El equipo de Diseño y Construcción de Amazon UE (Amazon D&C) es el equipo de ingeniería que diseña y construye los almacenes de Amazon en toda Europa y la región MENA. Los procesos de diseño e implementación de proyectos implican muchos tipos de Solicitudes de información (RFI) sobre requisitos de ingeniería relacionados con Amazon y pautas específicas del proyecto. Estas solicitudes van desde la simple recuperación de valores de diseño de referencia hasta la revisión de propuestas de ingeniería de valor, el análisis de informes y verificaciones de cumplimiento. Hoy en día, estos son abordados por un Equipo Técnico Central, compuesto por expertos en la materia (PYME) que pueden responder preguntas especializadas altamente técnicas y brindar este servicio a todas las partes interesadas y equipos durante todo el ciclo de vida del proyecto. El equipo está buscando un IA generativa Solución de respuesta a preguntas para obtener información rápidamente y continuar con su diseño de ingeniería. En particular, estos casos de uso no se limitan únicamente al equipo de D&C de Amazon, sino que son aplicables al alcance más amplio de los servicios de ingeniería globales involucrados en la implementación del proyecto. Toda la gama de partes interesadas y equipos involucrados en el ciclo de vida del proyecto puede beneficiarse de una solución generativa de respuesta a preguntas de IA, ya que permitirá un acceso rápido a información crítica, agilizando los procesos de diseño de ingeniería y gestión de proyectos.
Las soluciones de IA generativa existentes para responder preguntas se basan principalmente en Recuperación Generación Aumentada (TRAPO). RAG busca documentos a través de modelo de lenguaje grande (LLM) incrustación y vectorización, crea el contexto a partir de los resultados de búsqueda mediante agrupación y utiliza el contexto como un mensaje aumentado para inferir un modelo básico para obtener la respuesta. Este método es menos eficaz para los documentos altamente técnicos de Amazon D&C, que contienen importantes datos no estructurados, como hojas de Excel, tablas, listas, figuras e imágenes. En este caso, la tarea de respuesta a preguntas funciona mejor al ajustar el LLM con los documentos. El ajuste fino ajusta y adapta los pesos del LLM previamente entrenado para mejorar la calidad y precisión del modelo.
Para abordar estos desafíos, presentamos un nuevo marco con RAG y LLM perfeccionados. La solución utiliza JumpStart de Amazon SageMaker como servicio central para el ajuste y la inferencia del modelo. En esta publicación, no solo brindamos la solución, sino que también analizamos las lecciones aprendidas y las mejores prácticas al implementar la solución en casos de uso del mundo real. Comparamos y contrastamos el rendimiento de diferentes metodologías y LLM de código abierto en nuestro caso de uso y discutimos cómo encontrar el equilibrio entre el rendimiento del modelo y los costos de los recursos informáticos.
Resumen de la solución
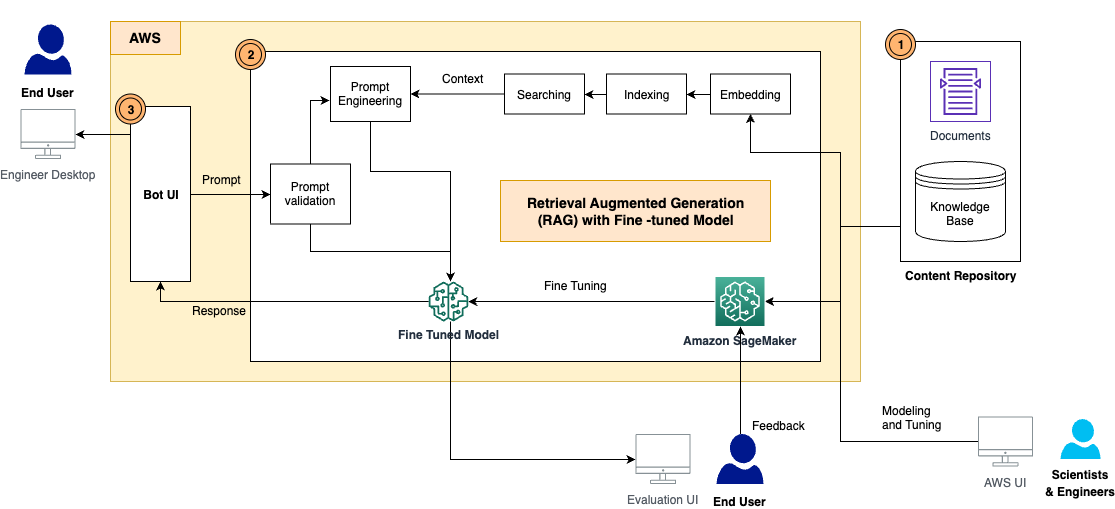
La solución tiene los siguientes componentes, como se muestra en el diagrama de arquitectura:
- repositorio de contenido – Los contenidos de D&C incluyen una amplia gama de documentos legibles por humanos con varios formatos, como archivos PDF, hojas de Excel, páginas wiki y más. En esta solución, almacenamos estos contenidos en un Servicio de almacenamiento simple de Amazon (Amazon S3) y los utilizó como base de conocimientos para la recuperación e inferencia de información. En el futuro, crearemos adaptadores de integración para acceder a los contenidos directamente desde donde viven.
