Hoy, nos complace anunciar que los modelos básicos de Code Llama, desarrollados por Meta, están disponibles para los clientes a través de JumpStart de Amazon SageMaker para implementar con un clic para ejecutar la inferencia. Code Llama es un modelo de lenguaje grande (LLM) de última generación capaz de generar código y lenguaje natural sobre el código a partir de indicaciones de código y lenguaje natural. Puede probar este modelo con SageMaker JumpStart, un centro de aprendizaje automático (ML) que brinda acceso a algoritmos, modelos y soluciones de ML para que pueda comenzar rápidamente con ML. En esta publicación, explicamos cómo descubrir e implementar el modelo Code Llama a través de SageMaker JumpStart.
Código Llama
Code Llama es un modelo lanzado por Meta que está construido sobre Llama 2. Este modelo de última generación está diseñado para mejorar la productividad de las tareas de programación de los desarrolladores ayudándoles a crear código bien documentado y de alta calidad. Los modelos destacan en Python, C++, Java, PHP, C#, TypeScript y Bash, y tienen el potencial de ahorrar tiempo a los desarrolladores y hacer que los flujos de trabajo del software sean más eficientes.
Viene en tres variantes, diseñadas para cubrir una amplia variedad de aplicaciones: el modelo fundamental (Code Llama), un modelo especializado en Python (Code Llama Python) y un modelo de seguimiento de instrucciones para comprender instrucciones en lenguaje natural (Code Llama Instruct). Todas las variantes de Code Llama vienen en cuatro tamaños: parámetros 7B, 13B, 34B y 70B. Las variantes de instrucción y base 7B y 13B admiten el relleno según el contenido circundante, lo que las hace ideales para aplicaciones de asistente de código. Los modelos se diseñaron utilizando Llama 2 como base y luego se entrenaron con 500 mil millones de tokens de datos de código, con la versión especializada de Python entrenada con 100 mil millones de tokens incrementales. Los modelos Code Llama proporcionan generaciones estables con hasta 100,000 tokens de contexto. Todos los modelos están entrenados en secuencias de 16,000 tokens y muestran mejoras en entradas con hasta 100,000 tokens.
El modelo está disponible bajo el mismo Licencia comunitaria como Llama 2.
Modelos de base en SageMaker
SageMaker JumpStart brinda acceso a una variedad de modelos de centros de modelos populares, incluidos Hugging Face, PyTorch Hub y TensorFlow Hub, que puede usar dentro de su flujo de trabajo de desarrollo de aprendizaje automático en SageMaker. Los avances recientes en ML han dado lugar a una nueva clase de modelos conocidos como modelos de cimientos, que normalmente se entrenan en miles de millones de parámetros y se adaptan a una amplia categoría de casos de uso, como resumen de texto, generación de arte digital y traducción de idiomas. Debido a que estos modelos son costosos de entrenar, los clientes prefieren utilizar modelos básicos previamente entrenados y ajustarlos según sea necesario, en lugar de entrenar estos modelos ellos mismos. SageMaker proporciona una lista seleccionada de modelos entre los que puede elegir en la consola de SageMaker.
Puede encontrar modelos básicos de diferentes proveedores de modelos dentro de SageMaker JumpStart, lo que le permitirá comenzar a trabajar con modelos básicos rápidamente. Puede encontrar modelos básicos basados en diferentes tareas o proveedores de modelos, y revisar fácilmente las características del modelo y los términos de uso. También puedes probar estos modelos utilizando un widget de interfaz de usuario de prueba. Cuando desee utilizar un modelo básico a escala, puede hacerlo sin salir de SageMaker utilizando cuadernos prediseñados de proveedores de modelos. Debido a que los modelos están alojados e implementados en AWS, puede estar seguro de que sus datos, ya sea que se utilicen para evaluar o utilizar el modelo a escala, nunca se comparten con terceros.
Descubra el modelo Code Llama en SageMaker JumpStart
Para implementar el modelo Code Llama 70B, complete los siguientes pasos en Estudio Amazon SageMaker:
- En la página de inicio de SageMaker Studio, elija Buen inicio en el panel de navegación.
- Busque modelos Code Llama y elija el modelo Code Llama 70B de la lista de modelos que se muestran.
