Las organizaciones de todas las industrias tienen requisitos de procesamiento de datos complejos para sus casos de uso analítico en diferentes sistemas de análisis, como lagos de datos en AWS, almacenes de datos (Desplazamiento al rojo de Amazon), buscar (Servicio Amazon OpenSearch), No SQL (Amazon DynamoDB), aprendizaje automático (Amazon SageMaker), y más. Los profesionales de análisis tienen la tarea de obtener valor de los datos almacenados en estos sistemas distribuidos para crear experiencias mejores, seguras y rentables para sus clientes. Por ejemplo, las empresas de medios digitales buscan combinar y procesar conjuntos de datos en bases de datos internas y externas para crear vistas unificadas de los perfiles de sus clientes, impulsar ideas para funciones innovadoras y aumentar la participación en la plataforma.
En estos escenarios, los clientes que buscan una oferta de integración de datos sin servidor utilizan Pegamento AWS como un componente central para el procesamiento y catalogación de datos. AWS Glue está bien integrado con los servicios de AWS y los productos de los socios, y proporciona opciones de extracción, transformación y carga (ETL) de bajo código o sin código para permitir análisis, aprendizaje automático (ML) o flujos de trabajo de desarrollo de aplicaciones. Los trabajos ETL de AWS Glue pueden ser un componente de una canalización más compleja. La orquestación de la ejecución y la gestión de las dependencias entre estos componentes es una capacidad clave en una estrategia de datos. Amazon Managed Workflows para Apache Airflows (Amazon MWAA) organiza canalizaciones de datos mediante tecnologías distribuidas, incluidos recursos locales, servicios de AWS y componentes de terceros.
En esta publicación, mostramos cómo simplificar el monitoreo de un trabajo de AWS Glue orquestado por Airflow utilizando las características más recientes de Amazon MWAA.
Resumen de la solución
Esta publicación trata sobre lo siguiente:
- Cómo actualizar un entorno Amazon MWAA a la versión 2.4.3.
- Cómo orquestar un trabajo de AWS Glue desde un Airflow Gráfico acíclico dirigido (TROZO DE CUERO).
- Mejoras en la observabilidad del paquete del proveedor Airflow Amazon en Amazon MWAA. Ahora puede consolidar registros de ejecución de trabajos de AWS Glue en la consola de Airflow para simplificar la solución de problemas de canalizaciones de datos. La consola de Amazon MWAA se convierte en una única referencia para monitorear y analizar las ejecuciones de trabajos de AWS Glue. Anteriormente, los equipos de soporte necesitaban acceder a la Consola de administración de AWS y tome medidas manuales para esta visibilidad. Esta función está disponible de forma predeterminada desde Amazon MWAA versión 2.4.3.
El siguiente diagrama ilustra la arquitectura de nuestra solución.

Requisitos previos
Necesita los siguientes requisitos previos:
Configurar el entorno de Amazon MWAA
Para obtener instrucciones sobre cómo crear su entorno, consulte Cree un entorno de Amazon MWAA. Para los usuarios existentes, recomendamos actualizar a la versión 2.4.3 para aprovechar las mejoras de observabilidad que se presentan en esta publicación.
Los pasos para actualizar Amazon MWAA a la versión 2.4.3 difieren según si la versión actual es 1.10.12 o 2.2.2. Discutimos ambas opciones en esta publicación.
Requisitos previos para configurar un entorno de Amazon MWAA
Debe cumplir con los siguientes requisitos previos:
Actualizar de la versión 1.10.12 a la 2.4.3
Si está utilizando la versión Amazon MWAA 1.10.12, Referirse a Migración a un nuevo entorno de Amazon MWAA para actualizar a 2.4.3.
Actualizar desde la versión 2.0.2 o 2.2.2 a 2.4.3
Si está utilizando la versión 2.2.2 o anterior del entorno Amazon MWAA, complete los siguientes pasos:
- Créar un requisitos.txt para cualquier dependencia personalizada con versiones específicas requeridas para sus DAG.
