Esta serie de tres partes demuestra cómo usar redes neuronales gráficas (GNN) y Amazonas Neptuno para generar recomendaciones de películas usando el IMDb y Box Office Mojo Películas/TV/OTT paquete de datos con licencia, que proporciona una amplia gama de metadatos de entretenimiento, incluidas más de mil millones de calificaciones de usuarios; créditos para más de 1 millones de miembros del elenco y del equipo; 11 millones de títulos de películas, televisión y entretenimiento; y datos de informes de taquilla global de más de 9 países. Muchos clientes de medios y entretenimiento de AWS obtienen licencias de datos de IMDb a través de Intercambio de datos de AWS para mejorar el descubrimiento de contenido y aumentar el compromiso y la retención del cliente.
El siguiente diagrama ilustra la arquitectura completa implementada como parte de esta serie.

In Parte 1, discutimos las aplicaciones de GNN y cómo transformar y preparar nuestros datos de IMDb en un gráfico de conocimiento (KG). Descargamos los datos de AWS Data Exchange y los procesamos en Pegamento AWS para generar archivos KG. Los archivos KG se almacenaron en Servicio de almacenamiento simple de Amazon (Amazon S3) y luego cargado en Amazonas Neptuno.
In Parte 2, demostramos cómo usar Aprendizaje automático de Amazon Neptune (en Amazon SageMaker) para entrenar el KG y crear incrustaciones de KG.
En esta publicación, lo guiaremos a través de cómo aplicar nuestras incrustaciones KG entrenadas en Amazon S3 para casos de uso de búsqueda fuera del catálogo usando Servicio Amazon OpenSearch y AWS Lambda. También implementa una aplicación web local para una experiencia de búsqueda interactiva. Todos los recursos utilizados en esta publicación se pueden crear usando un solo Kit de desarrollo en la nube de AWS (AWS CDK) como se describe más adelante en la publicación.
Antecedentes
¿Alguna vez ha buscado sin darse cuenta un título de contenido que no estaba disponible en una plataforma de transmisión de video? En caso afirmativo, descubrirá que, en lugar de enfrentarse a una página de resultados de búsqueda en blanco, encontrará una lista de películas del mismo género, con miembros del reparto o del equipo. ¡Esa es una experiencia de búsqueda fuera de catálogo!
Búsqueda fuera de catálogo (OOC) es cuando ingresa una consulta de búsqueda que no tiene una coincidencia directa en un catálogo. Este evento ocurre con frecuencia en plataformas de transmisión de video que constantemente compran una variedad de contenido de múltiples proveedores y compañías de producción por un tiempo limitado. La ausencia de relevancia o mapeo del catálogo de una empresa de transmisión a grandes bases de conocimiento de películas y programas puede resultar en una experiencia de búsqueda inferior a la media para los clientes que consultan contenido OOC, lo que reduce el tiempo de interacción con la plataforma. Esta asignación se puede realizar mediante la asignación manual de consultas OOC frecuentes al contenido del catálogo o se puede automatizar mediante el aprendizaje automático (ML).
En esta publicación, ilustramos cómo manejar OOC utilizando el poder del conjunto de datos de IMDb (la principal fuente de metadatos de entretenimiento global) y los gráficos de conocimiento.
Servicio de búsqueda abierta es un servicio completamente administrado que le facilita realizar análisis de registros interactivos, monitoreo de aplicaciones en tiempo real, búsqueda de sitios web y más. OpenSearch es una suite de análisis y búsqueda distribuida de código abierto derivada de Elasticsearch. OpenSearch Service ofrece las últimas versiones de OpenSearch, soporte para 19 versiones de Elasticsearch (versiones 1.5 a 7.10), así como capacidades de visualización impulsadas por OpenSearch Dashboards y Kibana (versiones 1.5 a 7.10). OpenSearch Service actualmente tiene decenas de miles de clientes activos con cientos de miles de clústeres bajo administración que procesan billones de solicitudes por mes. OpenSearch Service ofrece la búsqueda kNN, que puede mejorar la búsqueda en casos de uso, como recomendaciones de productos, detección de fraudes e imágenes, videos y algunos escenarios semánticos específicos, como similitud de documentos y consultas. Para obtener más información sobre las funcionalidades de búsqueda impulsadas por la comprensión del lenguaje natural de OpenSearch Service, consulte Creación de una aplicación de búsqueda basada en NLU con Amazon SageMaker y la función KNN de Amazon OpenSearch Service.
