Imagen del autor
En el mundo actual generamos información constantemente, pero gran parte de ella surge en formatos no estructurados.
Esto incluye la amplia gama de contenido de las redes sociales, así como innumerables archivos PDF y documentos de Word almacenados en las redes organizacionales.
Obtener información y valor de estas fuentes no estructuradas, ya sean documentos de texto, páginas web o actualizaciones de redes sociales, plantea un desafío considerable.
Sin embargo, la aparición de Large Language Models (LLM) como GPT o LlaMa ha revolucionado por completo la forma en que tratamos los datos no estructurados.
Estos modelos sofisticados sirven como instrumentos potentes para transformar datos no estructurados en información estructurada y valiosa, extrayendo efectivamente los tesoros escondidos dentro de nuestro panorama digital.
Veamos 4 formas diferentes de extraer información de datos no estructurados usando GPT 👇🏻
A lo largo de este tutorial, trabajaremos con la API de OpenAI. Si aún no tiene una cuenta funcional, consulte esto tutorial sobre cómo obtener su cuenta API OpenAI.
Imagina que tenemos un comercio electrónico (Amazon en este caso 😉), y somos nosotros los responsables de gestionar los millones de reseñas que los usuarios dejan sobre nuestros productos.
Para demostrar la oportunidad que representan los LLM para manejar este tipo de datos, estoy utilizando un Conjunto de datos de Kaggle con reseñas de Amazon.

Conjunto de datos original
Los datos estructurados se refieren a tipos de datos que se formatean y repiten de manera consistente. Los ejemplos clásicos incluyen transacciones bancarias, reservas de aerolíneas, ventas minoristas y registros de llamadas telefónicas.
Estos datos generalmente surgen de procesos transaccionales.
Estos datos son adecuados para el almacenamiento y la gestión dentro de un sistema de gestión de bases de datos convencional debido a su formato uniforme.
Por otro lado, el texto suele clasificarse como datos no estructurados. Históricamente, antes del desarrollo de técnicas de desambiguación textual, incorporar texto en un sistema de gestión de bases de datos estándar era un desafío debido a su estructura menos rígida.
Y esto nos lleva a la siguiente pregunta…
¿El texto está realmente desestructurado o posee una estructura subyacente que no es evidente de inmediato?
El texto posee inherentemente una estructura, pero esta complejidad no se alinea con el formato estructurado convencional reconocible por las computadoras. Las computadoras son capaces de interpretar estructuras simples y directas, pero el lenguaje, con su elaborada sintaxis, queda fuera de su campo de comprensión.
Entonces esto nos lleva a una última pregunta:
Si las computadoras tienen dificultades para procesar datos no estructurados de manera eficiente, ¿es posible convertir estos datos no estructurados a un formato estructurado para un mejor manejo?
La conversión manual a datos estructurados lleva mucho tiempo y tiene un alto riesgo de error humano. A menudo es una mezcla de palabras, oraciones y párrafos, en una amplia variedad de formatos, lo que dificulta que las máquinas comprendan su significado y lo estructuren.
Y aquí es precisamente donde los LLM juegan un papel clave. Convertir datos no estructurados a un formato estructurado es fundamental si queremos trabajarlos o procesarlos de alguna manera, incluido el análisis de datos, la recuperación de información y la gestión del conocimiento.
Los modelos de lenguajes grandes (LLM) como GPT-3 o GPT-4 ofrecen capacidades poderosas para extraer información de datos no estructurados.
Entonces, nuestras principales armas serán la API OpenAI y la creación de nuestros propios mensajes para definir lo que necesitamos. Aquí hay cuatro formas en que puede aprovechar estos modelos para obtener información estructurada a partir de datos no estructurados:
1. Resumen de texto
Los LLM pueden resumir de manera eficiente grandes volúmenes de texto, como informes, artículos o documentos extensos. Esto puede resultar especialmente útil para comprender rápidamente puntos y temas clave en conjuntos de datos extensos.