- Sube el archivo a Amazon S3 en la ubicación adecuada donde el entorno de Amazon MWAA apunta a los requisitos.txt para instalar las dependencias.
- Sigue los pasos en Migración a un nuevo entorno de Amazon MWAA y seleccione la versión 2.4.3.
Actualice sus DAG
Es posible que los clientes que actualizaron desde un entorno anterior de Amazon MWAA deban realizar actualizaciones en los DAG existentes. En la versión 2.4.3 de Airflow, el entorno de Airflow utilizará la versión 6.0.0 del paquete del proveedor de Amazon de forma predeterminada. Este paquete puede incluir algunos cambios potencialmente importantes, como cambios en los nombres de los operadores. por ejemplo, el Operador AWSGlueJob ha sido obsoleto y reemplazado por el PegamentoTrabajoOperador. Para mantener la compatibilidad, actualice sus DAG de Airflow reemplazando cualquier operador obsoleto o no compatible de versiones anteriores con los nuevos. Complete los siguientes pasos:
- Navegue hasta Operadores de Amazon AWS.
- Seleccione la versión adecuada instalada en su instancia de Amazon MWAA (6.0.0. de forma predeterminada) para encontrar una lista de operadores de Airflow admitidos.
- Realice los cambios necesarios en el código DAG existente y cargue los archivos modificados en la ubicación DAG en Amazon S3.
Orqueste el trabajo de AWS Glue desde Airflow
Esta sección cubre los detalles de orquestar un trabajo de AWS Glue dentro de los DAG de Airflow. Airflow facilita el desarrollo de canalizaciones de datos con dependencias entre sistemas heterogéneos, como procesos locales, dependencias externas, otros servicios de AWS y más.
Organice la agregación de registros de CloudTrail con AWS Glue y Amazon MWAA
En este ejemplo, analizamos un caso de uso de Amazon MWAA para orquestar un trabajo de AWS Glue Python Shell que conserva las métricas agregadas en función de los registros de CloudTrail.
CloudTrail permite la visibilidad de las llamadas a la API de AWS que se realizan en su cuenta de AWS. Un caso de uso común con estos datos sería recopilar métricas de uso sobre los principales que actúan sobre los recursos de su cuenta para necesidades regulatorias y de auditoría.
A medida que se registran los eventos de CloudTrail, se entregan como archivos JSON en Amazon S3, que no son ideales para consultas analíticas. Queremos agregar estos datos y conservarlos como archivos de Parquet para permitir un rendimiento de consulta óptimo. Como paso inicial, podemos utilizar Athena para realizar la consulta inicial de los datos antes de realizar agregaciones adicionales en nuestro trabajo de AWS Glue. Para obtener más información sobre cómo crear una tabla de AWS Glue Data Catalog, consulte Creación de la tabla para registros de CloudTrail en Athena mediante proyección de partición datos. Después de explorar los datos a través de Athena y decidir qué métricas queremos retener en las tablas agregadas, podemos crear un trabajo de AWS Glue.
Crear una tabla de CloudTrail en Athena
Primero, necesitamos crear una tabla en nuestro catálogo de datos que permita consultar los datos de CloudTrail a través de Athena. La siguiente consulta de ejemplo crea una tabla con dos particiones en la Región y la fecha (llamada snapshot_date). Asegúrese de reemplazar los marcadores de posición de su depósito de CloudTrail, ID de cuenta de AWS y nombre de tabla de CloudTrail:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Ejecute la consulta anterior en la consola de Athena y anote el nombre de la tabla y la base de datos de AWS Glue Data Catalog donde se creó. Usamos estos valores más adelante en el código DAG de Airflow.
