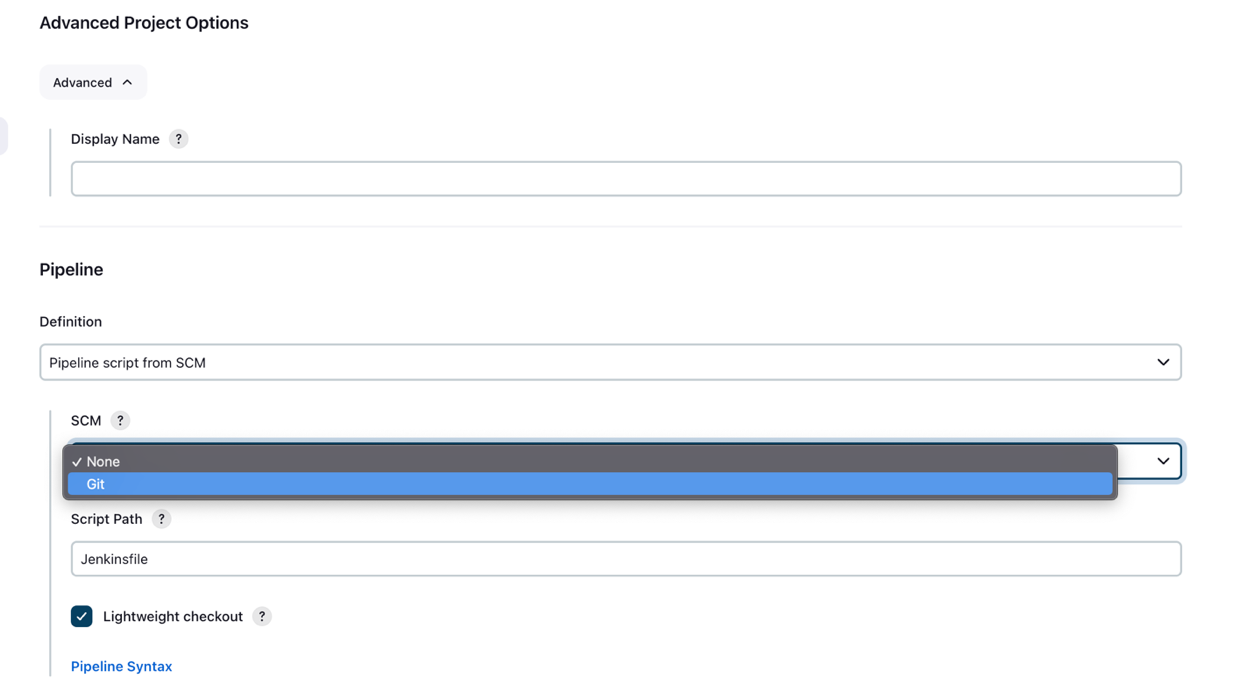
- URL del repositorio, entra en el bifurcado Repositorio GitHub URL.
- Referencias, ingrese las credenciales de GitHub guardadas en Jenkins.
- Participar
mainexistentes Ramas para construir sección, en función de la cual se activará la canalización de CI/CD.
- Ruta del guión, introduzca
Jenkinsfile. - Elige Guardar.
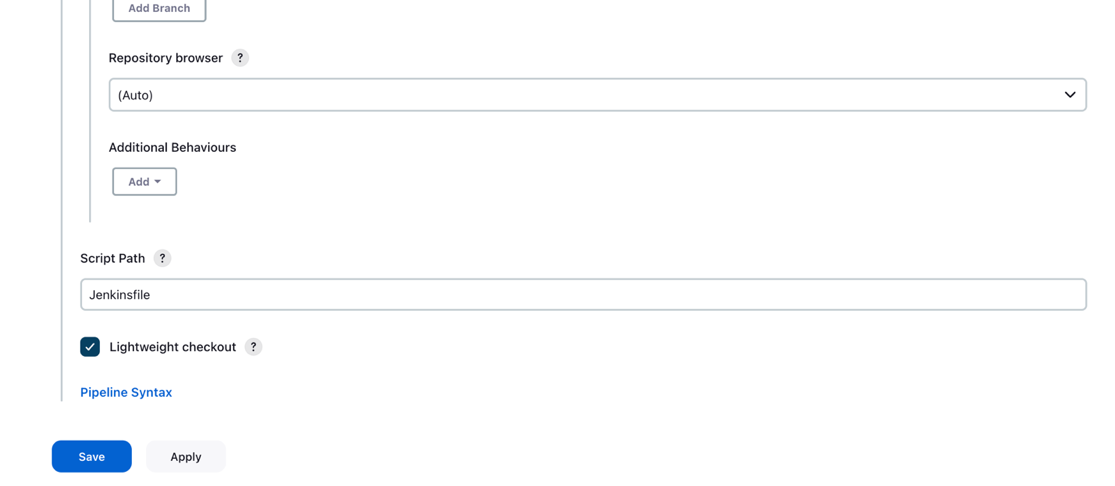
La canalización de Jenkins debe crearse y estar visible en su panel.
