Esta publicación está coescrita con Chaoyang He, Al Nevarez y Salman Avestimehr de FedML.
Muchas organizaciones están implementando el aprendizaje automático (ML) para mejorar la toma de decisiones comerciales mediante la automatización y el uso de grandes conjuntos de datos distribuidos. Con un mayor acceso a los datos, el aprendizaje automático tiene el potencial de proporcionar conocimientos y oportunidades comerciales incomparables. Sin embargo, compartir información confidencial sin procesar y no desinfectada entre diferentes ubicaciones plantea importantes riesgos de seguridad y privacidad, especialmente en industrias reguladas como la atención médica.
Para abordar este problema, el aprendizaje federado (FL) es una técnica de capacitación de ML colaborativa y descentralizada que ofrece privacidad de datos manteniendo la precisión y la fidelidad. A diferencia de la capacitación tradicional de ML, la capacitación de FL se realiza dentro de una ubicación aislada del cliente mediante una sesión segura e independiente. El cliente solo comparte los parámetros de su modelo de salida con un servidor centralizado, conocido como coordinador de entrenamiento o servidor de agregación, y no los datos reales utilizados para entrenar el modelo. Este enfoque alivia muchas preocupaciones sobre la privacidad de los datos y al mismo tiempo permite una colaboración efectiva en la capacitación de modelos.
Aunque FL es un paso hacia una mayor privacidad y seguridad de los datos, no es una solución garantizada. Las redes inseguras que carecen de control de acceso y cifrado aún pueden exponer información confidencial a los atacantes. Además, la información entrenada localmente puede exponer datos privados si se reconstruye mediante un ataque de inferencia. Para mitigar estos riesgos, el modelo FL utiliza algoritmos de capacitación personalizados y enmascaramiento y parametrización efectivos antes de compartir información con el coordinador de capacitación. Los fuertes controles de red en ubicaciones locales y centralizadas pueden reducir aún más los riesgos de inferencia y exfiltración.
En esta publicación, compartimos un enfoque FL utilizando FedML, Servicio Amazon Elastic Kubernetes (Amazon EKS), y Amazon SageMaker para mejorar los resultados de los pacientes y al mismo tiempo abordar las preocupaciones de seguridad y privacidad de los datos.
La necesidad de un aprendizaje federado en el ámbito sanitario
La atención médica depende en gran medida de fuentes de datos distribuidas para realizar predicciones y evaluaciones precisas sobre la atención al paciente. Limitar las fuentes de datos disponibles para proteger la privacidad afecta negativamente la precisión de los resultados y, en última instancia, la calidad de la atención al paciente. Por lo tanto, el aprendizaje automático crea desafíos para los clientes de AWS que necesitan garantizar la privacidad y la seguridad en entidades distribuidas sin comprometer los resultados de los pacientes.
Las organizaciones de atención médica deben navegar por estrictas regulaciones de cumplimiento, como la Ley de Responsabilidad y Portabilidad de Seguros Médicos (HIPAA) en los Estados Unidos, mientras implementan soluciones FL. Garantizar la privacidad, la seguridad y el cumplimiento de los datos se vuelve aún más crítico en el sector de la salud, ya que requiere un cifrado sólido, controles de acceso, mecanismos de auditoría y protocolos de comunicación seguros. Además, los conjuntos de datos de atención médica a menudo contienen tipos de datos complejos y heterogéneos, lo que hace que la estandarización y la interoperabilidad de los datos sean un desafío en entornos de FL.
Resumen del caso de uso
El caso de uso descrito en esta publicación es el de datos de enfermedades cardíacas en diferentes organizaciones, en los que un modelo de aprendizaje automático ejecutará algoritmos de clasificación para predecir enfermedades cardíacas en el paciente. Debido a que estos datos pertenecen a todas las organizaciones, utilizamos el aprendizaje federado para recopilar los hallazgos.
El Conjunto de datos sobre enfermedades cardíacas del Repositorio de Aprendizaje Automático de la Universidad de California en Irvine es un conjunto de datos ampliamente utilizado para la investigación cardiovascular y el modelado predictivo. Consta de 303 muestras, cada una de las cuales representa a un paciente, y contiene una combinación de atributos clínicos y demográficos, así como la presencia o ausencia de enfermedades cardíacas.
