Descubrir respuestas precisas y esclarecedoras a partir de grandes cantidades de texto es una capacidad interesante que permiten los modelos de lenguaje de gran tamaño (LLM). Al crear aplicaciones LLM, a menudo es necesario conectarse y consultar fuentes de datos externas para proporcionar un contexto relevante al modelo. Un enfoque popular es utilizar la generación aumentada de recuperación (RAG) para crear sistemas de preguntas y respuestas que comprendan información compleja y proporcionen respuestas naturales a las consultas. RAG permite que los modelos aprovechen amplias bases de conocimientos y ofrezcan un diálogo similar al humano para aplicaciones como chatbots y asistentes de búsqueda empresarial.
En esta publicación, exploramos cómo aprovechar el poder de LlamaIndex, Llama 2-70B-Chaty LangChain para crear potentes aplicaciones de preguntas y respuestas. Con estas tecnologías de vanguardia, puede ingerir corpus de texto, indexar conocimiento crítico y generar texto que responda a las preguntas de los usuarios de manera precisa y clara.
Llama 2-70B-Chat
Llama 2-70B-Chat es un poderoso LLM que compite con los modelos líderes. Está previamente entrenado en dos billones de tokens de texto y Meta pretende que se utilice para brindar asistencia por chat a los usuarios. Los datos de preentrenamiento provienen de datos disponibles públicamente y concluyen en septiembre de 2022, y los datos de ajuste finalizan en julio de 2023. Para obtener más detalles sobre el proceso de entrenamiento del modelo, las consideraciones de seguridad, los aprendizajes y los usos previstos, consulte el documento. Llama 2: Fundación abierta y modelos de chat optimizados. Los modelos Llama 2 están disponibles en JumpStart de Amazon SageMaker para una implementación rápida y sencilla.
LlamaIndex
LlamaIndex es un marco de datos que permite crear aplicaciones LLM. Proporciona herramientas que ofrecen conectores de datos para ingerir sus datos existentes con diversas fuentes y formatos (PDF, documentos, API, SQL y más). Ya sea que tenga datos almacenados en bases de datos o en archivos PDF, LlamaIndex facilita el uso de esos datos para los LLM. Como demostramos en esta publicación, las API de LlamaIndex facilitan el acceso a los datos y le permiten crear potentes aplicaciones y flujos de trabajo LLM personalizados.
Si está experimentando y desarrollando LLM, probablemente esté familiarizado con LangChain, que ofrece un marco sólido que simplifica el desarrollo y la implementación de aplicaciones basadas en LLM. Al igual que LangChain, LlamaIndex ofrece una serie de herramientas, incluidos conectores de datos, índices de datos, motores y agentes de datos, así como integraciones de aplicaciones como herramientas y observabilidad, seguimiento y evaluación. LlamaIndex se enfoca en cerrar la brecha entre los datos y los LLM potentes, simplificando las tareas de datos con funciones fáciles de usar. LlamaIndex está diseñado y optimizado específicamente para crear aplicaciones de búsqueda y recuperación, como RAG, porque proporciona una interfaz simple para consultar LLM y recuperar documentos relevantes.
Resumen de la solución
En esta publicación, demostramos cómo crear una aplicación basada en RAG usando LlamaIndex y un LLM. El siguiente diagrama muestra la arquitectura paso a paso de esta solución descrita en las siguientes secciones.
