Introducción
En el apasionante tema de la visión por computadora, donde las imágenes contienen muchos secretos e información, distinguir y resaltar elementos es crucial. La segmentación de imágenes, el proceso de dividir imágenes en regiones u objetos significativos, es esencial en varias aplicaciones que van desde imágenes médicas hasta conducción autónoma y reconocimiento de objetos. La segmentación precisa y automática ha sido un desafío durante mucho tiempo, y los enfoques tradicionales con frecuencia se quedan cortos en precisión y eficiencia. Entra en la arquitectura UNET, un método inteligente que ha revolucionado la segmentación de imágenes. Con su diseño simple y técnicas inventivas, UNET ha allanado el camino para resultados de segmentación más precisos y sólidos. Tanto si es un principiante en el apasionante campo de la visión artificial como si es un profesional experimentado que busca mejorar sus habilidades de segmentación, este artículo de blog en profundidad desentrañará las complejidades de UNET y proporcionará una comprensión completa de su arquitectura, componentes y utilidad.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Comprender la red neuronal de convolución
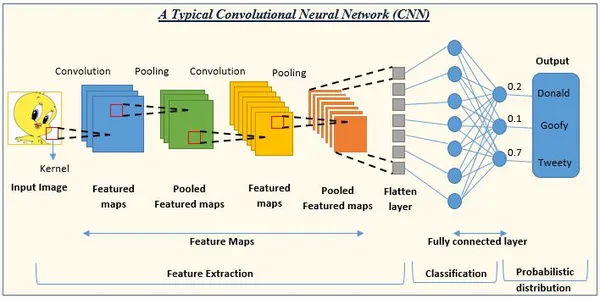
Las CNN son un modelo de aprendizaje profundo que se emplea con frecuencia en tareas de visión por computadora, incluida la clasificación de imágenes, el reconocimiento de objetos y la segmentación de imágenes. Las CNN son principalmente para aprender y extraer información relevante de las imágenes, lo que las hace extremadamente útiles en el análisis de datos visuales.
Los componentes críticos de las CNN
- Capas convolucionales: Las CNN comprenden una colección de filtros que se pueden aprender (núcleos) combinados con la imagen de entrada o los mapas de características. Cada filtro aplica multiplicaciones y sumas por elementos para producir un mapa de características que resalta patrones específicos o características locales en la entrada. Estos filtros pueden capturar muchos elementos visuales, como bordes, esquinas y texturas.
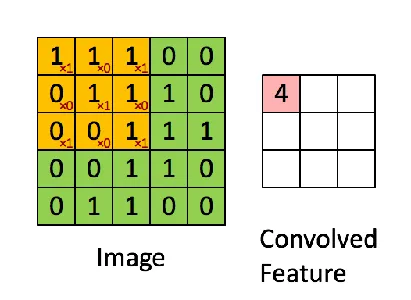
- Capas de agrupación: Cree los mapas de características mediante las capas convolucionales que se reducen mediante capas de agrupación. La agrupación reduce las dimensiones espaciales de los mapas de características al tiempo que mantiene la información más crítica, lo que reduce la complejidad computacional de las capas sucesivas y hace que el modelo sea más resistente a las fluctuaciones de entrada. La operación de agrupación más común es la agrupación máxima, que toma el valor más significativo dentro de un vecindario determinado.
- Funciones de activación: Introduzca la no linealidad en el modelo CNN utilizando funciones de activación. Aplíquelos a las salidas de capas convolucionales o de agrupación elemento por elemento, lo que permite que la red comprenda asociaciones complicadas y tome decisiones no lineales. Debido a su simplicidad y eficiencia para abordar el problema del gradiente de fuga, la función de activación de la Unidad lineal rectificada (ReLU) es común en las CNN.
- Capas completamente conectadas: Las capas totalmente conectadas, también denominadas capas densas, utilizan las entidades recuperadas para completar la operación de clasificación o regresión final. Conectan cada neurona en una capa con cada neurona en la siguiente, lo que permite que la red aprenda representaciones globales y haga juicios de alto nivel basados en la entrada combinada de las capas anteriores.
La red comienza con una pila de capas convolucionales para capturar características de bajo nivel, seguidas de capas de agrupación. Las capas convolucionales más profundas aprenden características de nivel superior a medida que evoluciona la red. Finalmente, use una o más capas completas para la operación de clasificación o regresión.
