Esta publicación está coescrita con Andries Engelbrecht y Scott Teal de Snowflake.
Las empresas evolucionan constantemente y los líderes de datos se enfrentan cada día al desafío de cumplir nuevos requisitos. Para muchas empresas y grandes organizaciones, no es factible tener un motor o herramienta de procesamiento para hacer frente a los diversos requisitos comerciales. Entienden que un enfoque único ya no funciona y reconocen el valor de adoptar herramientas escalables y flexibles y formatos de datos abiertos para respaldar la interoperabilidad en una arquitectura de datos moderna para acelerar la entrega de nuevas soluciones.
Los clientes están utilizando AWS y Snowflake para desarrollar arquitecturas de datos diseñadas específicamente que proporcionen el rendimiento necesario para los casos de uso de análisis e inteligencia artificial (IA) modernos. La implementación de estas soluciones requiere el intercambio de datos entre almacenes de datos diseñados específicamente. Es por eso que Snowflake y AWS brindan soporte mejorado para Apache Iceberg para habilitar y facilitar la interoperabilidad de datos entre servicios de datos.
Apache Iceberg es un formato de tabla de código abierto que proporciona confiabilidad, simplicidad y alto rendimiento para grandes conjuntos de datos con integridad transaccional entre varios motores de procesamiento. En esta publicación, discutimos lo siguiente:
- Ventajas de las tablas Iceberg para lagos de datos
- Dos patrones arquitectónicos para compartir tablas Iceberg entre AWS y Snowflake:
- Gestiona tus mesas Iceberg con Pegamento AWS Catálogo de datos
- Gestiona tus mesas Iceberg con Snowflake
- El proceso de convertir tablas de lagos de datos existentes en tablas Iceberg sin copiar los datos.
Ahora que tiene un alto nivel de comprensión de los temas, profundicemos en cada uno de ellos en detalle.
Ventajas del Apache Iceberg
Apache Iceberg es un formato de tabla de datos distribuido, impulsado por la comunidad, con licencia Apache 2.0 y 100% de código abierto que ayuda a simplificar el procesamiento de datos en grandes conjuntos de datos almacenados en lagos de datos. Los ingenieros de datos utilizan Apache Iceberg porque es rápido, eficiente y confiable a cualquier escala y mantiene registros de cómo cambian los conjuntos de datos con el tiempo. Apache Iceberg ofrece integraciones con marcos de procesamiento de datos populares como Apache Spark, Apache Flink, Apache Hive, Presto y más.
Las tablas Iceberg mantienen metadatos para abstraer grandes colecciones de archivos, proporcionando funciones de gestión de datos que incluyen viaje en el tiempo, reversión, compactación de datos y evolución completa del esquema, lo que reduce la sobrecarga de gestión. Desarrollado originalmente en Netflix antes de ser de código abierto para la Apache Software Foundation, Apache Iceberg era un diseño en blanco para resolver desafíos comunes del lago de datos, como de usuario mejorada, confiabilidad y rendimiento, y ahora cuenta con el respaldo de una sólida comunidad de desarrolladores enfocados en mejorar y agregar nuevas funciones continuamente al proyecto, satisfaciendo las necesidades reales de los usuarios y brindándoles opciones.
Lagos de datos transaccionales creados en AWS y Snowflake
Snowflake ofrece varias integraciones para mesas Iceberg con múltiples opciones de almacenamiento, que incluyen Amazon S3y múltiples opciones de catálogo, incluyendo Catálogo de datos de AWS Glue y Copo de nieve. AWS proporciona integraciones para varios servicios de AWS También con tablas Iceberg, incluido AWS Glue Data Catalog para realizar un seguimiento de los metadatos de las tablas. La combinación de Snowflake y AWS le brinda múltiples opciones para crear un lago de datos transaccionales para casos de uso analíticos y de otro tipo, como el intercambio de datos y la colaboración. Al agregar una capa de metadatos a los lagos de datos, se obtiene una mejor experiencia de usuario, una administración simplificada y un rendimiento y confiabilidad mejorados en conjuntos de datos muy grandes.