Este conjunto de datos multivariado tiene 76 atributos en la información del paciente, de los cuales 14 atributos se utilizan con mayor frecuencia para desarrollar y evaluar algoritmos de aprendizaje automático para predecir la presencia de enfermedades cardíacas en función de los atributos dados.
Marco FedML
Existe una amplia selección de marcos FL, pero decidimos utilizar el Marco FedML para este caso de uso porque es de código abierto y admite varios paradigmas de FL. FedML proporciona una popular biblioteca de código abierto, una plataforma MLOps y un ecosistema de aplicaciones para FL. Estos facilitan el desarrollo y la implementación de soluciones FL. Proporciona un conjunto completo de herramientas, bibliotecas y algoritmos que permiten a investigadores y profesionales implementar y experimentar con algoritmos FL en un entorno distribuido. FedML aborda los desafíos de la privacidad de datos, la comunicación y la agregación de modelos en FL, ofreciendo una interfaz fácil de usar y componentes personalizables. Con su enfoque en la colaboración y el intercambio de conocimientos, FedML tiene como objetivo acelerar la adopción de FL e impulsar la innovación en este campo emergente. El marco FedML es independiente del modelo e incluye soporte agregado recientemente para modelos de lenguajes grandes (LLM). Para obtener más información, consulte Lanzamiento de FedLLM: cree sus propios modelos de lenguaje grandes a partir de datos propietarios utilizando la plataforma FedML.
Pulpo FedML
La jerarquía y heterogeneidad del sistema es un desafío clave en los casos de uso de FL en la vida real, donde diferentes silos de datos pueden tener diferentes infraestructuras con CPU y GPU. En tales escenarios, puede utilizar Pulpo FedML.
FedML Octopus es la plataforma de nivel industrial de FL entre silos para capacitación entre organizaciones y cuentas. Junto con FedML MLOps, permite a los desarrolladores u organizaciones llevar a cabo una colaboración abierta desde cualquier lugar y a cualquier escala de forma segura. FedML Octopus ejecuta un paradigma de capacitación distribuida dentro de cada silo de datos y utiliza capacitaciones sincrónicas o asincrónicas.
Operaciones MLO de FedML
FedML MLOps permite el desarrollo local de código que luego se puede implementar en cualquier lugar utilizando los marcos de FedML. Antes de iniciar la capacitación, debe crear una cuenta FedML, así como crear y cargar los paquetes del servidor y del cliente en FedML Octopus. Para obtener más detalles, consulte pasos y Presentamos FedML Octopus: escalar el aprendizaje federado a producción con MLOps simplificados.
Resumen de la solución
Implementamos FedML en múltiples clústeres de EKS integrados con SageMaker para el seguimiento de experimentos. Usamos Proyectos de Amazon EKS para Terraform para implementar la infraestructura requerida. EKS Blueprints ayuda a componer clústeres EKS completos que están completamente equipados con el software operativo necesario para implementar y operar cargas de trabajo. Con EKS Blueprints, la configuración para el estado deseado del entorno EKS, como el plano de control, los nodos trabajadores y los complementos de Kubernetes, se describe como un plano de infraestructura como código (IaC). Una vez configurado un blueprint, se puede utilizar para crear entornos coherentes en varias cuentas y regiones de AWS mediante la automatización de la implementación continua.
El contenido compartido en esta publicación refleja situaciones y experiencias de la vida real, pero es importante tener en cuenta que el despliegue de estas situaciones en diferentes ubicaciones puede variar. Aunque utilizamos una única cuenta de AWS con VPC independientes, es fundamental comprender que las circunstancias y configuraciones individuales pueden diferir. Por lo tanto, la información proporcionada debe utilizarse como guía general y puede requerir adaptación en función de requisitos específicos y condiciones locales.
El siguiente diagrama ilustra la arquitectura de nuestra solución.
