Desde su lanzamiento en enero de 2021, el proyecto de búsqueda abierta ha publicado Versiones 14 Hasta junio 2023. Servicio Amazon OpenSearch admite las últimas versiones de OpenSearch hasta la versión 2.7.
OpenSearch Service proporciona dos opciones de configuración para implementar y operar OpenSearch a escala en la nube. Con los dominios administrados por OpenSearch Service, usted especifica una configuración de hardware y OpenSearch Service aprovisiona el hardware requerido y se encarga de la aplicación de parches de software, la recuperación de fallas, las copias de seguridad y el monitoreo. Con los dominios administrados, puede utilizar capacidades avanzadas sin costo adicional, como búsqueda entre clústeres, replicación entre clústeres, detección de anomalías, búsqueda semántica, análisis de seguridad y más. No necesita un equipo grande para mantener y operar su dominio de OpenSearch Service a escala. Su equipo debe estar familiarizado con los conceptos de fragmentación y Mejores prácticas de OpenSearch para utilizar la oferta gestionada de OpenSearch.
Amazon OpenSearch sin servidor proporciona una opción de implementación sencilla y totalmente automática. Cuando utiliza OpenSearch Serverless, crea un -- (un conjunto de índices que funcionan juntos en una carga de trabajo) y utilizan las API de OpenSearch, y OpenSearch Serverless hace el resto. No necesita preocuparse por el tamaño, la planificación de la capacidad o el ajuste de su clúster OpenSearch.
En esta publicación, proporcionamos una revisión de todas las funciones interesantes que se lanzarán en OpenSearch Service en la primera mitad de 2023.
Cree potentes soluciones de búsqueda
En esta sección, analizamos algunas de las funciones del servicio OpenSearch que le permiten crear potentes soluciones de búsqueda.
OpenSearch Serverless y el motor vectorial sin servidor
A principios de este año, anunciamos la disponibilidad general de OpenSearch Serverless. OpenSearch Serverless separa los componentes de almacenamiento y computación, y la indexación y la computación de consultas, para que puedan administrarse y escalarse de forma independiente. Usa Servicio de almacenamiento simple de Amazon (Amazon S3) como almacenamiento de datos principal para índices, lo que agrega durabilidad a sus datos. Las colecciones pueden aprovechar la capa de almacenamiento S3 para reducir la necesidad de almacenamiento activo y reducir los costos al llevar los datos al almacenamiento local cuando se accede a ellos.
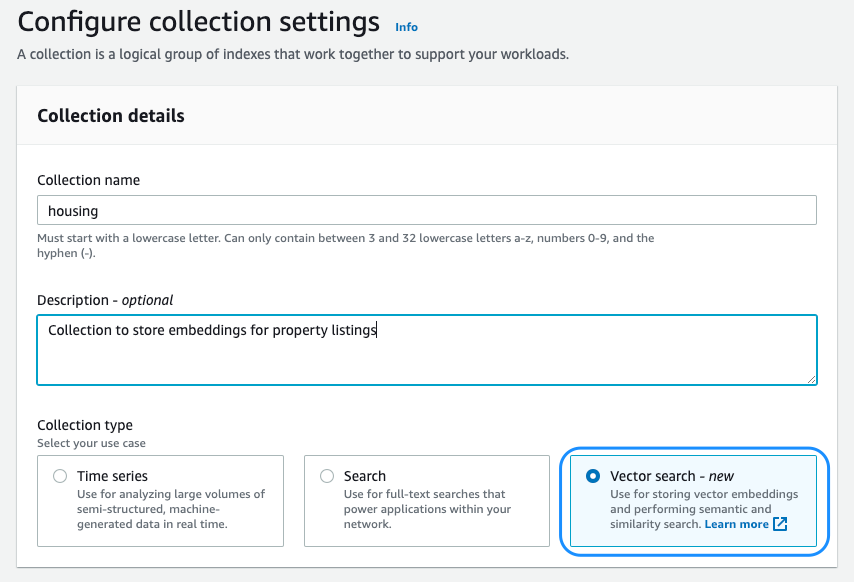
Cuando crea una colección sin servidor, establece un tipo de colección. OpenSearch Serverless optimiza el uso de recursos según el tipo que establezca. En el lanzamiento, podría crear colecciones de búsqueda y series temporales para casos de uso de búsqueda de texto completo y análisis de registros, respectivamente. En julio de 2023, presentamos una vista previa de la compatibilidad con un tercer tipo de colección: la búsqueda vectorial. El motor vectorial para OpenSearch Serverless es un motor de consultas y almacén de vectores simple, escalable y de alto rendimiento que permite IA generativa, búsqueda semántica, búsqueda de imágenes y más. Construido sobre OpenSearch Serverless, el motor vectorial hereda y se beneficia de su sólida arquitectura. Con el motor vectorial, no tiene que preocuparse por dimensionar, ajustar y escalar la infraestructura de backend. El motor vectorial ajusta automáticamente los recursos adaptándose a los patrones cambiantes de carga de trabajo y la demanda para proporcionar un rendimiento y una escala consistentemente rápidos. El motor vectorial utiliza algoritmos de vecino más cercano aproximado (ANN) del Biblioteca espacial no métrica (NMSLIB) y FAISS bibliotecas para impulsar la búsqueda k-NN.
