Contenido patrocinado
Por Jim Dowling, cofundador y director ejecutivo de Hopsworks
Este artículo presenta un patrón arquitectónico unificado para crear sistemas de aprendizaje automático (ML) por lotes y en tiempo real. Lo llamamos arquitectura de canalización FTI (Características, Capacitación, Inferencia). Los oleoductos FTI rompen el monolito Canalización de ML en 3 tuberías independientes, cada una con entradas y salidas claramente definidas, donde cada tubería se puede desarrollar, probar y operar de forma independiente. Para obtener una perspectiva histórica sobre la evolución de la arquitectura del FTI Pipeline, puede leer el artículo completo mapa mental en profundidad para MLOps .
En los últimos años, las operaciones de aprendizaje automático (MLOps) ha ganado popularidad como proceso de desarrollo, inspirado en los principios de DevOps, que introduce pruebas automatizadas, control de versiones de activos de aprendizaje automático y monitoreo operativo para permitir Sistemas de aprendizaje automático desarrollarse y desplegarse progresivamente. Sin embargo, los enfoques MLOps existentes a menudo presentan un panorama complejo y abrumador, lo que deja a muchos equipos luchando por recorrer el camino desde el desarrollo del modelo hasta la producción. En este artículo, presentamos una nueva perspectiva sobre la construcción de sistemas de aprendizaje automático a través del concepto de canalizaciones FTI. La arquitectura FTI ha permitido a innumerables desarrolladores crear sistemas de aprendizaje automático robustos con facilidad, reduciendo la carga cognitiva y fomentando una mejor colaboración entre equipos. Profundizamos en los principios básicos de los canales de FTI y exploramos sus aplicaciones en sistemas de aprendizaje automático por lotes y en tiempo real.
El enfoque FTI para este patrón arquitectónico se ha utilizado para crear cientos de sistemas ML. El patrón es el siguiente: un sistema de ML consta de tres canales de ML desarrollados y operados de forma independiente:
- una canalización de características que toma como entrada datos sin procesar que transforma en características (y etiquetas)
- un proceso de entrenamiento que toma como entrada características (y etiquetas) y genera un modelo entrenado, y
- un canal de inferencia que toma datos de nuevas características y un modelo entrenado y hace predicciones.
En esta FTI, no existe un único canal de lavado de dinero. La confusión sobre lo que hace el proceso de ML (¿incluye modelos de ingeniería y entrenamiento o también hace inferencias o solo uno de esos?) desaparece. La arquitectura FTI se aplica tanto a sistemas de ML por lotes como a sistemas de ML en tiempo real.

Figura 1: Canalizaciones de funciones, capacitación e inferencia (FTI) para crear sistemas de aprendizaje automático
La canalización de funciones puede ser un programa por lotes o un programa de transmisión por secuencias. El proceso de capacitación puede generar cualquier cosa, desde un modelo XGBoost simple hasta un modelo de lenguaje grande (LLM) ajustado con parámetros eficientes (PEFT), entrenado en muchas GPU. Finalmente, el canal de inferencia puede ser un programa por lotes que produce un lote de predicciones para un servicio en línea que recibe solicitudes de los clientes y devuelve predicciones en tiempo real.
Una gran ventaja de Los oleoductos FTI es que es una arquitectura abierta.. Puedes usar Python, Java o SQL. Si necesita realizar ingeniería de funciones en grandes volúmenes de datos, puede utilizar Spark, DBT o Beam. La capacitación generalmente se realizará en Python utilizando algún marco de aprendizaje automático, y la inferencia por lotes podría realizarse en Python o Spark, según sus volúmenes de datos. Sin embargo, los canales de inferencia en línea casi siempre están en Python, ya que los modelos normalmente se entrenan con Python.
