Vivimos en la era de los datos y la información en tiempo real, impulsados por aplicaciones de transmisión de datos de baja latencia. Hoy en día, todo el mundo espera una experiencia personalizada en cualquier aplicación y las organizaciones están innovando constantemente para aumentar la velocidad de operación comercial y toma de decisiones. El volumen de datos urgentes producidos está aumentando rápidamente, con la introducción de diferentes formatos de datos en nuevos negocios y casos de uso de clientes. Por lo tanto, es fundamental que las organizaciones adopten una infraestructura de transmisión de datos confiable, escalable y de baja latencia para ofrecer aplicaciones comerciales en tiempo real y mejores experiencias para los clientes.
Esta es la primera publicación de una serie de blogs que ofrece patrones arquitectónicos comunes en la creación de infraestructuras de transmisión de datos en tiempo real utilizando Kinesis Data Streams para una amplia gama de casos de uso. Su objetivo es proporcionar un marco para crear aplicaciones de transmisión de baja latencia en la nube de AWS utilizando Secuencias de datos de Amazon Kinesis y Servicios de análisis de datos personalizados de AWS.
En esta publicación, revisaremos los patrones arquitectónicos comunes de dos casos de uso: análisis de datos de series temporales y microservicios controlados por eventos. En la siguiente publicación de nuestra serie, exploraremos los patrones arquitectónicos en la creación de canales de transmisión para paneles de BI en tiempo real, agentes del centro de contacto, datos del libro mayor, recomendaciones personalizadas en tiempo real, análisis de registros, datos de IoT, captura de datos modificados y datos reales. -datos de marketing de tiempo. Todos estos patrones de arquitectura están integrados con Amazon Kinesis Data Streams.
Transmisión en tiempo real con Kinesis Data Streams
Amazon Kinesis Data Streams es un servicio de transmisión de datos sin servidor y nativo de la nube que facilita la captura, el procesamiento y el almacenamiento de datos en tiempo real a cualquier escala. Con Kinesis Data Streams, puede recopilar y procesar cientos de gigabytes de datos por segundo de cientos de miles de fuentes, lo que le permite escribir fácilmente aplicaciones que procesen información en tiempo real. Los datos recopilados están disponibles en milisegundos para permitir casos de uso de análisis en tiempo real, como paneles de control en tiempo real, detección de anomalías en tiempo real y precios dinámicos. De forma predeterminada, los datos dentro de Kinesis Data Stream se almacenan durante 24 horas con la opción de aumentar la retención de datos a 365 días. Si los clientes desean procesar los mismos datos en tiempo real con múltiples aplicaciones, pueden usar la función Enhanced Fan-Out (EFO). Antes de esta característica, cada aplicación que consumía datos de la transmisión compartía la salida de 2 MB/segundo/fragmento. Al configurar los consumidores de flujo para que utilicen una distribución mejorada, cada consumidor de datos recibe un canal de rendimiento de lectura dedicado de 2 MB/segundo por fragmento para reducir aún más la latencia en la recuperación de datos.
Para lograr alta disponibilidad y durabilidad, Kinesis Data Streams logra una alta durabilidad al replicar sincrónicamente los datos transmitidos en tres zonas de disponibilidad en una región de AWS y le brinda la opción de conservar los datos por hasta 365 días. Por motivos de seguridad, Kinesis Data Streams proporciona cifrado del lado del servidor para que pueda cumplir con estrictos requisitos de administración de datos cifrando sus datos en reposo y puntos finales de interfaz de Amazon Virtual Private Cloud (VPC) para mantener privado el tráfico entre su Amazon VPC y Kinesis Data Streams.
Kinesis Data Streams tiene integraciones nativas con otros servicios de AWS como Pegamento AWS y Puente de eventos de Amazon para crear aplicaciones de transmisión en tiempo real en AWS. Consulte Integraciones de Amazon Kinesis Data Streams para obtener detalles adicionales.
