En la era de los datos, las organizaciones utilizan cada vez más lagos de datos para almacenar y analizar grandes cantidades de datos estructurados y no estructurados. Los lagos de datos proporcionan un depósito centralizado de datos de diversas fuentes, lo que permite a las organizaciones desbloquear información valiosa e impulsar la toma de decisiones basada en datos. Sin embargo, a medida que los volúmenes de datos continúan creciendo, optimizar el diseño y la organización de los datos se vuelve crucial para realizar consultas y análisis eficientes.
Uno de los desafíos clave en los lagos de datos es la posibilidad de que el rendimiento de las consultas sea lento, especialmente cuando se trata de grandes conjuntos de datos. Esto puede atribuirse a factores como un diseño de datos ineficiente, lo que resulta en un escaneo excesivo de datos y un uso ineficiente de los recursos informáticos. Para abordar este desafío, prácticas comunes como la partición y el agrupamiento pueden mejorar significativamente el rendimiento de las consultas y reducir los costos de cálculo.
Separador de ambientes es una técnica que divide un gran conjunto de datos en partes más pequeñas y manejables según criterios específicos, como fecha, región o categoría de producto. Al dividir los datos, las consultas analíticas posteriores pueden omitir particiones irrelevantes, lo que reduce la cantidad de datos que deben escanearse y procesarse. Puede utilizar columnas de partición en la cláusula WHERE en consultas para escanear solo las particiones específicas que su consulta necesita. Esto puede conducir a tiempos de ejecución de consultas más rápidos y una utilización más eficiente de los recursos. Funciona especialmente bien cuando se eligen como clave columnas con baja cardinalidad.
¿Qué sucede si tiene una columna de alta cardinalidad que a veces necesita filtrar por clientes VIP? Cada cliente suele identificarse con un DNI, que puede ser de millones. La partición no es adecuada para columnas de cardinalidad tan alta porque termina con archivos pequeños, filtrado de particiones lento y alto Servicio de almacenamiento simple de Amazon (Amazon S3) Costo de API (se crea un prefijo S3 por valor de columna de partición). Aunque puede utilizar la partición con una clave natural, como ciudad o estado, para limitar su conjunto de datos hasta cierto punto, aún es necesario realizar consultas entre particiones basadas en fechas si sus datos son series temporales.
Aquí es donde agrupamiento entra en juego. El agrupamiento garantiza que todas las filas con los mismos valores de una o más columnas terminen en el mismo archivo. En lugar de un archivo por valor, como ocurre con la partición, se utiliza una función hash para distribuir los valores de manera uniforme entre un número fijo de archivos. Al organizar los datos de esta manera, puede realizar un filtrado eficiente, porque solo es necesario procesar los depósitos relevantes, lo que reduce aún más la sobrecarga computacional.
Existen varias opciones para implementar el agrupamiento en AWS. Un enfoque es utilizar el Atenea amazónica Declaración CREATE TABLE AS SELECT (CTAS), que le permite crear una tabla agrupada directamente desde una consulta. Alternativamente, puedes usar Pegamento AWS para Apache Spark, que proporciona soporte integrado para configuraciones de agrupación durante el proceso de transformación de datos. AWS Glue le permite definir parámetros de agrupación, como la cantidad de depósitos y las columnas en las que se realizará el depósito, lo que proporciona un diseño de datos optimizado para realizar consultas eficientes con Athena.
En esta publicación, analizamos cómo implementar el agrupamiento en lagos de datos de AWS, incluido el uso de la declaración Athena CTAS y AWS Glue para Apache Spark. También cubrimos el agrupamiento de mesas Apache Iceberg.
Caso de uso de ejemplo
En esta publicación, utiliza un conjunto de datos públicos, el Base de datos de superficie integrada de NOAA. Los analistas de datos realizan consultas únicas de datos durante los últimos cinco años a través de Athena. La mayoría de las consultas son para estaciones específicas con tipos de informes específicos. Las consultas deben completarse en 5 segundos y el costo debe optimizarse cuidadosamente. En este escenario, usted es un ingeniero de datos responsable de optimizar el costo y el rendimiento de las consultas.
Por ejemplo, si un analista desea recuperar datos de una estación específica (por ejemplo, ID de estación 123456) con un tipo de informe particular (por ejemplo, CRN01), la consulta podría parecerse a la siguiente consulta:
En el caso de la Base de Datos Integrada de Superficies de la NOAA, la station_id Es probable que la columna tenga una cardinalidad alta, con numerosos identificadores de estación únicos. Por otra parte, el report_type La columna puede tener una cardinalidad relativamente baja, con un conjunto limitado de tipos de informes. Dado este escenario, sería una buena idea dividir los datos por report_type y cubo por station_id.
Con esta estrategia de partición y agrupamiento, Athena puede eliminar primero las particiones para tipos de informes irrelevantes y luego escanear solo los depósitos dentro de la partición relevante que coincidan con el ID de estación especificado, lo que reduce significativamente la cantidad de datos procesados y acelera los tiempos de ejecución de las consultas. Este enfoque no sólo cumple con los requisitos de rendimiento de las consultas, sino que también ayuda a optimizar los costos al minimizar la cantidad de datos escaneados y facturados por cada consulta.
En esta publicación, examinamos cómo el diseño de los datos, en particular el agrupamiento, afecta el rendimiento de las consultas. También comparamos tres formas diferentes de lograr el agrupamiento. La siguiente tabla representa las condiciones para las tablas que se crearán.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | pegamento_cubo | athena_bucketed_iceberg |
| Formato | CSV | parquet | parquet | parquet | parquet |
| Compresión | n / a | Rápido | Rápido | Rápido | Rápido |
| Creado a través de | n / a | Atenea CTAS | Atenea CTAS | Pegamento ETL | Atenea CTAS con Iceberg |
| Motor | n / a | Trino | Trino | Apache Spark | iceberg apache |
| ¿Está dividido? | Si pero con diferente forma. | Sí | Sí | Sí | Sí |
| ¿Está en cubos? | No | No | Sí | Sí | Sí |
noaa_remote_original está dividido por el year columna, pero no por la report_type columna. Esta fila representa si la tabla está dividida por las columnas reales que se utilizan en las consultas.
Tabla de referencia
Para esta publicación, creará varias tablas con diferentes condiciones: algunas sin agrupación y otras con agrupación, para mostrar las características de rendimiento de la agrupación. Primero, creemos una tabla original usando los datos de la NOAA. En los pasos siguientes, ingiere datos de esta tabla para crear tablas de prueba.
Hay varias formas de definir una definición de tabla: ejecutando DDL, un rastreador de AWS Glue, la API del catálogo de datos de AWS Glue, etc. En este paso, ejecutará DDL a través de la consola de Athena.
Complete los siguientes pasos para crear el "bucketing_blog"."noaa_remote_original" tabla en el catálogo de datos:
- Abra la consola de Athena.
- En el editor de consultas, ejecute el siguiente DDL para crear una nueva base de datos de AWS Glue:
- Base de datos bajo Datos, escoger
bucketing_blogpara configurar la base de datos actual. - Ejecute el siguiente DDL para crear la tabla original:
Debido a que los datos de origen tienen campos entre comillas, utilizamos OpenCSVSerde en lugar del predeterminado LazySimpleSerde.
Estos archivos CSV tienen una fila de encabezado, que le decimos a Athena que omita agregando skip.header.line.count y estableciendo el valor en 1.
Para más detalles, consulte OpenCSVSerDe para procesar CSV.
- Ejecute el siguiente DDL para agregar particiones. Agregamos particiones solo durante 5 años de 124 años según el requisito del caso de uso:
- Ejecute el siguiente DML para verificar si puede consultar los datos correctamente:
Ahora está listo para comenzar a consultar la tabla original para examinar el rendimiento de referencia.