Puede comenzar a utilizar las nuevas capacidades del motor vectorial seleccionando Búsqueda de vectores al crear su colección en la consola del servicio OpenSearch. Referirse a Presentamos el motor vectorial para Amazon OpenSearch Serverless, ahora en versión preliminar para obtener más información sobre la nueva opción de búsqueda vectorial con OpenSearch Serverless.
Punto en el tiempo
Búsqueda de punto en el tiempo (PIT), lanzado en la versión 2.4 de OpenSearch Project y compatible con OpenSearch 2.5 en OpenSearch Service, proporciona coherencia en la paginación de búsqueda incluso cuando se incorporan o eliminan nuevos documentos dentro de un índice específico. Por ejemplo, supongamos que el usuario de su sitio web buscó "sofá azul" y pasó unos minutos mirando los resultados. Durante esos pocos minutos, la aplicación agregó algunos sofás adicionales al índice, cambiando el orden de los primeros 20 documentos. Si luego el usuario navega de la página 1 a la página 2, es posible que vea resultados que ya estaban en la página 1 pero que han bajado en el orden de los resultados. La paginación no es estable al agregar nuevos datos al índice. Si utiliza la búsqueda PIT, se garantiza que el orden de los resultados seguirá siendo el mismo en todas las páginas, independientemente de los cambios en el índice. Para obtener más información sobre las capacidades PIT, consulte Lo más destacado del lanzamiento: Paginar con un punto en el tiempo.
Complemento de relevancia de búsqueda
¿Alguna vez se preguntó qué pasaría si ajustara su función de relevancia? ¿Los resultados serían mejores o peores? Con el complemento de relevancia de búsqueda, ahora puede ver una comparación de resultados en paralelo en los paneles de OpenSearch. Una vista de interfaz de usuario simplifica ver cómo han cambiado los resultados y ajustar su relevancia a la perfección.
Tipos de campos adicionales
OpenSearch 2.7 (disponible en el servicio OpenSearch) admite las siguientes novedades tipos de mapeo de objetos:
- tipo de campo cartesiano – OpenSearch 2.7 en OpenSearch Service agrega un soporte más profundo para datos GEO. Si está creando una aplicación de realidad virtual, un diseño asistido por computadora (CAD) o un mapeo de instalaciones deportivas, puede beneficiarse del soporte de los tipos de campos cartesianos. campo de punto xy y campo de forma xy.
- Tipo de objeto plano – Cuando configuras el mapeo de tu campo en objeto_plano, OpenSearch indexa cualquier objeto JSON en el campo para permitirle buscar valores de hoja, incluso si no conoce el nombre del campo, y le permite buscar mediante notación de ruta de puntos. Referirse a Usar objeto plano en OpenSearch para obtener más información sobre cómo el tipo de asignación de objetos planos simplifica las asignaciones de índice y la experiencia de búsqueda en OpenSearch.
Análisis geográfico
A partir de OpenSearch 2.7 en OpenSearch Service, puede ejecutar consultas de agregación de cuadrícula GeoHex en conjuntos de datos creados con el Sistema de indexación geoespacial jerárquico hexagonal (H3) biblioteca de código abierto. H3 proporciona una precisión de hasta un metro cuadrado o menos, lo que lo hace útil para casos que requieren un alto grado de precisión. Debido a que las solicitudes de alta precisión requieren mucho procesamiento, debe asegurarse de limitar el área geográfica usando filtros.
Lleve la observabilidad al siguiente nivel
La observabilidad en OpenSearch es una colección de complementos y funciones que le permiten explorar, consultar y visualizar datos de telemetría almacenados en OpenSearch. En esta sección, analizamos cómo OpenSearch Service le permite llevar la observabilidad al siguiente nivel.
Esquema simple para la observabilidad.
Con la versión 2.6, el Proyecto OpenSearch lanzó un nuevo esquema unificado para Observabilidad llamado Esquema simple de observabilidad (SS4O) (compatible con OpenSearch 2.7 en el servicio OpenSearch). SS4O está inspirado en ambos OpenTelemetría y Elastic Common Schema (ECS) y utiliza Amazon Elastic Container Service (Amazon ECS) registros de eventos y metadatos de OpenTelemetry (OTel). SS4O especifica la estructura del índice (mapeo), las convenciones de nomenclatura del índice, una función de integración para agregar paneles y visualizaciones preconfigurados y un esquema JSON para aplicar y validar la estructura. SS4O cumple con las HOTEL esquema para registros, seguimientos y métricas.
Soporte de trazas de Jaeger
Con el lanzamiento de OpenSearch 2.5, ahora puede integrar Datos de seguimiento de Jaeger en OpenSearch y utilice el complemento Observability para analizar sus datos de seguimiento en formato Jaeger.
