A medida que las empresas recopilan cantidades cada vez mayores de datos de diversas fuentes, la estructura y organización de esos datos a menudo deben cambiar con el tiempo para satisfacer las necesidades analíticas en evolución. Sin embargo, alterar el esquema y las particiones de tablas en los lagos de datos tradicionales puede ser una tarea disruptiva y que requiere mucho tiempo, ya que requiere cambiar el nombre o recrear tablas enteras y reprocesar grandes conjuntos de datos. Esto dificulta la agilidad y el tiempo de comprensión.
La evolución del esquema permite agregar, eliminar, cambiar el nombre o modificar columnas sin necesidad de reescribir los datos existentes. Esto es fundamental para que las empresas en rápido movimiento aumenten las estructuras de datos para admitir nuevos casos de uso. Por ejemplo, una empresa de comercio electrónico puede agregar nuevos atributos demográficos de clientes o indicadores de estado de pedidos para enriquecer los análisis. iceberg apache gestiona estos cambios de esquema de forma compatible con versiones anteriores a través de su innovadora arquitectura de evolución de tablas de metadatos.
De manera similar, la evolución de las particiones permite agregar, eliminar o dividir particiones sin problemas. Por ejemplo, un mercado de comercio electrónico puede inicialmente dividir los datos de los pedidos por día. A medida que se acumulan los pedidos y las consultas por día se vuelven ineficientes, es posible que se divida en particiones de día y de ID de cliente. La partición de tablas organiza grandes conjuntos de datos de manera más eficiente para el rendimiento de las consultas. Iceberg ofrece a las empresas la flexibilidad de ajustar particiones de forma incremental en lugar de requerir tediosos procedimientos de reconstrucción. Se pueden agregar nuevas particiones de forma totalmente compatible sin tiempo de inactividad ni tener que reescribir archivos de datos existentes.
Esta publicación demuestra cómo puedes aprovechar Iceberg, Servicio de almacenamiento simple de Amazon (Amazon S3), Pegamento AWS, Formación del lago AWSy Gestión de identidades y accesos de AWS (IAM) para implementar un lago de datos transaccionales que respalde una evolución perfecta. Al permitir ajustes sencillos de esquemas y particiones a medida que evoluciona la información sobre los datos, puede beneficiarse de la flexibilidad preparada para el futuro necesaria para el éxito empresarial.
Resumen de la solución
Para nuestro caso de uso de ejemplo, una gran empresa de comercio electrónico ficticia procesa miles de pedidos cada día. Cuando los pedidos se reciben, actualizan, cancelan, envían, entregan o devuelven, los cambios se realizan en su sistema local y esos cambios deben replicarse en un lago de datos de S3 para que los analistas de datos puedan ejecutar consultas a través de Atenea amazónica. Los cambios también pueden contener actualizaciones de esquema. Debido a los requisitos de seguridad de diferentes organizaciones, necesitan gestionar un control de acceso detallado para los analistas a través de Lake Formation.
El siguiente diagrama ilustra la arquitectura de la solución.
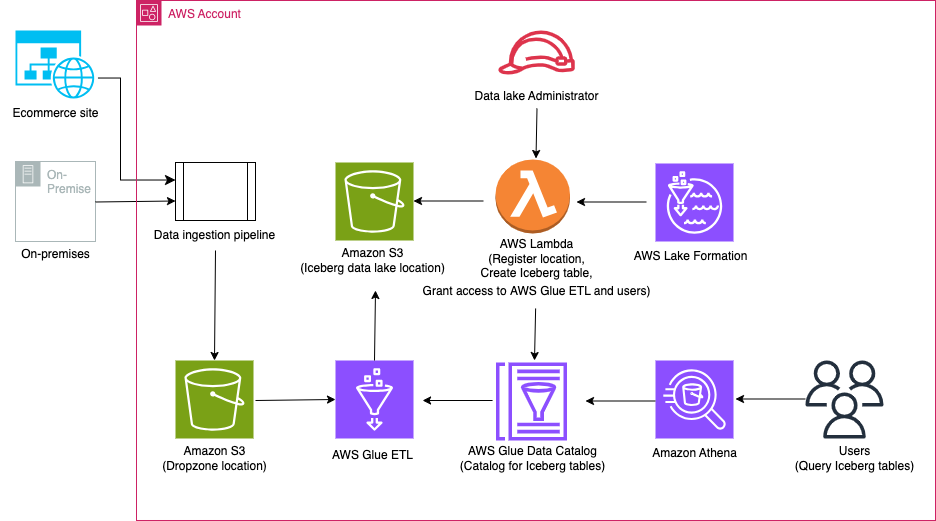
El flujo de trabajo de la solución incluye los siguientes pasos clave:
- Ingiere datos locales en una ubicación de Dropzone mediante una canalización de ingesta de datos.
- Combine los datos de la ubicación de Dropzone en Iceberg utilizando AWS Glue.
- Consulta los datos usando Athena.
Requisitos previos
Para este tutorial, debe tener los siguientes requisitos previos:
Configurar la infraestructura con AWS CloudFormation
Para crear su infraestructura con un Formación en la nube de AWS plantilla, complete los siguientes pasos:
- Inicie sesión como administrador en su cuenta de AWS.
- Abra la consola de AWS CloudFormation.
- Elige Pila de lanzamiento:

- Nombre de pila, ingresa un nombre (para esta publicación, icebergdemo1).
- Elige Siguiente.
- Proporcione información para los siguientes parámetros:
DatalakeUserNameDatalakeUserPasswordDatabaseNameTableNameDatabaseLFTagKeyDatabaseLFTagValueTableLFTagKeyTableLFTagValue
- Elige Siguiente.
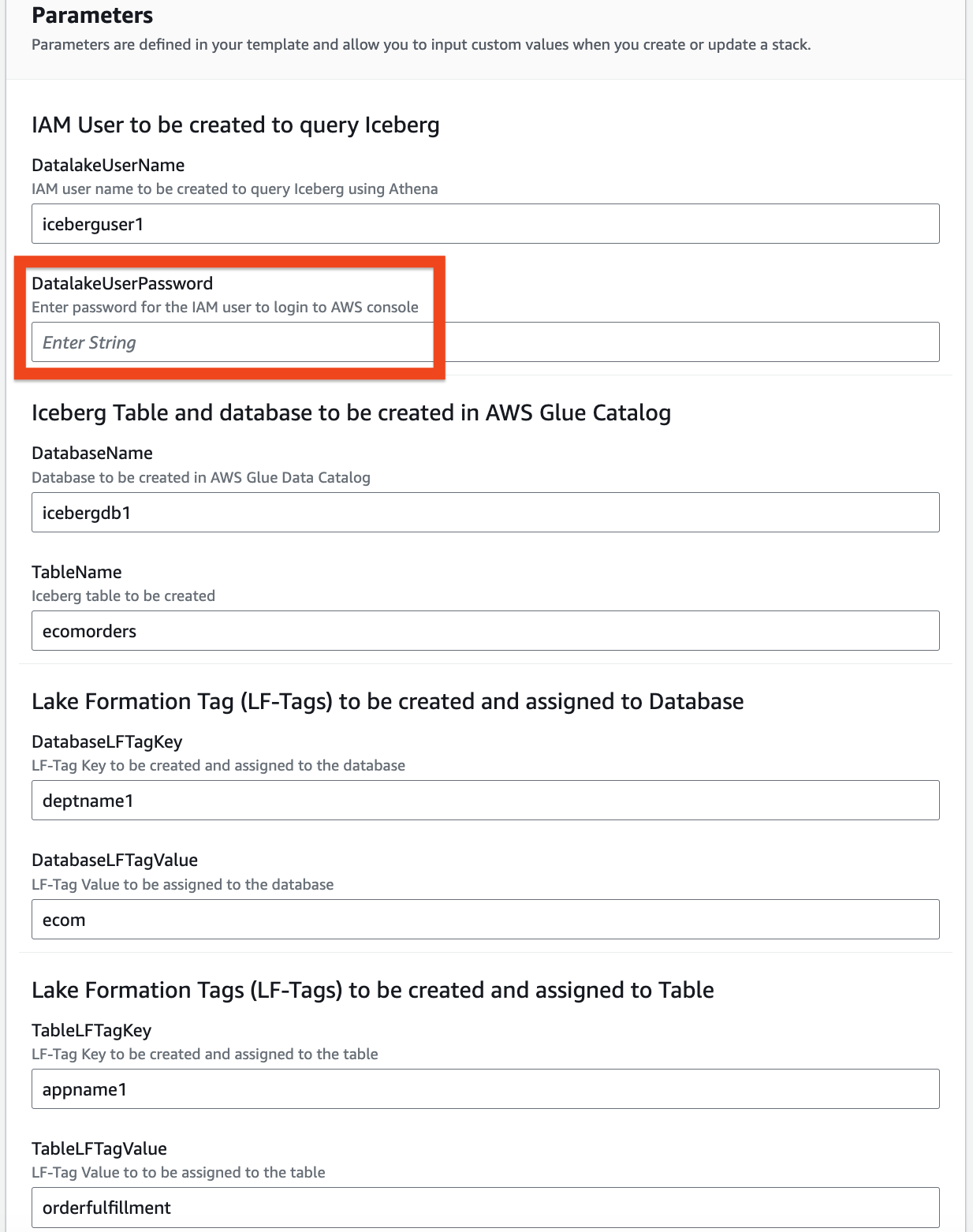
- Elige Siguiente otra vez.
