Estudio de pegamento de AWS ahora está integrado con Elaboración de datos de AWS Glue. AWS Glue Studio es una interfaz gráfica que facilita la creación, ejecución y supervisión de trabajos de extracción, transformación y carga (ETL) en Pegamento AWS. DataBrew es una herramienta de preparación de datos visuales que le permite limpiar y normalizar datos sin escribir ningún código. Las más de 200 transformaciones que proporciona ahora están disponibles para usarse en un trabajo visual de AWS Glue Studio.
En DataBrew, un recetas es un conjunto de pasos de transformación de datos que puede crear de forma interactiva en su interfaz visual intuitiva. En esta publicación, verá cómo usar la creación de una receta en DataBrew y luego aplicarla como parte de un trabajo de ETL visual de AWS Glue Studio.
Los usuarios existentes de DataBrew también se beneficiarán de esta integración: ahora puede ejecutar sus recetas como parte de un flujo de trabajo visual más amplio con todos los demás componentes que proporciona AWS Glue Studio, además de poder usar la configuración de trabajo avanzada y la última versión del motor de AWS Glue. .
Esta integración aporta distintos beneficios a los usuarios existentes de ambas herramientas:
- Tiene una vista centralizada en AWS Glue Studio del diagrama ETL general, de extremo a extremo
- Puede definir una receta de manera interactiva, ver valores, estadísticas y distribución en la consola de DataBrew, luego reutilizar esa lógica de procesamiento probada y versionada en trabajos visuales de AWS Glue Studio.
- Puede orquestar varias recetas de DataBrew en un trabajo ETL de AWS Glue o incluso varios trabajos mediante flujos de trabajo de AWS Glue
- Las recetas de DataBrew ahora pueden usar funciones de trabajo de AWS Glue, como marcadores para procesamiento de datos incremental, reintentos automáticos, escalado automático o agrupación de archivos pequeños para una mayor eficiencia.
Resumen de la solución
En nuestro caso de uso ficticio, el requisito es limpiar un conjunto de datos de reclamos médicos sintéticos creado para esta publicación, que tiene algunos problemas de calidad de datos introducidos a propósito para demostrar las capacidades de DataBrew en la preparación de datos. Luego, los datos de reclamos se incorporan al catálogo (para que sean visibles para los analistas), luego de enriquecerlos con algunos detalles relevantes sobre los proveedores médicos correspondientes provenientes de una fuente separada.
La solución consta de un trabajo visual de AWS Glue Studio que lee dos archivos CSV con reclamos y proveedores, respectivamente. El trabajo aplica una receta del primero para abordar los problemas de calidad, selecciona columnas del segundo, une ambos conjuntos de datos y finalmente almacena el resultado en Servicio de almacenamiento simple de Amazon (Amazon S3), creando una tabla en el catálogo para que los datos de salida puedan ser utilizados por otras herramientas como Atenea amazónica.
Crear una receta de DataBrew
Empiece por registrar el almacén de datos para el archivo de reclamaciones. Esto le permitirá crear la receta en su editor interactivo utilizando los datos reales para que pueda evaluar el resultado de las transformaciones a medida que las define.
- Descargue el archivo CSV de reclamos usando el siguiente enlace: alabama_claims_data_jun2023.csv.
- En la consola de DataBrew, elija Conjuntos de datos en el panel de navegación, luego elija Conectar nuevo conjunto de datos.
- Elige la opcion Carga de archivo.
- Nombre del conjunto de datos, introduzca
Alabama claims. - Seleccione un archivo para cargar, elija el archivo que acaba de descargar en su computadora.

- Introduzca el destino de S3, ingrese o busque un depósito en su cuenta y región.
- Deje el resto de opciones por defecto (CSV separado con coma y con encabezado) y complete la creación del conjunto de datos.
- Elige Proyecto en el panel de navegación, luego elija Crear proyecto.
- Nombre del proyecto, nombralo
ClaimsCleanup. - under Detalles de la receta, Para Receta adjunta, escoger Crear nueva receta, nombralo
ClaimsCleanup-recipey elija elAlabama claimsconjunto de datos que acaba de crear.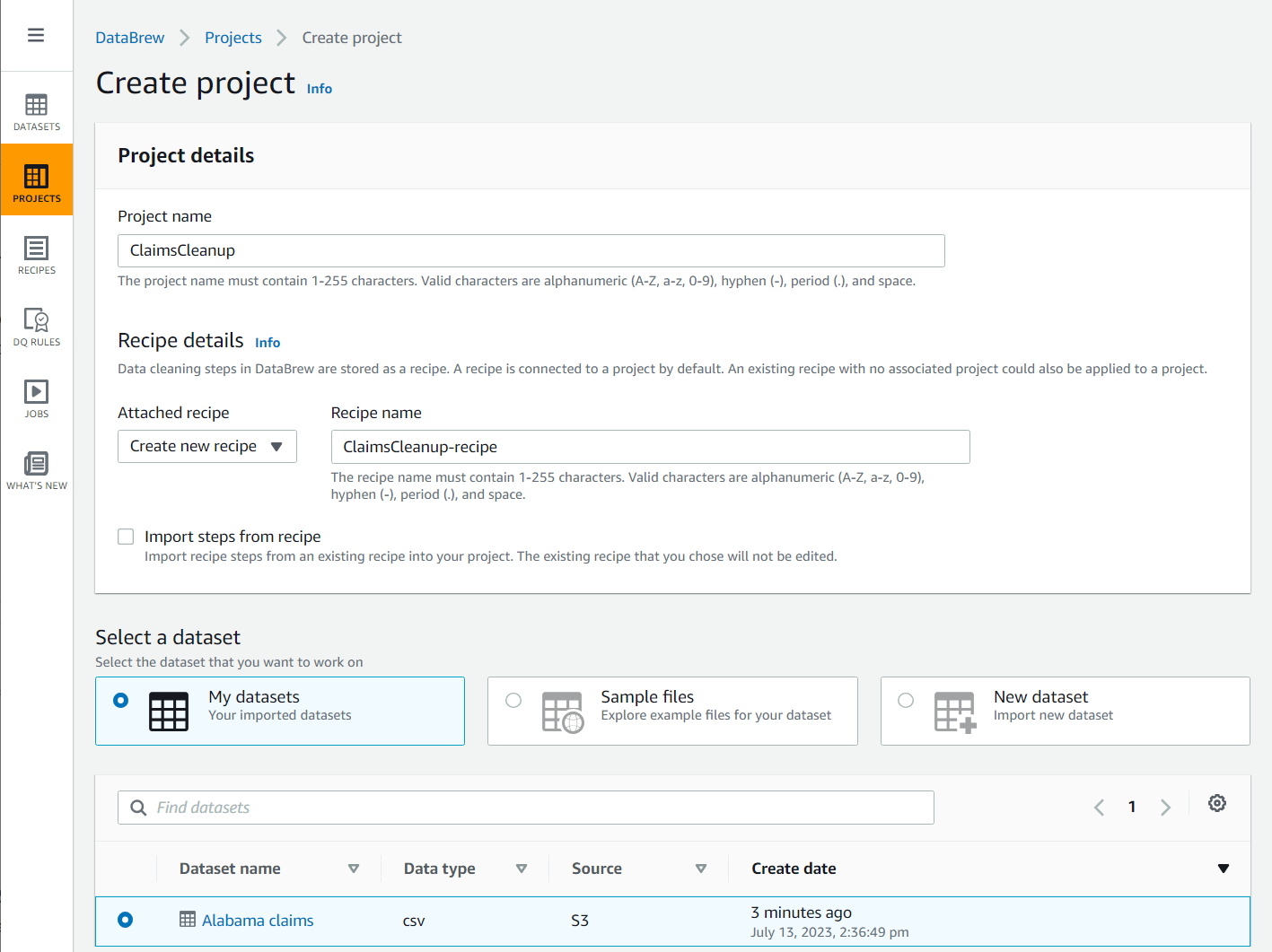
- Seleccione una rol adecuado para DataBrew o cree uno nuevo y complete la creación del proyecto.
Esto creará una sesión utilizando un subconjunto configurable de los datos. Después de que haya inicializado la sesión, puede notar que algunas de las celdas tienen valores no válidos o faltantes.