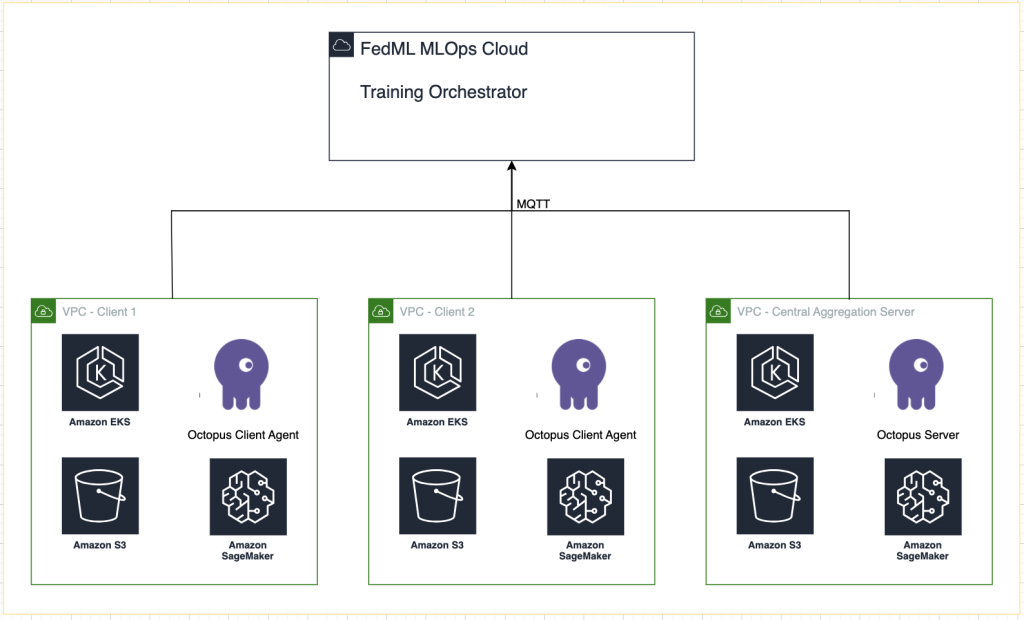
Además del seguimiento proporcionado por FedML MLOps para cada ejecución de capacitación, utilizamos Experimentos de Amazon SageMaker para realizar un seguimiento del rendimiento de cada modelo de cliente y del modelo centralizado (agregador).
SageMaker Experiments es una capacidad de SageMaker que le permite crear, administrar, analizar y comparar sus experimentos de ML. Al registrar los detalles, los parámetros y los resultados del experimento, los investigadores pueden reproducir y validar con precisión su trabajo. Permite una comparación y un análisis efectivos de diferentes enfoques, lo que conduce a una toma de decisiones informada. Además, el seguimiento de experimentos facilita la mejora iterativa al proporcionar información sobre la progresión de los modelos y permitir a los investigadores aprender de iteraciones anteriores, lo que en última instancia acelera el desarrollo de soluciones más efectivas.
Enviamos lo siguiente a SageMaker Experiments para cada ejecución:
- Métricas de evaluación del modelo – Pérdida de entrenamiento y área bajo la curva (AUC)
- Hiperparámetros – Época, tasa de aprendizaje, tamaño de lote, optimizador y disminución de peso.
Requisitos previos
Para seguir con esta publicación, debe tener los siguientes requisitos previos:
Implementar la solución
Para comenzar, clone el repositorio que aloja el código de muestra localmente:
Luego implemente la infraestructura del caso de uso usando los siguientes comandos:
La plantilla de Terraform puede tardar entre 20 y 30 minutos en implementarse por completo. Una vez implementada, siga los pasos de las siguientes secciones para ejecutar la aplicación FL.
Crear un paquete de implementación de MLOps
Como parte de la documentación de FedML, necesitamos crear los paquetes de cliente y servidor, que la plataforma MLOps distribuirá al servidor y a los clientes para comenzar la capacitación.