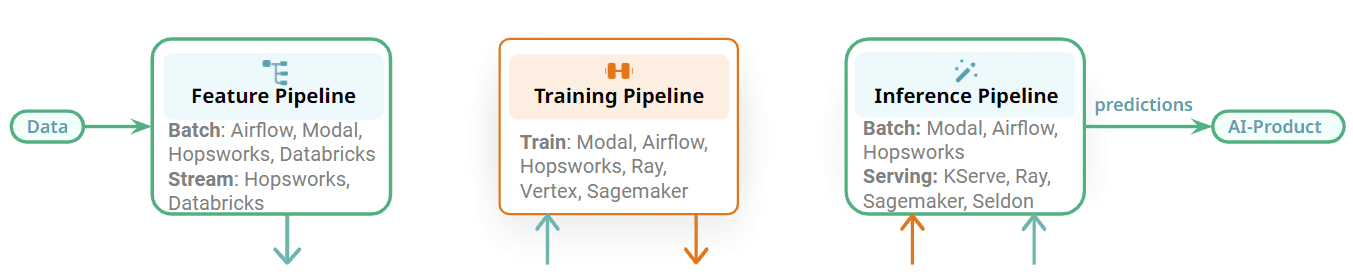
Figura 2: Elija el mejor orquestador para su canal/servicio de ML.
Los oleoductos de la FTI también son modulares y existe una interfaz clara entre las diferentes etapas. Cada oleoducto FTI puede operarse de forma independiente. En comparación con el canalización de aprendizaje automático monolítica, diferentes equipos ahora pueden ser responsables del desarrollo y operación de cada tubería. El impacto de esto es que para la orquestación, por ejemplo, un equipo podría usar un orquestador para una canalización de características y un equipo diferente podría usar un orquestador diferente para la canalización de inferencia por lotes. Como alternativa, podría utilizar el mismo orquestador para los tres canales FTI diferentes para un sistema de aprendizaje automático por lotes. Algunos ejemplos de orquestadores que se pueden usar en sistemas de aprendizaje automático incluyen orquestadores de uso general con muchas funciones, como Airflow, u orquestadores livianos, como Modal, u orquestadores administrados que ofrecen plataformas de funciones.
Sin embargo, algunos de los proyectos de la FTI no necesitarán orquestación. Los canales de capacitación se pueden ejecutar bajo demanda, cuando se necesita un nuevo modelo. Los canales de funciones de transmisión y los canales de inferencia en línea se ejecutan continuamente como servicios y no requieren orquestación. Flink, Spark Streaming y Beam se ejecutan como servicios en plataformas como Kubernetes, Databricks o Hopsworks. Los canales de inferencia en línea se implementan con su modelo en plataformas de servicio de modelos, como KServe (Hopsworks), Seldon, Sagemaker y Ray. La principal conclusión aquí es que los canales de ML son modulares con interfaces claras, lo que le permite elegir la mejor tecnología para ejecutar sus canales de FTI.
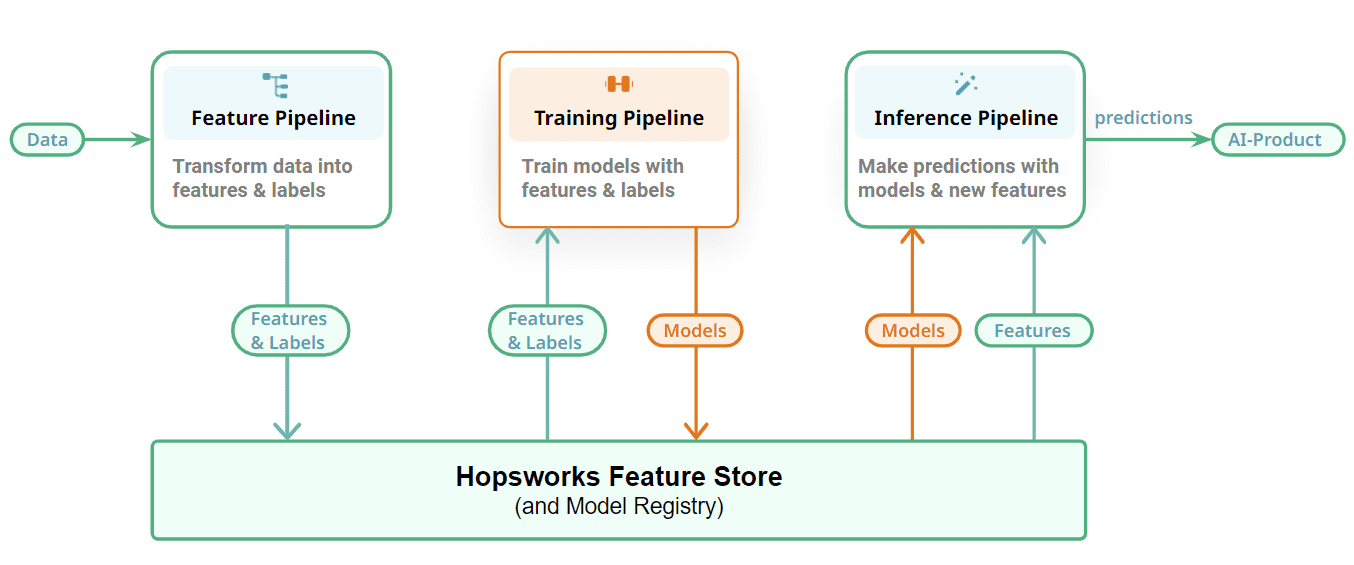
Figura 3: Conecte sus canalizaciones de aprendizaje automático con un almacén de funciones y un registro de modelos