Aprovisione depósitos de S3, recopile y prepare datos
Complete los siguientes pasos para configurar sus depósitos y datos de S3:
- Cree un depósito S3 de su elección con la cadena
sagemakeren la convención de nomenclatura como parte del nombre del depósito en las cuentas de desarrollo y producción para almacenar conjuntos de datos y artefactos de modelo. - Configure un depósito de S3 para mantener el estado de Terraform en la cuenta de producción.
- Descargue y guarde el disponible públicamente. Masa de mamografía UCI conjunto de datos al depósito S3 que creó anteriormente en la cuenta de desarrollo.
- Bifurca y clona el Repositorio GitHub dentro del dominio de SageMaker Studio en la cuenta de desarrollo. El repositorio tiene la siguiente estructura de carpetas:
- /environments – Script de configuración para el entorno de producción
- /mlops-infra – Código para implementar servicios de AWS utilizando el código Terraform
- / pipelines - Código para componentes de canalización de SageMaker
- Jenkinsfile – Script para implementar a través del canal Jenkins CI/CD
- configuración.py – Necesario para instalar los módulos Python necesarios y crear el comando run-pipeline
- modelado-de-gravedad-de-mamografía.ipynb - Le permite crear y ejecutar el flujo de trabajo de ML
- Cree una carpeta llamada datos dentro de la carpeta del repositorio de GitHub clonado y guarde una copia de la disponible públicamente. Masa de mamografía UCI conjunto de datos
- Siga el cuaderno de Jupyter
mammography-severity-modeling.ipynb. - Ejecute el siguiente código en el cuaderno para preprocesar el conjunto de datos y cárguelo en el depósito S3 en la cuenta de desarrollo:
El código generará los siguientes conjuntos de datos:
-
- datos/ mammo-train-dataset-part1.csv – Se utilizará para entrenar la primera versión del modelo.
- datos/ mammo-train-dataset-part2.csv – Se utilizará para entrenar la segunda versión del modelo junto con el conjunto de datos mammo-train-dataset-part1.csv.
- datos/mammo-batch-dataset.csv – Se utilizará para generar inferencias.
- datos/mammo-batch-dataset-outliers.csv – Introducirá valores atípicos en el conjunto de datos para fallar el proceso de inferencia. Esto nos permitirá probar el patrón para activar el reentrenamiento automatizado del modelo.
- Sube el conjunto de datos
mammo-train-dataset-part1.csvbajo el prefijomammography-severity-model/train-datasety cargar los conjuntos de datosmammo-batch-dataset.csvymammo-batch-dataset-outliers.csval prefijomammography-severity-model/batch-datasetdel depósito S3 creado en la cuenta de desarrollo: - Cargar los conjuntos de datos
mammo-train-dataset-part1.csvymammo-train-dataset-part2.csvbajo el prefijomammography-severity-model/train-dataseten el depósito S3 creado en la cuenta prod a través de la consola de Amazon S3.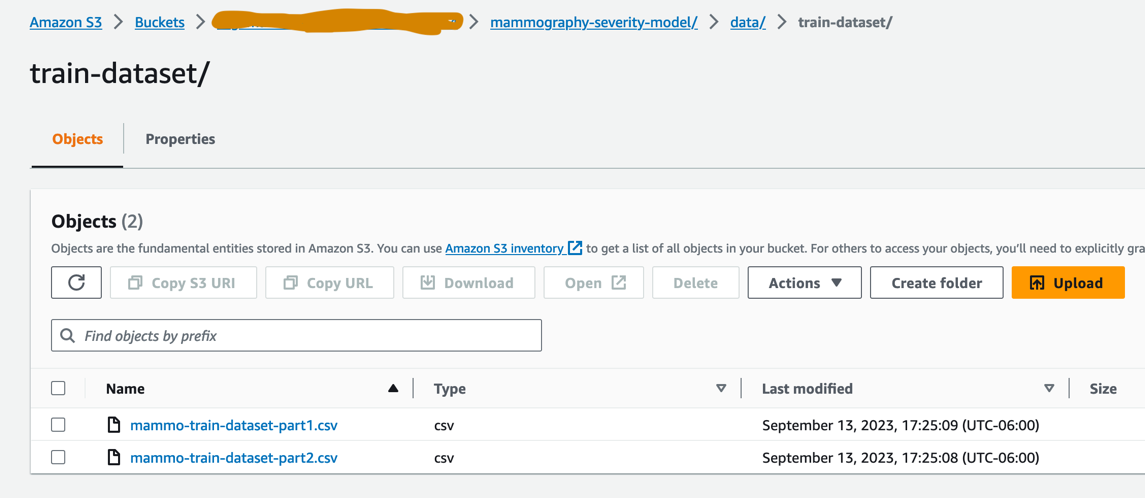
- Cargar los conjuntos de datos
mammo-batch-dataset.csvymammo-batch-dataset-outliers.csval prefijomammography-severity-model/batch-datasetdel depósito S3 en la cuenta de producción.