- En Revisar sección, revise los valores que ingresó.
- Seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM con nombres personalizados y elige Enviar.
En unos minutos, el estado de la pila cambiará a CREATE_COMPLETE.
Usted puede ir a la Pestaña de salidas de la pila para ver todos los recursos que ha aprovisionado. Los recursos tienen el prefijo del nombre de la pila que proporcionaste (para esta publicación, icebergdemo1).
Cree una tabla Iceberg usando Lambda y otorgue acceso usando Lake Formation
Para crear una tabla Iceberg y otorgarle acceso, complete los siguientes pasos:
- Navegue hasta la Recursos pestaña de la pila de CloudFormation icebergdemo1 y busque el ID lógico llamado
LambdaFunctionIceberg. - Elija el hipervínculo del ID físico asociado.
Serás redirigido a la función Lambda. icebergdemo1-Lambda-Create-Iceberg-and-Grant-access.
- En Configuración pestaña, elegir Variables de entorno en el panel izquierdo.

- En Código pestaña, puede inspeccionar el código de función.
La función utiliza el AWS SDK para Python (Boto3) API para aprovisionar los recursos. Asume la función de administrador del lago de datos aprovisionado para realizar las siguientes tareas:
- Grant DATA_LOCATION_ACCESS acceso a la función de administrador del lago de datos en la ubicación registrada del lago de datos
- Crear Etiquetas de formación de lagos (etiquetas LF)
- Cree una base de datos en el catálogo de datos de AWS Glue utilizando AWS Glue CREATE_DATABASE API
- Asignar etiquetas LF a la base de datos
- Conceder acceso DESCRIBE a la base de datos mediante etiquetas LF al usuario de IAM del lago de datos y al rol de IAM ETL de AWS Glue
- Cree una tabla Iceberg con AWS Glue crear mesa API:
- Asignar etiquetas LF a la mesa
- Otorgue DESCRIBE y SELECT en las etiquetas LF de la tabla Iceberg para el usuario de IAM del lago de datos
- Otorgue acceso TODOS, DESCRIBIR, SELECCIONAR, INSERTAR, ELIMINAR y ALTERAR en las etiquetas LF de la tabla Iceberg al rol ETL IAM de AWS Glue
- En Probar pestaña, elegir Probar para ejecutar la función.

Cuando se complete la función, verá el mensaje "Ejecutando función: exitosa".
Lake Formation lo ayuda a administrar, proteger y compartir globalmente datos de manera centralizada para análisis y aprendizaje automático. Con Lake Formation, puede administrar un control de acceso detallado para los datos del lago de datos en Amazon S3 y sus metadatos en el catálogo de datos.
Para agregar una ubicación de Amazon S3 como almacenamiento Iceberg en su lago de datos, registrar la ubicación con Formación del Lago. Luego puede usar los permisos de Lake Formation para un control de acceso detallado a los objetos del catálogo de datos que apuntan a esta ubicación y a los datos subyacentes en la ubicación.
La pila de CloudFormation registró la ubicación del lago de datos.

Permisos de ubicación de datos en Lake Formation permite a los directores crear y modificar recursos del catálogo de datos que apuntan a las ubicaciones registradas designadas de Amazon S3. Los permisos de ubicación de datos funcionan además de Lake Formation permisos de datos para proteger la información en su lago de datos.
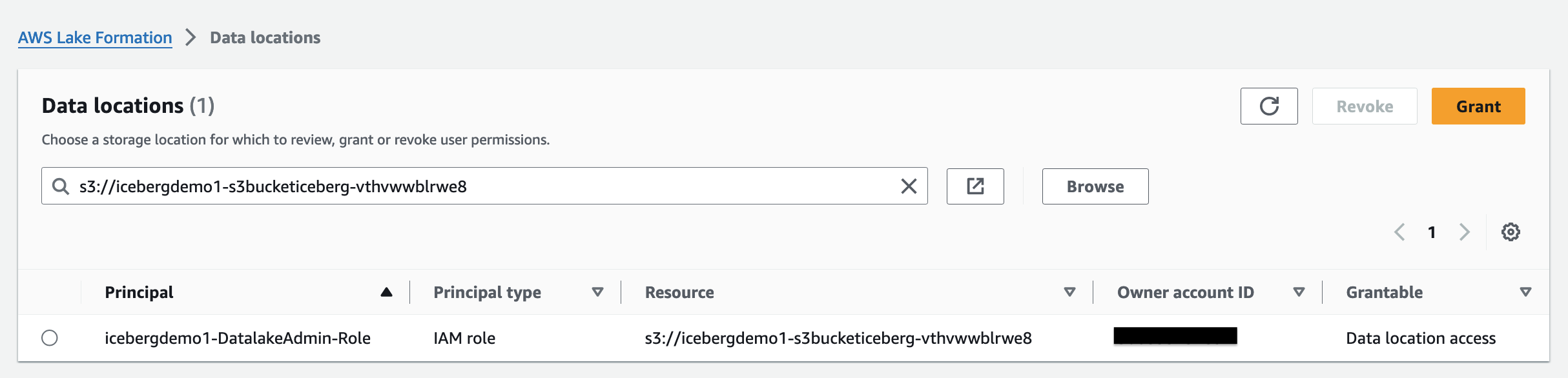
Control de acceso basado en etiquetas de Lake Formation (LF-TBAC) es una estrategia de autorización que define permisos basados en atributos. En Lake Formation, estos atributos se denominan etiquetas LF. Puede adjuntar etiquetas LF a recursos del catálogo de datos, entidades principales de Lake Formation y columnas de tabla. Puede asignar y revocar permisos en los recursos de Lake Formation utilizando estas etiquetas LF. Lake Formation permite operaciones en esos recursos cuando la etiqueta del principal coincide con la etiqueta del recurso.
Verifique la tabla Iceberg desde la consola de Lake Formation
Para verificar la tabla Iceberg, complete los siguientes pasos:
- En la consola de Lake Formation, elija Bases de datos en el panel de navegación.
- Abra la página de detalles para
icebergdb1.
