Los datos son su diferenciador generativo de IA y una solución exitosa IA generativa La implementación depende de una estrategia de datos sólida que incorpore un análisis integral. el gobierno de datos acercarse. Trabajar con grandes modelos de lenguaje (LLM) para casos de uso empresarial requiere la implementación de consideraciones de calidad y privacidad para impulsar una IA responsable. Sin embargo, los datos empresariales generados a partir de fuentes aisladas, combinados con la falta de una estrategia de integración de datos, crean desafíos para el aprovisionamiento de datos para aplicaciones de IA generativa. La necesidad de un extremo a extremo estrategia para la gestión de datos y la gobernanza de datos en cada paso del viaje, desde la ingesta, el almacenamiento y la consulta de datos hasta el análisis, la visualización y la ejecución de modelos de inteligencia artificial (IA) y aprendizaje automático (ML), sigue siendo de suma importancia para las empresas.
En esta publicación, analizamos las necesidades de gobernanza de datos de los canales de datos de aplicaciones de IA generativa, un componente fundamental para gobernar los datos utilizados por los LLM para mejorar la precisión y relevancia de sus respuestas a las indicaciones de los usuarios de una manera segura y transparente. Las empresas están haciendo esto mediante el uso de datos patentados con enfoques como la generación aumentada de recuperación (RAG), el ajuste y la capacitación previa continua con modelos básicos.
La gobernanza de datos es un componente fundamental de todos estos enfoques, y vemos dos áreas de enfoque emergentes. En primer lugar, muchos casos de uso de LLM se basan en conocimiento empresarial que debe extraerse de datos no estructurados, como documentos, transcripciones e imágenes, además de datos estructurados de almacenes de datos. Los datos no estructurados generalmente se almacenan en sistemas aislados en distintos formatos y, por lo general, no se administran ni gobiernan con el mismo nivel de rigor que los datos estructurados. En segundo lugar, las aplicaciones de IA generativa introducen una mayor cantidad de interacciones de datos que las aplicaciones convencionales, lo que requiere que las políticas de control de acceso, privacidad y seguridad de los datos se implementen como parte de los flujos de trabajo de los usuarios de IA generativa.
En esta publicación, cubrimos la gobernanza de datos para crear aplicaciones de IA generativa en AWS con una perspectiva sobre las fuentes de conocimiento empresarial estructuradas y no estructuradas, y el papel de la gobernanza de datos durante los flujos de trabajo de solicitud-respuesta del usuario.
Resumen del caso de uso
Exploremos un ejemplo de un asistente de IA de atención al cliente. La siguiente figura muestra el flujo de trabajo conversacional típico que se inicia con un mensaje de usuario.

El flujo de trabajo incluye los siguientes pasos clave de gobernanza de datos:
- Solicitar políticas de seguridad y control de acceso de usuarios.
- Acceda a políticas para extraer permisos basados en datos relevantes y filtrar resultados según la función y los permisos del usuario solicitado.
- Haga cumplir las políticas de privacidad de datos, como la redacción de información de identificación personal (PII).
- Aplique un control de acceso detallado.
- Otorgue permisos de rol de usuario para información confidencial y políticas de cumplimiento.
Para proporcionar una respuesta que incluya el contexto empresarial, cada mensaje de usuario debe complementarse con una combinación de información procedente de datos estructurados del almacén de datos y datos no estructurados del lago de datos empresarial. En el backend, los procesos de ingeniería de datos por lotes que actualizan el lago de datos empresariales deben expandirse para ingerir, transformar y administrar datos no estructurados. Como parte de la transformación, los objetos deben tratarse para garantizar la privacidad de los datos (por ejemplo, redacción de PII). Finalmente, las políticas de control de acceso también deben extenderse a los objetos de datos no estructurados y a almacenes de datos vectoriales.
Veamos cómo se puede aplicar la gobernanza de datos a los canales de datos de fuentes de conocimiento empresarial y a los flujos de trabajo de solicitud-respuesta del usuario.
Conocimiento empresarial: gestión de datos
La siguiente figura resume las consideraciones de gobernanza de datos para canalizaciones de datos y el flujo de trabajo para aplicar la gobernanza de datos.