Necesidad de una red totalmente conectada
Las CNN tradicionales generalmente están destinadas a trabajos de clasificación de imágenes en los que se asigna una sola etiqueta a toda la imagen de entrada. Por otro lado, las arquitecturas tradicionales de CNN tienen problemas con tareas más detalladas como la segmentación semántica, en la que cada píxel de una imagen debe clasificarse en varias clases o regiones. Aquí entran en juego las redes totalmente convolucionales (FCN).
Limitaciones de las Arquitecturas CNN Tradicionales en Tareas de Segmentación
Pérdida de información espacial: Las CNN tradicionales utilizan capas de agrupación para reducir gradualmente la dimensionalidad espacial de los mapas de características. Si bien esta reducción de resolución ayuda a capturar características de alto nivel, da como resultado una pérdida de información espacial, lo que dificulta la detección precisa y la división de objetos a nivel de píxel.
Tamaño de entrada fijo: Las arquitecturas CNN a menudo se construyen para aceptar imágenes de un tamaño específico. Sin embargo, las imágenes de entrada pueden tener varias dimensiones en las tareas de segmentación, lo que hace que las entradas de tamaño variable sean difíciles de administrar con las CNN típicas.
Precisión de localización limitada: Las CNN tradicionales a menudo usan capas completamente conectadas al final para proporcionar un vector de salida de tamaño fijo para la clasificación. Debido a que no retienen información espacial, no pueden localizar con precisión objetos o regiones dentro de la imagen.
Redes totalmente convolucionales (FCN) como solución para la segmentación semántica
Al trabajar exclusivamente en capas convolucionales y mantener la información espacial en toda la red, las redes totalmente convolucionales (FCN) abordan las limitaciones de las arquitecturas CNN clásicas en las tareas de segmentación. Los FCN están destinados a hacer predicciones píxel por píxel, y a cada píxel de la imagen de entrada se le asigna una etiqueta o clase. Los FCN permiten la construcción de un mapa de segmentación denso con pronósticos a nivel de píxel al aumentar el muestreo de los mapas de características. Las circunvoluciones transpuestas (también conocidas como desconvoluciones o capas de muestreo superior) se utilizan para reemplazar las capas completamente vinculadas después del diseño de CNN. La resolución espacial de los mapas de características aumenta mediante circunvoluciones transpuestas, lo que les permite tener el mismo tamaño que la imagen de entrada.
Durante el muestreo ascendente, los FCN generalmente usan conexiones de salto, omitiendo capas específicas y vinculando directamente los mapas de características de nivel inferior con los de nivel superior. Estas relaciones de salto ayudan a preservar los detalles detallados y la información contextual, lo que aumenta la precisión de localización de las regiones segmentadas. Los FCN son extremadamente efectivos en diversas aplicaciones de segmentación, incluida la segmentación de imágenes médicas, el análisis de escenas y la segmentación de instancias. Ahora puede manejar imágenes de entrada de varios tamaños, proporcionar predicciones a nivel de píxel y mantener la información espacial en toda la red aprovechando las FCN para la segmentación semántica.
Segmentación de imagen
La segmentación de imágenes es un proceso fundamental en visión de computadora en el que una imagen se divide en muchas partes o segmentos significativos y separados. A diferencia de la clasificación de imágenes, que proporciona una sola etiqueta a una imagen completa, la segmentación agrega etiquetas a cada píxel o grupo de píxeles, esencialmente dividiendo la imagen en partes semánticamente significativas. La segmentación de imágenes es importante porque permite una comprensión más detallada del contenido de una imagen. Podemos extraer información considerable sobre los límites, las formas, los tamaños y las relaciones espaciales de los objetos al segmentar una imagen en varias partes. Este análisis detallado es fundamental en varias tareas de visión por computadora, lo que permite aplicaciones mejoradas y admite interpretaciones de datos visuales de mayor nivel.

Comprender la arquitectura UNET
Las tecnologías tradicionales de segmentación de imágenes, como la anotación manual y la clasificación por píxeles, tienen varias desventajas que las hacen un desperdicio y dificultan los trabajos de segmentación precisos y efectivos. Debido a estas limitaciones, soluciones más avanzadas, como la UNET arquitectura, se han desarrollado. Veamos las fallas de las formas anteriores y por qué se creó UNET para superar estos problemas.
- Anotación manual: La anotación manual implica dibujar y marcar los límites de la imagen o las regiones de interés. Si bien este método produce resultados de segmentación confiables, requiere mucho tiempo, mucha mano de obra y es susceptible a errores humanos. La anotación manual no es escalable para grandes conjuntos de datos, y es difícil mantener la coherencia y el acuerdo entre los anotadores, especialmente en tareas de segmentación sofisticadas.