Puede ver las etiquetas LF de la base de datos asociada.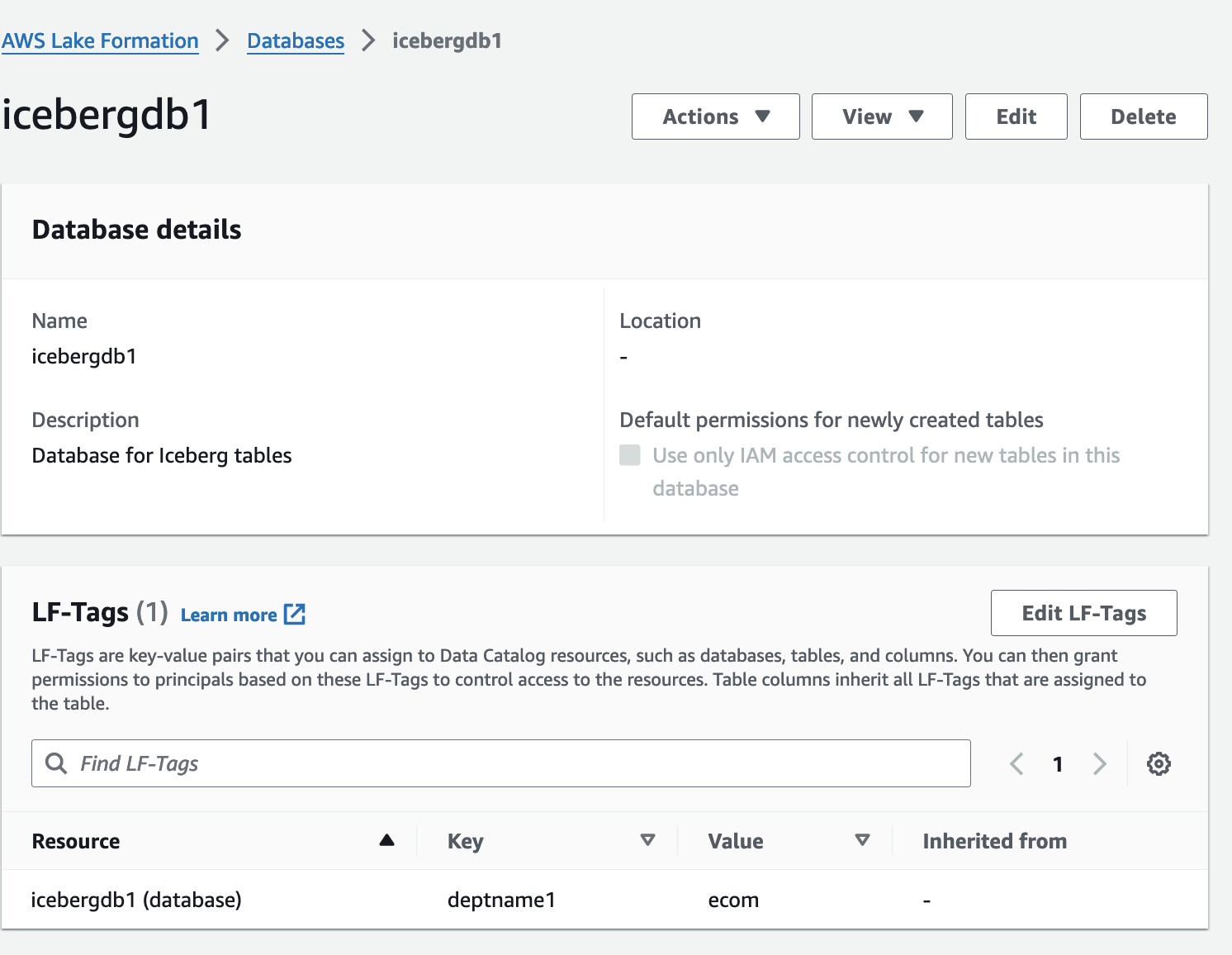
- Elige Mesas en el panel de navegación.
- Abra la página de detalles para
ecomorders.
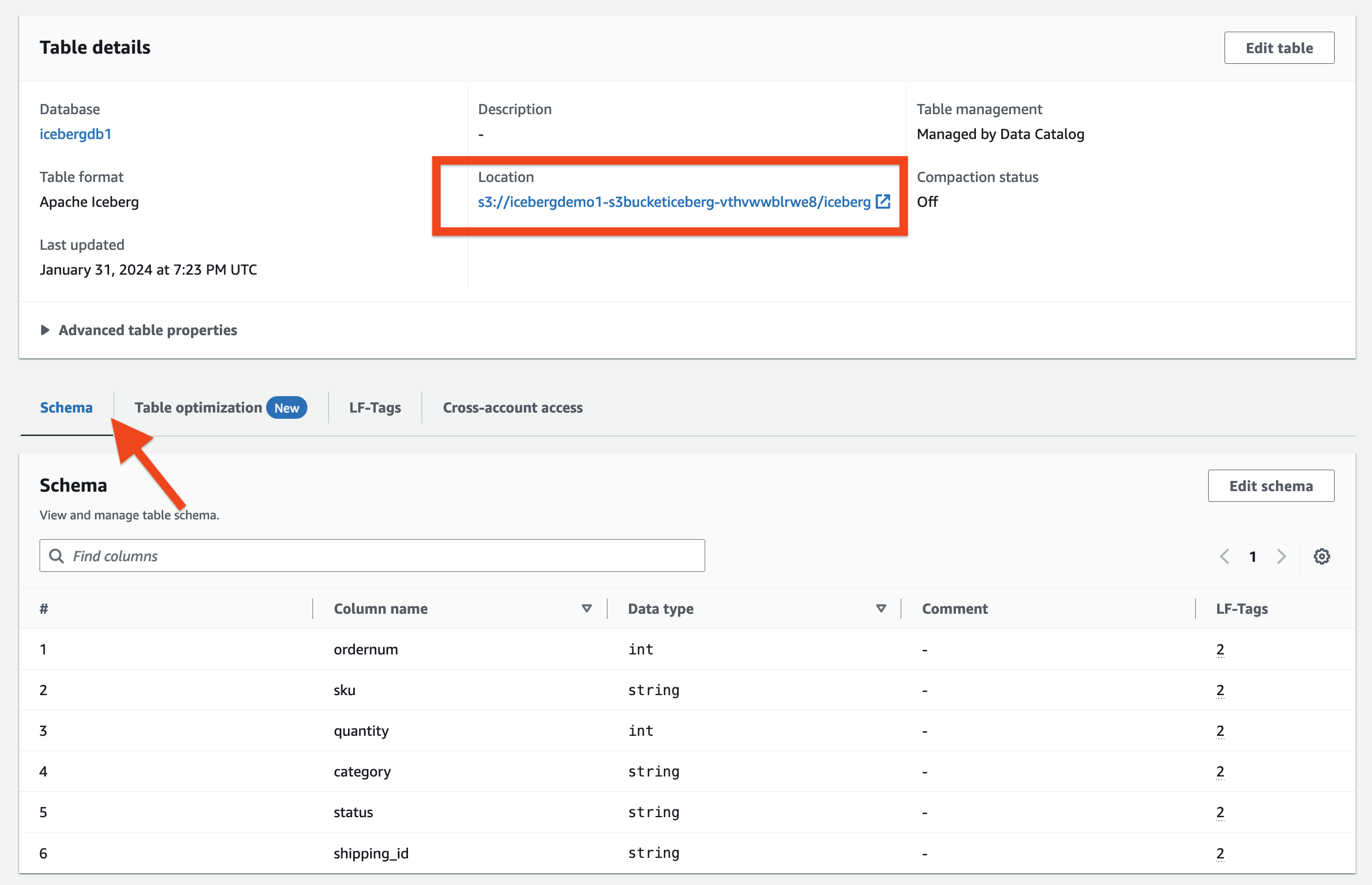
En Detalles de la tabla sección se puede observar lo siguiente:
- Formato de tabla muestra como iceberg apache
- Manejo de mesa muestra como Gestionado por el catálogo de datos
- Destino enumera la ubicación del lago de datos de la tabla Iceberg
En Etiquetas LF sección, puede ver la tabla asociada LF-Tags.
En Detalles de la tabla sección, ampliar Propiedades avanzadas de la tabla para ver lo siguiente:
metadata_locationapunta a la ubicación del archivo de metadatos de la tabla Icebergtable_typemuestra comoICEBERG
En Esquema pestaña, puede ver las columnas definidas en la tabla Iceberg.
Integre Iceberg con AWS Glue Data Catalog y Amazon S3
Iceberg rastrea archivos de datos individuales en una tabla en lugar de directorios. Cuando hay una confirmación explícita en la tabla, Iceberg crea archivos de datos y los agrega a la tabla. Iceberg mantiene el estado de la tabla en archivos de metadatos. Cualquier cambio en el estado de la tabla crea un nuevo archivo de metadatos que reemplaza atómicamente los metadatos anteriores. Los archivos de metadatos rastrean el esquema de la tabla, la configuración de particiones y otras propiedades.
Iceberg requiere que los sistemas de archivos que admitan las operaciones sean compatibles con almacenes de objetos como Amazon S3.
Iceberg crea instantáneas del contenido de la tabla. Cada instantánea es un conjunto completo de archivos de datos en la tabla en un momento dado. Los archivos de datos en instantáneas se almacenan en uno o más archivos de manifiesto que contienen una fila para cada archivo de datos de la tabla, sus datos de partición y sus métricas.
El siguiente diagrama ilustra esta jerarquía.