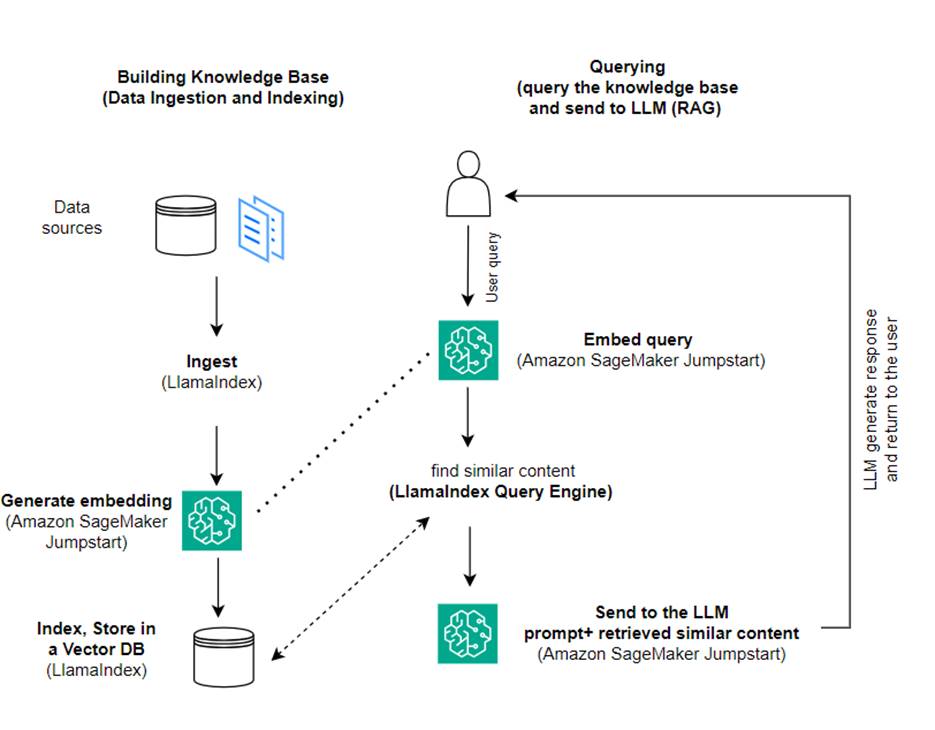
RAG combina la recuperación de información con la generación de lenguaje natural para producir respuestas más reveladoras. Cuando se le solicita, RAG primero busca corpus de texto para recuperar los ejemplos más relevantes de la entrada. Durante la generación de respuestas, el modelo considera estos ejemplos para aumentar sus capacidades. Al incorporar pasajes recuperados relevantes, las respuestas de RAG tienden a ser más objetivas, coherentes y consistentes con el contexto en comparación con los modelos generativos básicos. Este marco de recuperación y generación aprovecha las fortalezas tanto de la recuperación como de la generación, ayudando a abordar problemas como la repetición y la falta de contexto que pueden surgir de modelos conversacionales puramente autorregresivos. RAG presenta un enfoque eficaz para crear agentes conversacionales y asistentes de inteligencia artificial con respuestas contextualizadas y de alta calidad.
La construcción de la solución consta de los siguientes pasos:
- Preparar Estudio Amazon SageMaker como entorno de desarrollo e instalar las dependencias necesarias.
- Implemente un modelo de inserción desde el centro JumpStart de Amazon SageMaker.
- Descargue comunicados de prensa para utilizarlos como nuestra base de conocimientos externa.
- Cree un índice a partir de los comunicados de prensa para poder consultar y agregar contexto adicional al mensaje.
- Consulta la base de conocimientos.
- Cree una aplicación de preguntas y respuestas utilizando agentes LlamaIndex y LangChain.
Todo el código de esta publicación está disponible en el Repositorio GitHub.
Requisitos previos
Para este ejemplo, necesita una cuenta de AWS con un dominio de SageMaker y Gestión de identidades y accesos de AWS (IAM) permisos. Para obtener instrucciones de configuración de la cuenta, consulte Crear una cuenta de AWS. Si aún no tiene un dominio de SageMaker, consulte Dominio de Amazon SageMaker descripción general para crear uno. En esta publicación utilizamos el AmazonSageMakerFullAccess role. No se recomienda utilizar esta credencial en un entorno de producción. En su lugar, debería crear y utilizar un rol con permisos con privilegios mínimos. También puedes explorar cómo puedes usar Administrador de funciones de Amazon SageMaker para crear y administrar roles de IAM basados en personas para necesidades comunes de aprendizaje automático directamente a través de la consola de SageMaker.
Además, necesita acceso a un mínimo de los siguientes tamaños de instancia:
- ml.g5.2xgrande para el uso de endpoints al implementar el Abrazando la cara GPT-J modelo de incrustaciones de texto
- ml.g5.48xgrande para el uso del punto final al implementar el punto final del modelo Llama 2-Chat
Para aumentar su cuota, consulte Solicitar un aumento de cuota.
Implemente un modelo de incrustación GPT-J usando SageMaker JumpStart
Esta sección le ofrece dos opciones al implementar modelos SageMaker JumpStart. Puede utilizar una implementación basada en código utilizando el código proporcionado o utilizar la interfaz de usuario (UI) de SageMaker JumpStart.
