Introducción
Crear un buen currículum siempre ha motivado a todos los estudiantes a ser contratados por la empresa de sus sueños. Miles de personas de varias plataformas como Linkedin, naukri.com, etc., comienzan a postularse a medida que la empresa inicia su proceso de reclutamiento. Es muy imposible, por supuesto, entrevistar a todos los que se postulan. Aquí viene la inteligencia artificial evaluador de currículum (Palabra2Vec) para identificar buenos currículos y preseleccionarlos para entrevistas.
Después de limpiar los datos con PNL métodos como la tokenización y la eliminación de palabras vacías, utilicé Word2Vec de gensim para incrustaciones de palabras. Usando estas incrustaciones de palabras, el algoritmo K-Means se usa para generar K Clusters. Algunos de los grupos de esta lista contienen habilidades (técnicas, no tecnológicas y blandas).

OBJETIVOS DE APRENDIZAJE
En este artículo, usted-
- Identifique el diseño del currículum y determine el flujo de contenido.
- Más información sobre Word2vec
- ¿Cómo ayuda Word2Vec a extraer habilidades de los currículos?
Índice del contenido
- Enfoque de diccionario para la selección de currículums
- ¿Qué es Word2Vec?
- ¿Cómo es eficaz Word2Vec para la combinación de habilidades?
3.1 Entrenando el modelo word2vec
3.2 Leer el currículum y realizar la tokenización
3.3 Encontrar las similitudes entre las habilidades de JD y los tokens de currículum. - Inconvenientes de la combinación de habilidades de Word2Vec
- Guión
- Conclusión
Enfoque de diccionario para la selección de currículums
Un evaluador de currículum generalmente incluye los siguientes pasos:
- Currículum de lectura
- Clasificación de diseño
- Identificar el diseño del currículum es esencial, ya que determina el flujo de contenido dentro del currículum.
- Segmentación de secciones
- Identificar los encabezados de las secciones y segmentar el currículum usando estos encabezados como Cualificación educativa, Experiencia laboral, secciones de Conjunto de habilidades, etc.
- Extracción de información Incluye
- Detalles principales del candidato
- Conjunto de habilidades
- Detalles academicos
- Experiencia laboral
- Designación de empresa y trabajo
- Localización del empleo
La extracción del conjunto de habilidades incluye identificar las habilidades técnicas presentes en el currículum y relacionarlas con las habilidades obligatorias de JD. La forma más sencilla de extracción es comprobando su presencia en el diccionario de habilidades técnicas en el backend. Por lo general, JD tiene dominios especificados como habilidades y, por lo tanto, las habilidades en el diccionario deben asignarse a su dominio.

¿Qué pasa si las habilidades mencionadas en el currículum no están en el diccionario? ¿Qué sucede si una habilidad de currículum no está asignada a su dominio? ¡Simple, el currículum será rechazado!
Para resolver este problema, en lugar de verificar la presencia de una habilidad en el diccionario, será más eficiente verificar la presencia de una habilidad o sus habilidades relevantes. En este artículo, se introdujo una arquitectura de aprendizaje profundo para hacer coincidir las habilidades de currículum con las habilidades de JD de manera eficiente.
¿Qué es Word2Vec?