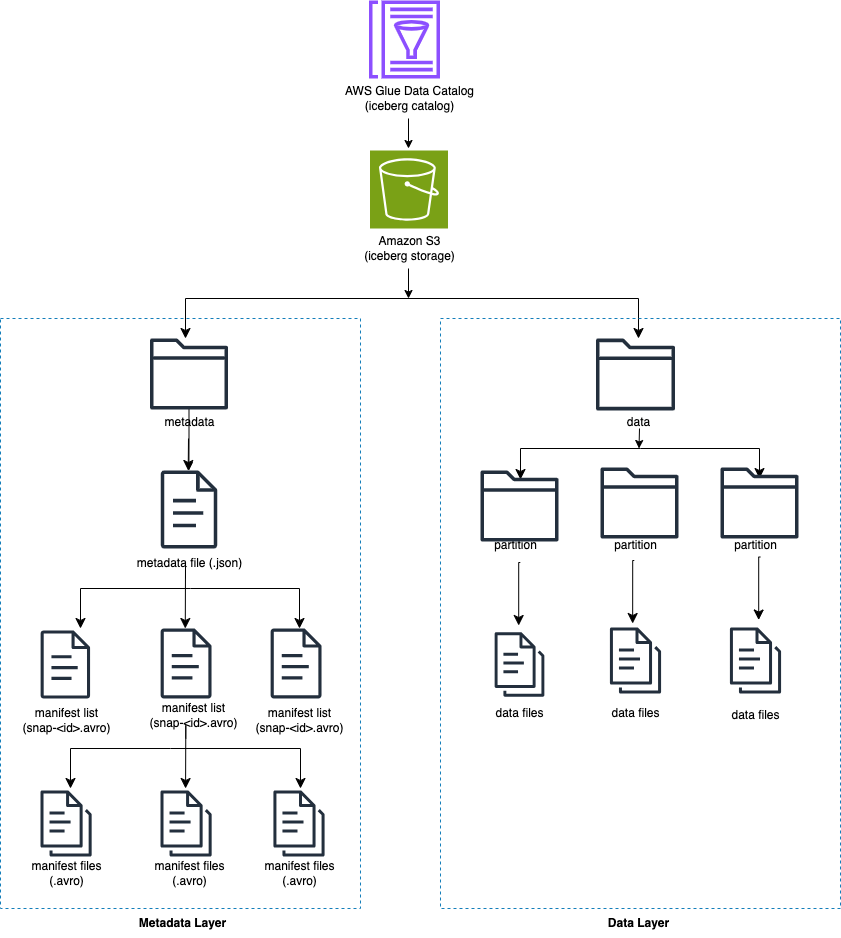
Cuando crea una tabla Iceberg, primero crea la carpeta de metadatos y un archivo de metadatos en la carpeta de metadatos. La carpeta de datos se crea cuando carga datos en la tabla Iceberg.

Contenido del archivo de metadatos Iceberg
El archivo de metadatos Iceberg contiene mucha información, incluida la siguiente:
- versión-formato –Versión de la mesa Iceberg
- Destino – Ubicación de la tabla en Amazon S3
- Esquemas – Nombre y tipo de datos de todas las columnas de la tabla.
- especificaciones de partición – Columnas particionadas
- órdenes de clasificación – Orden de clasificación de las columnas
- propiedades – Propiedades de la tabla
- ID de instantánea actual – Instantánea actual
- refs – Referencias de tablas
- instantáneas – Lista de instantáneas, cada una de las cuales contiene la siguiente información:
- secuencia de números – Número de secuencia de instantáneas en orden cronológico (el número más alto representa la instantánea actual, 1 para la primera instantánea)
- ID de instantánea – ID de instantánea
- marca de tiempo-ms – Marca de tiempo en la que se confirmó la instantánea.
- resumen – Resumen de cambios cometidos
- lista de manifiesto – Lista de manifiestos; este nombre de archivo comienza con snap-<id-instantánea>
- ID de esquema – Número de secuencia del esquema en orden cronológico (el número más alto representa el esquema actual)
- registro de instantáneas – Lista de instantáneas en orden cronológico.
- registro de metadatos – Lista de archivos de metadatos en orden cronológico
El archivo de metadatos tiene todos los cambios históricos en los datos y el esquema de la tabla. Revisar el contenido del archivo metarchivo directamente puede ser una tarea que requiere mucho tiempo. Afortunadamente, puedes consultar el Metadatos de Iceberg usando Athena.
Marco Iceberg en AWS Glue
AWS Glue 4.0 admite tablas Iceberg registradas con Lake Formation. En los trabajos ETL de AWS Glue, necesita el siguiente código para habilitar el marco Iceberg:
Para el acceso de lectura/escritura a los datos subyacentes, además de los permisos de Lake Formation, se otorgó el rol IAM de AWS Glue para ejecutar los trabajos ETL de AWS Glue. formación del lago: GetDataAccess Permiso IAM. Con este permiso, Lake Formation concede la solicitud de credenciales temporales para acceder a los datos.
La pila de CloudFormation aprovisionó los cuatro trabajos ETL de AWS Glue. El nombre de cada trabajo comienza con el nombre de su pila (icebergdemo1). Complete los siguientes pasos para ver los trabajos:
- Inicie sesión como administrador en su cuenta de AWS.
- En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación.
- Buscar trabajos con
icebergdemo1en el nombre.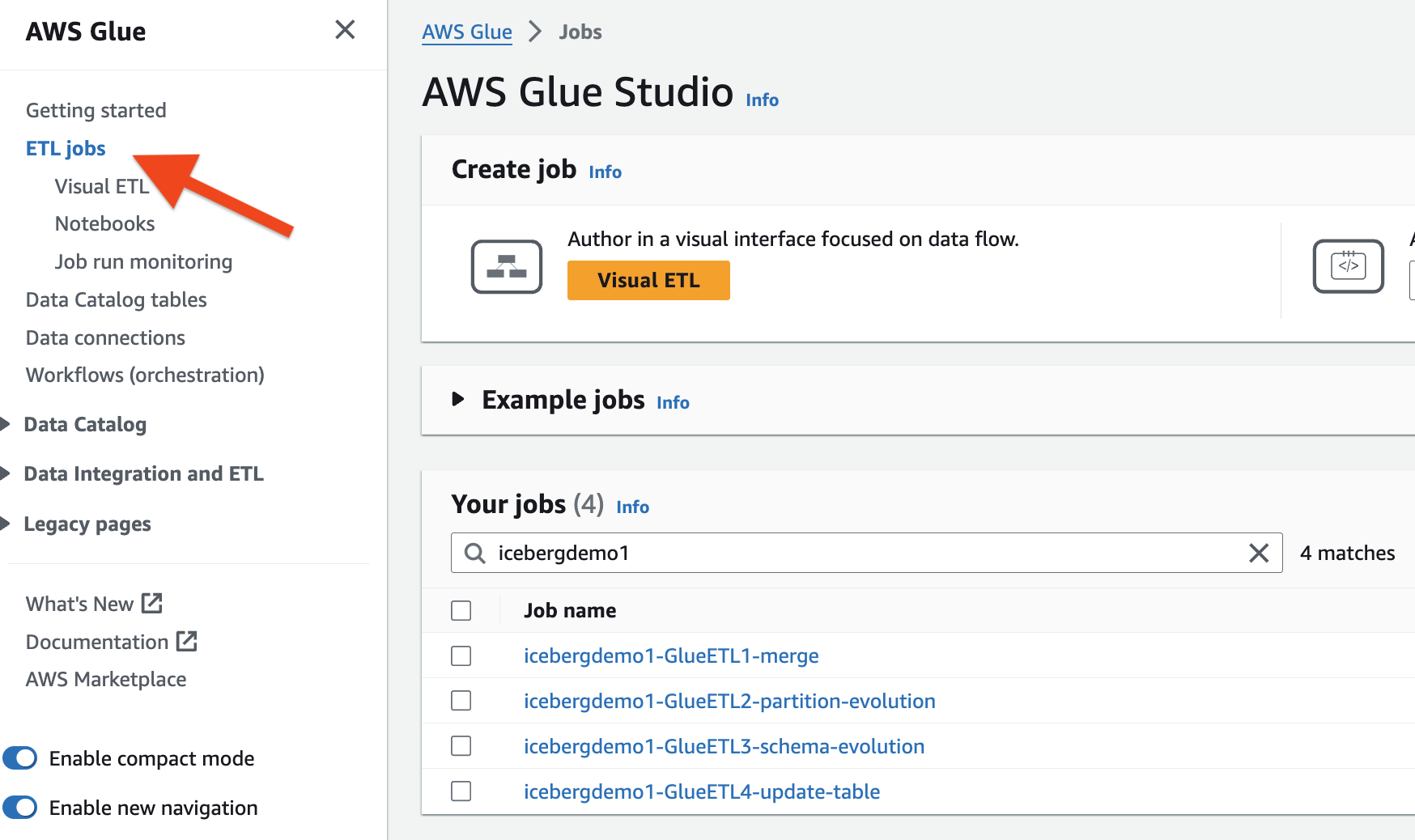
Fusionar datos de Dropzone en la tabla Iceberg
Para nuestro caso de uso, la empresa ingiere los datos de sus pedidos de comercio electrónico diariamente desde su ubicación local a una ubicación de Amazon S3 Dropzone. La pila de CloudFormation cargó tres archivos con pedidos de muestra durante 3 días, como se muestra en las siguientes figuras. Verás los datos en la ubicación de Dropzone. s3://icebergdemo1-s3bucketdropzone-kunftrcblhsk/data.