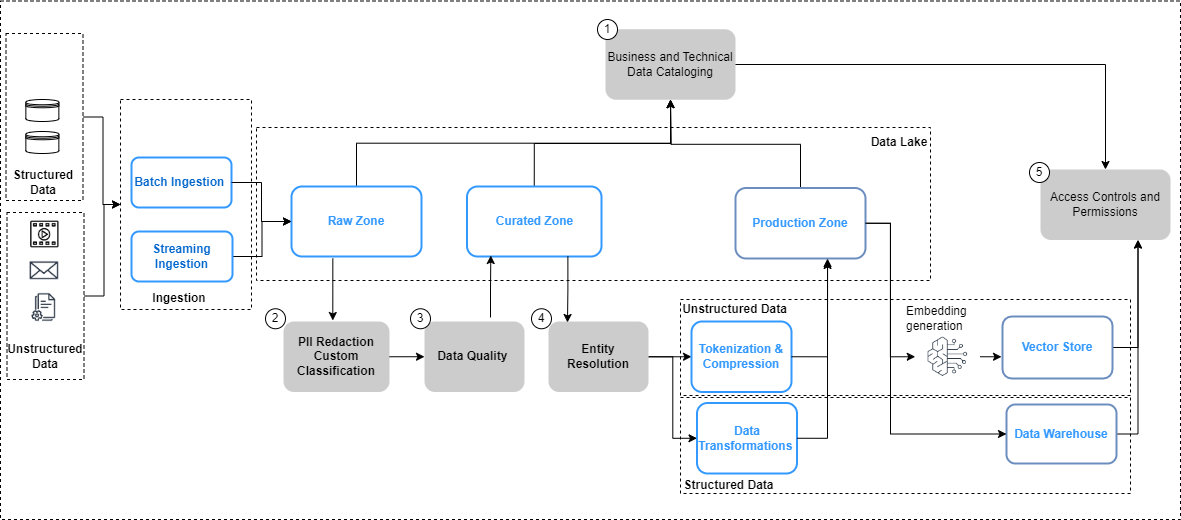
En la figura anterior, los procesos de ingeniería de datos incluyen los siguientes pasos de gobernanza de datos:
- Crear y actualizar un catálogo a través de la evolución de datos.
- Implementar políticas de privacidad de datos.
- Implementar la calidad de los datos por tipo de datos y fuente.
- Vincular conjuntos de datos estructurados y no estructurados.
- Implemente controles de acceso unificados y detallados para conjuntos de datos estructurados y no estructurados.
Veamos con más detalle algunos de los cambios clave en las canalizaciones de datos, a saber, la catalogación de datos, la calidad de los datos y la seguridad de la incorporación de vectores.
Descubrimiento de datos
A diferencia de los datos estructurados, que se gestionan en filas y columnas bien definidas, los datos no estructurados se almacenan como objetos. Para que los usuarios puedan descubrir y comprender los datos, el primer paso es crear un catálogo completo utilizando los metadatos que se generan y capturan en los sistemas de origen. Esto comienza con la ingesta de los objetos (como documentos y archivos de transcripción) de los sistemas de origen relevantes en la zona sin formato del archivo. datos in Servicio de almacenamiento simple de Amazon (Amazon S3) en sus respectivos formatos nativos (como se ilustra en la figura anterior). A partir de aquí, los metadatos del objeto (como el propietario del archivo, la fecha de creación y el nivel de confidencialidad) son extraído y consultado utilizando las capacidades de Amazon S3. Los metadatos pueden variar según la fuente de datos y es importante examinar los campos y, cuando sea necesario, derivar los campos necesarios para completar todos los metadatos necesarios. Por ejemplo, si un atributo como la confidencialidad del contenido no está etiquetado a nivel de documento en la aplicación de origen, es posible que sea necesario derivarlo como parte del proceso de extracción de metadatos y agregarlo como un atributo en el catálogo de datos. El proceso de ingesta necesita capturar actualizaciones de objetos (cambios, eliminaciones) además de objetos nuevos de forma continua. Para obtener una guía de implementación detallada, consulte Gestión y gobierno de datos no estructurados utilizando servicios de análisis y AI/ML de AWS. Para simplificar aún más el descubrimiento y la introspección entre glosarios empresariales y catálogos de datos técnicos, puede utilizar Zona de datos de Amazon para que los usuarios empresariales descubran y compartan datos almacenados en silos de datos.