Arquitectura moderna de transmisión de datos con Kinesis Data Streams
Una arquitectura de transmisión de datos moderna con Kinesis Data Streams se puede diseñar como una pila de cinco capas lógicas; Cada capa se compone de múltiples componentes diseñados específicamente que abordan requisitos específicos, como se ilustra en el siguiente diagrama:

La arquitectura consta de los siguientes componentes clave:
- Fuentes de transmisión – Su fuente de datos de transmisión incluye fuentes de datos como datos de secuencia de clics, sensores, redes sociales, dispositivos de Internet de las cosas (IoT), archivos de registro generados mediante el uso de sus aplicaciones web y móviles, y dispositivos móviles que generan datos semiestructurados y no estructurados como flujos continuos. a alta velocidad.
- Ingestión de flujo – La capa de ingesta de flujo es responsable de ingerir datos en la capa de almacenamiento de flujo. Proporciona la capacidad de recopilar datos de decenas de miles de fuentes de datos e ingerirlos en tiempo real. Puedes usar el SDK de Kinesis para ingerir datos de transmisión a través de API, el Biblioteca de productores de Kinesis para crear productores de streaming de alto rendimiento y larga duración, o un agente de kinesis para recopilar un conjunto de archivos e ingerirlos en Kinesis Data Streams. Además, puede utilizar muchas integraciones prediseñadas, como Servicio de migración de bases de datos de AWS (AWS DMS), Amazon DynamoDBy Núcleo de AWS IoT para ingerir datos sin código. También puede ingerir datos de plataformas de terceros como Apache Spark y Apache Kafka Connect.
- Almacenamiento de flujo – Kinesis Data Streams ofrece dos modos para respaldar el rendimiento de datos: bajo demanda y aprovisionado. El modo On-Demand, ahora la opción predeterminada, puede escalarse elásticamente para absorber rendimientos variables, de modo que los clientes no tengan que preocuparse por la gestión de la capacidad y el pago por rendimiento de datos. El modo On-Demand aumenta automáticamente el doble de la capacidad de transmisión por encima de su máxima ingesta de datos histórica para proporcionar capacidad suficiente para picos inesperados en la ingesta de datos. Alternativamente, los clientes que desean un control granular sobre los recursos de transmisión pueden usar el modo Aprovisionado y aumentar y reducir de manera proactiva la cantidad de fragmentos para cumplir con sus requisitos de rendimiento. Además, Kinesis Data Streams puede almacenar datos de streaming hasta 2 horas de forma predeterminada, pero puede extenderse hasta 24 días o 7 días según los casos de uso. Varias aplicaciones pueden consumir la misma transmisión.
- Procesamiento de flujo – La capa de procesamiento de flujo es responsable de transformar los datos a un estado consumible mediante la validación, limpieza, normalización, transformación y enriquecimiento de los datos. Los registros de transmisión se leen en el orden en que se producen, lo que permite realizar análisis en tiempo real, crear aplicaciones basadas en eventos o transmitir ETL (extracción, transformación y carga). Puedes usar Servicio administrado de Amazon para Apache Flink para procesamiento de datos de flujo complejo, AWS Lambda para el procesamiento de datos de flujo sin estado, y Pegamento AWS & EMR de Amazon para computación casi en tiempo real. También puede crear aplicaciones de consumo personalizadas con Biblioteca para consumidores de Kinesis, que se encargará de muchas tareas complejas asociadas con la computación distribuida.
- Destino - La capa de destino es como un destino diseñado específicamente según su caso de uso. Puede transmitir datos directamente a Desplazamiento al rojo de Amazon para almacenamiento de datos y Amazon EventBridge para crear aplicaciones basadas en eventos. También puedes usar Manguera de bomberos de datos de Amazon Kinesis para la integración de transmisión donde puede iluminar el procesamiento de transmisión con AWS Lambda y luego entregar la transmisión procesada a destinos como Amazon S3 lago de datos, servicio OpenSearch para análisis operativos, un almacén de datos Redshift, bases de datos No-SQL como Amazon DynamoDB y bases de datos relacionales como RDS de Amazon para consumir flujos en tiempo real en aplicaciones empresariales. El destino puede ser una aplicación basada en eventos para paneles de control en tiempo real, decisiones automáticas basadas en datos de transmisión procesados, alteración en tiempo real y más.