En nuestro caso, es mucho mejor tener un primer resumen de la reseña que la reseña completa. Entonces, GPT puede solucionarlo en segundos.
Y nuestra única tarea (y la más importante) será elaborar un buen mensaje.
En este caso, puedo decirle a GPT que:
Summarize the following review: "{review}" with a 3 words sentence.
Así que pongamos esto en práctica con unas pocas líneas de código.
Código por autor
Y obtendremos algo como lo siguiente...
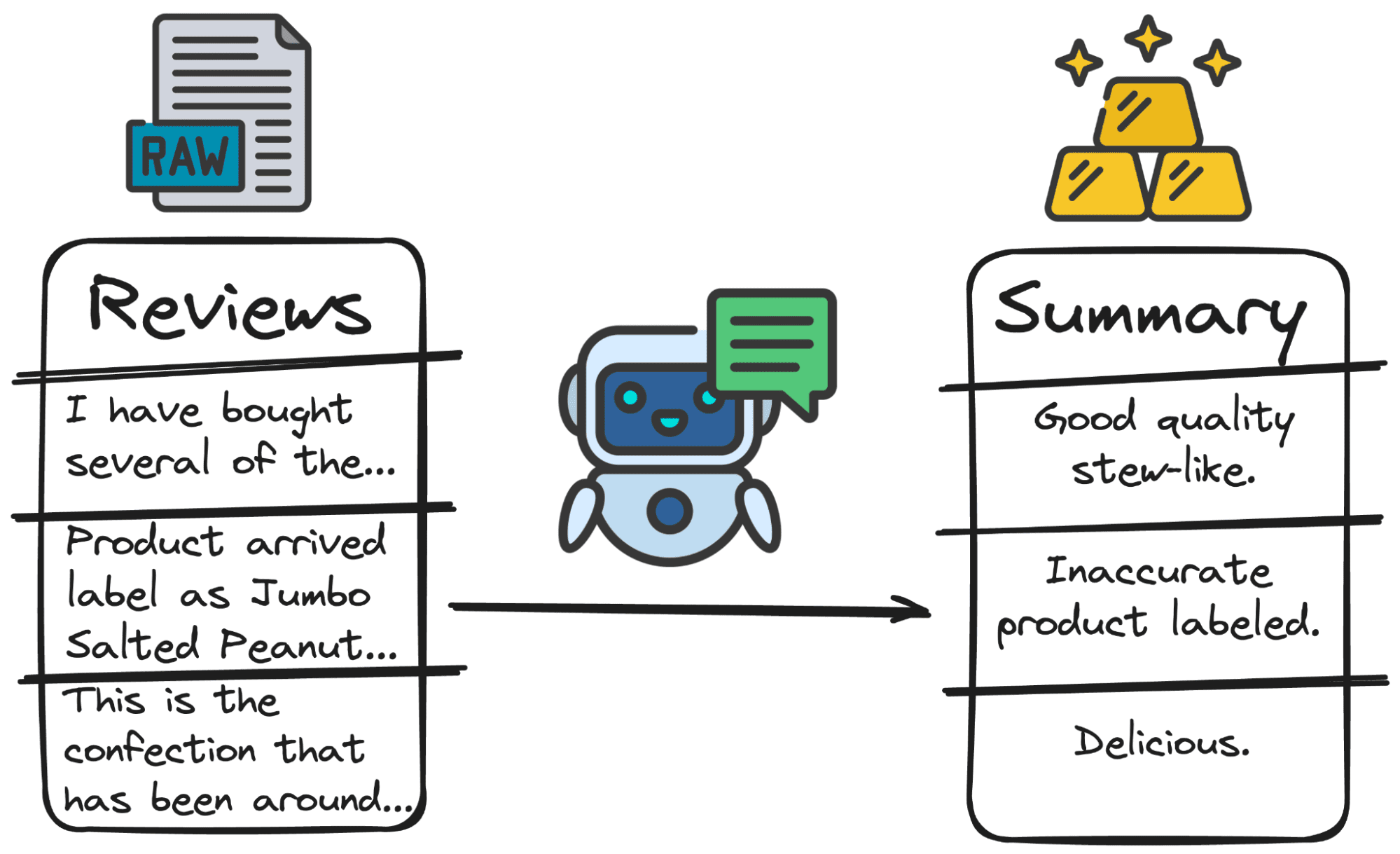
Imagen del autor
2 Análisis de los sentimientos
Estos modelos se pueden utilizar para el análisis de sentimientos, determinando el tono y el sentimiento de los datos de texto, como reseñas de clientes, publicaciones en redes sociales o encuestas de comentarios.