- Clasificación por píxeles: Otro enfoque común es la clasificación por píxeles, en la que cada píxel de una imagen se clasifica de forma independiente, generalmente utilizando algoritmos como árboles de decisión, máquinas de vectores de soporte (SVM) o bosques aleatorios. La categorización por píxeles, por otro lado, tiene dificultades para capturar el contexto global y las dependencias entre los píxeles circundantes, lo que genera problemas de segmentación excesiva o insuficiente. No puede considerar las relaciones espaciales y, con frecuencia, no ofrece límites de objetos precisos.
Supera desafíos
La arquitectura UNET se desarrolló para abordar estas limitaciones y superar los desafíos que enfrentan los enfoques tradicionales para la segmentación de imágenes. Así es como UNET aborda estos problemas:
- Aprendizaje de extremo a extremo: UNET adopta una técnica de aprendizaje de extremo a extremo, lo que significa que aprende a segmentar imágenes directamente de pares de entrada-salida sin la anotación del usuario. UNET puede extraer automáticamente características clave y ejecutar una segmentación precisa mediante la capacitación en un gran conjunto de datos etiquetados, lo que elimina la necesidad de una anotación manual que requiere mucha mano de obra.
- Arquitectura totalmente convolucional: UNET se basa en una arquitectura totalmente convolucional, lo que implica que se compone en su totalidad de capas convolucionales y no incluye ninguna capa totalmente conectada. Esta arquitectura permite que UNET funcione con imágenes de entrada de cualquier tamaño, aumentando su flexibilidad y adaptabilidad a diversas tareas de segmentación y variaciones de entrada.
- Arquitectura en forma de U con conexiones de salto: La arquitectura característica de la red incluye una ruta de codificación (ruta de contratación) y una ruta de decodificación (ruta de expansión), lo que le permite recopilar información local y contexto global. Las conexiones de salto cierran la brecha entre las rutas de codificación y decodificación, manteniendo la información crítica de las capas anteriores y permitiendo una segmentación más precisa.
- Información contextual y localización: UNET utiliza las conexiones de salto para agregar mapas de características de múltiples escalas de múltiples capas, lo que permite que la red absorba información contextual y capture detalles en diferentes niveles de abstracción. Esta integración de información mejora la precisión de la localización, lo que permite límites exactos de objetos y resultados de segmentación precisos.
- Aumento y Regularización de Datos: UNET emplea técnicas de regularización y aumento de datos para mejorar su resiliencia y capacidad de generalización durante el entrenamiento. Para aumentar la diversidad de los datos de entrenamiento, el aumento de datos implica agregar numerosas transformaciones a las imágenes de entrenamiento, como rotaciones, volteos, escalas y deformaciones. Las técnicas de regularización, como el abandono y la normalización por lotes, evitan el sobreajuste y mejoran el rendimiento del modelo en datos desconocidos.
Descripción general de la arquitectura UNET
UNET es una arquitectura de red neuronal totalmente convolucional (FCN) creada para aplicaciones de segmentación de imágenes. Fue propuesto por primera vez en 2015 por Olaf Ronneberger, Philipp Fischer y Thomas Brox. UNET se utiliza con frecuencia por su precisión en la segmentación de imágenes y se ha convertido en una opción popular en diversas aplicaciones de imágenes médicas. UNET combina una ruta de codificación, también llamada ruta de contratación, con una ruta de decodificación llamada ruta de expansión. La arquitectura lleva el nombre de su aspecto en forma de U cuando se representa en un diagrama. Debido a esta arquitectura en forma de U, la red puede registrar tanto las características locales como el contexto global, lo que genera resultados de segmentación exactos.
Componentes críticos de la arquitectura UNET
- Ruta de contratación (Ruta de codificación): La ruta de contratación de UNET comprende capas convolucionales seguidas de operaciones de agrupación máxima. Este método captura características de alta resolución y bajo nivel al reducir gradualmente las dimensiones espaciales de la imagen de entrada.
- Ruta de expansión (ruta de decodificación): Las circunvoluciones transpuestas, también conocidas como desconvoluciones o capas de muestreo superior, se utilizan para realizar un muestreo superior de los mapas de características de la ruta de codificación en la ruta de expansión de UNET. La resolución espacial de los mapas de características aumenta durante la fase de muestreo ascendente, lo que permite que la red reconstituya un mapa de segmentación denso.
