Introducción
Los datos son combustible para la industria de TI y el Proyecto de ciencia de datos en el mundo en línea de hoy. Las industrias de TI dependen en gran medida de conocimientos en tiempo real derivados de transmisión de datos fuentes. Manejar y procesar los datos de transmisión es el trabajo más difícil para Análisis de Datos. Sabemos que la transmisión de datos es información que se emite a gran volumen en un procesamiento continuo, lo que significa que los datos cambian cada segundo. Para manejar estos datos estamos utilizando Plataforma Confluente – Una distribución autogestionada y de nivel empresarial de Apache Kafka.
Kafka es una falla distribuida que puede ser manejada por la arquitectura, lo que sirve como una opción popular para administrar flujos de datos de alto rendimiento. Los datos de Kafka se recogen entonces en el MongoDB en forma de colecciones. En este artículo, vamos a crear el canal de extremo a extremo en el que los datos se obtienen con la ayuda de API en el canal y luego se recopilan en Kafka en forma de temas y luego se almacenan en MongoDB, desde allí podemos usarlo. en el proyecto o hacer la ingeniería de características.
OBJETIVOS DE APRENDIZAJE
- Aprenda qué es la transmisión de datos y cómo manejar la transmisión de datos con la ayuda de Kafka.
- Comprenda la plataforma Confluent: una distribución autogestionada y de nivel empresarial de Apache Kafka.
- Almacene los datos recopilados por Kafka en MongoDB, que es una base de datos NoSQL que almacena los datos no estructurados.
- Cree una canalización completamente de un extremo a otro para recuperar y almacenar los datos en la base de datos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
Identifica el problema
Para manejar la transmisión de datos que proviene del sensor, los vehículos que contienen datos del sensor se producen por segundo y es difícil manejar y preprocesar los datos para usar en el Proyecto de ciencia de datos. Entonces, para abordar este problema, estamos creando una canalización de un extremo a otro que maneja los datos y los almacena.
¿Qué es la transmisión de datos?
Transmisión de datos Son datos que se generan continuamente por diferentes fuentes y que son datos no estructurados. Se refiere a un flujo continuo de datos generados a partir de diferentes fuentes en tiempo real o casi en tiempo real. En el procesamiento por lotes tradicional, donde se recopilan datos y estos datos de transmisión se procesan a medida que se generan. La transmisión de datos puede ser datos de IOT, como sensores de temperatura y rastreadores GPS, o datos de máquinas, como datos generados por máquinas y equipos industriales, como datos de telemetría de vehículos y maquinaria de fabricación. Existen plataformas de procesamiento de datos en streaming como Apache-Kafka.
¿Qué es Kafka?
Apache Kafka es una plataforma que se utiliza para crear aplicaciones de transmisión y canalizaciones de datos en tiempo real. La API de Kafka Streams es una potente biblioteca que permite el procesamiento sobre la marcha, lo que le permite recopilar y crear parámetros de ventanas, realizar uniones de datos dentro de una secuencia y más. Apache Kafka consta de una capa de almacenamiento y una capa informática que combina la ingesta eficiente de datos en tiempo real, la transmisión de canales de datos y el almacenamiento entre sistemas.
¿Cuál será el enfoque?
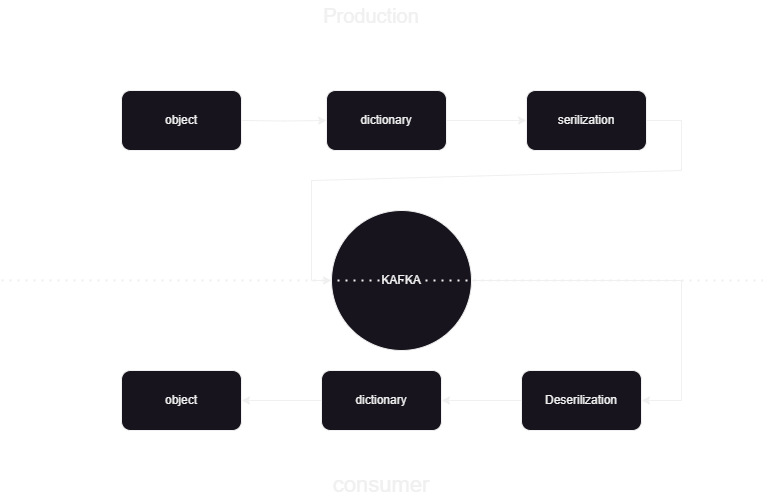
Este es un canal de aprendizaje automático que nos ayuda a saber cómo publicar y procesar los datos hacia y desde Kafka confluente en formato JSON. Hay dos partes del consumidor y productor del procesamiento de datos de Kafka. Almacenar los datos de transmisión de los diferentes productores y almacenarlos en confluente y luego se realiza la deserialización de los datos y esos datos se almacenan en la base de datos.