La clasificación más simple, pero más utilizada, de todos los tiempos es la polaridad.
- Reseñas positivas o por qué la gente está contenta con el producto.
- Reseñas negativas o por qué están molestos.
- Neutral o por qué la gente es indiferente con el producto.
Al analizar estos sentimientos, las empresas pueden medir la opinión pública, la satisfacción del cliente y las tendencias del mercado. Así, en lugar de que una persona decida cada reseña, podemos hacer que nuestro amigo GPT las clasifique por nosotros.
Entonces, nuevamente el código principal consistirá en un mensaje y una simple llamada a la API.
Pongamos esto en práctica.
Código por autor
Y obtendríamos algo de la siguiente manera:
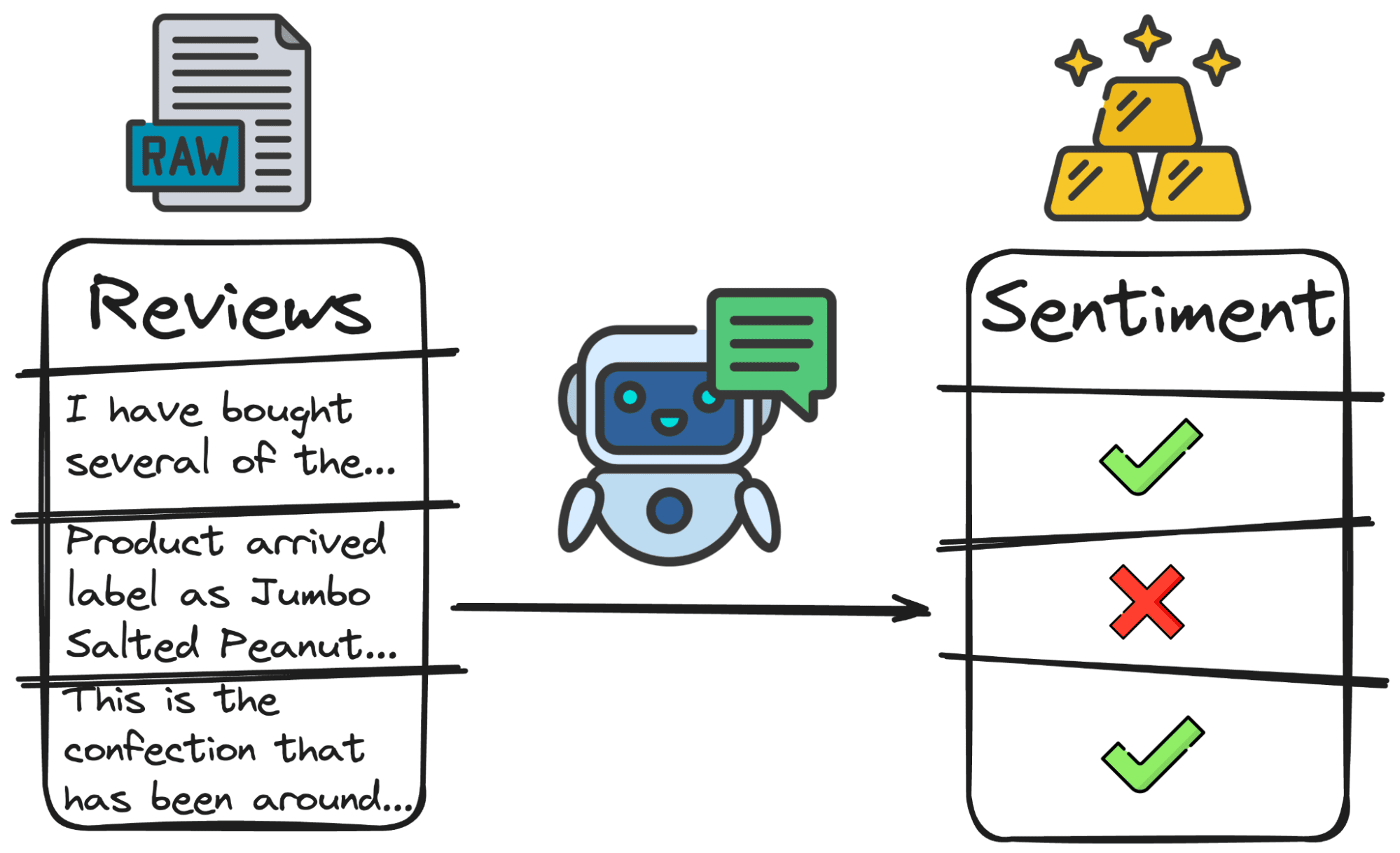
Imagen del autor
3. Análisis temático
