Amazon Lookout para la visión proporciona un servicio de detección de anomalías basado en aprendizaje automático (ML) para identificar imágenes normales (es decir, imágenes de objetos sin defectos) frente a imágenes anómalas (es decir, imágenes de objetos defectos), tipos de anomalías (p. ej., pieza faltante) y la ubicación de estas anomalías. Por lo tanto, Lookout for Vision es popular entre los clientes que buscan soluciones automatizadas para la inspección de calidad industrial (p. ej., detección de productos anormales). Sin embargo, los conjuntos de datos de los clientes suelen enfrentarse a dos problemas:
- El número de imágenes con anomalías puede ser muy bajo y es posible que no alcance el mínimo de anomalías/tipo de defecto impuesto por Lookout for Vision (~20).
- Es posible que las imágenes normales no tengan suficiente diversidad y que el modelo falle cuando las condiciones ambientales, como la iluminación, cambien en la producción.
Para superar estos problemas, esta publicación presenta una tubería de aumento de imágenes que se enfoca en ambos problemas: proporciona una forma de generar imágenes anómalas sintéticas mediante la eliminación de objetos en las imágenes y genera imágenes normales adicionales mediante la introducción de aumentos controlados como ruido gaussiano, tono, saturación, píxeles escala de valores, etc. Usamos el imgaug biblioteca para introducir el aumento para generar imágenes anómalas y normales adicionales para el segundo problema. Usamos Verdad del terreno de Amazon Sagemaker para generar máscaras de eliminación de objetos y la Lama algoritmo para eliminar objetos para el primer problema utilizando técnicas de pintura de imágenes (eliminación de objetos).
El resto del post está organizado de la siguiente manera. En la Sección 3, presentamos la canalización de aumento de imágenes para imágenes normales. En la Sección 4, presentamos la tubería de aumento de imágenes para imágenes anormales (también conocida como generación de defectos sintéticos). La Sección 5 ilustra los resultados del entrenamiento de Lookout for Vision utilizando el conjunto de datos aumentado. La Sección 6 demuestra cómo el modelo Lookout for Vision entrenado en datos sintéticos se comporta frente a defectos reales. En la Sección 7, hablamos sobre la estimación de costos para esta solución. Se puede acceder a todo el código que usamos para esta publicación esta página.
1. Descripción general de la solución
diagrama ML
El siguiente es el diagrama de la canalización de aumento de imágenes propuesta para el entrenamiento del modelo de localización de anomalías de Lookout for Vision:

El diagrama anterior comienza recopilando una serie de imágenes (paso 1). Aumentamos el conjunto de datos aumentando las imágenes normales (paso 3) y usando algoritmos de eliminación de objetos (pasos 2, 5-6). Luego, empaquetamos los datos en un formato que Amazon Lookout for Vision pueda consumir (pasos 7 y 8). Finalmente, en el paso 9, usamos los datos empaquetados para entrenar un modelo de localización de Lookout for Vision.
Esta tubería de aumento de imágenes brinda a los clientes flexibilidad para generar defectos sintéticos en el conjunto de datos de muestra limitado, así como para agregar más cantidad y variedad a las imágenes normales. Mejoraría el rendimiento del servicio Lookout for Vision, resolviendo el problema de la falta de datos del cliente y haciendo que el proceso de inspección de calidad automatizado sea más fluido.
2. Preparación de datos
Desde aquí hasta el final de la publicación, usamos el público FICS-PCB: un conjunto de datos de imágenes multimodales para la inspección visual automatizada de placas de circuitos impresos conjunto de datos con licencia bajo un Licencia Creative Commons Reconocimiento 4.0 Internacional (CC BY 4.0) para ilustrar la tubería de aumento de imágenes y la consiguiente capacitación y prueba de Lookout for Vision. Este conjunto de datos está diseñado para respaldar la evaluación de sistemas automatizados de inspección visual de PCB. Se recopiló en el laboratorio de Seguridad y Garantía (SCAN) de la Universidad de Florida. Se puede acceder esta página.
Partimos de la hipótesis de que el cliente solo proporciona una única imagen normal de una placa PCB (una muestra de PCB s10) como conjunto de datos. Se puede ver de la siguiente manera:

3. Aumento de imagen para imágenes normales
El servicio Lookout for Vision requiere al menos 20 imágenes normales y 20 anomalías por tipo de defecto. Dado que solo hay una imagen normal de los datos de muestra, debemos generar más imágenes normales utilizando técnicas de aumento de imágenes. Desde el punto de vista de ML, alimentar múltiples transformaciones de imágenes utilizando diferentes técnicas de aumento puede mejorar la precisión y la solidez del modelo.
Usaremos imgaug para el aumento de imágenes de imágenes normales. Imgaug es un paquete de Python de código abierto que le permite aumentar imágenes en experimentos de ML.
Primero, instalaremos el imgaug biblioteca en una Amazon SageMaker cuaderno.
A continuación, podemos instalar el paquete de python llamado 'IPyPlot'.
Luego, realizamos un aumento de imagen de la imagen original usando transformaciones que incluyen GammaContrast, SigmoidContrasty LinearContrast, y agregando ruido gaussiano en la imagen.
import imageio
import imgaug as ia
import imgaug.augmenters as iaa
import ipyplot
input_img = imageio.imread('s10.png')
noise=iaa.AdditiveGaussianNoise(10,40)
input_noise=noise.augment_image(input_img)
contrast=iaa.GammaContrast((0.5, 2.0))
contrast_sig = iaa.SigmoidContrast(gain=(5, 10), cutoff=(0.4, 0.6))
contrast_lin = iaa.LinearContrast((0.6, 0.4))
input_contrast = contrast.augment_image(input_img)
sigmoid_contrast = contrast_sig.augment_image(input_img)
linear_contrast = contrast_lin.augment_image(input_img)
images_list=[input_img, input_contrast,sigmoid_contrast,linear_contrast,input_noise]
labels = ['Original', 'Gamma Contrast','SigmoidContrast','LinearContrast','Gaussian Noise Image']
ipyplot.plot_images(images_list,labels=labels,img_width=180)