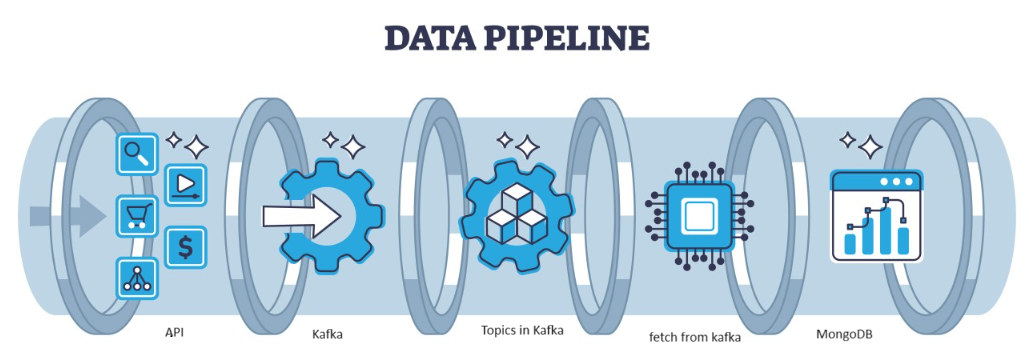
Descripción general de la arquitectura del sistema
Estamos procesando los datos de transmisión con la ayuda de Kafka confluente y Kafka se divide en dos partes:
- Productor de Kafka: El Productor de Kafka es responsable de producir y enviar datos a los temas de Kafka.
- Consumidor de Kafka: El consumidor de Kafka debe leer y procesar datos de los temas de Kafka.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
¿Qué son los componentes?
- Temas: Los temas son canales lógicos o categorías que publican los productores. Cada tema se divide en una o más particiones y cada tema se replica en varios intermediarios para lograr tolerancia a fallas. Los productores publican datos sobre temas específicos y los consumidores se suscriben a temas para utilizar los datos.
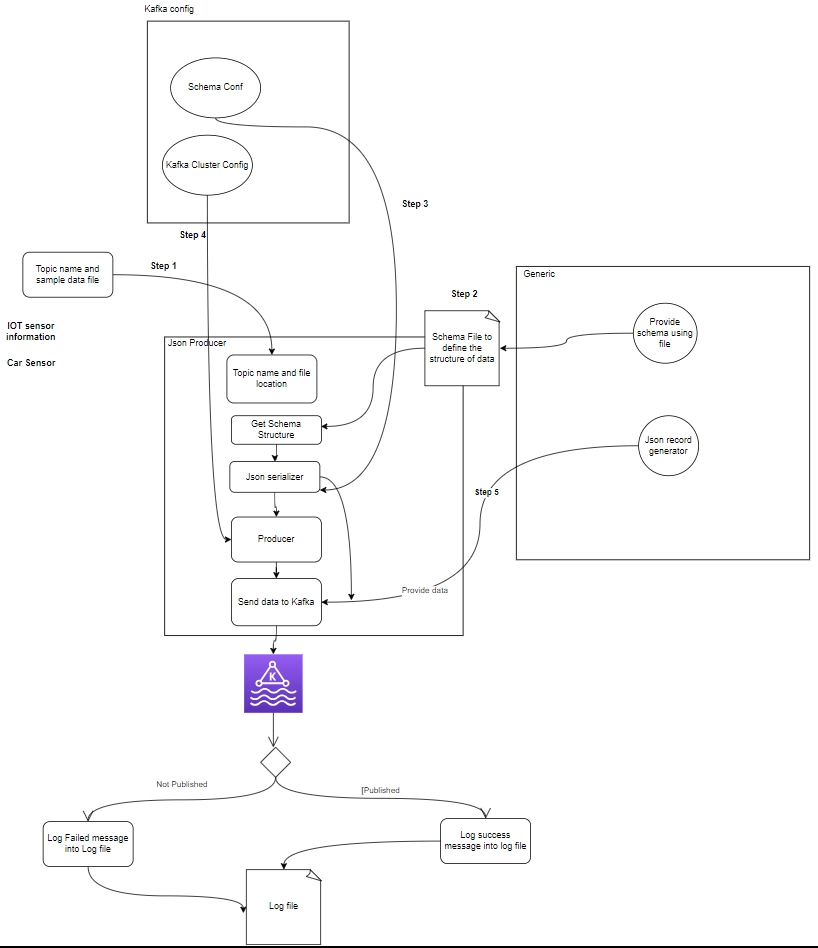
- Productores: Un Productor Apache Kafka es una aplicación cliente que publica (escribe) eventos en un clúster Kafka. Las aplicaciones que envían datos a temas se conocen como productores Kafka. Esta sección ofrece una visión general del productor Kafka.