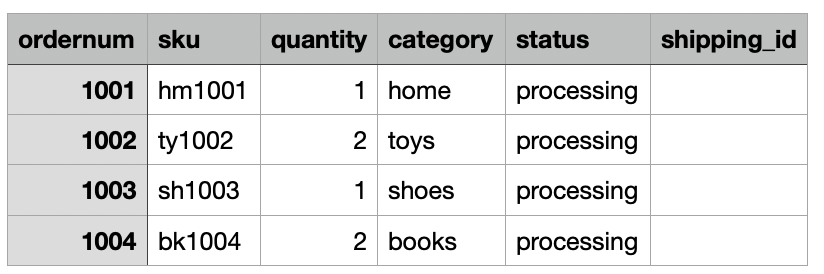


El trabajo ETL de AWS Glue icebergdemo1-GlueETL1-merge se ejecutará diariamente para fusionar los datos en la tabla Iceberg. Tiene la siguiente lógica para agregar o actualizar los datos en Iceberg:
- Cree un Spark DataFrame a partir de datos de entrada:
- Para un nuevo pedido, agréguelo a la tabla.
- Si la tabla tiene un orden coincidente, actualice el estado y
shipping_id:
Complete los siguientes pasos para ejecutar el trabajo de combinación de AWS Glue:
- En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación.
- Seleccione el trabajo ETL
icebergdemo1-GlueETL1-merge. - En Acciones menú desplegable, elija Ejecutar con parámetros.
- En Ejecutar parámetros página, vaya a Parámetros de trabajo.
- Para el
--dropzone_pathparámetro, proporcione la ubicación S3 de los datos de entrada (icebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge1). - Ejecute el trabajo para agregar todos los pedidos: 1001, 1002, 1003 y 1004.
- Para el
--dropzone_path parameter, cambie la ubicación de S3 aicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge2. - Ejecute el trabajo nuevamente para agregar los pedidos 2001 y 2002 y actualizar los pedidos 1001, 1002 y 1003.
- Para el
--dropzone_pathparámetro, cambie la ubicación de S3 aicebergdemo1-s3bucketdropzone-kunftrcblhsk/data/merge3. - Ejecute el trabajo nuevamente para agregar el pedido 3001 y actualizar los pedidos 1001, 1003, 2001 y 2002.
Vaya a la carpeta de datos de la tabla para ver los archivos de datos escritos por Iceberg cuando fusionó los datos en la tabla usando el trabajo Glue ETL. icebergdemo1-GlueETL1-merge.

Consultar Iceberg usando Athena
La pila de CloudFormation creó el usuario de IAM iceberguser1, que tiene acceso de lectura en la tabla Iceberg mediante etiquetas LF. Para consultar Iceberg usando Athena a través de este usuario, complete los siguientes pasos:
- Iniciar sesión como
iceberguser1En el correo electrónico “Su Cuenta de Usuario en su Nuevo Sistema XNUMXCX”. Consola de administración de AWS. - En la consola de Athena, elija Grupos de trabajo en el panel de navegación.
- Ubique el grupo de trabajo que CloudFormation aprovisionó (
icebergdemo1-workgroup) - Verifique la versión 3 del motor Athena.
La versión 3 del motor Athena admite Formatos de archivos iceberg, incluidos Parquet, ORC y Avro.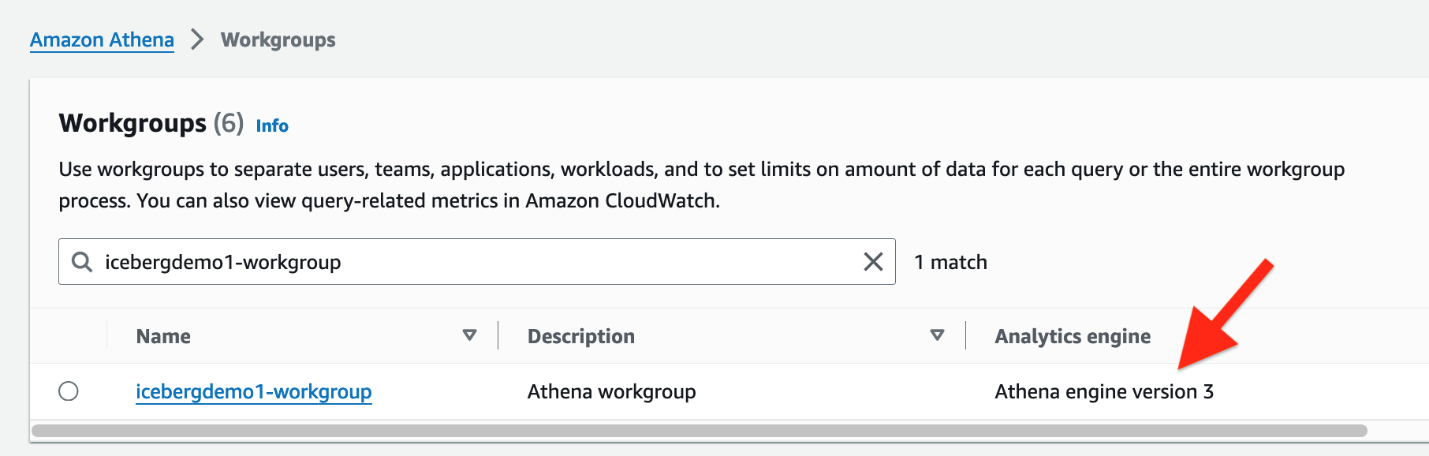
- Vaya al editor de consultas de Athena.
- Elija el grupo de trabajo icebergdemo1-workgroup en el menú desplegable.