Dado que necesitamos al menos 20 imágenes normales, y cuantas más mejor, generamos 10 imágenes aumentadas para cada una de las 4 transformaciones que se muestran arriba como nuestro conjunto de datos de imágenes normales. En el futuro, también planeamos transformar las imágenes para colocarlas en diferentes ubicaciones y diferentes ángulos para que el modelo entrenado pueda ser menos sensible a la ubicación del objeto en relación con la cámara fija.
4. Generación de defectos sintéticos para el aumento de imágenes anormales
En esta sección, presentamos una tubería de generación de defectos sintéticos para aumentar la cantidad de imágenes con anomalías en el conjunto de datos. Tenga en cuenta que, a diferencia de la sección anterior donde creamos nuevas muestras normales a partir de muestras normales existentes, aquí creamos nuevas imágenes de anomalías a partir de muestras normales. Esta es una característica atractiva para los clientes que carecen por completo de este tipo de imágenes en sus conjuntos de datos, por ejemplo, quitar un componente de la placa PCB normal. Esta canalización de generación de defectos sintéticos consta de tres pasos: en primer lugar, generamos máscaras sintéticas a partir de imágenes de origen (normales) mediante Amazon SageMaker Ground Truth. En esta publicación, nos enfocamos en un tipo de defecto específico: componente faltante. Esta generación de máscara proporciona una imagen de máscara y un archivo de manifiesto. En segundo lugar, el archivo de manifiesto debe modificarse y convertirse en un archivo de entrada para un punto final de SageMaker. Y tercero, el archivo de entrada se ingresa en un punto final de eliminación de objetos de SageMaker responsable de eliminar las partes de la imagen normal indicadas por la máscara. Este punto final proporciona la imagen anormal resultante.
4.1 Genere máscaras de defectos sintéticas con Amazon SageMaker Ground Truth
Amazon Sagemaker Ground Truth para el etiquetado de datos
Amazon SageMaker Ground Truth es un servicio de etiquetado de datos que facilita el etiquetado de datos y le brinda la opción de utilizar anotadores humanos a través de Amazon Mechanical Turk, proveedores externos o su propia mano de obra privada. Puedes seguir este tutorial para configurar un trabajo de etiquetado.
En esta sección, mostraremos cómo usamos Verdad fundamental de Amazon SageMaker para marcar "componentes" específicos en imágenes normales para eliminarlos en el siguiente paso. Tenga en cuenta que una contribución clave de esta publicación es que no usamos Amazon SageMaker Ground Truth en su forma tradicional (es decir, para etiquetar imágenes de entrenamiento). Aquí, lo usamos para generar una máscara para eliminarla en el futuro en imágenes normales. Estas eliminaciones en imágenes normales generarán los defectos sintéticos.
Para el propósito de esta publicación, en nuestro trabajo de etiquetado eliminaremos artificialmente hasta tres componentes de la placa PCB: IC, resistor1 y resistor2. Después de ingresar al trabajo de etiquetado como etiquetador, puede seleccionar el nombre de la etiqueta y dibujar una máscara de cualquier forma alrededor del componente que desea eliminar de la imagen como un defecto sintético. Tenga en cuenta que no puede incluir '_' en el nombre de la etiqueta para este experimento, ya que usamos '_' para separar diferentes metadatos en el nombre del defecto más adelante en el código.
En la siguiente imagen, dibujamos una máscara verde alrededor del IC (Circuito Integrado), una máscara azul alrededor de la resistencia 1 y una máscara naranja alrededor de la resistencia 2.

Después de que seleccionemos el enviar , Amazon SageMaker Ground Truth generará una máscara de salida con fondo blanco y un archivo de manifiesto de la siguiente manera:

{"source-ref":"s3://pcbtest22/label/s10.png","s10-label-ref":"s3://pcbtest22/label/s10-label/annotations/consolidated-annotation/output/0_2022-09-08T18:01:51.334016.png","s10-label-ref-metadata":{"internal-color-map":{"0":{"class-name":"BACKGROUND","hex-color":"#ffffff","confidence":0},"1":{"class-name":"IC","hex-color":"#2ca02c","confidence":0},"2":{"class-name":"resistor_1","hex-color":"#1f77b4","confidence":0},"3":{"class-name":"resistor_2","hex-color":"#ff7f0e","confidence":0}},"type":"groundtruth/semantic-segmentation","human-annotated":"yes","creation-date":"2022-09-08T18:01:51.498525","job-name":"labeling-job/s10-label"}}
Tenga en cuenta que hasta ahora no hemos generado ninguna imagen anormal. Acabamos de marcar los tres componentes que se eliminarán artificialmente y cuya eliminación generará imágenes anormales. Más adelante, usaremos (1) la imagen de máscara anterior y (2) la información del archivo de manifiesto como entradas para la canalización de generación de imágenes anómalas. La siguiente sección muestra cómo preparar la entrada para el extremo de SageMaker.
4.2 Preparar la entrada para el punto final de SageMaker
Transforme el manifiesto de Amazon SageMaker Ground Truth como un archivo de entrada de punto final de SageMaker
Primero, configuramos un Servicio de almacenamiento simple de Amazon (Amazon S3) depósito para almacenar todas las entradas y salidas para la canalización de aumento de imágenes. En la publicación, usamos un depósito S3 llamado qualityinspection. Luego generamos todas las imágenes normales aumentadas y las subimos a este cubo S3.
from PIL import Image import os import shutil import boto3 s3=boto3.client('s3') # make the image directory
dir_im="images"
if not os.path.isdir(dir_im):
os.makedirs(dir_im)
# create augmented images from original image
input_img = imageio.imread('s10.png') for i in range(10):
noise=iaa.AdditiveGaussianNoise(scale=0.2*255)
contrast=iaa.GammaContrast((0.5,2))
contrast_sig = iaa.SigmoidContrast(gain=(5,20), cutoff=(0.25, 0.75))
contrast_lin = iaa.LinearContrast((0.4,1.6))
input_noise=noise.augment_image(input_img)
input_contrast = contrast.augment_image(input_img)
sigmoid_contrast = contrast_sig.augment_image(input_img)
linear_contrast = contrast_lin.augment_image(input_img)
im_noise = Image.fromarray(input_noise)
im_noise.save(f'{dir_im}/input_noise_{i}.png') im_input_contrast = Image.fromarray(input_contrast)
im_input_contrast.save(f'{dir_im}/contrast_sig_{i}.png') im_sigmoid_contrast = Image.fromarray(sigmoid_contrast)
im_sigmoid_contrast.save(f'{dir_im}/sigmoid_contrast_{i}.png') im_linear_contrast = Image.fromarray(linear_contrast)
im_linear_contrast.save(f'{dir_im}/linear_contrast_{i}.png')
# move original image to image augmentation folder
shutil.move('s10.png','images/s10.png')
# list all the images in the image directory
imlist = [file for file in os.listdir(dir_im) if file.endswith('.png')] # upload augmented images to an s3 bucket
s3_bucket='qualityinspection'
for i in range(len(imlist)):
with open('images/'+imlist[i], 'rb') as data:
s3.upload_fileobj(data, s3_bucket, 'images/'+imlist[i]) # get the image s3 locations
im_s3_list=[]
for i in range(len(imlist)):
image_s3='s3://qualityinspection/images/'+imlist[i]
im_s3_list.append(image_s3)
A continuación, descargamos la máscara de Amazon SageMaker Ground Truth y la subimos a una carpeta llamada "máscara" en ese depósito S3.
# download Ground Truth annotation mask image to local from the Ground Truth s3 folder
s3.download_file('pcbtest22', 'label/S10-label3/annotations/consolidated-annotation/output/0_2022-09-09T17:25:31.918770.png', 'mask.png')
# upload mask to mask folder
s3.upload_file('mask.png', 'qualityinspection', 'mask/mask.png')
Después de eso, descargamos el archivo de manifiesto del trabajo de etiquetado de Amazon SageMaker Ground Truth y lo leemos como líneas json.
import json
#download output manifest to local
s3.download_file('pcbtest22', 'label/S10-label3/manifests/output/output.manifest', 'output.manifest')
# read the manifest file
with open('output.manifest','rt') as the_new_file:
lines=the_new_file.readlines()
for line in lines:
json_line = json.loads(line)
Por último, generamos un diccionario de entrada que registra la ubicación S3 de la imagen de entrada, la ubicación de la máscara, la información de la máscara, etc., lo guardamos como archivo txt y luego lo subimos a la carpeta de "entrada" del depósito S3 de destino.
# create input dictionary
input_dat=dict()
input_dat['input-image-location']=im_s3_list
input_dat['mask-location']='s3://qualityinspection/mask/mask.png'