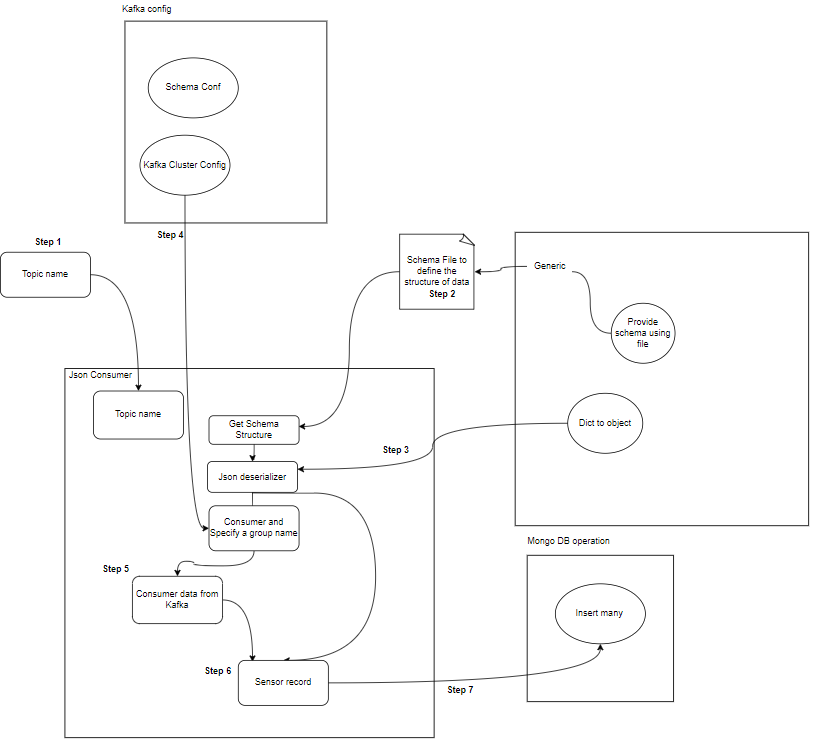
- Consumidor: Los consumidores de Kafka son responsables de leer y procesar los datos de los temas de Kafka y procesarlos. Los consumidores pueden ser parte de cualquier aplicación que necesite utilizar y reaccionar a datos de Kafka. Se suscriben a uno o más temas y datos de los corredores de Kafka. Los consumidores se pueden organizar en grupos de consumidores, donde cada grupo de consumidores tiene uno o más consumidores y cada tema de un tema es consumido por un solo consumidor dentro del grupo. Esto permite el procesamiento paralelo y el equilibrio de carga del consumo de datos.
¿Cuál es la estructura del proyecto?
Esto muestra el diagrama de flujo del proyecto sobre cómo se dividen la carpeta y los archivos en el proyecto:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Productor Kafka: El productor es la parte principal que genera datos del sensor (por ejemplo, a partir de archivos CSV en sample_data/) y los publica en un tema de Kafka. condiciones de error que pueden ocurrir durante la generación o publicación de datos.
- Corredor(es) de Kafka: Los intermediarios de Kafka almacenan y replican datos en el clúster de Kafka, manejan la partición de datos y garantizan la tolerancia a fallas y la alta disponibilidad.
- Consumidor(es) de Kafka: Los consumidores leen datos de temas de Kafka, los procesan (por ejemplo, transformaciones, agregaciones) y los almacenan en MongoDB. También monitorean las condiciones de error que pueden ocurrir durante el procesamiento de datos.
- MongoDB: MongoDB almacena los datos de los sensores recibidos de los consumidores de Kafka. Proporciona una consulta para la recuperación de datos y garantiza la durabilidad de los datos mediante mecanismos de replicación y tolerancia a fallas.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Requisitos previos para el almacenamiento de datos
Kafka confluente
- Crear cuenta: para comprender Kafka, necesita Confluent. Le encanta Apache Kafka®, pero no lo administra. El servicio nativo de la nube, completo y totalmente administrado va más allá de Kafka para que sus mejores personas puedan concentrarse en brindar valor a su negocio.
- Crear temas:
- Vaya a la página de inicio y a la barra lateral
- Vaya a Entorno y luego haga clic en Predeterminado
- Ir a los temas

- seleccione el nuevo tema y dé el nombre del tema

MongoDB
Cree un registro y luego inicie sesión en MongoDB Atlas y guarde el enlace de conexión de Mongodb Atlas para su uso posterior.