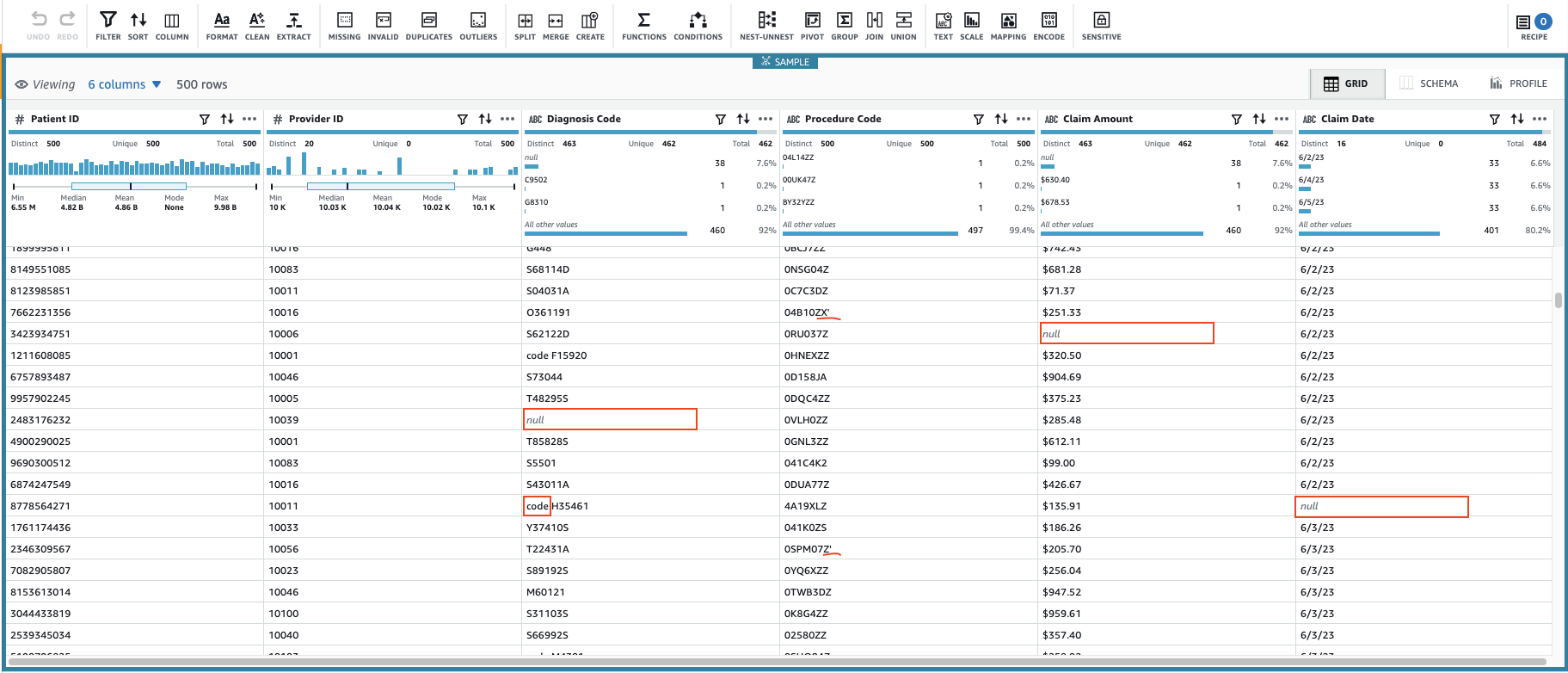
Además de los valores que faltan en las columnas Código de diagnóstico, Reclamar cantidady Fecha de reclamo, algunos valores en los datos tienen algunos caracteres adicionales: Código de diagnóstico los valores a veces tienen el prefijo "código" (espacio incluido), y Código de procedimiento los valores a veces van seguidos de comillas simples.
Reclamar cantidad Es probable que se utilicen valores para algunos cálculos, así que conviértalos en números y Datos de reclamación debe convertirse al tipo de fecha.
Ahora que identificamos los problemas de calidad de los datos a abordar, debemos decidir cómo abordar cada caso.
Hay varias formas de agregar pasos de receta, incluido el uso del menú contextual de la columna, la barra de herramientas en la parte superior o desde el resumen de la receta. Usando el último método, puede buscar el tipo de paso indicado para replicar la receta creada en esta publicación.
Reclamar cantidad es esencial para este caso de uso, y la decisión es eliminar dichas filas.
- agregar el paso Eliminar valores faltantes.
- Columna fuente, escoger Reclamar cantidad.
- Dejar la acción por defecto Eliminar filas con valores faltantes y elige Aplicá para salvarlo.
La vista ahora se actualiza para reflejar la aplicación del paso y las filas con cantidades que faltan ya no están allí.
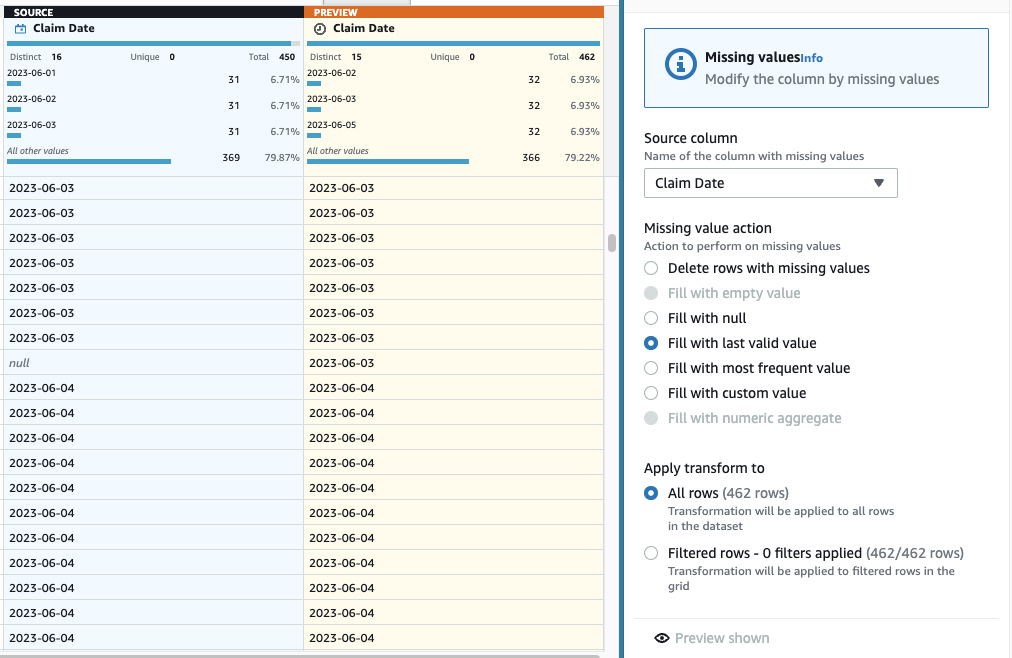
Código de diagnóstico puede estar vacío por lo que se acepta, pero en el caso de Fecha de reclamo, queremos tener una estimación razonable. Las filas de los datos se ordenan en orden cronológico, por lo que puede imputar las fechas que faltan utilizando el valor válido de las vistas previas de las filas anteriores. Suponiendo que todos los días tienen reclamos, el mayor error sería asignarlo al día de vista previa si fuera el primer reclamo de ese día al que le falta la fecha; con fines ilustrativos, consideremos aceptable ese error potencial.
Primero, convierta la columna de cadena a tipo de fecha.
- agregar el paso Cambiar tipo.
- Elige Fecha de reclamo como la columna y datos como el tipo, luego elija Aplicá.