input_dat['mask-info']=json_line['S10-label3-ref-metadata']['internal-color-map']
input_dat['output-bucket']='qualityinspection'
input_dat['output-project']='synthetic_defect' # Write the input as a txt file and upload it to s3 location
input_name='input.txt'
with open(input_name, 'w') as the_new_file:
the_new_file.write(json.dumps(input_dat))
s3.upload_file('input.txt', 'qualityinspection', 'input/input.txt')
El siguiente es un archivo de entrada de muestra:
{"input-image-location": ["s3://qualityinspection/images/s10.png", ... "s3://qualityinspection/images/contrast_sig_1.png"], "mask-location": "s3://qualityinspection/mask/mask.png", "mask-info": {"0": {"class-name": "BACKGROUND", "hex-color": "#ffffff", "confidence": 0}, "1": {"class-name": "IC", "hex-color": "#2ca02c", "confidence": 0}, "2": {"class-name": "resistor1", "hex-color": "#1f77b4", "confidence": 0}, "3": {"class-name": "resistor2", "hex-color": "#ff7f0e", "confidence": 0}}, "output-bucket": "qualityinspection", "output-project": "synthetic_defect"}
4.3 Cree un punto final de SageMaker asincrónico para generar defectos sintéticos con componentes faltantes
4.3.1 Modelo LaMa
Para eliminar componentes de la imagen original, usamos un modelo PyTorch de código abierto llamado LaMa de LaMa: pintura de máscara grande resistente a la resolución con circunvoluciones de Fourier. Es un modelo de pintura en pintura de máscara grande resistente a la resolución con circunvoluciones de Fourier desarrollado por Samsung AI. Las entradas para el modelo son una imagen y una máscara en blanco y negro y la salida es una imagen con los objetos dentro de la máscara eliminados. Usamos Amazon SageMaker Ground Truth para crear la máscara original y luego la transformamos en una máscara en blanco y negro según sea necesario. La aplicación del modelo LaMa se demuestra de la siguiente manera:
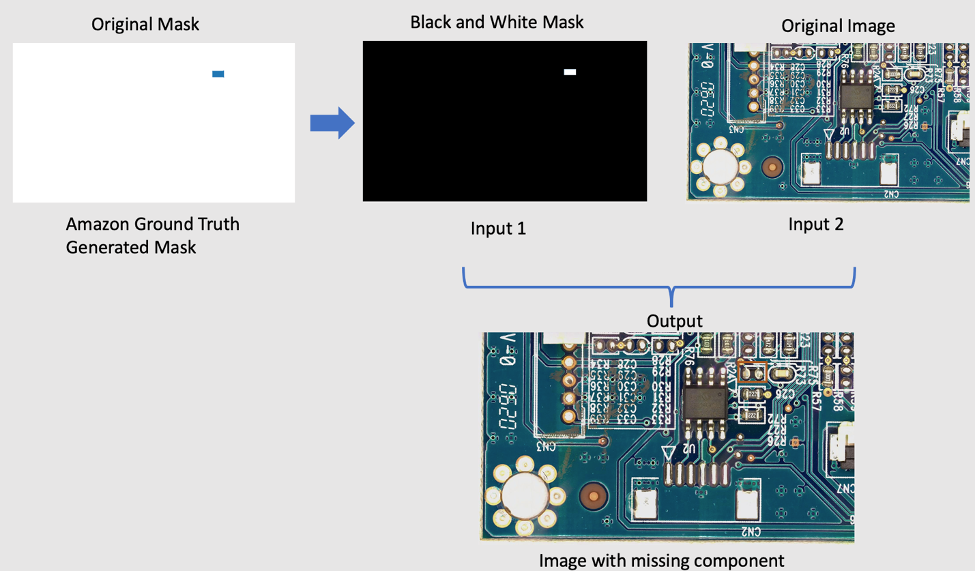
4.3.2 Introducción a la inferencia asíncrona de Amazon SageMaker
Inferencia asincrónica de Amazon SageMaker es una nueva opción de inferencia en Amazon SageMaker que pone en cola las solicitudes entrantes y las procesa de forma asincrónica. La inferencia asincrónica permite a los usuarios ahorrar costos ajustando automáticamente el recuento de instancias a cero cuando no hay solicitudes para procesar. Esto significa que solo paga cuando su terminal está procesando solicitudes. La nueva opción de inferencia asincrónica es ideal para cargas de trabajo donde los tamaños de solicitud son grandes (hasta 1 GB) y los tiempos de procesamiento de inferencia son del orden de minutos. El código para implementar e invocar el punto final es esta página.
4.3.3 Implementación de terminales
Para implementar el punto final asíncrono, primero debemos obtener el Rol de IAM y configurar algunas variables de entorno.
from sagemaker import get_execution_role
from sagemaker.pytorch import PyTorchModel
import boto3 role = get_execution_role()
env = dict()
env['TS_MAX_REQUEST_SIZE'] = '1000000000'
env['TS_MAX_RESPONSE_SIZE'] = '1000000000'
env['TS_DEFAULT_RESPONSE_TIMEOUT'] = '1000000'
env['DEFAULT_WORKERS_PER_MODEL'] = '1'
Como mencionamos antes, estamos usando el modelo PyTorch de código abierto LaMa: pintura de máscara grande resistente a la resolución con circunvoluciones de Fourier y el modelo preentrenado se ha subido a s3://qualityinspection/model/big-lama.tar.gz. image_uri apunta a un contenedor docker con el marco requerido y las versiones de python.
model = PyTorchModel(
entry_point="./inference_defect_gen.py",
role=role,
source_dir = './',
model_data='s3://qualityinspection/model/big-lama.tar.gz',
image_uri = '763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-inference:1.11.0-gpu-py38-cu113-ubuntu20.04-sagemaker',
framework_version="1.7.1",
py_version="py3",
env = env,
model_server_workers=1
)
Luego, debemos especificar parámetros de configuración específicos de inferencia asíncrona adicionales al crear la configuración del punto final.
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
bucket = 'qualityinspection'
prefix = 'async-endpoint'
async_config = AsyncInferenceConfig(output_path=f"s3://{bucket}/{prefix}/output",max_concurrent_invocations_per_instance=10)
A continuación, implementamos el punto final en una instancia ml.g4dn.xlarge ejecutando el siguiente código:
predictor = model.deploy(
initial_instance_count=1,
instance_type='ml.g4dn.xlarge',
model_server_workers=1,
async_inference_config=async_config
)
Después de aproximadamente 6 a 8 minutos, el extremo se crea correctamente y aparecerá en la consola de SageMaker.