Ejemplo de código de trabajo de AWS Glue
El siguiente código es una muestra. Trabajo de AWS Glue Python Shell que hace lo siguiente:
- Toma argumentos (que pasamos de nuestro Amazon MWAA DAG) sobre qué datos del día procesar
- Utiliza el SDK de AWS para pandas para ejecutar una consulta de Athena para realizar el filtrado inicial de los datos JSON de CloudTrail fuera de AWS Glue
- Usa Pandas para hacer agregaciones simples en los datos filtrados
- Envía los datos agregados a AWS Glue Data Catalog en una tabla
- Utiliza el registro durante el procesamiento, que será visible en Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Las siguientes son algunas ventajas clave en este trabajo de AWS Glue:
- Usamos una consulta de Athena para garantizar que el filtrado inicial se realice fuera de nuestro trabajo de AWS Glue. Como tal, un trabajo de Python Shell con un cálculo mínimo sigue siendo suficiente para agregar un gran conjunto de datos de CloudTrail.
- Aseguramos la opción de conjunto de biblioteca de análisis se activa al crear nuestro trabajo de AWS Glue para usar la biblioteca AWS SDK for Pandas.
Crear un trabajo de AWS Glue
Complete los siguientes pasos para crear su trabajo de AWS Glue:
- Copie el script en la sección anterior y guárdelo en un archivo local. Para esta publicación, el archivo se llama
script.py. - En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación.
- Cree un nuevo trabajo y seleccione Editor de secuencias de comandos Python Shell.
- Seleccione Cargar y editar un script existente y cargue el archivo que guardó localmente.
- Elige Crear.

- En Detalles del trabajo pestaña, ingrese un nombre para su trabajo de AWS Glue.
- Rol de IAM, elija una función existente o cree una nueva función que tenga los permisos necesarios para Amazon S3, AWS Glue y Athena. El rol debe consultar la tabla de CloudTrail que creó anteriormente y escribir en una ubicación de salida.
Puede usar el siguiente código de política de muestra. Reemplace los marcadores de posición con su depósito de registros de CloudTrail, el nombre de la tabla de salida, la base de datos de AWS Glue de salida, el depósito de S3 de salida, el nombre de la tabla de CloudTrail, la base de datos de AWS Glue que contiene la tabla de CloudTrail y su ID de cuenta de AWS.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Versión de Python, escoger 3.9 Python.
- Seleccione Cargue bibliotecas de análisis comunes.
- Unidades de procesamiento de datos, escoger 1 UPD.
- Deje las otras opciones como predeterminadas o ajústelas según sea necesario.
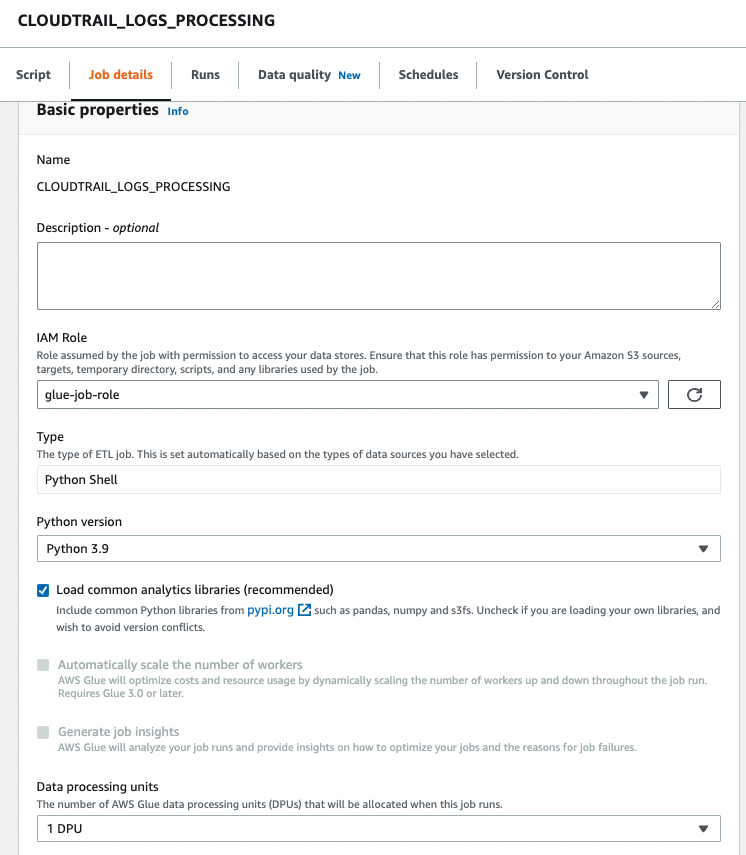
- Elige Guardar para guardar la configuración de su trabajo.