- Marco RAG con un LLM ajustado – Consta de los siguientes subcomponentes:
- marco GAR – Esto recupera los datos relevantes de los documentos, aumenta las indicaciones agregando los datos recuperados en contexto y los pasa a un LLM ajustado para generar resultados.
- LLM perfeccionado – Construimos el conjunto de datos de capacitación a partir de los documentos y contenidos y realizamos ajustes en el modelo básico. Después del ajuste, el modelo aprendió el conocimiento de los contenidos de D&C y, por lo tanto, puede responder a las preguntas de forma independiente.
- Módulo de validación rápida – Esto mide la coincidencia semántica entre la solicitud del usuario y el conjunto de datos para realizar un ajuste fino. Si el LLM está ajustado para responder esta pregunta, entonces puede inferir el modelo ajustado para una respuesta. De lo contrario, puede utilizar RAG para generar la respuesta.
- LangChain - Usamos LangChain para construir un flujo de trabajo para responder a las preguntas entrantes.
- IU de usuario final – Esta es la interfaz de usuario del chatbot para capturar las preguntas y consultas de los usuarios y presentar la respuesta de RAG y LLM.
En las siguientes secciones, demostramos cómo crear el flujo de trabajo RAG y construir los modelos ajustados.
RAG con modelos de base de SageMaker JumpStart
RAG combina los poderes de los modelos básicos de recuperación densa y secuencia a secuencia (seq2seq) previamente entrenados. Para responder preguntas de los documentos D&C de Amazon, debemos preparar lo siguiente con anticipación:
- Incrustar e indexar los documentos utilizando un modelo de incrustación LLM – Dividimos los múltiples documentos en pequeños fragmentos según el capítulo del documento y la estructura de la sección, los probamos con el modelo Amazon GPT-J-6B en SageMaker JumpStart para generar los índices y los almacenamos en un almacén de vectores FAISS.
- Un modelo básico previamente entrenado para generar respuestas a partir de indicaciones – Probamos con los modelos Flan-T5 XL, Flan-T5 XXL y Falcon-7B en SageMaker JumpStart
El proceso de respuesta a preguntas lo implementa LangChain, que es un marco para desarrollar aplicaciones basadas en modelos de lenguaje. El flujo de trabajo en la cadena contiene los siguientes pasos:
- Reciba una pregunta del usuario.
- Realizar búsqueda semántica en los documentos indexados a través de FAISS para obtener los K fragmentos de documentos más relevantes.
- Defina la plantilla de solicitud, como
- Aumente los fragmentos de documentos recuperados a medida que
{context}y la pregunta del usuario como{question}en el aviso. - Indique al modelo de base el mensaje de disparo cero construido.
- Devuelve la salida del modelo al usuario.
Probamos 125 preguntas sobre los requisitos y especificaciones de Amazon D&C y RAG obtuvo una buena respuesta para algunas preguntas. En el siguiente ejemplo, RAG con el modelo Flan-T5-XXL proporcionó una respuesta precisa de las secciones correctas de los documentos.
