Los modelos de lenguaje generativo han demostrado ser notablemente hábiles para resolver tareas lógicas y analíticas de procesamiento del lenguaje natural (PLN). Además, el uso de pronta ingenieria puede mejorar notablemente su rendimiento. Por ejemplo, cadena de pensamiento (CoT) es conocido por mejorar la capacidad de un modelo para problemas complejos de varios pasos. Para aumentar aún más la precisión en tareas que implican razonamiento, un autoconsistencia Se ha sugerido un enfoque de incitación, que reemplaza la decodificación codiciosa con estocástica durante la generación del lenguaje.
lecho rocoso del amazonas es un servicio totalmente administrado que ofrece una selección de modelos básicos de alto rendimiento de empresas líderes en inteligencia artificial y de Amazon a través de una única API, junto con un amplio conjunto de capacidades para construir IA generativa aplicaciones con seguridad, privacidad e IA responsable. Con el inferencia por lotes API, puede utilizar Amazon Bedrock para ejecutar inferencias con modelos básicos en lotes y obtener respuestas de manera más eficiente. Esta publicación muestra cómo implementar indicaciones de autoconsistencia mediante inferencia por lotes en Amazon Bedrock para mejorar el rendimiento del modelo en tareas aritméticas y de razonamiento de opción múltiple.
Resumen de la solución
La incitación a la autoconsistencia de los modelos lingüísticos se basa en la generación de múltiples respuestas que se agregan en una respuesta final. A diferencia de los enfoques de generación única como CoT, el procedimiento de muestreo y marginación de autoconsistencia crea una variedad de finalizaciones de modelos que conducen a una solución más consistente. La generación de diferentes respuestas para una determinada indicación es posible gracias al uso de una estrategia de decodificación estocástica, en lugar de codiciosa.
La siguiente figura muestra en qué se diferencia la autoconsistencia de la codiciosa CoT en que genera un conjunto diverso de caminos de razonamiento y los agrega para producir la respuesta final.

Estrategias de decodificación para la generación de texto.
El texto generado por modelos de lenguaje exclusivos de decodificadores se despliega palabra por palabra, y el token posterior se predice en función del contexto anterior. Para una indicación determinada, el modelo calcula una distribución de probabilidad que indica la probabilidad de que cada token aparezca a continuación en la secuencia. La decodificación implica traducir estas distribuciones de probabilidad en texto real. La generación de texto está mediada por un conjunto de parámetros de inferencia que a menudo son hiperparámetros del propio método de decodificación. Un ejemplo es el temperatura, que modula la distribución de probabilidad del siguiente token e influye en la aleatoriedad de la salida del modelo.
Decodificación codiciosa Es una estrategia de decodificación determinista que en cada paso selecciona el token con la mayor probabilidad. Aunque sencillo y eficiente, el enfoque corre el riesgo de caer en patrones repetitivos, porque ignora el espacio de probabilidad más amplio. Establecer el parámetro de temperatura en 0 en el momento de la inferencia equivale esencialmente a implementar una decodificación codiciosa.
Muestreo introduce estocasticidad en el proceso de decodificación al seleccionar aleatoriamente cada token posterior en función de la distribución de probabilidad predicha. Esta aleatoriedad da como resultado una mayor variabilidad de la producción. La decodificación estocástica resulta más adecuada para capturar la diversidad de resultados potenciales y, a menudo, produce respuestas más imaginativas. Los valores de temperatura más altos introducen más fluctuaciones y aumentan la creatividad de la respuesta del modelo.
Técnicas de estímulo: CoT y autoconsistencia
La capacidad de razonamiento de los modelos lingüísticos se puede aumentar mediante ingeniería rápida. En particular, se ha demostrado que CoT provocar razonamiento en tareas complejas de PNL. Una forma de implementar un tiro cero CoT se realiza mediante un aumento rápido con la instrucción de "pensar paso a paso". Otra es exponer el modelo a ejemplos de pasos intermedios de razonamiento en indicaciones de pocos disparos moda. Ambos escenarios suelen utilizar una decodificación codiciosa. CoT conduce a mejoras significativas en el rendimiento en comparación con la instrucción simple en tareas de aritmética, sentido común y razonamiento simbólico.