Configure un DAG de Amazon MWAA para orquestar el trabajo de AWS Glue
El siguiente código es para un DAG que puede orquestar el trabajo de AWS Glue que creamos. Aprovechamos las siguientes características clave en este DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Aumente la visibilidad de los trabajos de AWS Glue en Amazon MWAA
Los trabajos de AWS Glue escriben registros en Reloj en la nube de Amazon. Con las recientes mejoras de observabilidad del paquete de proveedores de Amazon de Airflow, estos registros ahora están integrados con los registros de tareas de Airflow. Esta consolidación brinda a los usuarios de Airflow visibilidad integral directamente en la interfaz de usuario de Airflow, lo que elimina la necesidad de buscar en CloudWatch o en la consola de AWS Glue.
Para usar esta función, asegúrese de que el rol de IAM adjunto al entorno de Amazon MWAA tenga los siguientes permisos para recuperar y escribir los registros necesarios:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Si verbose=true, los registros de ejecución de trabajos de AWS Glue se muestran en los registros de tareas de Airflow. El valor predeterminado es falso. Para obtener más información, consulte parámetros.
Cuando están habilitados, los DAG leen el flujo de registros de CloudWatch del trabajo de AWS Glue y los transmiten a los registros de pasos del trabajo de AWS Glue del DAG de Airflow. Esto proporciona información detallada sobre la ejecución de un trabajo de AWS Glue en tiempo real a través de los registros de DAG. Tenga en cuenta que los trabajos de AWS Glue generan un grupo de registros de CloudWatch de salida y error en función de STDOUT y STDERR del trabajo, respectivamente. Todos los registros del grupo de registros de salida y los registros de errores o excepciones del grupo de registros de errores se transmiten a Amazon MWAA.
Los administradores de AWS ahora pueden limitar el acceso de un equipo de soporte solo a Airflow, lo que convierte a Amazon MWAA en el único panel de control en la orquestación de trabajos y la administración del estado del trabajo. Anteriormente, los usuarios debían verificar el estado de ejecución del trabajo de AWS Glue en los pasos del DAG de Airflow y recuperar el identificador de ejecución del trabajo. Luego necesitaban acceder a la consola de AWS Glue para encontrar el historial de ejecución del trabajo, buscar el trabajo de interés utilizando el identificador y, finalmente, navegar a los registros de CloudWatch del trabajo para solucionar el problema.
Crear el DAG
Para crear el DAG, complete los siguientes pasos:
- Guarde el código DAG anterior en un archivo .py local, reemplazando los marcadores de posición indicados.
Los valores de su ID de cuenta de AWS, el nombre del trabajo de AWS Glue, la base de datos de AWS Glue con la tabla de CloudTrail y el nombre de la tabla de CloudTrail ya deberían conocerse. Puede ajustar el depósito de S3 de salida, la base de datos de AWS Glue de salida y el nombre de la tabla de salida según sea necesario, pero asegúrese de que el rol de IAM del trabajo de AWS Glue que utilizó anteriormente esté configurado en consecuencia.
- En la consola de Amazon MWAA, navegue a su entorno para ver dónde está almacenado el código DAG.
La carpeta DAG es el prefijo dentro del depósito S3 donde debe colocarse su archivo DAG.
- Cargue su archivo editado allí.