| Pregunta | ¿Cuáles son los requisitos de FONTANERÍA para bebederos y enfriadores de agua? (Sección 22 47 00) |
| Respuesta esperada | El Desarrollador deberá proporcionar barras dispensadoras de agua, colocadas en el piso en el espacio de la pared del Almacén inmediatamente adyacente a la entrada de cada bloque de baños que da servicio al Almacén y en la ubicación equivalente adyacente al bloque de baños de los Lockers Room. Las unidades deberán cumplir con el estándar de Amazon. Los números finales y la ubicación se acordarán con Amazon antes de la instalación. Se proporcionará un mínimo de dos unidades que dispensen agua fría y a temperatura ambiente en cada ubicación. Enfriadores de agua o barras de agua: el Desarrollador proporcionará suministros de agua potable según sea necesario para enfriadores de agua o barras de agua remotos en toda la instalación. El Desarrollador proporcionará puntos de agua, drenaje y cualquier servicio eléctrico requerido en las Salas de Descanso para los Bares de Agua los cuales serán proporcionados por el Contratista de Catering. |
| Respuesta RAG (incrustación GPT-J-6B con Flan-T5-XXL) | El Desarrollador deberá proporcionar barras dispensadoras de agua, colocadas en el piso en el espacio de la pared del Almacén inmediatamente adyacente a la entrada de cada bloque de baños que da servicio al Almacén y en la ubicación equivalente adyacente al bloque de baños de los Lockers Room. Las unidades deberán cumplir con el estándar de Amazon. Los números finales y la ubicación se acordarán con Amazon antes de la instalación. Se proporcionará un mínimo de dos unidades que dispensen agua fría y a temperatura ambiente en cada ubicación. Enfriadores de agua o barras de agua: el Desarrollador proporcionará suministros de agua potable según sea necesario para enfriadores de agua o barras de agua remotos en toda la instalación. El Desarrollador proporcionará puntos de agua, drenaje y cualquier servicio eléctrico requerido en las Salas de Descanso para los Bares de Agua los cuales serán proporcionados por el Contratista de Catering. |
Sin embargo, observamos que RAG no proporciona respuestas claras y nítidas a las preguntas más específicas y altamente técnicas, como directrices, números y cifras. Como se muestra en el siguiente ejemplo, cuando se espera un resultado de dimensión técnica, RAG no puede proporcionar la respuesta específica, principalmente porque el proceso de incrustación y búsqueda no puede devolver un contexto conciso.
| Pregunta | ¿Cuál es el requisito de altura de piso para el concreto del nivel del primer piso P2? |
| Respuesta esperada | 7,50 m AFFL |
| Respuesta RAG (incrustación GPT-J-6B con Flan-T5-XXL) | P2 Primer piso Concreto |
Esto debe mejorarse porque las alucinaciones no se toleran debido a la importancia de las consecuencias en este caso de uso.
Ajuste los LLM en SageMaker
Para abordar este desafío y mejorar la calidad de la respuesta, adoptamos un nuevo enfoque para ajustar el modelo LLM utilizando los documentos para una tarea de respuesta a preguntas. El modelo será entrenado para aprender el conocimiento correspondiente directamente de los documentos. A diferencia de RAG, no depende de si los documentos están incrustados e indexados correctamente, ni de si el algoritmo de búsqueda semántica es lo suficientemente efectivo como para devolver los contenidos más relevantes de la base de datos vectorial.
Para preparar el conjunto de datos de entrenamiento para su ajuste, extraemos la información de los documentos D&C y construimos los datos en el siguiente formato:
- Instrucción – Describe la tarea y proporciona indicaciones parciales.
- Entrada – Proporciona más contexto para consolidarlo en el mensaje.
- Respuesta – La salida del modelo.
Durante el proceso de capacitación, agregamos una clave de instrucción, una clave de entrada y una clave de respuesta a cada parte, las combinamos en el mensaje de capacitación y las tokenizamos. Luego, los datos se envían a un entrenador en SageMaker para generar el modelo ajustado.
Para acelerar el proceso de capacitación y reducir el costo de los recursos informáticos, empleamos Ajuste eficiente de parámetros (PEFT) con el Adaptación de bajo rango (LoRA) técnica. PEFT nos permite ajustar solo una pequeña cantidad de parámetros adicionales del modelo, y LoRA representa las actualizaciones de peso con dos matrices más pequeñas mediante descomposición de rango bajo. Con PEFT y LoRA en cuantificación de 8 bits (una operación de compresión que reduce aún más la huella de memoria del modelo y acelera el rendimiento del entrenamiento y la inferencia), podemos ajustar el entrenamiento de 125 pares de preguntas y respuestas dentro de una instancia de g4dn.x. con una sola GPU.
Para demostrar la eficacia del ajuste, lo probamos con varios LLM en SageMaker. Seleccionamos cinco modelos de tamaño pequeño: Bloom-7B, Flan-T5-XL, GPT-J-6B y Falcon-7B en SageMaker JumpStart, y Dolly-3B de Abrazando la cara en SageMaker.
