Datos no estructurados Es información que no se ajusta a un esquema predefinido o no está organizada según un modelo de datos preestablecido. La información no estructurada puede tener poca o mucha estructura, pero de manera inesperada o inconsistente. Texto, imágenes, audio y videos son ejemplos comunes de datos no estructurados. La mayoría de las empresas producen y consumen datos no estructurados, como documentos, correos electrónicos, páginas web, llamadas telefónicas al centro de participación y redes sociales. Según algunas estimaciones, los datos no estructurados pueden representar entre el 80% y el 90% de todos los datos empresariales nuevos y están creciendo muchas veces más rápido que los datos estructurados. Después de décadas de digitalizar todo en su empresa, es posible que tenga una enorme cantidad de datos, pero con un valor latente. Sin embargo, con la ayuda de la inteligencia artificial y el aprendizaje automático (ML), ahora hay nuevas herramientas de software disponibles para descubrir el valor de los datos no estructurados.
En esta publicación, analizamos cómo AWS puede ayudarlo a abordar con éxito los desafíos de extraer información a partir de datos no estructurados. Analizamos varios patrones de diseño y arquitecturas para extraer y catalogar información valiosa de datos no estructurados utilizando AWS. Además, mostramos cómo utilizar los servicios de IA/ML de AWS para analizar datos no estructurados.
Por qué es un desafío procesar y gestionar datos no estructurados
Los datos no estructurados constituyen una gran proporción de los datos de la empresa que no se pueden almacenar en un sistema de gestión de bases de datos relacionales (RDBMS) tradicional. Comprender los datos, categorizarlos, almacenarlos y extraer información de ellos puede resultar un desafío. Además, identificar cambios incrementales requiere patrones especializados y detectar datos confidenciales y cumplir con los requisitos de cumplimiento requiere funciones sofisticadas. Puede resultar difícil integrar datos no estructurados con datos estructurados de los sistemas de información existentes. Algunos ven los datos estructurados y no estructurados como manzanas y naranjas, en lugar de ser complementarios. Pero lo más importante de todo es que el supuesto valor latente de los datos no estructurados es un signo de interrogación que sólo puede responderse después de que se hayan aplicado estas sofisticadas técnicas. Por lo tanto, es necesario poder analizar y extraer valor de los datos de forma económica y flexible.
Resumen de la solución
El descubrimiento de datos y metadatos es uno de los requisitos principales en el análisis de datos, donde los consumidores de datos exploran qué datos están disponibles y en qué formato, y luego los consumen o consultan para su análisis. Si puede aplicar un esquema encima del conjunto de datos, entonces la consulta será sencilla porque puede cargar los datos en una base de datos o imponer un esquema de tabla virtual para realizar consultas. Pero en el caso de datos no estructurados, el descubrimiento de metadatos es un desafío porque los datos sin procesar no son fácilmente legibles.
Puede integrar diferentes tecnologías o herramientas para crear una solución. En esta publicación, explicamos cómo integrar diferentes servicios de AWS para proporcionar una solución de un extremo a otro que incluya extracción, administración y gobernanza de datos.
La solución integra datos en tres niveles. El primero son los datos de entrada sin procesar que son ingeridos por los sistemas de origen, el segundo son los datos de salida que se extraen de los datos de entrada mediante IA y el tercero es la capa de metadatos que mantiene una relación entre ellos para el descubrimiento de datos.
La siguiente es una arquitectura de alto nivel de la solución que podemos crear para procesar los datos no estructurados, suponiendo que los datos de entrada se ingieran en el almacén de objetos de entrada sin procesar.