Ejecute el oleoducto del tren
under <project-name>/pipelines/train, puede ver los siguientes scripts de Python:
- scripts/raw_preprocess.py - Se integra con SageMaker Processing para la ingeniería de funciones
- scripts/evaluar_model.py – Permite el cálculo de métricas del modelo, en este caso
auc_score - tren_pipeline.py – Contiene el código para el proceso de capacitación del modelo.
Complete los siguientes pasos:
- Cargue los scripts en Amazon S3:
- Obtenga la instancia de la tubería del tren:
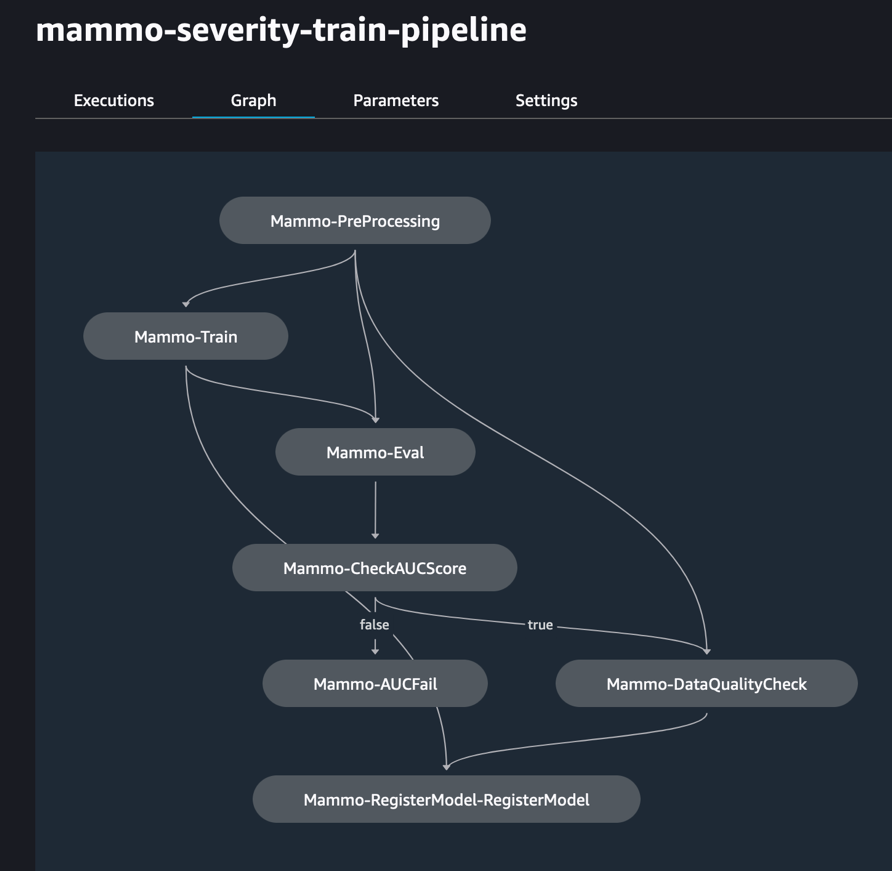
- Envíe la tubería del tren y ejecútela:
La siguiente figura muestra una ejecución exitosa del proceso de capacitación. El último paso del proceso registra el modelo en la cuenta de registro central de modelos.

Aprobar el modelo en el registro central de modelos.
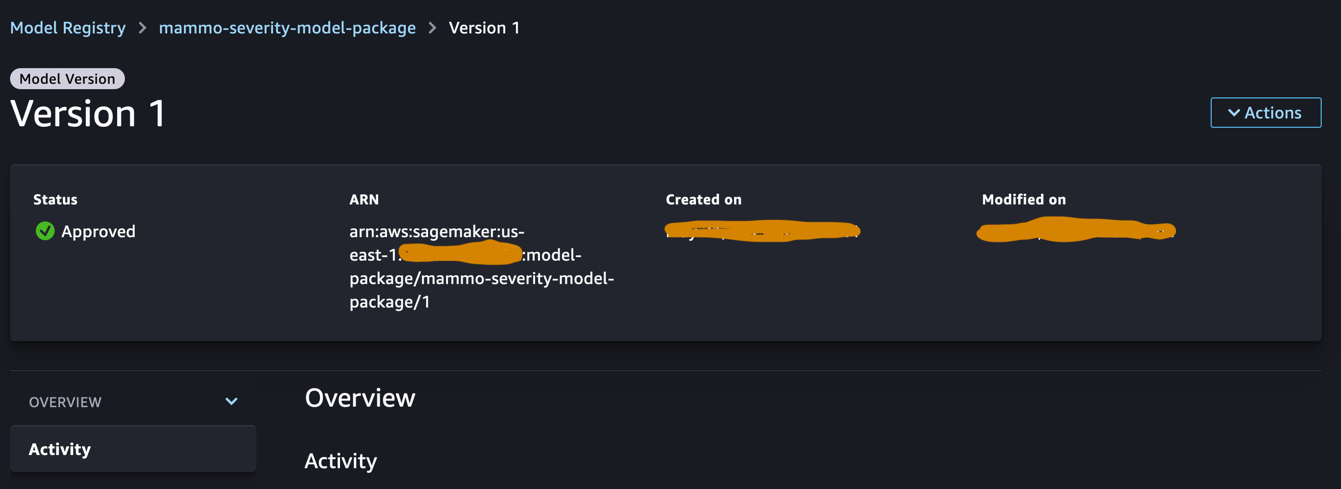
Inicie sesión en la cuenta de registro de modelos central y acceda al registro de modelos de SageMaker dentro del dominio de SageMaker Studio. Cambie el estado de la versión del modelo a Aprobado.