- Base de datos, escoger
icebergdb1. Verás la mesaecomorders. - Ejecute la siguiente consulta para ver los datos en la tabla Iceberg:
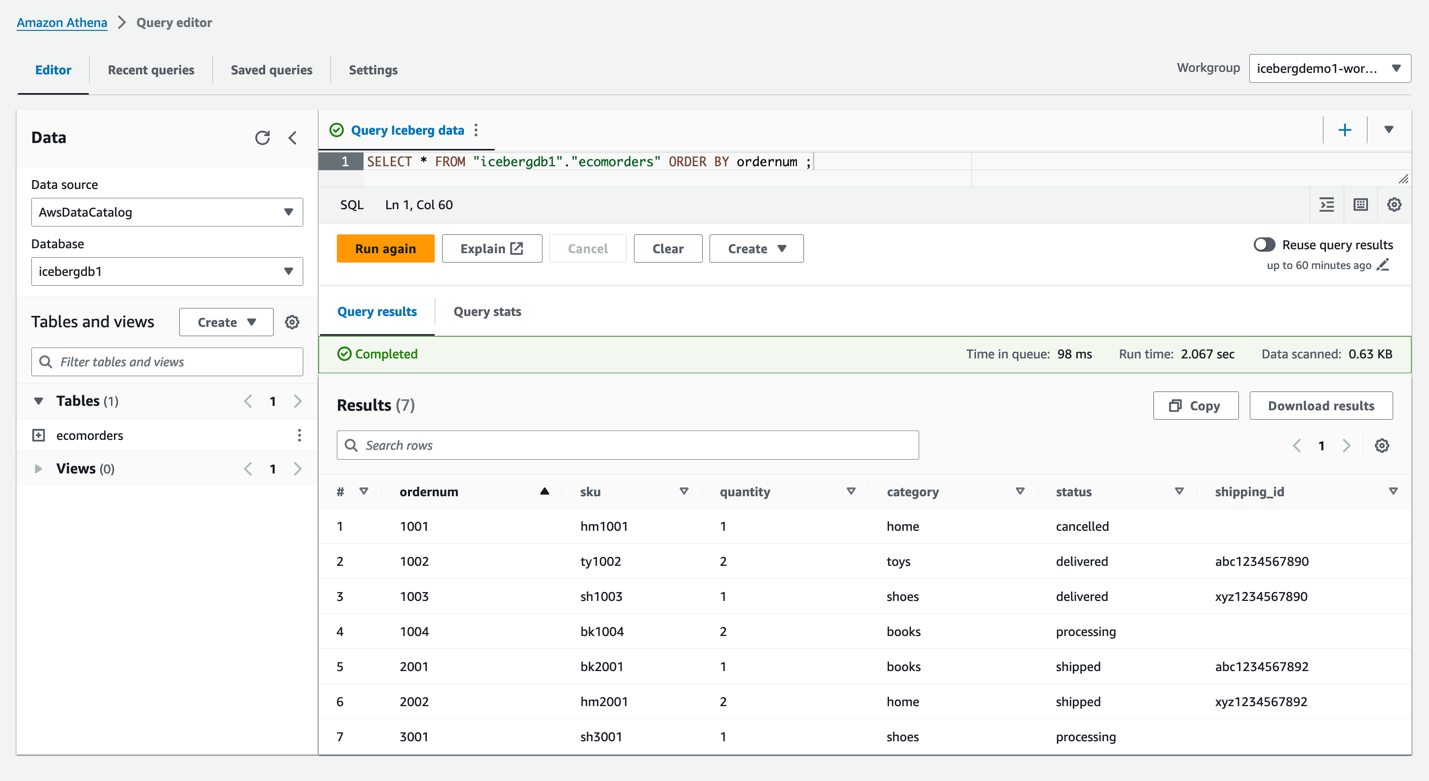
- Ejecute la siguiente consulta para ver las particiones actuales de la tabla:
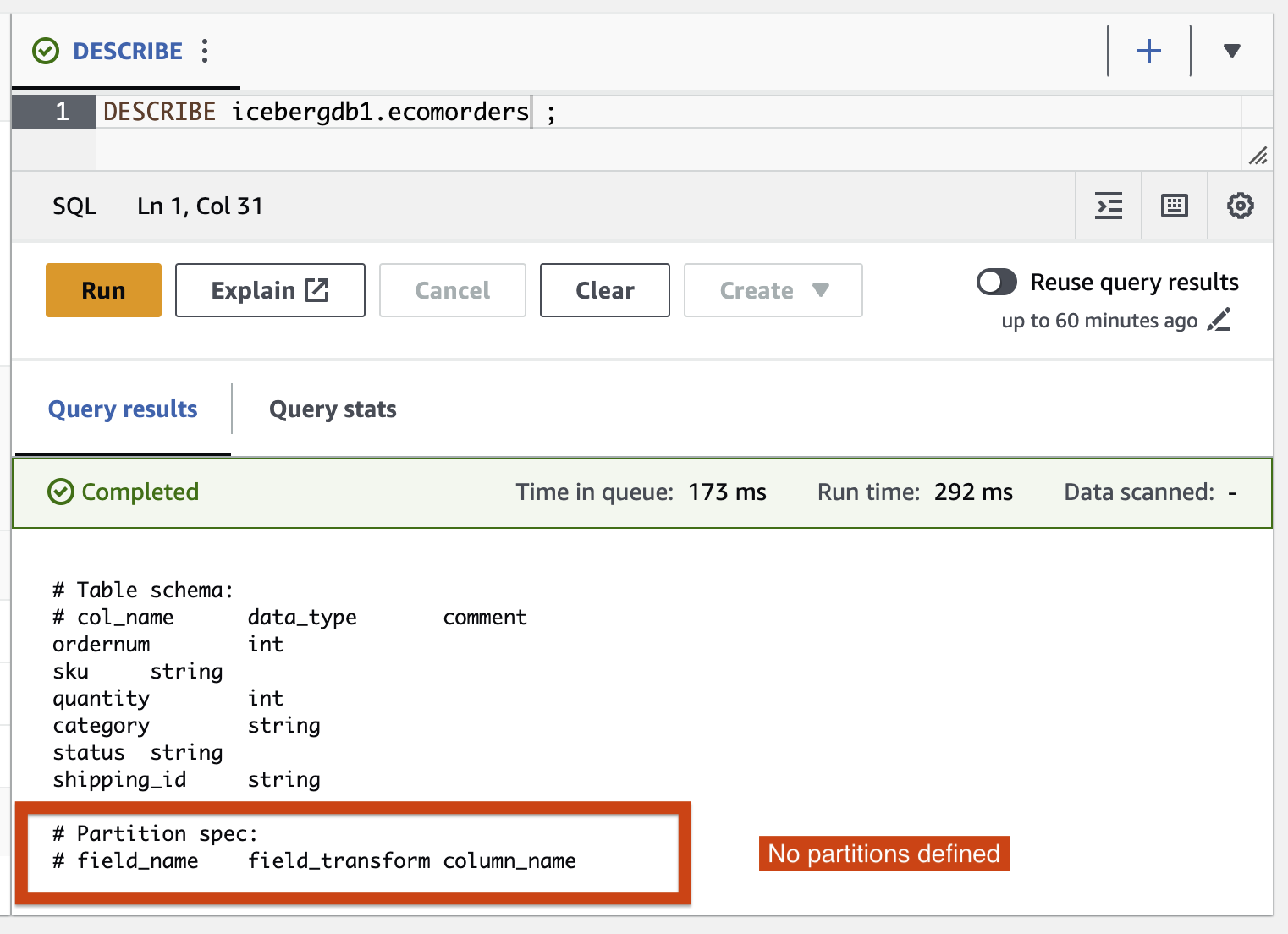
Partition-spec describe cómo se particiona la tabla. En este ejemplo, no hay campos particionados porque no definiste ninguna partición en la tabla.
Evolución de la partición Iceberg
Es posible que necesites cambiar la estructura de tu partición; por ejemplo, debido a cambios de tendencia en patrones de consulta comunes en análisis posteriores. Un cambio de estructura de partición para tablas tradicionales es una operación importante que requiere una copia completa de los datos.
Iceberg hace que esto sea sencillo. Cuando cambia la estructura de la partición en Iceberg, no es necesario reescribir los archivos de datos. Los datos antiguos escritos con particiones anteriores permanecen sin cambios. Los datos nuevos se escriben utilizando las nuevas especificaciones en un nuevo diseño. Los metadatos de cada una de las versiones de partición se mantienen por separado.
Agreguemos la categoría del campo de partición a la tabla Iceberg usando el trabajo ETL de AWS Glue icebergdemo1-GlueETL2-partition-evolution:
En la consola de AWS Glue, ejecute el trabajo ETL icebergdemo1-GlueETL2-partition-evolution. Cuando se complete el trabajo, podrá consultar particiones usando Athena.
