Las empresas utilizan cada vez más el aprendizaje automático (ML) para tomar decisiones casi en tiempo real, como colocar un anuncio, asignar un conductor, recomendar un producto o incluso fijar precios de productos y servicios de forma dinámica. Los modelos ML hacen predicciones dado un conjunto de datos de entrada conocido como Características, y los científicos de datos dedican fácilmente más del 60 % de su tiempo a diseñar y crear estas características. Además, las predicciones altamente precisas dependen del acceso oportuno a los valores de las características que cambian rápidamente con el tiempo, lo que agrega aún más complejidad al trabajo de crear una solución precisa y de alta disponibilidad. Por ejemplo, un modelo para una aplicación de viajes compartidos puede elegir el mejor precio para un viaje desde el aeropuerto, pero solo si conoce la cantidad de solicitudes de viaje recibidas en los últimos 10 minutos y la cantidad de pasajeros proyectados para aterrizar en los próximos 10 minutos. XNUMX minutos. Un modelo de enrutamiento en una aplicación de centro de llamadas puede elegir el mejor agente disponible para una llamada entrante, pero solo es efectivo si conoce los últimos clics de la sesión web del cliente.
Si bien el valor comercial de las predicciones de ML casi en tiempo real es enorme, la arquitectura requerida para entregarlas de manera confiable, segura y con buen rendimiento es complicada. Las soluciones necesitan actualizaciones de alto rendimiento y recuperación de baja latencia de los valores de características más recientes en milisegundos, algo que la mayoría de los científicos de datos no están preparados para ofrecer. Como resultado, algunas empresas han gastado millones de dólares en inventar su propia infraestructura patentada para la gestión de funciones. Otras empresas han limitado sus aplicaciones de ML a patrones más simples, como la puntuación por lotes, hasta que los proveedores de ML proporcionen soluciones listas para usar más completas para las tiendas de características en línea.
Para abordar estos desafíos, Tienda de funciones de Amazon SageMaker proporciona un repositorio central completamente administrado para funciones de ML, lo que facilita el almacenamiento y la recuperación de funciones de forma segura sin tener que crear y mantener su propia infraestructura. Feature Store le permite definir grupos de funciones, usar la ingestión por lotes y la ingestión de transmisión, recuperar los valores de funciones más recientes con una latencia de milisegundos de un solo dígito para obtener predicciones en línea de alta precisión y extraer conjuntos de datos correctos en un punto en el tiempo para el entrenamiento. En lugar de crear y mantener estas capacidades de infraestructura, obtiene un servicio completamente administrado que se escala a medida que crecen sus datos, permite compartir funciones entre equipos y permite que sus científicos de datos se centren en crear excelentes modelos de ML destinados a casos de uso comercial que cambian el juego. Los equipos ahora pueden ofrecer características sólidas una vez y reutilizarlas muchas veces en una variedad de modelos que pueden construir diferentes equipos.
Esta publicación muestra un ejemplo completo de cómo puede combinar la ingeniería de funciones de transmisión con Feature Store para tomar decisiones respaldadas por ML casi en tiempo real. Mostramos un caso de uso de detección de fraude con tarjetas de crédito que actualiza funciones agregadas a partir de una transmisión en vivo de transacciones y utiliza recuperaciones de funciones de baja latencia para ayudar a detectar transacciones fraudulentas. Pruébelo usted mismo visitando nuestro Repositorio GitHub.
Caso de uso de fraude con tarjeta de crédito
Los números de tarjetas de crédito robados se pueden comprar a granel en la web oscura de filtraciones anteriores o ataques de organizaciones que almacenan esta información confidencial. Los estafadores compran estas listas de tarjetas e intentan realizar tantas transacciones como sea posible con los números robados hasta que se bloquee la tarjeta. Estos ataques de fraude generalmente ocurren en un período corto de tiempo, y esto se puede detectar fácilmente en transacciones históricas porque la velocidad de las transacciones durante el ataque difiere significativamente del patrón de gasto habitual del titular de la tarjeta.
