Introducción
Computer Vision es una rama de la IA que proporciona a una máquina una comprensión de alto nivel de una imagen y el poder de realizar tareas en imágenes que incluso los humanos no pueden realizar. 2022 ha sido el año del auge de la Visión por Computador. Ha sido el año más productivo para Computer Vision hasta ahora. Se han desarrollado muchas tecnologías nuevas, se han lanzado productos, se han formado nuevos modelos y se han llevado a cabo muchas actualizaciones. De todas las innovaciones de este año, he preseleccionado la lista de éxitos de los 10 temas más útiles, poderosos y de tendencia en visión artificial en 2022.
Detección y seguimiento de objetos
La detección y el seguimiento de objetos es un área de investigación principal en visión por computadora y estuvo entre los mejores en visión por computadora en 2022. El primer trabajo en detección de objetos se remonta a 2000. Durante los próximos 20 años, este campo ha mejorado mucho y ha tenido éxito. Los investigadores siguen esforzándose por construir mejores algoritmos de detección de objetos. Tiene una amplia gama de aplicaciones en visión por computadora, como automóviles autónomos, seguridad y vigilancia, etc. Ahora, intentaremos comprender la detección y el seguimiento de objetos.
Como sugiere el nombre, la detección de objetos identifica el objeto y su ubicación en la imagen. Al mismo tiempo, el seguimiento de objetos se refiere a la capacidad de identificar un objeto en particular y su ubicación en el video. El estado del arte (SO ) en detección de objetos hasta 2021 fue YOLOv5. Cuando se trata de seguimiento de objetos, MOT y Deepsort han sido algoritmos de seguimiento ampliamente utilizados. En lo que respecta a la visión por computadora en 2022, explotaron dos tecnologías relacionadas con la detección y el seguimiento de objetos.
YOLOv7
yolov7 es una versión reciente de la familia YOLO. Es lo último en detección de objetos a partir de hoy. Superó a todos los demás algoritmos de detección de objetos en velocidad y precisión.
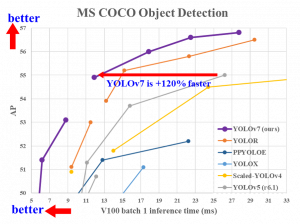
Fuente – github
Se puede inferir de la imagen que se muestra arriba que YOLOv7 funciona un 120 % más rápido que todas las demás versiones anteriores de YOLO.
Pista de bytes
ByteTrack es un sistema de seguimiento multiobjeto. El seguimiento de múltiples objetos (MOT) es un proceso de seguimiento de la ruta de múltiples objetos presentes en un solo cuadro de un video. La mayoría de los algoritmos MOT funcionan con puntajes de confianza y umbrales y descartes.Objetos que tienen puntajes bajos. El algoritmo ByteTrack no se basa en los valores de confianza del objeto detectado. En su lugar, rastrea la ruta de los objetos con puntaje bajo y encuentra similitudes con los otros marcos para detectar el objeto real y seguir el camino en consecuencia en lugar de descartar los objetos con puntaje bajo. Los objetos de puntuación baja se comparan con los tracklets y el objeto se detecta si realmente existe. El modelo ByteTrack funciona bien incluso para objetos que están ocluidos (cuando el objeto está oculto detrás de otro objeto).
Consigue un total de 80.3 MOTA