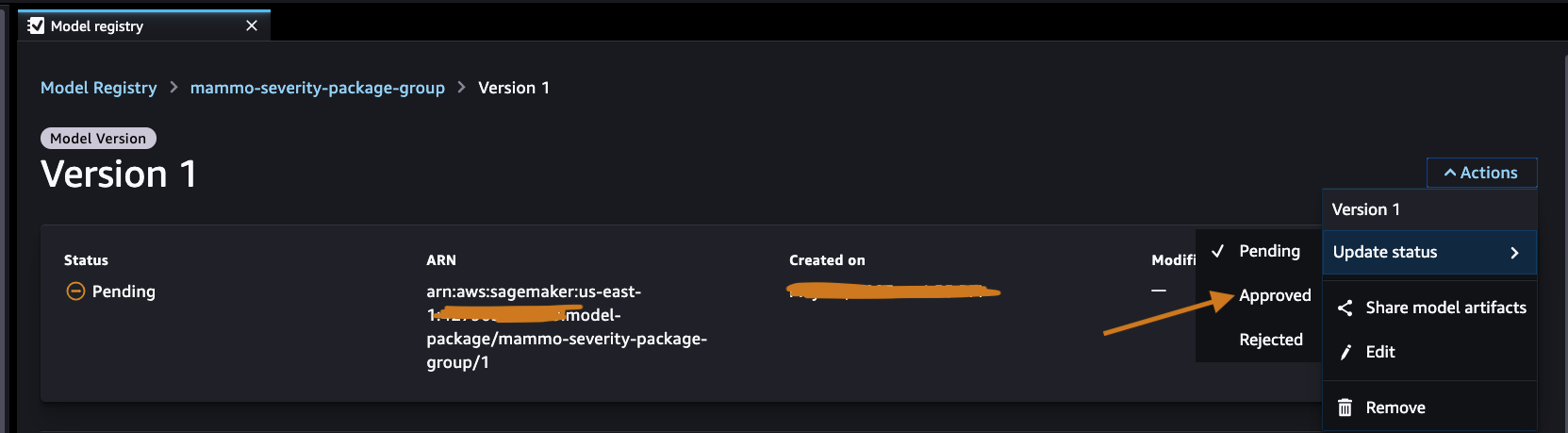
Una vez aprobado, el estado debe cambiarse en la versión del modelo.
Ejecutar el canal de inferencia (opcional)
Este paso no es necesario, pero aún puede ejecutar el proceso de inferencia para generar predicciones en la cuenta de desarrollo.
under <project-name>/pipelines/inference, puede ver los siguientes scripts de Python:
- scripts/lambda_helper.py – Extrae la última versión del modelo aprobado de la cuenta de registro de modelo central mediante un paso Lambda de SageMaker Pipelines
- inferencia_pipeline.py – Contiene el código para el proceso de inferencia del modelo.
Complete los siguientes pasos:
- Cargue el script en el depósito de S3:
- Obtenga la instancia del canal de inferencia utilizando el conjunto de datos por lotes normal:
- Envíe el canal de inferencia y ejecútelo:
La siguiente figura muestra una ejecución exitosa del proceso de inferencia. El último paso del proceso genera las predicciones y las almacena en el depósito de S3. Usamos MonitorBatchTransformStep para monitorear las entradas en el trabajo de transformación por lotes. Si hay valores atípicos, el proceso de inferencia entra en un estado fallido.