Finalmente, mostramos cómo conectamos nuestros canales de FTI con una capa con estado para almacenar los artefactos de ML: características, datos de entrenamiento/prueba y modelos. Las canalizaciones de funciones almacenan sus resultados y funciones como DataFrames en el almacén de funciones. Las tablas incrementales almacenan cada nueva actualización/agregación/eliminación como confirmaciones separadas usando un formato de tabla (usamos Apache Hudi en fábricas de lúpulo). Los canales de capacitación leen instantáneas consistentes en un momento dado de los datos de capacitación de Hopsworks para entrenar modelos y enviar el modelo entrenado a un registro de modelos. Puede incluir su registro de modelos favorito aquí, pero estamos predispuestos hacia el registro de modelos de Hopsworks. Los canales de inferencia por lotes también leen instantáneas consistentes en un momento dado de los datos de inferencia del almacén de características y producen predicciones aplicando el modelo a los datos de inferencia. Los canales de inferencia en línea calculan funciones bajo demanda y leen funciones precalculadas del almacén de funciones para crear un vector de característica que se utiliza para hacer predicciones en respuesta a solicitudes de aplicaciones/servicios en línea.
Canalizaciones de funciones
Los canales de funciones leen datos de fuentes de datos, calculan funciones y los incorporan al almacén de funciones. Algunas de las preguntas que deben responderse para cualquier canal de funciones determinado incluyen:
- ¿La canalización de funciones es por lotes o por streaming?
- ¿Las ingestas de funciones son operaciones incrementales o de carga completa?
- ¿Qué marco/lenguaje se utiliza para implementar la canalización de funciones?
- ¿Se realiza una validación de datos en los datos de la característica antes de la ingesta?
- ¿Qué orquestador se utiliza para programar la canalización de funciones?
- Si algunas características ya han sido calculadas por un sistema ascendente (por ejemplo, un almacén de datos), ¿cómo se evita la duplicación de esos datos y solo se leen esas características al crear datos de entrenamiento o de inferencia por lotes?
Canalizaciones de formación
En los canales de capacitación, algunos de los detalles que se pueden descubrir al hacer doble clic son:
- ¿Qué marco/lenguaje se utiliza para implementar el proceso de capacitación?
- ¿Qué plataforma de seguimiento de experimentos se utiliza?
- ¿El proceso de capacitación se ejecuta según un cronograma (de ser así, qué orquestador se utiliza) o se ejecuta bajo demanda (por ejemplo, en respuesta a la degradación del rendimiento de un modelo)?
