En esta serie de dos partes, demostramos cómo etiquetar y entrenar modelos para tareas de detección de objetos 3D. En la parte 1, analizamos el conjunto de datos que estamos utilizando, así como los pasos de preprocesamiento, para comprender y etiquetar los datos. En la parte 2, explicamos cómo entrenar un modelo en su conjunto de datos e implementarlo en producción.
LiDAR (detección y rango de luz) es un método para determinar rangos apuntando a un objeto o superficie con un láser y midiendo el tiempo que tarda la luz reflejada en regresar al receptor. Las empresas de vehículos autónomos suelen utilizar sensores LiDAR para generar una comprensión 3D del entorno que rodea a sus vehículos.
A medida que los sensores LiDAR se vuelven más accesibles y rentables, los clientes utilizan cada vez más datos de nubes de puntos en nuevos espacios como la robótica, el mapeo de señales y la realidad aumentada. Algunos dispositivos móviles nuevos incluso incluyen sensores LiDAR. La creciente disponibilidad de sensores LiDAR ha aumentado el interés en los datos de nubes de puntos para tareas de aprendizaje automático (ML), como detección y seguimiento de objetos 3D, segmentación 3D, síntesis y reconstrucción de objetos 3D y uso de datos 3D para validar la estimación de profundidad 2D.
En esta serie, le mostramos cómo entrenar un modelo de detección de objetos que se ejecuta en datos de nubes de puntos para predecir la ubicación de vehículos en una escena 3D. En esta publicación, nos enfocamos específicamente en el etiquetado de datos LiDAR. La salida del sensor LiDAR estándar es una secuencia de cuadros de nube de puntos 3D, con una tasa de captura típica de 10 cuadros por segundo. Para etiquetar la salida de este sensor, necesita una herramienta de etiquetado que pueda manejar datos 3D. Verdad fundamental de Amazon SageMaker facilita el etiquetado de objetos en un solo marco 3D o en una secuencia de marcos de nubes de puntos 3D para crear conjuntos de datos de entrenamiento de ML. Ground Truth también admite la fusión de sensores de datos de cámara y LiDAR con hasta ocho entradas de cámara de video.
Los datos son esenciales para cualquier proyecto de ML. Los datos 3D en particular pueden ser difíciles de obtener, visualizar y etiquetar. usamos el Conjunto de datos A2D2 en esta publicación y lo guiará a través de los pasos para visualizarlo y etiquetarlo.
A2D2 contiene 40,000 12,499 fotogramas con segmentación semántica y etiquetas de nube de puntos, incluidos 3 12,499 fotogramas con etiquetas de cuadro delimitador 3D. Dado que nos centramos en la detección de objetos, estamos interesados en los 14 XNUMX fotogramas con etiquetas de cuadro delimitador XNUMXD. Estas anotaciones incluyen XNUMX clases relevantes para la conducción como automóvil, peatón, camión, autobús, etc.
La siguiente tabla muestra la lista completa de clases:
| Home | Lista de clase |
| 1 | animal |
| 2 | bicicleta |
| 3 | autobús |
| 4 | de |
| 5 | transportador de caravanas |
| 6 | ciclista |
| 7 | vehículo de emergencia |
| 8 | motociclista |
| 9 | motocicleta |
| 10 | peatonal |
| 11 | trailer |
| 12 | camión |
| 13 | vehículo de utilidad |
| 14 | furgoneta/SUV |
Entrenaremos a nuestro detector para que detecte específicamente automóviles, ya que esa es la clase más común en nuestro conjunto de datos (32616 del total de 42816 objetos en el conjunto de datos están etiquetados como automóviles).
Resumen de la solución
En esta serie, cubrimos cómo visualizar y etiquetar sus datos con Amazon SageMaker Ground Truth y demostramos cómo usar estos datos en un trabajo de capacitación de Amazon SageMaker para crear un modelo de detección de objetos, implementado en un punto de enlace de Amazon SageMaker. En particular, usaremos una computadora portátil Amazon SageMaker para operar la solución e iniciar cualquier trabajo de etiquetado o capacitación.
El siguiente diagrama muestra el flujo general de datos del sensor desde el etiquetado hasta el entrenamiento y la implementación:

Aprenderá a entrenar e implementar un modelo de detección de objetos 3D en tiempo real con Amazon SageMaker Ground Truth con los siguientes pasos:
- Descargar y visualizar un conjunto de datos de nube de puntos
- Prepare los datos para etiquetarlos con el Herramienta de nube de puntos de Amazon SageMaker Ground Truth
- Inicie un trabajo de capacitación de Amazon SageMaker Ground Truth distribuido con MMDetección3D
- Evalúe los resultados de su trabajo de capacitación y perfile su utilización de recursos con Depurador de Amazon SageMaker
- Implementar un asíncrono Punto final de SageMaker
- Llame al punto final y visualice predicciones de objetos 3D
Servicios de AWS utilizados para implementar esta solución
Requisitos previos
El siguiente diagrama muestra cómo crear una fuerza de trabajo privada. Para obtener instrucciones paso a paso por escrito, consulte Cree una fuerza laboral de Amazon Cognito mediante la página Etiquetado de fuerzas laborales.