Los LLM pueden identificar y categorizar temas o temas dentro de grandes conjuntos de datos. Esto es particularmente útil para el análisis de datos cualitativos, donde es posible que deba examinar grandes cantidades de texto para comprender temas, tendencias o patrones comunes.
Al analizar reseñas, puede resultar útil comprender el objetivo principal de la reseña. Algunos usuarios se quejarán de algo (servicio, calidad, coste…), otros calificarán su experiencia con el producto (bien o mal) y otros realizarán preguntas.
Nuevamente, hacer este trabajo manualmente supondría muchas horas. Pero con nuestro amigo GPT, sólo se necesitan unas pocas líneas de código:
Código por autor
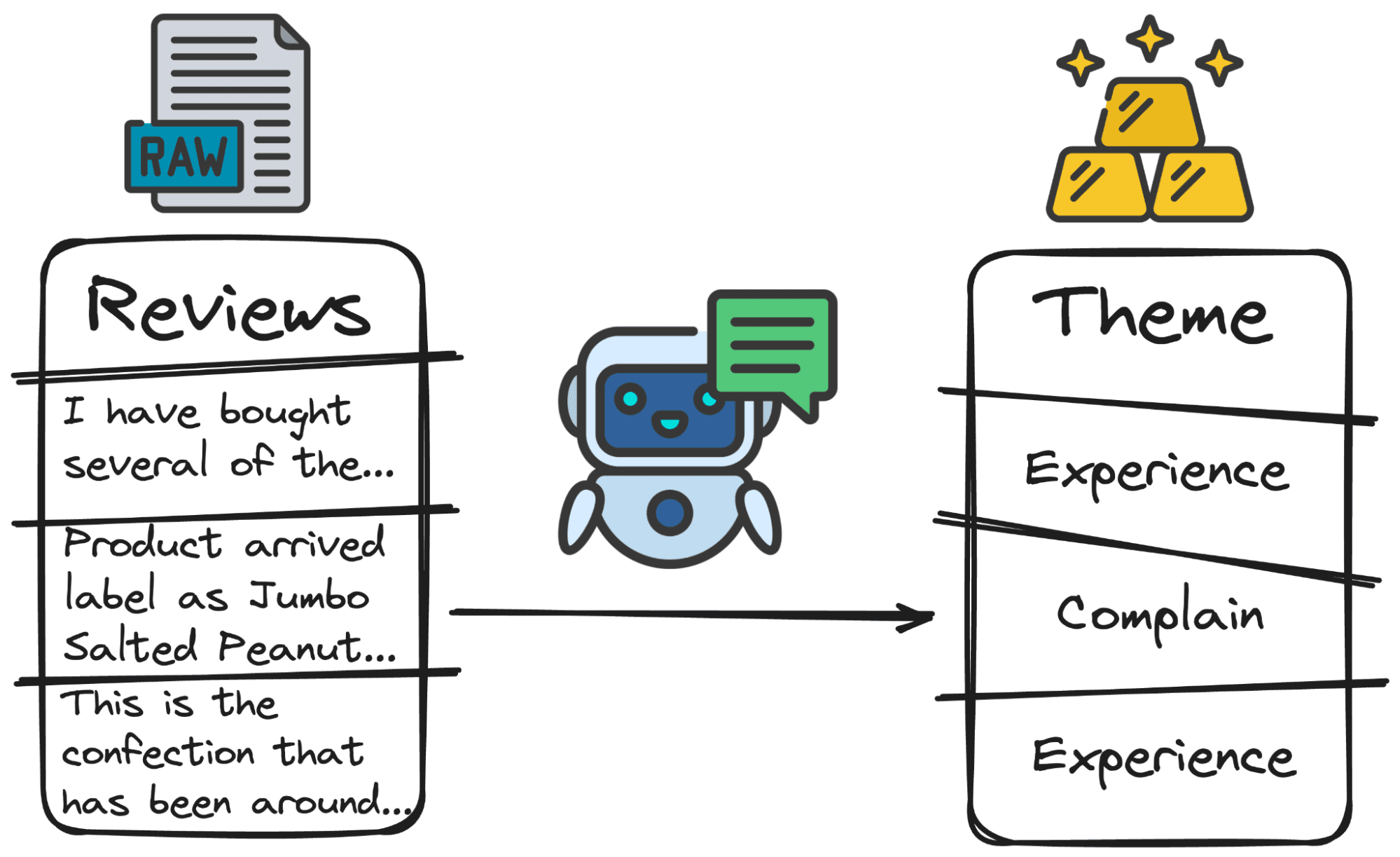
Imagen del autor
4. Extracción de palabras clave
Los LLM se pueden utilizar para extraer palabras clave. Es decir, detectar cualquier elemento que le solicitemos.