La siguiente tabla muestra una secuencia de transacciones de una tarjeta de crédito donde el titular de la tarjeta primero tiene un patrón de gasto genuino y luego experimenta un ataque de fraude a partir del 4 de noviembre.
| núm_cc | trans_tiempo | cantidad | etiqueta_fraude |
| ... 1248 | 01-nov 14:50:01 | 10.15 | 0 |
| ... 1248 | 02-nov 12:14:31 | 32.45 | 0 |
| ... 1248 | 02-nov 16:23:12 | 3.12 | 0 |
| ... 1248 | 04-nov 02:12:10 | 1.01 | 1 |
| ... 1248 | 04-nov 02:13:34 | 22.55 | 1 |
| ... 1248 | 04-nov 02:14:05 | 90.55 | 1 |
| ... 1248 | 04-nov 02:15:10 | 60.75 | 1 |
| ... 1248 | 04-nov 13:30:55 | 12.75 | 0 |
Para esta publicación, entrenamos un modelo ML para detectar este tipo de comportamiento mediante características de ingeniería que describen el patrón de gasto de una tarjeta individual, como la cantidad de transacciones o el monto promedio de transacción de esa tarjeta en un período de tiempo determinado. Este modelo protege a los tarjetahabientes del fraude en el punto de venta al detectar y bloquear transacciones sospechosas antes de que se pueda completar el pago. El modelo hace predicciones en un contexto en tiempo real de baja latencia y se basa en recibir cálculos de características actualizados al minuto para que pueda responder a un ataque de fraude en curso. En un escenario del mundo real, las funciones relacionadas con los patrones de gasto del titular de la tarjeta solo formarían parte del conjunto de funciones del modelo, y podemos incluir información sobre el comerciante, el titular de la tarjeta, el dispositivo utilizado para realizar el pago y cualquier otro dato que pueda ser relevante para la detección del fraude.
Debido a que nuestro caso de uso se basa en perfilar los patrones de gasto de una tarjeta individual, es crucial que podamos identificar las tarjetas de crédito en un flujo de transacciones. La mayoría de los conjuntos de datos de detección de fraude disponibles públicamente no proporcionan esta información, por lo que usamos Python Falsificador biblioteca para generar un conjunto de transacciones que cubren un período de 5 meses. Este conjunto de datos contiene 5.4 millones de transacciones repartidas en 10,000 0.25 números de tarjetas de crédito únicos (y falsos), y está intencionalmente desequilibrado para que coincida con la realidad del fraude con tarjetas de crédito (solo el XNUMX % de las transacciones son fraudulentas). Variamos el número de transacciones por día por tarjeta, así como los montos de las transacciones. Vea nuestro Repositorio GitHub para más información.
Resumen de la solución