Fuente – github
Puede leer más sobre ByteTrack aquí: https://arxiv.org/abs/2110.06864
Generación de Imagen y Video
La tecnología ha hecho posible generar imágenes y videos a partir de una descripción textual básica de una situación o imagen. Esta es una emocionante tecnología de visión por computadora en 2022, ya que puede ayudarlo a visualizar lo que imagina y mostrárselo a los demás. El truncamiento suave, una técnica de entrenamiento universal de modelos de difusión basados en puntajes, logró resultados de vanguardia en la generación de imágenes hasta 2021 en conjuntos de datos CIFAR-10, CelebA, CelebA-HQ 256 × 256 y STL-10. Ha habido avances en el campo y muchas grandes empresas como meta, google, OpenAI, etc., propusieron diferentes tecnologías y enfoques. Algunas de las herramientas y tecnologías lanzadas en 2022 se describen a continuación:
Imagen
Imagen, desarrollado por Google y lanzado en 2022, es un modelo de difusión de texto a imagen. Toma en una descripción de una imagen y produce imágenes realistas. Los modelos de difusión son modelos generativos que producen imágenes de alta resolución. Estos modelos funcionan en dos pasos. En el primer paso, se agregan algunos ruidos gaussianos aleatorios a la imagen y luego, en el segundo paso, el modelo aprende a invertir el proceso eliminando el ruido, generando así nuevos datos.
Imagen codifica el texto en codificaciones y luego usa el modelo de difusión para generar una imagen. Se utilizan una serie de modelos de difusión para producir imágenes de alta resolución. Es una tecnología realmente interesante ya que puedes visualizar tu pensamiento creativo con solo describir una imagen y generar lo que quieras en momentos.
Descripción de Img: una foto de un perro Corgi montando en bicicleta en Times Square. Lleva gafas de sol y un sombrero de playa.
Salida:

Fuente – Google
El codificador de texto codifica la descripción de lo dado y produce codificaciones sobre la base de las cuales el modelo de difusión produce imágenes de alta resolución. Aquí está el trabajo de investigación para su referencia. https://imagen.research.google/paper.pdf
Hacer un vídeo
¿Qué puede ser más interesante que generar una imagen a partir de la descripción? ¡Sí! ¡Adivinaste bien! Make-A-Video, lanzado por Meta en 2022, le permite generar un video basado en la descripción de la imagen. La modelo usa imágenes con alguna descripción para hacer un video dada la descripción. También utiliza videos sin etiquetar para aprender y mejorar el video generado.
El concepto del modelo se puede explicar en 3 sencillos pasos. La generación de texto a imagen, tomando instancias de un conjunto de secuencias de video no supervisadas, y luego la red de interpolación para completar los cuadros y formar un video. Se utiliza un montón de modelos y su combinación para generar videos de alta resolución. El enlace al trabajo de investigación se proporciona a continuación si desea leer más sobre la tecnología.

Fuente: makeavideo.studio
Puede explorar este asombroso invento y hacer muchas cosas, como agregar movimiento a un marco estático y llevar su imaginación a la pantalla. Esta tecnología es emocionante y vale la pena explorarla. Puede leer el trabajo de investigación aquí: https://arxiv.org/abs/2209.14792
DALL-E2
DALL-E2 es un sistema de IA desarrollado por OpenAI y lanzado en 2022 que puede crear imágenes y arte realistas basados en descripciones textuales. Ya hemos visto las mismas tecnologías, pero este sistema también vale la pena explorarlo y dedicarle algo de tiempo. Encontré DALL-E2 como uno de los mejores modelos presentes, que funciona en la generación de imágenes.