Privacidad de datos
Las fuentes de conocimiento empresarial a menudo contienen PII y otros datos confidenciales (como direcciones y números de Seguro Social). Según sus políticas de privacidad de datos, estos elementos deben tratarse (enmascararse, tokenizarse o redactarse) desde las fuentes antes de que puedan usarse para casos de uso posteriores. Desde la zona sin procesar en Amazon S3, los objetos deben procesarse antes de que puedan ser consumidos por los modelos de IA generativos posteriores. Un requisito clave aquí es Identificación y redacción de PII, que puedes implementar con Amazon Comprehend. Es importante recordar que no siempre será factible eliminar todos los datos confidenciales sin afectar el contexto de los datos. Contexto semántico es uno de los factores clave que impulsan la precisión y relevancia de los resultados del modelo de IA generativa, y es fundamental trabajar hacia atrás desde el caso de uso y lograr el equilibrio necesario entre los controles de privacidad y el rendimiento del modelo.
Enriquecimiento de datos
Además, es posible que sea necesario extraer metadatos adicionales de los objetos. Amazon Comprehend proporciona capacidades para reconocimiento de entidad (por ejemplo, identificar datos específicos del dominio, como números de póliza y números de reclamo) y clasificación personalizada (por ejemplo, categorizar una transcripción de un chat de atención al cliente según la descripción del problema). Además, es posible que deba combinar los datos estructurados y no estructurados para crear una imagen holística de entidades clave, como los clientes. Por ejemplo, en un escenario de lealtad de una aerolínea, sería muy valioso vincular la captura de datos no estructurados de las interacciones con los clientes (como transcripciones de chats de clientes y reseñas de clientes) con señales de datos estructurados (como compras de boletos y canje de millas) para crear un escenario más completo. perfil del cliente que luego puede permitir la entrega de recomendaciones de viaje mejores y más relevantes. Resolución de entidad de AWS es un servicio de ML que ayuda a hacer coincidir y vincular registros. Este servicio ayuda a vincular conjuntos de información relacionados para crear datos más profundos y conectados sobre entidades clave como clientes, productos, etc., lo que puede mejorar aún más la calidad y relevancia de los resultados de LLM. Está disponible en la zona transformada de Amazon S3 y está listo para consumirse posteriormente para almacenes de vectores, ajustes o capacitación de LLM. Después de estas transformaciones, los datos pueden estar disponibles en la zona seleccionada en Amazon S3.
Calidad de datos
Un factor crítico para aprovechar todo el potencial de la IA generativa depende de la calidad de los datos que se utilizan para entrenar los modelos, así como de los datos que se utilizan para aumentar y mejorar la respuesta del modelo a una entrada del usuario. Comprender los modelos y sus resultados en el contexto de precisión, sesgo y confiabilidad es directamente proporcional a la calidad de los datos utilizados para construir y entrenar los modelos.
Monitor de modelo de Amazon SageMaker proporciona una detección proactiva de desviaciones en la deriva de la calidad de los datos del modelo y la deriva de las métricas de calidad del modelo. También monitorea la desviación del sesgo en las predicciones de su modelo y la atribución de características. Para obtener más detalles, consulte Supervisión de modelos de aprendizaje automático en producción a gran escala con Amazon SageMaker Model Monitor. Detectar sesgos en su modelo es un elemento fundamental para una IA responsable, y Amazon SageMaker aclarar ayuda a detectar posibles sesgos que pueden producir un resultado negativo o menos preciso. Para obtener más información, consulte Descubra cómo Amazon SageMaker Clarify ayuda a detectar sesgos.
Un área de enfoque más nueva en la IA generativa es el uso y la calidad de los datos en las solicitudes de los almacenes de datos empresariales y propietarios. Una mejor práctica emergente a considerar aquí es desplazamiento a la izquierda, que pone un fuerte énfasis en mecanismos tempranos y proactivos de garantía de calidad. En el contexto de los canales de datos diseñados para procesar datos para aplicaciones de IA generativa, esto implica identificar y resolver problemas de calidad de datos en una etapa anterior para mitigar el impacto potencial de los problemas de calidad de datos más adelante. Calidad de datos de AWS Glue no solo mide y monitorea la calidad de sus datos en reposo en sus lagos de datos, almacenes de datos y bases de datos transaccionales, sino que también permite la detección y corrección temprana de problemas de calidad para sus canales de extracción, transformación y carga (ETL) para garantizar sus datos. cumple con los estándares de calidad antes de ser consumido. Para obtener más detalles, consulte Primeros pasos con AWS Glue Data Quality del catálogo de datos de AWS Glue.