Implementar con el SDK de Python de SageMaker
Puede utilizar el SDK de Python de SageMaker para implementar los LLM, como se muestra en la código disponible en el repositorio. Complete los siguientes pasos:
- Establezca el tamaño de instancia que se utilizará para la implementación del modelo de incrustaciones usando
instance_type = "ml.g5.2xlarge" - Localice el ID del modelo que se utilizará para las incrustaciones. En SageMaker JumpStart, se identifica como
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Recupere el contenedor del modelo previamente entrenado e impleméntelo para realizar inferencias.
SageMaker devolverá el nombre del punto final del modelo y el siguiente mensaje cuando el modelo de incorporación se haya implementado correctamente:
Implementar con SageMaker JumpStart en SageMaker Studio
Para implementar el modelo usando SageMaker JumpStart en Studio, complete los siguientes pasos:
- En la consola de SageMaker Studio, elija JumpStart en el panel de navegación.

- Busca y elige el modelo GPT-J 6B Embedding FP16.
- Elija Implementar y personalice la configuración de implementación.

- Para este ejemplo, necesitamos una instancia ml.g5.2xlarge, que es la instancia predeterminada sugerida por SageMaker JumpStart.
- Elija Implementar nuevamente para crear el punto final.
El terminal tardará aproximadamente entre 5 y 10 minutos en estar en servicio.

Una vez que haya implementado el modelo de incrustaciones, para utilizar la integración de LangChain con las API de SageMaker, debe crear una función para manejar las entradas (texto sin formato) y transformarlas en incrustaciones usando el modelo. Esto se hace creando una clase llamada ContentHandler, que toma un JSON de datos de entrada y devuelve un JSON de incrustaciones de texto: class ContentHandler(EmbeddingsContentHandler).
Pase el nombre del punto final del modelo al ContentHandler función para convertir el texto y devolver incrustaciones:
Puede ubicar el nombre del punto final en la salida del SDK o en los detalles de implementación en la interfaz de usuario de SageMaker JumpStart.
Puedes probar que el ContentHandler La función y el punto final funcionan como se esperaba al ingresar texto sin formato y ejecutar el embeddings.embed_query(text) función. Puedes usar el ejemplo proporcionado. text = "Hi! It's time for the beach" o prueba tu propio texto.
Implemente y pruebe Llama 2-Chat usando SageMaker JumpStart
Ahora puede implementar el modelo que puede tener conversaciones interactivas con sus usuarios. En este caso, elegimos uno de los modelos Llama 2-chat, que se identifica mediante
El modelo debe implementarse en un punto final en tiempo real utilizando predictor = my_model.deploy(). SageMaker devolverá el nombre del punto final del modelo, que puede utilizar para endpoint_name variable a la que hacer referencia más adelante.
Tu defines un print_dialogue función para enviar entradas al modelo de chat y recibir su respuesta de salida. La carga útil incluye hiperparámetros para el modelo, incluidos los siguientes:
- max_new_tokens – Se refiere al número máximo de tokens que el modelo puede generar en sus salidas.
- arriba_p – Se refiere a la probabilidad acumulada de los tokens que el modelo puede retener al generar sus resultados.
- temperatura – Se refiere a la aleatoriedad de los resultados generados por el modelo. Una temperatura mayor que 0 o igual a 1 aumenta el nivel de aleatoriedad, mientras que una temperatura de 0 generará las fichas más probables.
Debe seleccionar sus hiperparámetros según su caso de uso y probarlos adecuadamente. Modelos como la familia Llama requieren que incluyas un parámetro adicional que indique que has leído y aceptado el Acuerdo de licencia de usuario final (EULA):
Para probar el modelo, reemplace la sección de contenido de la carga útil de entrada: "content": "what is the recipe of mayonnaise?". Puede utilizar sus propios valores de texto y actualizar los hiperparámetros para comprenderlos mejor.
De manera similar a la implementación del modelo de incorporación, puede implementar Llama-70B-Chat usando la interfaz de usuario JumpStart de SageMaker:
- En la consola de SageMaker Studio, elija Buen inicio en el panel de navegación
- Busca y elige el
Llama-2-70b-Chat model - Acepte el EULA y elija Despliegue, usando la instancia predeterminada nuevamente
De manera similar al modelo de incrustación, puede utilizar la integración de LangChain creando una plantilla de controlador de contenido para las entradas y salidas de su modelo de chat. En este caso, define las entradas como aquellas provenientes de un usuario, e indica que se rigen por el system prompt. system prompt informa al modelo de su función de ayudar al usuario para un caso de uso particular.
