
YOLO, acrónimo de 'You only look once', es una herramienta de software de código abierto que se utiliza por su capacidad eficiente de detectar objetos en una imagen dada en tiempo real. El algoritmo YOLO utiliza modelos de redes neuronales convolucionales (CNN) para detectar objetos en una imagen.
El algoritmo requiere solo una propagación hacia adelante a través de una red neuronal dada para detectar todos los objetos en la imagen. Esto le da al algoritmo YOLO una ventaja en velocidad sobre otros, lo que lo convierte en uno de los algoritmos de detección más conocidos hasta la fecha.
Un algoritmo de detección de objetos es un algoritmo que es capaz de detectar ciertos objetos o formas en un marco dado. Por ejemplo, los algoritmos de detección simples pueden detectar e identificar formas en una imagen, como círculos o cuadrados, mientras que los algoritmos de detección más avanzados pueden detectar objetos más complejos, como humanos, bicicletas, automóviles, etc.
El algoritmo YOLO no solo ofrece alta velocidad de detección y rendimiento a través de su capacidad de propagación hacia adelante, sino que también los detecta con gran exactitud y precisión.
En este tutorial, nos centraremos en YOLOv5, que es la quinta y última versión del software YOLO. Se lanzó originalmente el 18 de mayo de 2020. El código fuente abierto de YOLO se puede encontrar en GitHub. Usaremos YOLO con la conocida biblioteca PyTorch.
PyTorch es un paquete de código abierto de aprendizaje profundo que se basa en la conocida biblioteca Torch. También es una biblioteca basada en Python que se usa más comúnmente para el procesamiento del lenguaje natural y la visión por computadora.
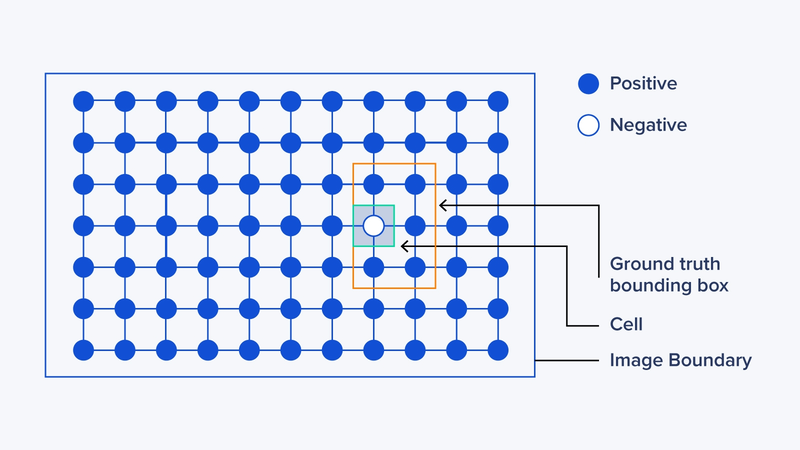
Paso 1: Bloques residuales (dividir la imagen en cuadros más pequeños en forma de cuadrícula)
En este paso, el cuadro completo (entero) se divide en cuadros o cuadrículas más pequeñas.
Todas las cuadrículas se dibujan sobre la imagen original y comparten la forma y el tamaño exactos. La idea detrás de estas divisiones es que cada cuadro de cuadrícula detecte los diferentes objetos dentro de él.
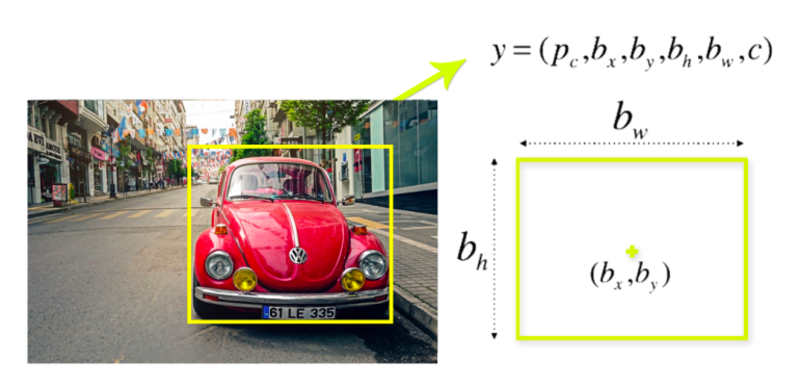
Paso 2: regresión del cuadro delimitador (identificación del objeto dentro de un cuadro delimitador)
Después de detectar un objeto determinado en una imagen, se dibuja un cuadro delimitador que lo rodea. El cuadro delimitador tiene parámetros como el punto central, alto, ancho y clase (tipo de objeto detectado).