Gobernanza de la tienda de vectores
Incrustaciones en bases de datos vectoriales Elevar la inteligencia y las capacidades de las aplicaciones de IA generativa al habilitar funciones como la búsqueda semántica y la reducción de las alucinaciones. Las incrustaciones suelen contener datos privados y confidenciales, y cifrar los datos es un paso recomendado en el flujo de trabajo de entrada del usuario. Amazon OpenSearch sin servidor almacena y busca sus incrustaciones de vectores y cifra sus datos en reposo con Servicio de administración de claves de AWS (AWS KMS). Para más detalles, ver Presentamos el motor vectorial para Amazon OpenSearch Serverless, ahora en versión preliminar. De manera similar, opciones adicionales de motores vectoriales en AWS, incluidas amazona kendra y Aurora amazónica, cifre sus datos en reposo con AWS KMS. Para obtener más información, consulte Cifrado en reposo y Protección de datos mediante cifrado.
A medida que las incorporaciones se generan y almacenan en un almacén de vectores, controlar el acceso a los datos con control de acceso basado en roles (RBAC) se convierte en un requisito clave para mantener la seguridad general. Servicio Amazon OpenSearch proporciona un controles de acceso detallados (FGAC) características con Gestión de identidades y accesos de AWS (IAM) reglas que se pueden asociar con Cognito Amazonas usuarios. Los mecanismos de control de acceso de usuarios correspondientes también son proporcionados por OpenSearch sin servidor, amazona kendray Aurora. Para obtener más información, consulte Control de acceso a datos para Amazon OpenSearch Serverless, Controlar el acceso de los usuarios a los documentos con tokensy Gestión de identidades y accesos para Amazon Aurora, respectivamente.
Flujos de trabajo de solicitud-respuesta del usuario
Los controles en el plano de gobernanza de datos deben integrarse en la aplicación de IA generativa como parte del proceso general. implementación de la solución para garantizar el cumplimiento de las políticas de seguridad de los datos (basadas en controles de acceso basados en roles) y privacidad de datos (basadas en el acceso basado en roles a datos confidenciales). La siguiente figura ilustra el flujo de trabajo para aplicar la gobernanza de datos.
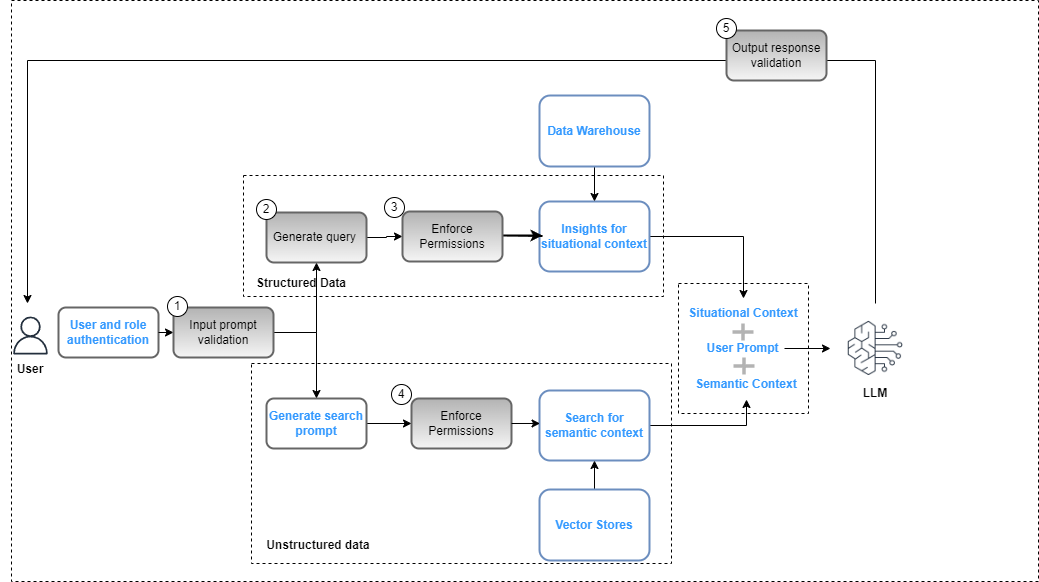
El flujo de trabajo incluye los siguientes pasos clave de gobernanza de datos:
- Proporcione un mensaje de entrada válido para la alineación con las políticas de cumplimiento (por ejemplo, sesgo y toxicidad).
- Genere una consulta asignando palabras clave de solicitud con el catálogo de datos.
- Aplicar políticas FGAC según el rol del usuario.
- Aplique políticas RBAC según el rol del usuario.
- Aplique la redacción de datos y contenido a la respuesta según los permisos de rol del usuario y las políticas de cumplimiento.