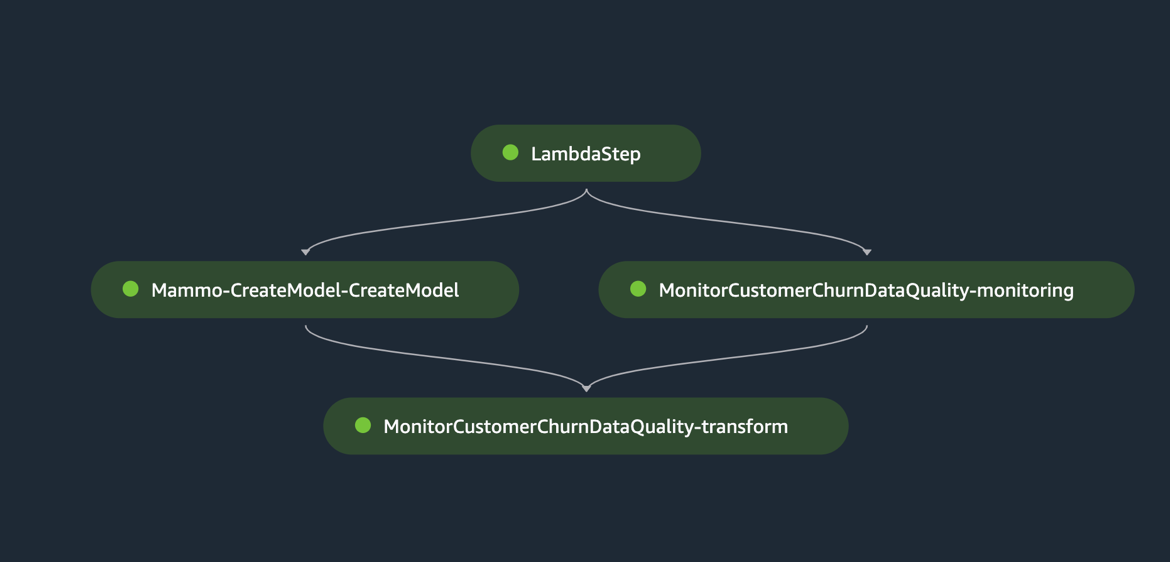
Ejecute el oleoducto Jenkins
La environment/ La carpeta dentro del repositorio de GitHub contiene el script de configuración para la cuenta prod. Complete los siguientes pasos para activar la canalización de Jenkins:
- Actualizar el script de configuración
prod.tfvars.jsonen base a los recursos creados en los pasos anteriores: - Una vez actualizado, inserte el código en el repositorio bifurcado de GitHub y combine el código en la rama principal.
- Vaya a la interfaz de usuario de Jenkins, elija Construir con parámetrosy active la canalización de CI/CD creada en los pasos anteriores.

Cuando la compilación esté completa y sea exitosa, podrá iniciar sesión en la cuenta de producción y ver los canales de entrenamiento y de inferencia dentro del dominio de SageMaker Studio.
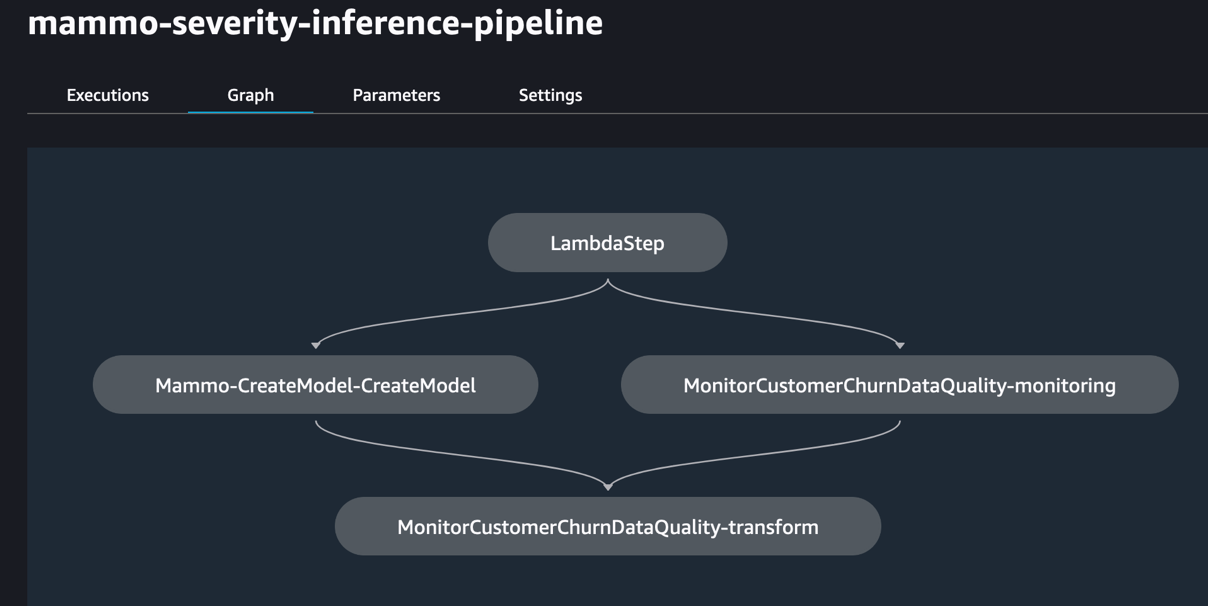
Además, verá tres reglas de EventBridge en la consola de EventBridge en la cuenta de producción:
- Programar el proceso de inferencia
- Enviar una notificación de falla en la tubería del tren.