Lanzamiento de la pila de AWS CloudFormation
Ahora que ha visto la estructura de la solución, la implementa en su cuenta para poder ejecutar un flujo de trabajo de ejemplo. AWS CloudFormation administra todos los pasos de implementación relacionados con la canalización de etiquetado. Esto significa que AWS Cloudformation crea su instancia de notebook, así como cualquier función o depósito de Amazon S3 para admitir la ejecución de la solución.
Puede lanzar la pila en la región de AWS us-east-1 en la consola de AWS CloudFormation mediante el Pila de lanzamiento
botón. Para iniciar la pila en una Región diferente, use las instrucciones que se encuentran en el LÉAME de la Repositorio GitHub.
![]()

Esto toma aproximadamente 20 minutos para crear todos los recursos. Puede monitorear el progreso desde la interfaz de usuario (IU) de AWS CloudFormation.
Una vez que su plantilla de CloudFormation termine de ejecutarse, vuelva a la consola de AWS.
Abriendo el cuaderno
Las instancias de notebook de Amazon SageMaker son instancias informáticas de aprendizaje automático que se ejecutan en la aplicación Jupyter Notebook. Amazon SageMaker administra la creación de instancias y recursos relacionados. Utilice cuadernos de Jupyter en su instancia de cuaderno para preparar y procesar datos, escribir código para entrenar modelos, implementar modelos en el alojamiento de Amazon SageMaker y probar o validar sus modelos.
Siga los siguientes pasos para acceder al entorno de Notebook de Amazon SageMaker:
- En servicios busque Amazon SageMaker.
- under Notebook, seleccione Instancias de cuaderno.

- Se debe aprovisionar una instancia de Notebook. Seleccione Abrir JupyterLab, que se encuentra en el lado derecho de la instancia de Notebook preaprovisionada bajo Acciones.

- Verás un ícono como este mientras se carga la página:

- Será redirigido a una nueva pestaña del navegador que se parece al siguiente diagrama:
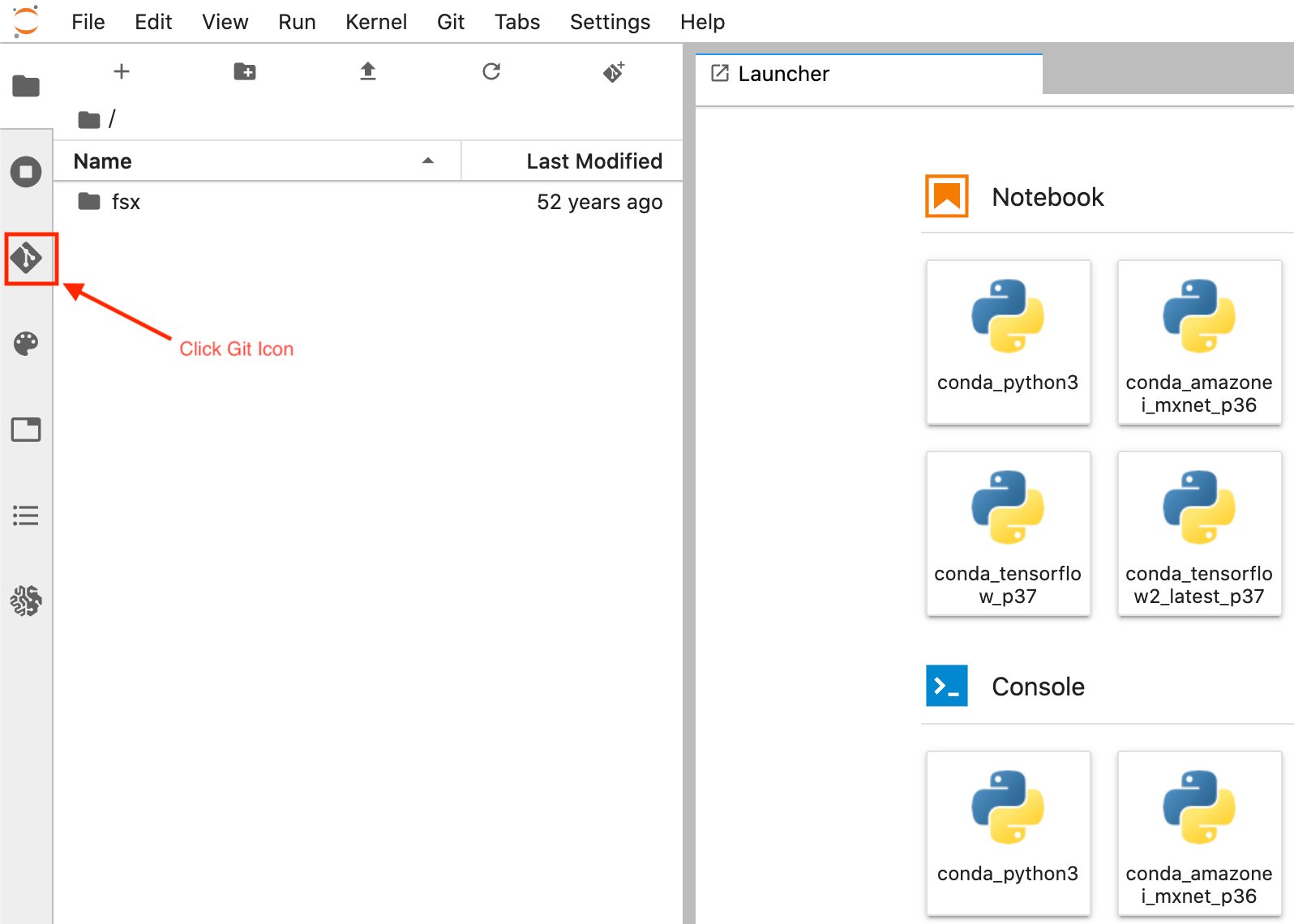
- Una vez que esté en la interfaz de usuario del iniciador de instancias de portátiles de Amazon SageMaker. En la barra lateral izquierda, seleccione el Git icono como se muestra en el siguiente diagrama.
