Lo que los usuarios esperan de los motores de búsqueda ha evolucionado a lo largo de los años. Para la mayoría de los usuarios, simplemente devolver rápidamente resultados léxicamente relevantes ya no es suficiente. Ahora los usuarios buscan métodos que les permitan obtener resultados aún más relevantes a través de la comprensión semántica o incluso buscar similitudes visuales de imágenes en lugar de una búsqueda textual de metadatos. Servicio Amazon OpenSearch incluye muchas características que le permiten mejorar su experiencia de búsqueda. Estamos entusiasmados con las funciones y mejoras del servicio OpenSearch que agregamos a ese conjunto de herramientas en 2023.
2023 fue un año de rápida innovación dentro del espacio de la inteligencia artificial (IA) y el aprendizaje automático (ML), y la búsqueda ha sido un importante beneficiario de ese progreso. A lo largo de 2023, Amazon OpenSearch Service invirtió en permitir que los equipos de búsqueda utilicen las últimas tecnologías de IA/ML para mejorar y aumentar sus experiencias de búsqueda existentes, sin tener que reescribir sus aplicaciones o crear orquestaciones personalizadas, lo que permitió desbloquear un rápido desarrollo, iteración y productización. Estas inversiones incluyen la introducción de nuevos métodos de búsqueda, así como funcionalidades para simplificar la implementación de los métodos disponibles, que revisamos en esta publicación.
Antecedentes: búsqueda léxica y semántica
Antes de comenzar, repasemos la búsqueda léxica y semántica.
búsqueda léxica
En la búsqueda léxica, el motor de búsqueda compara las palabras de la consulta de búsqueda con las palabras de los documentos, haciendo coincidir palabra por palabra. Solo los elementos que tienen palabras escritas por el usuario coinciden con la consulta. La búsqueda léxica tradicional, basada en modelos de frecuencia de términos como BM25, se utiliza ampliamente y es eficaz para muchas aplicaciones de búsqueda. Sin embargo, las técnicas de búsqueda léxica tienen dificultades para ir más allá de las palabras incluidas en la consulta del usuario, lo que da lugar a que no siempre se devuelvan resultados potenciales muy relevantes.
Búsqueda semántica
En la búsqueda semántica, el motor de búsqueda utiliza un modelo ML para codificar texto u otros medios (como imágenes y videos) de los documentos fuente como un vector denso en un espacio vectorial de alta dimensión. Esto también se llama incrustación el texto en el espacio vectorial. De manera similar, codifica la consulta como un vector y luego usa una métrica de distancia para encontrar vectores cercanos en el espacio multidimensional para encontrar coincidencias. El algoritmo para encontrar vectores cercanos se llama k-vecinos más cercanos (k-NN). La búsqueda semántica no coincide con términos de consulta individuales: encuentra documentos cuya incrustación vectorial está cerca de la incrustación de la consulta en el espacio vectorial y, por lo tanto, semánticamente similar a la consulta. Esto le permite devolver elementos muy relevantes incluso si no contienen ninguna de las palabras que estaban en la consulta.
OpenSearch ha proporcionado búsqueda de similitud de vectores (k-NN y k-NN aproximado) durante varios años, lo que ha sido valioso para los clientes que lo adoptaron. Sin embargo, no todos los clientes que tienen la oportunidad de beneficiarse de k-NN lo han adoptado, debido al importante esfuerzo de ingeniería y recursos necesarios para hacerlo.
Lanzamientos de 2023: fundamentos
En 2023, se lanzaron varias funciones y mejoras en OpenSearch Service, incluidas nuevas funciones que son elementos fundamentales para seguir mejorando las búsquedas.