Guía paso a paso para la configuración del proyecto
- Instalación de Python: asegúrese de que Python esté instalado en su máquina. Puedes descargar e instalar Python del sitio web oficial.
- Versión de Conda: verifique la versión de Conda en la terminal.
- Creación de entorno virtual: cree un entorno virtual utilizando venv.
conda create -p venv python==3.10 -y- Activación del entorno virtual: Activar el entorno virtual:
conda activate venv/- Instalar los paquetes necesarios: Utilice pip para instalar las dependencias necesarias enumeradas en el archivo requisitos.txt:
pip install -r requirements.txt- tenemos que configurar algunas de las variables de entorno en el sistema local. Esta es la variable de entorno del clúster de nube confluente.
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
Actualice la credencial en el archivo .env y ejecute el siguiente comando para ejecutar su aplicación en la ventana acoplable.
- Cree un archivo .env en el directorio raíz de su proyecto si no está disponible, pegue el contenido a continuación y actualice las credenciales
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Ejecutando el archivo de Productor y Consumidor:
python producer_main.py
python consumer_main.py¿Cómo implementar el código?
- src/: Este directorio es la carpeta principal para todos los archivos de código fuente. Dentro de este directorio, tenemos los siguientes subdirectorios:
consumidor/: este directorio contiene el código de Kafka_consumer, responsable de leer datos de los temas de Kafka y procesarlos.
productor/: este directorio contiene el código de Kafka_producer, responsable de generar y enviar datos del sensor a los temas de Kafka. - LÉAME.md: Este archivo Markdown contiene documentación e instrucciones para el proyecto, incluida una descripción general de su propósito, las instrucciones, pautas de uso y cualquier información.
- requisitos.txt: Este archivo enumera la biblioteca de Python necesaria para el proyecto. Cada dependencia aparece junto con su número de versión. Herramientas como pip pueden usar este archivo para instalar las dependencias necesarias automáticamente.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: Para conectar MongoDB Altas a través del enlace, estamos escribiendo el script en Python
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
ingrese su URL que es una copia de MongoDb Altas
Salida:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Este archivo se ejecuta y luego llamamos al pitón productor_main.py y esto llamará al siguiente archivo:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Salida:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Este archivo se ejecuta y luego llamamos al Python consumidor_main.py y esto llamará al siguiente archivo:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Salida:

Cuando ejecutamos tanto al consumidor como al productor, el sistema se ejecuta en Kafka y la información/datos se recopilan más rápido.

Salida:
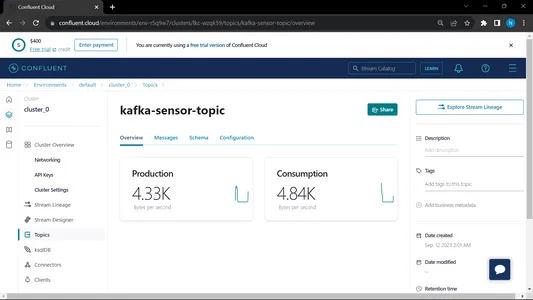
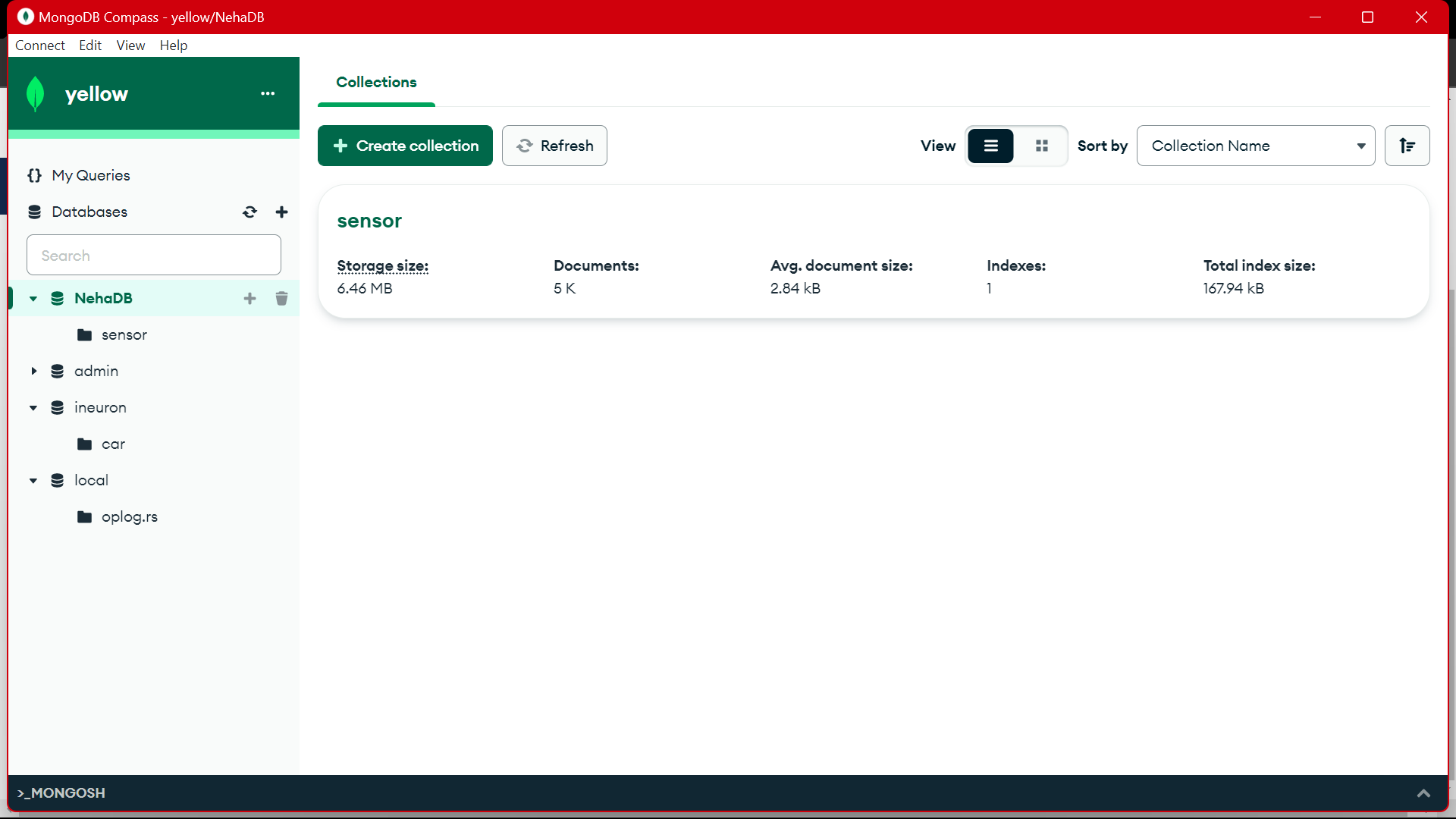
Desde MongoDB estamos utilizando estos datos para preprocesarlos en EDA, sobre estos datos se realizan trabajos de ingeniería de características y análisis de datos.
[Contenido incrustado]
Conclusión
En este artículo, entendemos cómo almacenamos y procesamos la transmisión de datos desde el sensor a Kafka en formato JSON y luego almacenamos los datos en MongoDB. Sabemos que los datos en streaming son datos que se emiten a gran volumen en un procesamiento continuo, lo que significa que los datos cambian cada segundo. Hemos creado el canal de extremo a extremo en el que los datos se obtienen con la ayuda de API en el canal y luego se recopilan en Kafka en forma de temas y luego se almacenan en MongoDB, desde allí podemos usarlos en el proyecto o hacer lo mismo. Ingeniería de características.
Puntos clave
- Aprenda qué es la transmisión de datos y cómo manejar la transmisión de datos con la ayuda de Kafka.
- Comprenda la plataforma Confluent: una distribución autogestionada y de nivel empresarial de Apache Kafka.
- almacene los datos recopilados por Kafka en MongoDB, que es una base de datos NoSQL que almacena los datos no estructurados.
- Cree una canalización completamente de un extremo a otro para recuperar y almacenar los datos en la base de datos.
- comprender la funcionalidad de cada componente del proyecto, implementarlo en la ventana acoplable e implementarlo en una nube para usarlo en cualquier momento.
Recursos
Preguntas frecuentes
R. MongoDB almacena los datos en datos no estructurados. Los datos de transmisión son formas no estructuradas de datos para la utilización de la memoria. Usamos MongoDB como base de datos.
R. El propósito es crear un canal de procesamiento de datos en tiempo real donde los datos ingeridos en temas de Kafka se puedan consumir, procesar y almacenar en MongoDB para análisis, informes o uso de aplicaciones adicionales.
R. Los casos de uso incluyen análisis en tiempo real, procesamiento de datos de IoT, agregación de registros, monitoreo de redes sociales y sistemas de recomendación, donde los datos de transmisión deben procesarse y almacenarse para su posterior análisis o uso de aplicaciones.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