- Seleccione Clonar un repositorio .
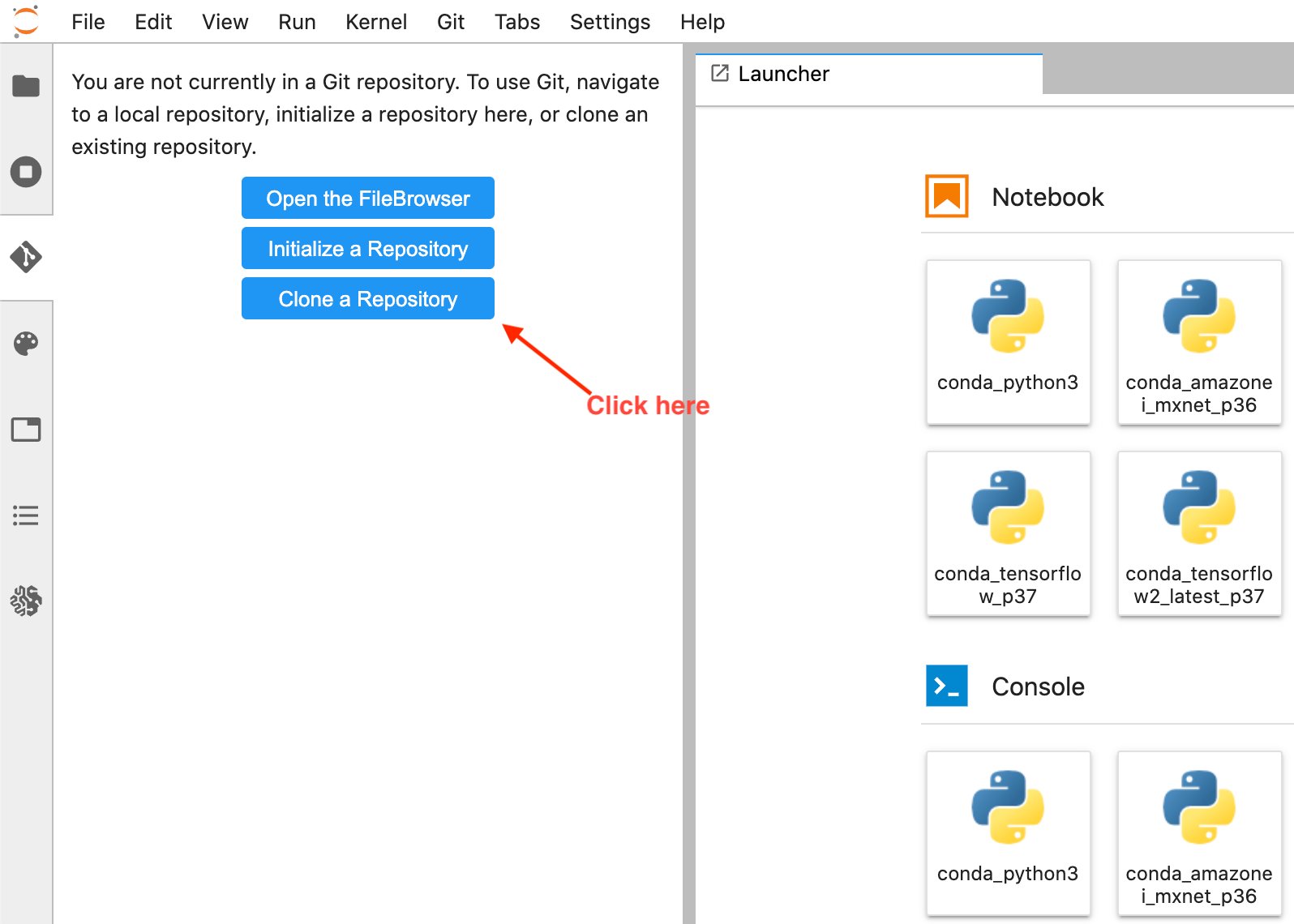
- Ingrese la URL de GitHub (https://github.com/aws-samples/end-2-end-3d-ml) en la ventana emergente y elija clonar.