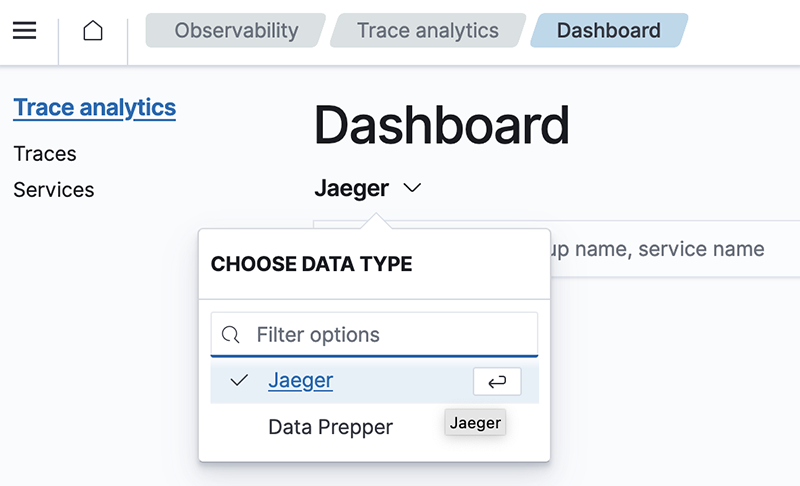
La observabilidad le brinda visibilidad sobre el estado de su sistema y aplicaciones de microservicio. OpenSearch Dashboards viene con un Complemento de observabilidad, que proporciona una experiencia unificada para recopilar y monitorear métricas, registros y seguimientos de fuentes de datos comunes. Con el complemento Observability, puede monitorear y alertar sobre sus registros, métricas y seguimientos para garantizar que su aplicación esté disponible, funcione y esté libre de errores.
En la primera mitad de 2023, agregamos la capacidad de crear paneles de observabilidad y paneles estándar desde el menú principal de OpenSearch Dashboards. Antes de eso, necesitabas navegar hasta el complemento Observability para crear visualizaciones de análisis de eventos usando Lenguaje de procesamiento canalizado (PLP). Con esta versión, hicimos esta función más accesible al integrar un nuevo tipo de visualización llamado "PPL" dentro de la lista de tipos de visualización en el menú principal de Paneles. Esto le ayuda a correlacionar tanto los conocimientos empresariales como los análisis de observabilidad en un solo lugar.
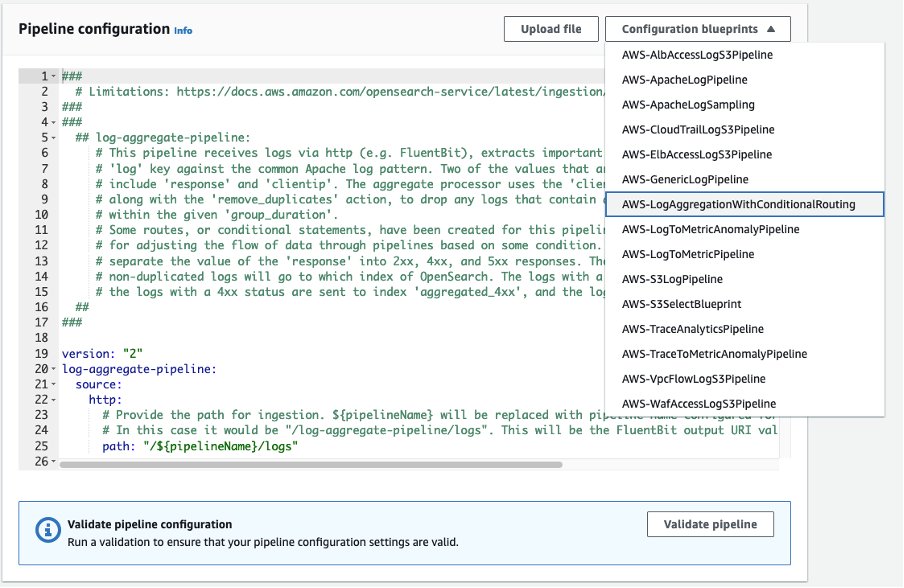
Cree canales de ingesta sin servidor
En abril de 2023, se lanzó el servicio OpenSearch Ingestión de Amazon OpenSearch, un canal de ingesta totalmente administrado y escalado automáticamente para dominios de OpenSearch Service y colecciones de OpenSearch Serverless. La ingesta de OpenSearch funciona con Preparador de datos, con complementos de origen y receptor para procesar, muestrear, filtrar, enriquecer y entregar datos para análisis posteriores. Referirse a Complementos y opciones compatibles para canalizaciones de ingesta de Amazon OpenSearch para obtener más información.
El servicio se adapta automáticamente a las demandas de su carga de trabajo ampliando y reduciendo las unidades informáticas (OCU) de OpenSearch. Cada OCU proporciona un rendimiento estimado de 8 GB por hora (su carga de trabajo determinará el rendimiento real) y es una combinación de 8 GiB de memoria y 2 vCPU. Puede ampliar hasta 96 OCU.
La ingesta de OpenSearch proporciona planos de canalización listos para usar que proporcionan plantillas de configuración para las canalizaciones de ingesta más comunes. Para obtener más información, consulte Cree una canalización de análisis de registros sin servidor mediante Amazon OpenSearch Ingestion con Amazon OpenSearch Service administrado.
Habilite su negocio con funciones de seguridad
En esta sección, analizamos cómo puede utilizar el servicio OpenSearch para habilitar su empresa con funciones de seguridad.