- ¿Se necesitan GPU para el entrenamiento? En caso afirmativo, ¿cómo se asignan a los canales de formación?
- ¿Qué codificación/escalado de funciones se realiza en qué funciones? (Por lo general, almacenamos datos de características sin codificar en el almacén de características, para que puedan usarse para EDA (análisis de datos exploratorios). La codificación/escalado se realiza de manera consistente en canales de entrenamiento e inferencia). Ejemplos de técnicas de codificación de características incluyen canalizaciones de aprendizaje de scikit o transformaciones declarativas en vistas de características (Obras de lúpulo).
- ¿Qué proceso de evaluación y validación de modelos se utiliza?
- ¿Qué registro de modelo se utiliza para almacenar los modelos entrenados?
Tuberías de inferencia
Los canales de inferencia son tan diversos como las aplicaciones que habilita la IA. En los canales de inferencia, algunos de los detalles que se pueden descubrir al hacer doble clic son:
- ¿Qué es el consumidor de predicciones (es un panel de control o una aplicación en línea) y cómo consume las predicciones?
- ¿Es un proceso de inferencia por lotes o en línea?
- ¿Qué tipo de codificación/escalado de funciones se realiza en qué funciones?
- Para una canalización de inferencia por lotes, ¿qué marco/lenguaje se utiliza? ¿Qué orquestador se utiliza para ejecutarlo según una programación? ¿Qué sumidero se utiliza para consumir las predicciones producidas?
- Para una canalización de inferencia en línea, ¿qué servidor de servicio de modelos se utiliza para alojar el modelo implementado? ¿Cómo se implementa el proceso de inferencia en línea: como una clase de predictor o con un paso de transformador separado? ¿Se necesitan GPU para la inferencia? ¿Existe un SLA (acuerdos de nivel de servicio) sobre cuánto tiempo se tarda en responder a las solicitudes de predicción?
El mantra existente es que MLOps se trata de automatizar la integración continua (CI), la entrega continua (CD) y la capacitación continua (CT) para sistemas ML. Pero esto es demasiado abstracto para muchos desarrolladores. MLOps realmente trata sobre el desarrollo continuo de productos habilitados para ML que evolucionan con el tiempo. Los datos de entrada disponibles (características) cambian con el tiempo, el objetivo que intenta predecir cambia con el tiempo. Necesita realizar cambios en el código fuente y desea asegurarse de que cualquier cambio que realice no rompa su sistema ML ni degrade su rendimiento. Y desea acelerar el tiempo necesario para realizar esos cambios y realizar pruebas antes de que esos cambios se implementen automáticamente en producción.
Entonces, desde nuestra perspectiva, una definición más concisa de MLOps que permite que los sistemas ML evolucionen de manera segura con el tiempo es que requiere, como mínimo, pruebas, control de versiones y monitoreo automatizados de los artefactos ML. MLOps se trata de pruebas, control de versiones y monitoreo automatizados de artefactos de aprendizaje automático.