Utiliza una versión de GPT-3 modificada para generar imágenes y se entrena con millones de imágenes de todo Internet. DALL-E utiliza una combinación de técnicas de PNL para comprender el significado del texto de entrada y técnicas de visión artificial para generar la imagen. Está entrenado en un gran conjunto de datos de imágenes y sus descripciones textuales asociadas, lo que le permite aprender las relaciones entre las palabras y las características visuales. DALL-E puede generar imágenes coherentes con el texto de entrada aprendiendo estas relaciones.
Aquí está el enlace al trabajo de investigación si está interesado en leer en detalle: https://arxiv.org/abs/2102.12092
PELÍCULA: interpolación de cuadros para movimiento grande
FILM es otro modelo de generación de video desarrollado por Google que convierte fotos que son casi similares y están separadas por unos pocos cuadros en un video en cámara lenta. El modelo hace que parezca que el video es capturado por una cámara en cámara lenta al interpolar los cuadros entre los dos cuadros. La distancia entre el marco resulta ser un problema, pero el extractor de características se ocupa de eso. Se utilizan más conceptos que, quizás, se puedan despegar en otro blog. Pero solo una descripción general por ahora.
Los códigos y el modelo preentrenado están presentes en Google-research GitHub para mayor referencia. Este modelo puede producir la toma como una foto en vivo en un iPhone en cámara lenta. Puede ser muy interesante y útil ya que a veces podemos perder una toma perfecta pero ¡oye! Hay CINE para encargarse de eso….
Fuente: film-net.github.io
Aquí está el enlace al trabajo de investigación para su referencia: https://arxiv.org/pdf/2202.04901.pdf
Infinite Nature Zero: generación de recorridos aéreos en 3D a partir de fotografías fijas
Estoy seguro de que has visto esas locas tomas en las películas y específicamente en los documentales de vida silvestre donde la cámara vuela sobre el paisaje produciendo una toma enfermiza de la naturaleza o un lapso de tiempo de la nube, que parece ser muy hermoso. El equipo de investigación de Google lanzó el modelo Infinite Nature Zero en 2022 que puede generar esos asombrosos disparos a partir de imágenes fijas. ¡Sí! Lo escuchaste bien, de imágenes fijas. Tiene cero en su nombre ya que requiere 0 videos para entrenar para producir videos.
El modelo utiliza GAN (Redes antagónicas generativas) para generar las imágenes. El modelo utiliza un patrón de entrenamiento de generación de vistas autosupervisado mediante el muestreo de vistas similares con ángulos de cámara y trayectorias similares. El modelo puede generar tomas fascinantes sin recibir ningún video.
Fuente: naturaleza infinita-cero.github.io
Puede mirar el trabajo de investigación para su referencia. https://arxiv.org/abs/2207.11148
Aplicación de transformadores a problemas de imagen
Los transformadores son redes neuronales de autoatención que funcionan en el mecanismo de paralelización. Aprende la lógica y la semántica de las oraciones y puede usarse para el procesamiento del lenguaje natural. Se diferencia de otras técnicas de PNL en que otras técnicas pueden procesar todo el texto a la vez o en 'paralelo'. Por el contrario, el transformador puede resultar eficiente ya que las palabras distantes entre sí también pueden compararse y analizarse contextualmente, lo que da como resultado mejores predicciones y contexto del texto.

Fuente - wikipedia
El transformador de visión similar a un transformador supera a la CNN sota actual, que se usa ampliamente en tareas de visión por computadora, pero ha habido un aumento en el uso de un transformador en este campo, ya que supera a la CNN en términos de precisión y velocidad.
Algunas tecnologías que explotaron en visión artificial en 2022:
Transformadores de visión escalable
Vision Transformer (ViT) ha logrado resultados de vanguardia en muchos puntos de referencia de visión por computadora. Logra una precisión total del 90.45 % en el conjunto de datos de ImageNet, que es sota hasta la fecha. El concepto de escalado es el concepto principal que ayuda al modelo a lograr el máximo de precisión. Se han realizado y analizado algunos experimentos con los datos y el escalado del modelo, y se ha logrado la arquitectura refinada final. Aquí está el enlace al trabajo de investigación si desea leer más sobre la tecnología: https://arxiv.org/abs/2106.04560
Pix2Seq: una nueva interfaz de lenguaje para la detección de objetos
Pix2Seq es un marco de algoritmo de detección de objetos lanzado por Google en 2022. El marco asume que la tarea de detección de objetos predice la siguiente palabra en NLP. Los cuadros delimitadores se toman como tokens ya que la máquina está entrenada para comprender la imagen y generar cuadros delimitadores similares. El modelo logra una precisión notable en el conjunto de datos COCO sin utilizar enfoques como el aumento de datos y otras técnicas utilizadas por los otros algoritmos.
Aprendizaje auto-supervisado
El aprendizaje autosupervisado ha sido uno de los temas más candentes en 2022. El algoritmo de aprendizaje autosupervisado no requiere etiquetas explícitas como entrada. Más bien, aprende de una parte de los propios datos. El algoritmo de aprendizaje autosupervisado resuelve el problema de nuestra dependencia excesiva de los datos etiquetados. La autogeneración de las etiquetas hace que el problema pase de ser un problema de aprendizaje no supervisado a uno supervisado. Aquí hay algunas técnicas lanzadas en visión artificial en 2022 para el aprendizaje autosupervisado.
datos2vec
Data2Vec se lanzó a principios de este año en enero de 2022. Data2vec se usa en patrones de aprendizaje en los datos y usa el mismo método de aprendizaje para el habla, la PNL o la visión por computadora. La intuición detrás de Data2Vec es que el modelo recibe una vista rota/enmascarada de la entrada, como la imagen que se muestra a continuación. Por lo tanto, el modelo recibe solo un 20% de datos sin procesar y se le pide que prediga la salida analizando los patrones y aprendiendo la representación abstracta en los datos sin recibir miles de imágenes de un gato como los algoritmos tradicionales.