La herramienta OpenSearch Comparar resultados de búsqueda
El Comparar resultados de búsqueda La herramienta, generalmente disponible en OpenSearch Service versión 2.11, le permite comparar resultados de búsqueda de dos técnicas de clasificación en paralelo, en OpenSearch Dashboards, para determinar si una consulta produce mejores resultados que la otra. Para los clientes que estén interesados en experimentar con los últimos métodos de búsqueda impulsados por modelos asistidos por ML, la capacidad de comparar resultados de búsqueda es fundamental. Esto puede incluir comparar técnicas de búsqueda léxica, búsqueda semántica y búsqueda híbrida para comprender los beneficios de cada técnica frente a su corpus, o ajustes como la ponderación de campos y diferentes estrategias de derivación o lematización.
La siguiente captura de pantalla muestra un ejemplo del uso de la herramienta Comparar resultados de búsqueda.
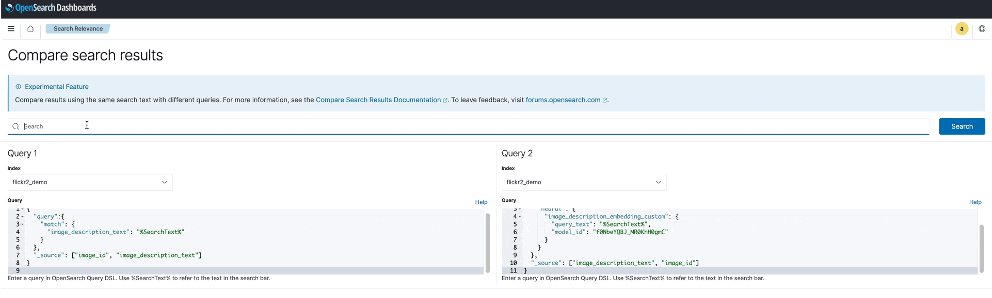
Para obtener más información sobre la búsqueda semántica y la búsqueda intermodal y experimentar con una demostración de la herramienta Comparar resultados de búsqueda, consulte Pruebe la búsqueda semántica con el motor vectorial de Amazon OpenSearch Service.
Canalizaciones de búsqueda
Los profesionales de la búsqueda buscan introducir nuevas formas de mejorar las consultas de búsqueda y los resultados. Con la disponibilidad general de canales de búsqueda, a partir de la versión 2.9 del servicio OpenSearch, puede crear consultas de búsqueda y procesamiento de resultados como una composición de pasos de procesamiento modulares, sin complicar el software de su aplicación. Al integrar procesadores para funciones como filtros y con la capacidad de agregar un script para ejecutarlo en documentos recién indexados, puede hacer que sus aplicaciones de búsqueda sean más precisas y eficientes y reducir la necesidad de desarrollo personalizado.
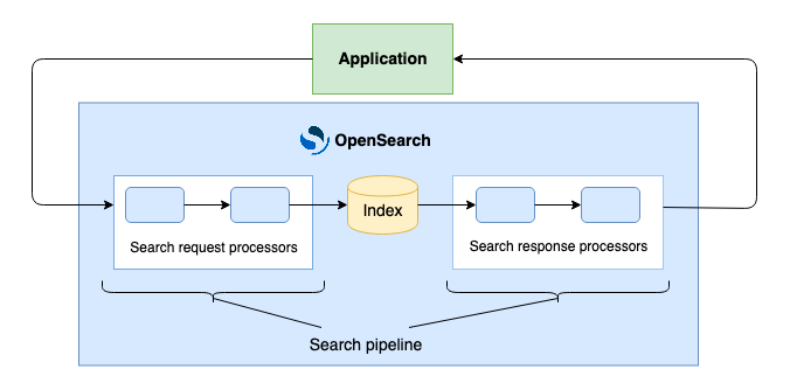
Los canales de búsqueda incorporan tres procesadores integrados: filter_query, rename_field y script request, así como nuevas API centradas en los desarrolladores para permitir que los desarrolladores que quieran construir sus propios procesadores puedan hacerlo. OpenSearch continuará agregando procesadores integrados adicionales para ampliar aún más esta funcionalidad en las próximas versiones.