Para crear estos paquetes, ejecute el siguiente script que se encuentra en el directorio raíz:
Esto creará los paquetes respectivos en el siguiente directorio en el directorio raíz del proyecto:
Cargue los paquetes a la plataforma FedML MLOps
Complete los siguientes pasos para cargar los paquetes:
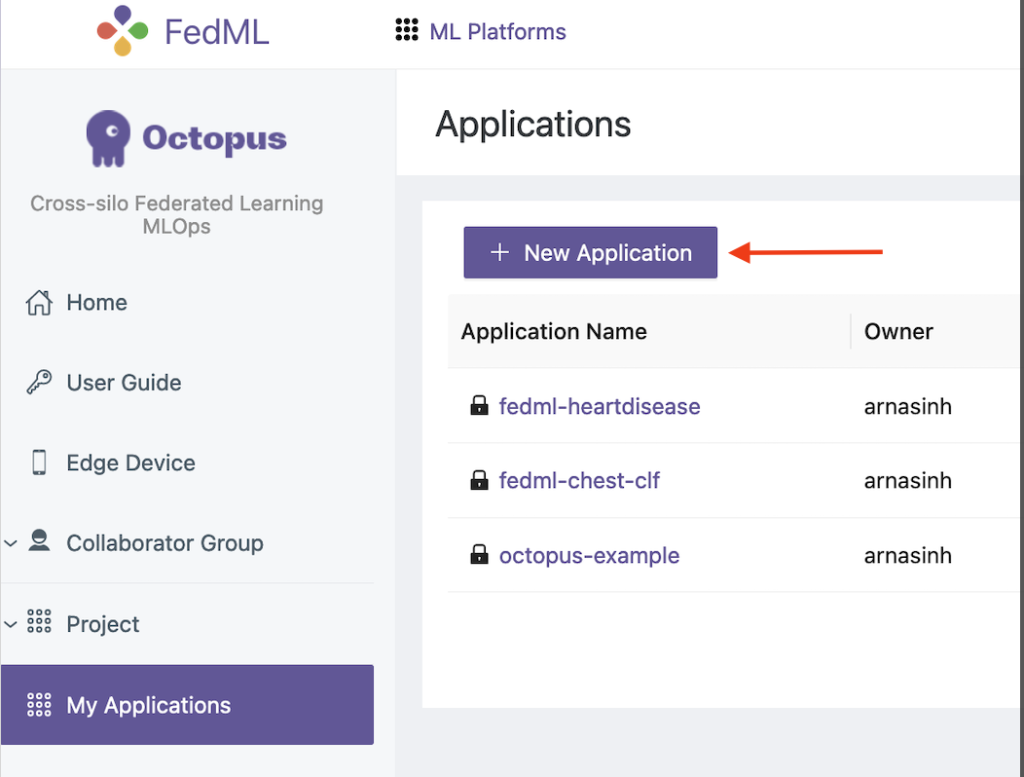
- En la interfaz de usuario de FedML, elija mis aplicaciónes en el panel de navegación.
- Elige Nueva aplicación.
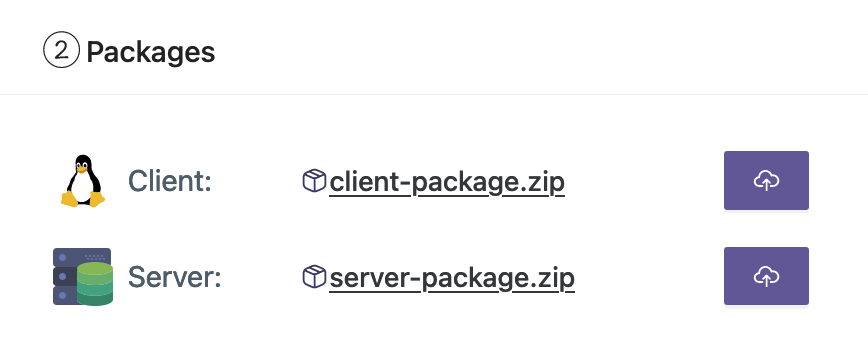
- Cargue los paquetes de cliente y servidor desde su estación de trabajo.
- También puede ajustar los hiperparámetros o crear otros nuevos.

Activar el entrenamiento federado
Para ejecutar un entrenamiento federado, complete los siguientes pasos:
- En la interfaz de usuario de FedML, elija Lista de Proyectos en el panel de navegación.
- Elige Crear un nuevo proyecto.
- Ingrese un nombre de grupo y un nombre de proyecto, luego elija OK.

- Elija el proyecto recién creado y elija Crear nueva ejecución para iniciar una carrera de entrenamiento.