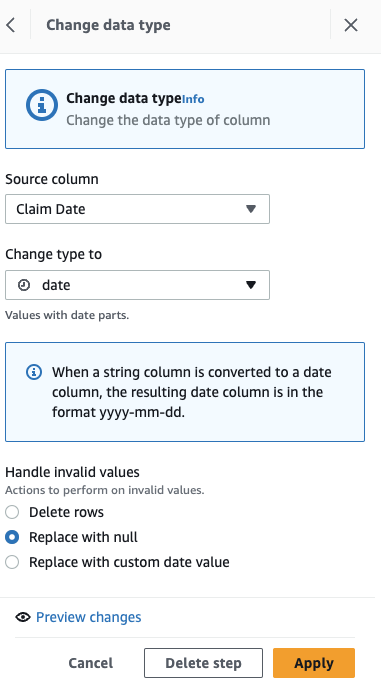
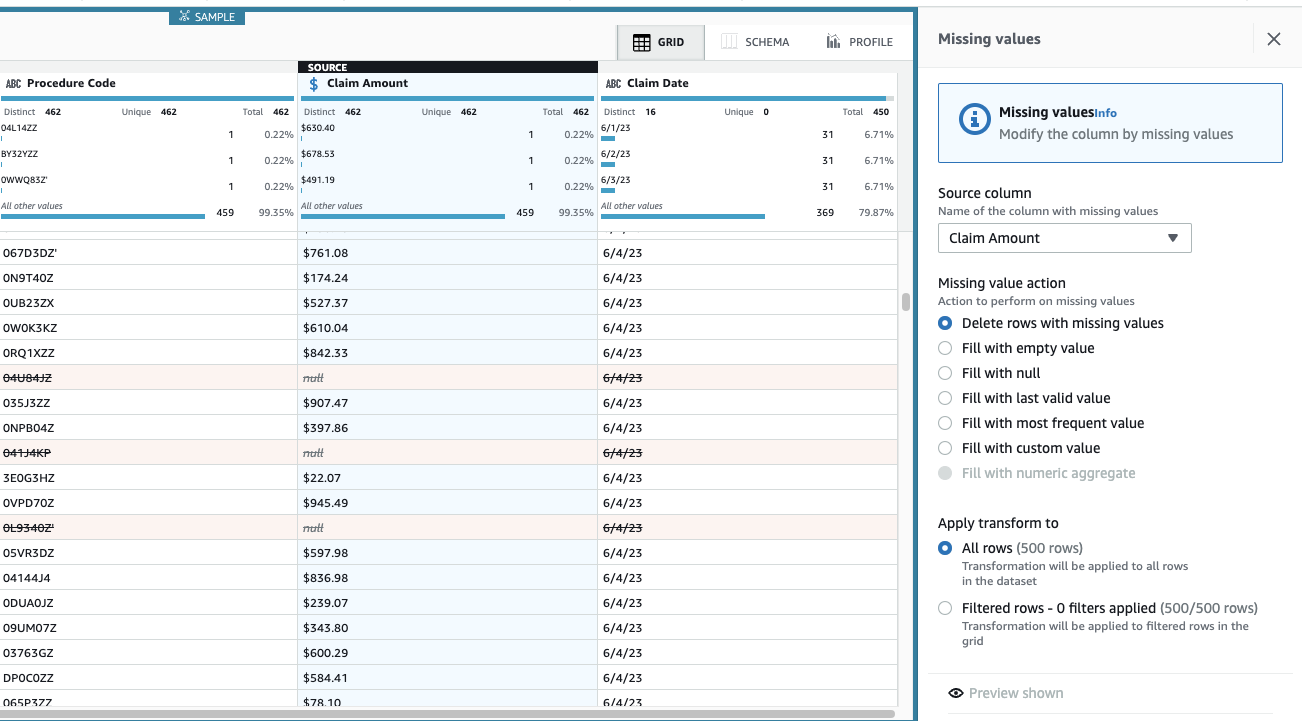
- Ahora para hacer la imputación de fechas faltantes, agregue el paso Rellenar o imputar valores faltantes.
- Seleccione Rellenar con el último valor válido como acción y elija Fecha de reclamo como fuente.
- Elige Vista previa de cambios para validarlo, luego elija Aplicá para salvar el paso.
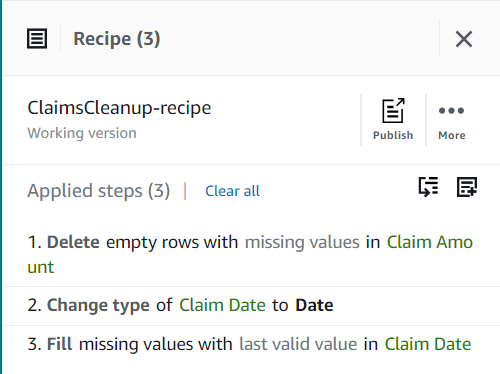
Hasta ahora, su receta debe tener tres pasos, como se muestra en la siguiente captura de pantalla.
- A continuación, agregue el paso Quitar las comillas.
- Elija el Código de procedimiento columna y seleccione Comillas iniciales y finales.
- Vista previa para verificar que tiene el efecto deseado y aplicar el nuevo paso.

- agregar el paso Eliminar caracteres especiales.
- Elija el Reclamar cantidad columna y, para ser más específicos, seleccione Caracteres especiales personalizados e introduzca
$para Introduzca caracteres especiales personalizados.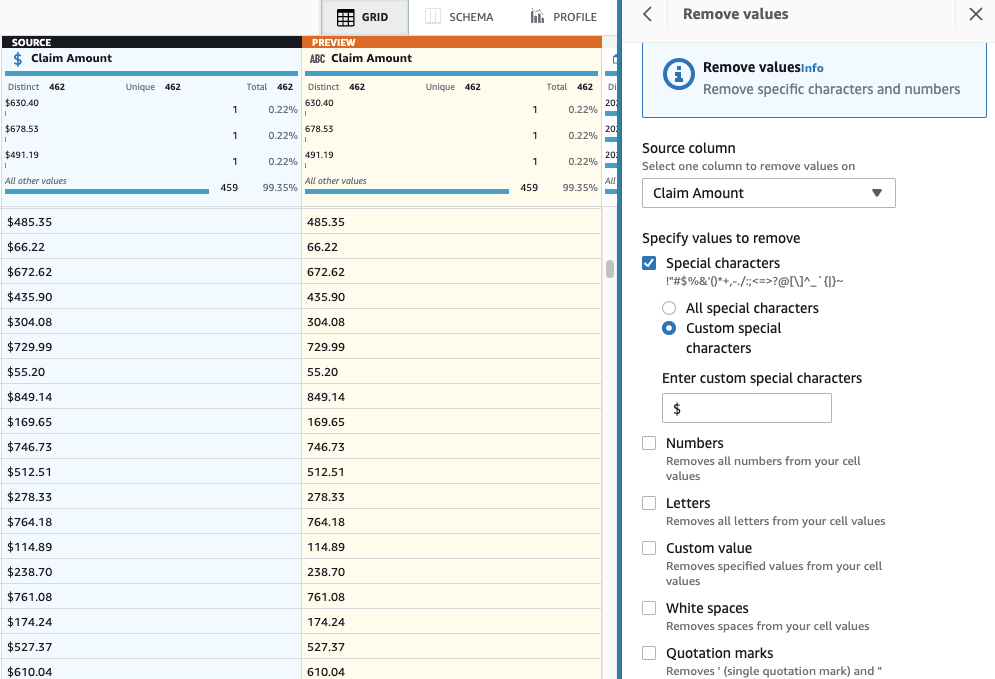
- Agrega una Cambiar tipo paso en la columna Reclamar cantidad y elige doble como el tipo.
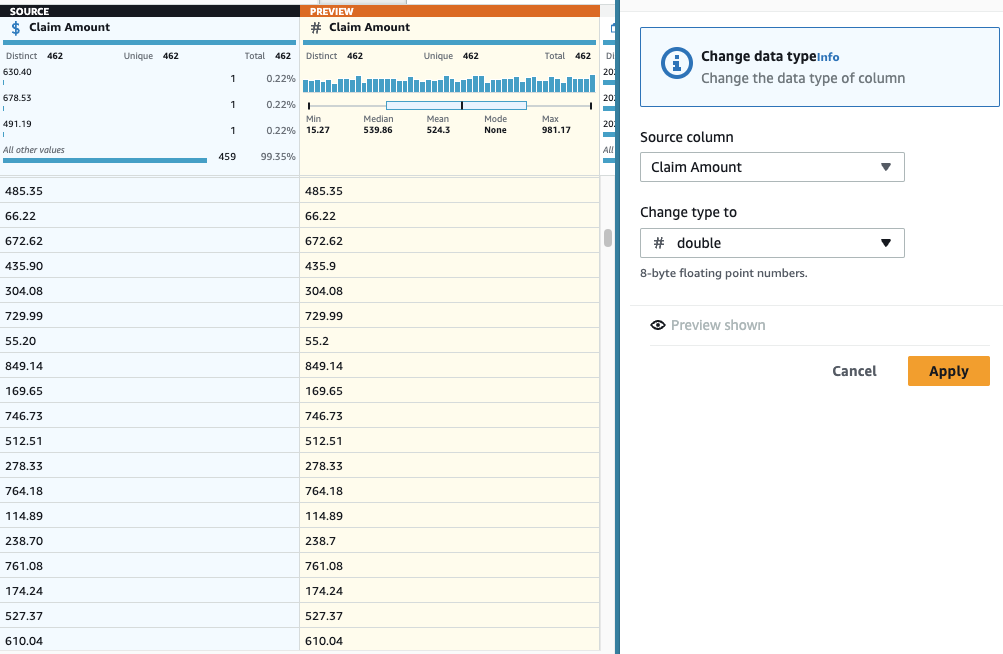
- Como último paso, para eliminar el prefijo "código" superfluo, agregue un Reemplazar valor o patrón paso.