- Ejecute una consulta en la tabla original para evaluar el rendimiento de la consulta como punto de referencia. La siguiente consulta selecciona registros para cinco estaciones específicas con tipo de informe
CRN05: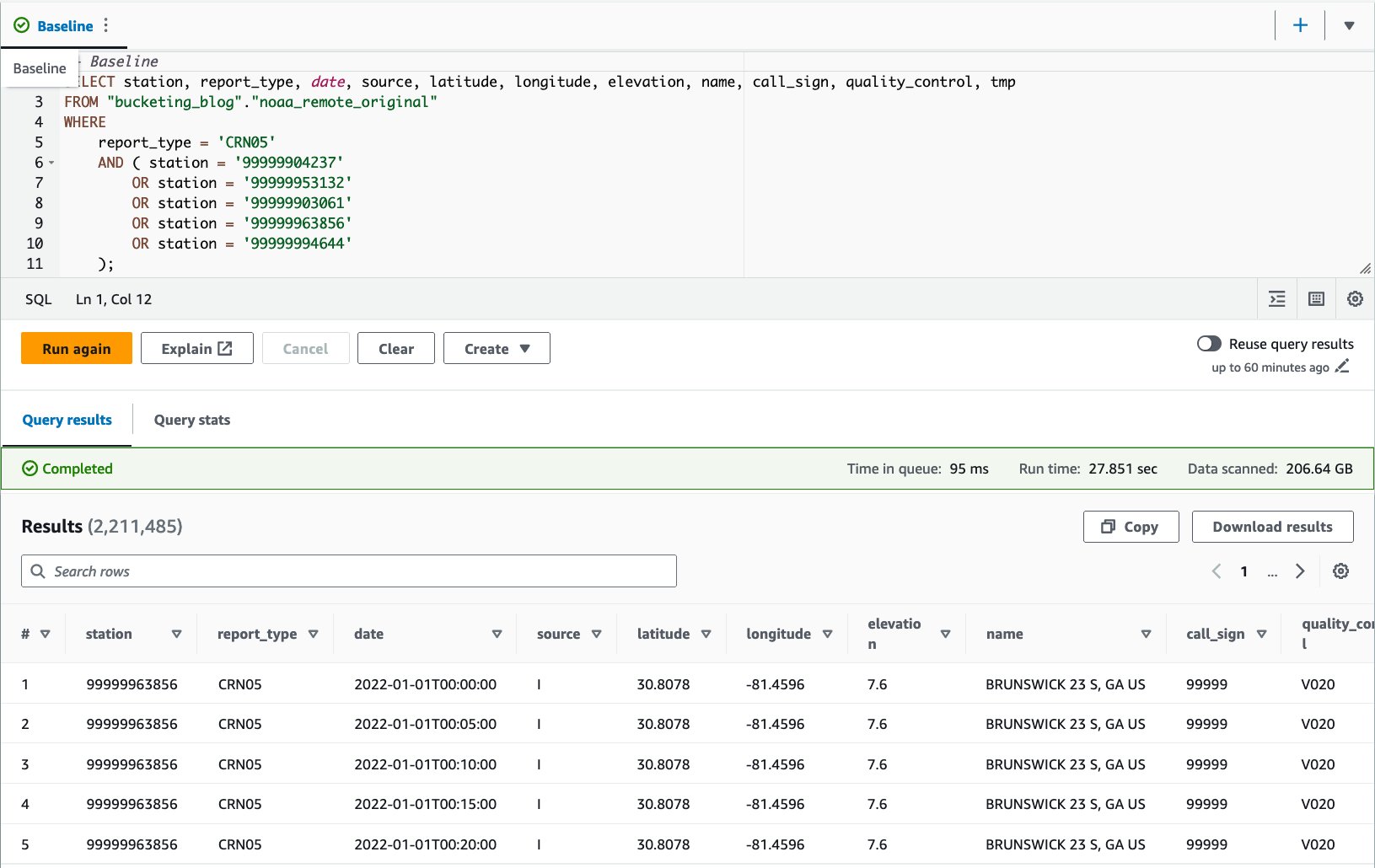
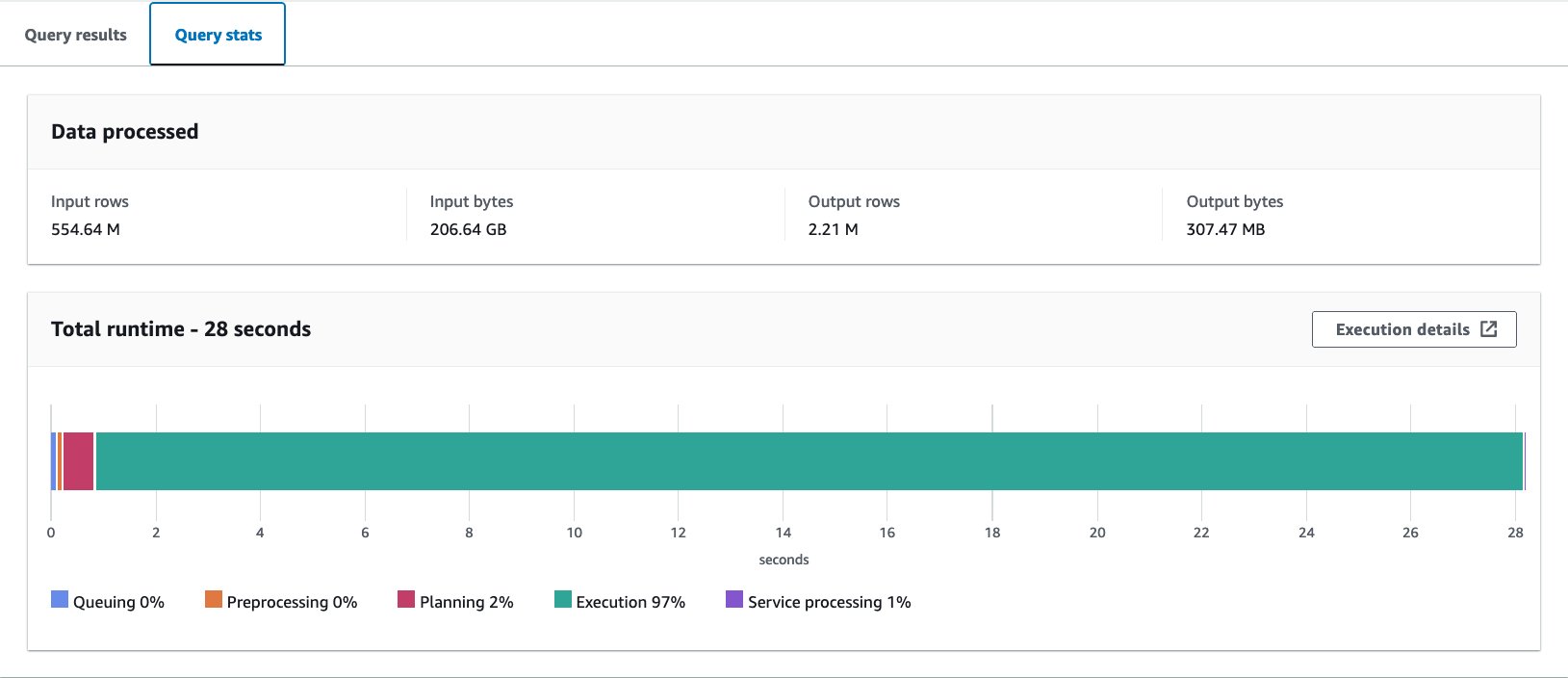
Ejecutamos esta consulta 10 veces. El tiempo de ejecución promedio de 10 consultas es de 27.6 segundos, mucho más que nuestro objetivo de 10 segundos, y se escanean 155.75 GB de datos para devolver 1.65 millones de registros. Este es el rendimiento básico de la tabla sin formato original. Es hora de empezar a optimizar el diseño de los datos desde esta línea de base.
A continuación, crea tablas con condiciones diferentes a las originales: una sin agrupación y otra con agrupación, y las compara.
Optimice el diseño de datos con Athena CTAS
En esta sección, utilizamos una consulta Athena CTAS para optimizar el diseño de los datos y su formato.
Primero, creemos una tabla con particiones pero sin agrupamiento. La nueva tabla está dividida por la columna. report_type porque la mayoría de las consultas esperadas usan esta columna en la cláusula WHERE y los objetos se almacenan como Parquet con compresión Snappy.
- Abra el editor de consultas de Athena.
- Ejecute la siguiente consulta, proporcionando su propio depósito y prefijo de S3:
Sus datos deberían verse como las siguientes capturas de pantalla.