- Cuando el canal de inferencia no logra activar el canal del tren, envíe una notificación

Finalmente, verá un tema de notificación de SNS en la consola de Amazon SNS que envía notificaciones por correo electrónico. Recibirá un correo electrónico pidiéndole que confirme la aceptación de estos correos electrónicos de notificación.

Pruebe el proceso de inferencia utilizando un conjunto de datos por lotes sin valores atípicos
Para probar si el proceso de inferencia funciona como se esperaba en la cuenta de producción, podemos iniciar sesión en la cuenta de producción y activar el proceso de inferencia utilizando el conjunto de datos por lotes sin valores atípicos.
Ejecute la canalización a través de la consola de SageMaker Pipelines en el dominio de SageMaker Studio de la cuenta de producción, donde transform_input será el URI de S3 del conjunto de datos sin valores atípicos (s3://<s3-bucket-in-prod-account>/mammography-severity-model/data/mammo-batch-dataset.csv).
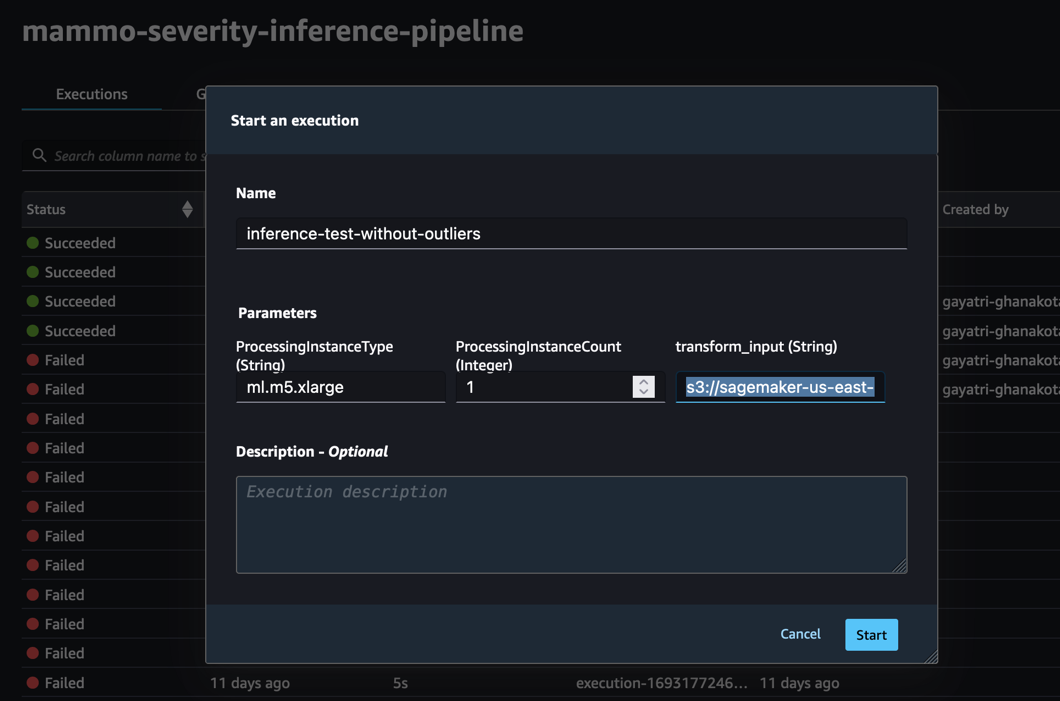
La canalización de inferencia tiene éxito y escribe las predicciones en el depósito de S3.
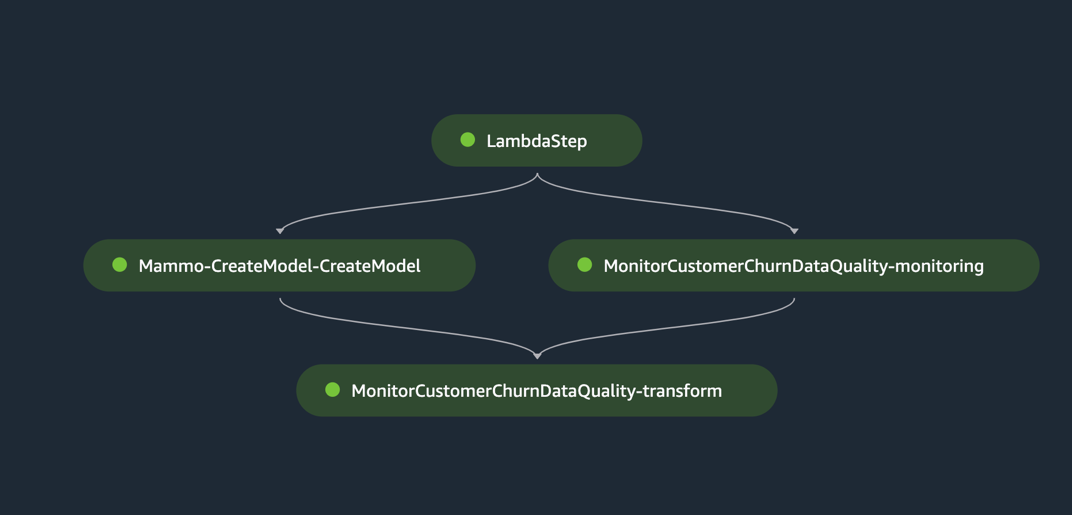
Pruebe el proceso de inferencia utilizando un conjunto de datos por lotes con valores atípicos
Puede ejecutar el proceso de inferencia utilizando el conjunto de datos por lotes con valores atípicos para comprobar si el mecanismo de reentrenamiento automatizado funciona como se esperaba.