- Elige la columna Código de diagnóstico, Y para Ingrese un valor personalizado, introduzca
code(con un espacio al final).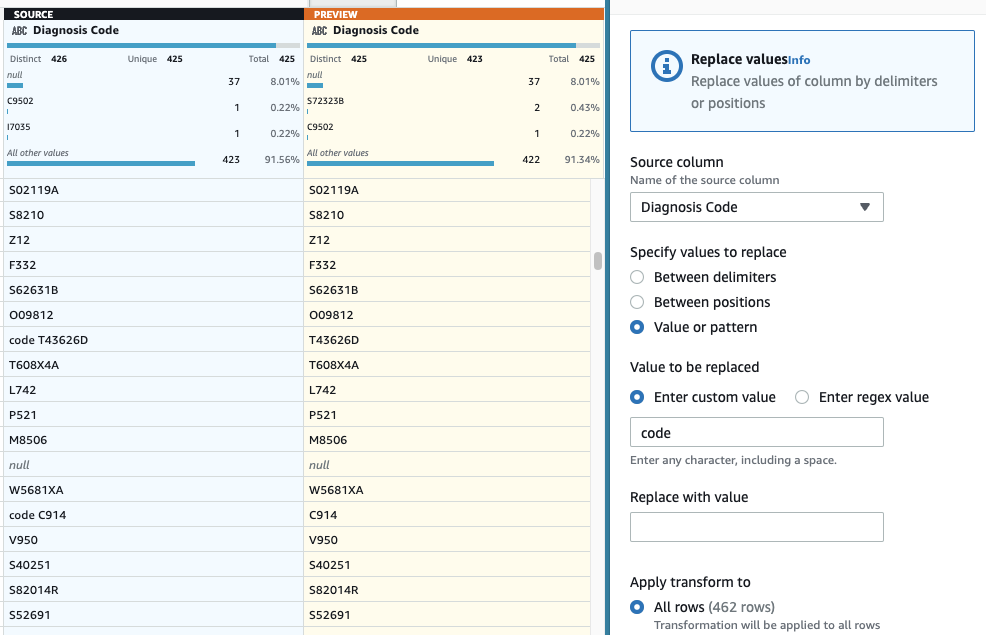
Ahora que ha abordado todos los problemas de calidad de datos identificados en la muestra, publique el proyecto como una receta.
- Elige Publicar existentes Receta panel, introduzca una descripción opcional y complete la publicación.
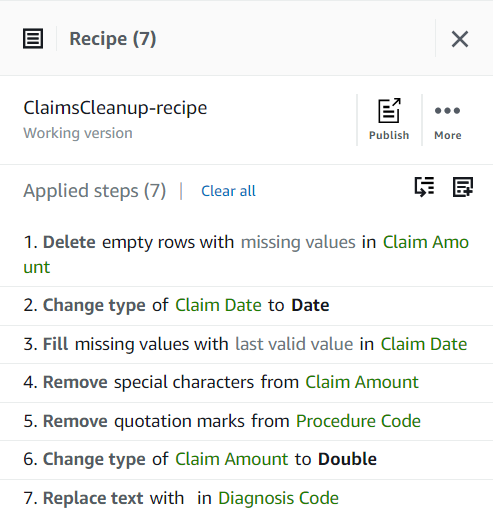
Cada vez que publique, se creará una versión diferente de la receta. Más tarde, podrá elegir qué versión de la receta usar.
Cree un trabajo de ETL visual en AWS Glue Studio
A continuación, crea el trabajo que utiliza la receta. Complete los siguientes pasos:
- En la consola de AWS Glue Studio, elija ETL visuales en el panel de navegación.
- Elige Visual con un lienzo en blanco y crear el trabajo visual.
- En la parte superior del trabajo, reemplace "Trabajo sin título" con un nombre de su elección.
- En Detalles del trabajo ficha, especifique un rol que usará el trabajo.
Esto tiene que ser un Gestión de identidades y accesos de AWS (YO SOY) rol adecuado para AWS Glue con permisos para Amazon S3 y AWS Glue Data Catalog. Tenga en cuenta que el rol que se usó antes para DataBrew no se puede usar para ejecutar trabajos, por lo que no aparecerá en la lista. Rol de IAM menú desplegable aquí.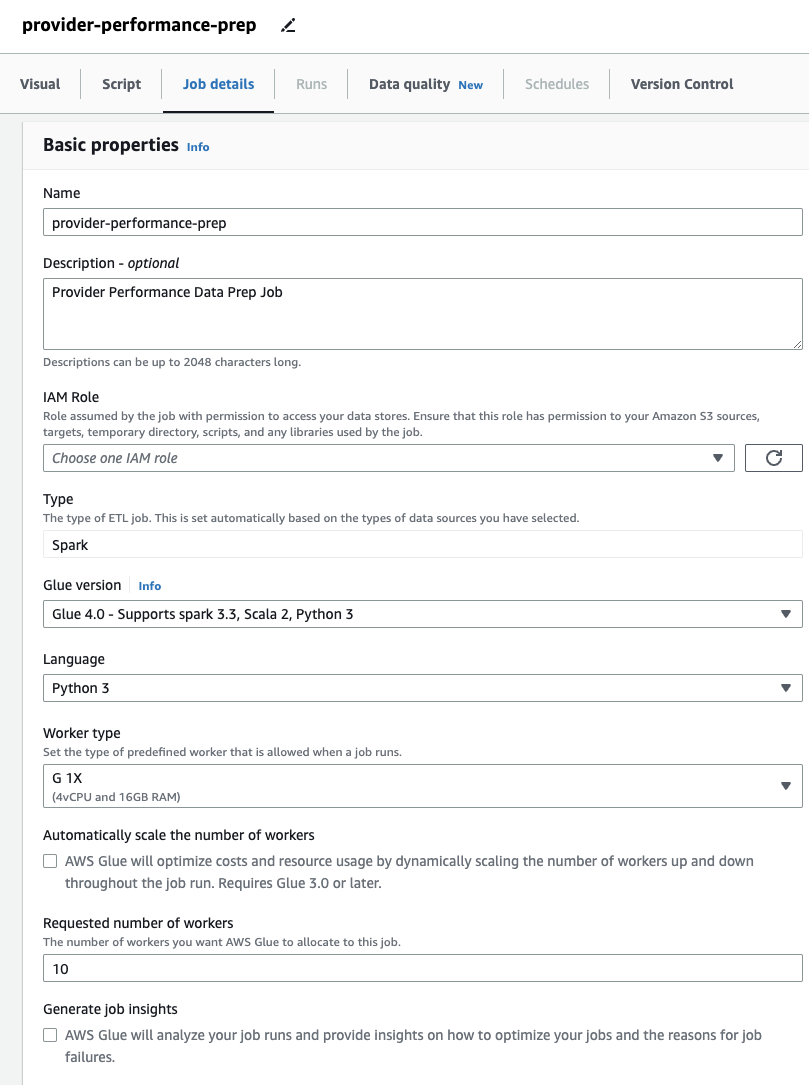