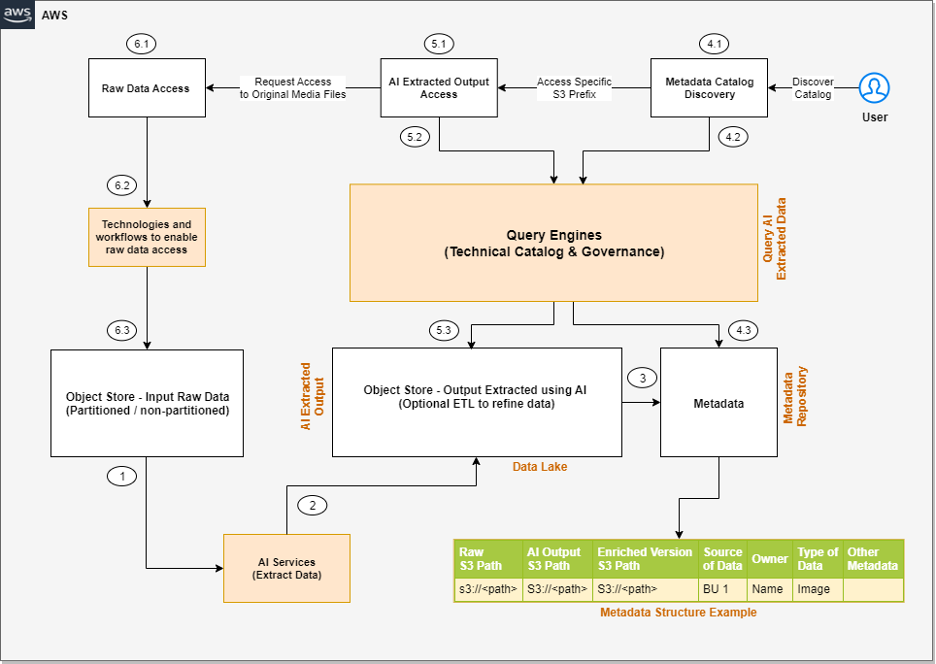
Los pasos del flujo de trabajo son los siguientes:
- Los servicios integrados de IA extraen datos de los datos no estructurados.
- Estos servicios escriben la salida en un lago de datos.
- Una capa de metadatos ayuda a construir la relación entre los datos sin procesar y los resultados extraídos por IA. Cuando los datos y metadatos estén disponibles para los usuarios finales, podemos dividir el patrón de acceso del usuario en pasos adicionales.
- En el paso de descubrimiento del catálogo de metadatos, podemos utilizar motores de consulta para acceder a los metadatos para su descubrimiento y aplicar filtros según nuestras necesidades analíticas. Luego pasamos a la siguiente etapa de acceder a los datos reales extraídos de los datos sin procesar no estructurados.
- El usuario final accede a la salida de los servicios de IA y utiliza los motores de consulta para consultar los datos estructurados disponibles en el lago de datos. Opcionalmente, podemos integrar herramientas adicionales que ayudan a controlar el acceso y proporcionar gobernanza.
- Puede haber escenarios en los que, después de acceder a la salida extraída por IA, el usuario final quiera acceder al objeto original sin procesar (como archivos multimedia) para un análisis más detallado. Además, debemos asegurarnos de tener políticas de control de acceso para que el usuario final tenga acceso solo a los datos sin procesar respectivos a los que desea acceder.
Ahora que entendemos la arquitectura de alto nivel, analicemos qué servicios de AWS podemos integrar en cada paso de la arquitectura para proporcionar una solución de un extremo a otro.
El siguiente diagrama es la versión mejorada de nuestra arquitectura de solución, donde hemos integrado los servicios de AWS.