Queremos que nuestro modelo de detección de fraude clasifique las transacciones de tarjetas de crédito al notar una ráfaga de transacciones recientes que difiere significativamente del patrón de gastos habitual del titular de la tarjeta. Suena bastante simple, pero ¿cómo lo construimos?
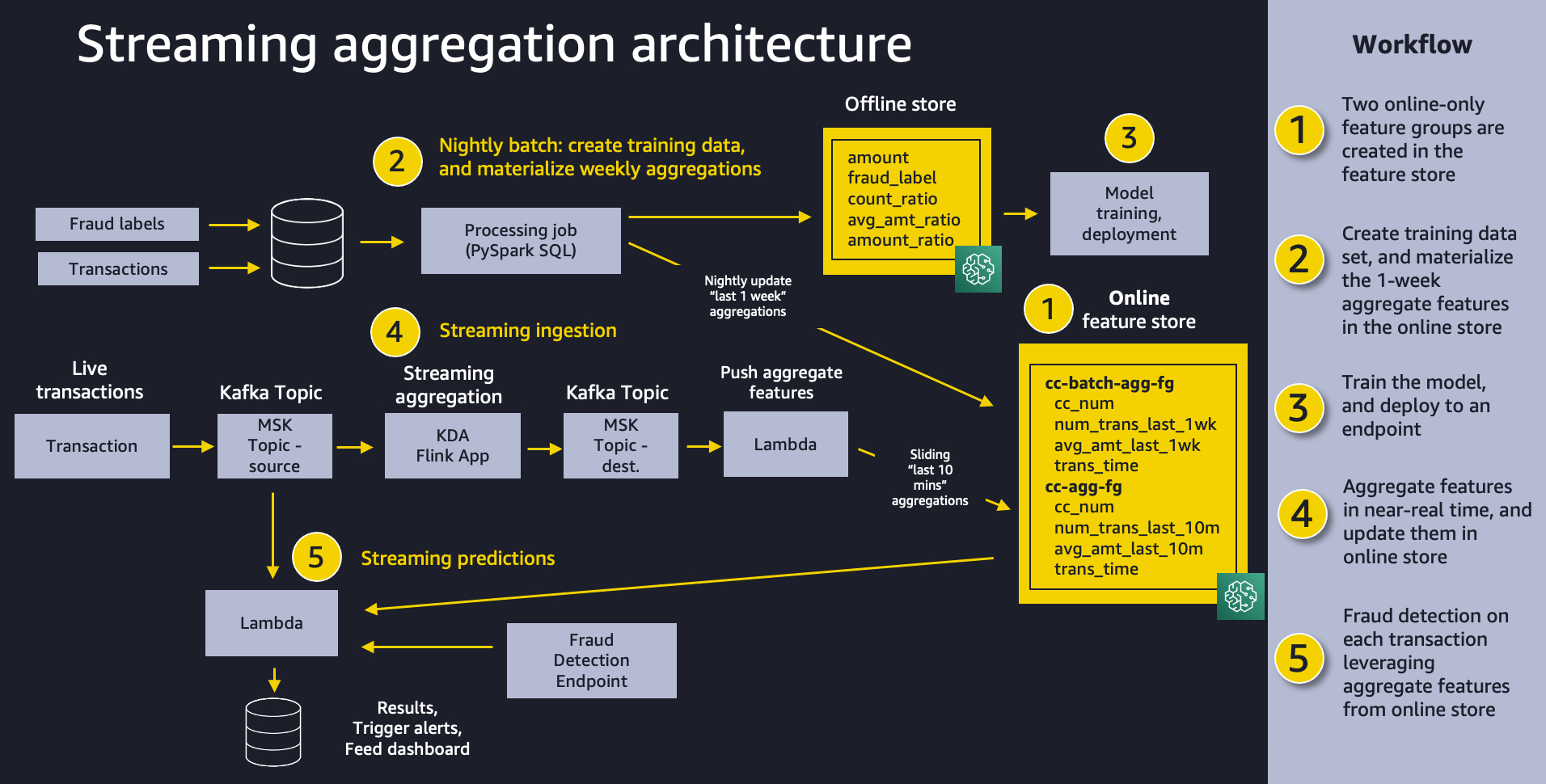
El siguiente diagrama muestra la arquitectura general de nuestra solución. Creemos que este mismo patrón funcionará bien para una variedad de casos de uso de agregación de transmisión. En un nivel alto, el patrón involucra las siguientes cinco piezas:
- Tienda de características – Utilizamos Feature Store para proporcionar un repositorio de funciones con escrituras de alto rendimiento y lecturas seguras de baja latencia, utilizando valores de funciones que se organizan en varios grupos de funciones.
- Ingestión de lotes – La ingestión por lotes toma transacciones de tarjetas de crédito históricas etiquetadas y crea las características y proporciones agregadas necesarias para entrenar el modelo de detección de fraude. Usamos un Procesamiento de Amazon SageMaker trabajo y el Contenedor Spark incorporado para calcular los recuentos semanales agregados y los promedios de los montos de las transacciones e incorporarlos a la tienda de características para usarlos en la inferencia en línea.
- Entrenamiento e implementación de modelos – Este aspecto de nuestra solución es sencillo. Usamos Amazon SageMaker para entrenar un modelo usando el algoritmo XGBoost incorporado en características agregadas creadas a partir de transacciones históricas. El modelo se implementa en un punto final de SageMaker, donde maneja las solicitudes de detección de fraude en transacciones en vivo.
- Transmisión de ingestión - Un Análisis de datos de Amazon Kinesis para la aplicación Apache Flink respaldada por temas de Apache Kafka en Amazon Managed Streaming para Apache Kafka (MSK) (Amazon MSK) calcula características agregadas a partir de un flujo de transacciones y un AWS Lambda La función actualiza la tienda de características en línea. Apache Flink es un marco y motor popular para procesar flujos de datos.
- Predicciones de transmisión – Por último, hacemos predicciones de fraude en un flujo de transacciones, utilizando Lambda para extraer funciones agregadas de la tienda de funciones en línea. Usamos los últimos datos de características para calcular las proporciones de transacciones y luego llamamos al punto final de detección de fraude.
Requisitos previos
Proporcionamos un Formación en la nube de AWS plantilla para crear los recursos necesarios para esta solución. La siguiente tabla enumera las pilas disponibles para diferentes regiones.