Administre su tabla Iceberg con AWS Glue
Puede utilizar AWS Glue para ingerir, catalogar, transformar y administrar los datos en Servicio de almacenamiento simple de Amazon (Amazon S3). AWS Glue es un servicio de integración de datos sin servidor que le permite crear, ejecutar y monitorear visualmente canalizaciones de extracción, transformación y carga (ETL) para cargar datos en sus lagos de datos en formato Iceberg. Con AWS Glue, puede descubrir y conectarse a más de 70 fuentes de datos diversas y administrar sus datos en un catálogo de datos centralizado. Snowflake se integra con el catálogo de datos de AWS Glue para acceder al catálogo de tablas de Iceberg y a los archivos de Amazon S3 para consultas analíticas. Esto mejora enormemente el rendimiento y el coste informático en comparación con mesas externas en Snowflake, porque los metadatos adicionales mejoran la poda en los planes de consulta.
Puede utilizar esta misma integración para aprovechar las capacidades de colaboración e intercambio de datos en Snowflake. Esto puede ser muy poderoso si tiene datos en Amazon S3 y necesita habilitar el intercambio de datos de Snowflake con otras unidades de negocios, socios, proveedores o clientes.
El siguiente diagrama de arquitectura proporciona una descripción general de alto nivel de este patrón.
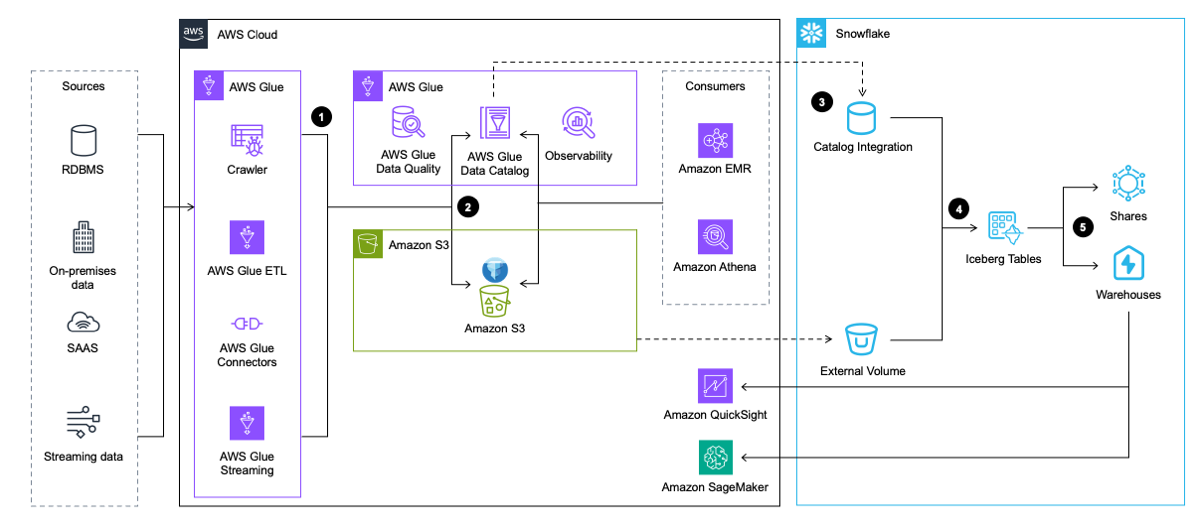
El flujo de trabajo incluye los siguientes pasos:
- AWS Glue extrae datos de aplicaciones, bases de datos y fuentes de streaming. Luego, AWS Glue lo transforma y lo carga en el lago de datos de Amazon S3 en formato de tabla Iceberg, mientras inserta y actualiza los metadatos sobre la tabla Iceberg en AWS Glue Data Catalog.
- El rastreador de AWS Glue genera y actualiza los metadatos de las tablas Iceberg y los almacena en el catálogo de datos de AWS Glue para las tablas Iceberg existentes en un lago de datos S3.
- Snowflake se integra con AWS Glue Data Catalog para recuperar la ubicación de la instantánea.
- En caso de una consulta, Snowflake utiliza la ubicación de la instantánea de AWS Glue Data Catalog para leer los datos de la tabla Iceberg en Amazon S3.
- Snowflake puede realizar consultas en los formatos de tabla Iceberg y Snowflake. Puede compartir datos para colaborar con una o más cuentas en la misma región de Snowflake. También puedes usar datos en Snowflake para visualización usando Amazon QuickSight, o usarlo para Fines de aprendizaje automático (ML) e inteligencia artificial (IA) Amazon SageMaker.