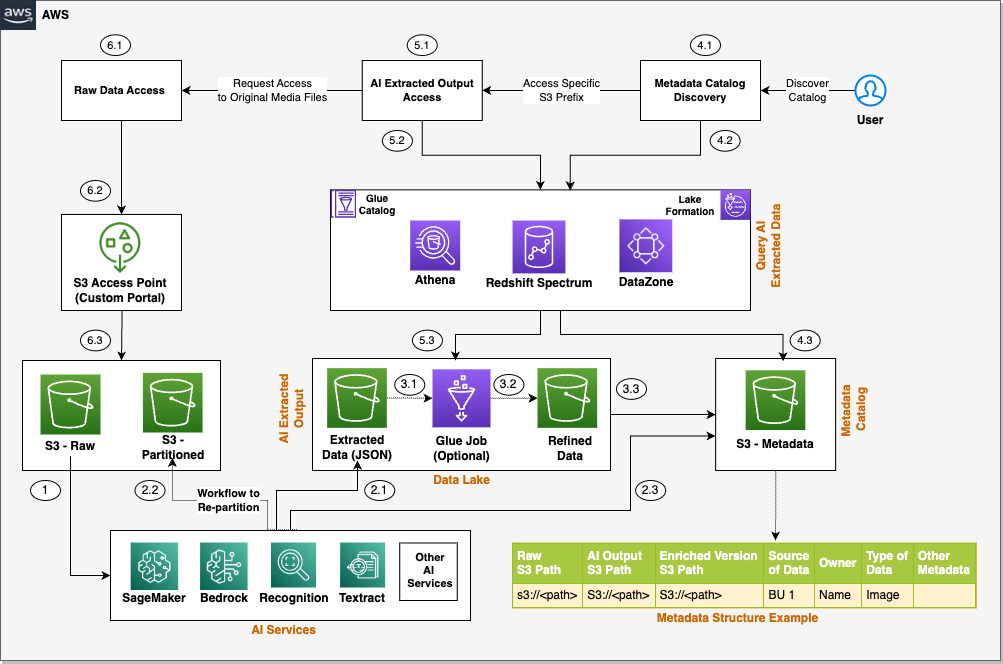
Comprendamos en detalle cómo se integran estos servicios de AWS. Hemos dividido los pasos en dos flujos amplios de usuarios: procesamiento de datos y enriquecimiento de metadatos (pasos 1 a 3) y usuarios finales que acceden a los datos y metadatos con un control de acceso detallado (pasos 4 a 6).
- Varios servicios de IA (que analizaremos en la siguiente sección) extraen datos de conjuntos de datos no estructurados.
- La salida se escribe en un Servicio de almacenamiento simple de Amazon (Amazon S3) (etiquetado como JSON extraído en el diagrama anterior). Opcionalmente, podemos reestructurar los objetos sin procesar de entrada para una mejor partición, lo que puede ayudar al implementar un control de acceso detallado en los datos de entrada sin procesar (etiquetados como depósito particionado en el diagrama).
- Después de la fase inicial de extracción de datos, podemos aplicar transformaciones adicionales para enriquecer los conjuntos de datos utilizando Pegamento AWS. También creamos una capa de metadatos adicional, que mantiene una relación entre la ruta del objeto S3 sin procesar, la ruta de salida extraída por IA, la ruta S3 de la versión enriquecida opcional y cualquier otro metadato que ayude al usuario final a descubrir los datos.
- En el paso de descubrimiento del catálogo de metadatos, utilizamos el catálogo de datos de AWS Glue como catálogo técnico. Atenea amazónica y Espectro de Redshift de Amazon como motores de consulta, Formación del lago AWS para un control de acceso detallado y Zona de datos de Amazon para una gobernanza adicional.
- Se espera que el resultado extraído por IA esté disponible como un archivo delimitado o en formato JSON. Podemos crear una tabla del catálogo de datos de AWS Glue para realizar consultas utilizando Athena o Redshift Spectrum. Al igual que en el paso anterior, podemos utilizar las políticas de Lake Formation para un control de acceso detallado.
- Por último, el usuario final accede a los datos sin procesar no estructurados disponibles en Amazon S3 para su posterior análisis. Hemos propuesto integrar Puntos de acceso de Amazon S3 para el control de acceso en esta capa. Explicamos esto en detalle más adelante en esta publicación.
Ahora ampliemos las siguientes partes de la arquitectura para comprender mejor la implementación:
- Uso de los servicios de IA de AWS para procesar datos no estructurados
- Uso de puntos de acceso S3 para integrar el control de acceso en datos no estructurados de S3 sin procesar
Procese datos no estructurados con los servicios de IA de AWS
Como comentamos anteriormente, los datos no estructurados pueden venir en una variedad de formatos, como texto, audio, video e imágenes, y cada tipo de datos requiere un enfoque diferente para extraer metadatos. Los servicios de IA de AWS están diseñados para extraer metadatos de diferentes tipos de datos no estructurados. Los siguientes son los servicios más utilizados para el procesamiento de datos no estructurados:
- Amazon Comprehend – Este servicio de procesamiento de lenguaje natural (NLP) utiliza ML para extraer metadatos de datos de texto. Puede analizar texto en varios idiomas, detectar entidades, extraer frases clave, determinar opiniones y más. Con Amazon Comprehend, puede obtener fácilmente información a partir de grandes volúmenes de datos de texto, como extraer la entidad del producto, el nombre del cliente y la opinión de publicaciones en las redes sociales.