Paso 3: Intersección sobre unión (IOU)
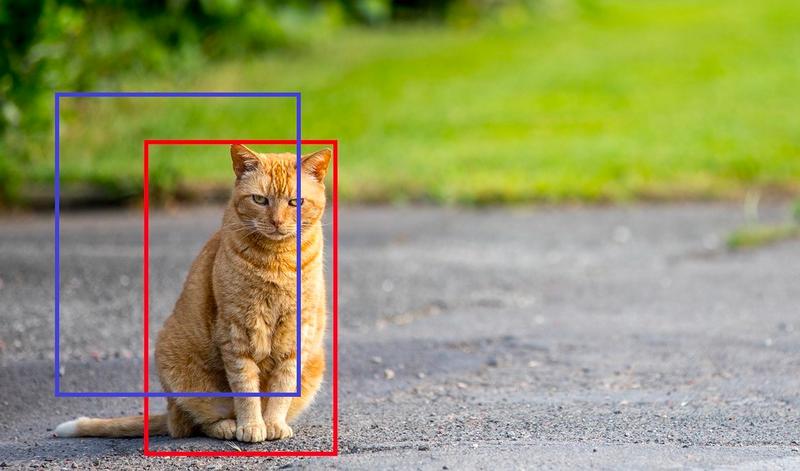
El Pagarés , corto para intersección sobre unión, se utiliza para calcular la precisión de nuestro modelo. Esto se logra cuantificando el grado de intersección de dos cuadros que son el cuadro de valor real (cuadro rojo en la imagen) y el cuadro devuelto por nuestro resultado (cuadro azul en la imagen).
En la parte del tutorial de este artículo, identificamos nuestro valor IOU como 40 por ciento, lo que significa que si la intersección de las dos casillas está por debajo del 40 por ciento, esta predicción no debe tenerse en cuenta. Esto se hace para ayudarnos a calcular la precisión de nuestras predicciones.
A continuación se muestra una imagen que muestra el proceso completo del algoritmo de detección de YOLO

Para obtener información adicional sobre cómo funciona el algoritmo YOLO, consulte el Introducción al algoritmo YOLO.
El objetivo principal del ejemplo de este tutorial es utilizar el algoritmo YOLO para detectar una lista de enfermedades del tórax en una imagen determinada. Al igual que con cualquier modelo de aprendizaje automático, ejecutaremos el nuestro utilizando miles de imágenes escaneadas en el pecho. El objetivo es que el algoritmo YOLO detecte con éxito todas las lesiones en la imagen dada.
Conjunto de datos
El Conjunto de datos de imágenes VinBigData 512 utilizado en este tutorial se puede encontrar en Kaggle. El conjunto de datos se divide en dos partes, los conjuntos de datos de entrenamiento y de prueba. El conjunto de datos de entrenamiento contiene 15,000 3,000 imágenes, mientras que el conjunto de datos de prueba contiene 4. Esta división de datos entre el entrenamiento y la prueba es de alguna manera óptima ya que el conjunto de datos de entrenamiento suele ser de 5 a XNUMX veces el tamaño del conjunto de datos de prueba.
La otra parte del conjunto de datos contiene la etiqueta de todas las imágenes. Dentro de este conjunto de datos, cada imagen está etiquetada con un nombre de clase (enfermedad torácica encontrada), junto con el ID de clase, el ancho y el alto de la imagen, etc. Consulte la imagen a continuación para ver todas las columnas disponibles.
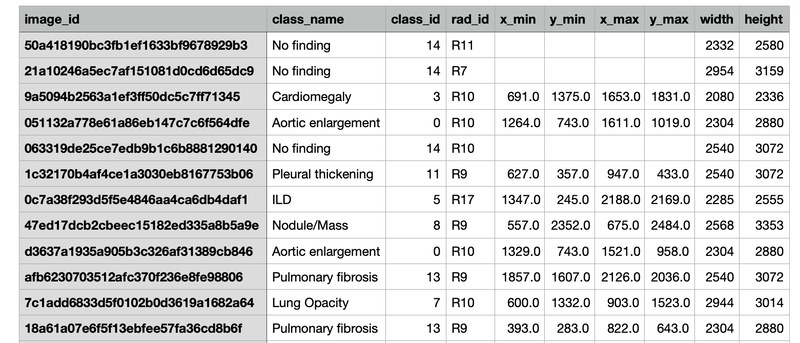
Nota: Puede ver el código original utilizado en este ejemplo en Kaggle.