En las siguientes secciones, exploramos cada componente de nuestra solución con más detalle.
Tienda de características
Los modelos de ML se basan en funciones bien diseñadas que provienen de una variedad de fuentes de datos, con transformaciones tan simples como cálculos o tan complicadas como una canalización de varios pasos que requiere horas de tiempo de cómputo y codificación compleja. Feature Store permite la reutilización de estas funciones entre equipos y modelos, lo que mejora la productividad de los científicos de datos, acelera el tiempo de comercialización y garantiza la coherencia de la entrada del modelo.
Cada característica dentro de Feature Store está organizada en una agrupación lógica llamada grupo de características. Tú decides qué grupos de funciones necesitas para tus modelos. Cada uno puede tener docenas, cientos o incluso miles de funciones. Los grupos de funciones se administran y escalan de forma independiente, pero todos están disponibles para la búsqueda y el descubrimiento en equipos de científicos de datos responsables de muchos modelos de aprendizaje automático independientes y casos de uso.
Los modelos de AA a menudo requieren funciones de varios grupos de funciones. Un aspecto clave de un grupo de características es la frecuencia con la que sus valores de características deben actualizarse o materializarse para la inferencia o el entrenamiento posterior. Actualiza algunas funciones cada hora, cada noche o semanalmente, y un subconjunto de funciones debe transmitirse a la tienda de funciones casi en tiempo real. La transmisión de todas las actualizaciones de funciones generaría una complejidad innecesaria e incluso podría reducir la calidad de las distribuciones de datos al no brindarle la oportunidad de eliminar valores atípicos.
En nuestro caso de uso, creamos un grupo de funciones llamado cc-agg-batch-fg para funciones agregadas de tarjetas de crédito actualizadas por lotes, y una llamada cc-agg-fg para funciones de transmisión.
La cc-agg-batch-fg El grupo de funciones se actualiza todas las noches y proporciona funciones agregadas que miran hacia atrás en una ventana de tiempo de 1 semana. Volver a calcular las agregaciones de 1 semana en las transacciones de transmisión no ofrece señales significativas y sería una pérdida de recursos.
Por el contrario, nuestro cc-agg-fg El grupo de funciones debe actualizarse de forma continua, ya que ofrece los últimos recuentos de transacciones y los montos promedio de transacciones en una ventana de tiempo de 10 minutos. Sin agregación de transmisión, no pudimos detectar el patrón típico de ataque de fraude de una secuencia rápida de compras.
Al aislar las funciones que se recalculan cada noche, podemos mejorar el rendimiento de ingestión de nuestras funciones de transmisión. La separación nos permite optimizar la ingesta para cada grupo de forma independiente. Cuando diseñe para sus casos de uso, tenga en cuenta que los modelos que requieren funciones de una gran cantidad de grupos de funciones pueden querer realizar múltiples recuperaciones del almacén de funciones en paralelo para evitar agregar una latencia excesiva a un flujo de trabajo de predicción en tiempo real.
Los grupos de características para nuestro caso de uso se muestran en la siguiente tabla.
| cc-agg-fg | cc-agg-lote-fg |
| cc_num (identificación del registro) | cc_num (identificación del registro) |
| trans_tiempo | trans_tiempo |
| núm_trans_último_10m | num_trans_last_1w |
| avg_amt_last_10m | avg_amt_last_1w |
Cada grupo de funciones debe tener una función utilizada como identificador de registro (para esta publicación, el número de tarjeta de crédito). El identificador de registro actúa como clave principal para el grupo de funciones, lo que permite búsquedas rápidas y uniones entre grupos de funciones. También se requiere una función de tiempo de evento, que permite que la tienda de funciones realice un seguimiento del historial de valores de funciones a lo largo del tiempo. Esto se vuelve importante cuando se mira hacia atrás en el estado de las características en un momento específico.
En cada grupo de funciones, rastreamos la cantidad de transacciones por tarjeta de crédito única y el monto promedio de la transacción. La única diferencia entre nuestros dos grupos es la ventana de tiempo utilizada para la agregación. Usamos una ventana de 10 minutos para la agregación de transmisión y una ventana de 1 semana para la agregación por lotes.