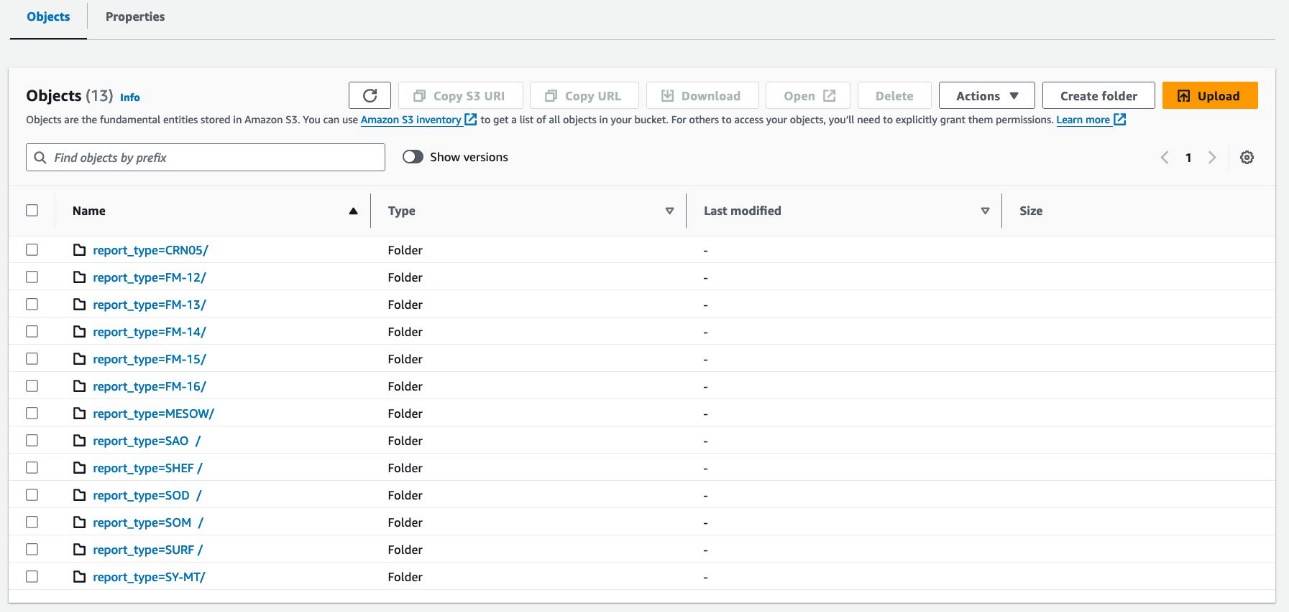
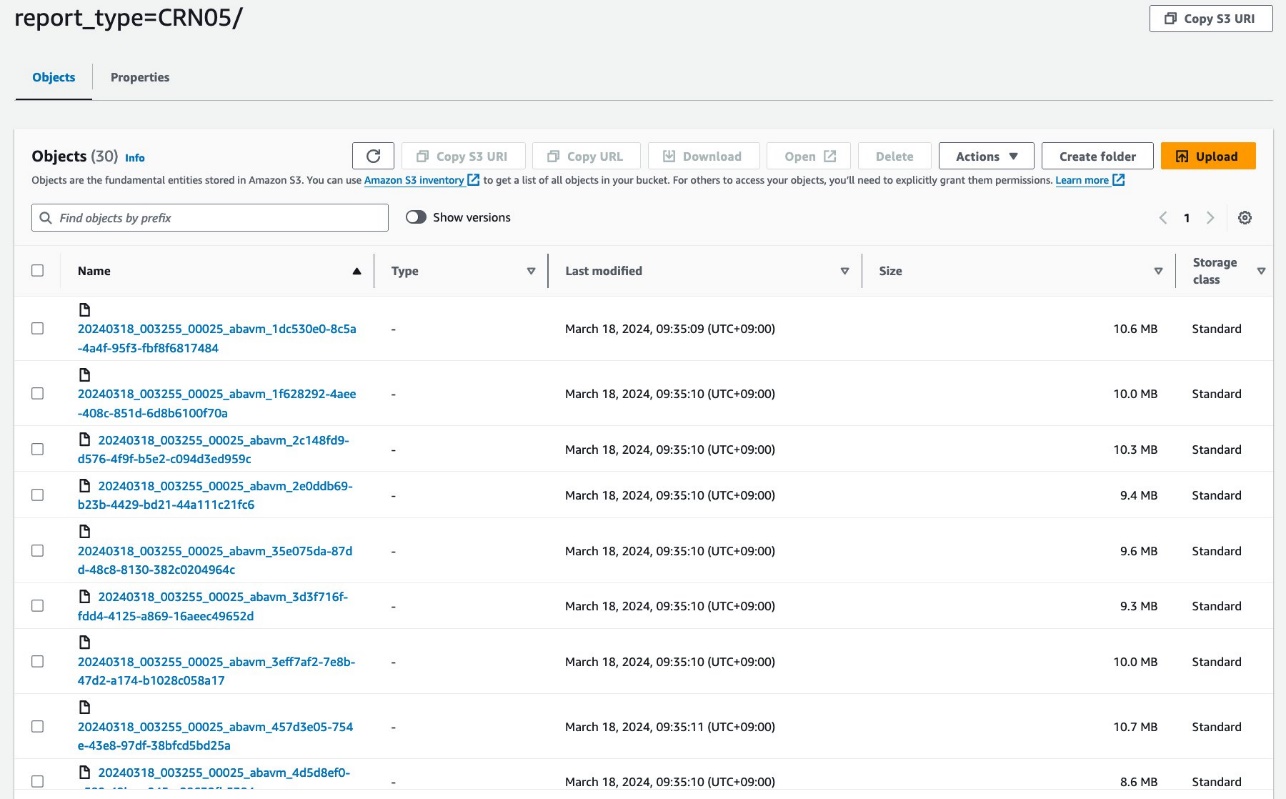
Hay 30 archivos debajo de la partición.
A continuación, crea una tabla con agrupamiento estilo Hive. La cantidad de depósitos debe ajustarse cuidadosamente mediante experimentos para su propio caso de uso. En términos generales, cuantos más depósitos tenga, menor será la granularidad, lo que podría dar lugar a un mejor rendimiento. Por otro lado, demasiados archivos pequeños pueden generar ineficiencia en la planificación y el procesamiento de consultas. Además, el agrupamiento solo funciona si consulta algunos valores de la clave de agrupamiento. Cuantos más valores agregue a su consulta, más probabilidades tendrá de terminar leyendo todos los depósitos.
La siguiente es la consulta de referencia para optimizar:
En este ejemplo, la tabla se dividirá en 16 depósitos mediante una columna de alta cardinalidad (station), que se supone que se utiliza para la cláusula WHERE de la consulta. Todas las demás condiciones siguen siendo las mismas. La consulta de referencia tiene cinco valores en el ID de la estación y se espera que las consultas tengan alrededor de ese número como máximo, que es suficiente menos que el número de depósitos, por lo que 16 deberían funcionar bien. Es posible especificar una cantidad mayor de depósitos, pero no se puede usar CTAS si la cantidad total de particiones excede 100.
- Ejecute la siguiente consulta:
La consulta crea objetos S3 organizados como se muestra en las siguientes capturas de pantalla.
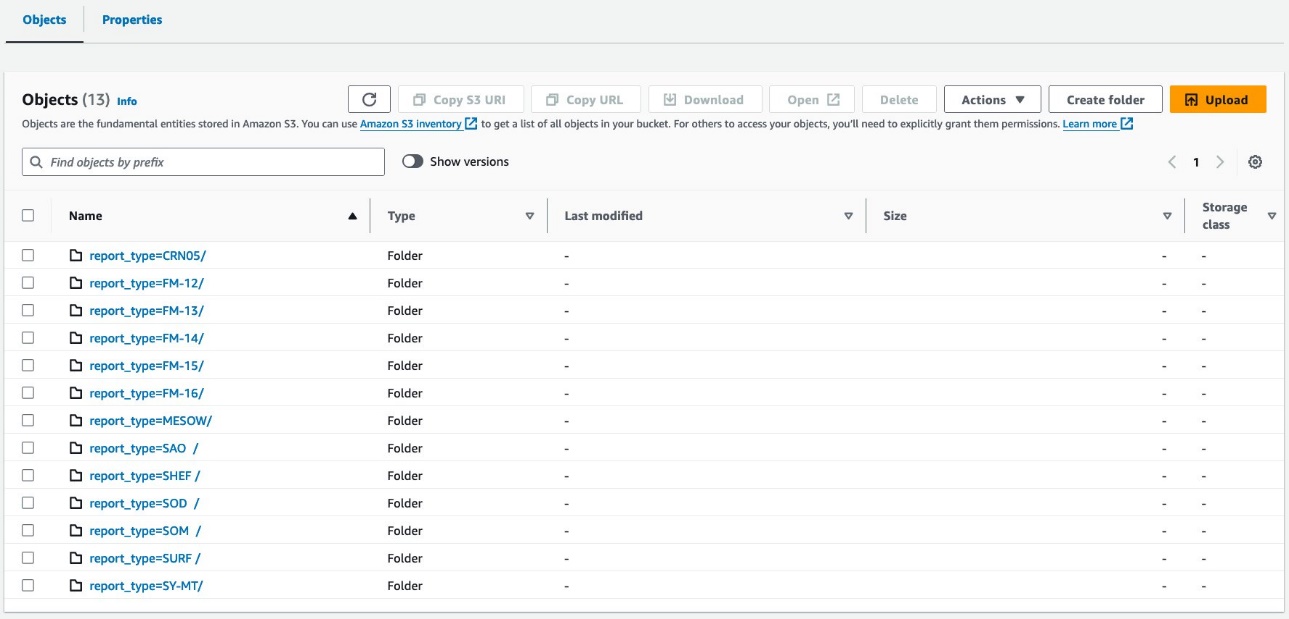

El diseño a nivel de tabla se ve exactamente igual entre athena_non_bucketed y athena_bucketed: hay 13 particiones en cada tabla. La diferencia es la cantidad de objetos debajo de las particiones. Hay 16 objetos (depósitos) por partición, de aproximadamente 10 a 25 MB cada uno en este caso. El número de depósitos es constante en el valor especificado independientemente de la cantidad de datos, pero el tamaño del depósito depende de la cantidad de datos.