Paso 1: Importación de las bibliotecas necesarias
Para empezar, importaremos las bibliotecas y los paquetes necesarios al principio de nuestro código. Primero, expliquemos algunas de las bibliotecas más comunes que acabamos de importar. NumPy es una biblioteca Python numérica de código abierto que permite a los usuarios crear matrices y realizar una serie de operaciones matemáticas en ellas.
import pandas as pd
import os
import numpy as np
import shutil
import ast
from sklearn import model_selection
from tqdm import tqdm
import wandb
from sklearn.model_selection import GroupKFold
from IPython.display import Image, clear_output # to display images
from os import listdir
from os.path import isfile
from glob import glob
import yaml
# clear_output()
Paso 2: Definiendo Nuestros Caminos
Para facilitarnos la vida, comenzaremos definiendo las rutas directas a las etiquetas y las imágenes de los conjuntos de datos de entrenamiento y prueba.
TRAIN_LABELS_PATH = './vinbigdata/labels/train'
VAL_LABELS_PATH = './vinbigdata/labels/val'
TRAIN_IMAGES_PATH = './vinbigdata/images/train' #12000
VAL_IMAGES_PATH = './vinbigdata/images/val' #3000
External_DIR = '../input/vinbigdata-512-image-dataset/vinbigdata/train' # 15000
os.makedirs(TRAIN_LABELS_PATH, exist_ok = True)
os.makedirs(VAL_LABELS_PATH, exist_ok = True)
os.makedirs(TRAIN_IMAGES_PATH, exist_ok = True)
os.makedirs(VAL_IMAGES_PATH, exist_ok = True)
size = 51
Paso 3: Importación y lectura del conjunto de datos textuales
Aquí importaremos y leeremos el conjunto de datos textuales. Estos datos se almacenan como filas y columnas en un formato de archivo CSV.
df = pd.read_csv('../input/vinbigdata-512-image-dataset/vinbigdata/train.csv')
df.head()
Nota: la función df.head() imprime las primeras 5 filas del conjunto de datos dado.
Paso 4: filtrado y limpieza del conjunto de datos
Como ningún conjunto de datos es perfecto, la mayoría de las veces es necesario un proceso de filtrado para optimizar un conjunto de datos, optimizando así el rendimiento de nuestro modelo. En este paso, eliminaríamos cualquier fila con una identificación de clase que sea igual a 14.
Esta identificación de clase representa un no hallazgo en la clase de enfermedad. La razón por la que descartamos esta clase es que puede confundir nuestro modelo. Además, lo ralentizará porque nuestro conjunto de datos será un poco más grande.
df = df[df.class_id!=14].reset_index(drop = True)
Paso 5: Cálculo de las coordenadas del cuadro delimitador para YOLO
Como se mencionó anteriormente en el Sección 'Cómo funciona el algoritmo de YOLO' (particularmente los pasos 1 y 2), el algoritmo YOLO espera que el conjunto de datos esté en un formato determinado. Aquí revisaremos el marco de datos y aplicaremos algunas transformaciones.
El objetivo final del siguiente código es calcular las nuevas dimensiones x-mid, y-mid, ancho y alto para cada punto de datos.
df['x_min'] = df.apply(lambda row: (row.x_min)/row.width, axis = 1)*float(size)
df['y_min'] = df.apply(lambda row: (row.y_min)/row.height, axis = 1)*float(size)
df['x_max'] = df.apply(lambda row: (row.x_max)/row.width, axis =1)*float(size)
df['y_max'] = df.apply(lambda row: (row.y_max)/row.height, axis =1)*float(size) df['x_mid'] = df.apply(lambda row: (row.x_max+row.x_min)/2, axis =1)
df['y_mid'] = df.apply(lambda row: (row.y_max+row.y_min)/2, axis =1) df['w'] = df.apply(lambda row: (row.x_max-row.x_min), axis =1)
df['h'] = df.apply(lambda row: (row.y_max-row.y_min), axis =1) df['x_mid'] /= float(size)
df['y_mid'] /= float(size) df['w'] /= float(size)
df['h'] /= float(size)
Paso 6: cambiar el formato de datos proporcionado
En esta parte del código, cambiaremos el formato de datos dado de todas las filas del conjunto de datos en las siguientes columnas; .Esto es necesario ya que el algoritmo YOLOv5 solo puede leer los datos en este formato específico.
def preproccess_data(df, labels_path, images_path): for column, row in tqdm(df.iterrows(), total=len(df)): attributes = row[ ["class_id", "x_mid", "y_mid", "w", "h"] ].values attributes = np.array(attributes) np.savetxt( os.path.join(labels_path, f"{row['image_id']}.txt"), [attributes], fmt=["%d", "%f", "%f", "%f", "%f"], ) shutil.copy( os.path.join( "/kaggle/input/vinbigdata-512-image-dataset/vinbigdata/train", f"{row['image_id']}.png", ), images_path, )
Luego ejecutaremos la función preproccess_data dos veces, una con el conjunto de datos de entrenamiento y sus imágenes, y la segunda con el conjunto de datos de prueba y sus imágenes.
preproccess_data(df, TRAIN_LABELS_PATH, TRAIN_IMAGES_PATH)
preproccess_data(val_df, VAL_LABELS_PATH, VAL_IMAGES_PATH)
Usando la línea a continuación, clonaremos el algoritmo YOLOv5 en nuestro modelo.