4.3.4 Invocar el punto final
Luego, usamos el archivo txt de entrada que generamos anteriormente como la entrada del punto final e invocamos el punto final usando el siguiente código:
import boto3
runtime= boto3.client('runtime.sagemaker')
response = runtime.invoke_endpoint_async(EndpointName='pytorch-inference-2022-09-16-02-04-37-888',
InputLocation='s3://qualityinspection/input/input.txt')
El comando anterior terminará la ejecución inmediatamente. Sin embargo, la inferencia continuará durante varios minutos hasta que complete todas las tareas y devuelva todas las salidas en el depósito S3.
4.3.5 Comprobar el resultado de la inferencia del punto final
Después de seleccionar el punto final, verá la sesión de Monitor. Seleccione 'Ver registros' para verificar los resultados de la inferencia en la consola.

Aparecerán dos entradas de registro en Flujos de registro. el llamado data-log mostrará el resultado final de la inferencia, mientras que el otro registro de registro mostrará los detalles de la inferencia, que generalmente se usa con fines de depuración.

Si la solicitud de inferencia tiene éxito, verá el mensaje: Inference request succeeded.en el registro de datos y también obtenga información de la latencia total del modelo, el tiempo total del proceso, etc. en el mensaje. Si la inferencia falla, verifique el otro registro para depurar. También puede verificar el resultado sondeando el estado de la solicitud de inferencia. Más información sobre la inferencia asincrónica de Amazon SageMaker esta página.

4.3.6 Generación de defectos sintéticos con componentes faltantes usando el punto final
Completaremos cuatro tareas en el punto final:
- El servicio de localización de anomalías de Lookout for Vision requiere un defecto por imagen en el conjunto de datos de entrenamiento para optimizar el rendimiento del modelo. Por lo tanto, debemos separar las máscaras para diferentes defectos en el punto final mediante filtrado de color.

- Divida el conjunto de datos de prueba/tren para satisfacer el siguiente requisito:
- al menos 10 imágenes normales y 10 anomalías para el conjunto de datos del tren
- un defecto/imagen en el conjunto de datos del tren
- al menos 10 imágenes normales y 10 anomalías para el conjunto de datos de prueba
- se permiten múltiples defectos por imagen para el conjunto de datos de prueba
- Genere defectos sintéticos y cárguelos en las ubicaciones S3 de destino.
Generamos un defecto por imagen y más de 20 defectos por clase para el conjunto de datos del tren, así como de 1 a 3 defectos por imagen y más de 20 defectos por clase para el conjunto de datos de prueba.
El siguiente es un ejemplo de la imagen de origen y sus defectos sintéticos con tres componentes: IC, resistor1 y resistor 2 faltantes.

imagen original

40_im_mask_IC_resistor1_resistor2.jpg (el nombre del defecto indica los componentes que faltan)
- Genere archivos de manifiesto para el conjunto de datos de prueba/entrenamiento registrando toda la información anterior.
Finalmente, generaremos manifiestos de prueba/entrenamiento para registrar información, como la ubicación S3 del defecto sintético, la ubicación S3 de la máscara, la clase de defecto, el color de la máscara, etc.
Las siguientes son líneas json de muestra para una anomalía y una imagen normal en el manifiesto.
Por anomalía:
{"source-ref": "s3://qualityinspection/synthetic_defect/anomaly/train/6_im_mask_IC.jpg", "auto-label": 11, "auto-label-metadata": {"class-name": "anomaly", "type": "groundtruth/image-classification"}, "anomaly-mask-ref": "s3://qualityinspection/synthetic_defect/mask/MixMask/mask_IC.png", "anomaly-mask-ref-metadata": {"internal-color-map": {"0": {"class-name": "IC", "hex-color": "#2ca02c", "confidence": 0}}, "type": "groundtruth/semantic-segmentation"}}
Para imagen normal:
{"source-ref": "s3://qualityinspection/synthetic_defect/normal/train/25_im.jpg", "auto-label": 12, "auto-label-metadata": {"class-name": "normal", "type": "groundtruth/image-classification"}}
4.3.7 Estructura de carpetas de Amazon S3
La entrada y la salida del punto final se almacenan en el depósito de S3 de destino en la siguiente estructura:


5 Entrenamiento y resultado del modelo Lookout for Vision
5.1 Configure un proyecto, cargue un conjunto de datos y comience la capacitación del modelo.
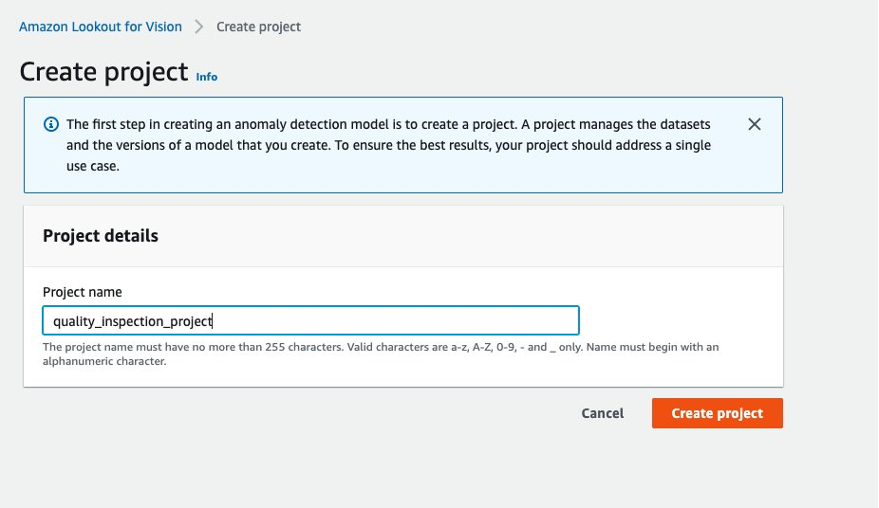
- Primero, puede ir a Lookout for Vision desde el AWS Console y crear un proyecto.
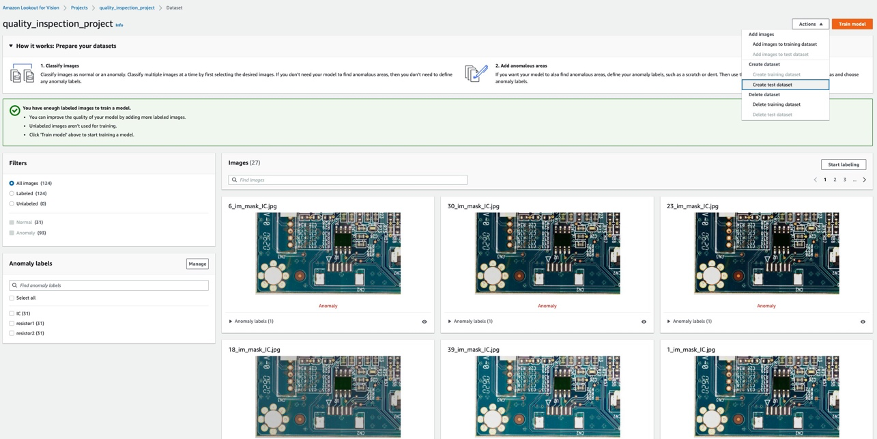
- Luego, puede crear un conjunto de datos de entrenamiento eligiendo Importe imágenes etiquetadas por SageMaker Ground Truth y proporcione la ubicación de Amazon S3 del manifiesto del conjunto de datos del tren generado por el punto final de SageMaker.

- A continuación, puede crear un conjunto de datos de prueba eligiendo Importe imágenes etiquetadas por SageMaker Ground Truth de nuevo y proporcione la ubicación de Amazon S3 del manifiesto del conjunto de datos de prueba generado por el punto final de SageMaker.
.......
:
- Después de que los conjuntos de datos de entrenamiento y prueba se carguen correctamente, puede seleccionar el Modelo de tren en la esquina superior derecha para activar el entrenamiento del modelo de localización de anomalías.
......
- En nuestro experimento, el modelo tardó un poco más de una hora en completar el entrenamiento. Cuando el estado muestra el entrenamiento completo, puede seleccionar el enlace del modelo para verificar el resultado.
:

5.2 Resultado del entrenamiento del modelo
5.2.1 Métricas de rendimiento del modelo
Después de seleccionar en el modelo 1 como se muestra arriba, podemos ver en la puntuación de 100 % de precisión, 100 % de recuperación y 100 % de F1 que el rendimiento del modelo es bastante bueno. También podemos comprobar el rendimiento por etiqueta (componente faltante) y estaremos encantados de descubrir que las puntuaciones F1 de las tres etiquetas están por encima del 93 % y que los IoU medios están por encima del 85 %. Este resultado es satisfactorio para este pequeño conjunto de datos que demostramos en la publicación.

5.2.2 Visualización de la detección de defectos sintéticos en el conjunto de datos de prueba.
Como muestra la siguiente imagen, cada imagen será defectuosa como un normal or anomaly etiqueta con una puntuación de confianza. Si es una anomalía, mostrará una máscara sobre el área anormal en la imagen con un color diferente para cada tipo de defecto.

El siguiente es un ejemplo de componentes faltantes combinados (tres defectos en este caso) en el conjunto de datos de prueba:

A continuación, puede compilar y empaquetar el modelo como un AWS IoT Greengrass componente siguiendo las instrucciones de esta publicación, Identifique la ubicación de las anomalías con Amazon Lookout for Vision en el perímetro sin usar una GPUy ejecutar inferencias en el modelo.
6. Pruebe el modelo Lookout for Vision entrenado en datos sintéticos contra defectos reales
Para probar si el modelo entrenado en el defecto sintético puede funcionar bien contra defectos reales, elegimos un conjunto de datos (conjunto de datos alienígenas) de esta página para ejecutar un experimento.
Primero, comparamos el defecto sintético generado y el defecto real. La imagen de la izquierda es un defecto real al que le falta la cabeza, y la imagen de la derecha es un defecto generado al que se le quitó la cabeza usando un modelo ML.