Luego, este controlador de contenido se pasa al invocar el modelo, además de los hiperparámetros y atributos personalizados antes mencionados (aceptación de EULA). Analiza todos estos atributos utilizando el siguiente código:
Cuando el punto final esté disponible, puede probar que funciona como se esperaba. puedes actualizar llm("what is amazon sagemaker?") con tu propio texto. También es necesario definir el específico ContentHandler para invocar el LLM usando LangChain, como se muestra en la código y el siguiente fragmento de código:
Utilice LlamaIndex para construir el RAG
Para continuar, instale LlamaIndex para crear la aplicación RAG. Puedes instalar LlamaIndex usando el pip: pip install llama_index
Primero debe cargar sus datos (base de conocimientos) en LlamaIndex para indexarlos. Esto implica algunos pasos:
- Elija un cargador de datos:
LlamaIndex proporciona una serie de conectores de datos disponibles en LlamaHub para tipos de datos comunes como JSON, CSV y archivos de texto, así como otras fuentes de datos, lo que le permite ingerir una variedad de conjuntos de datos. En esta publicación utilizamos SimpleDirectoryReader para ingerir algunos archivos PDF como se muestra en el código. Nuestra muestra de datos son dos comunicados de prensa de Amazon en versión PDF en el comnunicados de prensa carpeta en nuestro repositorio de código. Después de cargar los archivos PDF, podrá ver que se han convertido en una lista de 11 elementos.
En lugar de cargar los documentos directamente, también puede convertir el Document objeto en Node objetos antes de enviarlos al índice. La elección entre enviar todo el Document objeto al índice o convertir el Documento en Node Los objetos antes de la indexación dependen de su caso de uso específico y de la estructura de sus datos. El enfoque de nodos suele ser una buena opción para documentos largos, en los que desea dividir y recuperar partes específicas de un documento en lugar de todo el documento. Para obtener más información, consulte Documentos / Nodos.
- Cree una instancia del cargador y cargue los documentos:
Este paso inicializa la clase del cargador y cualquier configuración necesaria, como por ejemplo si se deben ignorar los archivos ocultos. Para obtener más detalles, consulte Lector de directorio simple.
- Llame al cargador
load_datamétodo para analizar sus archivos y datos de origen y convertirlos en objetos de documento LlamaIndex, listos para indexar y consultar. Puede utilizar el siguiente código para completar la ingesta de datos y la preparación para la búsqueda de texto completo utilizando las capacidades de indexación y recuperación de LlamaIndex:
- Construya el índice:
La característica clave de LlamaIndex es su capacidad para construir índices organizados sobre datos, que se representan como documentos o nodos. La indexación facilita la consulta eficiente de los datos. Creamos nuestro índice con el almacén de vectores en memoria predeterminado y con nuestra configuración de configuración definida. El índice de llamas Ajustes es un objeto de configuración que proporciona recursos y configuraciones de uso común para operaciones de indexación y consulta en una aplicación LlamaIndex. Actúa como un objeto singleton, de modo que le permite establecer configuraciones globales y, al mismo tiempo, le permite anular componentes específicos localmente pasándolos directamente a las interfaces (como LLM, modelos integrados) que los utilizan. Cuando un componente particular no se proporciona explícitamente, el marco LlamaIndex recurre a la configuración definida en el Settings objeto como valor predeterminado global. Para utilizar nuestros modelos de incrustación y LLM con LangChain y configurar el Settings necesitamos instalar llama_index.embeddings.langchain y llama_index.llms.langchain. Podemos configurar el Settings objeto como en el siguiente código:
De forma predeterminada, VectorStoreIndex utiliza una en memoria SimpleVectorStore que se inicializa como parte del contexto de almacenamiento predeterminado. En casos de uso de la vida real, a menudo es necesario conectarse a almacenes de vectores externos como Servicio Amazon OpenSearch. Para obtener más detalles, consulte Motor vectorial para Amazon OpenSearch sin servidor.
Ahora puede ejecutar Preguntas y respuestas sobre sus documentos utilizando el motor_query de LlamaIndex. Para hacerlo, pasa el índice que creaste anteriormente para consultas y haz tu pregunta. El motor de consultas es una interfaz genérica para consultar datos. Toma una consulta en lenguaje natural como entrada y devuelve una respuesta rica. El motor de consultas normalmente se construye sobre uno o más índices usando perros perdigueros.