Resumen de la solución
En esta publicación, presentamos una solución para manejar situaciones OOC a través de la búsqueda de incrustación basada en gráficos de conocimiento utilizando las capacidades de búsqueda de k-vecino más cercano (kNN) de OpenSearch Service. Los servicios clave de AWS utilizados para implementar esta solución son OpenSearch Service, SageMaker, Lambda y Amazon S3.
Check out Parte 1 y Parte 2 de esta serie para obtener más información sobre la creación de gráficos de conocimiento y la integración de GNN con Amazon Neptune ML.
Nuestra solución OOC asume que tiene un KG combinado obtenido al fusionar una empresa de transmisión KG e IMDb KG. Esto se puede hacer a través de técnicas simples de procesamiento de texto que hacen coincidir los títulos con el tipo de título (película, serie, documental), elenco y equipo. Además, este gráfico de conocimiento conjunto debe ser entrenado para generar incrustaciones de gráficos de conocimiento a través de las canalizaciones mencionadas en Parte 1 y Parte 2. El siguiente diagrama ilustra una vista simplificada del KG combinado.
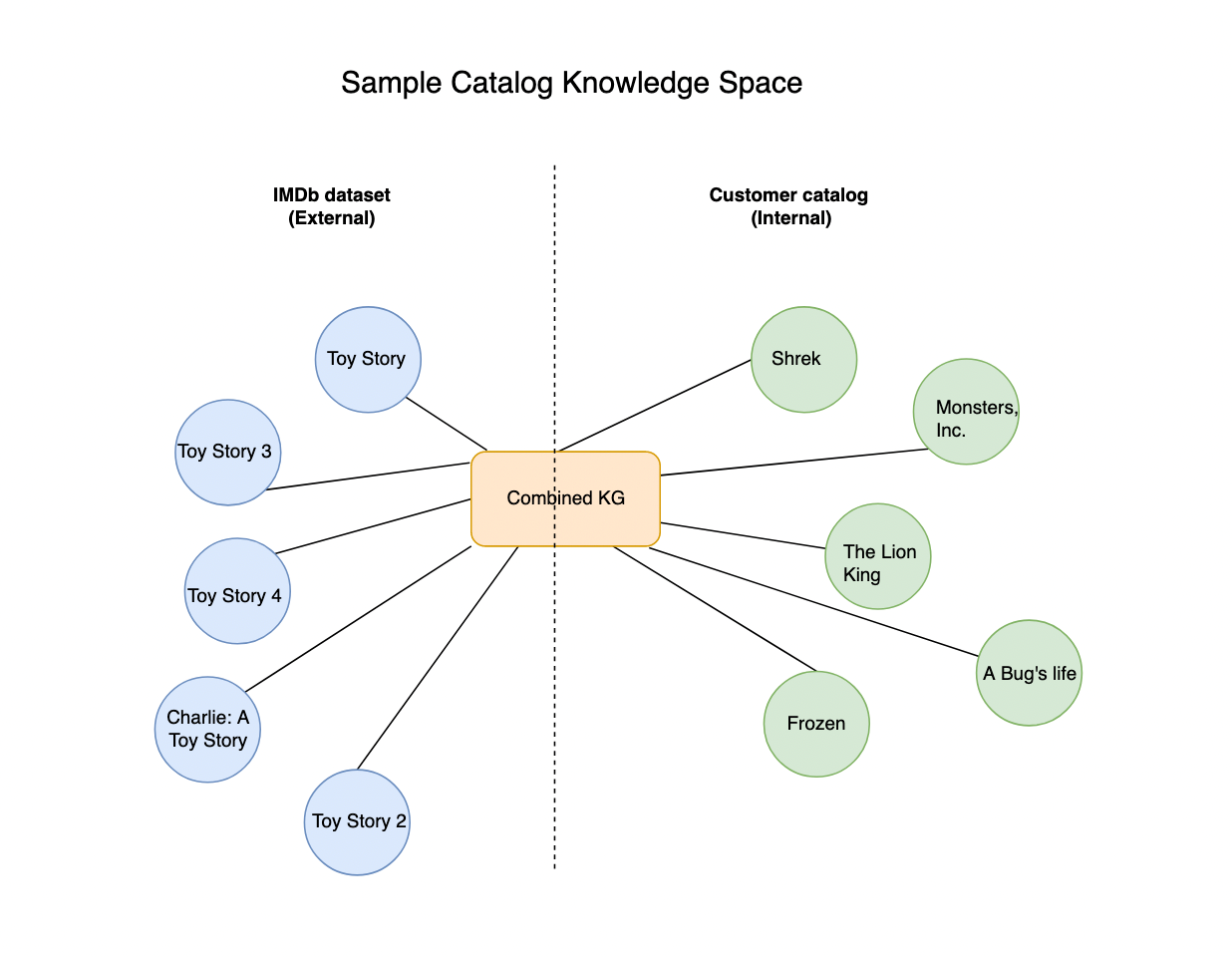
Para demostrar la funcionalidad de búsqueda OOC con un ejemplo simple, dividimos el gráfico de conocimiento de IMDb en catálogo de clientes y fuera del catálogo de clientes. Marcamos los títulos que contienen "Toy Story" como recurso fuera del catálogo de clientes y el resto del gráfico de conocimiento de IMDb como catálogo de clientes. En un escenario en el que el catálogo de clientes no se mejora ni se fusiona con bases de datos externas, una búsqueda de "historia del juguete" devolvería cualquier título que tenga las palabras "juguete" o "historia" en sus metadatos, con la búsqueda de texto de OpenSearch. Si el catálogo de clientes se asignó a IMDb, sería más fácil deducir que la consulta "toy story" no