- Amazon Transcribe – Este servicio de voz a texto utiliza ML para convertir voz en texto y extraer metadatos de datos de audio. Puede reconocer varios hablantes, transcribir conversaciones, identificar palabras clave y más. Con Amazon Transcribe, puede convertir datos no estructurados, como grabaciones de atención al cliente, en texto y obtener más información a partir de ellos.
- Reconocimiento de amazonas – Este servicio de análisis de imágenes y videos utiliza ML para extraer metadatos de datos visuales. Puede reconocer objetos, personas, rostros y texto, detectar contenido inapropiado y más. Con Amazon Rekognition, puede analizar fácilmente imágenes y vídeos para obtener información valiosa, como identificar el tipo de entidad (humana u otra) e identificar si la persona es una celebridad conocida en una imagen.
- Amazon Textil – Puede utilizar este servicio de ML para extraer metadatos de documentos e imágenes escaneados. Puede extraer texto, tablas y formularios de imágenes, archivos PDF y documentos escaneados. Con Amazon Textract, puede digitalizar documentos y extraer datos como el nombre del cliente, el nombre del producto, el precio del producto y la fecha de una factura.
- Amazon SageMaker – Este servicio le permite crear e implementar modelos de aprendizaje automático personalizados para una amplia gama de casos de uso, incluida la extracción de metadatos de datos no estructurados. Con SageMaker, puede crear modelos personalizados que se adapten a sus necesidades específicas, lo que puede resultar particularmente útil para extraer metadatos de datos no estructurados que requieren un alto grado de precisión o conocimiento de un dominio específico.
- lecho rocoso del amazonas – Este servicio totalmente administrado ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial como AI21 Labs, Anthropic, Cohere, Meta, Stability AI y Amazon con una única API. También ofrece un amplio conjunto de capacidades para crear aplicaciones de IA generativa, simplificando el desarrollo y manteniendo la privacidad y la seguridad.
Con estos servicios de IA especializados, puede extraer metadatos de manera eficiente a partir de datos no estructurados y utilizarlos para análisis e información adicionales. Es importante tener en cuenta que cada servicio tiene sus propias fortalezas y limitaciones, y elegir el servicio adecuado para su caso de uso específico es fundamental para lograr resultados precisos y confiables.
Los servicios de IA de AWS están disponibles a través de varias API, lo que le permite integrar capacidades de IA en sus aplicaciones y flujos de trabajo. Funciones de paso de AWS es un servicio de flujo de trabajo sin servidor que le permite coordinar y orquestar múltiples servicios de AWS, incluidos los servicios de IA, en un único flujo de trabajo. Esto puede resultar especialmente útil cuando necesita procesar grandes cantidades de datos no estructurados y realizar múltiples tareas relacionadas con la IA, como análisis de texto, reconocimiento de imágenes y PNL.
Con funciones escalonadas y AWS Lambda funciones, puede crear flujos de trabajo sofisticados que incluyan servicios de IA y otros servicios de AWS. Por ejemplo, puede utilizar Amazon S3 para almacenar datos de entrada, invocar una función Lambda para activar un trabajo de Amazon Transcribe para transcribir un archivo de audio y utilizar el resultado para activar un trabajo de análisis de Amazon Comprehend para generar metadatos de opinión para el texto transcrito. Esto le permite crear flujos de trabajo complejos de varios pasos que son fáciles de administrar, escalables y rentables.
A continuación se muestra un ejemplo de arquitectura que muestra cómo Step Functions puede ayudar a invocar servicios de IA de AWS mediante funciones Lambda.