Arquitectura de análisis en tiempo real para series temporales
Los datos de series de tiempo son una secuencia de puntos de datos registrados durante un intervalo de tiempo para medir eventos que cambian con el tiempo. Algunos ejemplos son los precios de las acciones a lo largo del tiempo, los flujos de clics en páginas web y los registros de dispositivos a lo largo del tiempo. Los clientes pueden utilizar datos de series temporales para monitorear los cambios a lo largo del tiempo, de modo que puedan detectar anomalías, identificar patrones y analizar cómo ciertas variables se ven influenciadas a lo largo del tiempo. Los datos de series temporales generalmente se generan a partir de múltiples fuentes en grandes volúmenes y deben recopilarse de manera rentable casi en tiempo real.
Normalmente, existen tres objetivos principales que los clientes desean lograr al procesar datos de series temporales:
- Obtenga información en tiempo real sobre el rendimiento del sistema y detecte anomalías
- Comprender el comportamiento del usuario final para realizar un seguimiento de las tendencias y consultar/crear visualizaciones a partir de estos conocimientos.
- Tenga una solución de almacenamiento duradera para ingerir y almacenar datos de archivo y de acceso frecuente.
Con Kinesis Data Streams, los clientes pueden capturar continuamente terabytes de datos de series temporales de miles de fuentes para su limpieza, enriquecimiento, almacenamiento, análisis y visualización.
El siguiente patrón de arquitectura ilustra cómo se pueden lograr análisis en tiempo real para datos de series temporales con Kinesis Data Streams:
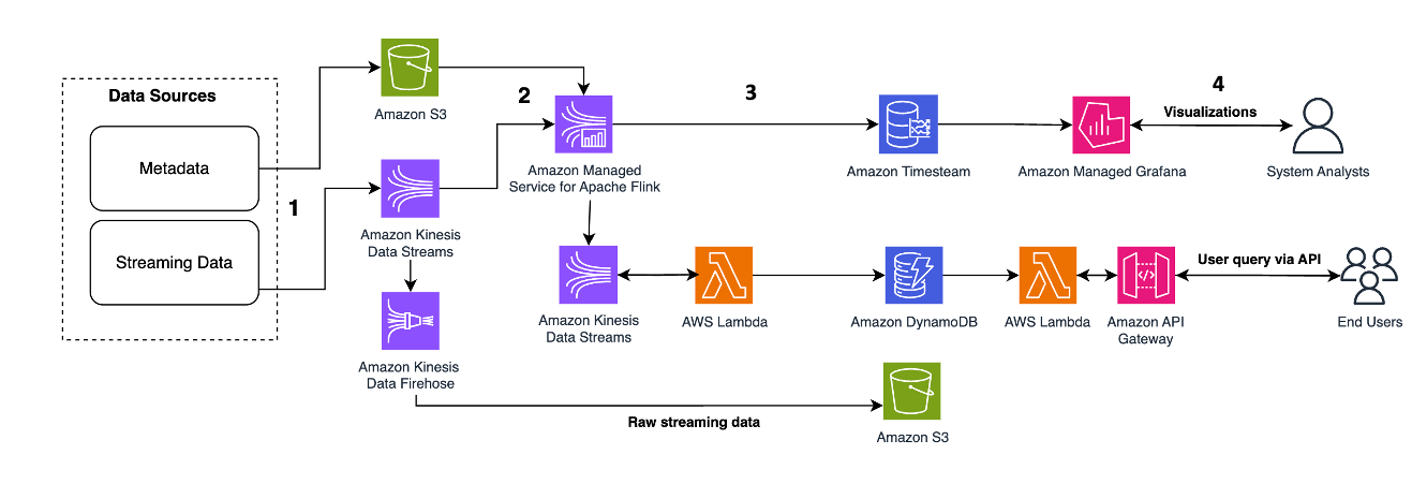
Los pasos del flujo de trabajo son los siguientes:
- Ingestión y almacenamiento de datos – Kinesis Data Streams puede capturar y almacenar continuamente terabytes de datos de miles de fuentes.