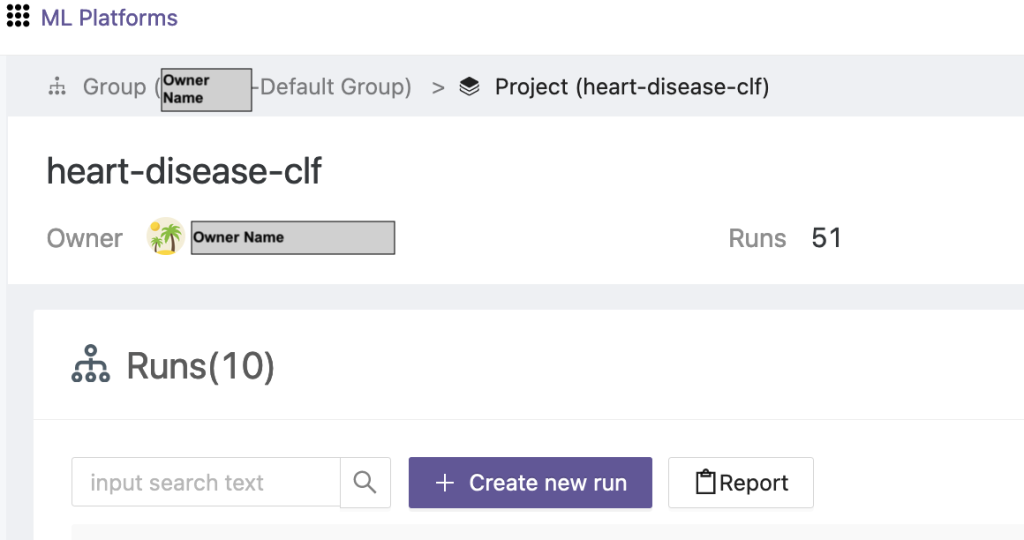
- Seleccione los dispositivos cliente perimetrales y el servidor agregador central para esta ejecución de capacitación.
- Elija la aplicación que creó en los pasos anteriores.

- Actualice cualquiera de los hiperparámetros o utilice la configuración predeterminada.
- Elige Inicio para empezar a entrenar.

- Elija el Estado de entrenamiento y espere a que se complete la ejecución de entrenamiento. También puede navegar a las pestañas disponibles.
- Cuando finalice el entrenamiento, elija el System para ver la duración del tiempo de capacitación en sus servidores perimetrales y eventos de agregación.
Ver resultados y detalles del experimento
Cuando finalice la capacitación, podrá ver los resultados utilizando FedML y SageMaker.
En la interfaz de usuario de FedML, en el fexibles pestaña, puede ver el modelo de agregador y cliente. También puede descargar estos modelos desde el sitio web.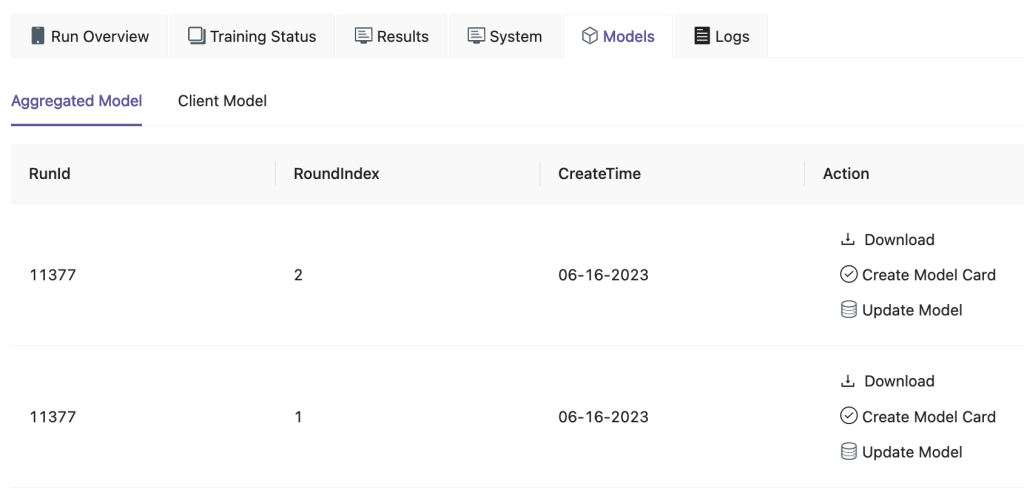
También puede iniciar sesión en Estudio Amazon SageMaker y elige Experimentos en el panel de navegación.