Habilite SAML durante la creación del dominio
Autenticación SAML para OpenSearch Dashboards se introdujo en los dominios del servicio OpenSearch con Elasticsearch versión 6.7 o superior y OpenSearch versión 1.0 o superior, pero había que esperar a que se creara el dominio para habilitar SAML. En febrero de 2023, le permitimos especificar la compatibilidad con SAML durante la creación del dominio. El soporte está disponible cuando crea dominios en el Consola de administración de AWS, SDK de AWSo Formación en la nube de AWS plantillas. La autenticación SAML para OpenSearch Dashboards le permite integrarse directamente con proveedores de identidad (IdP) como Okta, Ping Identity, OneLogin, Auth0, Active Directory Federation Services (ADFS) y Azure Active Directory.
Análisis de seguridad con OpenSearch
OpenSearch 2.5 en OpenSearch Service lanzó soporte para OpenSearch complemento de análisis de seguridad. En el pasado, identificar alertas de seguridad procesables y obtener información valiosa requería experiencia y familiaridad significativas con varios productos de seguridad. Sin embargo, con el análisis de seguridad, ahora puede beneficiarse de flujos de trabajo simplificados que facilitan la correlación de múltiples registros de seguridad y la investigación de incidentes de seguridad, todo dentro del entorno OpenSearch, incluso sin experiencia previa en seguridad. El complemento de análisis de seguridad incluye una extensa colección de más de 2,200 Sigma de código abierto reglas de seguridad. Estas reglas desempeñan un papel crucial en la detección de posibles amenazas a la seguridad en tiempo real a partir de sus registros de eventos. Con el complemento de análisis de seguridad, también puede diseñar reglas personalizadas, personalizar alertas de seguridad según la gravedad de la amenaza y recibir notificaciones automáticas en su destino preferido, como correo electrónico o un canal de Slack. Para obtener más información sobre la creación de detectores y la configuración de reglas, consulte Identifique y solucione las amenazas de seguridad para su empresa mediante análisis de seguridad con Amazon OpenSearch Service.