- Omitir conexiones: Las conexiones de salto se utilizan en UNET para conectar capas coincidentes desde la codificación hasta las rutas de decodificación. Estos enlaces permiten que la red recopile datos locales y globales. La red retiene la información espacial esencial y mejora la precisión de la segmentación al integrar mapas de características de capas anteriores con las de la ruta de decodificación.
- Concatenación: La concatenación se usa comúnmente para implementar conexiones de salto en UNET. Los mapas de características de la ruta de codificación se concatenan con los mapas de características sobremuestreados de la ruta de decodificación durante el procedimiento de sobremuestreo. Esta concatenación permite que la red incorpore información de múltiples escalas para una segmentación adecuada, explotando el contexto de alto nivel y las características de bajo nivel.
- Capas totalmente convolucionales: UNET comprende capas convolucionales sin capas completamente conectadas. Esta arquitectura convolucional permite que UNET maneje imágenes de tamaños ilimitados mientras conserva la información espacial en toda la red, haciéndola flexible y adaptable a varias tareas de segmentación.
La ruta de codificación, o ruta de contratación, es un componente esencial de la arquitectura UNET. Es responsable de extraer información de alto nivel de la imagen de entrada mientras reduce gradualmente las dimensiones espaciales.
Capas convolucionales
El proceso de codificación comienza con un conjunto de capas convolucionales. Las capas convolucionales extraen información a múltiples escalas aplicando un conjunto de filtros de aprendizaje a la imagen de entrada. Estos filtros operan en el campo receptivo local, lo que permite que la red capture patrones espaciales y características menores. Con cada capa convolucional, la profundidad de los mapas de características crece, lo que permite que la red aprenda representaciones más complicadas.
Función de activación
Después de cada capa convolucional, se aplica elemento por elemento una función de activación como la Unidad lineal rectificada (ReLU) para inducir la no linealidad en la red. La función de activación ayuda a la red a aprender correlaciones no lineales entre las imágenes de entrada y las características recuperadas.
Capas de agrupación
Las capas de agrupación se utilizan después de las capas convolucionales para reducir la dimensionalidad espacial de los mapas de características. Las operaciones, como la agrupación máxima, dividen los mapas de características en regiones que no se superponen y mantienen solo el valor máximo dentro de cada zona. Reduce la resolución espacial al reducir el muestreo de los mapas de características, lo que permite que la red capture datos más abstractos y de mayor nivel.
El trabajo de la ruta de codificación es capturar características en varias escalas y niveles de abstracción de manera jerárquica. El proceso de codificación se centra en extraer el contexto global y la información de alto nivel a medida que disminuyen las dimensiones espaciales.
Saltar conexiones
La disponibilidad de conexiones de salto que conectan los niveles apropiados desde la ruta de codificación a la ruta de decodificación es una de las características distintivas de la arquitectura UNET. Estos enlaces de salto son fundamentales para mantener los datos clave durante el proceso de codificación.
Los mapas de características de capas anteriores recopilan detalles locales e información detallada durante la ruta de codificación. Estos mapas de funciones se concatenan con los mapas de funciones muestreados en la canalización de decodificación utilizando conexiones de salto. Esto permite que la red incorpore datos de múltiples escalas, características de bajo nivel y contexto de alto nivel en el proceso de segmentación.
Al conservar la información espacial de las capas anteriores, UNET puede localizar objetos de manera confiable y mantener los detalles más finos en los resultados de la segmentación. Las conexiones de salto de UNET ayudan a abordar el problema de la pérdida de información causada por la reducción de resolución. Los enlaces de salto permiten una mejor integración de la información local y global, mejorando el rendimiento de la segmentación en general.
En resumen, el enfoque de codificación UNET es fundamental para capturar características de alto nivel y reducir las dimensiones espaciales de la imagen de entrada. La ruta de codificación extrae representaciones progresivamente abstractas a través de capas convolucionales, funciones de activación y capas de agrupación. Al integrar las características locales y el contexto global, la introducción de enlaces de salto permite preservar información espacial crítica, facilitando resultados de segmentación confiables.
Ruta de decodificación en UNET
Un componente crítico de la arquitectura UNET es la ruta de decodificación, también conocida como ruta de expansión. Es responsable de aumentar el muestreo de los mapas de características de la ruta de codificación y construir la máscara de segmentación final.