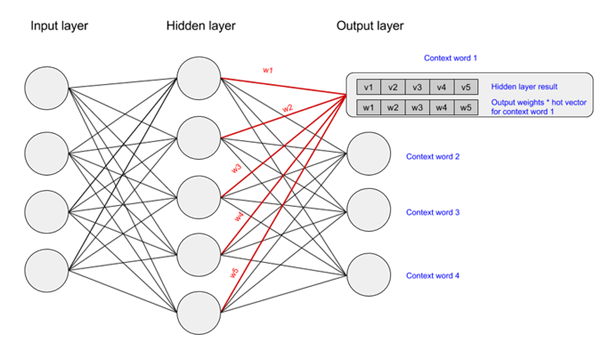
Palabra2Vec es una de las incrustación de palabras arquitecturas para transformar texto en números, es decir, un vector. Word2Vec se diferencia de otras técnicas de representación como BOW, codificación One-Hot, TF-IDF, etc., ya que captura las relaciones semánticas y sintácticas entre palabras utilizando una red neuronal simple con una capa oculta.. En resumen, las palabras que están relacionadas se colocarán cerca unas de otras en el espacio vectorial. Los pesos obtenidos en la capa oculta tras la convergencia del modelo son las incrustaciones. Entonces, usando word2vec, podemos realizar tareas como la próxima palabra/predicción de palabras basadas en las dos arquitecturas diferentes de Word2Vec
- Bolsa continua de palabras
Dada una secuencia de palabras, es decir, palabras de contexto, predice una palabra que es muy probable que ocurra a continuación. - saltar gramo
Funciona exactamente de manera opuesta a CBOW, al que se le da la palabra, predice las siguientes t palabras de contexto.
Haga clic en este enlace para saber más sobre Word2Vec
¿Cómo es eficaz Word2Vec para la combinación de habilidades?
¿Cómo es útil word2vec para hacer coincidir currículum habilidades con JD? La solución son solo tres simples pasos:
- Entrenamiento del modelo word2vec
- Leer el currículum y realizar la tokenización
- Encontrar las similitudes entre las habilidades de JD y los tokens de currículum.
Entrenamiento del modelo word2vec
- Nota: nuestra implementación se limita solo a los currículums de ciencia de datos. Se puede generalizar aún más mejorando los datos.
Importación de todas las bibliotecas necesarias
importar gensim de gensim.models.phrases importar frases, frases de gensim.models importar Word2Vec importar pandas como pd importar joblib
Recopilación de datos:
-
- Raspado web
- Los datos se recopilan extrayendo datos de varios sitios web relacionados con la ciencia de datos, libros electrónicos, etc., utilizando la sopa hermosa de python.
- Preprocesamiento de datos
- Conversión de minúsculas
- Eliminación de números
- Eliminación de palabras vacías
- Raspado web
No se realizan derivaciones ni lematizaciones para evitar la pérdida de vocabulario. Por ejemplo, cuando "Aprendizaje automático" se deriva o se lematiza, las palabras "máquina" y "aprendizaje" se derivan o se lematizan por separado. Por lo tanto, da como resultado un "aprendizaje automático" y, por lo tanto, una pérdida de habilidad.
Aquí están nuestros datos de muestra
Creación de palabras n-gram utilizando la clase de frases de gensim. Los datos se pasan a la clase de frases y devuelven un objeto. El objeto devuelto se puede guardar localmente y utilizar cuando sea necesario.
df=pd.read_csv('/content/data_100.csv') enviado = [row.split() for row in df['data']] frases = Frases(enviado, min_count=30, progreso_per=10000) frases=frases [enviado]
Más sobre la biblioteca gensim
Construcción de vocabulario usando la biblioteca Gensim:
Word2Vec requiere que construyamos la tabla de vocabulario (simplemente digiriendo todas las palabras, filtrando las palabras únicas/ y haciendo algunos recuentos básicos sobre ellas).
Entrenamiento del modelo:
El modelo word2vec se entrena con la biblioteca gensim y se guarda localmente para usarlo cuando sea necesario.
w2v_model = Word2Vec(min_count=20, window=3, size=300, sample=6e-5, alpha=0.03, min_alpha=0.0007, negative=20 ) #Construyendo vocabulario w2v_model.build_vocab(frases) #Guardando el vocabulario construido localmente w2v_model .wv.vocab.keys().to_csv('vocabulary.csv') #Entrenamiento del modelo w2v_model.train(sentences, total_examples = w2v_model.corpus_count, epochs = 30, report_delay = 1) #guardando la ruta del modelo = "/content /drive/MyDrive" model = joblib.load(path) print(w2v_model.wv.similarity('neural_network', 'machine_learning'))
Salida:
0.65735245
Leer el currículum y realizar la tokenización
leyendo un currículum
Un currículum puede tener diferentes formas, como pdf, docx, imagen, etc. Se utilizan diferentes herramientas para extraer información de diferentes formas de currículum.