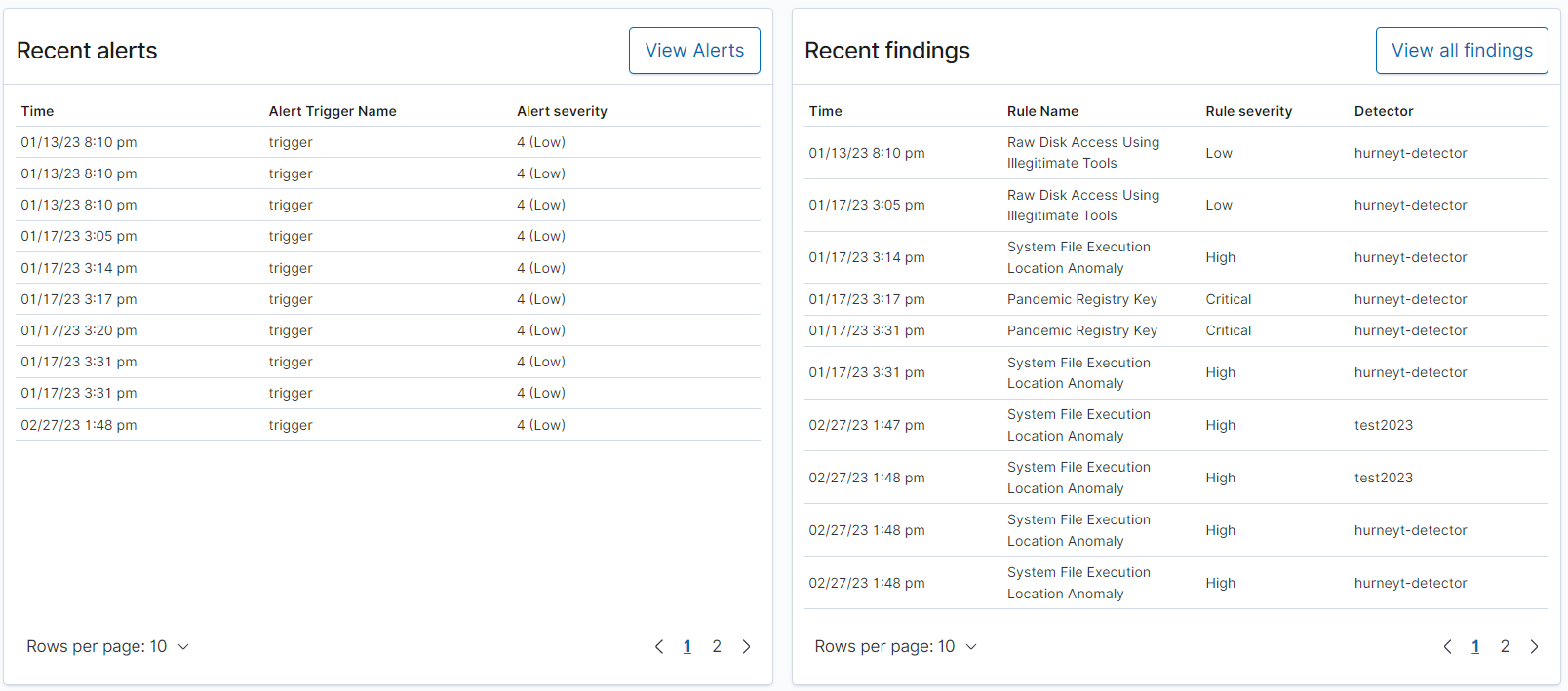
Ingerir eventos de Amazon Security Lake
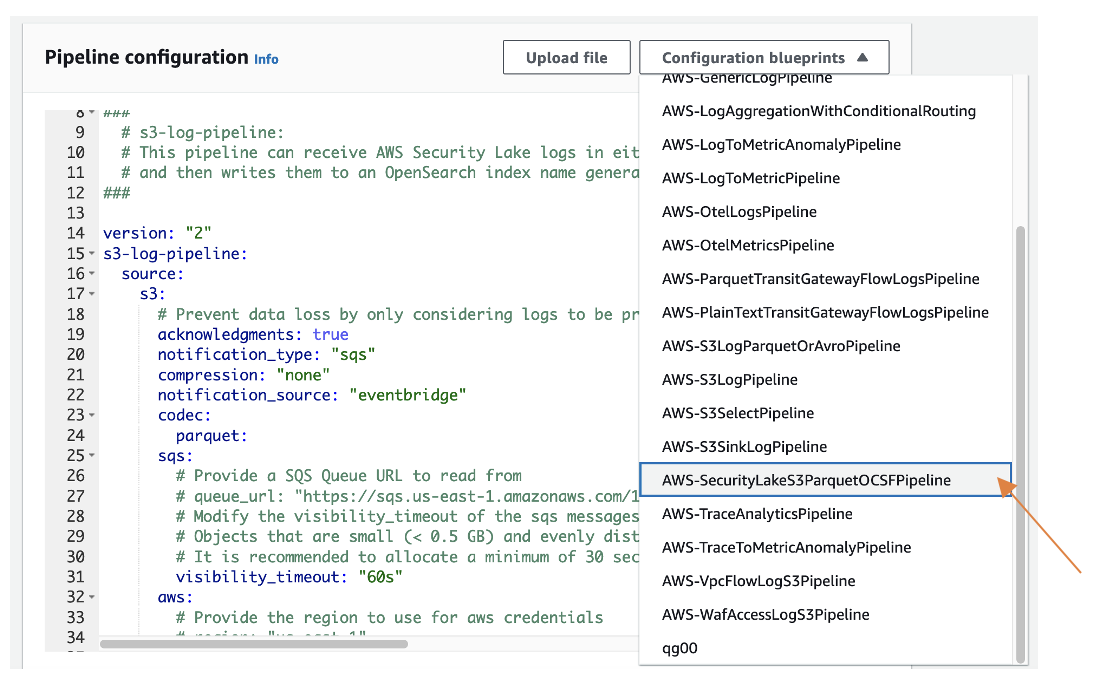
En junio de 2023, OpenSearch Ingestion agregó soporte para la ingesta en tiempo real de eventos de Lago de seguridad de Amazon, lo que reduce el tiempo de indexación de los datos de seguridad en OpenSearch Service. Con Amazon Security Lake centralizando los datos de seguridad de varias fuentes, puede aprovechar las amplias capacidades de análisis de seguridad y las ricas visualizaciones del panel de OpenSearch Service para obtener información valiosa rápidamente. Utilizando el Marco de esquema de ciberseguridad abierto (OCSF), Amazon Security Lake normaliza y combina datos de diversas fuentes de seguridad empresarial en formato Apache Parquet. OpenSearch Ingestion ahora permite la ingesta en formato Parquet, con procesadores integrados para convertir datos en documentos JSON antes de indexarlos. Además, hay un plan especializado para la ingesta de datos de Amazon Security Lake y soporte para Data Prepper 2.3.0, que ofrece nuevas funciones como receptor S3, códec Avro, procesador de ofuscación, etiquetado de eventos, expresiones avanzadas y muestreo de cola.
Simplifique las operaciones del clúster
En esta sección, analizamos cómo puede utilizar el servicio OpenSearch para simplificar las operaciones del clúster.
Ejecución en seco mejorada para cambios de configuración
OpenSearch Service ha introducido una opción mejorada de ejecución en seco que le permite validar los cambios de configuración antes de aplicarlos a sus clústeres. Esta característica garantiza que cualquier posible error de validación que pueda ocurrir durante la implementación de cambios de configuración se verifique y se resuma para su revisión. Además, el ensayo indicará si un implementación azul/verde es necesario aplicar un cambio, lo que le permitirá planificar en consecuencia.