El modelo puede reconstruir la imagen como se muestra a continuación.

El modelo muestra un rendimiento de última generación en comparación con los métodos existentes anteriormente. Puede consultar el trabajo de investigación a través de este enlace: Trabajo de investigación
Mejorar el aprendizaje de transferencia
El uso del aprendizaje por transferencia ha facilitado la vida de los entusiastas de la ciencia de datos. Transferir aprendizaje es cuando usamos un modelo previamente entrenado como VGG-16 para realizar una tarea similar en un conjunto de datos personalizado. Los pesos aprendidos por el modelo se reutilizan y se vuelven a entrenar en los datos que queremos para realizar la tarea similar para la que se entrenó el modelo. Esto ahorra mucho tiempo y esfuerzo ya que no tenemos que entrenar el modelo en millones de imágenes y preocuparnos por la precisión del modelo y otros aspectos.
Aunque el aprendizaje de transferencia fue rápido, ha habido algunas mejoras más en 2022, lo que es mejor para nosotros. Aquí hay algunas tecnologías que explotaron en 2022.
Ajuste fino robusto de modelos Zero-Shot
Los modelos de tiro cero, como sugiere el nombre, son modelos que no están ajustados en un conjunto de datos específico. Esta tecnología demostró ser precisa en una distribución particular, pero reduce la robustez en los cambios de distribución. El sólido ajuste fino de los modelos de disparo cero ha mejorado la precisión de estos modelos en los turnos de distribución. El concepto utilizado es el uso armonioso de los pesos del modelo zero-shot y fine-tuned model (WiSE-FT).
Esto mejora la precisión en los cambios de distribución al 4-6 % y 1.6 puntos porcentuales en el conjunto de datos de ImageNet. Lea más sobre el ajuste fino robusto para modelos de disparo cero aquí: https://arxiv.org/abs/2109.01903
Detección de objetos de pocos disparos con transformador cruzado completo
La detección de objetos con pocos disparos se refiere a la tarea en la que el modelo detecta las clases invisibles con muy pocos ejemplos de entrenamiento. Este método resuelve el problema de nuestra dependencia excesiva de miles de imágenes anotadas. El sota anterior usaba una red siamesa basada en dos ramificaciones para la detección de objetos de pocos disparos. Hubo algunos problemas en la red utilizada que se resuelven con el modelo totalmente basado en transformadores cruzados.
El concepto detrás de este enfoque es que codifica un conjunto de pocas imágenes que se dan como ejemplos de entrenamiento. Incluye transformadores cruzados tanto en la columna vertebral como en el cabezal de detección y utiliza un SGD para optimizar el entrenamiento para reducir errores bentre clases reales y erróneamente predichas. Lea más sobre Detección de objetos de pocos disparos con transformador cruzado completo aquí:
https://arxiv.org/abs/2203.15021
Conclusión
Este artículo da una visión general de las últimas tecnologías lanzadas y en auge en visión artificial en 2022; todavía hay mucho por venir. Captamos brevemente algunos conceptos que se utilizan en estas tecnologías. La visión por computadora es un campo vasto que todavía se está abriendo camino. Hay mucho por descubrir y explorar y muchas oportunidades en el futuro cercano. Los animo a investigar los temas que discutimos y profundizar en la gloria de Computer Vision. Espero que les haya gustado el artículo y estén ansiosos por explorarlo.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2022/12/computer-vision-in-2022-a-quick-recap/