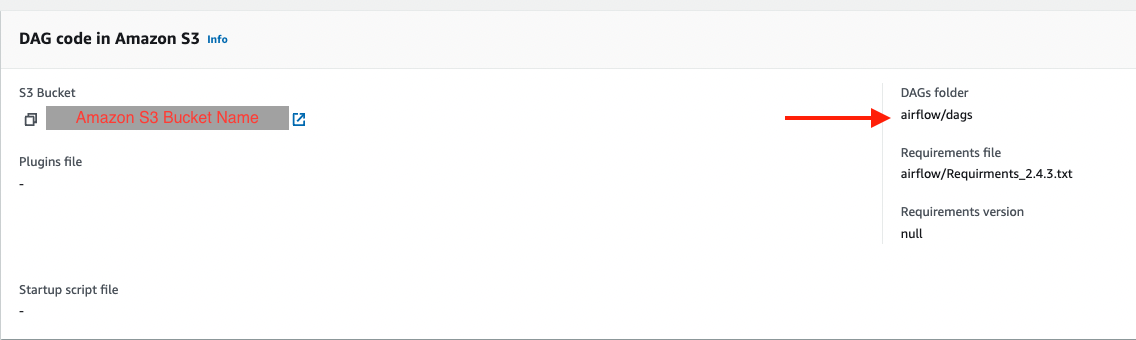
- Abra la consola de Amazon MWAA para confirmar que el DAG aparece en la tabla.

Ejecute el DAG
Para ejecutar el DAG, complete los siguientes pasos:
- Elija entre las siguientes opciones:
- Activar DAG – Esto hace que los datos de ayer se utilicen como datos para procesar
- Activar DAG con configuración – Con esta opción, puede pasar una fecha diferente, potencialmente para rellenos, que se recupera usando
dag_run.confen el código DAG y luego se pasa al trabajo de AWS Glue como un parámetro

La siguiente captura de pantalla muestra las opciones de configuración adicionales si elige Activar DAG con configuración.
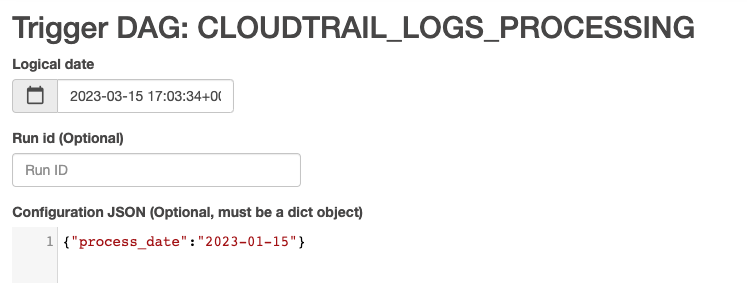
- Supervise el DAG mientras se ejecuta.
- Cuando el DAG esté completo, abra los detalles de la ejecución.
En el panel derecho, puede ver los registros o elegir Detalles de instancia de tarea para una vista completa.

- Vea los registros de salida del trabajo de AWS Glue en Amazon MWAA sin utilizar la consola de AWS Glue gracias a la
GlueJobOperatorbandera detallada.
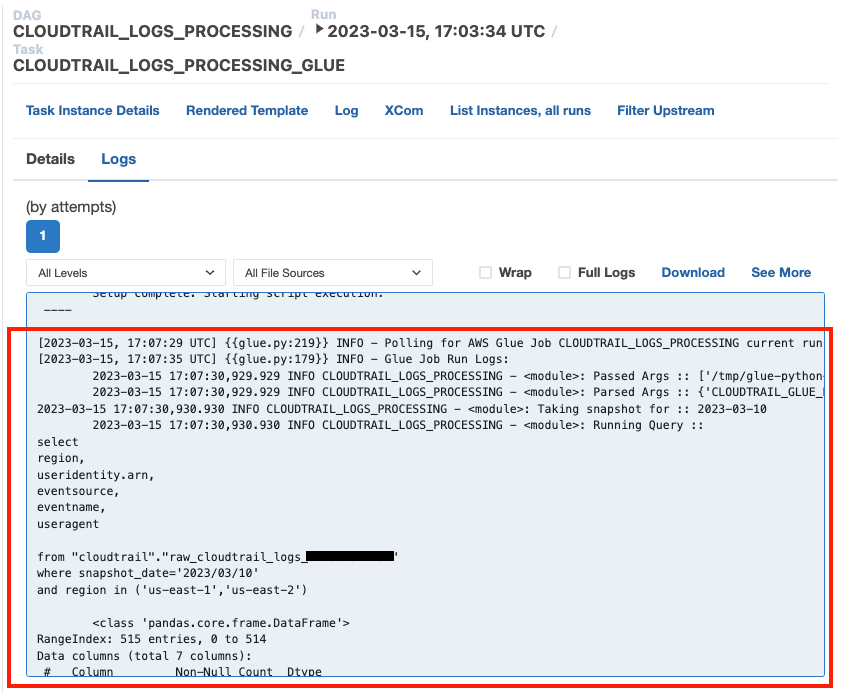
El trabajo de AWS Glue tendrá resultados escritos en la tabla de salida que especificó.