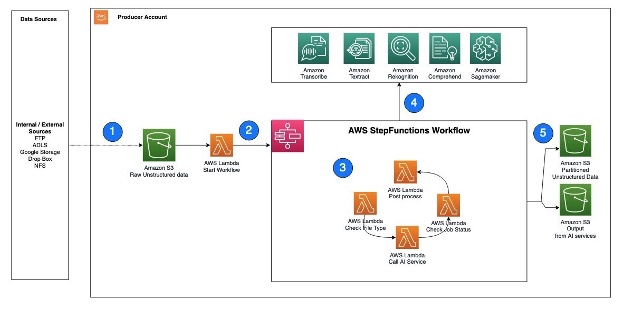
Los pasos del flujo de trabajo son los siguientes:
- Los datos no estructurados, como archivos de texto, archivos de audio y archivos de video, se incorporan al depósito sin formato de S3.
- Se activa una función Lambda para leer los datos del depósito S3 y llamar a Step Functions para organizar el flujo de trabajo necesario para extraer los metadatos.
- El flujo de trabajo de Step Functions comprueba el tipo de archivo, llama a las API del servicio de IA de AWS correspondientes, comprueba el estado del trabajo y realiza el posprocesamiento necesario en la salida.
- Se puede acceder a los servicios de IA de AWS a través de API e invocarlos como trabajos por lotes. Para extraer metadatos de diferentes tipos de datos no estructurados, puede utilizar varios servicios de IA en secuencia, y cada servicio procesa el tipo de archivo correspondiente.
- Una vez que el flujo de trabajo de Step Functions completa el proceso de extracción de metadatos y realiza el posprocesamiento necesario, el resultado resultante se almacena en un depósito de S3 para catalogarlo.
A continuación, comprendamos cómo podemos implementar seguridad o control de acceso tanto en la salida extraída como en los objetos de entrada sin procesar.
Implementar control de acceso a datos sin procesar y procesados en Amazon S3
Solo consideramos controles de acceso para tres tipos de datos cuando administramos datos no estructurados: la salida semiestructurada extraída por IA, los metadatos y los archivos originales no estructurados sin procesar. Cuando se trata de resultados extraídos por IA, están en formato JSON y se pueden restringir a través de Lake Formation y Amazon DataZone. Recomendamos mantener los metadatos (información que captura qué conjuntos de datos no estructurados ya están procesados por la canalización y disponibles para análisis) abiertos a su organización, lo que permitirá el descubrimiento de metadatos en toda la organización.
Para controlar el acceso a datos sin procesar no estructurados, puede integrar puntos de acceso S3 y explorar soporte adicional en el futuro a medida que evolucionen los servicios de AWS. Los puntos de acceso S3 simplifican el acceso a los datos para cualquier servicio de AWS o aplicación de cliente que almacene datos en Amazon S3. Los puntos de acceso son puntos finales de red con nombre que están conectados a depósitos que puede utilizar para realizar operaciones de objetos de S3. Cada punto de acceso tiene distintos permisos y controles de red que Amazon S3 aplica para cualquier solicitud que se realice a través de ese punto de acceso. Cada punto de acceso aplica una política de punto de acceso personalizada que funciona junto con la política de depósito adjunta al depósito subyacente. Con los puntos de acceso de S3, puede crear políticas de control de acceso únicas para cada punto de acceso para controlar fácilmente el acceso a conjuntos de datos específicos dentro de un depósito de S3. Esto funciona bien en escenarios de depósitos compartidos o de múltiples inquilinos donde a los usuarios o equipos se les asignan prefijos únicos dentro de un depósito de S3.
Un punto de acceso puede admitir un único usuario o aplicación, o grupos de usuarios o aplicaciones dentro y entre cuentas, lo que permite una gestión separada de cada punto de acceso. Cada punto de acceso está asociado con un único depósito y contiene un control de origen de red y un control de bloqueo de acceso público. Por ejemplo, puede crear un punto de acceso con un control de origen de red que solo permita el acceso al almacenamiento desde su nube privada virtual (VPC), una sección lógicamente aislada de la nube de AWS. También puede crear un punto de acceso con la política de punto de acceso configurada para permitir solo el acceso a objetos con un prefijo definido o a objetos con etiquetas específicas. También puede configurar ajustes personalizados de Bloquear acceso público para cada punto de acceso.
La siguiente arquitectura proporciona una descripción general de cómo un usuario final puede obtener acceso a objetos S3 específicos asumiendo una configuración específica. Gestión de identidades y accesos de AWS (IAM) función. Si tiene una gran cantidad de objetos S3 para controlar el acceso, considere agrupar los objetos S3, asignarles etiquetas y luego definir el control de acceso por etiquetas.