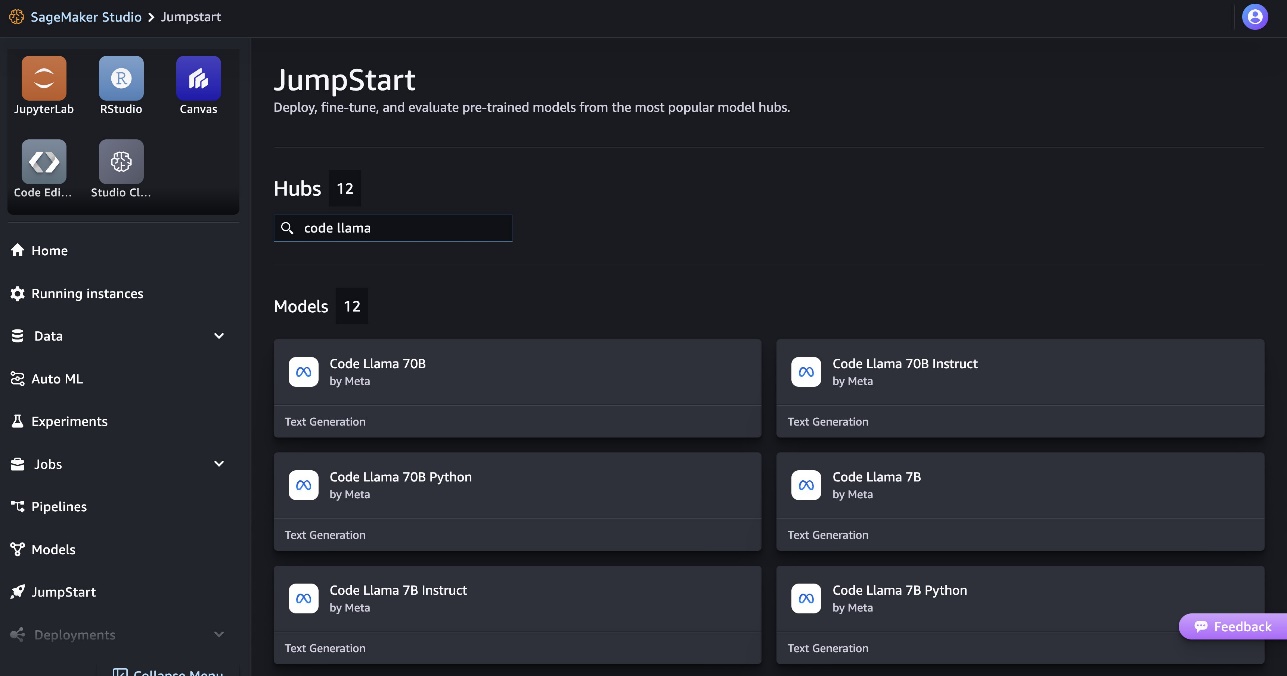
Puedes encontrar más información sobre el modelo en la ficha del modelo Code Llama 70B.
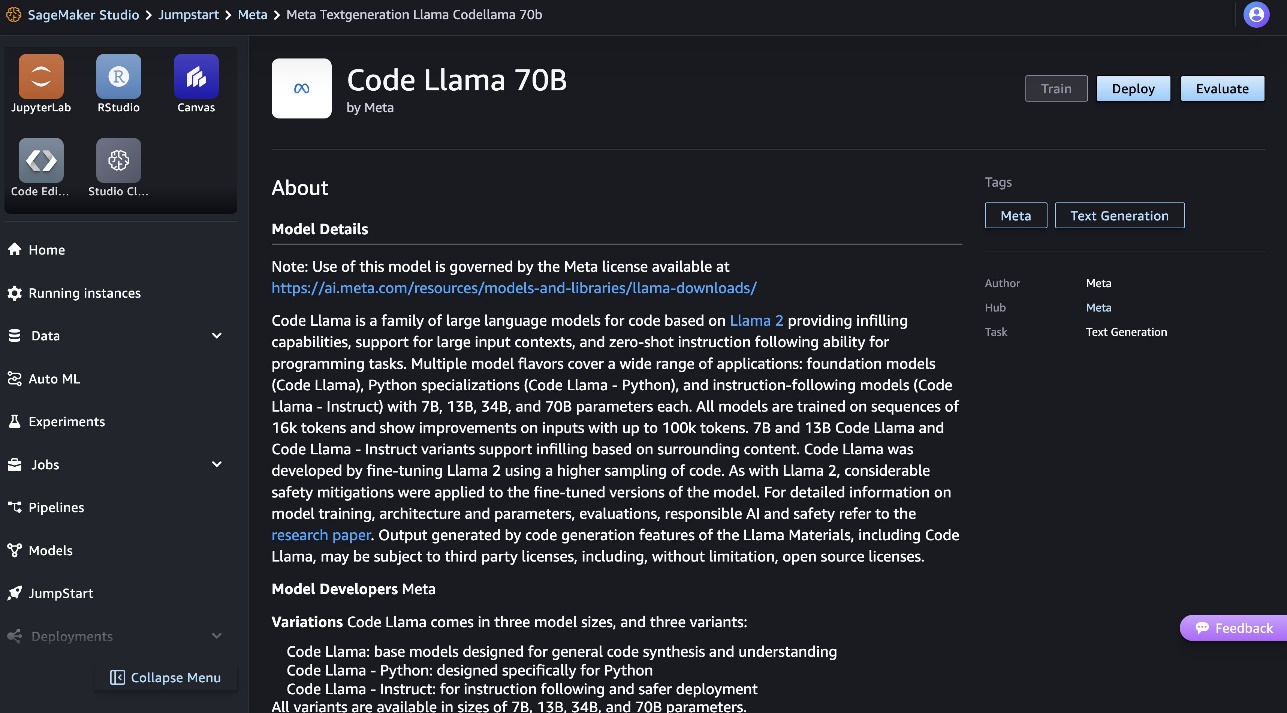
La siguiente captura de pantalla muestra la configuración del punto final. Puede cambiar las opciones o utilizar las predeterminadas.