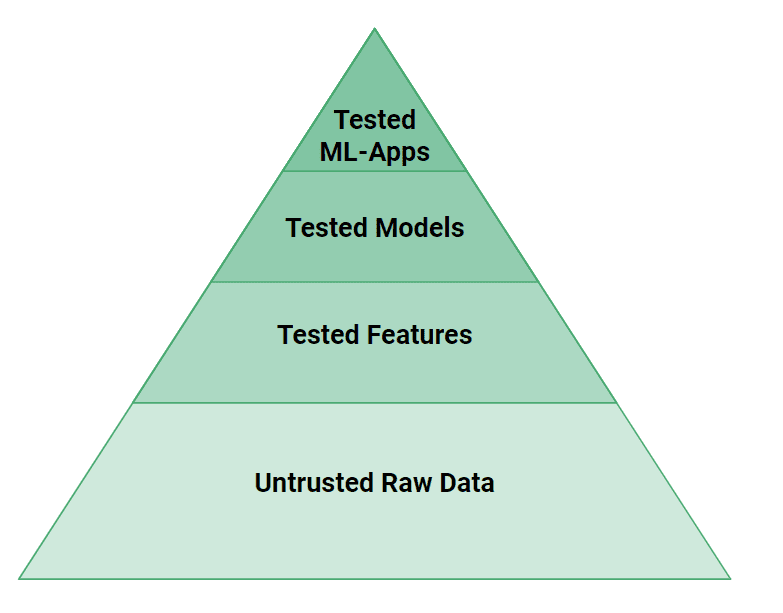
Figura 4: La pirámide de pruebas para artefactos de aprendizaje automático
En la figura 4, podemos ver que se necesitan más niveles de prueba en los sistemas ML que en los sistemas de software tradicionales. Pequeños errores en los datos o el código pueden provocar fácilmente que un modelo de aprendizaje automático haga predicciones incorrectas. Desde una perspectiva de prueba, si las aplicaciones web son aviones propulsados por hélice, los sistemas ML son motores a reacción. Se necesita un importante esfuerzo de ingeniería para probar y validar los sistemas ML para que sean seguros.
A alto nivel, necesitamos probar tanto el código fuente como los datos de ML Systems. Se puede probar la lógica de las características creadas por los canales de características con pruebas unitarias y verificar sus datos de entrada con pruebas de validación de datos (p. ej., Grandes expectativas). Es necesario probar el rendimiento de los modelos, pero también la falta de sesgo contra grupos conocidos de usuarios vulnerables. Finalmente, en la cima de la pirámide, ML-Systems necesita probar su rendimiento con pruebas A/B antes de poder cambiar y utilizar un nuevo modelo.
Finalmente, necesitamos versionar los artefactos de ML para que los operadores de sistemas de ML puedan actualizar y revertir de forma segura las versiones de los modelos implementados. El soporte del sistema para la actualización o degradación de modelos mediante botones es uno de los santos griales de MLOps. Pero los modelos necesitan características para hacer predicciones, por lo que las versiones del modelo están conectadas a las versiones de características y los modelos y características deben actualizarse o degradarse sincrónicamente. Afortunadamente, no necesita un año de rotación como Google SRE para actualizar o degradar fácilmente los modelos: el soporte de plataforma para artefactos de ML versionados debería hacer que esta sea una operación de mantenimiento del sistema de ML sencilla.
A continuación se muestra una muestra de algunos de los sistemas de aprendizaje automático de código abierto disponibles integrados en la arquitectura FTI. Han sido construidos en su mayoría por practicantes y estudiantes.
Sistemas de aprendizaje automático por lotes
Sistema de aprendizaje automático en tiempo real
Este artículo presenta la arquitectura de canalización de FTI para MLOps, que ha permitido a numerosos desarrolladores crear y mantener sistemas de aprendizaje automático de manera eficiente. Según nuestra experiencia, esta arquitectura reduce significativamente la carga cognitiva asociada con el diseño y la explicación de sistemas de aprendizaje automático, especialmente en comparación con los enfoques tradicionales de MLOps. En entornos corporativos, fomenta una mejor comunicación entre equipos al establecer interfaces claras, promoviendo así la colaboración y acelerando el desarrollo de sistemas de aprendizaje automático de alta calidad. Si bien simplifica la complejidad general, también permite una exploración en profundidad de los oleoductos individuales. Nuestro objetivo para la arquitectura del canal FTI es facilitar un mejor trabajo en equipo y una implementación más rápida del modelo, acelerando en última instancia la transformación social impulsada por la IA.
Lea más sobre los principios y elementos fundamentales que constituyen la arquitectura de FTI Pipelines en nuestro completo mapa mental en profundidad para MLOps.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/2023/09/hopsworks-unify-batch-ml-systems-feature-training-inference-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=unify-batch-and-ml-systems-with-feature-training-inference-pipelines