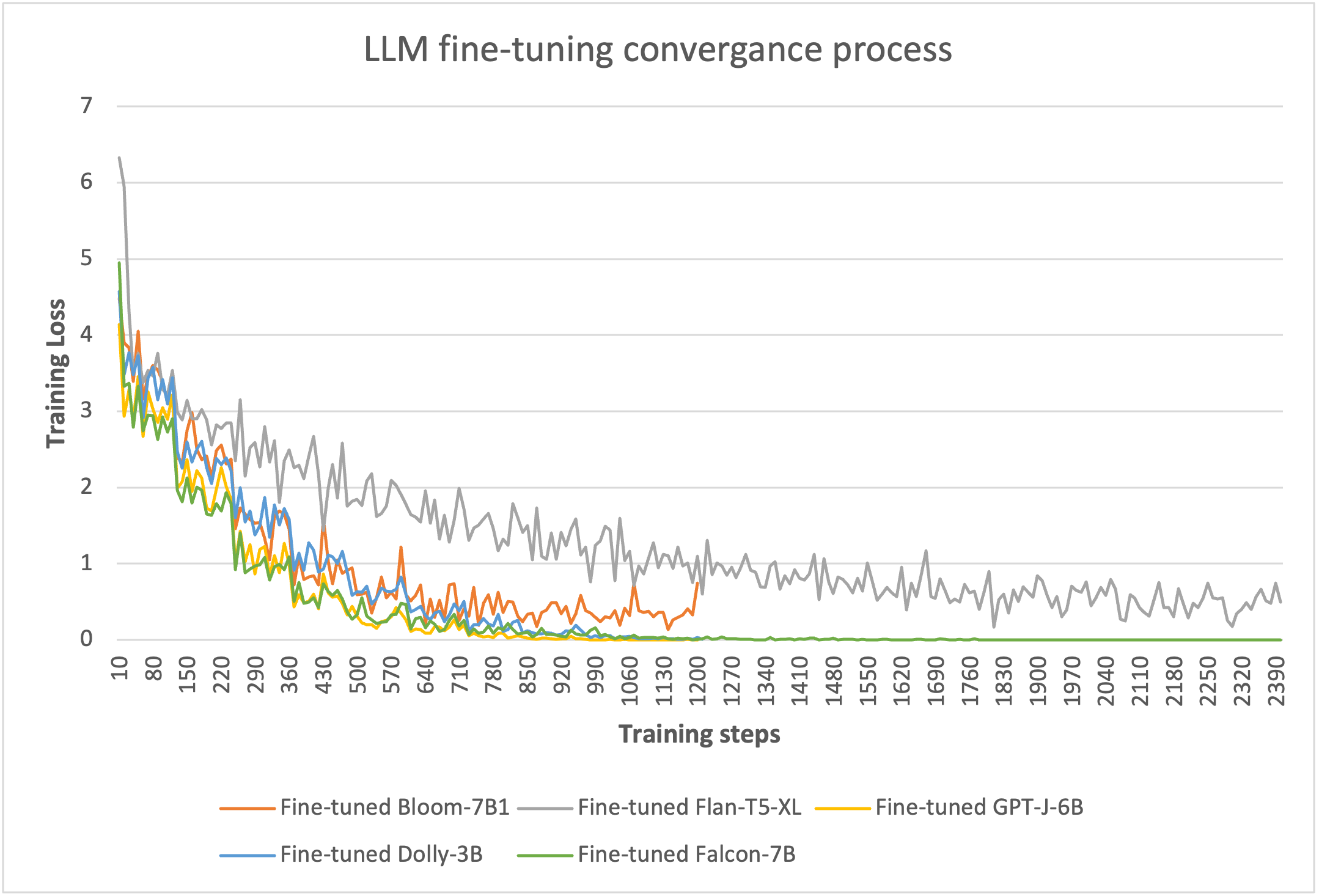
A través del entrenamiento basado en LoRA de 8 bits, podemos reducir los parámetros entrenables a no más del 5% de los pesos totales de cada modelo. El entrenamiento tarda entre 10 y 20 épocas en converger, como se muestra en la siguiente figura. Para cada modelo, los procesos de ajuste pueden caber en una sola GPU de una instancia g4dn.x, lo que optimizó los costos de los recursos informáticos.