Incitación a la autoconsistencia se basa en el supuesto de que introducir diversidad en el proceso de razonamiento puede ser beneficioso para ayudar a que los modelos converjan en la respuesta correcta. La técnica utiliza decodificación estocástica para lograr este objetivo en tres pasos:
- Indique el modelo de lenguaje con ejemplos de CoT para provocar el razonamiento.
- Reemplace la decodificación codiciosa con una estrategia de muestreo para generar un conjunto diverso de rutas de razonamiento.
- Agregue los resultados para encontrar la respuesta más consistente en el conjunto de respuestas.
Se ha demostrado que la autoconsistencia supera las indicaciones de CoT en puntos de referencia populares de aritmética y razonamiento de sentido común. Una limitación del enfoque es su mayor costo computacional.
Esta publicación muestra cómo las indicaciones de autoconsistencia mejoran el rendimiento de los modelos de lenguaje generativo en dos tareas de razonamiento de PNL: resolución de problemas aritméticos y respuesta a preguntas de dominio específico de opción múltiple. Demostramos el enfoque mediante inferencia por lotes en Amazon Bedrock:
- Accedemos al SDK de Amazon Bedrock Python en JupyterLab en un Amazon SageMaker instancia de cuaderno.
- Para el razonamiento aritmético, sugerimos Comando Coherencia en el conjunto de datos GSM8K de problemas matemáticos de la escuela primaria.
- Para el razonamiento de opción múltiple, sugerimos AI21 Labs Jurásico-2 Medio sobre una pequeña muestra de preguntas del examen Asociado de Arquitecto de Soluciones Certificado de AWS.
Requisitos previos
Este tutorial supone los siguientes requisitos previos:

El costo estimado para ejecutar el código que se muestra en esta publicación es de $100, suponiendo que ejecute la solicitud de autoconsistencia una vez con 30 rutas de razonamiento usando un valor para el muestreo basado en la temperatura.
Conjunto de datos para investigar las capacidades de razonamiento aritmético
GSM8K es un conjunto de datos de problemas matemáticos de escuela primaria ensamblados por humanos que presentan una alta diversidad lingüística. Cada problema requiere de 2 a 8 pasos para resolverse y requiere realizar una secuencia de cálculos elementales con operaciones aritméticas básicas. Estos datos se utilizan comúnmente para comparar las capacidades de razonamiento aritmético de varios pasos de los modelos de lenguaje generativo. El Conjunto de trenes GSM8K Comprende 7,473 registros. Lo siguiente es un ejemplo:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Configurar para ejecutar inferencia por lotes con Amazon Bedrock
La inferencia por lotes le permite ejecutar múltiples llamadas de inferencia a Amazon Bedrock de forma asincrónica y mejorar el rendimiento de la inferencia de modelos en grandes conjuntos de datos. El servicio está en versión preliminar al momento de escribir este artículo y solo está disponible a través de la API. Referirse a Ejecutar inferencia por lotes para acceder a las API de inferencia por lotes a través de SDK personalizados.
Después de haber descargado y descomprimido el SDK de Python en una instancia de notebook de SageMaker, puede instalarlo ejecutando el siguiente código en una celda de notebook de Jupyter:
Formatee y cargue datos de entrada en Amazon S3
Los datos de entrada para la inferencia por lotes deben prepararse en formato JSONL con recordId y modelInput llaves. Este último debe coincidir con el campo del cuerpo del modelo que se invocará en Amazon Bedrock. En particular, algunos parámetros de inferencia admitidos para el comando Cohere en temperature por aleatoriedad, max_tokens para la longitud de salida, y num_generations para generar múltiples respuestas, todas las cuales se pasan junto con el prompt as modelInput:
See Parámetros de inferencia para modelos de cimentación. para obtener más detalles, incluidos otros proveedores de modelos.