PDF – usando pdfplomber
Imagen – usando OCR
Preparación de datos
Después de extraer los datos, el siguiente paso es el preprocesamiento, la creación de n-gramas y la tokenización.
Encontrar las similitudes entre las habilidades de JD y los tokens de currículum
Aquí viene el paso final. Después de realizar los dos primeros pasos, obtenemos lo siguiente
- Modelo Word2vec/incrustaciones de palabras
- Objeto de frases
- Vocabulario de datos
- fichas de currículum
Las habilidades de JD se ingresan manualmente. Ahora, necesitamos encontrar la similitud entre las habilidades de JD y los tokens de currículum; si una habilidad JD tiene al menos una habilidad relevante en los tokens de currículum, entonces se considerará como "presente" en el currículum, de lo contrario, "ausente" en el currículum.
¿Cómo verificar las habilidades relevantes? La respuesta es la similitud del coseno. La habilidad se considera relevante si la similitud del coseno entre las dos incrustaciones es inferior a un cierto umbral.
Creamos dos matrices de incrustaciones de habilidades JD y reanudamos las incrustaciones de tokens para encontrar el numerador de la similitud del coseno de todas las incrustaciones simultáneamente, es decir, AB
Inconvenientes de Word2Vec para la combinación de habilidades
¿Qué pasa si una habilidad JD no está presente en el vocabulario que se usó para construir el modelo? El modelo no tendrá su incrustación; tales palabras se eliminan de las palabras del vocabulario. Este es un gran inconveniente de word2vec. Incrustaciones a nivel de personaje se podría hacer para solucionar este problema. Texto rápido funciona en incrustaciones a nivel de personaje.
La principal diferencia entre Word2Vec y FastText es que Word2Vec introduce palabras individuales en la red neuronal para encontrar las incrustaciones, mientras que FastText divide las palabras en varios n-gramas (sub-palabras). El vector de incrustación de palabras para una palabra será la suma de todos los n-gramas.
Guión
Instalación de paquetes necesarios
!pip install pdfplumber !pip install pytesseract !sudo apt install tesseract-ocr !pip install pdf2image !sudo apt-get update !sudo apt-get install python-poppler !pip install PyMuPDF !pip install Aspose.Email-for-Python-via -NET !pip instalar aspose-palabras
Importación de bibliotecas necesarias
importar pandas como pd importar os importar advertencias advertencias.filterwarnings(acción = 'ignorar') importar gensim de gensim.models importar Word2Vec importar cadena importar numpy como np de itertools importar groupby, contar importar re importar subproceso importar os.path importar sys importar registro import joblib de gensim.models.phrases import Phrases, Phraser import pytesseract import cv2 from pdf2image import convert_from_path from PIL import Image Image.MAX_IMAGE_PIXELS = 1000000000 import aspose.words as aw import fitz logger_watchtower = logging.getLogger(__name__) from pandas.core. common import SettingWithCopyWarning advertencias.simplefilter(action="ignorar", categoría=SettingWithCopyWarning)
Función para leer currículum