Inferencia del modelo ajustado implementado en SageMaker
Implementamos el modelo ajustado junto con el marco RAG en un único nodo GPU g4dn.x en SageMaker y comparamos los resultados de la inferencia para las 125 preguntas. El rendimiento del modelo se mide mediante dos métricas. uno es el ROUGE (Suplente orientado al recuerdo para la evaluación de Gisting), un puntaje popular procesamiento natural del lenguaje (NLP) método de evaluación del modelo que calcula el cociente de las palabras coincidentes bajo el recuento total de palabras en la oración de referencia. El otro es el similitud semántica (textual) puntuación, que mide qué tan cerca está el significado de dos fragmentos de texto mediante el uso de un modelo transformador para codificar oraciones para obtener sus incrustaciones, y luego usa una métrica de similitud de coseno para calcular su puntuación de similitud. A partir de los experimentos, podemos ver que estas dos métricas son bastante consistentes al presentar la calidad de las respuestas a las preguntas.
En la siguiente tabla y figura, podemos ver que el modelo Falcon-7B ajustado proporciona la mejor calidad de respuesta, y los modelos Flan-T5-XL y Dolly-3B también generan respuestas precisas.
| . | RAG_GPT-J-6B_Flan-T5-XL | RAG_GPT-J-6B_Flan-T5-XXL | Bloom-7B1 afinado | Flan-T5-XL afinado | GPT-J-6B afinado | Dolly-3B afinado | Falcon-7B afinado |
| Puntuación ROJA | 0.1938 | 0.2747 | 0.3914 | 0.4977 | 0.3740 | 0.6991 | 0.9459 |
| Puntuación de similitud semántica | 0.4121 | 0.4786 | 0.5666 | 0.7205 | 0.5414 | 0.8147 | 0.9774 |

El siguiente es un ejemplo de respuesta de los modelos. RAG con el modelo Flan-T5-XL proporcionó una respuesta altamente alucinada, mientras que la respuesta de RAG con el modelo Flan-T5-XXL más grande fue más relevante pero aún no pudo cubrir el mensaje esperado completo. Comparativamente, todos los modelos ajustados (Flan-T5-XL, Dolly-3B y Falcon-7B) pudieron proporcionar la respuesta más precisa como respuesta esperada.
| Pregunta | ¿Cuáles son los requisitos para el sellador/endurecedor posterior al pulido? (TS0004 – sección 2.8) |
| Respuesta esperada | Se utilizará un sellador/endurecedor a base de litio después de cualquier procedimiento de esmerilado/lijado realizado en AR Floor. Consulte TGC /0007 Procedimientos SCA de piso AR. Se considerarán alternativas, pero deberán ser aprobadas por Amazon y el consultor de pisos. |
| Respuesta de RAG (GPT-J-6B integrado con Flan-T5-XL) | El endurecedor de concreto penetrante debe discutirse en la reunión previa al vertido y debe ser aprobado por el consultor de pisos y Amazon. |
| Respuesta de RAG (GPT-J-6B integrado con Flan-T5-XXL) | El compuesto propuesto debe discutirse en la reunión previa al vertido y debe ser aprobado por el consultor de pisos y Amazon. Se considerarán alternativas, pero deberán ser aprobadas por Amazon y el consultor de pisos. |
| Respuesta del Flan-T5-XL afinado | Se utilizará un sellador/endurecedor a base de litio después de cualquier procedimiento de esmerilado/lijado realizado en AR Floor. Consulte TGC /0007 Procedimientos SCA de piso AR. Se considerarán alternativas, pero deberán ser aprobadas por Amazon y el consultor de pisos. |
| Respuesta de Dolly-3B afinada | Se utilizará un sellador/endurecedor a base de litio después de cualquier procedimiento de esmerilado/lijado realizado en AR Floor. Consulte TGC /0007 Procedimientos SCA de piso AR. Se considerarán alternativas, pero deberán ser aprobadas por Amazon y el consultor de pisos. |
| Respuesta del Falcon-7B afinado | Se utilizará un sellador/endurecedor a base de litio después de cualquier procedimiento de esmerilado/lijado realizado en AR Floor. Consulte TGC /0007 Procedimientos SCA de piso AR. Se considerarán alternativas, pero deberán ser aprobadas por Amazon y el consultor de pisos. |
Prototipo de solución y resultado.