Nuestros experimentos sobre razonamiento aritmético se realizan en la configuración de pocos disparos sin personalizar ni ajustar Cohere Command. Usamos el mismo conjunto de ocho ejemplos de pocos disparos de la cadena de pensamiento (Tabla 20) y autoconsistencia (Tabla 17) documentos. Las indicaciones se crean concatenando los ejemplos con cada pregunta del conjunto de trenes GSM8K.
Nosotros fijamos max_tokens a 512 y num_generations a 5, el máximo permitido por Cohere Command. Para una decodificación codiciosa, configuramos temperature a 0 y para mayor coherencia, realizamos tres experimentos a temperaturas 0.5, 0.7 y 1. Cada configuración produce datos de entrada diferentes según los valores de temperatura respectivos. Los datos tienen formato JSONL y se almacenan en Amazon S3.
Cree y ejecute trabajos de inferencia por lotes en Amazon Bedrock
La creación de trabajos de inferencia por lotes requiere un cliente de Amazon Bedrock. Especificamos las rutas de entrada y salida de S3 y le damos a cada trabajo de invocación un nombre único:
Los trabajos son creado pasando el rol de IAM, el ID del modelo, el nombre del trabajo y la configuración de entrada/salida como parámetros a la API de Amazon Bedrock:
Publicaciones, monitoreoy parada Los trabajos de inferencia por lotes son compatibles con sus respectivas llamadas API. En el momento de la creación, los empleos aparecen primero como Submittedentonces como InProgress, y finalmente como Stopped, Failedo Completed.
Si los trabajos se completan correctamente, el contenido generado se puede recuperar de Amazon S3 utilizando su ubicación de salida única.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
La autoconsistencia mejora la precisión del modelo en tareas aritméticas
La autoconsistencia de Cohere Command supera a una codiciosa línea de base de CoT en términos de precisión en el conjunto de datos GSM8K. Para mayor coherencia, tomamos muestras de 30 rutas de razonamiento independientes a tres temperaturas diferentes, con topP y topK establecer en su valores predeterminados. Las soluciones finales se agregan eligiendo el suceso más consistente mediante votación mayoritaria. En caso de empate, elegimos aleatoriamente una de las respuestas mayoritarias. Calculamos los valores de precisión y desviación estándar promediados en 100 ejecuciones.
La siguiente figura muestra la precisión del conjunto de datos GSM8K de Cohere Command solicitado con CoT ávido (azul) y autoconsistencia en valores de temperatura 0.5 (amarillo), 0.7 (verde) y 1.0 (naranja) en función del número de muestras caminos de razonamiento.