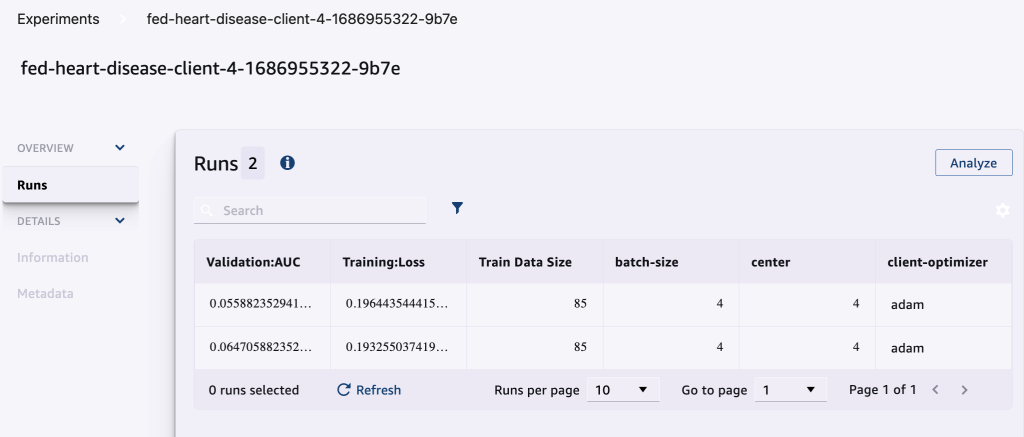
La siguiente captura de pantalla muestra los experimentos registrados.
Código de seguimiento del experimento
En esta sección, exploramos el código que integra el seguimiento de experimentos de SageMaker con la capacitación del marco FL.
En un editor de su elección, abra la siguiente carpeta para ver las ediciones del código para inyectar el código de seguimiento del experimento de SageMaker como parte de la capacitación:
Para el seguimiento de la formación, nosotros crear un experimento de SageMaker con parámetros y métricas registradas utilizando el log_parameter y log_metric comando como se describe en el siguiente ejemplo de código.
Una entrada en el config/fedml_config.yaml El archivo declara el prefijo del experimento, al que se hace referencia en el código para crear nombres de experimento únicos: sm_experiment_name: "fed-heart-disease". Puede actualizar esto a cualquier valor de su elección.
Por ejemplo, consulte el siguiente código para heart_disease_trainer.py, que utiliza cada cliente para entrenar el modelo en su propio conjunto de datos:
Para cada ejecución del cliente, los detalles del experimento se rastrean utilizando el siguiente código en heart_disease_trainer.py:
Del mismo modo, puedes utilizar el código en heart_disease_aggregator.py para ejecutar una prueba con datos locales después de actualizar los pesos del modelo. Los detalles se registran después de cada comunicación ejecutada con los clientes.
Limpiar
Cuando haya terminado con la solución, asegúrese de limpiar los recursos utilizados para garantizar la utilización eficiente de los recursos y la gestión de costos, y evitar gastos innecesarios y desperdicio de recursos. La limpieza activa del entorno, como eliminar instancias no utilizadas, detener servicios innecesarios y eliminar datos temporales, contribuye a una infraestructura limpia y organizada. Puede utilizar el siguiente código para limpiar sus recursos:
Resumen
Al utilizar Amazon EKS como infraestructura y FedML como marco para FL, podemos proporcionar un entorno escalable y administrado para entrenar e implementar modelos compartidos respetando al mismo tiempo la privacidad de los datos. Con la naturaleza descentralizada de FL, las organizaciones pueden colaborar de forma segura, desbloquear el potencial de los datos distribuidos y mejorar los modelos de ML sin comprometer la privacidad de los datos.
Como siempre, AWS agradece sus comentarios. Deje sus pensamientos y preguntas en la sección de comentarios.