Capas de sobremuestreo (convoluciones transpuestas)
Para aumentar la resolución espacial de los mapas de características, el método de decodificación UNET incluye capas de muestreo superior, que con frecuencia se realizan mediante convoluciones transpuestas o deconvoluciones. Las circunvoluciones transpuestas son esencialmente lo contrario de las circunvoluciones regulares. Mejoran las dimensiones espaciales en lugar de disminuirlas, lo que permite un muestreo superior. Al construir un kernel disperso y aplicarlo al mapa de características de entrada, las circunvoluciones transpuestas aprenden a muestrear los mapas de características. La red aprende a llenar los espacios entre las ubicaciones espaciales actuales durante este proceso, lo que aumenta la resolución de los mapas de características.
Concatenación
Los mapas de características de las capas anteriores se concatenan con los mapas de características muestreados durante la fase de decodificación. Esta concatenación permite que la red agregue información de múltiples escalas para una segmentación correcta, aprovechando el contexto de alto nivel y las características de bajo nivel. Además del muestreo superior, la ruta de decodificación de UNET incluye conexiones de salto de los niveles comparables de la ruta de codificación.
La red puede recuperar e integrar características detalladas perdidas durante la codificación concatenando mapas de características de conexiones de salto. Permite una localización y delineación de objetos más precisa en la máscara de segmentación.
El proceso de decodificación en UNET reconstruye un mapa de segmentación denso que se ajusta a la resolución espacial de la imagen de entrada al muestrear progresivamente los mapas de características e incluir enlaces de salto.
La función de la ruta de decodificación es recuperar la información espacial perdida durante la ruta de codificación y refinar los resultados de la segmentación. Combina detalles de codificación de bajo nivel con contexto de alto nivel obtenido de las capas de muestreo ascendente para proporcionar una máscara de segmentación precisa y completa.
UNET puede aumentar la resolución espacial de los mapas de características mediante el uso de circunvoluciones transpuestas en el proceso de decodificación, y así aumentar el muestreo para que coincidan con el tamaño de la imagen original. Las circunvoluciones transpuestas ayudan a la red a generar una máscara de segmentación densa y de grano fino al aprender a llenar los vacíos y expandir las dimensiones espaciales.
En resumen, el proceso de decodificación en UNET reconstruye la máscara de segmentación al mejorar la resolución espacial de los mapas de características a través de capas de muestreo superior y conexiones de salto. Las circunvoluciones transpuestas son fundamentales en esta fase porque permiten que la red realice un muestreo superior de los mapas de características y construya una máscara de segmentación detallada que coincida con la imagen de entrada original.
Contracción y Expansión de Caminos en UNET
La arquitectura UNET sigue una estructura de "codificador-decodificador", donde la ruta de contratación representa el codificador y la ruta de expansión representa el decodificador. Este diseño se asemeja a codificar información en forma comprimida y luego decodificarla para reconstruir los datos originales.
Ruta de contratación (codificador)
El codificador en UNET es el camino de contratación. Extrae el contexto y comprime la imagen de entrada al disminuir gradualmente las dimensiones espaciales. Este método incluye capas convolucionales seguidas de procedimientos de agrupación, como la agrupación máxima para reducir la muestra de los mapas de características. La ruta de contratación es responsable de obtener características de alto nivel, aprender el contexto global y disminuir la resolución espacial. Se enfoca en comprimir y abstraer la imagen de entrada, capturando eficientemente la información relevante para la segmentación.
Ruta de expansión (decodificador)
El decodificador en UNET es el camino en expansión. Al muestrear los mapas de características de la ruta de contratación, recupera información espacial y genera el mapa de segmentación final. La ruta de expansión comprende capas de muestreo superior, a menudo realizadas con convoluciones transpuestas o desconvoluciones para aumentar la resolución espacial de los mapas de características. La ruta de expansión reconstruye las dimensiones espaciales originales a través de conexiones de salto al integrar los mapas de características muestreados con los mapas equivalentes de la ruta de contracción. Este método permite que la red recupere características detalladas y localice correctamente los elementos.
El diseño de UNET captura el contexto global y los detalles locales mezclando vías de contracción y expansión. La ruta de contracción comprime la imagen de entrada en una representación compacta, decidió construir un mapa de segmentación detallado por la ruta de expansión. La ruta de expansión se refiere a la decodificación de la representación comprimida en un mapa de segmentación denso y preciso. Reconstruye la información espacial faltante y refina los resultados de la segmentación. Esta estructura de codificador-decodificador permite una segmentación de precisión utilizando contexto de alto nivel e información espacial detallada.