Imaginemos, por ejemplo, que queremos saber si el producto al que se adjunta la reseña es el producto del que habla el usuario. Para ello debemos detectar qué producto está reseñando el usuario.
Y de nuevo… podemos pedirle a nuestro modelo GPT que averigüe del producto principal del que está hablando el usuario.
¡Así que pongamos esto en práctica!
Código por autor
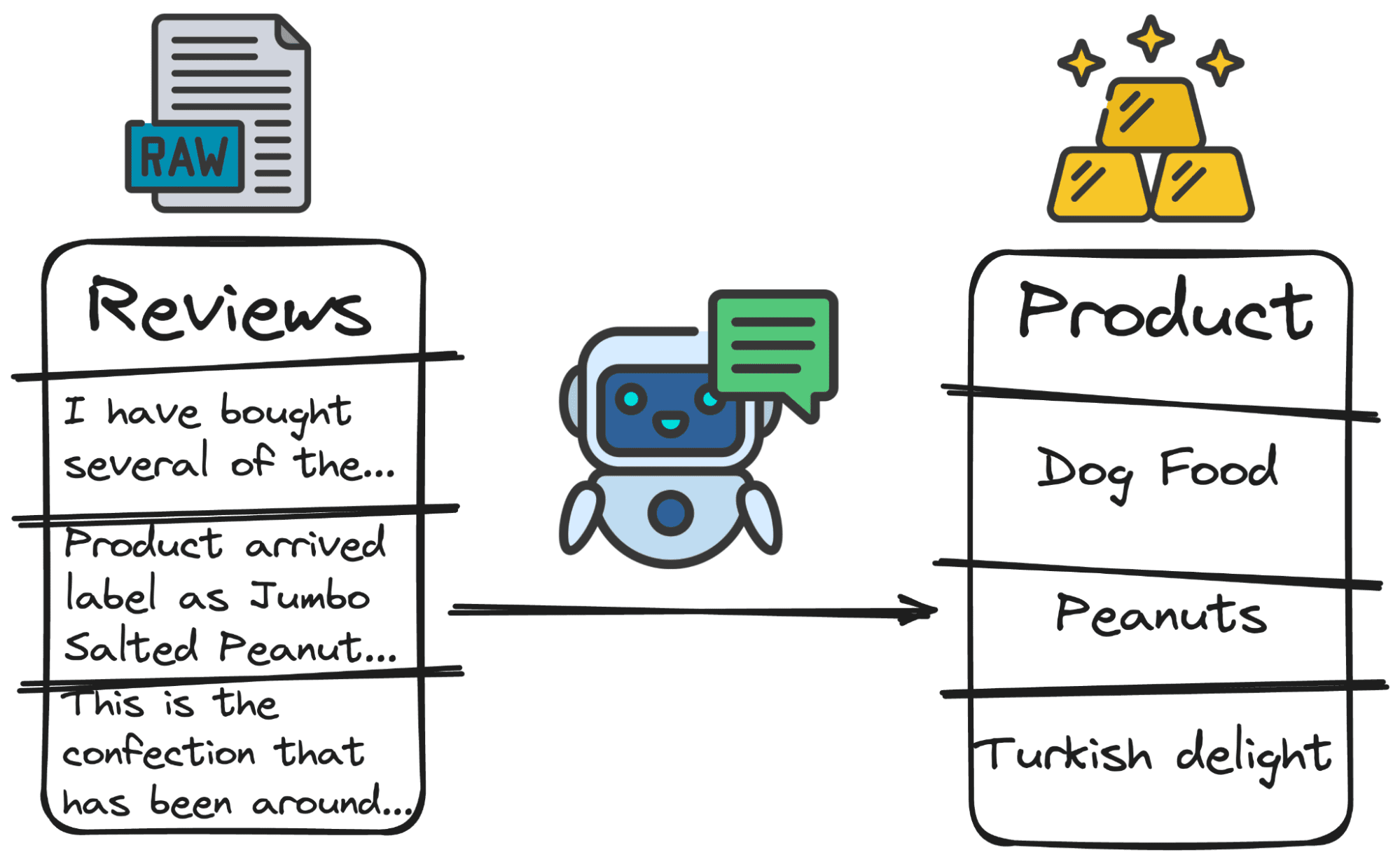
Imagen del autor
En conclusión, no se puede subestimar el poder transformador de los modelos de lenguajes grandes (LLM) para convertir datos no estructurados en conocimientos estructurados. Aprovechando estos modelos, podemos extraer información significativa del vasto mar de datos no estructurados que fluye dentro de nuestro mundo digital.
Los cuatro métodos discutidos (resumen de texto, análisis de sentimientos, análisis temático y extracción de palabras clave) demuestran la versatilidad y eficiencia de los LLM en el manejo de diversos desafíos de datos.
Estas capacidades permiten a las organizaciones obtener una comprensión más profunda de los comentarios de los clientes, las tendencias del mercado y las ineficiencias operativas.
Josep Ferrer es un ingeniero analítico de Barcelona. Se graduó en ingeniería física y actualmente trabaja en el campo de la Ciencia de Datos aplicada a la movilidad humana. Es un creador de contenido a tiempo parcial centrado en la ciencia y la tecnología de datos. Puedes contactarlo en Etiqueta LinkedIn, Twitter or Medio.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/5-ways-of-converting-unstructured-data-into-structured-insights-with-llms?utm_source=rss&utm_medium=rss&utm_campaign=5-ways-of-converting-unstructured-data-into-structured-insights-with-llms