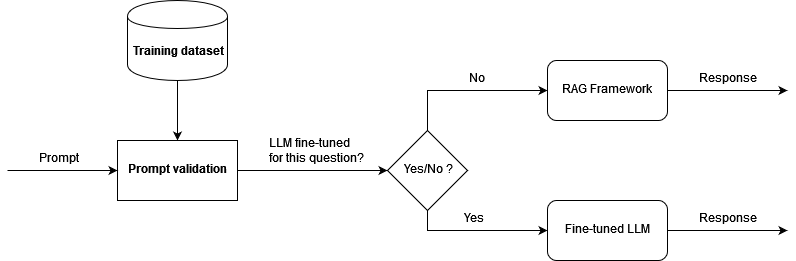
Desarrollamos un prototipo basado en la arquitectura presentada y realizamos una prueba de concepto para demostrar el resultado. Para aprovechar tanto el marco RAG como el LLM ajustado, y también para reducir la alucinación, primero validamos semánticamente la pregunta entrante. Si la pregunta se encuentra entre los datos de entrenamiento para el ajuste fino (el modelo ajustado ya tiene el conocimiento para proporcionar una respuesta de alta calidad), entonces dirigimos la pregunta como un mensaje para inferir el modelo ajustado. De lo contrario, la pregunta pasa por LangChain y obtiene la respuesta de RAG. El siguiente diagrama ilustra este flujo de trabajo.
Probamos la arquitectura con un conjunto de datos de prueba de 166 preguntas, que contiene las 125 preguntas utilizadas para ajustar el modelo y 41 preguntas adicionales con las que el modelo ajustado no fue entrenado. El marco RAG con el modelo integrado y el modelo Falcon-7B ajustado proporcionó resultados de alta calidad con una puntuación ROUGE de 0.7898 y una puntuación de similitud semántica de 0.8781. Como se muestra en los siguientes ejemplos, el marco es capaz de generar respuestas a las preguntas de los usuarios que coinciden con los documentos de D&C.
La siguiente imagen es nuestro primer documento de ejemplo.

La siguiente captura de pantalla muestra la salida del bot.

El bot también puede responder con datos de una tabla o lista y mostrar cifras para las preguntas correspondientes. Por ejemplo, utilizamos el siguiente documento.

La siguiente captura de pantalla muestra la salida del bot.

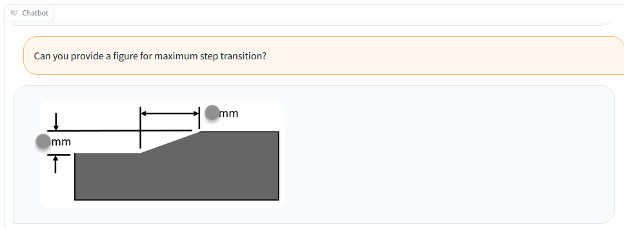
También podemos utilizar un documento con una figura, como en el siguiente ejemplo.

La siguiente captura de pantalla muestra la salida del bot con texto y la figura.

La siguiente captura de pantalla muestra la salida del bot con solo la figura.
Lecciones aprendidas y mejores prácticas
A través del diseño de la solución y los experimentos con múltiples LLM, aprendimos cómo garantizar la calidad y el rendimiento de la tarea de respuesta a preguntas en una solución de IA generativa. Recomendamos las siguientes mejores prácticas cuando aplique la solución a sus casos de uso de respuesta a preguntas:
- RAG proporciona respuestas razonables a preguntas de ingeniería. El rendimiento depende en gran medida de la incrustación e indexación de documentos. Para documentos muy desestructurados, es posible que necesite algo de trabajo manual para dividir y aumentar adecuadamente los documentos antes de incrustarlos e indexarlos con LLM.
- La búsqueda de índice es importante para determinar el resultado final de RAG. Debe ajustar adecuadamente el algoritmo de búsqueda para lograr un buen nivel de precisión y garantizar que RAG genere respuestas más relevantes.
- Los LLM perfeccionados pueden aprender conocimientos adicionales a partir de documentos altamente técnicos y no estructurados, y poseen el conocimiento dentro del modelo sin depender de los documentos después de la capacitación. Esto es especialmente útil para casos de uso en los que no se toleran las alucinaciones.
- Para garantizar la calidad de la respuesta del modelo, el formato del conjunto de datos de entrenamiento para el ajuste debe utilizar una plantilla de aviso específica de la tarea correctamente definida. El proceso de inferencia debe seguir el mismo modelo para generar respuestas similares a las humanas.