Gestiona tu mesa Iceberg con Snowflake
Un segundo patrón también proporciona interoperabilidad entre AWS y Snowflake, pero implementa canales de ingeniería de datos para la ingesta y transformación a Snowflake. En este patrón, Snowflake carga los datos en las tablas Iceberg a través de integraciones con servicios de AWS como AWS Glue o mediante otras fuentes como Snowpipe. Luego, Snowflake escribe datos directamente en Amazon S3 en formato Iceberg para que Snowflake y varios servicios de AWS accedan posteriormente, y Snowflake administra el catálogo de Iceberg que rastrea las ubicaciones de las instantáneas en las tablas para que accedan los servicios de AWS.
Al igual que el patrón anterior, puede usar tablas Iceberg administradas por Snowflake con el uso compartido de datos de Snowflake, pero también puede usar S3 para compartir conjuntos de datos en los casos en que una de las partes no tenga acceso a Snowflake.
El siguiente diagrama de arquitectura proporciona una descripción general de este patrón con tablas Iceberg administradas por Snowflake.
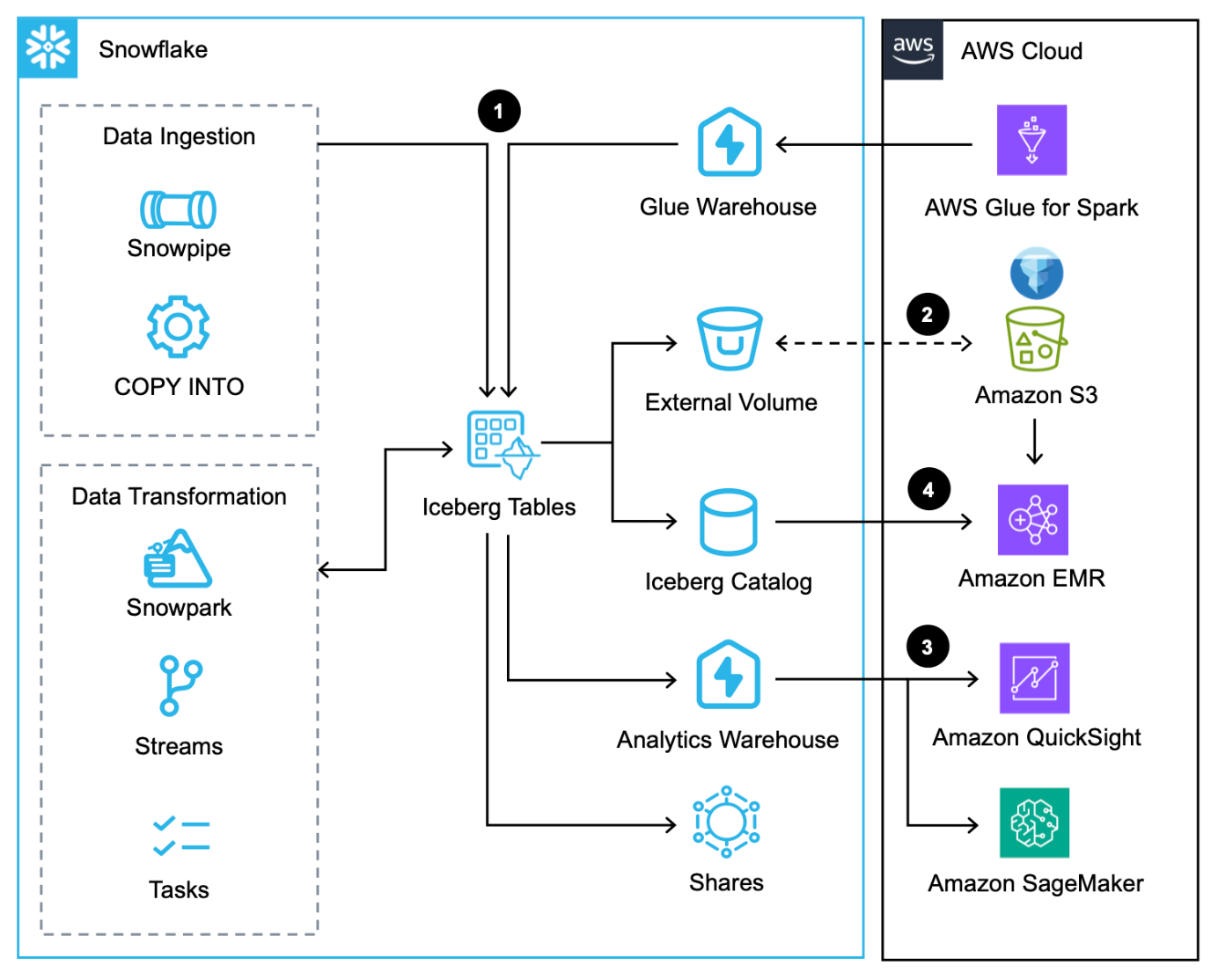
Este flujo de trabajo consta de los siguientes pasos:
- Además de cargar datos a través del Comando COPY, Pipa de nievey el conector nativo Snowflake para AWS Glue, puedes integrar datos a través de Snowflake Compartir datos.