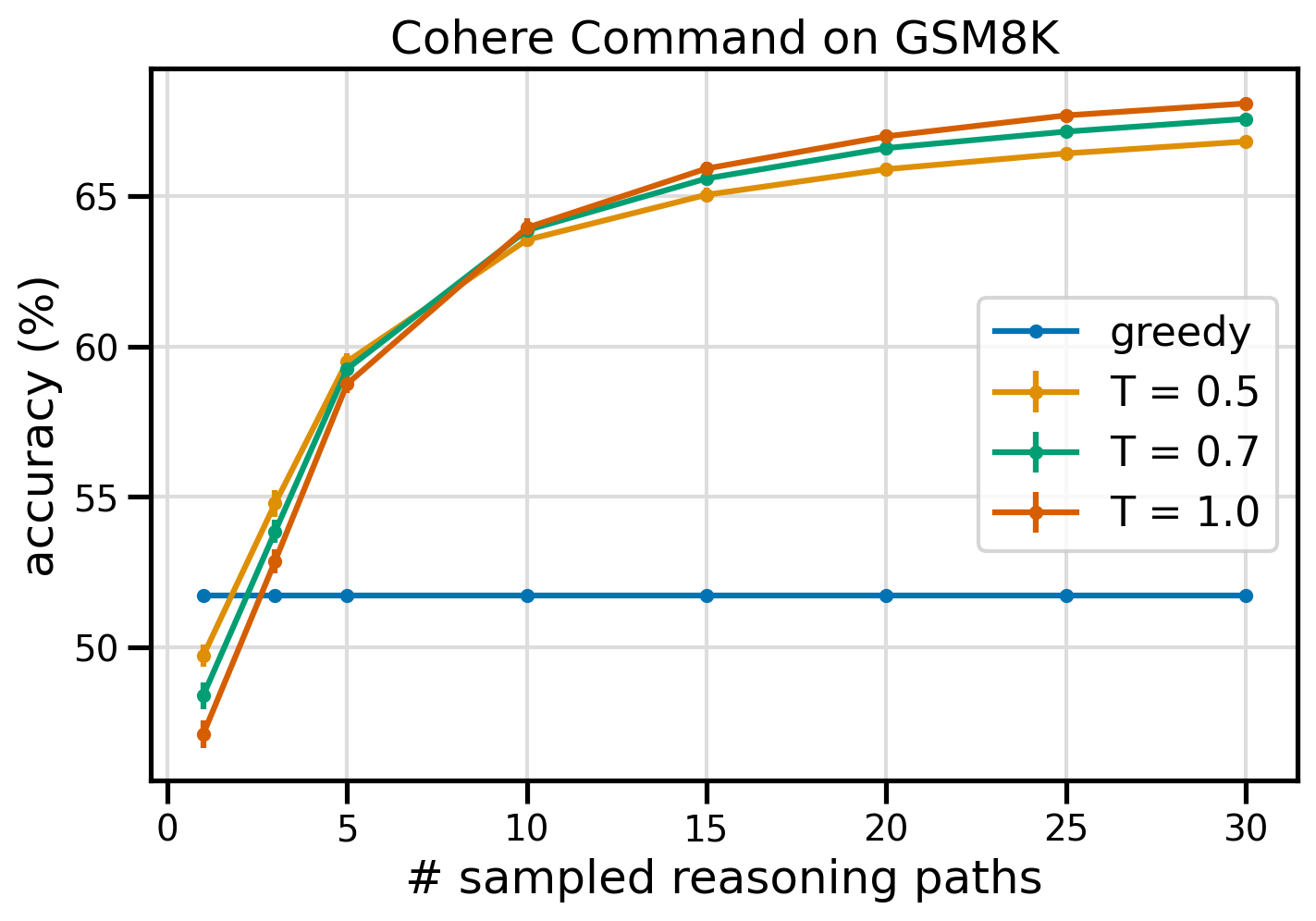
La figura anterior muestra que la autoconsistencia mejora la precisión aritmética sobre la codiciosa CoT cuando el número de rutas muestreadas es tan bajo como tres. El rendimiento aumenta constantemente a medida que se avanza en el razonamiento, lo que confirma la importancia de introducir diversidad en la generación de pensamiento. Cohere Command resuelve el conjunto de preguntas GSM8K con una precisión del 51.7 % cuando se le solicita con CoT frente al 68 % con 30 rutas de razonamiento autoconsistentes en T=1.0. Los tres valores de temperatura estudiados arrojan resultados similares, siendo las temperaturas más bajas comparativamente más eficaces en caminos menos muestreados.
Consideraciones prácticas sobre eficiencia y costo.
La autoconsistencia está limitada por el mayor tiempo de respuesta y el costo incurrido al generar múltiples resultados por mensaje. Como ejemplo práctico, la inferencia por lotes para la generación codiciosa con Cohere Command en 7,473 registros GSM8K finalizó en menos de 20 minutos. El trabajo tomó 5.5 millones de tokens como entrada y generó 630,000 tokens de salida. En la actualidad Precios de inferencia de Amazon Bedrock, el costo total incurrido fue de alrededor de $9.50.