- Acepte el Acuerdo de licencia de usuario final (EULA) y elija Despliegue.
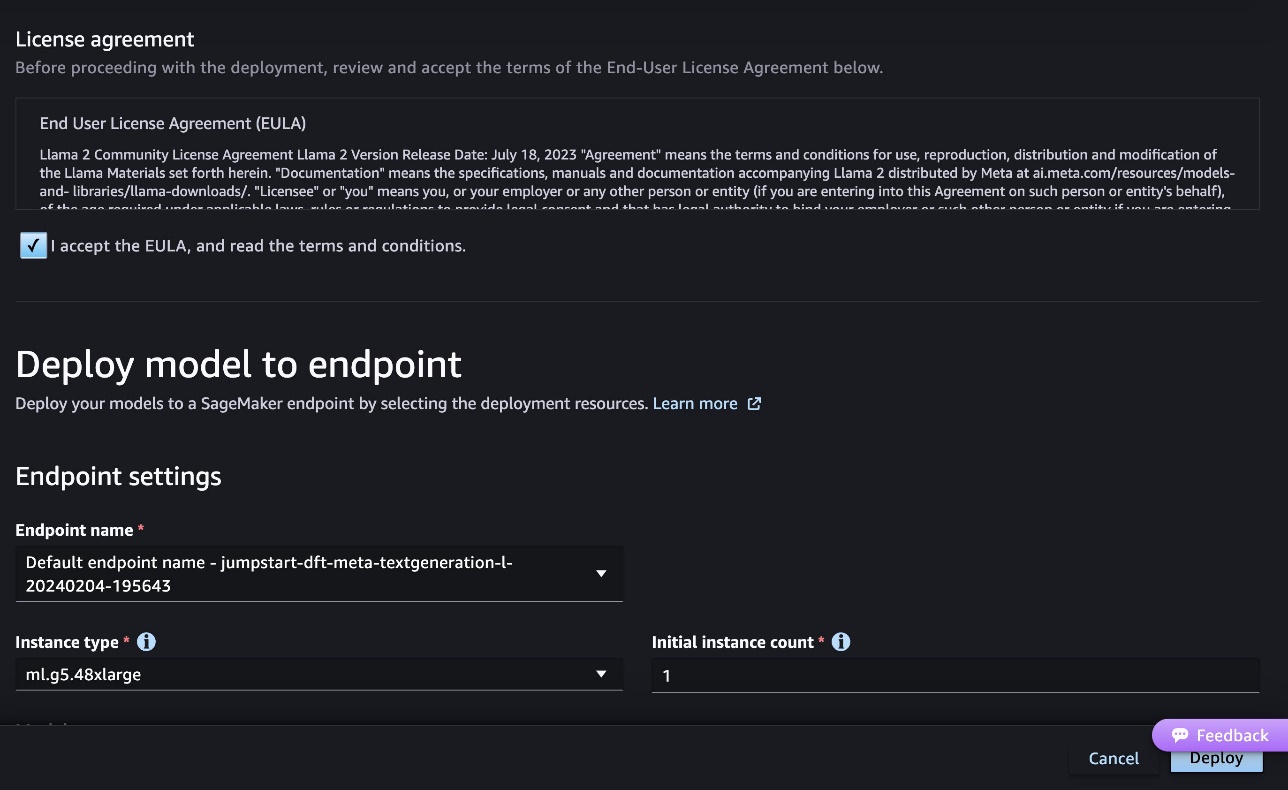
Esto iniciará el proceso de implementación del punto final, como se muestra en la siguiente captura de pantalla.