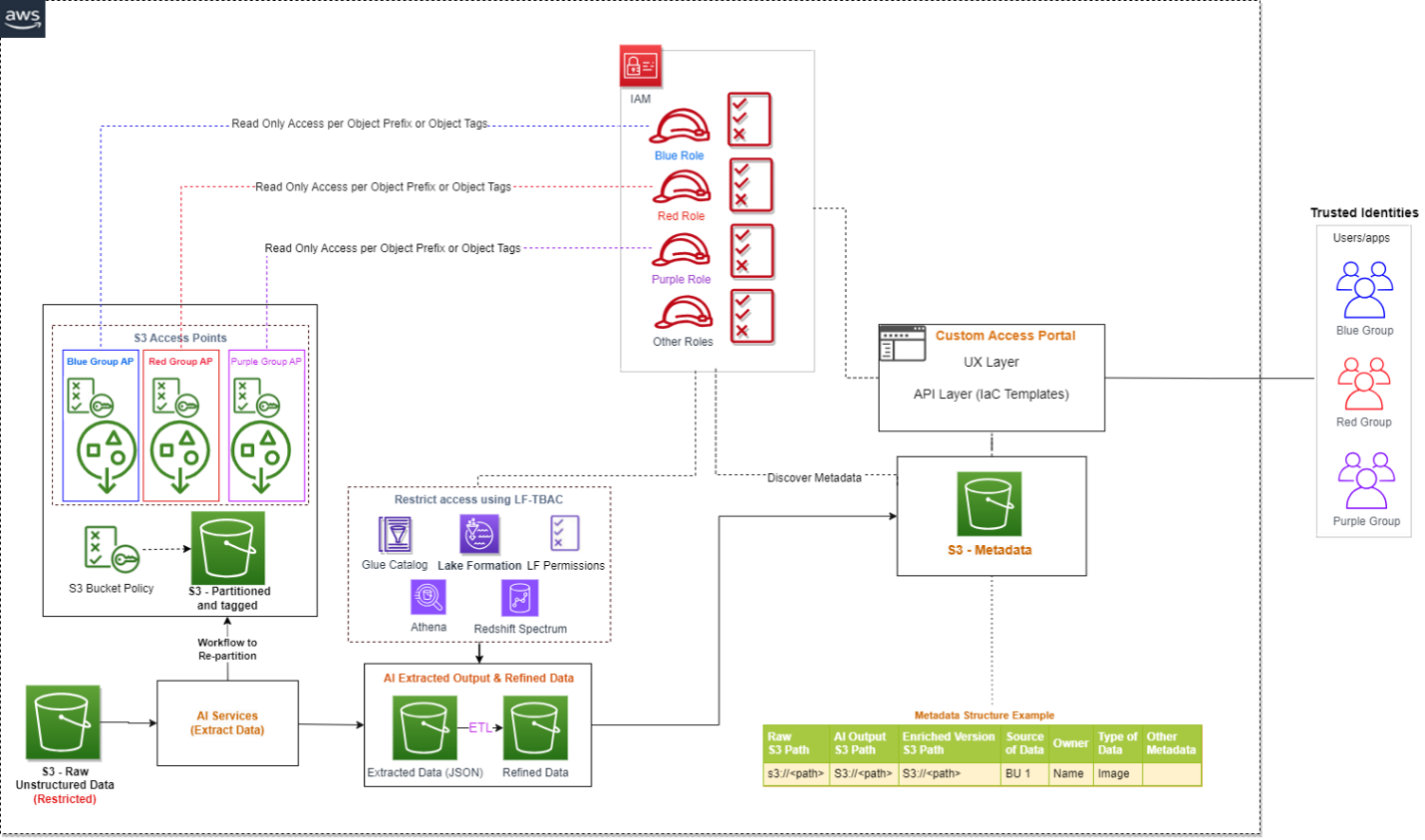
Si está implementando una solución que integra datos de S3 disponibles en varias cuentas de AWS, puede aprovechar soporte entre cuentas para puntos de acceso S3.