Para mantener la coherencia con Cohere Command, utilizamos el parámetro de inferencia num_generations para crear múltiples finalizaciones por mensaje. Al momento de escribir este artículo, Amazon Bedrock permite un máximo de cinco generaciones y tres generaciones simultáneas. Submitted trabajos de inferencia por lotes. Los trabajos pasan a la InProgress estado secuencialmente, por lo tanto, muestrear más de cinco rutas requiere múltiples invocaciones.
La siguiente figura muestra los tiempos de ejecución de Cohere Command en el conjunto de datos GSM8K. El tiempo de ejecución total se muestra en el eje x y el tiempo de ejecución por ruta de razonamiento muestreada en el eje y. La generación codiciosa se ejecuta en el menor tiempo posible, pero genera un mayor costo de tiempo por ruta muestreada.

La generación codiciosa se completa en menos de 20 minutos para el conjunto GSM8K completo y muestra una ruta de razonamiento única. La autoconsistencia con cinco muestras requiere aproximadamente un 50% más de tiempo para completarse y cuesta alrededor de $14.50, pero produce cinco caminos (más del 500%) en ese tiempo. El tiempo de ejecución total y el costo aumentan paso a paso con cada cinco rutas de muestreo adicionales. Un análisis de costo-beneficio sugiere que la configuración recomendada para la implementación práctica de la autoconsistencia es de 1 a 2 trabajos de inferencia por lotes con 5 a 10 rutas de muestreo. Esto logra un rendimiento mejorado del modelo manteniendo a raya el costo y la latencia.
La autoconsistencia mejora el rendimiento del modelo más allá del razonamiento aritmético
Una cuestión crucial para demostrar la idoneidad de las indicaciones de autoconsistencia es si el método tiene éxito en otras tareas de PNL y modelos de lenguaje. Como extensión de un caso de uso relacionado con Amazon, realizamos un análisis pequeño de preguntas de muestra del Certificación de Asociado de Arquitecto de Soluciones de AWS. Este es un examen de opción múltiple sobre tecnología y servicios de AWS que requiere conocimiento del dominio y la capacidad de razonar y decidir entre varias opciones.
Preparamos un conjunto de datos de SAA-C01 y SAA-C03 preguntas de examen de muestra. De las 20 preguntas disponibles, utilizamos las primeras 4 como ejemplos de pocas tomas y solicitamos al modelo que responda las 16 restantes. Esta vez, realizamos inferencias con el modelo AI21 Labs Jurassic-2 Mid y generamos un máximo de 10 rutas de razonamiento en temperatura 0.7. Los resultados muestran que la autoconsistencia mejora el desempeño: aunque el CoT codicioso produce 11 respuestas correctas, la autoconsistencia tiene éxito en 2 más.
La siguiente tabla muestra los resultados de precisión para 5 y 10 rutas de muestreo promediadas en 100 ejecuciones.
| . | Decodificación codiciosa | T = 0.7 |
| # rutas de muestra: 5 | 68.6 | 74.1 ± 0.7 |
| # rutas de muestra: 10 | 68.6 | 78.9 ± 0.3 |
En la siguiente tabla, presentamos dos preguntas del examen que son respondidas incorrectamente por el codicioso CoT mientras la autoconsistencia tiene éxito, resaltando en cada caso las huellas de razonamiento correctas (verde) o incorrectas (rojo) que llevaron al modelo a producir respuestas correctas o incorrectas. Aunque no todos los caminos muestreados generados por la autoconsistencia son correctos, la mayoría converge en la respuesta verdadera a medida que aumenta el número de caminos muestreados. Observamos que entre 5 y 10 caminos suelen ser suficientes para mejorar los resultados codiciosos, con rendimientos decrecientes en términos de eficiencia más allá de esos valores.