El siguiente diagrama ilustra la arquitectura de los canales de búsqueda.
Vectores de tamaño byte en Lucene
Hasta ahora, el complemento k-NN en OpenSearch admitía la indexación y consulta de vectores de tipo flotante, ocupando cada elemento vectorial 4 bytes. Esto puede resultar costoso en memoria y almacenamiento, especialmente para casos de uso a gran escala. Con la nueva función de vector de bytes en OpenSearch Service versión 2.9, puede reducir los requisitos de memoria en un factor de 4 y reducir significativamente la latencia de búsqueda, con una pérdida mínima de calidad (recuperación). Para obtener más información, consulte Vectores cuantificados en bytes en OpenSearch.
Soporte para nuevos analizadores de lenguaje.
OpenSearch Service anteriormente admitía complementos de análisis de idiomas como IK (chino), Kuromoji (japonés) y Seunjeon (coreano), entre varios otros. Agregamos soporte para Nori (coreano), Sudachi (japonés), Pinyin (chino) y STConvert Analysis (chino). Estos nuevos complementos están disponibles como un nuevo tipo de paquete, ZIP-PLUGIN, junto con el tipo de paquete TXT-DICTIONARY admitido anteriormente. Puedes navegar hasta el Buceo y Alojamiento página de la consola del servicio OpenSearch para asociar estos complementos a su clúster o utilice la API AssociatePackage.
Lanzamientos de 2023: mejoras en la facilidad de uso
El servicio OpenSearch también realizó mejoras en 2023 para mejorar la facilidad de uso dentro de las funciones de búsqueda clave.
Búsqueda semántica con búsqueda neuronal.
Anteriormente, implementar la búsqueda semántica significaba que su aplicación era responsable del middleware para integrar modelos de incrustación de texto en la búsqueda e ingesta, orquestar la codificación del corpus y luego usar una búsqueda k-NN en el momento de la consulta.
Se presenta el servicio OpenSearch búsqueda neuronal en la versión 2.9, lo que permite a los desarrolladores crear y poner en funcionamiento aplicaciones de búsqueda semántica con un trabajo pesado indiferenciado significativamente reducido. Su aplicación ya no necesita ocuparse de la vectorización de documentos y consultas; la búsqueda semántica hace eso e invoca k-NN durante el tiempo de consulta. La búsqueda semántica a través de la función de búsqueda neuronal transforma documentos u otros medios en incrustaciones vectoriales e indexa tanto el texto como sus incrustaciones vectoriales en un índice vectorial. Cuando utiliza una consulta neuronal durante la búsqueda, la búsqueda neuronal convierte el texto de la consulta en una incrustación vectorial, utiliza la búsqueda vectorial para comparar la consulta y las incrustaciones de documentos y devuelve los resultados más cercanos. Esta funcionalidad se lanzó inicialmente como experimental en la versión 2.4 del servicio OpenSearch y ahora está disponible de forma generalizada con la versión 2.9.
Conectores AI/ML para habilitar funciones de búsqueda impulsadas por AI
Con OpenSearch Service 2.9, puede utilizar conectores de IA listos para usar para servicios de IA y aprendizaje automático de AWS y alternativas de terceros para potenciar funciones como la búsqueda neuronal. Por ejemplo, puede conectarse a modelos de ML externos alojados en Amazon SageMaker, que proporciona capacidades integrales para gestionar modelos con éxito en producción. Si desea utilizar los últimos modelos básicos a través de una experiencia totalmente administrada, puede usar conectores para lecho rocoso del amazonas para potenciar casos de uso como la búsqueda multimodal. Nuestra versión inicial incluye un conector para Cohere Embed y, a través de SageMaker y Amazon Bedrock, tiene acceso a más opciones de terceros. Puede configurar algunas de estas integraciones en sus dominios a través del Integraciones de la consola del servicio OpenSearch (consulte la siguiente captura de pantalla) e incluso automatice la implementación del modelo en SageMaker.