Con Feature Store, tiene la flexibilidad de crear grupos de funciones que están solo fuera de línea, solo en línea o tanto en línea como fuera de línea. Una tienda en línea proporciona escrituras de alto rendimiento y recuperaciones de valores de características de baja latencia, lo que es ideal para la inferencia en línea. Se proporciona una tienda fuera de línea usando Servicio de almacenamiento simple de Amazon (Amazon S3), brindando a las empresas un repositorio altamente escalable, con un historial completo de valores de características, particionado por grupo de características. La tienda fuera de línea es ideal para casos de uso de capacitación y puntuación por lotes.
Cuando habilita un grupo de funciones para proporcionar tiendas tanto en línea como fuera de línea, SageMaker sincroniza automáticamente los valores de las funciones con una tienda fuera de línea, agregando continuamente los valores más recientes para brindarle un historial completo de valores a lo largo del tiempo. Otro beneficio de los grupos de funciones que están tanto en línea como fuera de línea es que ayudan a evitar el problema del sesgo de entrenamiento e inferencia. SageMaker le permite alimentar tanto el entrenamiento como la inferencia con los mismos valores de características transformados, lo que garantiza la coherencia para generar predicciones más precisas. El objetivo de nuestra publicación es demostrar la transmisión de funciones en línea, por lo que implementamos grupos de funciones solo en línea.
Ingestión de lotes
Para materializar nuestras funciones por lotes, creamos una canalización de funciones que se ejecuta como un trabajo de procesamiento de SageMaker todas las noches. El trabajo tiene dos responsabilidades: producir el conjunto de datos para entrenar nuestro modelo y completar el grupo de funciones por lotes con los valores más actualizados para las funciones agregadas de 1 semana, como se muestra en el siguiente diagrama.

Cada transacción histórica utilizada en el conjunto de capacitación se enriquece con características agregadas para la tarjeta de crédito específica involucrada en la transacción. Analizamos dos ventanas de tiempo deslizantes separadas: una semana atrás y los 1 minutos anteriores. Las características reales utilizadas para entrenar el modelo incluyen las siguientes proporciones de estos valores agregados:
- amt_ratio1 =
avg_amt_last_10m / avg_amt_last_1w - amt_ratio2 =
transaction_amount / avg_amt_last_1w - proporción_de_recuento =
num_trans_last_10m / num_trans_last_1w
Por ejemplo, count_ratio es el recuento de transacciones de los 10 minutos anteriores dividido por el recuento de transacciones de la última semana.
Nuestro modelo ML puede aprender patrones de actividad normal frente a actividad fraudulenta a partir de estas proporciones, en lugar de depender de recuentos sin procesar y montos de transacciones. Los patrones de gasto en diferentes tarjetas varían mucho, por lo que las proporciones normalizadas brindan una mejor señal para el modelo que las cantidades agregadas en sí mismas.
Es posible que se pregunte por qué nuestro trabajo por lotes está computando funciones con una retrospectiva de 10 minutos. ¿No es eso solo relevante para la inferencia en línea? Necesitamos la ventana de 10 minutos en las transacciones históricas para crear un conjunto de datos de entrenamiento preciso. Esto es fundamental para garantizar la coherencia con la ventana de transmisión de 10 minutos que se utilizará casi en tiempo real para respaldar la inferencia en línea.
El conjunto de datos de entrenamiento resultante del trabajo de procesamiento se puede guardar directamente como un CSV para el entrenamiento de modelos, o se puede ingerir de forma masiva en un grupo de características fuera de línea que se puede usar para otros modelos y por otros equipos de ciencia de datos para abordar una amplia variedad de otros casos de uso. Por ejemplo, podemos crear y completar un grupo de características llamado cc-transactions-fg. Luego, nuestro trabajo de capacitación puede extraer un conjunto de datos de capacitación específico según las necesidades de nuestro modelo específico, seleccionando rangos de fechas específicos y un subconjunto de características de interés. Este enfoque permite a varios equipos reutilizar grupos de funciones y mantener menos canalizaciones de funciones, lo que genera importantes ahorros de costes y mejoras de productividad a lo largo del tiempo. Este cuaderno de ejemplo demuestra el patrón de uso de Feature Store como un repositorio central desde el cual los científicos de datos pueden extraer conjuntos de datos de entrenamiento.