Ahora está listo para realizar consultas en cada tabla para evaluar el rendimiento de las consultas. La consulta seleccionará registros con cinco estaciones específicas y tipo de informe. CRN05 durante los últimos 5 años. Aunque no puede ver qué datos de una estación específica se encuentran en qué depósito, Athena los ha calculado y ubicado correctamente.
- Consulta la tabla no agrupada con la siguiente declaración:

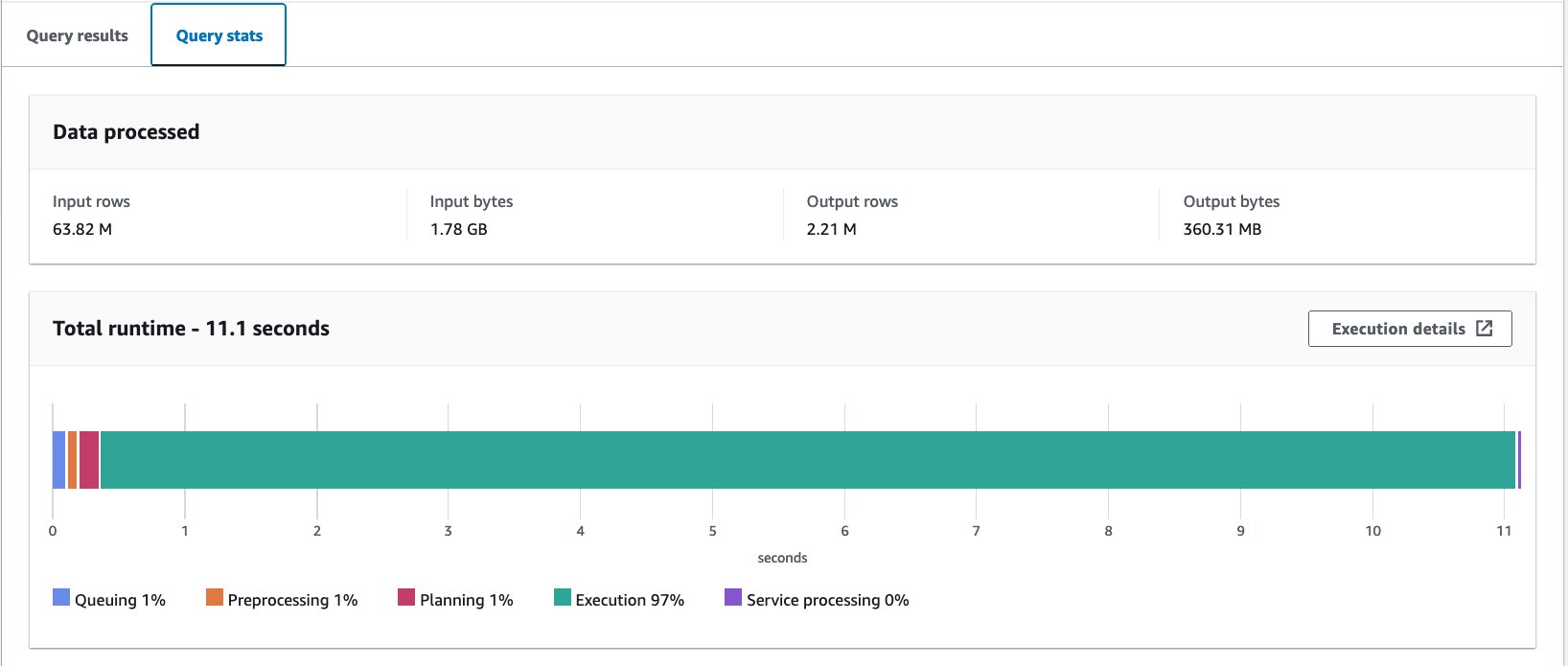
Ejecutamos esta consulta 10 veces. El tiempo de ejecución promedio de las 10 consultas es de 10.95 segundos y se escanean 358 MB de datos para devolver 2.21 millones de registros. Tanto el tiempo de ejecución como el tamaño del escaneo se han reducido significativamente porque ha particionado los datos y ahora puede leer solo una partición donde se omiten 12 particiones de 13. Además, la cantidad de datos escaneados ha bajado de 206 GB a 360 MB, lo que supone una reducción del 99.8%. Esto no se debe sólo a la partición, sino también al cambio de formato a Parquet y la compresión con Snappy.
- Consulta la tabla agrupada con la siguiente declaración:
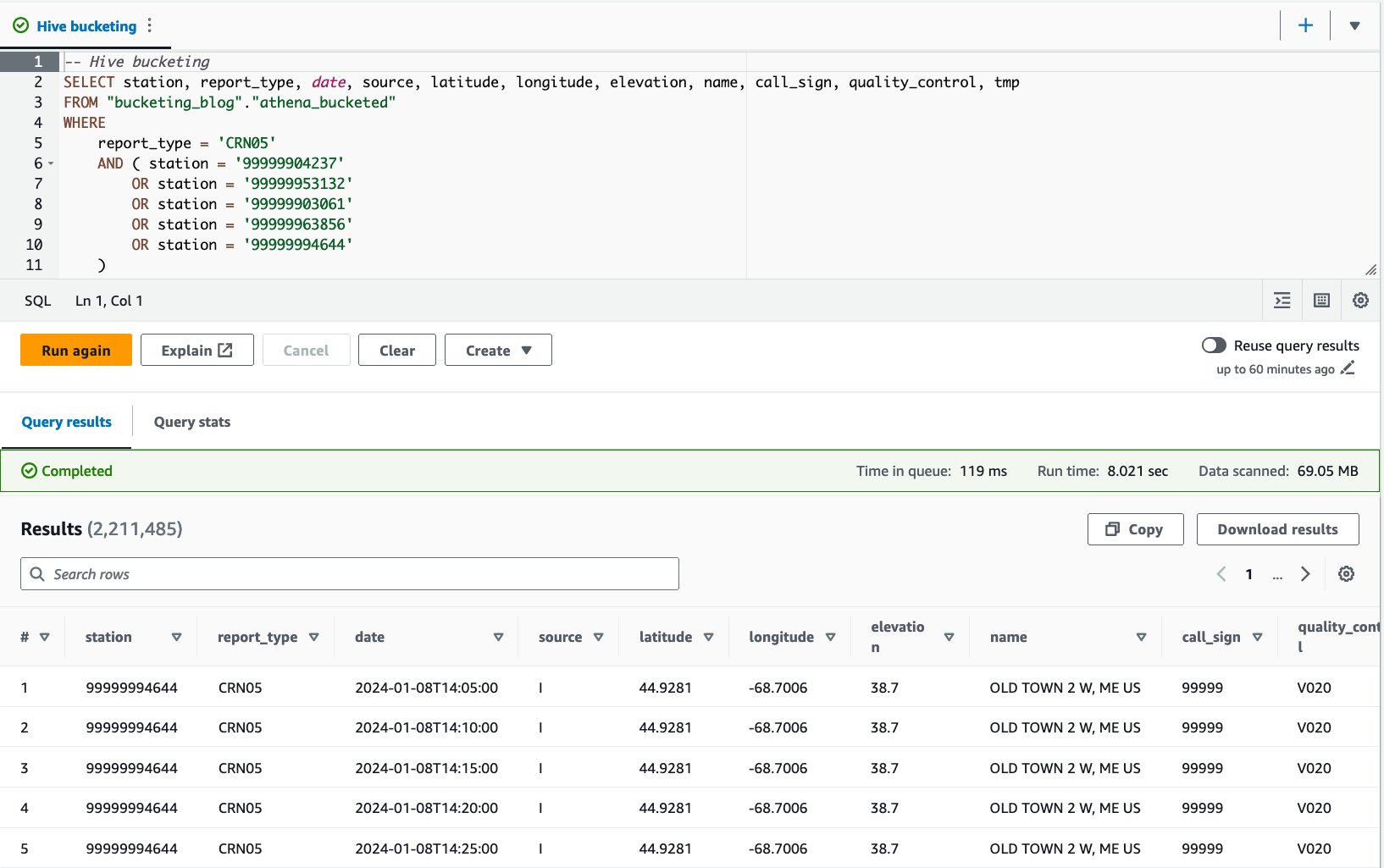
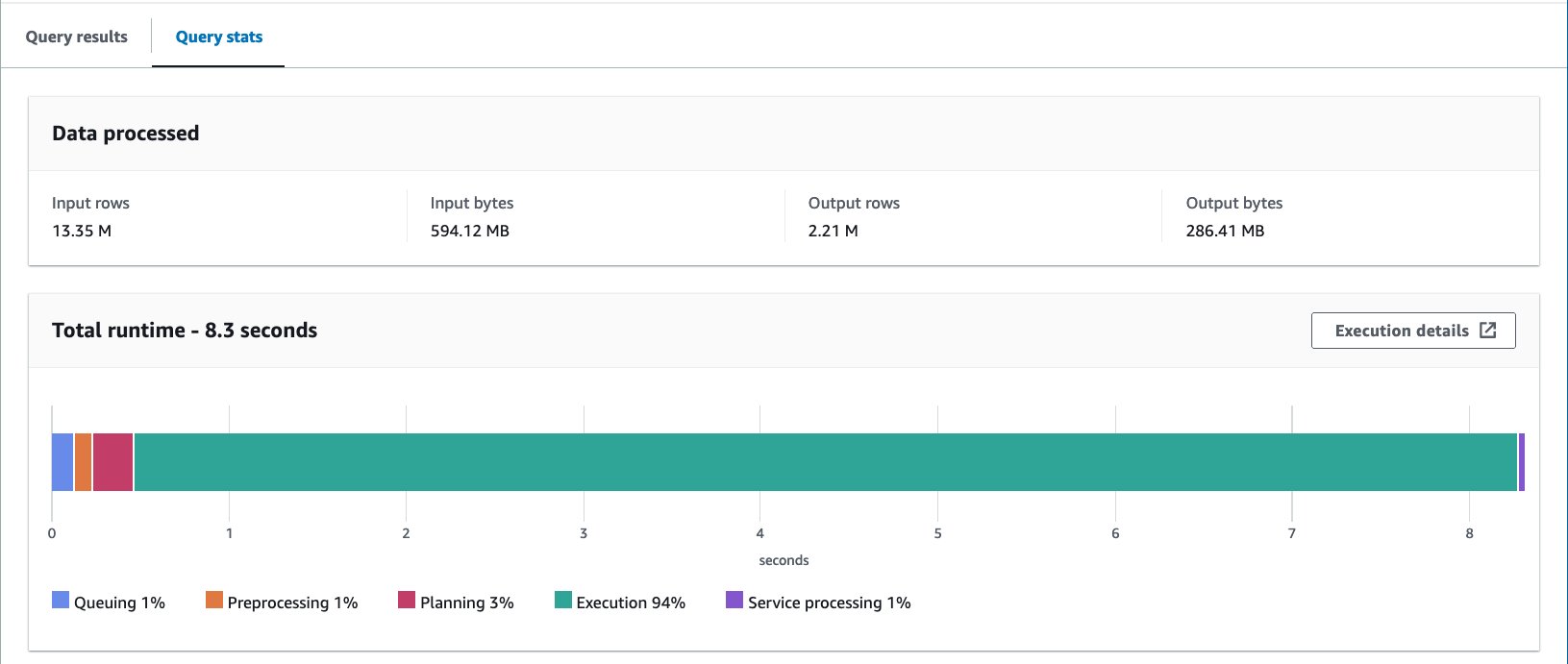
Ejecutamos esta consulta 10 veces. El tiempo de ejecución promedio de las 10 consultas es de 7.82 segundos y se escanean 69 MB de datos para devolver 2.21 millones de registros. Esto significa una reducción del tiempo de ejecución promedio de 10.95 a 7.82 segundos (-29 %) y una reducción drástica de los datos escaneados de 358 MB a 69 MB (-81 %) para devolver la misma cantidad de registros en comparación con la tabla sin cubos. . En este caso, tanto el tiempo de ejecución como los datos escaneados se mejoraron mediante la agrupación. Esto significa que el agrupamiento contribuyó no sólo al rendimiento sino también a la reducción de costos.
Consideraciones
Como se indicó anteriormente, dimensione su depósito con cuidado para maximizar el rendimiento de su consulta. El agrupamiento solo funciona si consulta algunos valores de la clave de agrupamiento. Considere la posibilidad de crear más depósitos que la cantidad de valores esperados en la consulta real.