Acerca de los autores
 Randy DeFauw es arquitecto principal de soluciones sénior en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión por computadora para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el ámbito tecnológico, desde ingeniería de software hasta gestión de productos. Entró en el espacio del big data en 2013 y continúa explorando esa área. Trabaja activamente en proyectos en el espacio ML y ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
Randy DeFauw es arquitecto principal de soluciones sénior en AWS. Tiene un MSEE de la Universidad de Michigan, donde trabajó en visión por computadora para vehículos autónomos. También tiene un MBA de la Universidad Estatal de Colorado. Randy ha ocupado diversos puestos en el ámbito tecnológico, desde ingeniería de software hasta gestión de productos. Entró en el espacio del big data en 2013 y continúa explorando esa área. Trabaja activamente en proyectos en el espacio ML y ha presentado en numerosas conferencias, incluidas Strata y GlueCon.
 Arnab Sinha es arquitecto de soluciones senior para AWS y actúa como director de tecnología de campo para ayudar a las organizaciones a diseñar y crear soluciones escalables que respalden los resultados comerciales en migraciones de centros de datos, transformación digital y modernización de aplicaciones, big data y aprendizaje automático. Ha brindado apoyo a clientes de una variedad de industrias, incluidas la energía, el comercio minorista, la manufactura, la atención médica y las ciencias biológicas. Arnab posee todas las certificaciones de AWS, incluida la certificación de especialidad ML. Antes de unirse a AWS, Arnab fue líder tecnológico y anteriormente ocupó puestos de liderazgo de arquitecto e ingeniería.
Arnab Sinha es arquitecto de soluciones senior para AWS y actúa como director de tecnología de campo para ayudar a las organizaciones a diseñar y crear soluciones escalables que respalden los resultados comerciales en migraciones de centros de datos, transformación digital y modernización de aplicaciones, big data y aprendizaje automático. Ha brindado apoyo a clientes de una variedad de industrias, incluidas la energía, el comercio minorista, la manufactura, la atención médica y las ciencias biológicas. Arnab posee todas las certificaciones de AWS, incluida la certificación de especialidad ML. Antes de unirse a AWS, Arnab fue líder tecnológico y anteriormente ocupó puestos de liderazgo de arquitecto e ingeniería.
 Prachi Kulkarni es arquitecto senior de soluciones en AWS. Su especialización es el aprendizaje automático y trabaja activamente en el diseño de soluciones utilizando diversas ofertas de análisis, big data y ML de AWS. Prachi tiene experiencia en múltiples ámbitos, incluidos atención médica, beneficios, comercio minorista y educación, y ha trabajado en diversos puestos en ingeniería y arquitectura de productos, gestión y éxito del cliente.
Prachi Kulkarni es arquitecto senior de soluciones en AWS. Su especialización es el aprendizaje automático y trabaja activamente en el diseño de soluciones utilizando diversas ofertas de análisis, big data y ML de AWS. Prachi tiene experiencia en múltiples ámbitos, incluidos atención médica, beneficios, comercio minorista y educación, y ha trabajado en diversos puestos en ingeniería y arquitectura de productos, gestión y éxito del cliente.
 Sherif domador es arquitecto principal de soluciones en AWS, con una experiencia diversa en el ámbito de la tecnología y los servicios de consultoría empresarial, a lo largo de más de 17 años como arquitecto de soluciones. Con un enfoque en infraestructura, la experiencia de Tamer cubre un amplio espectro de sectores verticales, incluidos comercial, atención médica, automotriz, sector público, manufactura, petróleo y gas, servicios de medios y más. Su competencia se extiende a varios dominios, como la arquitectura de la nube, la informática de punta, las redes, el almacenamiento, la virtualización, la productividad empresarial y el liderazgo técnico.
Sherif domador es arquitecto principal de soluciones en AWS, con una experiencia diversa en el ámbito de la tecnología y los servicios de consultoría empresarial, a lo largo de más de 17 años como arquitecto de soluciones. Con un enfoque en infraestructura, la experiencia de Tamer cubre un amplio espectro de sectores verticales, incluidos comercial, atención médica, automotriz, sector público, manufactura, petróleo y gas, servicios de medios y más. Su competencia se extiende a varios dominios, como la arquitectura de la nube, la informática de punta, las redes, el almacenamiento, la virtualización, la productividad empresarial y el liderazgo técnico.