- Los LLM a menudo tienen un precio considerable y exigen recursos considerables y costos exorbitantes. Puede utilizar PEFT y LoRA y técnicas de cuantificación para reducir la demanda de potencia informática y evitar altos costos de capacitación e inferencia.
- SageMaker JumpStart proporciona LLM previamente capacitados y de fácil acceso para realizar ajustes, inferencias e implementación. Puede acelerar significativamente el diseño y la implementación de su solución de IA generativa.
Conclusión
Con el marco RAG y los LLM optimizados en SageMaker, podemos brindar respuestas similares a las humanas a las preguntas e indicaciones de los usuarios, lo que les permite recuperar de manera eficiente información precisa de un gran volumen de documentos altamente desestructurados y desorganizados. Continuaremos desarrollando la solución, como proporcionar un mayor nivel de respuesta contextual de interacciones anteriores y perfeccionar aún más los modelos a partir de la retroalimentación humana.
Sus comentarios son siempre bienvenidos; por favor deje sus pensamientos y preguntas en la sección de comentarios.
Sobre los autores
 Yunfeibai es arquitecto sénior de soluciones en AWS. Con experiencia en IA/ML, ciencia de datos y análisis, Yunfei ayuda a los clientes a adoptar los servicios de AWS para obtener resultados comerciales. Diseña soluciones de análisis de datos y AI/ML que superan desafíos técnicos complejos e impulsan objetivos estratégicos. Yunfei tiene un doctorado en Ingeniería Electrónica y Eléctrica. Fuera del trabajo, Yunfei disfruta de la lectura y la música.
Yunfeibai es arquitecto sénior de soluciones en AWS. Con experiencia en IA/ML, ciencia de datos y análisis, Yunfei ayuda a los clientes a adoptar los servicios de AWS para obtener resultados comerciales. Diseña soluciones de análisis de datos y AI/ML que superan desafíos técnicos complejos e impulsan objetivos estratégicos. Yunfei tiene un doctorado en Ingeniería Electrónica y Eléctrica. Fuera del trabajo, Yunfei disfruta de la lectura y la música.
 Burak Gozluklu es un arquitecto principal de soluciones especializado en ML ubicado en Boston, MA. Burak tiene más de 15 años de experiencia en la industria en modelado de simulación, ciencia de datos y tecnología ML. Ayuda a los clientes globales a adoptar tecnologías de AWS y específicamente soluciones de IA/ML para lograr sus objetivos comerciales. Burak tiene un doctorado en Ingeniería Aeroespacial de METU, una maestría en Ingeniería de Sistemas y un postdoctorado en dinámica de sistemas del MIT en Cambridge, MA. Burak es un apasionado del yoga y la meditación.
Burak Gozluklu es un arquitecto principal de soluciones especializado en ML ubicado en Boston, MA. Burak tiene más de 15 años de experiencia en la industria en modelado de simulación, ciencia de datos y tecnología ML. Ayuda a los clientes globales a adoptar tecnologías de AWS y específicamente soluciones de IA/ML para lograr sus objetivos comerciales. Burak tiene un doctorado en Ingeniería Aeroespacial de METU, una maestría en Ingeniería de Sistemas y un postdoctorado en dinámica de sistemas del MIT en Cambridge, MA. Burak es un apasionado del yoga y la meditación.
 Elad Dwek es gerente de tecnología de la construcción en Amazon. Con experiencia en construcción y gestión de proyectos, Elad ayuda a los equipos a adoptar nuevas tecnologías y procesos basados en datos para ejecutar proyectos de construcción. Identifica necesidades y soluciones, y facilita el desarrollo de atributos personalizados. Elad tiene un MBA y una licenciatura en Ingeniería Estructural. Fuera del trabajo, Elad disfruta del yoga, la carpintería y viajar con su familia.
Elad Dwek es gerente de tecnología de la construcción en Amazon. Con experiencia en construcción y gestión de proyectos, Elad ayuda a los equipos a adoptar nuevas tecnologías y procesos basados en datos para ejecutar proyectos de construcción. Identifica necesidades y soluciones, y facilita el desarrollo de atributos personalizados. Elad tiene un MBA y una licenciatura en Ingeniería Estructural. Fuera del trabajo, Elad disfruta del yoga, la carpintería y viajar con su familia.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/a-generative-ai-powered-solution-on-amazon-sagemaker-to-help-amazon-eu-design-and-construction/