Implementar el modelo con SageMaker Python SDK
Alternativamente, puede implementar a través del cuaderno de ejemplo eligiendo cuaderno abierto dentro de la página de detalles del modelo de Classic Studio. El cuaderno de ejemplo proporciona orientación integral sobre cómo implementar el modelo para inferencia y limpieza de recursos.
Para implementar usando el portátil, comenzamos seleccionando un modelo apropiado, especificado por el model_id. Puede implementar cualquiera de los modelos seleccionados en SageMaker con el siguiente código:
Esto implementa el modelo en SageMaker con configuraciones predeterminadas, incluido el tipo de instancia predeterminado y las configuraciones de VPC predeterminadas. Puede cambiar estas configuraciones especificando valores no predeterminados en JumpStartModelo. Tenga en cuenta que, de forma predeterminada, accept_eula se establece a False. Necesitas configurar accept_eula=True para implementar el punto final con éxito. Al hacerlo, acepta el acuerdo de licencia de usuario y la política de uso aceptable como se mencionó anteriormente. Tú también puedes descargar el acuerdo de licencia.
Invocar un punto final de SageMaker
Una vez implementado el punto final, puede realizar inferencias utilizando Boto3 o SageMaker Python SDK. En el siguiente código, utilizamos el SDK de Python de SageMaker para llamar al modelo para realizar inferencia e imprimir la respuesta:
La función print_response toma una carga útil que consta de la carga útil y la respuesta del modelo e imprime la salida. Code Llama admite muchos parámetros mientras realiza la inferencia:
- longitud máxima – El modelo genera texto hasta que la longitud de salida (que incluye la longitud del contexto de entrada) alcanza
max_length. Si se especifica, debe ser un entero positivo. - max_new_tokens – El modelo genera texto hasta que la longitud de salida (excluyendo la longitud del contexto de entrada) alcanza
max_new_tokens. Si se especifica, debe ser un entero positivo. - num_vigas – Esto especifica el número de haces utilizados en la búsqueda codiciosa. Si se especifica, debe ser un número entero mayor o igual a
num_return_sequences. - no_repeat_ngram_size – El modelo asegura que una secuencia de palabras de
no_repeat_ngram_sizeno se repite en la secuencia de salida. Si se especifica, debe ser un entero positivo mayor que 1. - temperatura – Esto controla la aleatoriedad en la salida. Más alto
temperatureda como resultado una secuencia de salida con palabras de baja probabilidad y menortemperatureda como resultado una secuencia de salida con palabras de alta probabilidad. Sitemperaturees 0, da como resultado una decodificación codiciosa. Si se especifica, debe ser un valor flotante positivo. - parada_temprana - Si
True, la generación de texto finaliza cuando todas las hipótesis de haz llegan al final del token de oración. Si se especifica, debe ser booleano. - hacer_muestra - Si
True, el modelo muestra la siguiente palabra según la probabilidad. Si se especifica, debe ser booleano. - top_k – En cada paso de la generación de texto, el modelo toma muestras solo de los
top_kpalabras más probables. Si se especifica, debe ser un entero positivo. - arriba_p – En cada paso de la generación de texto, el modelo toma muestras del conjunto más pequeño posible de palabras con probabilidad acumulativa.
top_p. Si se especifica, debe ser un valor flotante entre 0 y 1. - retorno_texto_completo - Si
True, el texto de entrada será parte del texto generado de salida. Si se especifica, debe ser booleano. El valor predeterminado para ello esFalse. - detener – Si se especifica, debe ser una lista de cadenas. La generación de texto se detiene si se genera cualquiera de las cadenas especificadas.