Puede ver que la solución RAG puede recuperar la respuesta correcta de los documentos proporcionados:
Utilice las herramientas y agentes de LangChain
Loader clase. El cargador está diseñado para cargar datos en LlamaIndex o posteriormente como herramienta en un Agente de LangChain. Esto le brinda más poder y flexibilidad para usarlo como parte de su aplicación. Empiece por definir su del IRS de la clase de agente LangChain. La función que pasas a tu herramienta consulta el índice que creaste sobre tus documentos usando LlamaIndex.
Luego, seleccione el tipo correcto de agente que le gustaría utilizar para su implementación de RAG. En este caso se utiliza el chat-zero-shot-react-description agente. Con este agente, el LLM utilizará la herramienta disponible (en este escenario, el RAG sobre la base de conocimientos) para brindar la respuesta. Luego inicializa el agente pasando su herramienta, LLM y tipo de agente:
Puedes ver al agente pasando thoughts, actionsy observation , utilice la herramienta (en este escenario, consultando sus documentos indexados); y devolver un resultado:
Puede encontrar el código de implementación de un extremo a otro en el documento adjunto Repositorio GitHub.
Limpiar
Para evitar costos innecesarios, puede limpiar sus recursos, ya sea mediante los siguientes fragmentos de código o la interfaz de usuario de Amazon JumpStart.
Para usar el SDK de Boto3, use el siguiente código para eliminar el punto final del modelo de incrustación de texto y el punto final del modelo de generación de texto, así como las configuraciones de los puntos finales:
Para utilizar la consola de SageMaker, complete los siguientes pasos:
- En la consola de SageMaker, en Inferencia en el panel de navegación, elija Puntos finales
- Busque los puntos finales de incrustación y generación de texto.
- En la página de detalles del punto final, elija Eliminar.
- Elija Eliminar nuevamente para confirmar.
Conclusión
Para casos de uso centrados en la búsqueda y recuperación, LlamaIndex proporciona capacidades flexibles. Destaca en la indexación y recuperación para LLM, lo que la convierte en una herramienta poderosa para la exploración profunda de datos. LlamaIndex le permite crear índices de datos organizados, utilizar diversos LLM, aumentar los datos para un mejor rendimiento de los LLM y consultar datos con lenguaje natural.
Esta publicación demostró algunos conceptos y capacidades clave de LlamaIndex. Usamos GPT-J para incrustar y Llama 2-Chat como LLM para crear una aplicación RAG, pero puedes usar cualquier modelo adecuado en su lugar. Puede explorar la amplia gama de modelos disponibles en SageMaker JumpStart.
También mostramos cómo LlamaIndex puede proporcionar herramientas potentes y flexibles para conectar, indexar, recuperar e integrar datos con otros marcos como LangChain. Con las integraciones de LlamaIndex y LangChain, puede crear aplicaciones LLM más potentes, versátiles y reveladoras.
Acerca de los autores
 Dra. Romina Sharifpour es arquitecto senior de soluciones de inteligencia artificial y aprendizaje automático en Amazon Web Services (AWS). Ha pasado más de 10 años liderando el diseño y la implementación de soluciones innovadoras de un extremo a otro habilitadas por avances en ML e IA. Las áreas de interés de Romina son el procesamiento del lenguaje natural, los modelos de lenguaje grandes y MLOps.
Dra. Romina Sharifpour es arquitecto senior de soluciones de inteligencia artificial y aprendizaje automático en Amazon Web Services (AWS). Ha pasado más de 10 años liderando el diseño y la implementación de soluciones innovadoras de un extremo a otro habilitadas por avances en ML e IA. Las áreas de interés de Romina son el procesamiento del lenguaje natural, los modelos de lenguaje grandes y MLOps.
 nicole pinto es un arquitecto de soluciones especializado en IA/ML con sede en Sydney, Australia. Su experiencia en servicios financieros y de atención médica le brinda una perspectiva única para resolver los problemas de los clientes. Le apasiona ayudar a los clientes a través del aprendizaje automático y empoderar a la próxima generación de mujeres en STEM.
nicole pinto es un arquitecto de soluciones especializado en IA/ML con sede en Sydney, Australia. Su experiencia en servicios financieros y de atención médica le brinda una perspectiva única para resolver los problemas de los clientes. Le apasiona ayudar a los clientes a través del aprendizaje automático y empoderar a la próxima generación de mujeres en STEM.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