Además, una consulta de Athena CTAS está limitada a crear hasta 100 particiones a la vez. Si necesita una gran cantidad de particiones, es posible que desee utilizar la extracción, transformación y carga (ETL) de AWS Glue, aunque existe una solución alternativa para dividir en múltiples declaraciones SQL.
Optimice el diseño de datos con AWS Glue ETL
Apache Spark es un marco de procesamiento distribuido de código abierto que permite ETL flexible con PySpark, Scala y Spark SQL. Le permite particionar y agrupar sus datos según sus requisitos. Spark tiene varias opciones de ajuste para acelerar los trabajos. Puede automatizar y monitorear trabajos de Spark sin esfuerzo. En esta sección, utilizamos trabajos ETL de AWS Glue para ejecutar código Spark y optimizar el diseño de los datos.
A diferencia del agrupamiento de Athena, AWS Glue ETL utiliza el agrupamiento basado en Spark como algoritmo de agrupamiento. Todo lo que necesita hacer es agregar la siguiente propiedad de tabla a la tabla: bucketing_format = 'spark'. Para obtener detalles sobre esta propiedad de tabla, consulte Partición y agrupación en Athena.
Complete los siguientes pasos para crear una tabla con agrupamiento a través de AWS Glue ETL:
- En la consola de AWS Glue, elija Empleos de ETL en el panel de navegación.
- Elige Crear trabajo y elige ETL visuales.
- under Agregar nodos, escoger Catálogo de datos de AWS Glue para Fuentes.
- Base de datos, escoger
bucketing_blog. - Mesa, escoger
noaa_remote_original. - under Agregar nodos, escoger Cambiar esquema para Transforma.
- under Agregar nodos, escoger Transformación personalizada para Transforma.
- Nombre, introduzca
ToS3WithBucketing. - Padres de nodo, escoger Cambiar esquema.
- Bloque de código, ingrese el siguiente fragmento de código:
La siguiente captura de pantalla muestra el trabajo creado con AWS Glue Studio para generar una tabla y datos.