Puede especificar cualquier subconjunto de estos parámetros al invocar un punto final. A continuación, mostramos un ejemplo de cómo invocar un punto final con estos argumentos.
Completar código
Los siguientes ejemplos demuestran cómo realizar la finalización de código donde la respuesta esperada del punto final es la continuación natural del mensaje.
Primero ejecutamos el siguiente código:
Obtenemos el siguiente resultado:
Para nuestro siguiente ejemplo, ejecutamos el siguiente código:
Obtenemos el siguiente resultado:
Codigo de GENERACION
Los siguientes ejemplos muestran la generación de código Python usando Code Llama.
Primero ejecutamos el siguiente código:
Obtenemos el siguiente resultado:
Para nuestro siguiente ejemplo, ejecutamos el siguiente código:
Obtenemos el siguiente resultado:
Estos son algunos de los ejemplos de tareas relacionadas con el código que utilizan Code Llama 70B. Puede utilizar el modelo para generar código aún más complicado. ¡Le animamos a que lo pruebe utilizando sus propios casos de uso y ejemplos relacionados con el código!
Limpiar
Después de haber probado los puntos finales, asegúrese de eliminar los puntos finales de inferencia de SageMaker y el modelo para evitar incurrir en cargos. Utilice el siguiente código:
Conclusión
En esta publicación, presentamos Code Llama 70B en SageMaker JumpStart. Code Llama 70B es un modelo de última generación para generar código a partir de indicaciones en lenguaje natural y código. Puede implementar el modelo con unos simples pasos en SageMaker JumpStart y luego usarlo para llevar a cabo tareas relacionadas con el código, como la generación y el relleno de código. Como siguiente paso, intente utilizar el modelo con sus propios casos de uso y datos relacionados con el código.
Sobre los autores
 Dr.Kyle Ulrich es un científico aplicado del equipo JumpStart de Amazon SageMaker. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
Dr.Kyle Ulrich es un científico aplicado del equipo JumpStart de Amazon SageMaker. Sus intereses de investigación incluyen algoritmos escalables de aprendizaje automático, visión artificial, series temporales, no paramétricos bayesianos y procesos gaussianos. Su doctorado es de la Universidad de Duke y ha publicado artículos en NeurIPS, Cell y Neuron.
 Dr. Farooq Sabir es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Tiene un doctorado y una maestría en ingeniería eléctrica de la Universidad de Texas en Austin y una maestría en informática del Instituto de Tecnología de Georgia. Tiene más de 15 años de experiencia laboral y también le gusta enseñar y asesorar a estudiantes universitarios. En AWS, ayuda a los clientes a formular y resolver sus problemas comerciales en ciencia de datos, aprendizaje automático, visión artificial, inteligencia artificial, optimización numérica y dominios relacionados. Con sede en Dallas, Texas, a él y a su familia les encanta viajar y hacer viajes largos por carretera.
Dr. Farooq Sabir es arquitecto sénior de soluciones especialista en inteligencia artificial y aprendizaje automático en AWS. Tiene un doctorado y una maestría en ingeniería eléctrica de la Universidad de Texas en Austin y una maestría en informática del Instituto de Tecnología de Georgia. Tiene más de 15 años de experiencia laboral y también le gusta enseñar y asesorar a estudiantes universitarios. En AWS, ayuda a los clientes a formular y resolver sus problemas comerciales en ciencia de datos, aprendizaje automático, visión artificial, inteligencia artificial, optimización numérica y dominios relacionados. Con sede en Dallas, Texas, a él y a su familia les encanta viajar y hacer viajes largos por carretera.
 junio ganó es gerente de producto en SageMaker JumpStart. Se enfoca en hacer que los modelos básicos sean fácilmente detectables y utilizables para ayudar a los clientes a crear aplicaciones de IA generativa. Su experiencia en Amazon también incluye la aplicación de compras móviles y la entrega de última milla.
junio ganó es gerente de producto en SageMaker JumpStart. Se enfoca en hacer que los modelos básicos sean fácilmente detectables y utilizables para ayudar a los clientes a crear aplicaciones de IA generativa. Su experiencia en Amazon también incluye la aplicación de compras móviles y la entrega de última milla.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/code-llama-70b-is-now-available-in-amazon-sagemaker-jumpstart/