- Seleccione Explorador de archivos para ver la carpeta de GitHub.
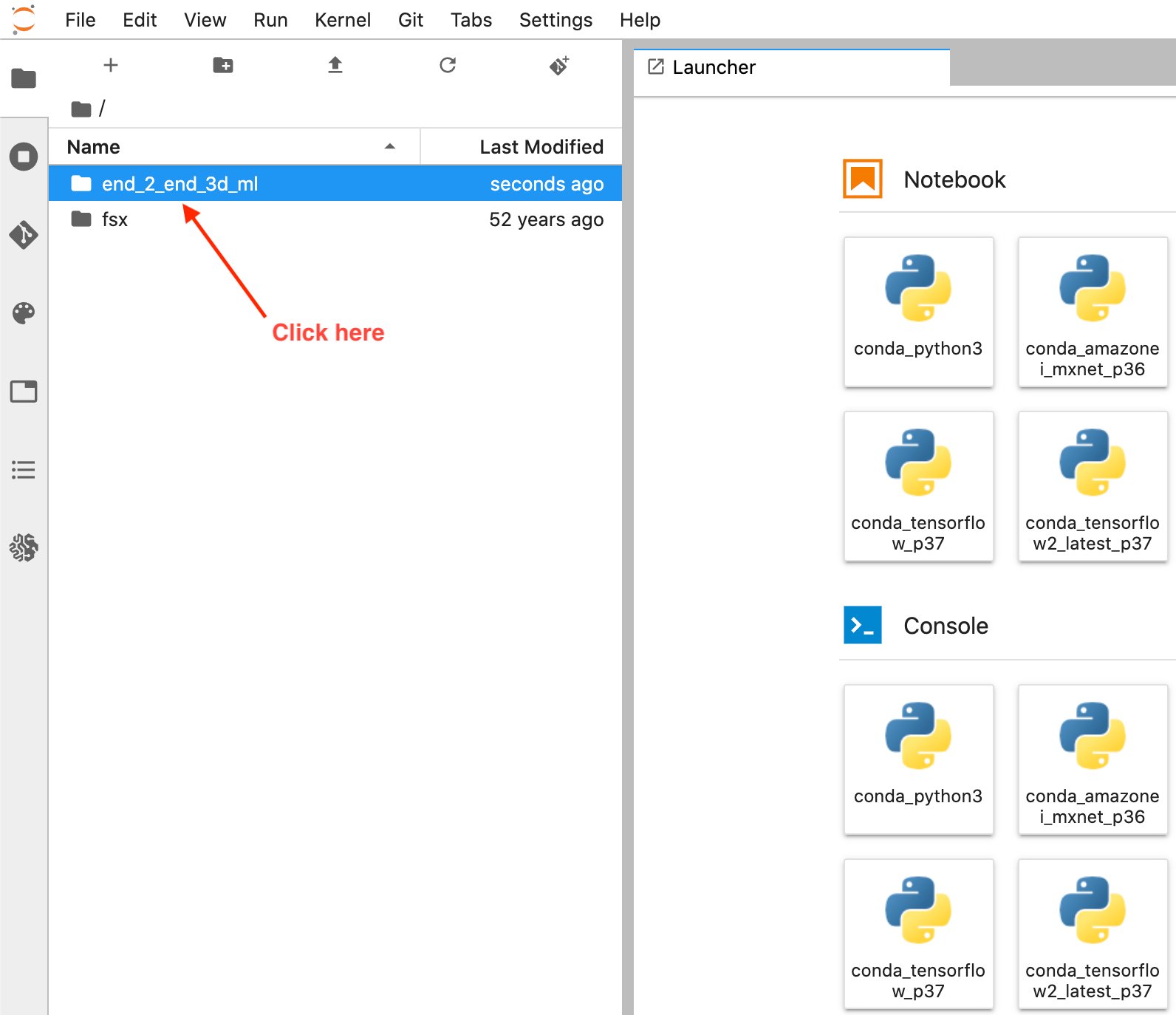
- Abra el cuaderno titulado
1_visualization.ipynb.
Funcionamiento de la computadora portátil
General
Las primeras celdas del cuaderno en la sección titulada Archivos descargados explica cómo descargar el conjunto de datos e inspeccionar los archivos que contiene. Una vez que se ejecutan las celdas, los datos tardan unos minutos en terminar de descargarse.
Una vez descargado, puede revisar la estructura de archivos de A2D2, que es una lista de escenas o unidades. Una escena es una breve grabación de los datos del sensor de nuestro vehículo. A2D2 proporciona 18 de estas escenas para que entrenemos, todas identificadas por fechas únicas. Cada escena contiene datos de cámara 2D, etiquetas 2D, anotaciones de cuboides 3D y nubes de puntos 3D.