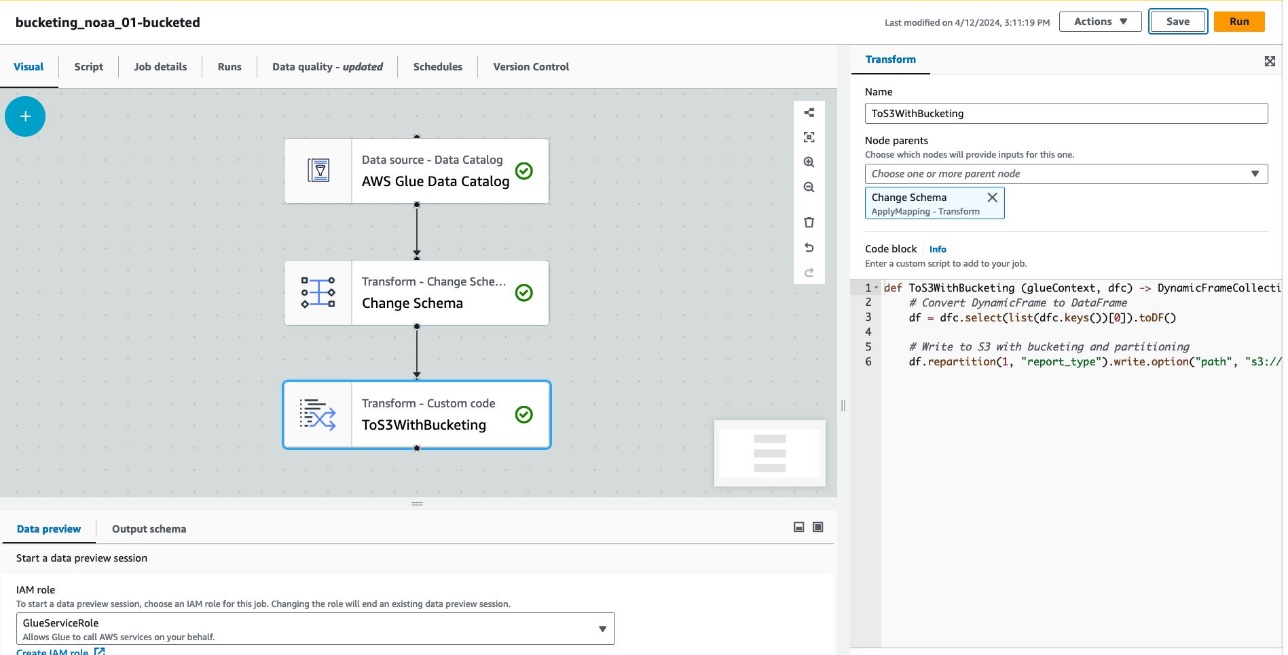
Cada nodo representa lo siguiente:
- El Catálogo de datos de AWS Glue El nodo carga el
noaa_remote_originaltabla del catálogo de datos - El Cambiar esquema El nodo se asegura de cargar las columnas registradas en el catálogo de datos.
- El ToS3ConBucketing El nodo escribe datos en Amazon S3 con particiones y depósitos basados en Spark.
El trabajo se ha creado correctamente en el editor visual.
- under Detalles del trabajo, Para Rol de IAM, escoge tu Gestión de identidades y accesos de AWS (IAM) para este trabajo.
- Tipo de trabajador, escoger G.8X.
- Número solicitado de trabajadores, ingrese 5.
- Elige Guardar, A continuación, elija Ejecutar.
Después de estos pasos, la mesa glue_bucketed. Ha sido creado.
- Elige Mesas en el panel de navegación y elija la tabla
glue_bucketed. - En Acciones menú, seleccione Editar tabla bajo Gestiona.
- En Propiedades de la tabla sección, elija Añada.
- Agregar un par de claves con clave
bucketing_formaty valor chispa.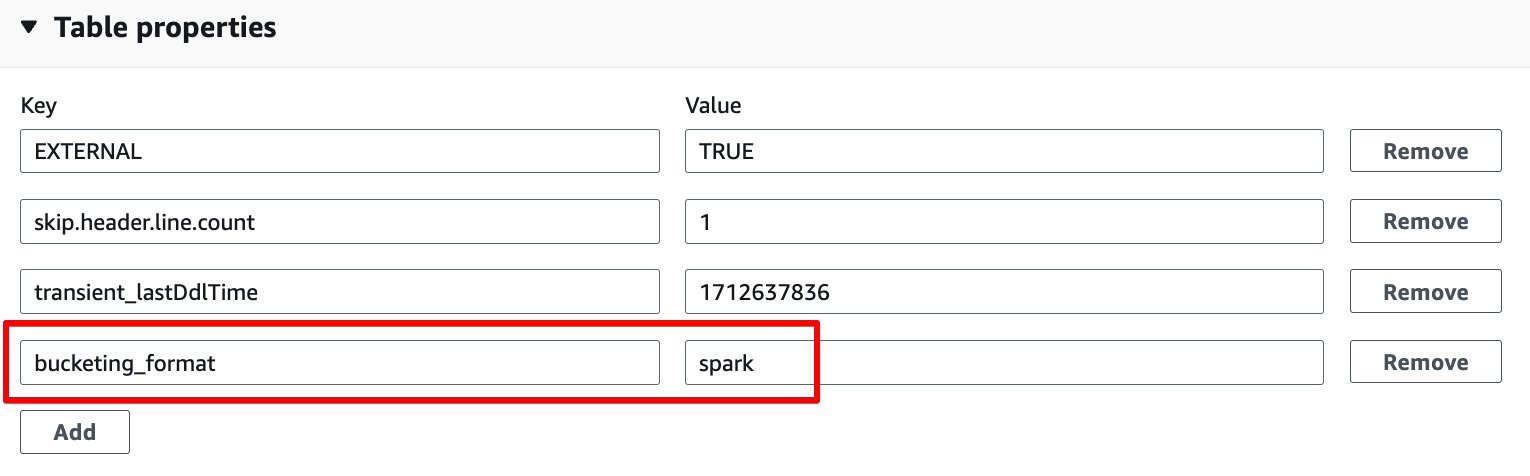
- Elige Guardar.
Ahora es el momento de consultar las tablas.
- Consulta la tabla agrupada con la siguiente declaración:

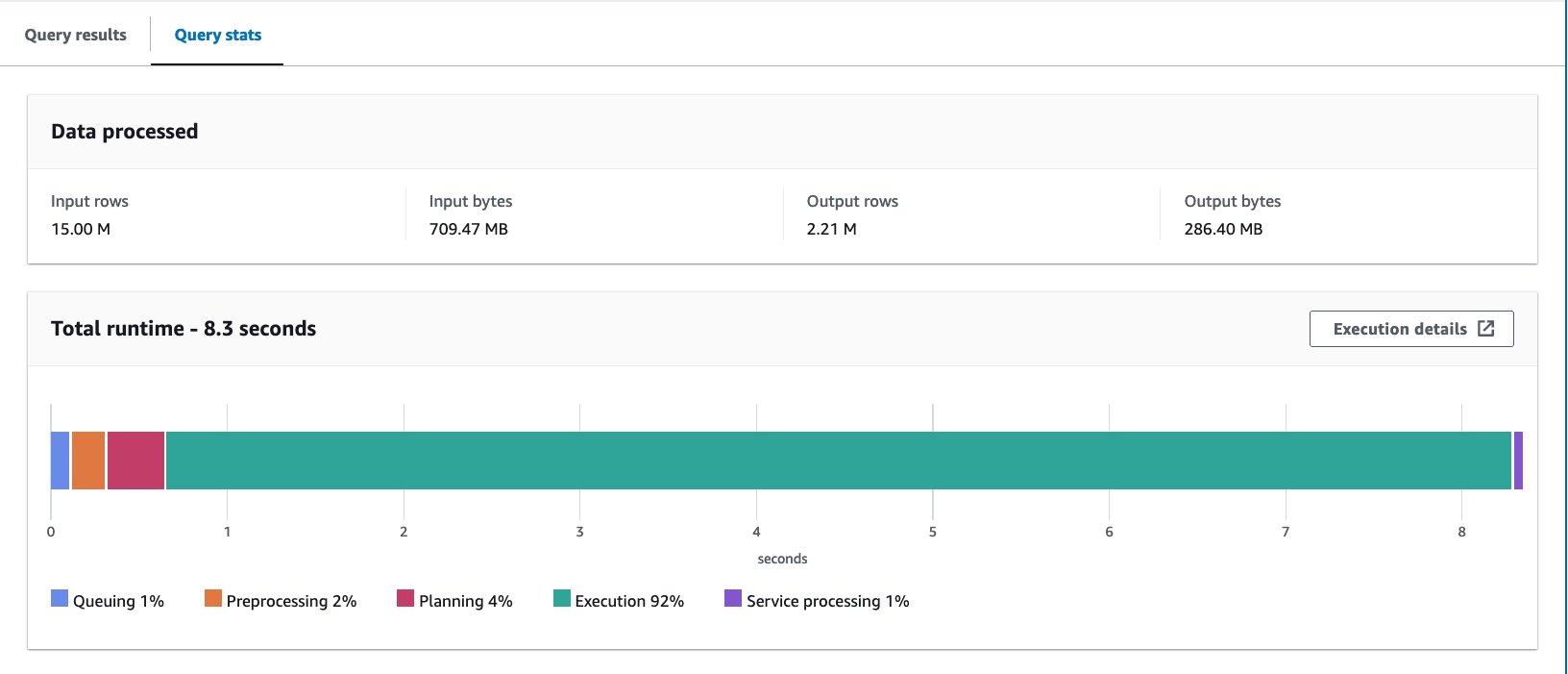
Ejecutamos la consulta 10 veces. El tiempo de ejecución promedio de las 10 consultas es de 7.09 segundos y se escanean 88 MB de datos para devolver 2.21 millones de registros. En este caso, tanto el tiempo de ejecución como los datos escaneados se mejoraron mediante la agrupación. Esto significa que el agrupamiento contribuyó no sólo al rendimiento sino también a la reducción de costos.