Defecto real
|

defecto sintético
|
En segundo lugar, usamos las detecciones de prueba en Lookout for Vision para probar el modelo contra el defecto real. Puede guardar las imágenes de prueba en el depósito S3 e importarlas desde Amazon S3 o cargar imágenes desde su computadora. Luego, seleccione Detecta anomalías para ejecutar la detección.
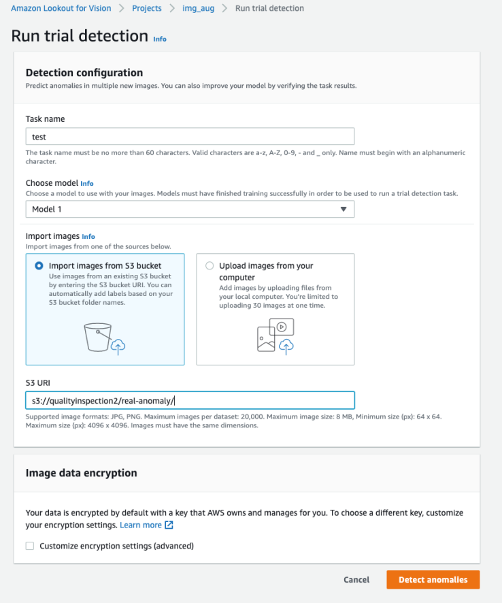
Finalmente, puede ver el resultado de la predicción del defecto real. El modelo entrenado en defectos sintéticos puede detectar el defecto real con precisión en este experimento.
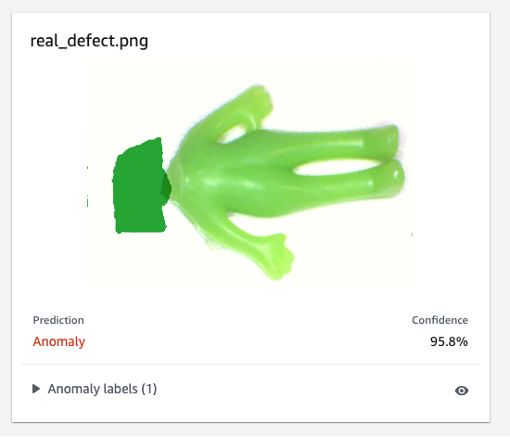
Es posible que el modelo entrenado en defectos sintéticos no siempre funcione bien en defectos reales, especialmente en placas de circuito que son mucho más complicadas que este conjunto de datos de muestra. Si desea volver a entrenar el modelo con defectos reales, puede seleccionar el botón naranja etiquetado Verifique las predicciones de la máquina en la esquina superior derecha del resultado de la predicción, y luego verifíquelo como Correcto or Incorrecto.
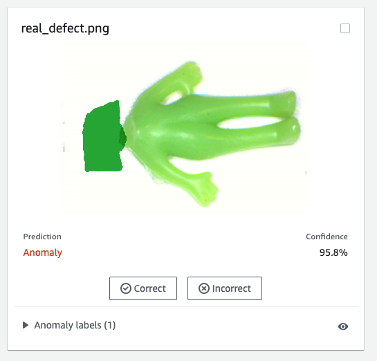
Luego, puede agregar la imagen y la etiqueta verificadas al conjunto de datos de entrenamiento seleccionando el botón naranja en la esquina superior derecha para mejorar el rendimiento del modelo.