En resumen, las rutas de contracción y expansión de UNET se asemejan a una estructura de “codificador-decodificador”. El camino de expansión es el decodificador, recuperando la información espacial y generando el mapa de segmentación final. Por el contrario, la ruta de contratación sirve como codificador, capturando el contexto y comprimiendo la imagen de entrada. Esta arquitectura permite que UNET codifique y decodifique información de manera efectiva, lo que permite una segmentación de imágenes precisa y completa.
Omitir conexiones en UNET
Las conexiones de salto son esenciales para el diseño de UNET porque permiten que la información viaje entre las rutas de contracción (codificación) y expansión (descodificación). Son fundamentales para mantener la información espacial y mejorar la precisión de la segmentación.
Conservación de la información espacial
Es posible que se pierda parte de la información espacial durante la ruta de codificación, ya que los mapas de características se someten a procedimientos de reducción de muestreo, como la agrupación máxima. Esta pérdida de información puede provocar una menor precisión de localización y una pérdida de detalles de granularidad fina en la máscara de segmentación.
Al establecer conexiones directas entre las capas correspondientes en los procesos de codificación y decodificación, las conexiones de salto ayudan a solucionar este problema. Las conexiones de salto protegen la información espacial vital que, de otro modo, se perdería durante la reducción de resolución. Estas conexiones permiten que la información del flujo de codificación evite la reducción de muestreo y se transmita directamente a la ruta de decodificación.
Fusión de información multiescala
Las conexiones de salto permiten la fusión de información de múltiples escalas de muchas capas de red. Los niveles posteriores del proceso de codificación capturan información semántica y de contexto de alto nivel, mientras que las capas anteriores capturan detalles locales e información detallada. UNET puede combinar con éxito información local y global al conectar estos mapas de características desde la ruta de codificación a las capas equivalentes en la ruta de decodificación. Esta integración de información multiescala mejora la precisión de la segmentación en general. La red puede usar datos de bajo nivel de la ruta de codificación para refinar los hallazgos de segmentación en la ruta de decodificación, lo que permite una localización más precisa y una mejor delimitación de los límites de los objetos.
Combinación de contexto de alto nivel y detalles de bajo nivel
Las conexiones de salto permiten que la ruta de decodificación combine contexto de alto nivel y detalles de bajo nivel. Los mapas de características concatenados de las conexiones de salto incluyen los mapas de características sobremuestreados de la ruta de decodificación y los mapas de características de la ruta de codificación.
Esta combinación permite que la red aproveche el contexto de alto nivel registrado en la ruta de decodificación y las características detalladas capturadas en la ruta de codificación. La red puede incorporar información de varios tamaños, lo que permite una segmentación más precisa y detallada.
UNET puede aprovechar la información de múltiples escalas, preservar los detalles espaciales y fusionar el contexto de alto nivel con los detalles de bajo nivel agregando conexiones de salto. Como resultado, mejora la precisión de la segmentación, mejora la localización de objetos y se conserva la información detallada en la máscara de segmentación.
En conclusión, las conexiones de omisión en UNET son fundamentales para mantener la información espacial, integrar información de múltiples escalas y aumentar la precisión de la segmentación. Proporcionan un flujo de información directo a través de las rutas de codificación y decodificación, lo que permite que la red recopile detalles locales y globales, lo que da como resultado una segmentación de imágenes más precisa y detallada.
Función de pérdida en UNET
Es fundamental seleccionar una función de pérdida adecuada mientras se entrena UNET y se optimizan sus parámetros para las tareas de segmentación de imágenes. UNET emplea con frecuencia funciones de pérdida amigables con la segmentación, como el coeficiente de Dice o la pérdida de entropía cruzada.
Pérdida de coeficiente de dados
El coeficiente Dice es una estadística de similitud que calcula la superposición entre las máscaras de segmentación anticipada y verdadera. La pérdida del coeficiente de Dice, o pérdida blanda de Dice, se calcula restando uno del coeficiente de Dice. Cuando las máscaras de verdad anticipada y terrestre se alinean bien, la pérdida se minimiza, lo que da como resultado un coeficiente de Dados más alto.
La pérdida del coeficiente Dice es especialmente eficaz para conjuntos de datos desequilibrados en los que la clase de fondo tiene muchos píxeles. Al penalizar los falsos positivos y los falsos negativos, promueve que la red divida con precisión las regiones de primer plano y de fondo.