Puede ver la estructura de archivos para el conjunto de datos A2D2 con lo siguiente:
Configuración del sensor A2D2
La siguiente sección recorre la lectura de algunos de estos datos de nube de puntos para asegurarnos de que los estamos interpretando correctamente y podemos visualizarlos en el cuaderno antes de intentar convertirlos a un formato listo para el etiquetado de datos.
Para cualquier tipo de configuración de conducción autónoma en la que tengamos datos de sensores 2D y 3D, la captura de datos de calibración del sensor es esencial. Además de los datos sin procesar, también descargamos cams_lidar.json. Este archivo contiene la traducción y la orientación de cada sensor en relación con el marco de coordenadas del vehículo, esto también se puede denominar posición del sensor o ubicación en el espacio. Esto es importante para convertir puntos del marco de coordenadas de un sensor al marco de coordenadas del vehículo. En otras palabras, es importante para visualizar los sensores 2D y 3D mientras conduce el vehículo. El marco de coordenadas del vehículo se define como un punto estático en el centro del vehículo, con el eje x en la dirección del movimiento hacia adelante del vehículo, el eje y que indica la izquierda y la derecha, siendo la izquierda positiva, y el eje z- eje que apunta a través del techo del vehículo. Un punto (X,Y,Z) de (5,2,1) significa que este punto está 5 metros por delante de nuestro vehículo, 2 metros a la izquierda y 1 metro por encima de nuestro vehículo. Tener estas calibraciones también nos permite proyectar puntos 3D en nuestra imagen 2D, lo que es especialmente útil para las tareas de etiquetado de nubes de puntos.
Para ver la configuración del sensor en el vehículo, consulte el siguiente diagrama.
Los datos de la nube de puntos en los que estamos entrenando están específicamente alineados con la cámara frontal o el centro frontal de la cámara: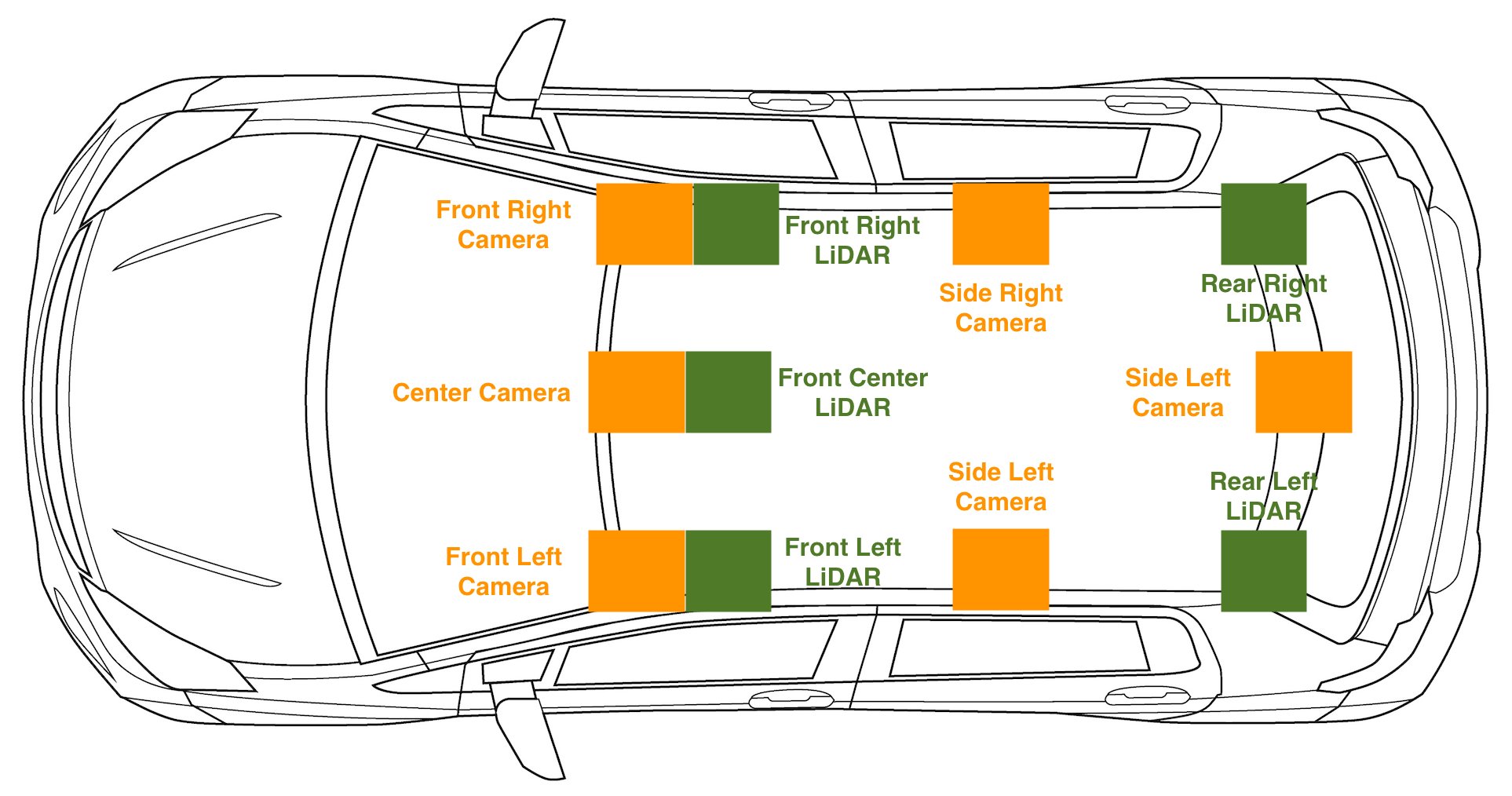
Esto coincide con nuestra visualización de sensores de cámara en 3D: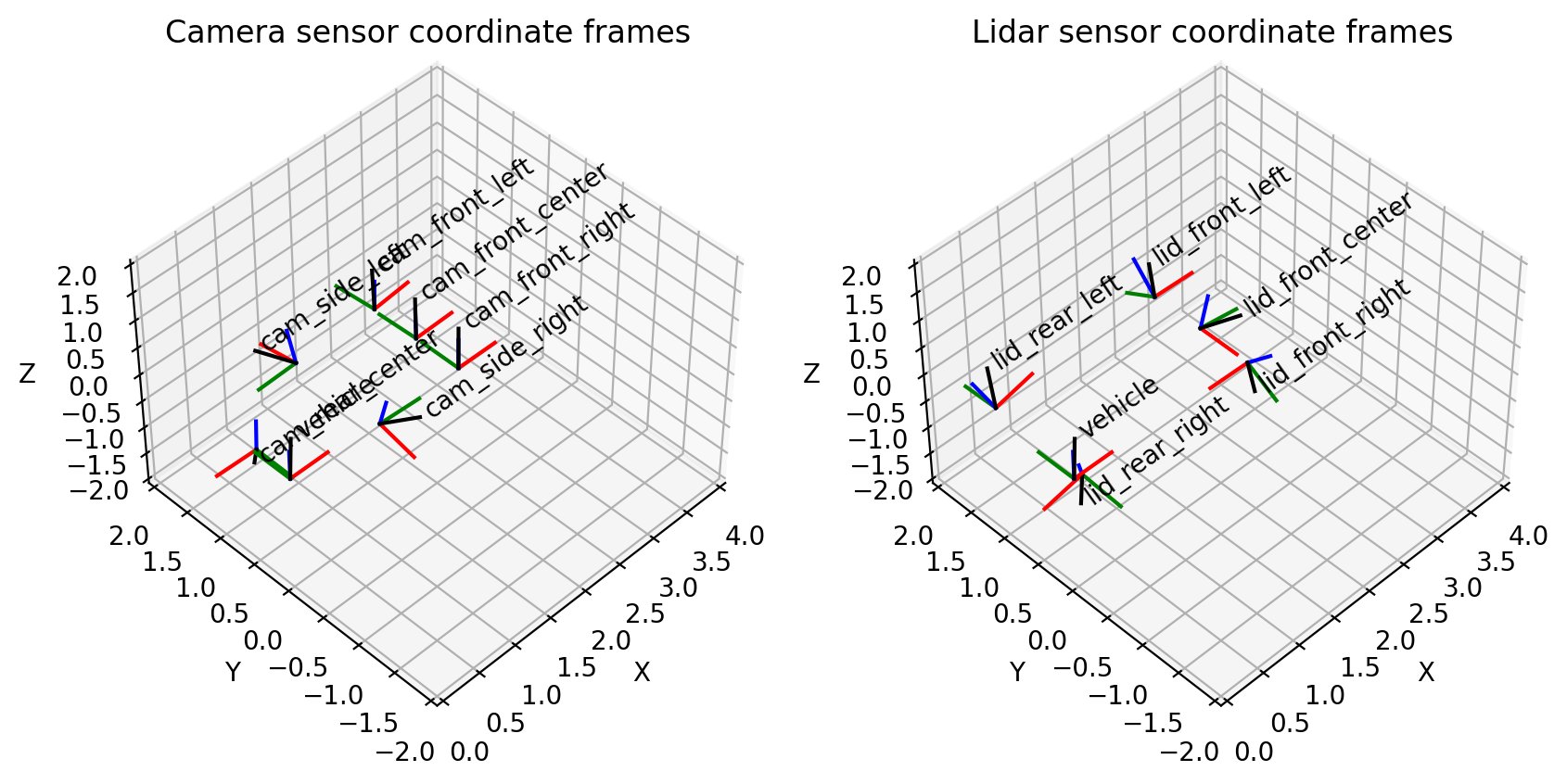
Esta parte del cuaderno explica cómo validar que el conjunto de datos A2D2 coincida con nuestras expectativas sobre las posiciones de los sensores y que podamos alinear los datos de los sensores de nube de puntos en el marco de la cámara. Siéntase libre de pasar todas las celdas por la que se titula Proyección de 3D a 2D para ver la superposición de datos de su nube de puntos en la siguiente imagen de la cámara.