7. Estimación de costos
Esta canalización de aumento de imágenes para Lookout for Vision es muy rentable. En el ejemplo que se muestra arriba, Amazon SageMaker Ground Truth Labeling, Amazon SageMaker notebook y SageMaker asynchronous endpoint deployment and inference solo cuestan unos pocos dólares. Para el servicio Lookout for Vision, solo paga por lo que usa. Hay tres componentes que determinan su factura: cargos por entrenar el modelo (horas de entrenamiento), cargos por detectar anomalías en la nube (horas de inferencia de la nube) y/o cargos por detectar anomalías en el borde (unidades de inferencia del borde). En nuestro experimento, el modelo Lookout for Vision tomó un poco más de una hora para completar el entrenamiento y costó $2.00 por hora de entrenamiento. Además, puede usar el modelo entrenado para la inferencia en la nube o en el borde con el precio indicado esta página.
8. Limpiar
Para evitar incurrir en cargos innecesarios, use la Consola para eliminar los puntos finales y los recursos que creó mientras ejecutaba los ejercicios en la publicación.
- Abra la consola de SageMaker y elimine los siguientes recursos:
- El punto final. Al eliminar el punto final, también se elimina la instancia informática de ML o las instancias que la admiten.
- under Inferencia, escoger Endpoints.
- Elija el punto final que creó en el ejemplo, elija Accionesy luego elige Borrar.
- La configuración del punto final.
- under Inferencia, escoger Configuraciones de punto final.
- Elija la configuración de punto final que creó en el ejemplo, elija Accionesy luego elige Borrar.
- El modelo.
- under Inferencia, escoger fexibles.
- Elija el modelo que creó en el ejemplo, elija Accionesy luego elige Borrar.
- La instancia del cuaderno. Antes de eliminar la instancia del cuaderno, deténgala.
- under Notebook, escoger Instancias de cuaderno.
- Elija la instancia del cuaderno que creó en el ejemplo, elija Accionesy luego elige Detener. La instancia del cuaderno tarda varios minutos en detenerse. Cuando el Estado cambios a Detenido, continúe con el siguiente paso.
- Elige Accionesy luego elige Borrar.
- Abra la Consola de Amazon S3y, a continuación, elimine el depósito que creó para almacenar los artefactos del modelo y el conjunto de datos de entrenamiento.
- Abra la Consola de Amazon CloudWatchy, a continuación, elimine todos los grupos de registro cuyos nombres empiecen por
/aws/sagemaker/.
También puede eliminar el punto final del cuaderno de SageMaker ejecutando el siguiente código:
import boto3
sm_boto3 = boto3.client("sagemaker")
sm_boto3.delete_endpoint(EndpointName='endpoint name')
9. Conclusión
En esta publicación, demostramos cómo anotar máscaras de defectos sintéticos con Amazon SageMaker Ground Truth, cómo usar diferentes técnicas de aumento de imágenes para transformar una imagen normal en la cantidad deseada de imágenes normales, crear un punto de enlace asíncrono de SageMaker y preparar el archivo de entrada para el punto final, así como invocar el punto final. Por último, demostramos cómo usar el manifiesto de entrenamiento/prueba para entrenar un modelo de localización de anomalías de Lookout for Vision. Esta canalización propuesta se puede extender a otros modelos de ML para generar defectos sintéticos, y todo lo que necesita hacer es personalizar el modelo y el código de inferencia en el punto final de SageMaker.
Comience explorando Lookout for Vision para la inspección de calidad automatizada esta página.
Acerca de los autores
 kara yang es científico de datos en AWS Professional Services. Le apasiona ayudar a los clientes a lograr sus objetivos comerciales con los servicios en la nube de AWS y ha ayudado a las organizaciones a crear soluciones integrales de inteligencia artificial y aprendizaje automático en múltiples industrias, como la fabricación, la automoción, la sostenibilidad medioambiental y la industria aeroespacial.
kara yang es científico de datos en AWS Professional Services. Le apasiona ayudar a los clientes a lograr sus objetivos comerciales con los servicios en la nube de AWS y ha ayudado a las organizaciones a crear soluciones integrales de inteligencia artificial y aprendizaje automático en múltiples industrias, como la fabricación, la automoción, la sostenibilidad medioambiental y la industria aeroespacial.
 Octavi Obiols-Ventas es un científico computacional especializado en aprendizaje profundo (DL) y aprendizaje automático certificado como arquitecto asociado de soluciones. Con un amplio conocimiento tanto en la nube como en el borde, ayuda a acelerar los resultados comerciales mediante la creación de soluciones de IA de extremo a extremo. Octavi obtuvo su doctorado en ciencias computacionales en la Universidad de California, Irvine, donde impulsó lo último en algoritmos DL+HPC.
Octavi Obiols-Ventas es un científico computacional especializado en aprendizaje profundo (DL) y aprendizaje automático certificado como arquitecto asociado de soluciones. Con un amplio conocimiento tanto en la nube como en el borde, ayuda a acelerar los resultados comerciales mediante la creación de soluciones de IA de extremo a extremo. Octavi obtuvo su doctorado en ciencias computacionales en la Universidad de California, Irvine, donde impulsó lo último en algoritmos DL+HPC.
 Fabián Benítez-Quiroz es un científico de datos de IoT Edge en los servicios profesionales de AWS. Tiene un doctorado en visión artificial y reconocimiento de patrones de la Universidad Estatal de Ohio. Fabian está involucrado en ayudar a los clientes a ejecutar sus modelos de Machine Learning con baja latencia en dispositivos IoT y en la nube.
Fabián Benítez-Quiroz es un científico de datos de IoT Edge en los servicios profesionales de AWS. Tiene un doctorado en visión artificial y reconocimiento de patrones de la Universidad Estatal de Ohio. Fabian está involucrado en ayudar a los clientes a ejecutar sus modelos de Machine Learning con baja latencia en dispositivos IoT y en la nube.
 manish talreja es gerente principal de productos para soluciones de IoT en AWS. Le apasiona ayudar a los clientes a crear soluciones innovadoras utilizando los servicios de AWS IoT y ML en la nube y en el perímetro.
manish talreja es gerente principal de productos para soluciones de IoT en AWS. Le apasiona ayudar a los clientes a crear soluciones innovadoras utilizando los servicios de AWS IoT y ML en la nube y en el perímetro.
 Yuxin Yang es arquitecto de AI/ML en AWS, certificado en la especialidad de aprendizaje automático de AWS. Ella permite a los clientes acelerar sus resultados mediante la creación de soluciones integrales de IA/ML, incluido el mantenimiento predictivo, la visión por computadora y el aprendizaje reforzado. Yuxin obtuvo su maestría en la Universidad de Stanford, donde se centró en el aprendizaje profundo y el análisis de big data.
Yuxin Yang es arquitecto de AI/ML en AWS, certificado en la especialidad de aprendizaje automático de AWS. Ella permite a los clientes acelerar sus resultados mediante la creación de soluciones integrales de IA/ML, incluido el mantenimiento predictivo, la visión por computadora y el aprendizaje reforzado. Yuxin obtuvo su maestría en la Universidad de Stanford, donde se centró en el aprendizaje profundo y el análisis de big data.
 Yingmao Timothy Li es un científico de datos con AWS. Se unió a AWS hace 11 meses y trabaja con una amplia gama de servicios y tecnologías de aprendizaje automático para crear soluciones para un conjunto diverso de clientes. Tiene un doctorado en Ingeniería Eléctrica. En su tiempo libre, disfruta de los juegos al aire libre, las carreras de autos, la natación y volar en un cachorro de gaitero para cruzar el país y explorar el cielo.
Yingmao Timothy Li es un científico de datos con AWS. Se unió a AWS hace 11 meses y trabaja con una amplia gama de servicios y tecnologías de aprendizaje automático para crear soluciones para un conjunto diverso de clientes. Tiene un doctorado en Ingeniería Eléctrica. En su tiempo libre, disfruta de los juegos al aire libre, las carreras de autos, la natación y volar en un cachorro de gaitero para cruzar el país y explorar el cielo.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/image-augmentation-pipeline-for-amazon-lookout-for-vision/