- Snowflake escribe tablas Iceberg en Amazon S3 y actualiza los metadatos automáticamente con cada transacción.
- Snowflake consulta las tablas Iceberg en Amazon S3 para cargas de trabajo analíticas y de aprendizaje automático mediante servicios como QuickSight y SageMaker.
- Los servicios de Apache Spark en AWS pueden acceder a ubicaciones de instantáneas desde Snowflake a través de un SDK de Snowflake Iceberg Catalog y escanee directamente los archivos de la tabla Iceberg en Amazon S3.
Comparando soluciones
Estos dos patrones resaltan las opciones disponibles para los usuarios de datos hoy en día para maximizar la interoperabilidad de sus datos entre Snowflake y AWS utilizando Apache Iceberg. Pero, ¿qué patrón es ideal para su caso de uso? Si ya está utilizando AWS Glue Data Catalog y solo necesita Snowflake para consultas de lectura, entonces el primer patrón puede integrar Snowflake con AWS Glue y Amazon S3 para consultar tablas Iceberg. Si aún no está utilizando AWS Glue Data Catalog y requiere que Snowflake realice lecturas y escrituras, entonces el segundo patrón probablemente sea una buena solución que permita almacenar y acceder a datos desde AWS.
Teniendo en cuenta que las lecturas y escrituras probablemente operarán por tabla en lugar de por toda la arquitectura de datos, es recomendable utilizar una combinación de ambos patrones.
Migre lagos de datos existentes a un lago de datos transaccional utilizando Apache Iceberg
Puede convertir tablas de lagos de datos existentes basadas en Parquet, ORC y Avro en Amazon S3 al formato Iceberg para aprovechar los beneficios de la integridad transaccional y al mismo tiempo mejorar el rendimiento y la experiencia del usuario. Hay varias opciones de migración de tablas Iceberg (INSTANTÁNEA, EMIGRARy AGREGAR ARCHIVOS) para migrar las tablas del lago de datos existentes al formato Iceberg, que es preferible a reescribir todos los archivos de datos subyacentes, un esfuerzo costoso y que requiere mucho tiempo con grandes conjuntos de datos. En esta sección, nos centramos en ADD_FILES porque es útil para migraciones personalizadas.
Para las opciones ADD_FILES, puede utilizar AWS Glue para generar metadatos y estadísticas de Iceberg para una tabla de lago de datos existente y crear nuevas tablas de Iceberg en AWS Glue Data Catalog para uso futuro sin necesidad de reescribir los datos subyacentes. Para obtener instrucciones sobre cómo generar metadatos y estadísticas de Iceberg mediante AWS Glue, consulte Migre un lago de datos existente a un lago de datos transaccional utilizando Apache Iceberg or Convierta las tablas del lago de datos de Amazon S3 existentes en tablas Iceberg no administradas de Snowflake mediante AWS Glue.
Esta opción requiere que detenga las canalizaciones de datos mientras convierte los archivos a tablas Iceberg, lo cual es un proceso sencillo en AWS Glue porque solo es necesario cambiar el destino a una tabla Iceberg.