| Pregunta |
Una aplicación web permite a los clientes cargar pedidos en un depósito de S3. Los eventos de Amazon S3 resultantes activan una función Lambda que inserta un mensaje en una cola SQS. Una única instancia EC2 lee mensajes de la cola, los procesa y los almacena en una tabla de DynamoDB dividida por un ID de pedido único. Se espera que el tráfico del próximo mes aumente en un factor de 10 y un arquitecto de soluciones está revisando la arquitectura para detectar posibles problemas de escala. ¿Qué componente es MÁS probable que necesite una remodelación para poder escalar y adaptarse al nuevo tráfico? A. Función lambda |
Una aplicación que se ejecuta en AWS utiliza una implementación de clúster de base de datos Amazon Aurora Multi-AZ para su base de datos. Al evaluar las métricas de rendimiento, un arquitecto de soluciones descubrió que las lecturas de la base de datos provocan una alta E/S y agregan latencia a las solicitudes de escritura en la base de datos. ¿Qué debería hacer el arquitecto de soluciones para separar las solicitudes de lectura de las solicitudes de escritura? A. Habilite el almacenamiento en caché de lectura en la base de datos de Aurora. |
| Respuesta correcta | C – Una única instancia EC2 no escalará y es un único punto de falla en la arquitectura. Una solución mucho mejor sería tener instancias EC2 en un grupo de Auto Scaling en 2 zonas de disponibilidad para leer mensajes de la cola. Las otras respuestas son todos servicios administrados que se pueden configurar para escalar o escalarán automáticamente. | C – Las réplicas de Aurora proporcionan una forma de descargar el tráfico de lectura. Las réplicas de Aurora comparten el mismo almacenamiento subyacente que la base de datos principal, por lo que el tiempo de demora es generalmente muy bajo. Las réplicas de Aurora tienen sus propios puntos finales, por lo que será necesario configurar la aplicación para dirigir el tráfico de lectura a los nuevos puntos finales. |
| Decodificación codiciosa | Es posible que no sea posible escalar la instancia EC2 directamente, ya que es posible que no sea posible cambiar el tamaño de la instancia. Escalar la función Lambda puede no ser suficiente, ya que las funciones Lambda tienen un límite de asignación de memoria de 6 GB. Es posible que escalar la cola SQS no sea suficiente, ya que SQS tiene un límite de 10,000 mensajes. Las tablas de DynamoDB se pueden escalar aprovisionando más unidades de capacidad. La respuesta correcta es d. | Modificación de la aplicación para leer desde la instancia en espera Multi-AZ (opción B) es el mejor enfoque. La instancia en espera se replica de forma asincrónica desde la instancia principal, por lo que las operaciones de lectura no interferirán con las operaciones de escritura. Habilitar el almacenamiento en caché de lectura directa (opción A) o crear una réplica de Aurora (opción C) no resolverá el problema de contención de E/S. Crear una segunda base de datos de Aurora y vincularla como una réplica de lectura (opción D) tampoco resolverá el problema de contención de E/S. La respuesta correcta es b. |
| Ruta de muestra n.° 1 | Es posible que escalar la instancia EC2 a 10 veces su tamaño actual no sea factible, ya sea desde una perspectiva de costo o rendimiento. Se necesitaría una instancia más grande, lo que puede resultar costoso. Un enfoque más rentable podría ser utilizar un enjambre de instancias más pequeñas (por ejemplo, Auto Scaling Group) para compartir la carga. En este caso, es probable que sea necesario rediseñar la instancia EC2. La respuesta correcta es c. | Modificar la aplicación para utilizar los puntos finales apropiados no es una solución práctica ya que requeriría cambios en el código de la aplicación. La respuesta correcta es C: crear una réplica de Aurora y modificar la aplicación para utilizar los puntos finales adecuados. |
| Ruta de muestra n.° 2 | Escalar una sola instancia EC2 es más difícil y problemático que escalar los otros componentes del servicio. Amazon SQS, Lambda y DynamoDB pueden escalar automáticamente para hacer frente al aumento de carga. La respuesta correcta es c. |
(C) Cree una réplica de Aurora y modifique la aplicación para utilizar los puntos finales adecuados. Al configurar una réplica de Aurora, puede separar el tráfico de lectura del tráfico de escritura. Las réplicas de Aurora utilizan diferentes URL de punto final, lo que le permite dirigir el tráfico de lectura a la réplica en lugar de a la base de datos principal. La réplica puede procesar solicitudes de lectura en paralelo con solicitudes de escritura en la base de datos principal., reduciendo la E/S y la latencia. |
Limpiar
La ejecución de inferencia por lotes en Amazon Bedrock está sujeta a cargos según los precios de Amazon Bedrock. Cuando complete el tutorial, elimine su instancia de notebook de SageMaker y elimine todos los datos de sus depósitos de S3 para evitar incurrir en cargos futuros.