Conclusión
Esta publicación explica cómo puede utilizar los servicios de IA de AWS para extraer datos legibles de conjuntos de datos no estructurados, crear una capa de metadatos sobre ellos para permitir el descubrimiento de datos y crear un mecanismo de control de acceso sobre los objetos S3 sin procesar y los datos extraídos utilizando Lake Formation. , Amazon DataZone y puntos de acceso S3.
Además de los servicios de IA de AWS, también puede integrar modelos de lenguaje grandes con bases de datos vectoriales para permitir la búsqueda semántica o de similitudes sobre conjuntos de datos no estructurados. Para obtener más información sobre cómo habilitar la búsqueda semántica en datos no estructurados mediante la integración Servicio Amazon OpenSearch como base de datos vectorial, consulte Pruebe la búsqueda semántica con el motor vectorial de Amazon OpenSearch Service.
Al momento de escribir esta publicación, los puntos de acceso S3 son una de las mejores soluciones para implementar el control de acceso en objetos S3 sin formato mediante etiquetado, pero a medida que las características del servicio de AWS evolucionen en el futuro, también puede explorar opciones alternativas.
Acerca de los autores
 Sakti Mishra es arquitecto principal de soluciones en AWS, donde ayuda a los clientes a modernizar su arquitectura de datos y definir su estrategia de datos de un extremo a otro, incluida la seguridad de los datos, la accesibilidad, la gobernanza y más. También es el autor del libro. Simplifique el análisis de Big Data con Amazon EMR. Fuera del trabajo, a Sakti le gusta aprender nuevas tecnologías, ver películas y visitar lugares con la familia.
Sakti Mishra es arquitecto principal de soluciones en AWS, donde ayuda a los clientes a modernizar su arquitectura de datos y definir su estrategia de datos de un extremo a otro, incluida la seguridad de los datos, la accesibilidad, la gobernanza y más. También es el autor del libro. Simplifique el análisis de Big Data con Amazon EMR. Fuera del trabajo, a Sakti le gusta aprender nuevas tecnologías, ver películas y visitar lugares con la familia.
 Bhavana Chirumamilla es un arquitecto residente sénior en AWS con una gran pasión por las operaciones de datos y aprendizaje automático. Ella aporta una gran experiencia y entusiasmo para ayudar a las empresas a crear datos efectivos y estrategias de ML. En su tiempo libre, a Bhavana le gusta pasar tiempo con su familia y participar en diversas actividades, como viajar, hacer caminatas, hacer jardinería y mirar documentales.
Bhavana Chirumamilla es un arquitecto residente sénior en AWS con una gran pasión por las operaciones de datos y aprendizaje automático. Ella aporta una gran experiencia y entusiasmo para ayudar a las empresas a crear datos efectivos y estrategias de ML. En su tiempo libre, a Bhavana le gusta pasar tiempo con su familia y participar en diversas actividades, como viajar, hacer caminatas, hacer jardinería y mirar documentales.
 Sheela Sonone es arquitecto residente sénior en AWS. Ayuda a los clientes de AWS a tomar decisiones informadas y hacer concesiones sobre la aceleración de sus cargas de trabajo e implementaciones de datos, análisis y AI/ML. En su tiempo libre, le gusta pasar tiempo con su familia, normalmente en las canchas de tenis.
Sheela Sonone es arquitecto residente sénior en AWS. Ayuda a los clientes de AWS a tomar decisiones informadas y hacer concesiones sobre la aceleración de sus cargas de trabajo e implementaciones de datos, análisis y AI/ML. En su tiempo libre, le gusta pasar tiempo con su familia, normalmente en las canchas de tenis.
 Daniel Bruno es arquitecto residente principal en AWS. Lleva más de 20 años creando soluciones de análisis y aprendizaje automático y divide su tiempo ayudando a los clientes a crear programas de ciencia de datos y diseñando productos de aprendizaje automático impactantes.
Daniel Bruno es arquitecto residente principal en AWS. Lleva más de 20 años creando soluciones de análisis y aprendizaje automático y divide su tiempo ayudando a los clientes a crear programas de ciencia de datos y diseñando productos de aprendizaje automático impactantes.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/unstructured-data-management-and-governance-using-aws-ai-ml-and-analytics-services/