Conclusión
En esta publicación, vio los dos patrones de arquitectura para implementar Apache Iceberg en un lago de datos para una mejor interoperabilidad entre AWS y Snowflake. También brindamos orientación sobre cómo migrar tablas de lagos de datos existentes al formato Iceberg.
REGÍSTRATE para Día del desarrollador de AWS el 10 de abril ponerse manos a la obra no solo con Apache Iceberg, sino también con canales de transmisión de datos con Manguera de datos de Amazon y Transmisión de Snowpipey aplicaciones de IA generativa con Streamlit en copo de nieve y lecho rocoso del amazonas.
Acerca de los autores
 Andrés Engelbrecht es Arquitecto Principal de Soluciones para Socios en Snowflake y trabaja con socios estratégicos. Participa activamente con socios estratégicos como AWS que respaldan integraciones de productos y servicios, así como el desarrollo de soluciones conjuntas con socios. Andries tiene más de 20 años de experiencia en el campo de datos y análisis.
Andrés Engelbrecht es Arquitecto Principal de Soluciones para Socios en Snowflake y trabaja con socios estratégicos. Participa activamente con socios estratégicos como AWS que respaldan integraciones de productos y servicios, así como el desarrollo de soluciones conjuntas con socios. Andries tiene más de 20 años de experiencia en el campo de datos y análisis.
 Deen Bandhu Prasad es especialista sénior en análisis en AWS y se especializa en servicios de big data. Le apasiona ayudar a los clientes a crear arquitecturas de datos modernas en la nube de AWS. Ha ayudado a clientes de todos los tamaños a implementar soluciones de gestión de datos, almacén de datos y lago de datos.
Deen Bandhu Prasad es especialista sénior en análisis en AWS y se especializa en servicios de big data. Le apasiona ayudar a los clientes a crear arquitecturas de datos modernas en la nube de AWS. Ha ayudado a clientes de todos los tamaños a implementar soluciones de gestión de datos, almacén de datos y lago de datos.
 Brian Dolan Se unió a Amazon como Gerente de Relaciones Militares en 2012 después de su primera carrera como Aviador Naval. En 2014, Brian se unió a Amazon Web Services, donde ayudó a clientes canadienses, desde nuevas empresas hasta empresas, a explorar la nube de AWS. Más recientemente, Brian fue miembro del equipo de desarrollo de negocios no relacionales como especialista en comercialización para Amazon DynamoDB y Amazon Keyspaces antes de unirse a la organización de especialistas mundiales en análisis en 2022 como especialista en comercialización para AWS Glue.
Brian Dolan Se unió a Amazon como Gerente de Relaciones Militares en 2012 después de su primera carrera como Aviador Naval. En 2014, Brian se unió a Amazon Web Services, donde ayudó a clientes canadienses, desde nuevas empresas hasta empresas, a explorar la nube de AWS. Más recientemente, Brian fue miembro del equipo de desarrollo de negocios no relacionales como especialista en comercialización para Amazon DynamoDB y Amazon Keyspaces antes de unirse a la organización de especialistas mundiales en análisis en 2022 como especialista en comercialización para AWS Glue.
 Nidhi Gupta es arquitecto de soluciones de socio sénior en AWS. Pasa sus días trabajando con clientes y socios, resolviendo desafíos arquitectónicos. Le apasiona la integración y orquestación de datos, el procesamiento de big data y sin servidor, y el aprendizaje automático. Nidhi tiene una amplia experiencia liderando el diseño de arquitectura y el lanzamiento de producción e implementaciones para cargas de trabajo de datos.
Nidhi Gupta es arquitecto de soluciones de socio sénior en AWS. Pasa sus días trabajando con clientes y socios, resolviendo desafíos arquitectónicos. Le apasiona la integración y orquestación de datos, el procesamiento de big data y sin servidor, y el aprendizaje automático. Nidhi tiene una amplia experiencia liderando el diseño de arquitectura y el lanzamiento de producción e implementaciones para cargas de trabajo de datos.
 Scott Teal es líder de marketing de productos en Snowflake y se centra en lagos de datos, almacenamiento y gobernanza.
Scott Teal es líder de marketing de productos en Snowflake y se centra en lagos de datos, almacenamiento y gobernanza.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-your-data-lake-with-amazon-s3-aws-glue-and-snowflake/