existe en el catálogo y que las principales coincidencias en IMDb son "Toy Story", "Toy Story 2", "Toy Story 3”, “Toy Story 4” y “Charlie: Toy Story” en orden decreciente de relevancia con coincidencia de texto. Para obtener resultados dentro del catálogo para cada una de estas coincidencias, podemos generar cinco películas más cercanas en la similitud de incrustación de kNN basada en el catálogo del cliente (del KG conjunto) a través de OpenSearch Service.
Una experiencia OOC típica sigue el flujo ilustrado en la siguiente figura.
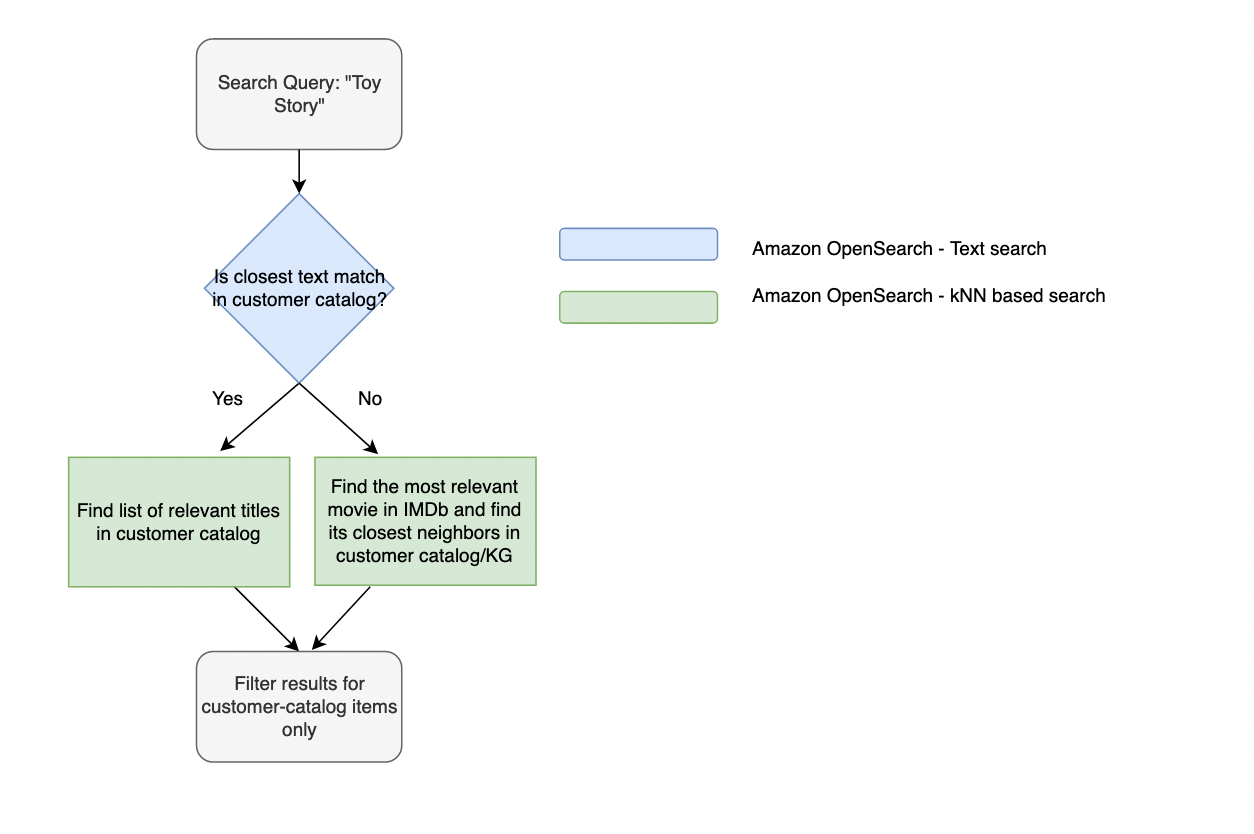
El siguiente video muestra los cinco primeros resultados OOC (número de aciertos) para la consulta "toy story" y las coincidencias relevantes en el catálogo de clientes (número de recomendaciones).
Aquí, la consulta se compara con el gráfico de conocimiento mediante la búsqueda de texto en OpenSearch Service. Luego mapeamos las incrustaciones de la coincidencia de texto con los títulos del catálogo del cliente utilizando el índice kNN de OpenSearch Service. Debido a que la consulta del usuario no se puede asignar directamente a las entidades del gráfico de conocimiento, utilizamos un enfoque de dos pasos para encontrar primero las similitudes de consulta basadas en el título y luego los elementos similares al título mediante incrustaciones del gráfico de conocimiento. En las siguientes secciones, recorremos el proceso de configuración de un clúster de OpenSearch Service, la creación y carga de índices de gráficos de conocimiento y la implementación de la solución como una aplicación web.
Requisitos previos
Para implementar esta solución, debe tener un Cuenta de AWS, familiaridad con OpenSearch Service, SageMaker, Lambda y Formación en la nube de AWS, y ha completado los pasos en Parte 1 y Parte 2 de esta serie
Recursos de la solución de lanzamiento