Además de crear un conjunto de datos de entrenamiento, usamos el PutRecord API para poner las agregaciones de funciones de 1 semana en la tienda de funciones en línea todas las noches. El siguiente código muestra cómo colocar un registro en un grupo de funciones en línea dados valores de funciones específicos, incluido un identificador de registro y una hora de evento:
Los ingenieros de ML a menudo crean una versión separada del código de ingeniería de funciones para las funciones en línea basadas en el código original escrito por los científicos de datos para el entrenamiento del modelo. Esto puede ofrecer el rendimiento deseado, pero es un paso de desarrollo adicional e introduce más posibilidades de formación e inferencia sesgada. En nuestro caso de uso, mostramos cómo el uso de SQL para agregaciones puede permitir que un científico de datos proporcione el mismo código tanto para lotes como para transmisión.
Transmisión de ingestión
Feature Store ofrece recuperación de milisegundos de un solo dígito de funciones precalculadas, y también puede desempeñar un papel eficaz en soluciones que requieren ingesta de transmisión. Nuestro caso de uso demuestra ambos. La retrospectiva semanal se maneja como un grupo de características precalculado, que se materializa todas las noches como se mostró anteriormente. Ahora profundicemos en cómo calculamos las características agregadas sobre la marcha durante una ventana de 10 minutos y las incorporamos en el almacén de características para una posterior inferencia en línea.
En nuestro caso de uso, incorporamos transacciones de tarjetas de crédito en vivo a un tema de MSK de origen y usamos una aplicación Kinesis Data Analytics for Apache Flink para crear características agregadas en un tema de MSK de destino. La aplicación está escrita usando Apache FlinkSQL. Flink SQL simplifica el desarrollo de aplicaciones de transmisión mediante SQL estándar. Es fácil aprender Flink si alguna vez ha trabajado con una base de datos o un sistema similar a SQL si cumple con ANSI-SQL 2011. Además de SQL, podemos construir aplicaciones Java y Scala en Análisis de datos de Amazon Kinesis utilizando bibliotecas de código abierto basadas en Apache Flink. Luego usamos una función de Lambda para leer el tema de MSK de destino e ingerir las funciones agregadas en un grupo de funciones de SageMaker para la inferencia. Crear la aplicación Apache Flink utilizando la API SQL de Flink es sencillo. Usamos Flink SQL para agregar los datos de transmisión en el tema MSK de origen y almacenarlos en un tema MSK de destino.
Para producir recuentos agregados y cantidades promedio mirando hacia atrás en una ventana de 10 minutos, usamos la siguiente consulta Flink SQL en el tema de entrada y canalizamos los resultados al tema de destino:
| núm_cc | cantidad | datetime | núm_trans_último_10m | avg_amt_last_10m |
| ... 1248 | 50.00 | Nov-01,22: 01: 00 | 1 | 74.99 |
| ... 9843 | 99.50 | Nov-01,22: 02: 30 | 1 | 99.50 |
| ... 7403 | 100.00 | Nov-01,22: 03: 48 | 1 | 100.00 |
| ... 1248 | 200.00 | Nov-01,22: 03: 59 | 2 | 125.00 |
| ... 0732 | 26.99 | 01 de noviembre, 22:04:15 | 1 | 26.99 |
| ... 1248 | 50.00 | Nov-01,22: 04: 28 | 3 | 100.00 |
| ... 1248 | 500.00 | Nov-01,22: 05: 05 | 4 | 200.00 |
En este ejemplo, observe que la última fila tiene un recuento de cuatro transacciones en los últimos 10 minutos desde la tarjeta de crédito que termina en 1248 y un monto de transacción promedio correspondiente de $ 200.00. La consulta SQL es coherente con la utilizada para impulsar la creación de nuestro conjunto de datos de entrenamiento, lo que ayuda a evitar el sesgo de entrenamiento y de inferencia.
A medida que las transacciones se transmiten a la aplicación de agregación Kinesis Data Analytics for Apache Flink, la aplicación envía los resultados agregados a nuestra función Lambda, como se muestra en el siguiente diagrama. La función Lambda toma estas características y completa el cc-agg-fg grupo de características.

Enviamos los valores de funciones más recientes al almacén de funciones desde Lambda mediante una simple llamada a la API de PutRecord. La siguiente es la pieza central del código de Python para almacenar las características agregadas:
Preparamos el registro como una lista de pares de valores con nombre, incluida la hora actual como la hora del evento. La API de Feature Store garantiza que este nuevo registro siga el esquema que identificamos cuando creamos el grupo de funciones. Si ya existía un registro para esta clave principal, ahora se sobrescribe en la tienda en línea.