Si antes solo utilizó trabajos de DataBrew, tenga en cuenta que en AWS Glue Studio, puede elegir la configuración de rendimiento y costo, incluido el tamaño del trabajador, el escalado automático y Ejecución flexible, además de utilizar el último tiempo de ejecución de AWS Glue 4.0 y beneficiarse de las importantes mejoras de rendimiento que ofrece. Para este trabajo, puede usar la configuración predeterminada, pero reduzca la cantidad solicitada de trabajadores en aras de la frugalidad. Para este ejemplo, dos trabajadores servirán. - En Visual pestaña, agregue una fuente S3 y asígnele un nombre
Providers. - URL de S3, introduzca
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.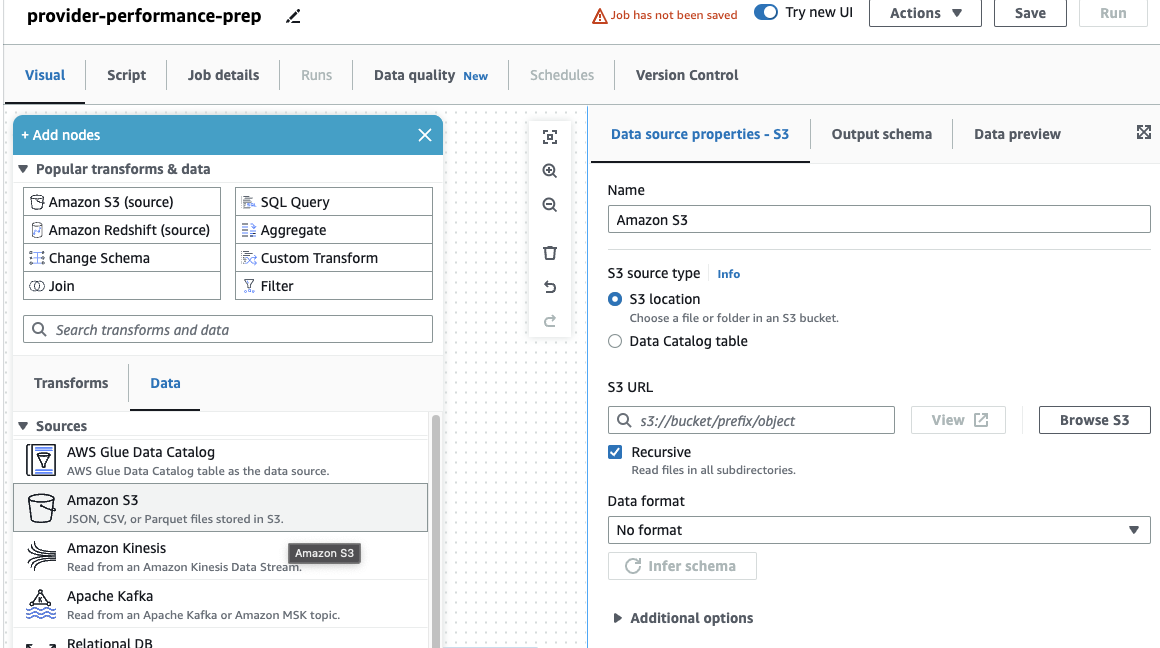
- Seleccione el formato como CSV y elige Inferir esquema.
Ahora el esquema está listado en el esquema de salida pestaña utilizando el encabezado del archivo.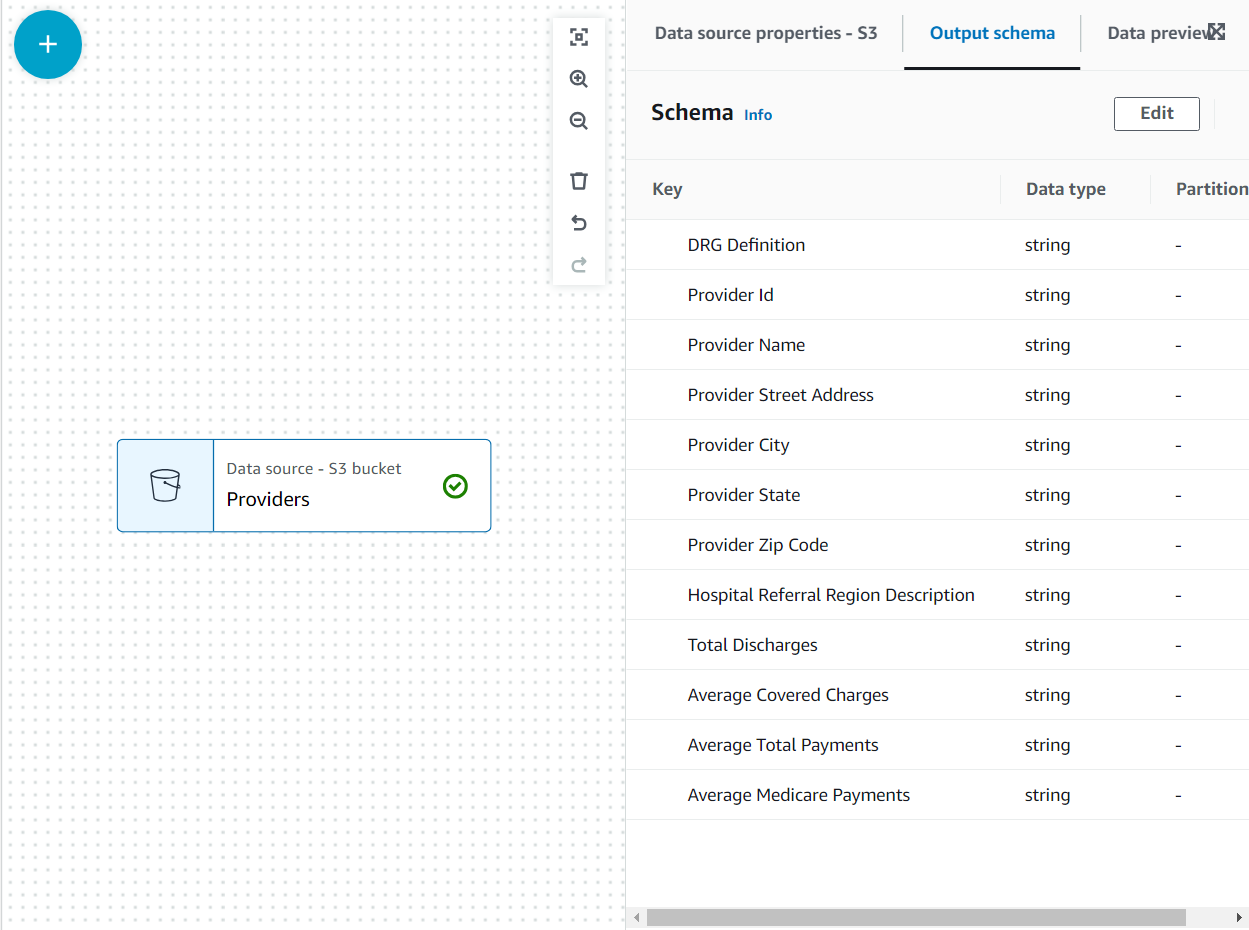
En este caso de uso, la decisión es que no se necesitan todas las columnas del conjunto de datos de proveedores, por lo que podemos descartar el resto.
- Con la Los proveedores nodo seleccionado, agregue un Soltar campos transform (si no seleccionó el nodo principal, no tendrá uno; en ese caso, asigne el nodo principal manualmente).
- Seleccione todos los campos después Código postal del proveedor.