El siguiente diagrama de arquitectura muestra el flujo de trabajo fuera del catálogo.
Utilizará el kit de desarrollo de la nube de AWS (CDK) para aprovisionar los recursos necesarios para las aplicaciones de búsqueda OOC. El código para lanzar estos recursos realiza las siguientes operaciones:
- Crea una VPC para los recursos.
- Crea un dominio de OpenSearch Service para la aplicación de búsqueda.
- Crea una función Lambda para procesar y cargar metadatos de películas e incrustaciones en los índices de OpenSearch Service (
**-ReadFromOpenSearchLambda-**). - Crea una función Lambda que toma como entrada la consulta del usuario de una aplicación web y devuelve títulos relevantes de OpenSearch (
**-LoadDataIntoOpenSearchLambda-**). - Crea una API Gateway que agrega una capa adicional de seguridad entre la interfaz de usuario de la aplicación web y Lambda.
Para comenzar, complete los siguientes pasos:
- Ejecute el código y los cuadernos desde Parte 1 y Parte 2.
- Navegue hasta la
part3-out-of-catalogcarpeta en el repositorio de código.

- Inicie AWS CDK desde la terminal con el comando
bash launch_stack.sh. - Proporcione las dos rutas de archivo S3 creadas en la Parte 2 como entrada:
- La ruta de S3 al archivo CSV de incrustaciones de películas.
- La ruta de S3 al archivo de nodo de película.

- Espere hasta que el script proporcione todos los recursos necesarios y termine de ejecutarse.
- Copie la URL de API Gateway que imprime el script de AWS CDK y guárdela. (Usamos esto para la aplicación Streamlit más adelante).
Crear un dominio de servicio de OpenSearch
Con fines ilustrativos, crea un dominio de búsqueda en una zona de disponibilidad en una instancia r6g.large.search dentro de una VPC y una subred seguras. Tenga en cuenta que la mejor práctica sería configurar tres zonas de disponibilidad con una instancia principal y dos réplicas.