Conversión a Amazon SageMaker Ground Truth

Después de visualizar nuestros datos en nuestro cuaderno, podemos convertir con confianza nuestras nubes de puntos en Amazon Formato 3D de SageMaker Ground Truth para verificar y ajustar nuestras etiquetas. Esta sección explica la conversión del formato de datos de A2D2 a un formato de Amazon Archivo de secuencia de SageMaker Ground Truth, con el formato de entrada utilizado por la modalidad de seguimiento de objetos.
El formato de archivo de secuencia incluye los formatos de nube de puntos, las imágenes asociadas con cada nube de puntos y todos los datos de posición y orientación del sensor necesarios para alinear las imágenes con las nubes de puntos. Estas conversiones se realizan utilizando la información del sensor leída en la sección anterior. El siguiente ejemplo es un formato de archivo de secuencia de Amazon SageMaker Ground Truth, que describe una secuencia con un solo paso de tiempo.
La nube de puntos para este paso de tiempo se encuentra en s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/20180807145028_lidar_frontcenter_000000091.txt y tiene un formato de <x coordinate> <y coordinate> <z coordinate>.
Asociada con la nube de puntos, hay una sola imagen de cámara ubicada en s3://sagemaker-us-east-1-322552456788/a2d2_smgt/20180807_145028_out/undistort_20180807145028_camera_frontcenter_000000091.png. Observe que tomamos el archivo de secuencia que define todos los parámetros de la cámara para permitir la proyección desde la nube de puntos a la cámara y viceversa.
La conversión a este formato de entrada requiere que escribamos una conversión del formato de datos de A2D2 a formatos de datos compatibles con Amazon SageMaker Ground Truth. Este es el mismo proceso al que debe someterse cualquier persona al traer sus propios datos para el etiquetado. Explicaremos cómo funciona esta conversión, paso a paso. Si sigue en el cuaderno, mire la función llamada a2d2_scene_to_smgt_sequence_and_seq_label.
Conversión de nube de puntos
El primer paso es convertir los datos de un archivo comprimido con formato Numpy (NPZ), que se generó con numpy.Savez método, a un formato 3D sin procesar aceptado para Amazon SageMaker Ground Truth. Específicamente, generamos un archivo con una fila por punto. Cada punto 3D está definido por tres coordenadas de coma flotante X, Y y Z. Cuando especificamos nuestro formato en el archivo de secuencia, usamos la cadena text/xyz para representar este formato. Amazon SageMaker Ground Truth también admite agregar valores de intensidad o puntos rojo verde azul (RGB).
Los archivos NPZ de A2D2 contienen varias matrices Numpy, cada una con su propio nombre. Para realizar una conversión, cargamos el archivo NPZ usando Numpy's carga método, acceda a la matriz llamada puntos (es decir, una matriz Nx3, donde N es el número de puntos en la nube de puntos), y guárdelo como texto en un nuevo archivo usando Numpy's Guardar método.
Preprocesamiento de imágenes
A continuación, preparamos nuestros archivos de imagen. A2D2 proporciona imágenes PNG y Amazon SageMaker Ground Truth admite imágenes PNG; sin embargo, estas imágenes están distorsionadas. La distorsión a menudo ocurre porque la lente que toma la imagen no está alineada paralelamente al plano de la imagen, lo que hace que algunas áreas de la imagen se vean más cerca de lo esperado. Esta distorsión describe la diferencia entre una cámara física y una modelo idealizado de cámara estenopeica. Si no se tiene en cuenta la distorsión, Amazon SageMaker Ground Truth no podrá representar nuestros puntos 3D sobre las vistas de la cámara, lo que hace que sea más difícil realizar el etiquetado. Para obtener un tutorial sobre la calibración de la cámara, consulte esta documentación de OpenCV.
Si bien Amazon SageMaker Ground Truth admite coeficientes de distorsión en su archivo de entrada, también puede realizar un preprocesamiento antes del trabajo de etiquetado. Dado que A2D2 proporciona un código de ayuda para eliminar la distorsión, lo aplicamos a la imagen y dejamos los campos relacionados con la distorsión fuera de nuestro archivo de secuencia. Tenga en cuenta que los campos relacionados con la distorsión incluyen k1, k2, k3, k4, p1, p2 y sesgo.
Conversión de posición, orientación y proyección de la cámara
Más allá de los archivos de datos sin procesar necesarios para el etiquetado, el archivo de secuencia también requiere información de posición y orientación de la cámara para realizar la proyección de puntos 3D en las vistas de cámara 2D. Necesitamos saber dónde está mirando la cámara en el espacio 3D para averiguar cómo se deben representar las etiquetas de cuboides 3D y los puntos 3D sobre nuestras imágenes.