El motivo de los bytes más grandes escaneados en comparación con el ejemplo de Athena CTAS es que los valores se distribuyeron de manera diferente en esta tabla. En la tabla agrupada de AWS Glue, los valores se distribuyeron en cinco archivos. En la tabla agrupada de Athena CTAS, los valores se distribuyeron en cuatro archivos. Recuerde que las filas se distribuyen en depósitos mediante una función hash. El algoritmo de agrupación de Spark utiliza una función hash diferente a la de Hive y, en este caso, dio como resultado una distribución diferente entre los archivos.
Consideraciones
Pegar marco dinámico no admite el almacenamiento en depósitos de forma nativa. Debe utilizar Spark DataFrame en lugar de DynamicFrame para agrupar tablas.
Para obtener información sobre cómo ajustar el rendimiento de AWS Glue ETL, consulte Mejores prácticas para ajustar el rendimiento de trabajos de AWS Glue para Apache Spark.
Optimice el diseño de datos de Iceberg con particiones ocultas
Apache Iceberg es un formato de tabla abierta de alto rendimiento para tablas analíticas enormes, que aporta la confiabilidad y simplicidad de las tablas SQL a big data. Recientemente, ha habido una gran demanda para utilizar tablas Apache Iceberg para lograr capacidades avanzadas como transacciones ACID, consultas de viajes en el tiempo y más.
En Iceberg, el agrupamiento funciona de manera diferente al método de tabla de Hive que hemos visto hasta ahora. En Iceberg, la división en depósitos es un subconjunto de la partición y se puede aplicar mediante la transformación de partición de depósitos. La forma en que lo usa y el resultado final es similar al agrupamiento en tablas de Hive. Para obtener más detalles sobre las transformaciones del cubo Iceberg, consulte Detalles de transformación del depósito.
Complete los siguientes pasos:
- Abra el editor de consultas de Athena.
- Ejecute la siguiente consulta para crear una tabla Iceberg con particiones ocultas junto con agrupación:
Sus datos deberían verse como la siguiente captura de pantalla.

Hay dos carpetas: data y metadata. profundizar hasta data.
Verá prefijos aleatorios debajo del data carpeta. Elija el primero para ver sus detalles.
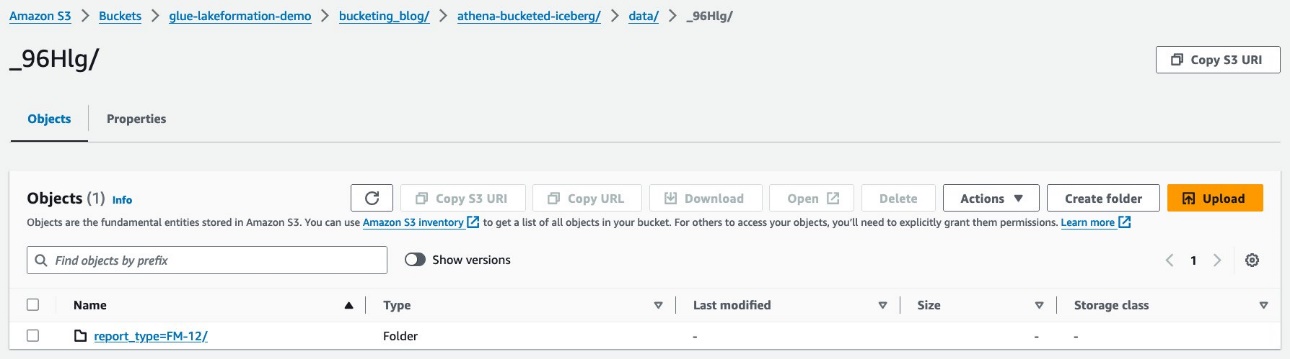
Verá la partición de nivel superior basada en report_type columna. Profundice hasta el siguiente nivel.

Verá la partición de segundo nivel, agrupada con el station columna.
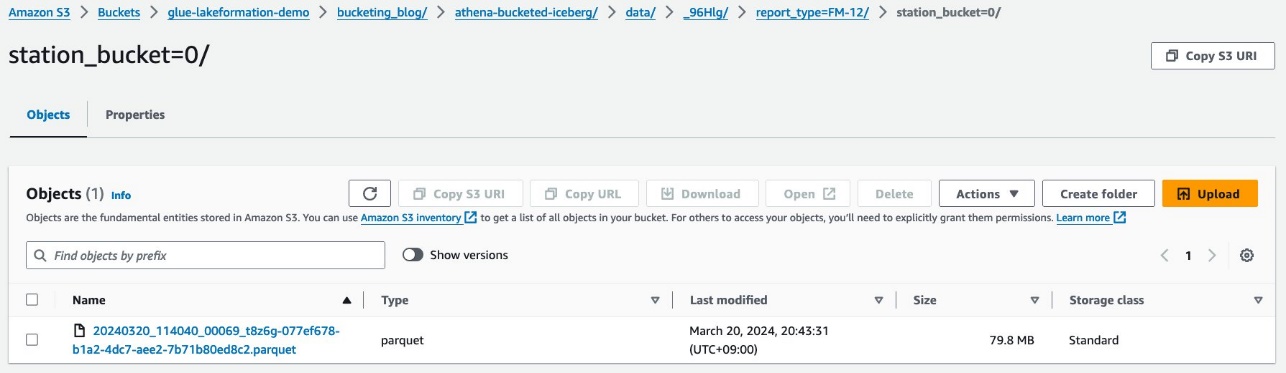
Los archivos de datos de Parquet se encuentran en estas carpetas.
- Consulta la tabla agrupada con la siguiente declaración:
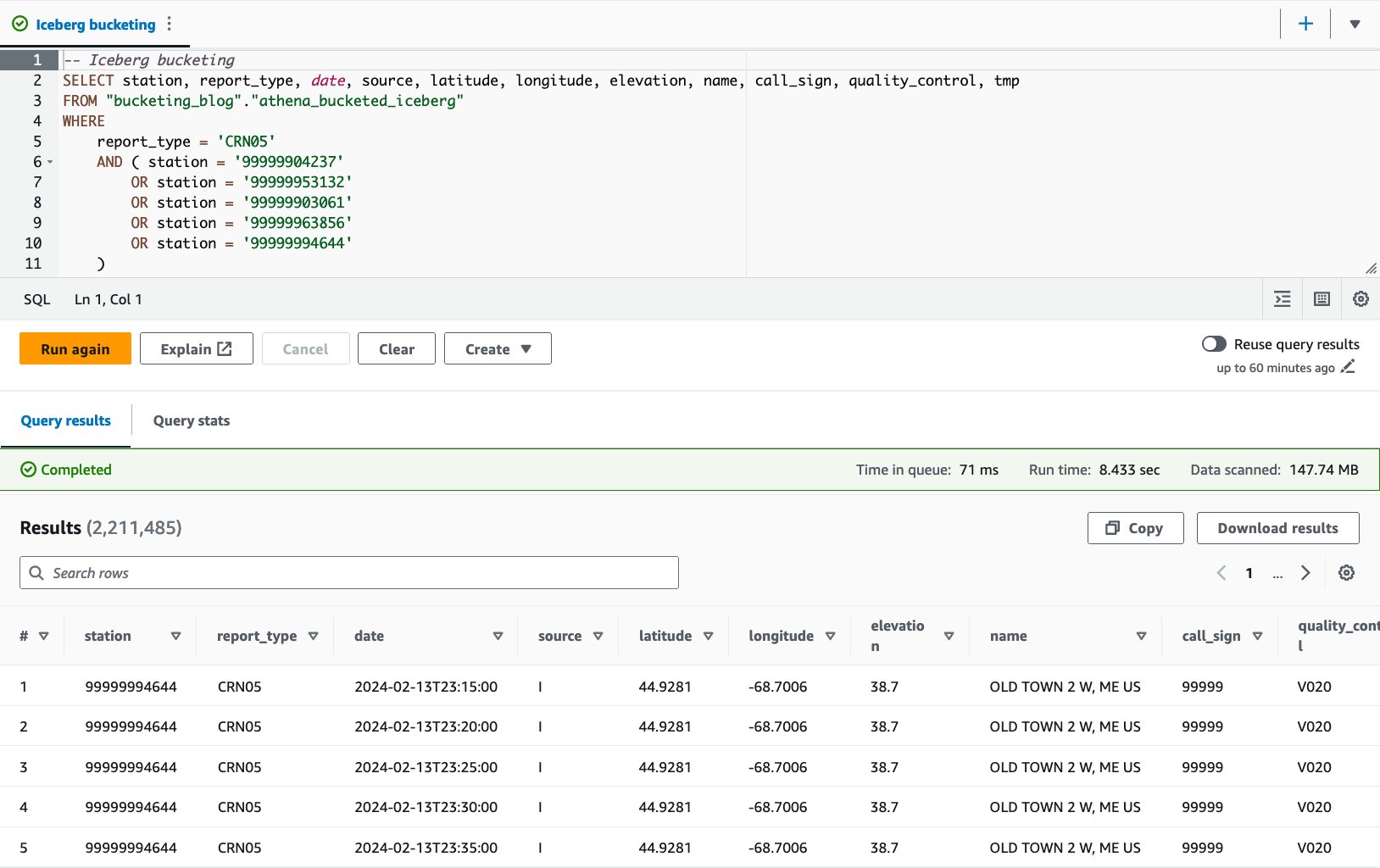
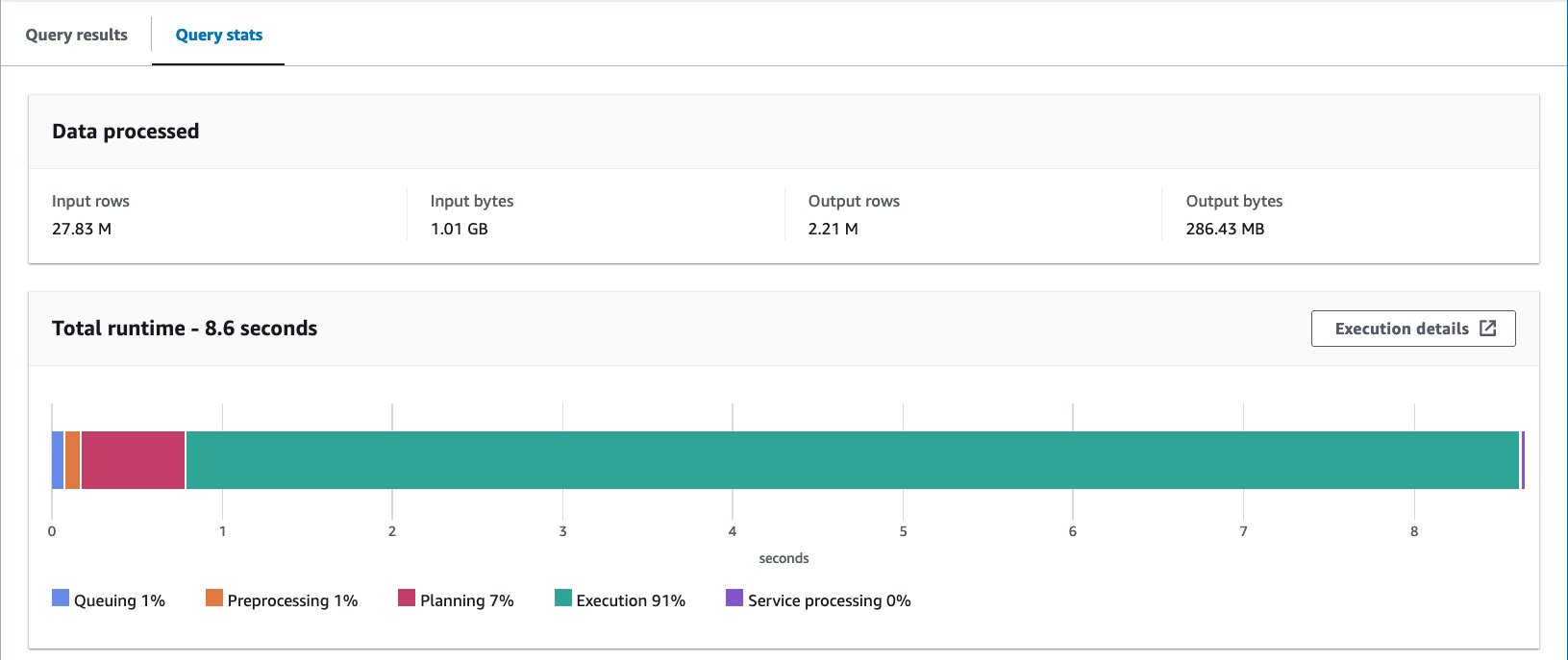
Con la tabla agrupada en Iceberg, el tiempo de ejecución promedio de las 10 consultas es de 8.03 segundos y se escanean 148 MB de datos para devolver 2.21 millones de registros. Esto es menos eficiente que agrupar con AWS Glue o Athena, pero considerando los beneficios de las diversas características de Iceberg, está dentro de un rango aceptable.
Resultados
La siguiente tabla resume todos los resultados.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | pegamento_cubo | athena_bucketed_iceberg |
| Formato | CSV | parquet | parquet | parquet | Iceberg (parquet) |
| Compresión | n / a | Rápido | Rápido | Rápido | Rápido |