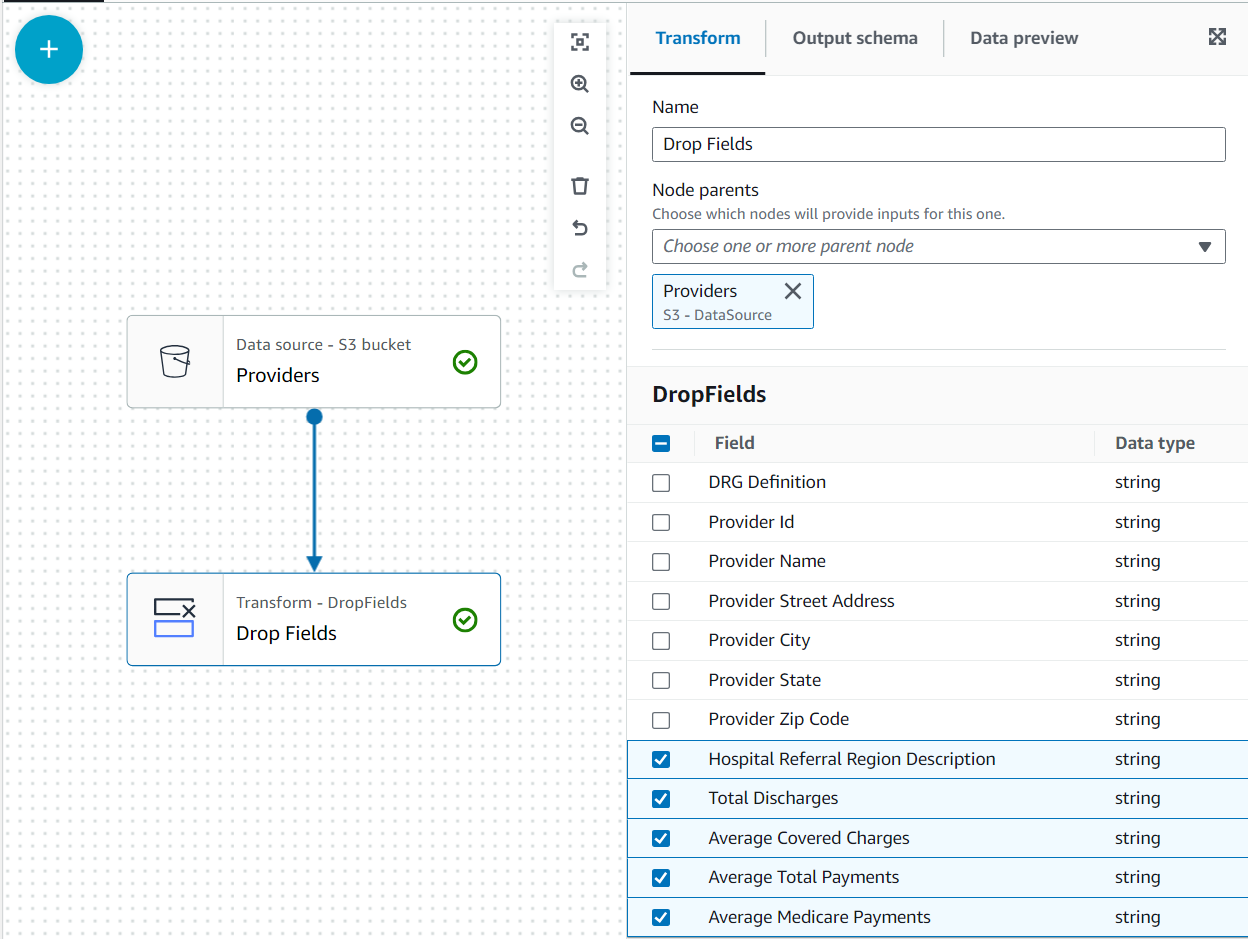
Posteriormente, a estos datos se unirán los reclamos del estado de Alabama a través del proveedor; sin embargo, ese segundo conjunto de datos no tiene el estado especificado. Podemos utilizar el conocimiento de los datos para optimizar la combinación filtrando los datos que realmente necesitamos.
- Agrega una Filtrar transformate como un hijo de Soltar campos.
- Nombralo
Alabama providersy agregue una condición que el estado debe cumplirAL.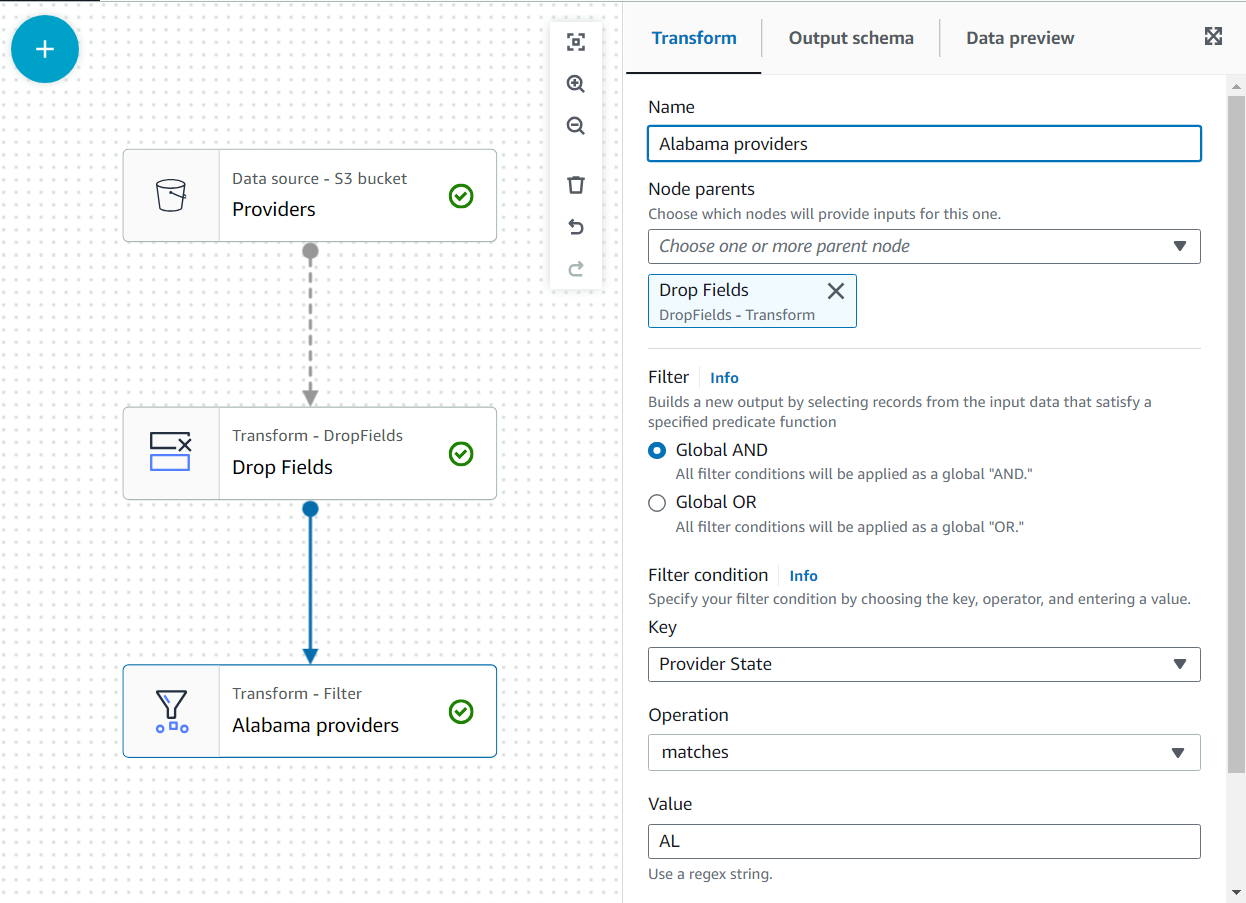
- Agregue la segunda fuente (una nueva fuente S3) y asígnele un nombre
Alabama claims. - Para entrar a URL de S3, abra DataBrew en una pestaña separada del navegador, seleccione Conjuntos de datos en el panel de navegación y, en la tabla, copie la ubicación que se muestra en la tabla para reclamos de alabama (copie el texto que comienza con s3://, no el enlace http asociado). Luego, de vuelta en el trabajo visual, péguelo como URL de S3; si es correcto, lo verás en el esquema de salida tabula los campos de datos enumerados.
- Seleccione el formato CSV e infiera el esquema como lo hizo con la otra fuente.