Cree un índice de OpenSearch Service y cargue datos
Utiliza funciones de Lambda (creadas con el comando de pila de lanzamiento de AWS CDK) para crear los índices de OpenSearch Service. Para iniciar la creación del índice, complete los siguientes pasos:
- En la consola de Lambda, abra el
LoadDataIntoOpenSearchLambdaFunción lambda.
- En Probar pestaña, elegir Probar para crear e incorporar datos en el índice del servicio OpenSearch.

El siguiente código para esta función de Lambda se puede encontrar en part3-out-of-catalog/cdk/ooc/lambdas/LoadDataIntoOpenSearchLambda/lambda_handler.py:
La función realiza las siguientes tareas:
- Carga el archivo de nodo de película IMDB KG que contiene los metadatos de la película y sus incrustaciones asociadas desde las rutas del archivo S3 que se pasaron al archivo de creación de pila
launch_stack.sh. - Combina los dos archivos de entrada para crear un marco de datos único para la creación de índices.
- Inicializa el cliente del servicio OpenSearch mediante la biblioteca Python de Boto3.
- Crea dos índices para el texto (
ooc_text) y búsqueda incrustada de kNN (ooc_knn) y cargas masivas de datos del marco de datos combinado a través delingest_data_into_opsfunción.
Este proceso de ingestión de datos tarda de 5 a 10 minutos y se puede monitorear a través del Reloj en la nube de Amazon inicia sesión en el Monitoreo pestaña de la función Lambda.
Cree dos índices para habilitar la búsqueda basada en texto y la búsqueda basada en la incorporación de kNN. La búsqueda de texto asigna la consulta de forma libre que el usuario ingresa a los títulos de la película. La búsqueda de incrustación de kNN encuentra las k películas más cercanas a la mejor coincidencia de texto del espacio latente de KG para devolverlas como salidas.
Implementar la solución como una aplicación web local
Ahora que tiene una búsqueda de texto en funcionamiento y un índice kNN en OpenSearch Service, está listo para crear una aplicación web basada en ML.
Usamos la streamlit Paquete Python para crear una ilustración frontal para esta aplicación. Él IMDb-Knowledge-Graph-Blog/part3-out-of-catalog/run_imdb_demo.py archivo de Python en nuestro Repositorio GitHub tiene el código requerido para iniciar una aplicación web local para explorar esta capacidad.
Para ejecutar el código, complete los siguientes pasos:
- Instale la
streamlityaws_requests_authPaquete de Python en su entorno de Python virtual local a través de los siguientes comandos en su terminal:
- Reemplace el marcador de posición de la URL de API Gateway en el código de la siguiente manera con el creado por AWS CDK:
api = '<ENTER URL OF THE API GATEWAY HERE>/opensearch-lambda?q={query_text}&numMovies={num_movies}&numRecs={num_recs}'
- Inicie la aplicación web con el comando
streamlit run run_imdb_demo.pydesde su terminal.
Este script inicia una aplicación web Streamlit a la que se puede acceder en su navegador web. La URL de la aplicación web se puede recuperar de la salida del script, como se muestra en la siguiente captura de pantalla.

La aplicación acepta nuevas cadenas de búsqueda, número de resultados y número de recomendaciones. El número de visitas corresponde a la cantidad de títulos OOC coincidentes que debemos recuperar del catálogo externo (IMDb). El número de recomendaciones corresponde a cuántos vecinos más cercanos debemos recuperar del catálogo de clientes según la búsqueda de incrustación de kNN. Ver el siguiente código:
Esta entrada (consulta, número de visitas y recomendaciones) se pasa al **-ReadFromOpenSearchLambda-** Función Lambda creada por AWS CDK a través de la solicitud de API Gateway. Esto se hace en la siguiente función:
Los resultados de salida de la función Lambda de OpenSearch Service se pasan a API Gateway y se muestran en la aplicación Streamlit.
Limpiar
Puede eliminar todos los recursos creados por AWS CDK a través del comando npx cdk destroy –app “python3 appy.py” --all en la misma instancia (dentro del cdk carpeta) que se usó para iniciar la pila (consulte la siguiente captura de pantalla).