Ejecute la canalización a través de la consola de SageMaker Pipelines en el dominio de SageMaker Studio de la cuenta de producción, donde transform_input será el URI de S3 del conjunto de datos con valores atípicos (s3://<s3-bucket-in-prod-account>/mammography-severity-model/data/mammo-batch-dataset-outliers.csv).

El proceso de inferencia falla como se esperaba, lo que activa la regla EventBridge, que a su vez activa el proceso de tren.
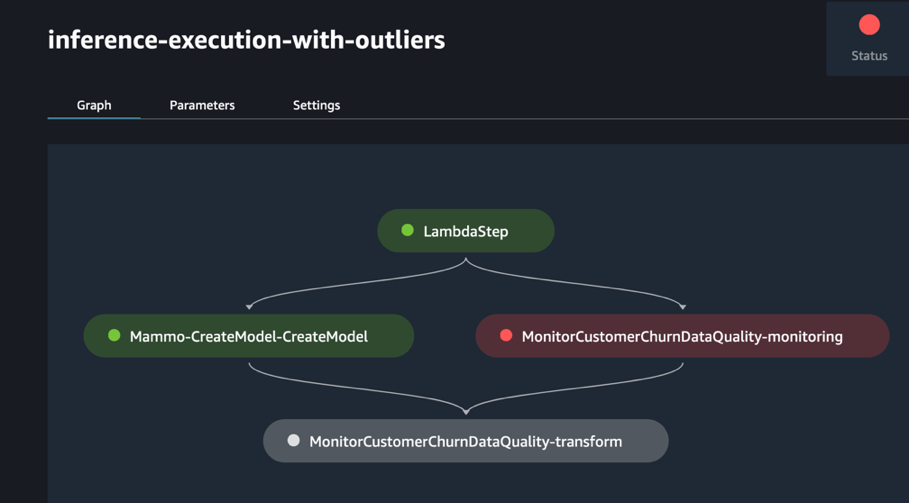
Después de unos momentos, debería ver una nueva ejecución de la tubería del tren en la consola de SageMaker Pipelines, que recoge los dos conjuntos de datos de trenes diferentes (mammo-train-dataset-part1.csv y mammo-train-dataset-part2.csv) cargado en el depósito S3 para volver a entrenar el modelo.

También verá una notificación enviada al correo electrónico suscrito al tema de SNS.
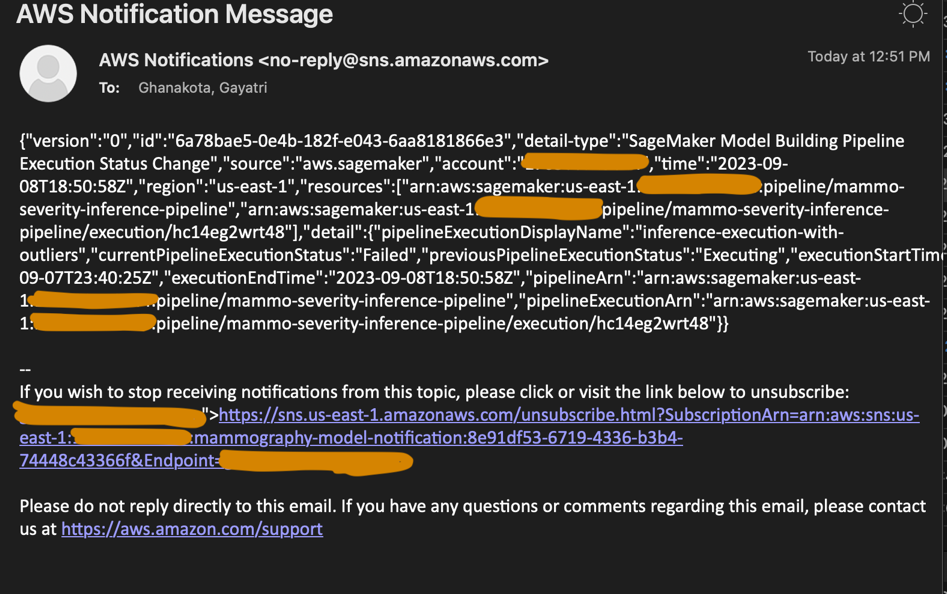
Para utilizar la versión actualizada del modelo, inicie sesión en la cuenta de registro central del modelo y apruebe la versión del modelo, que se seleccionará durante la siguiente ejecución del canal de inferencia activado a través de la regla EventBridge programada.