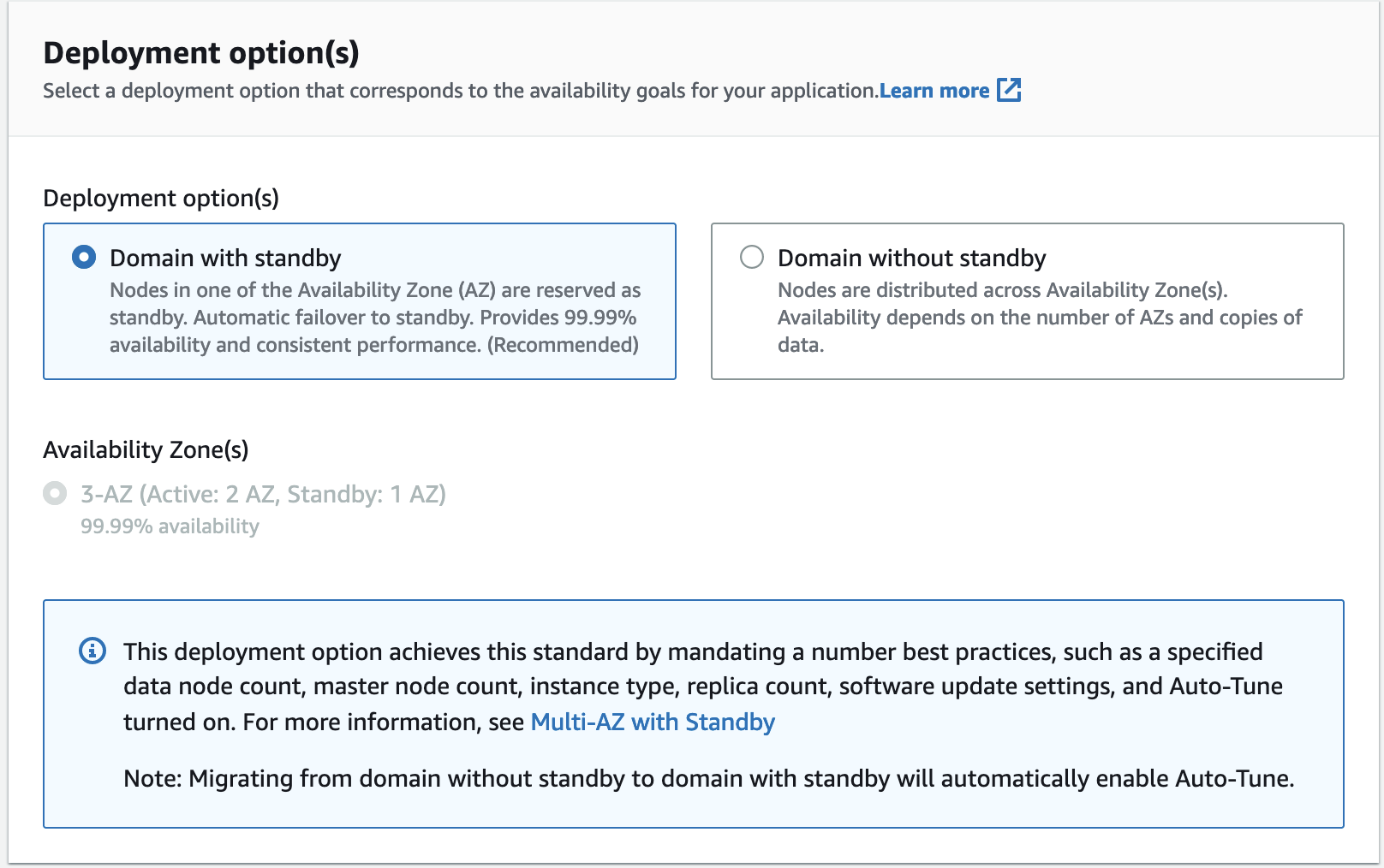
Garantice una alta disponibilidad y un rendimiento constante
El servicio OpenSearch ahora ofrece una disponibilidad del 99.99 % con Multi-AZ con modo de espera despliegue. Esta nueva capacidad hace que sus cargas de trabajo críticas para el negocio sean más resistentes a posibles fallas de infraestructura, como fallas en la zona de disponibilidad. Antes de este nuevo lanzamiento, OpenSearch Service se recuperaba automáticamente de las interrupciones de la zona de disponibilidad asignando más capacidad en la zona de disponibilidad afectada y redistribuyendo fragmentos automáticamente. Sin embargo, este enfoque es reactivo a las fallas de infraestructura y red y generalmente conduce a una alta latencia y una mayor utilización de recursos en todos los nodos. La función Multi-AZ con Standby implementa la infraestructura en tres zonas de disponibilidad, mientras mantiene dos zonas activas y una zona en espera. Requiere un mínimo de dos réplicas para mantener la redundancia de datos en las zonas de disponibilidad para un tiempo de recuperación de menos de un minuto.