 Hans Nesbitt es un arquitecto de soluciones senior en AWS con sede en el sur de California. Trabaja con clientes en todo el oeste de EE. UU. para crear arquitecturas de nube altamente escalables, flexibles y resistentes. En su tiempo libre le gusta pasar tiempo con su familia, cocinar y tocar la guitarra.
Hans Nesbitt es un arquitecto de soluciones senior en AWS con sede en el sur de California. Trabaja con clientes en todo el oeste de EE. UU. para crear arquitecturas de nube altamente escalables, flexibles y resistentes. En su tiempo libre le gusta pasar tiempo con su familia, cocinar y tocar la guitarra.
 Chaoyang él es cofundador y director de tecnología de FedML, Inc., una startup que trabaja para una comunidad que crea IA abierta y colaborativa desde cualquier lugar y a cualquier escala. Su investigación se centra en algoritmos, sistemas y aplicaciones de aprendizaje automático distribuidos y federados. Recibió su doctorado en Ciencias de la Computación de la Universidad del Sur de California.
Chaoyang él es cofundador y director de tecnología de FedML, Inc., una startup que trabaja para una comunidad que crea IA abierta y colaborativa desde cualquier lugar y a cualquier escala. Su investigación se centra en algoritmos, sistemas y aplicaciones de aprendizaje automático distribuidos y federados. Recibió su doctorado en Ciencias de la Computación de la Universidad del Sur de California.
 Al Nevarez es Director de Gestión de Productos en FedML. Antes de FedML, fue gerente de productos de grupo en Google y gerente senior de ciencia de datos en LinkedIn. Tiene varias patentes relacionadas con productos de datos y estudió ingeniería en la Universidad de Stanford.
Al Nevarez es Director de Gestión de Productos en FedML. Antes de FedML, fue gerente de productos de grupo en Google y gerente senior de ciencia de datos en LinkedIn. Tiene varias patentes relacionadas con productos de datos y estudió ingeniería en la Universidad de Stanford.
 Salman Avestimehr es cofundador y director ejecutivo de FedML. Ha sido profesor del decano de la USC, director del Centro USC-Amazon sobre IA confiable y Amazon Scholar en Alexa AI. Es un experto en aprendizaje automático federado y descentralizado, teoría de la información, seguridad y privacidad. Es miembro del IEEE y recibió su doctorado en EECS de UC Berkeley.
Salman Avestimehr es cofundador y director ejecutivo de FedML. Ha sido profesor del decano de la USC, director del Centro USC-Amazon sobre IA confiable y Amazon Scholar en Alexa AI. Es un experto en aprendizaje automático federado y descentralizado, teoría de la información, seguridad y privacidad. Es miembro del IEEE y recibió su doctorado en EECS de UC Berkeley.
 Samir Lad es un consumado tecnólogo empresarial de AWS que trabaja en estrecha colaboración con los ejecutivos de nivel C de los clientes. Como ex ejecutivo de alta dirección que ha impulsado transformaciones en múltiples empresas de Fortune 100, Samir comparte sus invaluables experiencias para ayudar a sus clientes a tener éxito en su propio viaje de transformación.
Samir Lad es un consumado tecnólogo empresarial de AWS que trabaja en estrecha colaboración con los ejecutivos de nivel C de los clientes. Como ex ejecutivo de alta dirección que ha impulsado transformaciones en múltiples empresas de Fortune 100, Samir comparte sus invaluables experiencias para ayudar a sus clientes a tener éxito en su propio viaje de transformación.
 Esteban Kraemer es asesor de la junta directiva y CxO y ex ejecutivo de AWS. Stephen defiende la cultura y el liderazgo como bases del éxito. Considera que la seguridad y la innovación son los impulsores de la transformación de la nube que permiten organizaciones altamente competitivas basadas en datos.
Esteban Kraemer es asesor de la junta directiva y CxO y ex ejecutivo de AWS. Stephen defiende la cultura y el liderazgo como bases del éxito. Considera que la seguridad y la innovación son los impulsores de la transformación de la nube que permiten organizaciones altamente competitivas basadas en datos.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/federated-learning-on-aws-using-fedml-amazon-eks-and-amazon-sagemaker/