- Consulte esta tabla a través de Athena para confirmar que se realizó correctamente.
Resumen
Amazon MWAA ahora proporciona un lugar único para realizar un seguimiento del estado de los trabajos de AWS Glue y le permite utilizar la consola de Airflow como panel único para la orquestación de trabajos y la administración del estado. En esta publicación, repasamos los pasos para orquestar trabajos de AWS Glue a través de Airflow usando GlueJobOperator. Con las nuevas mejoras de observabilidad, puede solucionar sin problemas los trabajos de AWS Glue en una experiencia unificada. También demostramos cómo actualizar su entorno de Amazon MWAA a una versión compatible, actualizar las dependencias y cambiar la política de roles de IAM en consecuencia.
Para obtener más información sobre los pasos comunes de solución de problemas, consulte Solución de problemas: creación y actualización de un entorno de Amazon MWAA. Para obtener detalles detallados sobre la migración a un entorno Amazon MWAA, consulte Actualización de 1.10 a 2. Para obtener más información sobre los cambios en el código de fuente abierta para una mayor visibilidad de los trabajos de AWS Glue en el paquete del proveedor Airflow de Amazon, consulte el retransmitir registros de trabajos de AWS Glue.
Por último, recomendamos visitar la Blog de grandes datos de AWS para obtener otro material sobre análisis, aprendizaje automático y gobierno de datos en AWS.
Acerca de los autores
 Rushabh Lokhande es ingeniero de datos y aprendizaje automático en la práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar grandes soluciones de datos, aprendizaje automático y análisis. Fuera del trabajo, disfruta pasar tiempo con la familia, leer, correr y jugar al golf.
Rushabh Lokhande es ingeniero de datos y aprendizaje automático en la práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar grandes soluciones de datos, aprendizaje automático y análisis. Fuera del trabajo, disfruta pasar tiempo con la familia, leer, correr y jugar al golf.
 ryan gomes es ingeniero de datos y aprendizaje automático en la práctica de análisis de servicios profesionales de AWS. Le apasiona ayudar a los clientes a lograr mejores resultados a través de análisis y soluciones de aprendizaje automático en la nube. Fuera del trabajo, disfruta hacer ejercicio, cocinar y pasar tiempo de calidad con amigos y familiares.
ryan gomes es ingeniero de datos y aprendizaje automático en la práctica de análisis de servicios profesionales de AWS. Le apasiona ayudar a los clientes a lograr mejores resultados a través de análisis y soluciones de aprendizaje automático en la nube. Fuera del trabajo, disfruta hacer ejercicio, cocinar y pasar tiempo de calidad con amigos y familiares.
 Vishwa Gupta es Arquitecto de datos sénior en la práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar grandes soluciones de análisis y datos. Fuera del trabajo, disfruta pasar tiempo con la familia, viajar y probar comida nueva.
Vishwa Gupta es Arquitecto de datos sénior en la práctica de análisis de servicios profesionales de AWS. Ayuda a los clientes a implementar grandes soluciones de análisis y datos. Fuera del trabajo, disfruta pasar tiempo con la familia, viajar y probar comida nueva.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Compra y Vende Acciones en Empresas PRE-IPO con PREIPO®. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/