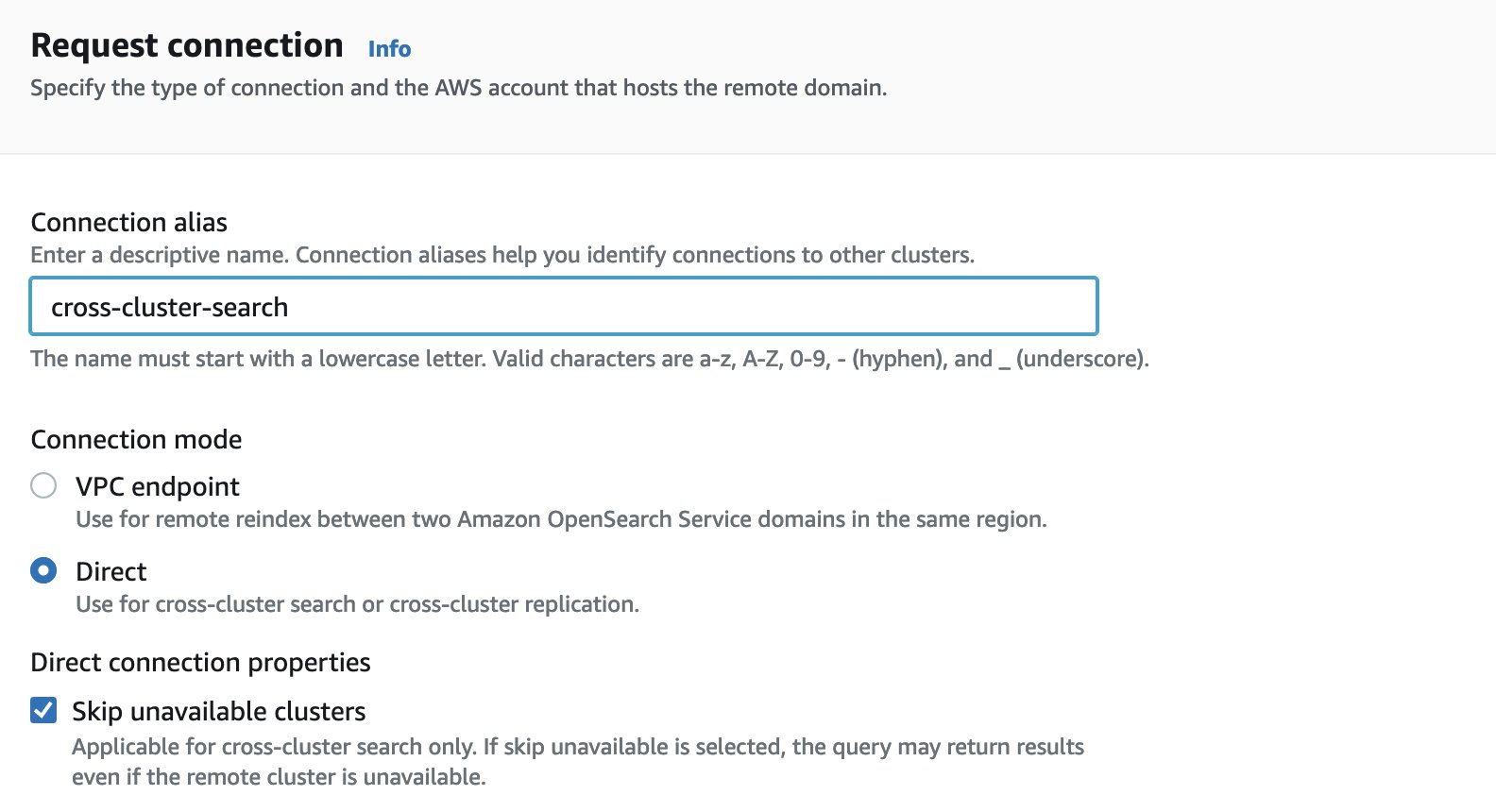
Omitir clústeres no disponibles en la búsqueda entre clústeres
Con el lanzamiento de la Saltar clústeres no disponibles opción para búsqueda entre clústeres En junio de 2023, sus consultas de búsqueda entre clústeres arrojarán resultados incluso si tiene fragmentos o índices no disponibles en uno de los clústeres remotos. La característica está habilitada de forma predeterminada cuando solicita la conexión a un clúster remoto en la consola del servicio OpenSearch.
Mejore su experiencia con los paneles de OpenSearch
El lanzamiento de OpenSearch 2.5 y OpenSearch 2.7 en OpenSearch Service ha traído nuevas funciones para administrar flujos de datos e índices en la interfaz de usuario de OpenSearch Dashboards.
Gestión de instantáneas
De forma predeterminada, OpenSearch Service toma instantáneas de sus datos cada hora con un tiempo de retención de 14 días. Las instantáneas automáticas son de naturaleza incremental y lo ayudan a recuperarse de una pérdida de datos o una falla del clúster. Además de las instantáneas horarias predeterminadas, OpenSearch Service brinda la capacidad de ejecutar instantáneas manuales y almacenarlas en un depósito de S3. Puede utilizar la administración de instantáneas para crear instantáneas manuales, definir una política de retención de instantáneas y configurar la frecuencia y el momento de la creación de instantáneas. La gestión de instantáneas está disponible en complemento de gestión de índices en los paneles de OpenSearch.