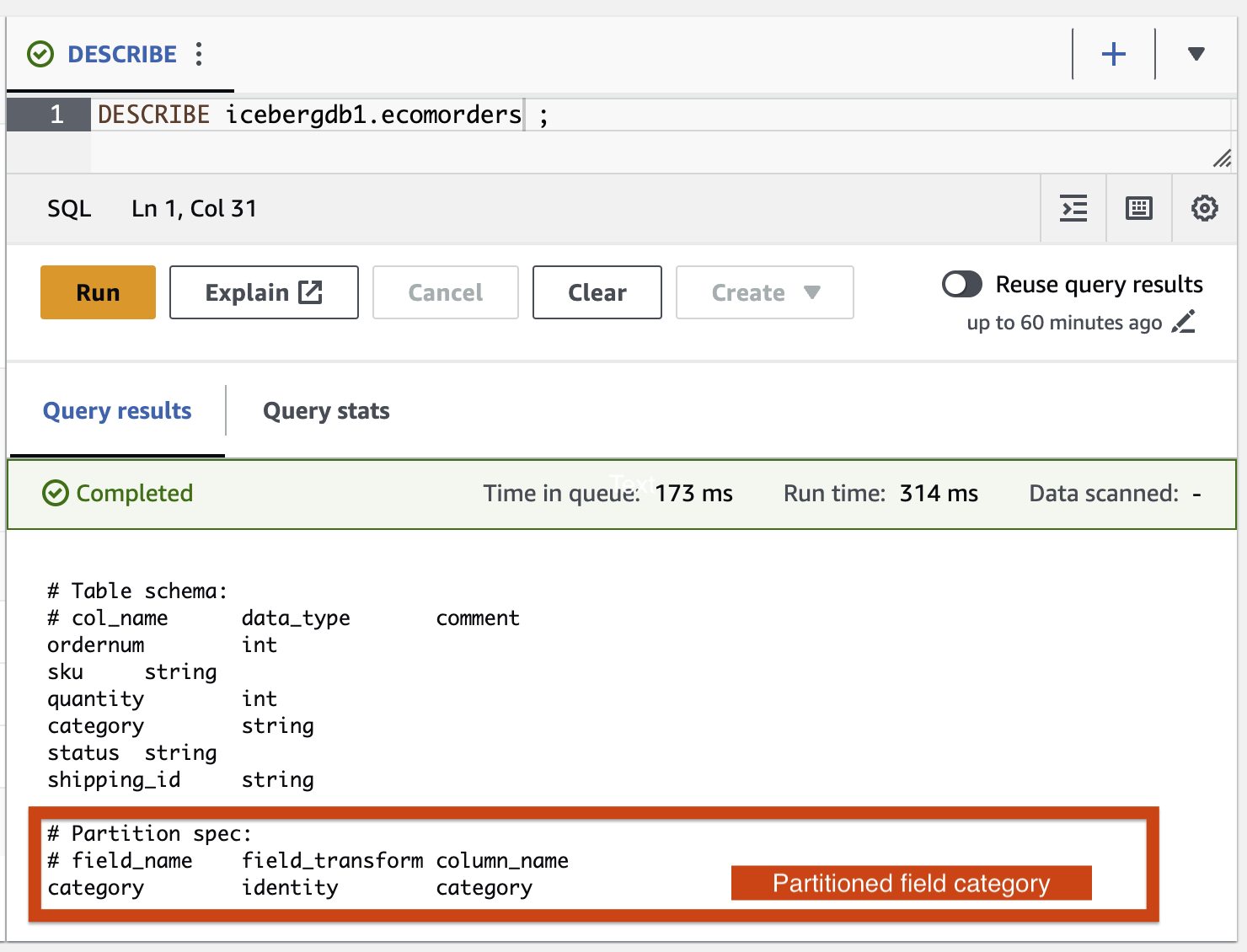
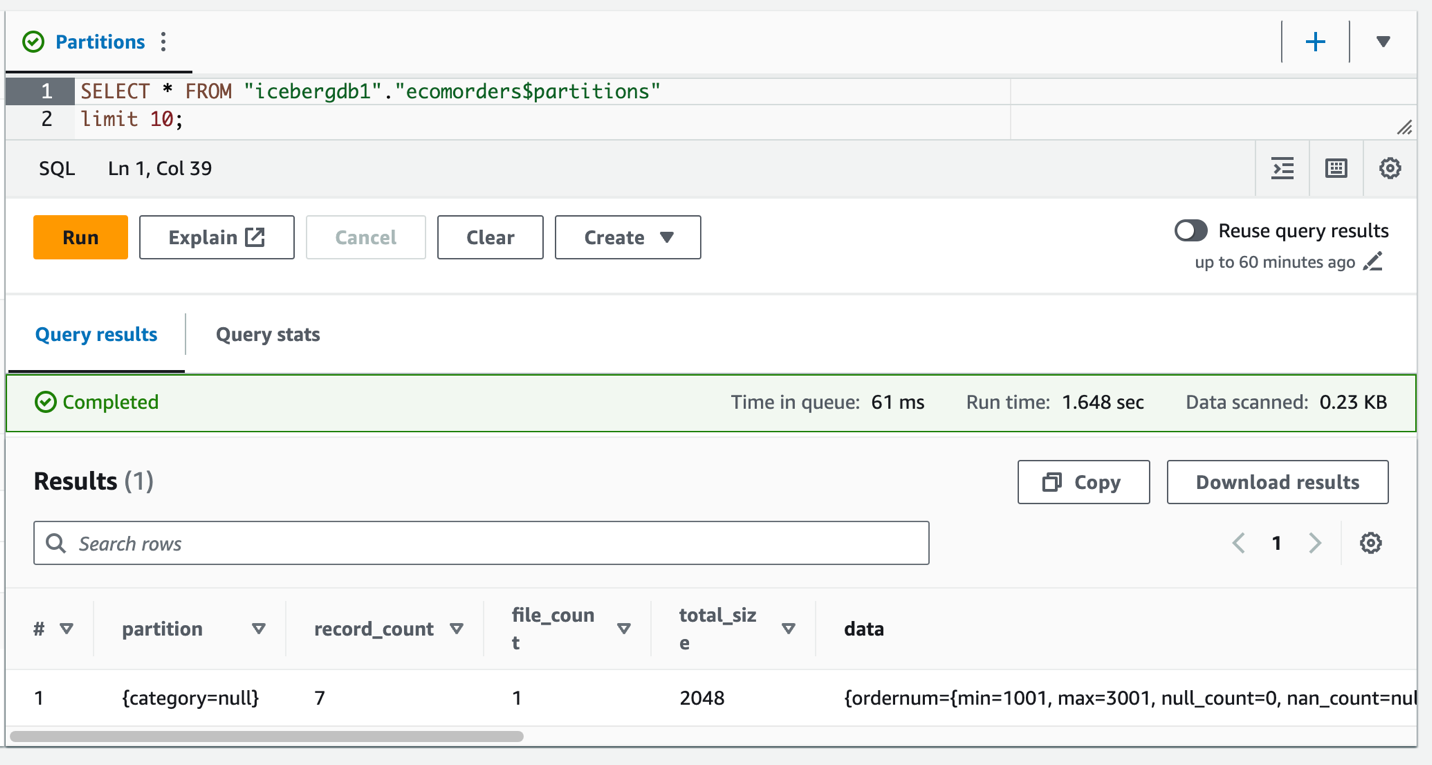
Puede ver la categoría del campo de partición, pero los valores de la partición son nulos. No hay archivos de datos nuevos en la carpeta de datos, porque la evolución de la partición es una operación de metadatos y no reescribe archivos de datos. Cuando agregue o actualice datos, verá los valores de partición correspondientes completos.
Evolución del esquema del iceberg
Iceberg admite la evolución de las tablas in situ. Puede evolucionar un esquema de tabla al igual que SQL. Las actualizaciones del esquema Iceberg son cambios de metadatos, por lo que no es necesario reescribir archivos de datos para realizar la evolución del esquema.
Para explorar la evolución del esquema Iceberg, ejecute el trabajo ETL icebergdemo1-GlueETL3-schema-evolution a través de la consola de AWS Glue. El trabajo ejecuta las siguientes declaraciones SparkSQL:
En el editor de consultas de Athena, ejecute la siguiente consulta:

Puede verificar los cambios de esquema en la tabla Iceberg:
- Se ha agregado una nueva columna llamada
shipping_carrier - La columna
shipping_idha sido renombrado atracking_number - El tipo de datos de la columna.