Conclusión
En esta publicación, le mostramos cómo crear una solución para la búsqueda OOC usando texto y búsqueda basada en kNN usando SageMaker y OpenSearch Service. Usó incrustaciones de modelos de gráficos de conocimiento personalizados para encontrar vecinos más cercanos en su catálogo a los títulos de IMDb. Ahora puedes, por ejemplo, buscar “The Rings of Power”, una serie de fantasía desarrollada por Amazon Prime Video, en otras plataformas de transmisión y razonar cómo podrían haber optimizado el resultado de la búsqueda.
Para obtener más información sobre el ejemplo de código en esta publicación, consulte la Repositorio GitHub. Para obtener más información sobre cómo colaborar con Amazon ML Solutions Lab para crear aplicaciones de ML de última generación similares, consulte Laboratorio de soluciones de aprendizaje automático de Amazon. Para obtener más información sobre la licencia de conjuntos de datos de IMDb, visite desarrollador.imdb.com.
Acerca de los autores
 divya bhargavi es científica de datos y líder vertical de medios y entretenimiento en Amazon ML Solutions Lab, donde resuelve problemas comerciales de alto valor para los clientes de AWS mediante el aprendizaje automático. Trabaja en comprensión de imágenes/videos, sistemas de recomendación de gráficos de conocimiento, casos de uso de publicidad predictiva.
divya bhargavi es científica de datos y líder vertical de medios y entretenimiento en Amazon ML Solutions Lab, donde resuelve problemas comerciales de alto valor para los clientes de AWS mediante el aprendizaje automático. Trabaja en comprensión de imágenes/videos, sistemas de recomendación de gráficos de conocimiento, casos de uso de publicidad predictiva.
 Gaurav Relé es un científico de datos en el laboratorio de soluciones de Amazon ML, donde trabaja con clientes de AWS en diferentes verticales para acelerar el uso del aprendizaje automático y los servicios en la nube de AWS para resolver sus desafíos comerciales.
Gaurav Relé es un científico de datos en el laboratorio de soluciones de Amazon ML, donde trabaja con clientes de AWS en diferentes verticales para acelerar el uso del aprendizaje automático y los servicios en la nube de AWS para resolver sus desafíos comerciales.
 mateo rodas es un científico de datos que trabaja en Amazon ML Solutions Lab. Se especializa en la construcción de canalizaciones de aprendizaje automático que involucran conceptos como el procesamiento del lenguaje natural y la visión por computadora.
mateo rodas es un científico de datos que trabaja en Amazon ML Solutions Lab. Se especializa en la construcción de canalizaciones de aprendizaje automático que involucran conceptos como el procesamiento del lenguaje natural y la visión por computadora.
 Karan Sindwani es científico de datos en Amazon ML Solutions Lab, donde crea e implementa modelos de aprendizaje profundo. Se especializa en el área de visión artificial. En su tiempo libre, disfruta del senderismo.
Karan Sindwani es científico de datos en Amazon ML Solutions Lab, donde crea e implementa modelos de aprendizaje profundo. Se especializa en el área de visión artificial. En su tiempo libre, disfruta del senderismo.
 Soji Adeshina es científico aplicado en AWS, donde desarrolla modelos basados en redes neuronales gráficas para aprendizaje automático en tareas de gráficos con aplicaciones para fraude y abuso, gráficos de conocimiento, sistemas de recomendación y ciencias de la vida. En su tiempo libre le gusta leer y cocinar.
Soji Adeshina es científico aplicado en AWS, donde desarrolla modelos basados en redes neuronales gráficas para aprendizaje automático en tareas de gráficos con aplicaciones para fraude y abuso, gráficos de conocimiento, sistemas de recomendación y ciencias de la vida. En su tiempo libre le gusta leer y cocinar.
 Vidya Sagar Ravipati es Gerente en Amazon ML Solutions Lab, donde aprovecha su vasta experiencia en sistemas distribuidos a gran escala y su pasión por el aprendizaje automático para ayudar a los clientes de AWS en diferentes verticales de la industria a acelerar su adopción de la nube y la inteligencia artificial.
Vidya Sagar Ravipati es Gerente en Amazon ML Solutions Lab, donde aprovecha su vasta experiencia en sistemas distribuidos a gran escala y su pasión por el aprendizaje automático para ayudar a los clientes de AWS en diferentes verticales de la industria a acelerar su adopción de la nube y la inteligencia artificial.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/power-recommendations-and-search-using-an-imdb-knowledge-graph-part-3/