- Como hijo de esta fuente, busca en el Agregar nodos menú para
recipey elige Receta de preparación de datos.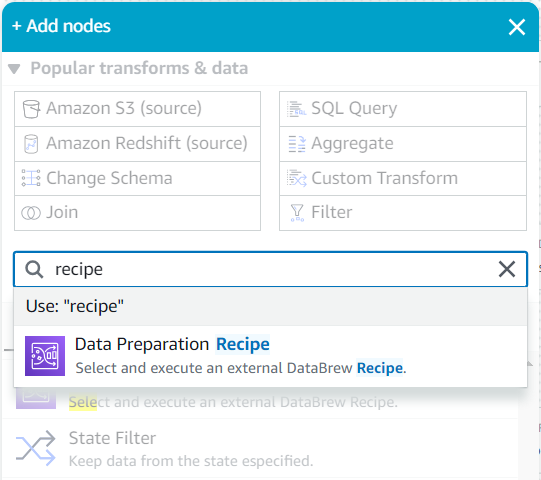
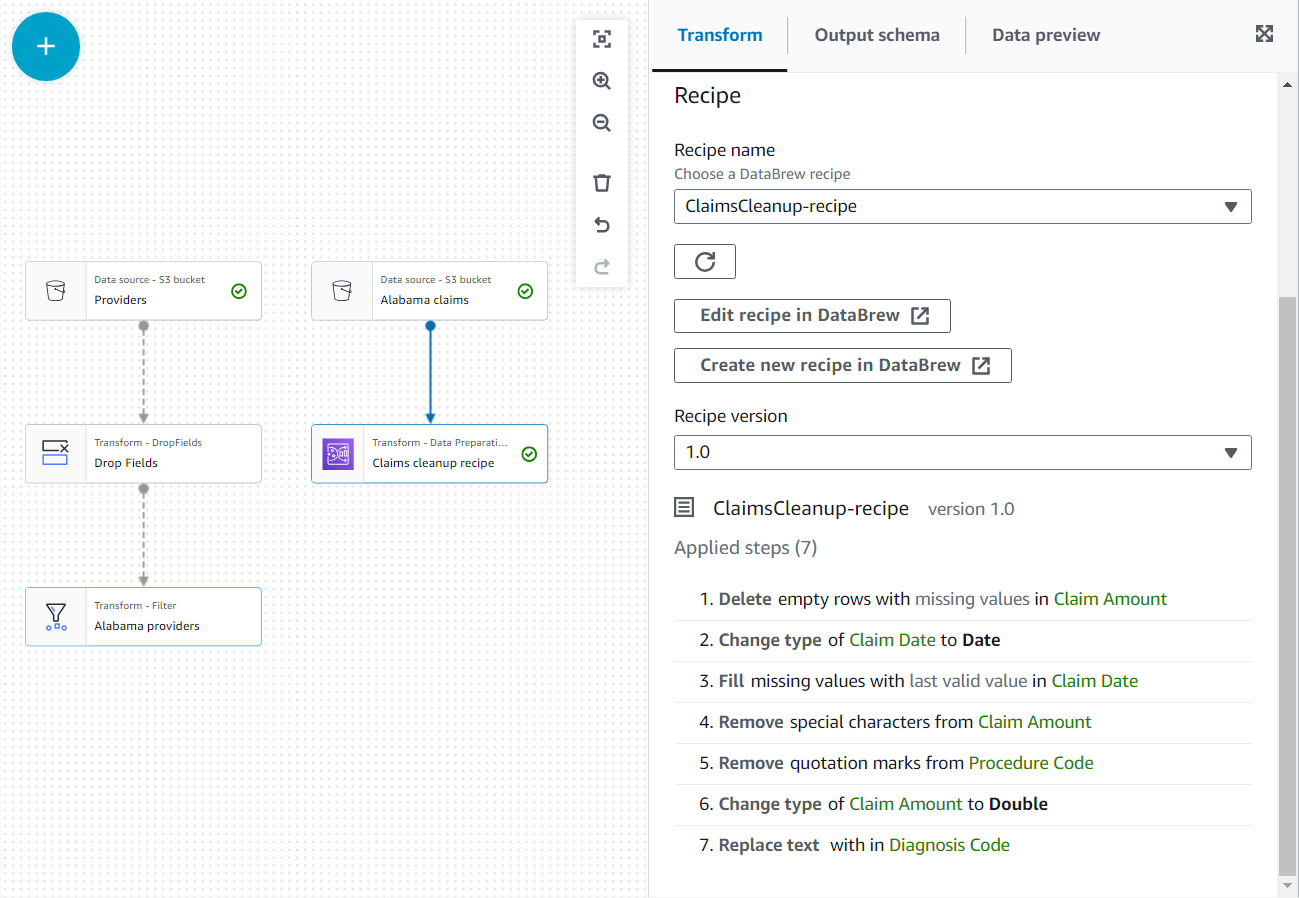
- En las propiedades de este nuevo nodo, asígnele el nombre
Claim cleanup recipey elige la receta y la versión que publicaste antes. - Puede revisar los pasos de la receta aquí y usar el enlace a DataBrew para hacer cambios si es necesario.
- Agrega una Únete nodo y seleccione ambos Proveedores de Alabama y Reclamar recetas de limpieza como padre.
- Agregue una condición de unión que iguale la ID del proveedor de ambas fuentes.
- Como último paso, agregue un nodo S3 como destino (tenga en cuenta que el primero que aparece cuando busca es el origen; asegúrese de seleccionar la versión que aparece como destino).
- En la configuración del nodo, deje el formato predeterminado JSON e ingrese una URL de S3 en la que el rol de trabajo tenga permiso para escribir.
Además, haga que la salida de datos esté disponible como una tabla en el catálogo.
- En Opciones de actualización del catálogo de datos sección, seleccione la segunda opción Cree una tabla en el catálogo de datos y, en ejecuciones posteriores, actualice el esquema y agregue nuevas particionesy, a continuación, seleccione una base de datos en la que tenga permiso para crear tablas.
- Asignar
alabama_claimscomo el nombre y elegir Fecha de reclamo como clave de partición (esto es con fines ilustrativos; una tabla pequeña como esta realmente no necesita particiones si no se agregarán más datos más adelante).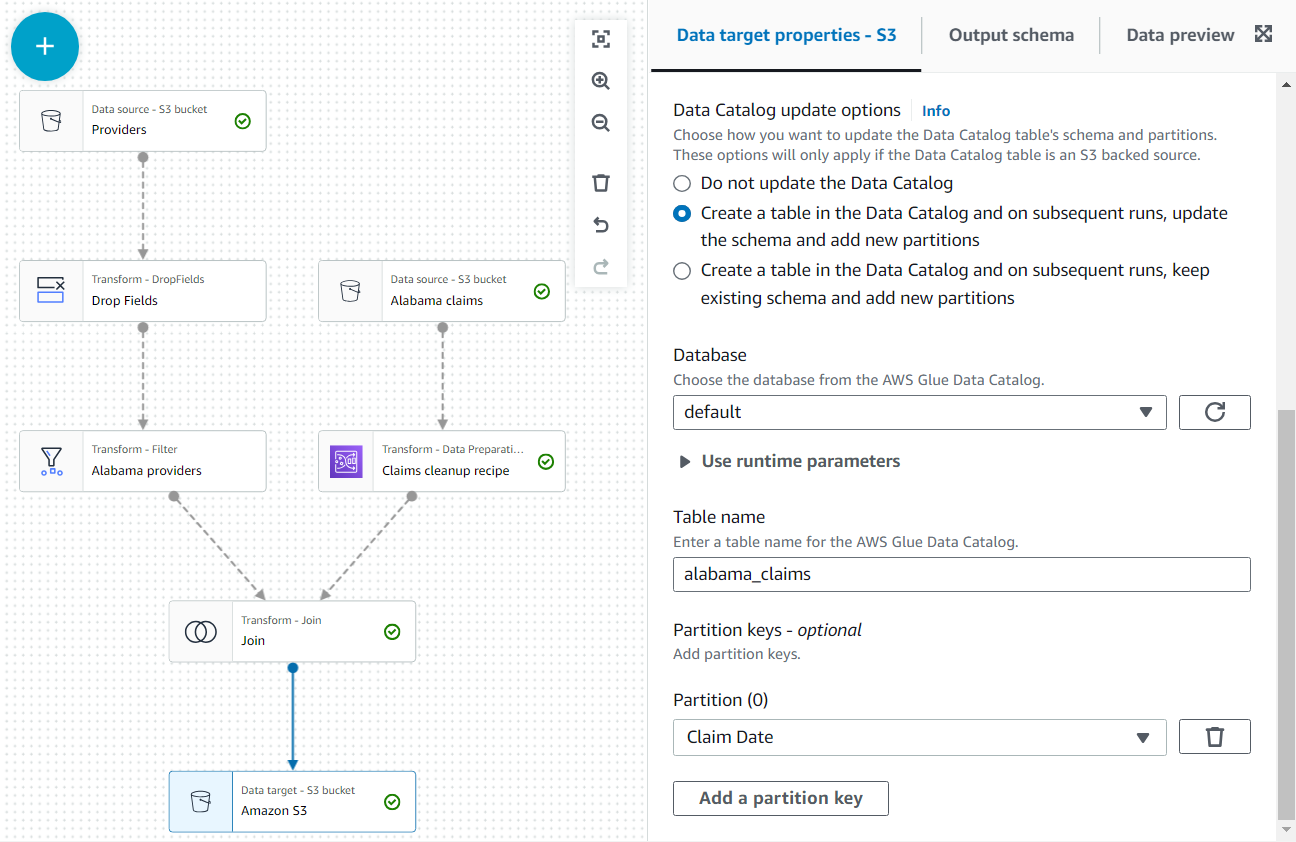
- Ahora puede guardar y ejecutar el trabajo.