def _skills_in_box(image_gray,threshold=60): ''' Función para identificar casillas e identificar habilidades en ellas: dada una ruta de imagen, devuelve una cadena con texto. Parámetros: img_path: Ruta de la imagen thresh : Umbral de la caja para convertirla a 0 ''' img = image_gray.copy() thresh_inv = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)[ 1] # Desenfocar la imagen blur = cv2.GaussianBlur(thresh_inv,(1,1),0) thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)[1] # encontrar contornos contornos = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[0] mask = np.ones(img.shape[:2], dtype="uint8") * 255 disponible = 0 para c en contornos: # obtener el delimitando rect x, y, w, h = cv2.boundingRect(c) si w*h>1000: cv2.rectangle(mask, (x+5, y+5), (x+w-5, y+h- 5), (0, 0, 255), -1) disponible = 1 res = '' si disponible == 1: res_final = cv2.bitwise_and(img, img, mask=cv2.bitwise_not(mask)) res_final[res_final< =umbral]=0 kernel = np.array([[0, -1, 0], [-1, 5,-1], [0, -1, 0]]) res_fin = cv2.filter2D(src=res_final , d depth=-1, kernel=kernel) vt = pytesseract.image_to_data(255-res_final,output_type='data.frame') vt = vt[vt.con f != -1] res = '' for i in vt[vt['conf']>=43]['text']: res = res + str(i) + ' ' print(res) return res def _image_to_string (img): ''' Función para convertir imágenes a escala de grises y convertir a texto: Dada una ruta de imagen, devuelve texto en ella. Parámetros: img_path: Ruta de la imagen ''' img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) res = '' string1 = pytesseract.image_to_data(img,output_type='data.frame') string1 = string1[string1[' conf'] != -1] for i in string1[string1['conf']>=43]['text']: res = res + str(i) + ' ' string3 = _skills_in_box(img) return res+string3 def _pdf_to_png(pdf_path): ''' Función para convertir pdf a imagen y guardarlo en una carpeta y convertir la imagen en cadena Parámetro: pdf_path: Ruta del pdf ''' string = '' images = convert_from_path(pdf_path) for j in tqdm(range(len(images))): # Guardar páginas como imágenes en el pdf image = np.array(images[j]) string += _image_to_string(image) string += 'n' return string def ocr(paths ): ''' Función para verificar si el pdf es una imagen o no. Si el archivo está en .doc lo convierte a .pdf si el pdf está en formato de imagen la función convierte .pdf a .png Parámetro: rutas: lista que contiene las rutas de todos los archivos pdf ''' text = "" res = "" intente: doc = fitz.open(rutas) for page in doc: text += page.get_text() if len(text) <=10 : res = _pdf_to_png(paths) else: res = text excepto: doc = aw.Document (rutas) doc.save("Documento.pdf") doc = fitz.open("Documento.pdf") for page in doc: text += page.get_text() if len(text) <=10 : res = _pdf_to_png ("Documento.pdf") else: res = text os.remove("Documento.pdf") return res
Función para encontrar la similitud del coseno
def to_la(L): k=lista(L) l=np.array(k) return l.reformar(-1, 1) def cos(A, B): dot_prod=np.matmul(A,BT) norm_a= np.recíproco(np.sum(np.abs(A)**2,eje=-1)**(1./2)) norm_b=np.recíproco(np.sum(np.abs(B)** 2,eje=-1)**(1./2)) norma_a=a_la(norma_a) norma_b=a_la(norma_b) k=np.matmul(norma_a,norma_b.T) lista de retorno(np.multiply(punto_prod,k ))
Función para encontrar las similitudes y devolver las habilidades coincidentes finales