Consideraciones
Aunque la solución demostrada muestra un rendimiento mejorado de los modelos de lenguaje cuando se les solicita coherencia propia, es importante tener en cuenta que el tutorial no está listo para producción. Antes de implementar en producción, debe adaptar esta prueba de concepto a su propia implementación, teniendo en cuenta los siguientes requisitos:
- Restricción de acceso a API y bases de datos para evitar el uso no autorizado.
- Cumplimiento de las mejores prácticas de seguridad de AWS con respecto al acceso a roles de IAM y grupos de seguridad.
- Validación y desinfección de la entrada del usuario para evitar ataques de inyección rápida.
- Monitoreo y registro de procesos activados para permitir pruebas y auditorías.
Conclusión
Esta publicación muestra que las indicaciones de autoconsistencia mejoran el rendimiento de los modelos de lenguaje generativo en tareas complejas de PNL que requieren habilidades aritméticas y lógicas de opción múltiple. La autoconsistencia utiliza decodificación estocástica basada en la temperatura para generar varias rutas de razonamiento. Esto aumenta la capacidad del modelo para provocar pensamientos diversos y útiles para llegar a respuestas correctas.
Con la inferencia por lotes de Amazon Bedrock, se solicita al modelo de lenguaje Cohere Command que genere respuestas autoconsistentes a un conjunto de problemas aritméticos. La precisión mejora del 51.7% con decodificación codiciosa al 68% con muestreo de autoconsistencia de 30 rutas de razonamiento en T=1.0. El muestreo de cinco rutas ya mejora la precisión en 7.5 puntos porcentuales. El enfoque es transferible a otros modelos de lenguaje y tareas de razonamiento, como lo demuestran los resultados del modelo Jurassic-21 Mid de AI2 Labs en un examen de certificación de AWS. En un conjunto de preguntas de tamaño pequeño, la autoconsistencia con cinco caminos muestreados aumenta la precisión en 5 puntos porcentuales en comparación con el CoT codicioso.
Le recomendamos que implemente indicaciones de autoconsistencia para mejorar el rendimiento en sus propias aplicaciones con modelos de lenguaje generativo. Aprender más acerca de Comando Coherencia y Laboratorios AI21 Jurásico Modelos disponibles en Amazon Bedrock. Para obtener más información sobre la inferencia por lotes, consulte Ejecutar inferencia por lotes.
Agradecimientos
El autor agradece a los revisores técnicos Amin Tajgardoon y Patrick McSweeney por sus útiles comentarios.
Sobre la autora

lucía santamaría es científica aplicada sénior en la Universidad ML de Amazon, donde se centra en elevar el nivel de competencia de ML en toda la empresa a través de educación práctica. Lucía tiene un doctorado en astrofísica y le apasiona democratizar el acceso al conocimiento y las herramientas tecnológicas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