Aunque las canalizaciones de tren y de inferencia utilizan una URL de conjunto de datos estática, puede pasar la URL del conjunto de datos a las canalizaciones de tren y de inferencia como variables dinámicas para utilizar conjuntos de datos actualizados para volver a entrenar el modelo y generar predicciones en un escenario del mundo real.
Limpiar
Para evitar incurrir en cargos futuros, complete los siguientes pasos:
- Elimine el dominio de SageMaker Studio en todas las cuentas de AWS.
- Elimine todos los recursos creados fuera de SageMaker, incluidos los depósitos de S3, las funciones de IAM, las reglas de EventBridge y los temas de SNS configurados a través de Terraform en la cuenta de producción.
- Elimine las canalizaciones de SageMaker creadas entre cuentas utilizando el Interfaz de línea de comandos de AWS (CLI de AWS).
Conclusión
Las organizaciones a menudo necesitan alinearse con conjuntos de herramientas de toda la empresa para permitir la colaboración entre diferentes áreas funcionales y equipos. Esta colaboración garantiza que su plataforma MLOps pueda adaptarse a las necesidades comerciales en evolución y acelera la adopción de ML en todos los equipos. Esta publicación explicó cómo crear un marco MLOps en una configuración de múltiples entornos para permitir el reentrenamiento automatizado de modelos, la inferencia por lotes y el monitoreo con Amazon SageMaker Model Monitor, el control de versiones de modelos con SageMaker Model Registry y la promoción de código y canalizaciones de aprendizaje automático en todos los entornos con un Tubería de CI/CD. Mostramos esta solución utilizando una combinación de servicios de AWS y conjuntos de herramientas de terceros. Para obtener instrucciones sobre cómo implementar esta solución, consulte la Repositorio GitHub. También puede ampliar esta solución incorporando sus propias fuentes de datos y marcos de modelado.
Acerca de los autores
 Gayatri Ghanakota es ingeniero sénior de aprendizaje automático en AWS Professional Services. Le apasiona desarrollar, implementar y explicar soluciones de IA/ML en varios dominios. Antes de este cargo, lideró múltiples iniciativas como científica de datos e ingeniera de ML con las principales firmas globales en el espacio financiero y minorista. Tiene una maestría en Ciencias de la Computación especializada en Ciencia de Datos de la Universidad de Colorado, Boulder.
Gayatri Ghanakota es ingeniero sénior de aprendizaje automático en AWS Professional Services. Le apasiona desarrollar, implementar y explicar soluciones de IA/ML en varios dominios. Antes de este cargo, lideró múltiples iniciativas como científica de datos e ingeniera de ML con las principales firmas globales en el espacio financiero y minorista. Tiene una maestría en Ciencias de la Computación especializada en Ciencia de Datos de la Universidad de Colorado, Boulder.
 Sunita Koppar es un arquitecto sénior de lago de datos con servicios profesionales de AWS. Le apasiona resolver los problemas de los clientes al procesar big data y brindar soluciones escalables a largo plazo. Antes de ocupar este puesto, desarrolló productos en los dominios de Internet, telecomunicaciones y automoción, y ha sido cliente de AWS. Tiene una maestría en Ciencia de Datos de la Universidad de California, Riverside.
Sunita Koppar es un arquitecto sénior de lago de datos con servicios profesionales de AWS. Le apasiona resolver los problemas de los clientes al procesar big data y brindar soluciones escalables a largo plazo. Antes de ocupar este puesto, desarrolló productos en los dominios de Internet, telecomunicaciones y automoción, y ha sido cliente de AWS. Tiene una maestría en Ciencia de Datos de la Universidad de California, Riverside.
 Dash Saswata es consultor de DevOps en AWS Professional Services. Ha trabajado con clientes de los sectores de la salud y las ciencias biológicas, la aviación y la fabricación. Le apasiona todo lo relacionado con la automatización y tiene una amplia experiencia en el diseño y creación de soluciones para clientes a escala empresarial en AWS. Fuera del trabajo, se dedica a su pasión por la fotografía y captar amaneceres.
Dash Saswata es consultor de DevOps en AWS Professional Services. Ha trabajado con clientes de los sectores de la salud y las ciencias biológicas, la aviación y la fabricación. Le apasiona todo lo relacionado con la automatización y tiene una amplia experiencia en el diseño y creación de soluciones para clientes a escala empresarial en AWS. Fuera del trabajo, se dedica a su pasión por la fotografía y captar amaneceres.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/promote-pipelines-in-a-multi-environment-setup-using-amazon-sagemaker-model-registry-hashicorp-terraform-github-and-jenkins-ci-cd/