Predicciones de transmisión
Ahora que contamos con ingestión de transmisión para mantener la tienda de funciones actualizada con los valores de funciones más recientes, veamos cómo hacemos predicciones de fraude.
Creamos una segunda función de Lambda que utiliza el tema MSK de origen como disparador. Para cada nuevo evento de transacción, la función de Lambda primero recupera las funciones por lotes y de transmisión de Feature Store. Para detectar anomalías en el comportamiento de las tarjetas de crédito, nuestro modelo busca picos en los montos de las compras recientes o en la frecuencia de las compras. La función Lambda calcula proporciones simples entre las agregaciones de 1 semana y las agregaciones de 10 minutos. Luego invoca el extremo del modelo de SageMaker usando esos índices para hacer la predicción de fraude, como se muestra en el siguiente diagrama.

Usamos el siguiente código para recuperar valores de características a pedido de la tienda de características antes de llamar al punto final del modelo de SageMaker:
SageMaker también admite la recuperación de varios registros de características con un llamada única, incluso si son de diferentes grupos de funciones.
Finalmente, con el vector de características de entrada del modelo ensamblado, llamamos al extremo del modelo para predecir si una transacción de tarjeta de crédito específica es fraudulenta. SageMaker también admite la recuperación de varios registros de funciones con una sola llamada, incluso si pertenecen a diferentes grupos de funciones.
sagemaker_runtime = boto3.client(service_name='runtime.sagemaker')
request_body = ','.join(features)
response = sagemaker_runtime.invoke_endpoint( EndpointName=ENDPOINT_NAME, ContentType='text/csv', Body=request_body)
probability = json.loads(response['Body'].read().decode('utf-8'))En este ejemplo, el modelo arrojó una probabilidad del 98 % de que la transacción específica fuera fraudulenta y pudo usar funciones de entrada agregadas casi en tiempo real basadas en los 10 minutos más recientes de transacciones en esa tarjeta de crédito.
Probar la solución de extremo a extremo
Para demostrar el flujo de trabajo completo e integral de nuestra solución, simplemente enviamos las transacciones con tarjeta de crédito a nuestro tema de origen MSK. Nuestra agregación automatizada de Kinesis Data Analytics para Apache Flink toma el control desde allí, manteniendo una vista casi en tiempo real de los recuentos y montos de transacciones en Feature Store, con una ventana retrospectiva deslizante de 10 minutos. Estas funciones se combinan con las funciones agregadas de 1 semana que ya se incorporaron a la tienda de funciones por lotes, lo que nos permite hacer predicciones de fraude en cada transacción.
Enviamos una sola transacción desde tres tarjetas de crédito diferentes. Luego simulamos un ataque de fraude en una cuarta tarjeta de crédito enviando muchas transacciones consecutivas en segundos. El resultado de nuestra función Lambda se muestra en la siguiente captura de pantalla. Como era de esperar, las primeras tres transacciones únicas se prevén como NOT FRAUD. De las 10 transacciones fraudulentas, la primera se prevé como NOT FRAUD, y el resto están correctamente identificados como FRAUD. Observe cómo las características agregadas se mantienen actualizadas, lo que ayuda a generar predicciones más precisas.

Conclusión
Hemos demostrado cómo Feature Store puede desempeñar un papel clave en la arquitectura de la solución para flujos de trabajo operativos críticos que necesitan agregación de transmisión e inferencia de baja latencia. Con una tienda de características lista para la empresa, puede usar la ingestión por lotes y la ingestión de transmisión para alimentar grupos de características y acceder a valores de características a pedido para realizar predicciones en línea para un valor comercial significativo. Las funciones de ML ahora se pueden compartir a escala entre muchos equipos de científicos de datos y miles de modelos de ML, lo que mejora la consistencia de los datos, la precisión del modelo y la productividad de los científicos de datos. Feature Store ya está disponible y puede probarlo ejemplo completo. Háganos saber lo que piensas.
Un agradecimiento especial a todos los que contribuyeron a la anterior entrada del blog con una arquitectura similar: Paul Hargis, James Leoni y Arunprasath Shankar.