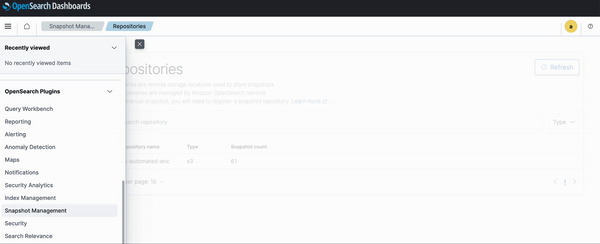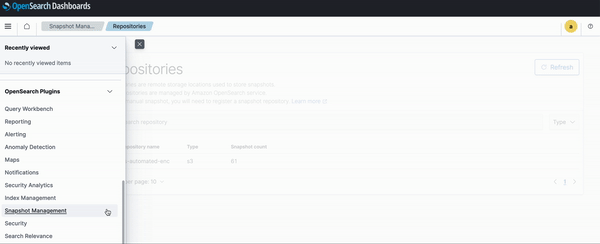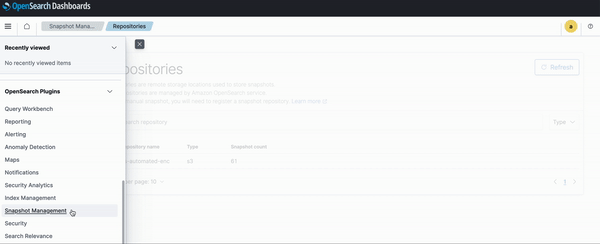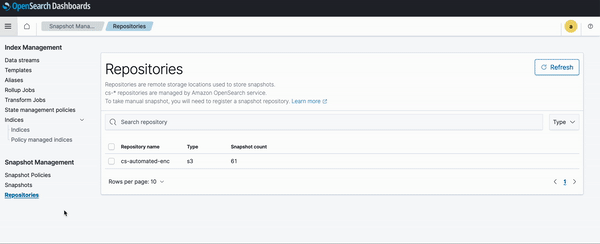
Gestión de índices y flujos de datos.
Con el soporte de OpenSearch 2.5 y OpenSearch 2.7 en OpenSearch Service, ahora puede utilizar el complemento de gestión de índices en los paneles de OpenSearch para administrar flujos de datos, plantillas de índice y alias de índice.
La interfaz de usuario de administración de índices proporciona capacidades ampliadas para incluir la ejecución de transferencia manual y forzar acciones de combinación para flujos de datos. También puede administrar visualmente varias plantillas de índice y definir asignaciones de índice, cantidad de fragmentos primarios, cantidad de réplicas y actualización interna de sus índices.
Conclusión
¡Ha sido una primera mitad del año muy ocupada! OpenSearch Project y OpenSearch Service han lanzado OpenSearch Serverless para utilizar OpenSearch sin preocuparse por la infraestructura, el índice o los fragmentos; OpenSearch Ingestion para ingerir sus datos; el motor vectorial para OpenSearch Serverless; análisis de seguridad para analizar datos de Amazon Security Lake; mejoras operativas para lograr una disponibilidad del 99.99 %; y mejoras al complemento Observability. OpenSearch Service proporciona un conjunto completo de capacidades, que incluyen una base de datos vectorial, búsqueda semántica y un motor de análisis de registros. Lo invitamos a consultar las funciones descritas en esta publicación y agradecemos que nos brinde sus valiosos comentarios.
Puede comenzar teniendo experiencia práctica con los talleres disponibles públicamente para búsqueda semántica, observabilidad de microserviciosy OpenSearch sin servidor. También puede obtener más información sobre las características del servicio y los casos de uso consultando más Publicaciones del blog del servicio OpenSearch.
Acerca de los autores
 Hajer Bouafif es arquitecto de soluciones especialista en análisis en Amazon Web Services. Se centra en Amazon OpenSearch Service y ayuda a los clientes a diseñar y crear cargas de trabajo de análisis bien diseñadas en diversas industrias. A Hajer le gusta pasar tiempo al aire libre y descubrir nuevas culturas.
Hajer Bouafif es arquitecto de soluciones especialista en análisis en Amazon Web Services. Se centra en Amazon OpenSearch Service y ayuda a los clientes a diseñar y crear cargas de trabajo de análisis bien diseñadas en diversas industrias. A Hajer le gusta pasar tiempo al aire libre y descubrir nuevas culturas.

Aish Gunasekar es un arquitecto de soluciones especializado con enfoque en Amazon OpenSearch Service. Su pasión en AWS es ayudar a los clientes a diseñar arquitecturas altamente escalables y ayudarlos en su viaje de adopción de la nube. Fuera del trabajo, le gusta hacer senderismo y hornear.
 jon manejador es arquitecto principal de soluciones sénior en Amazon Web Services con sede en Palo Alto, CA. Jon trabaja en estrecha colaboración con OpenSearch y Amazon OpenSearch Service, brindando ayuda y orientación a una amplia gama de clientes que tienen cargas de trabajo de análisis de registros y búsquedas que desean trasladar a la nube de AWS. Antes de unirse a AWS, la carrera de Jon como desarrollador de software incluyó 4 años de codificación de un motor de búsqueda de comercio electrónico a gran escala. Jon tiene una Licenciatura en Artes de la Universidad de Pensilvania y una Maestría en Ciencias y un Doctorado en Ciencias de la Computación e Inteligencia Artificial de la Universidad Northwestern.
jon manejador es arquitecto principal de soluciones sénior en Amazon Web Services con sede en Palo Alto, CA. Jon trabaja en estrecha colaboración con OpenSearch y Amazon OpenSearch Service, brindando ayuda y orientación a una amplia gama de clientes que tienen cargas de trabajo de análisis de registros y búsquedas que desean trasladar a la nube de AWS. Antes de unirse a AWS, la carrera de Jon como desarrollador de software incluyó 4 años de codificación de un motor de búsqueda de comercio electrónico a gran escala. Jon tiene una Licenciatura en Artes de la Universidad de Pensilvania y una Maestría en Ciencias y un Doctorado en Ciencias de la Computación e Inteligencia Artificial de la Universidad Northwestern.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- ChartPrime. Eleve su juego comercial con ChartPrime. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-h1-2023-in-review/