ordernumha cambiado de int a bigint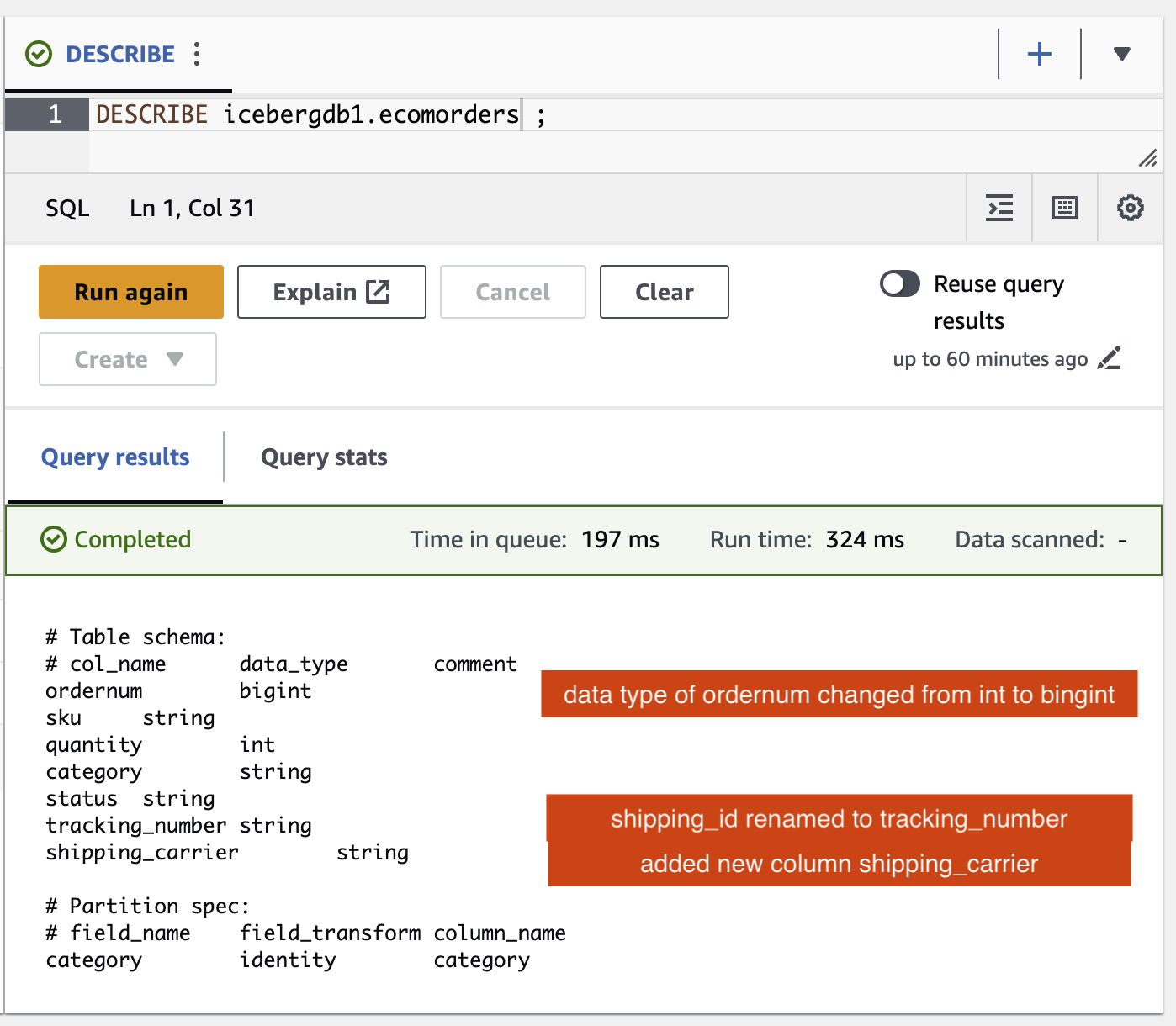
Actualización posicional
Los datos en tracking_number contiene el transportista de envío concatenado con el número de seguimiento. Supongamos que queremos dividir estos datos para mantener al transportista en el shipping_carrier campo y el número de seguimiento en el tracking_number campo.
En la consola de AWS Glue, ejecute el trabajo ETL icebergdemo1-GlueETL4-update-table. El trabajo ejecuta la siguiente declaración SparkSQL para actualizar la tabla:
Consulta la tabla Iceberg para verificar los datos actualizados sobre tracking_number y shipping_carrier.
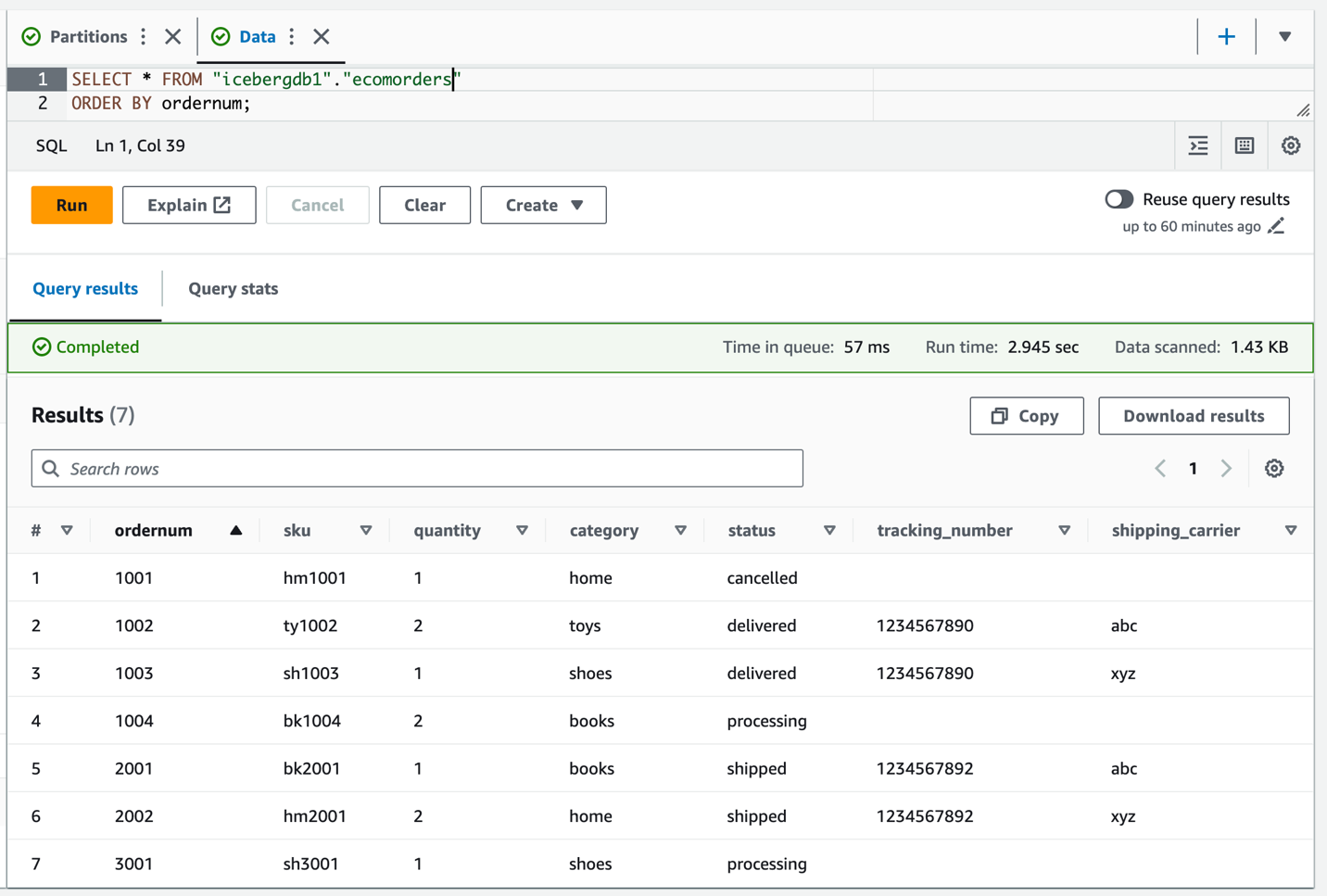
Ahora que los datos se han actualizado en la tabla, debería ver los valores de partición completados para la categoría:

Limpiar
Para evitar incurrir en cargos futuros, limpie los recursos que creó:
- En la consola Lambda, abra la página de detalles de la función
icebergdemo1-Lambda-Create-Iceberg-and-Grant-access. - En Variables de entorno sección, elija la clave
Task_To_Performy actualizar el valor aCLEANUP. - Ejecute la función, que elimina la base de datos, la tabla y sus etiquetas LF asociadas.
- En la consola de AWS CloudFormation, elimine la pila icebergdemo1.
Conclusión
En esta publicación, creó una tabla Iceberg utilizando la API de AWS Glue y utilizó Lake Formation para controlar el acceso a la tabla Iceberg en un lago de datos transaccionales. Con los trabajos ETL de AWS Glue, fusionó datos en la tabla Iceberg y realizó la evolución del esquema y de la partición sin reescribir ni recrear la tabla Iceberg. Con Athena, consultaste los datos y metadatos de Iceberg.
Según los conceptos y las demostraciones de esta publicación, ahora puede crear un lago de datos transaccionales en una empresa utilizando Iceberg, AWS Glue, Lake Formation y Amazon S3.
Sobre la autora
 Satya Adimula es arquitecto de datos senior en AWS con sede en Boston. Con más de dos décadas de experiencia en datos y análisis, Satya ayuda a las organizaciones a obtener conocimientos empresariales a partir de sus datos a escala.
Satya Adimula es arquitecto de datos senior en AWS con sede en Boston. Con más de dos décadas de experiencia en datos y análisis, Satya ayuda a las organizaciones a obtener conocimientos empresariales a partir de sus datos a escala.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/use-aws-glue-etl-to-perform-merge-partition-evolution-and-schema-evolution-on-apache-iceberg/