Pérdida de entropía cruzada
Utilice la función de pérdida de entropía cruzada en tareas de segmentación de imágenes. Mide la disimilitud entre las probabilidades de clase predichas y las etiquetas de verdad del terreno. Trate cada píxel como un problema de clasificación independiente en la segmentación de imágenes, y la pérdida de entropía cruzada se calcula por píxel.
La pérdida de entropía cruzada alienta a la red a asignar altas probabilidades a las etiquetas de clase correctas para cada píxel. Penaliza las desviaciones de la verdad del terreno, promoviendo resultados de segmentación precisos. Esta función de pérdida es efectiva cuando las clases de primer plano y segundo plano están equilibradas o cuando varias clases están involucradas en la tarea de segmentación.
La elección entre la pérdida del coeficiente de Dice y la pérdida de entropía cruzada depende de los requisitos específicos de la tarea de segmentación y las características del conjunto de datos. Ambas funciones de pérdida tienen ventajas y pueden combinarse o personalizarse según las necesidades específicas.
1: Importación de bibliotecas
import tensorflow as tf
import os
import numpy as np
from tqdm import tqdm
from skimage.io import imread, imshow
from skimage.transform import resize
import matplotlib.pyplot as plt
import random2: Dimensiones de la imagen - Configuración
IMG_WIDTH = 128
IMG_HEIGHT = 128
IMG_CHANNELS = 33: Configuración de la aleatoriedad
seed = 42
np.random.seed = seed4: Importación del conjunto de datos
# Data downloaded from - https://www.kaggle.com/competitions/data-science-bowl-2018/data #importing datasets
TRAIN_PATH = 'stage1_train/'
TEST_PATH = 'stage1_test/'5: Lectura de todas las imágenes presentes en la subcarpeta
train_ids = next(os.walk(TRAIN_PATH))[1]
test_ids = next(os.walk(TEST_PATH))[1]6: Entrenamiento
X_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)7: Cambiar el tamaño de las imágenes
print('Resizing training images and masks')
for n, id_ in tqdm(enumerate(train_ids), total=len(train_ids)): path = TRAIN_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_train[n] = img #Fill empty X_train with values from img mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool) for mask_file in next(os.walk(path + '/masks/'))[2]: mask_ = imread(path + '/masks/' + mask_file) mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True), axis=-1) mask = np.maximum(mask, mask_) Y_train[n] = mask 8: Prueba de las imágenes
# test images
X_test = np.zeros((len(test_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
sizes_test = []
print('Resizing test images') for n, id_ in tqdm(enumerate(test_ids), total=len(test_ids)): path = TEST_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] sizes_test.append([img.shape[0], img.shape[1]]) img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_test[n] = img print('Done!')9: Comprobación aleatoria de las imágenes
image_x = random.randint(0, len(train_ids))
imshow(X_train[image_x])
plt.show()
imshow(np.squeeze(Y_train[image_x]))
plt.show()10: Construcción del modelo
inputs = tf.keras.layers.Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = tf.keras.layers.Lambda(lambda x: x / 255)(inputs)11: Caminos
#Contraction path
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = tf.keras.layers.Dropout(0.1)(c1)
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = tf.keras.layers.MaxPooling2D((2, 2))(c1) c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = tf.keras.layers.Dropout(0.1)(c2)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = tf.keras.layers.MaxPooling2D((2, 2))(c2) c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = tf.keras.layers.Dropout(0.2)(c3)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = tf.keras.layers.MaxPooling2D((2, 2))(c3) c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = tf.keras.layers.Dropout(0.2)(c4)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(c4) c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = tf.keras.layers.Dropout(0.3)(c5)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)12: Rutas de expansión
u6 = tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = tf.keras.layers.Dropout(0.2)(c6)
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6) u7 = tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = tf.keras.layers.Dropout(0.2)(c7)
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7) u8 = tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = tf.keras.layers.Dropout(0.1)(c8)
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8) u9 = tf.keras.layers.Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1], axis=3)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = tf.keras.layers.Dropout(0.1)(c9)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)13: Salidas
outputs = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(c9)14: Resumen
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()15: Modelo de punto de control