| Creado a través de | n / a | Atenea CTAS | Atenea CTAS | Pegamento ETL | Atenea CTAS con Iceberg |
| Motor | n / a | Trino | Trino | Apache Spark | iceberg apache |
| Tamaño de la tabla (GB) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| El número de objetos S3 | 53360 | 376 | 192 | 192 | 195 |
| ¿Está dividido? | Si pero con diferente forma. | Sí | Sí | Sí | Sí |
| ¿Está en cubos? | No | No | Sí | Sí | Sí |
| Formato de agrupación | n / a | n / a | Colmena | Spark | Iceberg |
| Número de cubos | n / a | n / a | 16 | 16 | 16 |
| Tiempo de ejecución promedio (seg) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| Tamaño escaneado (MB) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
Con athena_bucketed, glue_bucketedy athena_bucketed_iceberg, pudiste alcanzar el objetivo de latencia de 10 segundos. Con la agrupación, obtuvo una reducción del 25 % al 40 % en el tiempo de ejecución y una reducción del 60 % al 85 % en el tamaño del escaneo, lo que puede contribuir tanto a la latencia como a la optimización de costos.
Como puede ver en el resultado, aunque la partición contribuye significativamente a reducir tanto el tiempo de ejecución como el tamaño del análisis, el agrupamiento también puede contribuir a reducirlos aún más.
Athena CTAS es lo suficientemente sencillo y rápido para completar el proceso de agrupación. AWS Glue ETL es más flexible y escalable para lograr casos de uso avanzados. Puede elegir cualquiera de los métodos según sus requisitos y caso de uso, ya que puede aprovechar la agrupación mediante cualquiera de las opciones.
Conclusión
En esta publicación, demostramos cómo optimizar el diseño de los datos de su tabla con particiones y depósitos a través de Athena CTAS y AWS Glue ETL. Demostramos que el agrupamiento contribuye a acelerar la latencia de las consultas y reducir el tamaño del escaneo para optimizar aún más los costos. También analizamos el agrupamiento de tablas Iceberg mediante particiones ocultas.
Combinar solo una técnica para optimizar el diseño de los datos reduciendo el escaneo de datos. Para optimizar todo el diseño de sus datos, recomendamos considerar otras opciones como la partición, el uso de formato de archivo en columnas y la compresión junto con el agrupamiento. Esto puede permitir que sus datos mejoren aún más el rendimiento de las consultas.
¡Feliz cubo!
Acerca de los autores
 Takeshi Nakatani es consultor principal de Big Data en el equipo de Servicios Profesionales en Tokio. Tiene 26 años de experiencia en la industria de TI, con experiencia en arquitectura de infraestructura de datos. En sus días libres puede ser baterista de rock o motociclista.
Takeshi Nakatani es consultor principal de Big Data en el equipo de Servicios Profesionales en Tokio. Tiene 26 años de experiencia en la industria de TI, con experiencia en arquitectura de infraestructura de datos. En sus días libres puede ser baterista de rock o motociclista.
 Noritaka Sekiyama es arquitecto principal de Big Data en el equipo de AWS Glue. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre le gusta andar en bicicleta con su bicicleta de carretera.
Noritaka Sekiyama es arquitecto principal de Big Data en el equipo de AWS Glue. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre le gusta andar en bicicleta con su bicicleta de carretera.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