def comprobar(ruta,habilidades,l2,w2v_modelo1,frases,patrón): texto = ocr(ruta) texto = re.sub(r'[^x00-x7f]',r' ',texto) texto = texto.inferior( ) texto = re.sub("\|,|/|:|)|("," ",texto) t2 = texto.split() l_2=l2.copy() match=list(set(re.findall( patrón,texto))) oraciones=frases[t2] resume_skills_dict={} res_jdskill_intersect=list(set(sentences).intersection(set(l_2))) if(len(match)!=0): for k in match: k =k.replace(' ','_') resume_skills_dict[k]=1 prueba: l_2.remove(k) excepto: continue l6=list(set(l_2).intersection(skills['0'])) l6_minus_skills= list(set(l_2).difference(skills['0'])) for i in l6_minus_skills: resume_skills_dict[i]=0 if(len(l6)==0): return resume_skills_dict l4=list(set(sentences). intersección(habilidades['0'])) arr1=np.array([w2v_model1[i] for i in l6]) arr2=np.array([w2v_model1[i] for i in l4]) similarity_values=cos(arr1, arr2) cuenta=0 para i en valores_similares: k=lista(filtro(lambda x: x<0.38, lista(i))) if(len(k)==len(i)): resume_skills_dict[l6[count]] =0 else: resume_skills=[s for s in range(len( i)) if(i[s])>0.38] resume_skills_dict[l6[count]]=1 count+=1 return resume_skills_dict
Funciones requeridas para realizar el preprocesamiento de habilidades de JD
def Convertir(cadena): li = lista(cadena.dividir()) volver lista(establecer(li)) def preprocesar(cadena): cadena = cadena.reemplazar(",",' ') cadena= cadena.reemplazar(" '",' ') cadena = Convertir(cadena) cadena de retorno
Función Principal
if __name__ == "__main__": #Arg 1 = vocabulario, Arg 2 = modelo, Arg 3 = objeto de frases, Arg 4 = Habilidades obligatorias de JD, Arg 5 = Ruta de currículum argv = sys.argv[1:] w2v_model1 = joblib. load(argv[0]) skills=pd.read_csv(argv[1]) asignador = {} guión bajo=[] jd_skills=argv[3] jd_skills=" ".join(jd_skills.strip().split()) jd_skills =jd_skills.replace(', ',',') patrón=jd_skills.replace(',','|').lower() para i en jd_skills.split(','): si '_' en i: guión bajo.append(i) mapeador[i.lower().replace('_',' ')] = i jd_skills=jd_skills.replace(' ','_') jd_skills=jd_skills.replace(',',' , ') for i in jd_skills.split(', '): if i not in underscore: if '_' in i: mapper[i.lower().replace('_',' ')] = i.replace ('_',' ') elif '-' in i: mapeador[i.inferior().replace('-',' ')] = i else: mapeador[i.inferior()] = i jd_skills=jd_skills .replace('-','_') frases=Frases.load(argv[2]) líneas = [preprocess(jd_skills.lower().rstrip())] frases=Frases.load(argv[2]) final_jd_skills =lista(conjunto(líneas[0]).intersección(habilidades['0'])) ruta = argv[4] res=check(ruta,habilidades,líneas[0],w2v_model1,frases,patrón) for dict in res: res_dict={} for i in dict.keys(): j=i.replace('_',' ') res_dict[asignador[j]] = dict[i] print('skills_matched:',res_dict)
Argumento de la línea de comandos
!python3 demo1.py '/content/drive/MyDrive/Skill_Matching_Files/Model(cbow).joblib' '/content/drive/MyDrive/Skill_Matching_Files/vocab_split.csv' '/content/drive/MyDrive/Skill_Matching_Files/phrases_split.pkl' 'julia, kaggle, ml, mysql, oracle, python, pytorch, r, scikit learn, copo de nieve, sql, tensorflow' '/content/drive/MyDrive/Skill_Matching_Files/TESTING RESUME/Copy of 0_A.a.aa.pdf'
Salida
skills_matched: {'python': 1, 'r': 1, 'oracle': 0, 'snowflake': 1, 'pytorch': 1, 'tensorflow': 1, 'ml': 1, 'sql': 1 , 'kaggle': 1, 'mysql': 1, 'julia': 1, 'aprender scikit': 1}
Conclusión
Espero que el artículo le haya brindado información sobre cómo extraer habilidades de los currículos. Aprendió cómo se utiliza la técnica de incrustación de palabras de Word2Vec para examinar los currículos de varias empresas en la industria de contratación y empresas.
Comente a continuación o conéctese conmigo en LinkedIn para enviar una consulta o comentario si tiene alguna duda.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/01/an-approach-to-extract-skills-from-resume-using-word2vec/