- En Ron pestaña, puede realizar un seguimiento del proceso y ver métricas detalladas del trabajo utilizando el enlace de identificación del trabajo.
El trabajo debería tardar unos minutos en completarse.
- Cuando el trabajo esté completo, vaya a la consola de Athena.
- busca la mesa
alabama_claimsen la base de datos que seleccionó y, utilizando el menú contextual, elija Tabla de vista previa, que ejecutará una instrucción SELECT * SQL simple en la tabla.
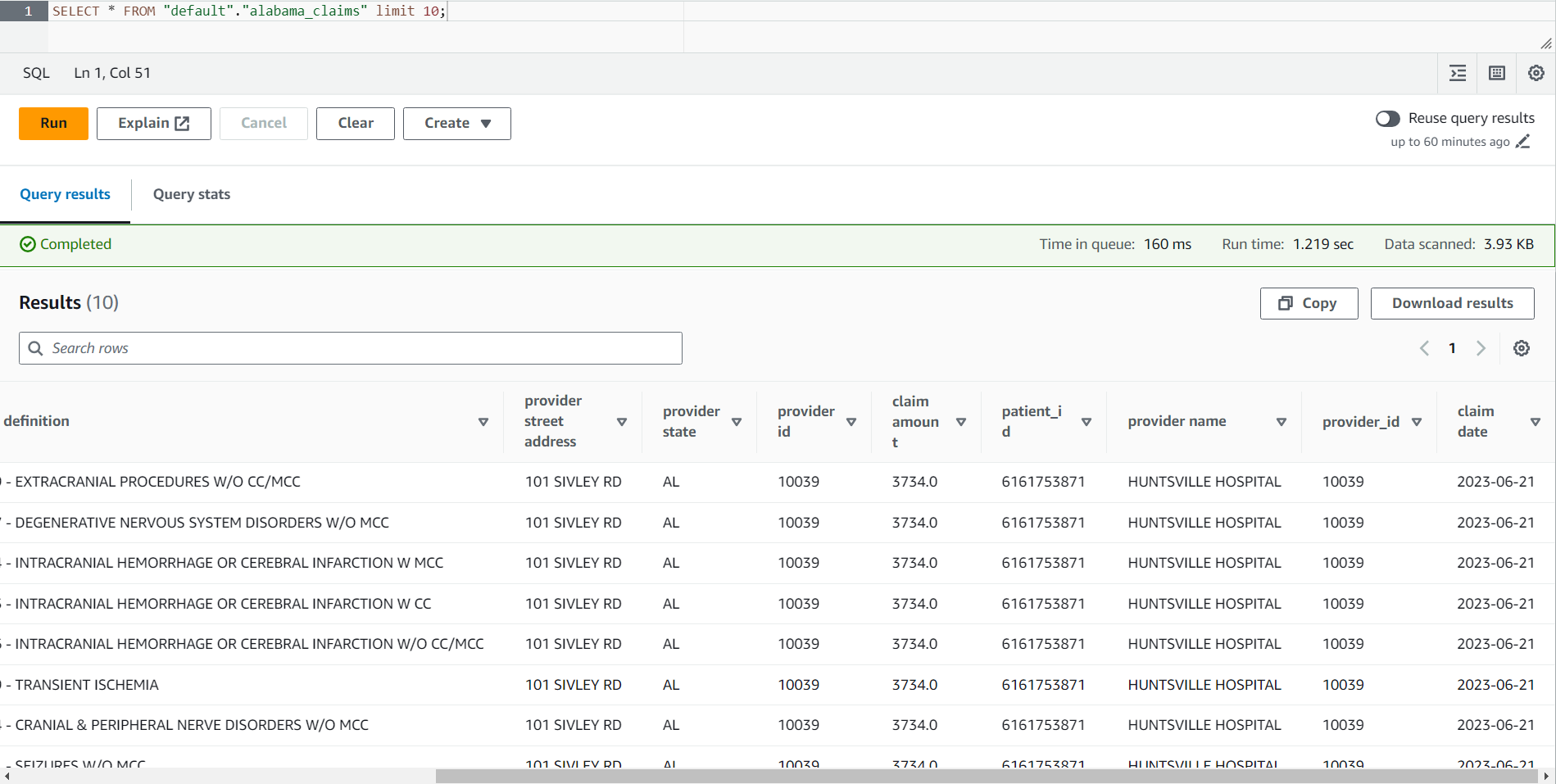
Puede ver en el resultado del trabajo que los datos fueron limpiados por la receta de DataBrew y enriquecidos por la unión de AWS Glue Studio.
Apache Spark es el motor que ejecuta los trabajos creados en AWS Glue Studio. Al usar la interfaz de usuario de Spark en los registros de eventos que produce, puede ver información sobre el plan y la ejecución del trabajo, lo que puede ayudarlo a comprender cómo se está desempeñando su trabajo y los posibles cuellos de botella en el rendimiento. Por ejemplo, para este trabajo en un conjunto de datos grande, podría usarlo para comparar el impacto de filtrar explícitamente el estado del proveedor antes de realizar la combinación, o identificar si puede beneficiarse al agregar una transformación de equilibrio automático para mejorar el paralelismo.
De forma predeterminada, el trabajo almacenará los registros de eventos de Apache Spark en la ruta s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Para ver los trabajos, debe instalar un servidor de historial usando uno de los métodos disponibles.
Limpiar
Si ya no necesita esta solución, puede eliminar los archivos generados en Amazon S3, la tabla creada por el trabajo, la receta de DataBrew y el trabajo de AWS Glue.
Conclusión
En esta publicación, mostramos cómo puede usar AWS DataBrew para crear una receta con el editor interactivo provisto y luego usar la receta publicada como parte de un trabajo de ETL visual de AWS Glue Studio. Incluimos algunos ejemplos de tareas comunes que se requieren al realizar la preparación de datos y la ingesta de datos en las tablas de AWS Glue Catalog.
Este ejemplo usó una sola receta en el trabajo visual, pero es posible usar varias recetas en diferentes partes del proceso ETL, así como reutilizar la misma receta en varios trabajos.
Estas soluciones de AWS Glue le permiten crear canalizaciones de ETL avanzadas que son fáciles de construir y mantener, todo sin escribir ningún código. Puede comenzar a crear soluciones que combinen ambas herramientas hoy.
Sobre los autores
 Mijaíl Smirnov es ingeniero sénior de desarrollo de software en el equipo de AWS Glue y forma parte del equipo de desarrollo de AWS Glue DataBrew. Fuera del trabajo, sus intereses incluyen aprender a tocar la guitarra y viajar con su familia.
Mijaíl Smirnov es ingeniero sénior de desarrollo de software en el equipo de AWS Glue y forma parte del equipo de desarrollo de AWS Glue DataBrew. Fuera del trabajo, sus intereses incluyen aprender a tocar la guitarra y viajar con su familia.
 gonzalo herreros es Arquitecto sénior de Big Data en el equipo de AWS Glue. Basado en Dublín, Irlanda, ayuda a los clientes a tener éxito con soluciones de big data basadas en AWS Glue. En su tiempo libre, disfruta de los juegos de mesa y el ciclismo.
gonzalo herreros es Arquitecto sénior de Big Data en el equipo de AWS Glue. Basado en Dublín, Irlanda, ayuda a los clientes a tener éxito con soluciones de big data basadas en AWS Glue. En su tiempo libre, disfruta de los juegos de mesa y el ciclismo.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/