checkpointer = tf.keras.callbacks.ModelCheckpoint('model_for_nuclei.h5', verbose=1, save_best_only=True) callbacks = [ tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), tf.keras.callbacks.TensorBoard(log_dir='logs')] results = model.fit(X_train, Y_train, validation_split=0.1, batch_size=16, epochs=25, callbacks=callbacks)16: Última Etapa – Predicción
idx = random.randint(0, len(X_train)) preds_train = model.predict(X_train[:int(X_train.shape[0]*0.9)], verbose=1)
preds_val = model.predict(X_train[int(X_train.shape[0]*0.9):], verbose=1)
preds_test = model.predict(X_test, verbose=1) preds_train_t = (preds_train > 0.5).astype(np.uint8)
preds_val_t = (preds_val > 0.5).astype(np.uint8)
preds_test_t = (preds_test > 0.5).astype(np.uint8) # Perform a sanity check on some random training samples
ix = random.randint(0, len(preds_train_t))
imshow(X_train[ix])
plt.show()
imshow(np.squeeze(Y_train[ix]))
plt.show()
imshow(np.squeeze(preds_train_t[ix]))
plt.show() # Perform a sanity check on some random validation samples
ix = random.randint(0, len(preds_val_t))
imshow(X_train[int(X_train.shape[0]*0.9):][ix])
plt.show()
imshow(np.squeeze(Y_train[int(Y_train.shape[0]*0.9):][ix]))
plt.show()
imshow(np.squeeze(preds_val_t[ix]))
plt.show()Conclusión
En esta completa publicación de blog, hemos cubierto la arquitectura UNET para la segmentación de imágenes. Al abordar las limitaciones de las metodologías anteriores, la arquitectura UNET ha revolucionado la segmentación de imágenes. Sus rutas de codificación y decodificación, omisión de conexiones y otras modificaciones, como U-Net++, Attention U-Net y Dense U-Net, han demostrado ser muy eficaces para capturar el contexto, mantener la información espacial y aumentar la precisión de la segmentación. El potencial para la segmentación precisa y automática con UNET ofrece nuevos caminos para mejorar la visión por computadora y más allá. Alentamos a los lectores a aprender más sobre UNET y experimentar con su implementación para maximizar su utilidad en sus proyectos de segmentación de imágenes.
Puntos clave
1. La segmentación de imágenes es esencial en las tareas de visión artificial, ya que permite la división de imágenes en regiones u objetos significativos.
2. Los enfoques tradicionales para la segmentación de imágenes, como la anotación manual y la clasificación por píxeles, tienen limitaciones en términos de eficiencia y precisión.
3. Desarrollar la arquitectura UNET para abordar estas limitaciones y lograr resultados de segmentación precisos.
4. Es una red neuronal totalmente convolucional (FCN) que combina una ruta de codificación para capturar características de alto nivel y un método de decodificación para generar la máscara de segmentación.
5. Omita las conexiones en UNET, conserve la información espacial, mejore la propagación de características y mejore la precisión de la segmentación.
6. Encontró aplicaciones exitosas en imágenes médicas, análisis de imágenes satelitales y control de calidad industrial, logrando puntos de referencia notables y reconocimiento en competencias.
Preguntas frecuentes
R. La arquitectura U-Net es una arquitectura popular de red neuronal convolucional (CNN) común para tareas de segmentación de imágenes. Inicialmente desarrollado para la segmentación de imágenes biomédicas, desde entonces ha encontrado aplicaciones en varios dominios. La arquitectura U-Net maneja información local y global y tiene una estructura de codificador-decodificador en forma de U.
R. La arquitectura U-Net consta de una ruta de codificador y una ruta de decodificador. La ruta del codificador reduce gradualmente las dimensiones espaciales de la imagen de entrada mientras aumenta el número de canales de características. Esto ayuda a extraer características abstractas y de alto nivel. La ruta del decodificador realiza operaciones de sobremuestreo y concatenación. Y recupere las dimensiones espaciales mientras reduce el número de canales de funciones. La red aprende a combinar las funciones de bajo nivel de la ruta del codificador con las funciones de alto nivel de la ruta del decodificador para generar máscaras de segmentación.
R. La arquitectura U-Net ofrece varias ventajas para las tareas de segmentación de imágenes. En primer lugar, su diseño en forma de U permite combinar funciones de bajo y alto nivel, lo que permite una mejor localización de los objetos. En segundo lugar, las conexiones de salto entre las rutas del codificador y del decodificador ayudan a preservar la información espacial, lo que permite una segmentación más precisa. Por último, la arquitectura U-Net tiene una cantidad relativamente pequeña de parámetros, lo que la hace más eficiente desde el punto de vista computacional que otras arquitecturas.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/08/unet-architecture-mastering-image-segmentation/