Acerca de los autores
 marca roy es Arquitecto Principal de Aprendizaje Automático de AWS, que ayuda a los clientes a diseñar y crear soluciones de IA/ML. El trabajo de Mark cubre una amplia gama de casos de uso de ML, con un interés principal en tiendas de características, visión artificial, aprendizaje profundo y escalado de ML en toda la empresa. Ha ayudado a empresas en muchas industrias, incluidas las de seguros, servicios financieros, medios y entretenimiento, atención médica, servicios públicos y manufactura. Mark posee seis certificaciones de AWS, incluida la Certificación de especialidad de ML. Antes de unirse a AWS, Mark fue arquitecto, desarrollador y líder tecnológico durante más de 25 años, incluidos 19 años en servicios financieros.
marca roy es Arquitecto Principal de Aprendizaje Automático de AWS, que ayuda a los clientes a diseñar y crear soluciones de IA/ML. El trabajo de Mark cubre una amplia gama de casos de uso de ML, con un interés principal en tiendas de características, visión artificial, aprendizaje profundo y escalado de ML en toda la empresa. Ha ayudado a empresas en muchas industrias, incluidas las de seguros, servicios financieros, medios y entretenimiento, atención médica, servicios públicos y manufactura. Mark posee seis certificaciones de AWS, incluida la Certificación de especialidad de ML. Antes de unirse a AWS, Mark fue arquitecto, desarrollador y líder tecnológico durante más de 25 años, incluidos 19 años en servicios financieros.
 Raj Ramasubbu es un Arquitecto de Soluciones Especialista en Análisis Sénior centrado en big data y análisis y AI/ML con Amazon Web Services. Ayuda a los clientes a diseñar y crear soluciones basadas en la nube altamente escalables, seguras y de alto rendimiento en AWS. Raj proporcionó experiencia técnica y liderazgo en la creación de soluciones de ingeniería de datos, análisis de big data, inteligencia empresarial y ciencia de datos durante más de 18 años antes de unirse a AWS. Ayudó a clientes en varios sectores verticales de la industria, como atención médica, dispositivos médicos, ciencias de la vida, comercio minorista, administración de activos, seguros de automóviles, REIT residencial, agricultura, seguros de títulos, cadena de suministro, administración de documentos y bienes raíces.
Raj Ramasubbu es un Arquitecto de Soluciones Especialista en Análisis Sénior centrado en big data y análisis y AI/ML con Amazon Web Services. Ayuda a los clientes a diseñar y crear soluciones basadas en la nube altamente escalables, seguras y de alto rendimiento en AWS. Raj proporcionó experiencia técnica y liderazgo en la creación de soluciones de ingeniería de datos, análisis de big data, inteligencia empresarial y ciencia de datos durante más de 18 años antes de unirse a AWS. Ayudó a clientes en varios sectores verticales de la industria, como atención médica, dispositivos médicos, ciencias de la vida, comercio minorista, administración de activos, seguros de automóviles, REIT residencial, agricultura, seguros de títulos, cadena de suministro, administración de documentos y bienes raíces.
 Prabhakar Chandrasekaran es un administrador técnico sénior de cuentas con AWS Enterprise Support. Prabhakar disfruta ayudar a los clientes a crear soluciones de IA/ML de vanguardia en la nube. También trabaja con clientes empresariales brindándoles orientación proactiva y asistencia operativa, ayudándolos a mejorar el valor de sus soluciones cuando usan AWS. Prabhakar tiene seis AWS y otras seis certificaciones profesionales. Con más de 20 años de experiencia profesional, Prabhakar era ingeniero de datos y líder de programa en el espacio de servicios financieros antes de unirse a AWS.
Prabhakar Chandrasekaran es un administrador técnico sénior de cuentas con AWS Enterprise Support. Prabhakar disfruta ayudar a los clientes a crear soluciones de IA/ML de vanguardia en la nube. También trabaja con clientes empresariales brindándoles orientación proactiva y asistencia operativa, ayudándolos a mejorar el valor de sus soluciones cuando usan AWS. Prabhakar tiene seis AWS y otras seis certificaciones profesionales. Con más de 20 años de experiencia profesional, Prabhakar era ingeniero de datos y líder de programa en el espacio de servicios financieros antes de unirse a AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Acuñando el futuro con Adryenn Ashley. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/use-streaming-ingestion-with-amazon-sagemaker-feature-store-and-amazon-msk-to-make-ml-backed-decisions-in-near-real-time/