Los modelos integrados se catalogan en su dominio de OpenSearch Service, para que su equipo pueda descubrir la variedad de modelos que están integrados y disponibles para su uso. Incluso tiene la opción de habilitar controles de seguridad granulares en sus recursos de modelo y conector para controlar el acceso a nivel de modelo y conector.
Para fomentar un ecosistema abierto, creamos un marco para capacitar a los socios para que creen y publiquen fácilmente conectores de IA. Los proveedores de tecnología pueden simplemente crear un proyecto, que es un documento JSON que describe la comunicación RESTful segura entre OpenSearch y su servicio. Los socios tecnológicos pueden publicar sus conectores en nuestro sitio comunitario y usted puede utilizar inmediatamente estos conectores de IA, ya sea para un clúster autoadministrado o en el servicio OpenSearch. Puede encontrar planos para cada conector en el Repositorio de ML Commons en GitHub.
Búsqueda híbrida respaldada por combinación de puntuaciones
Las tecnologías semánticas, como las incrustaciones de vectores para la búsqueda neuronal y los modelos de lenguaje grande (LLM) de IA generativa para el procesamiento del lenguaje natural, han revolucionado la búsqueda, reduciendo la necesidad de administrar y ajustar manualmente las listas de sinónimos. Por otro lado, la búsqueda basada en texto (léxica) supera a la búsqueda semántica en algunos casos importantes, como números de piezas o nombres de marcas. La búsqueda híbrida, la combinación de los dos métodos, proporciona una relevancia de búsqueda un 14 % mayor (medida por NDCG@10, una medida de la calidad de la clasificación) que BM25 solo, por lo que los clientes quieren utilizar la búsqueda híbrida para obtener lo mejor de ambos. Para obtener más información sobre la precisión y el rendimiento de la puntuación de evaluación comparativa detallada, consulte Mejore la relevancia de la búsqueda con la búsqueda híbrida, generalmente disponible en OpenSearch 2.10.
Hasta ahora, combinarlos ha sido un desafío dadas las diferentes escalas de relevancia de cada método. Anteriormente, para implementar un enfoque híbrido, había que ejecutar múltiples consultas de forma independiente y luego normalizar y combinar puntuaciones fuera de OpenSearch. Con el lanzamiento del nuevo combinación de puntuación híbrida y normalización tipo de consulta en OpenSearch Service 2.11, OpenSearch maneja la normalización y combinación de puntuaciones en una sola consulta, lo que hace que la búsqueda híbrida sea más fácil de implementar y una forma más eficiente de mejorar la relevancia de la búsqueda.
Nuevos métodos de búsqueda
Por último, OpenSearch Service ahora presenta nuevos métodos de búsqueda.
Recuperación neuronal escasa
Se presenta el servicio OpenSearch 2.11 búsqueda neuronal dispersa, un nuevo tipo de método de incrustación dispersa que es similar en muchos aspectos a la indexación clásica basada en términos, pero con palabras y frases de baja frecuencia mejor representadas. La recuperación semántica dispersa utiliza modelos transformadores (como BERT) para crear incrustaciones ricas en información que resuelven el problema de la falta de coincidencia de vocabulario de una manera escalable, al tiempo que tienen un costo computacional y una latencia similares a los de la búsqueda léxica. Esta nueva funcionalidad de recuperación dispersa con OpenSearch ofrece dos modos con diferentes ventajas: un modo de solo documento y un modo bicodificador. El modo de solo documento puede ofrecer un rendimiento de baja latencia más comparable a la búsqueda BM25, con limitaciones para la sintaxis avanzada en comparación con los métodos densos. El modo bicodificador puede maximizar la relevancia de la búsqueda mientras funciona con latencias más altas. Con esta actualización, ahora puede elegir el método que mejor se adapte a sus requisitos de rendimiento, precisión y costo.