Como parte del ciclo de solicitud, se debe analizar la solicitud del usuario y extraer las palabras clave para garantizar la alineación con las políticas de cumplimiento mediante un servicio como Amazon Comprehend (consulte Nuevo para Amazon Comprehend: Detección de toxicidad) o Barandillas para Amazon Bedrock (vista previa). Cuando esto se valida, si el mensaje requiere que se extraigan datos estructurados, las palabras clave se pueden usar en el catálogo de datos (comerciales o técnicos) para extraer las tablas y campos de datos relevantes y construir una consulta desde el almacén de datos. Los permisos de usuario se evalúan utilizando Formación del lago AWS para filtrar los datos relevantes. En el caso de datos no estructurados, los resultados de la búsqueda están restringidos según las políticas de permisos de usuario implementadas en el almacén de vectores. Como paso final, la respuesta de salida del LLM debe evaluarse en función de los permisos del usuario (para garantizar la privacidad y seguridad de los datos) y el cumplimiento de la seguridad (por ejemplo, pautas de sesgo y toxicidad).
Aunque este proceso es específico de la implementación de un RAG y es aplicable a otras estrategias de implementación de LLM, existen controles adicionales:
- Ingeniería rápida – El acceso a las plantillas de avisos para invocar debe restringirse según controles de acceso aumentado por la lógica empresarial.
- Modelos de ajuste y modelos básicos de formación. – En los casos en los que se utilizan objetos de la zona seleccionada en Amazon S3 como datos de entrenamiento para ajustar los modelos básicos, las políticas de permisos deben configurarse con Gestión de identidad y acceso de Amazon S3 a nivel de depósito u objeto según los requisitos.
Resumen
La gobernanza de datos es fundamental para permitir a las organizaciones crear aplicaciones empresariales de IA generativa. A medida que los casos de uso empresarial sigan evolucionando, será necesario ampliar la infraestructura de datos para gobernar y gestionar conjuntos de datos nuevos, diversos y no estructurados para garantizar la alineación con las políticas de privacidad, seguridad y calidad. Estas políticas deben implementarse y gestionarse como parte de la ingesta, el almacenamiento y la gestión de datos de la base de conocimientos empresariales junto con los flujos de trabajo de interacción del usuario. Esto garantiza que las aplicaciones de IA generativa no solo minimicen el riesgo de compartir información inexacta o incorrecta, sino que también protejan contra sesgos y toxicidades que pueden conducir a resultados dañinos o difamatorios. Para obtener más información sobre la gobernanza de datos en AWS, consulte ¿Qué es la gobernanza de datos?
En publicaciones posteriores, brindaremos orientación de implementación sobre cómo expandir la gobernanza de la infraestructura de datos para respaldar casos de uso de IA generativa.
Acerca de los autores
 Krishna Rupana Gunta lidera un equipo de especialistas en datos e inteligencia artificial en AWS. Él y su equipo trabajan con los clientes para ayudarlos a innovar más rápido y tomar mejores decisiones utilizando datos, análisis e IA/ML. Se le puede contactar a través de LinkedIn.
Krishna Rupana Gunta lidera un equipo de especialistas en datos e inteligencia artificial en AWS. Él y su equipo trabajan con los clientes para ayudarlos a innovar más rápido y tomar mejores decisiones utilizando datos, análisis e IA/ML. Se le puede contactar a través de LinkedIn.
 Imtiaz (Taz) Sayed es el líder tecnológico de análisis de WW en AWS. Le gusta interactuar con la comunidad en todo lo relacionado con datos y análisis. Se le puede contactar a través de LinkedIn.
Imtiaz (Taz) Sayed es el líder tecnológico de análisis de WW en AWS. Le gusta interactuar con la comunidad en todo lo relacionado con datos y análisis. Se le puede contactar a través de LinkedIn.
 Raghvender Arni (Arni) Lidera el equipo de aceleración del cliente (CAT) dentro de AWS Industries. El CAT es un equipo global multifuncional de arquitectos de nube, ingenieros de software, científicos de datos y expertos y diseñadores de IA/ML orientados al cliente que impulsa la innovación a través de prototipos avanzados e impulsa la excelencia operativa en la nube a través de experiencia técnica especializada.
Raghvender Arni (Arni) Lidera el equipo de aceleración del cliente (CAT) dentro de AWS Industries. El CAT es un equipo global multifuncional de arquitectos de nube, ingenieros de software, científicos de datos y expertos y diseñadores de IA/ML orientados al cliente que impulsa la innovación a través de prototipos avanzados e impulsa la excelencia operativa en la nube a través de experiencia técnica especializada.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/data-governance-in-the-age-of-generative-ai/