!git clone https://github.com/ultralytics/yolov5.git
Paso 7: Definiendo las Clases de nuestro Modelo
Aquí definiremos las 14 enfermedades torácicas disponibles en nuestros modelos como clases. Estas son las enfermedades reales que se pueden identificar en las imágenes del conjunto de datos.
classes = [ 'Aortic enlargement', 'Atelectasis', 'Calcification', 'Cardiomegaly', 'Consolidation', 'ILD', 'Infiltration', 'Lung Opacity', 'Nodule/Mass', 'Other lesion', 'Pleural effusion', 'Pleural thickening', 'Pneumothorax', 'Pulmonary fibrosis'] data = dict( train = '../vinbigdata/images/train', val = '../vinbigdata/images/val', nc = 14, names = classes ) with open('./yolov5/vinbigdata.yaml', 'w') as outfile: yaml.dump(data, outfile, default_flow_style=False) f = open('./yolov5/vinbigdata.yaml', 'r')
print('nyaml:')
print(f.read())
Paso 8: Entrenamiento del modelo
Para empezar, abriremos el directorio YOLOv5. Luego usaremos pip para instalar todas las bibliotecas escritas dentro del archivo de requisitos.
El archivo de requisitos contiene todas las bibliotecas requeridas que el código base necesita para funcionar. También instalaremos otras bibliotecas como pycocotools, seaborn y pandas.
%cd ./yolov5
!pip install -U -r requirements.txt
!pip install pycocotools>=2.0 seaborn>=0.11.0 pandas thop
clear_output()
Wandb, abreviatura de pesos y sesgos, nos permite monitorear un modelo de red neuronal dado.
# b39dd18eed49a73a53fccd7b684ea7ecaed75b08
wandb.login()
Ahora entrenaremos el YOLOv5 en el conjunto vinbigdata provisto para 100 épocas. También pasaremos algunas otras banderas como –img 512 que le dice al modelo que el tamaño de nuestra imagen es de 512 píxeles, –batch 16 permitirá que nuestro modelo tome 16 imágenes por lote. Usando el indicador –data ./vinbigdata.yaml, pasaremos nuestro conjunto de datos, que es el conjunto de datos vinbigdata.yaml.
!python train.py --img 512 --batch 16 --epochs 100 --data ./vinbigdata.yaml --cfg models/yolov5x.yaml --weights yolov5x.pt --cache --name vin
Paso 9: Evaluación del modelo
Primero, identificaremos el directorio del conjunto de datos de prueba junto con el directorio de pesos.
test_dir = ( f"/kaggle/input/vinbigdata-{size}-image-dataset/vinbigdata/test"
)
weights_dir = "./runs/train/vin3/weights/best.pt"
os.listdir("./runs/train/vin3/weights")
En esta parte, usaremos detect.py como nuestra inferencia para verificar la precisión de nuestras predicciones. También pasaremos algunas banderas como –conf 0.15 que es el umbral de confianza del modelo. Si la tasa de confianza de un objeto detectado es inferior al 15 por ciento, elimínelo de nuestra salida. El indicador –iou 0.4 informa a nuestro modelo que si la intersección sobre la unión de dos cajas está por debajo del 40 por ciento, entonces debe eliminarse.
!python detect.py --weights $weights_dir
--img 512
--conf 0.15
--iou 0.4
--source $test_dir
--save-txt --save-conf --exist-ok
En este artículo explicamos qué es YOLOv5 y cómo funciona el algoritmo básico de YOLO. A continuación, pasamos a explicar brevemente PyTorch. Luego cubrimos un par de razones por las que debería usar YOLO sobre otros algoritmos de detección similares.
Finalmente, lo guiamos a través de un modelo de aprendizaje automático que es capaz de detectar enfermedades del tórax en imágenes de rayos X. En este ejemplo, usamos YOLO como nuestro principal algoritmo de detección para encontrar y localizar lesiones torácicas. Luego clasificamos cada lesión en una clase o enfermedad determinada.
Si está interesado en el aprendizaje automático y en la creación de sus propios modelos, especialmente modelos que requieren la detección de múltiples objetos en una imagen o representación de video determinada, definitivamente vale la pena probar YOLOv5.
kevin vu administra el blog de Exxact Corp y trabaja con muchos de sus talentosos autores que escriben sobre diferentes aspectos del Deep Learning.
Original. Publicado de nuevo con permiso.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2022/12/yolov5-pytorch-tutorial.html?utm_source=rss&utm_medium=rss&utm_campaign=yolov5-pytorch-tutorial