Búsqueda multimodal
OpenSearch Service 2.11 introduce la búsqueda multimodal de texto e imágenes mediante búsqueda neuronal. Esta funcionalidad le permite buscar pares de imágenes y texto, como elementos del catálogo de productos (imagen y descripción del producto), en función de la similitud visual y semántica. Esto permite nuevas experiencias de búsqueda que pueden ofrecer resultados más relevantes. Por ejemplo, puede buscar "blusa blanca" para recuperar productos con imágenes que coincidan con esa descripción, incluso si el título del producto es "camisa color crema". El modelo ML que impulsa esta experiencia es capaz de asociar características semánticas y visuales. También puede buscar por imagen para recuperar productos visualmente similares o buscar por texto e imagen para encontrar los productos más similares a un artículo del catálogo de productos en particular.
Ahora puede incorporar estas capacidades en su aplicación para conectarse directamente a modelos multimodales y ejecutar consultas de búsqueda multimodal sin tener que crear middleware personalizado. El modelo Amazon Titan Multimodal Embeddings se puede integrar con OpenSearch Service para admitir este método. Referirse a Búsqueda multimodal para obtener orientación sobre cómo comenzar con la búsqueda semántica multimodal y busque más tipos de entrada que se agregarán en futuras versiones. También puedes probar la demostración de búsqueda intermodal de textos e imágenes, que muestra la búsqueda de imágenes mediante descripciones textuales.
Resumen
OpenSearch Service ofrece una variedad de herramientas diferentes para crear su aplicación de búsqueda, pero la mejor implementación dependerá de su corpus y de sus necesidades y objetivos comerciales. Alentamos a los profesionales de la búsqueda a comenzar a realizar pruebas. los métodos de búsqueda disponibles para encontrar el ajuste adecuado para su caso de uso. En 2024 y en adelante, puede esperar seguir viendo este rápido ritmo de innovación en búsquedas para mantener las últimas y mejores tecnologías de búsqueda al alcance de los profesionales de búsqueda de OpenSearch.
Acerca de los autores
 David Braun es gerente sénior de producto en el equipo OpenSearch de Amazon Web Services. Le apasiona mejorar la facilidad de uso de OpenSearch y ampliar las herramientas disponibles para respaldar mejor todos los casos de uso de los clientes.
David Braun es gerente sénior de producto en el equipo OpenSearch de Amazon Web Services. Le apasiona mejorar la facilidad de uso de OpenSearch y ampliar las herramientas disponibles para respaldar mejor todos los casos de uso de los clientes.
 Stavros Macrakis es gerente técnico senior de productos en el proyecto OpenSearch de Amazon Web Services. Le apasiona brindar a los clientes las herramientas para mejorar la calidad de sus resultados de búsqueda.
Stavros Macrakis es gerente técnico senior de productos en el proyecto OpenSearch de Amazon Web Services. Le apasiona brindar a los clientes las herramientas para mejorar la calidad de sus resultados de búsqueda.
 Dylan Tong es gerente sénior de productos en Amazon Web Services. Dirige las iniciativas de productos para IA y aprendizaje automático (ML) en OpenSearch, incluidas las capacidades de base de datos de vectores de OpenSearch. Dylan tiene décadas de experiencia trabajando directamente con clientes y creando productos y soluciones en el dominio de bases de datos, análisis e IA/ML. Dylan tiene una licenciatura y una maestría en informática de la Universidad de Cornell.
Dylan Tong es gerente sénior de productos en Amazon Web Services. Dirige las iniciativas de productos para IA y aprendizaje automático (ML) en OpenSearch, incluidas las capacidades de base de datos de vectores de OpenSearch. Dylan tiene décadas de experiencia trabajando directamente con clientes y creando productos y soluciones en el dominio de bases de datos, análisis e IA/ML. Dylan tiene una licenciatura y una maestría en informática de la Universidad de Cornell.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-search-enhancements-2023-roundup/