Debido a que hemos cargado las posiciones de nuestros sensores en un administrador de transformación común en la sección de configuración del sensor A2D2, podemos consultar fácilmente el administrador de transformación para obtener la información que queremos. En nuestro caso, tratamos la posición del vehículo como (0, 0, 0) en cada cuadro porque no tenemos información de posición del sensor proporcionada por el conjunto de datos de detección de objetos de A2D2. Entonces, en relación con nuestro vehículo, la orientación y la posición de la cámara se describen mediante el siguiente código:
Ahora que se han convertido la posición y la orientación, también debemos proporcionar valores para fx, fy, cx y cy, todos los parámetros para cada cámara en el formato de archivo de secuencia.
Estos parámetros se refieren a valores en la matriz de la cámara. Mientras que la posición y la orientación describen en qué dirección está orientada una cámara, la matriz de la cámara describe el campo de visión de la cámara y exactamente cómo un punto 3D relativo a la cámara se convierte en una ubicación de píxel 2D en una imagen.
A2D2 proporciona una matriz de cámara. En el siguiente código se muestra una matriz de cámara de referencia, junto con la forma en que nuestro cuaderno indexa esta matriz para obtener los campos apropiados.
Con todos los campos analizados del formato de A2D2, podemos guardar el archivo de secuencia y usarlo en un Amazon Archivo de manifiesto de entrada de SageMaker Ground Truth para iniciar un trabajo de etiquetado. Este trabajo de etiquetado nos permite crear etiquetas de cuadro delimitador 3D para usar en sentido descendente para el entrenamiento del modelo 3D.
Ejecute todas las celdas hasta el final del cuaderno y asegúrese de reemplazar el workteam ARN con Amazon SageMaker Ground Truth workteam ARN que creó un requisito previo. Después de aproximadamente 10 minutos de etiquetar el tiempo de creación del trabajo, debería poder iniciar sesión en el portal del trabajador y usar el interfaz de usuario de etiquetado para visualizar tu escena.
Limpiar
Elimine la pila de AWS CloudFormation que implementó con el Pila de lanzamiento botón llamado ThreeD en la consola de AWS CloudFormation para eliminar todos los recursos utilizados en esta publicación, incluidas las instancias en ejecución.
Costos estimados
El costo aproximado es de $5 por 2 horas.
Conclusión
En esta publicación, demostramos cómo tomar datos 3D y convertirlos en un formulario listo para etiquetar en Amazon SageMaker Ground Truth. Con estos pasos, puede etiquetar sus propios datos 3D para entrenar modelos de detección de objetos. En la próxima publicación de esta serie, le mostraremos cómo tomar A2D2 y entrenar un modelo de detector de objetos en las etiquetas que ya están en el conjunto de datos.
¡Feliz edificio!
Acerca de los autores
 Isaac Privitera es científico de datos sénior en el Laboratorio de soluciones de aprendizaje automático de Amazon, donde desarrolla soluciones personalizadas de aprendizaje automático y aprendizaje profundo para abordar los problemas comerciales de los clientes. Trabaja principalmente en el espacio de la visión por computadora, y se enfoca en brindar a los clientes de AWS capacitación distribuida y aprendizaje activo.
Isaac Privitera es científico de datos sénior en el Laboratorio de soluciones de aprendizaje automático de Amazon, donde desarrolla soluciones personalizadas de aprendizaje automático y aprendizaje profundo para abordar los problemas comerciales de los clientes. Trabaja principalmente en el espacio de la visión por computadora, y se enfoca en brindar a los clientes de AWS capacitación distribuida y aprendizaje activo.
 Vidya Sagar Ravipati es Gerente en el Laboratorio de soluciones de aprendizaje automático de Amazon, donde aprovecha su vasta experiencia en sistemas distribuidos a gran escala y su pasión por el aprendizaje automático para ayudar a los clientes de AWS en diferentes verticales de la industria a acelerar su adopción de la inteligencia artificial y la nube. Anteriormente, fue ingeniero de aprendizaje automático en servicios de conectividad en Amazon que ayudó a crear plataformas de personalización y mantenimiento predictivo.
Vidya Sagar Ravipati es Gerente en el Laboratorio de soluciones de aprendizaje automático de Amazon, donde aprovecha su vasta experiencia en sistemas distribuidos a gran escala y su pasión por el aprendizaje automático para ayudar a los clientes de AWS en diferentes verticales de la industria a acelerar su adopción de la inteligencia artificial y la nube. Anteriormente, fue ingeniero de aprendizaje automático en servicios de conectividad en Amazon que ayudó a crear plataformas de personalización y mantenimiento predictivo.
 Jeremy Feltracco es un ingeniero de desarrollo de software con th Laboratorio de soluciones de aprendizaje automático de Amazon en los servicios web de Amazon. Utiliza su experiencia en visión artificial, robótica y aprendizaje automático para ayudar a los clientes de AWS a acelerar su adopción de IA.
Jeremy Feltracco es un ingeniero de desarrollo de software con th Laboratorio de soluciones de aprendizaje automático de Amazon en los servicios web de Amazon. Utiliza su experiencia en visión artificial, robótica y aprendizaje automático para ayudar a los clientes de AWS a acelerar su adopción de IA.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/using-amazon-sagemaker-with-point-clouds-part-1-ground-truth-for-3d-labeling/