- Procesamiento de flujo – Una aplicación creada con Servicio administrado de Amazon para Apache Flink puede leer los registros del flujo de datos para detectar y limpiar cualquier error en los datos de series temporales y enriquecer los datos con metadatos específicos para optimizar el análisis operativo. El uso de un flujo de datos en el medio proporciona la ventaja de utilizar los datos de series temporales en otros procesos y soluciones al mismo tiempo. Luego se invoca una función Lambda con estos eventos y puede realizar cálculos de series temporales en la memoria.
- Destinos – Después de la limpieza y el enriquecimiento, los datos de series de tiempo procesados se pueden transmitir a flujo de tiempo de Amazon base de datos para paneles y análisis en tiempo real, o almacenados en bases de datos como DynamoDB para consultas del usuario final. Los datos sin procesar se pueden transmitir a Amazon S3 para archivarlos.
- Visualización y obtención de conocimientos – Los clientes pueden consultar, visualizar y crear alertas utilizando Servicio gestionado de Amazon para Grafana. Grafana admite fuentes de datos que son backends de almacenamiento para datos de series temporales. Para acceder a sus datos desde Timestream, debe instalar el complemento Timestream para Grafana. Los usuarios finales pueden consultar datos de la tabla de DynamoDB con Puerta de enlace API de Amazon actuando como apoderado.
Consulte Procesamiento casi en tiempo real con Amazon Kinesis, Amazon Timestream y Grafana mostrando un canal de transmisión sin servidor para procesar y almacenar datos de telemetría de dispositivos IoT en un almacén de datos optimizado para series temporales como Amazon Timestream.
Enriquecimiento y reproducción de datos en tiempo real para microservicios de abastecimiento de eventos
Los microservicios son un enfoque arquitectónico y organizativo para el desarrollo de software en el que el software se compone de pequeños servicios independientes que se comunican a través de API bien definidas. Al crear microservicios basados en eventos, los clientes quieren lograr 1. alta escalabilidad para manejar el volumen de eventos entrantes y 2. confiabilidad del procesamiento de eventos y mantener la funcionalidad del sistema frente a fallas.
Los clientes utilizan patrones de arquitectura de microservicios para acelerar la innovación y el tiempo de comercialización de nuevas funciones, porque hace que las aplicaciones sean más fáciles de escalar y más rápidas de desarrollar. Sin embargo, enriquecer y reproducir los datos en una llamada de red a otro microservicio es un desafío porque puede afectar la confiabilidad de la aplicación y dificultar la depuración y el seguimiento de errores. Para resolver este problema, el abastecimiento de eventos es un patrón de diseño eficaz que centraliza los registros históricos de todos los cambios de estado para su enriquecimiento y reproducción, y desacopla las cargas de trabajo de lectura de las de escritura. Los clientes pueden utilizar Kinesis Data Streams como almacén de eventos centralizado para microservicios de abastecimiento de eventos, porque KDS puede 1/ manejar gigabytes de rendimiento de datos por segundo por flujo y transmitir los datos en milisegundos, para cumplir con los requisitos de alta escalabilidad y casi en tiempo real. latencia, 2/ integrarse con Flink y S3 para enriquecer y lograr datos mientras está completamente desacoplado de los microservicios, y 3/ permitir el reintento y la lectura asincrónica en un momento posterior, porque KDS retiene el registro de datos durante un período predeterminado de 24 horas, y opcionalmente hasta 365 días.
El siguiente patrón arquitectónico es una ilustración genérica de cómo se pueden utilizar Kinesis Data Streams para microservicios de abastecimiento de eventos:
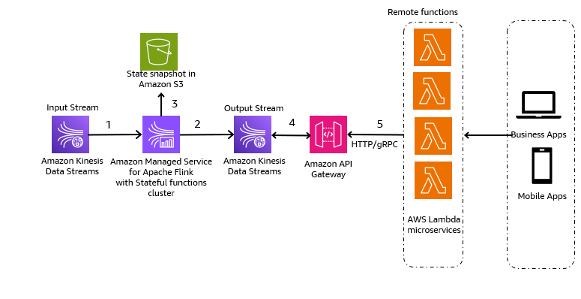
Los pasos en el flujo de trabajo son los siguientes:
- Ingestión y almacenamiento de datos – Puede agregar la entrada de sus microservicios a Kinesis Data Streams para su almacenamiento.
- Procesamiento de flujo – Funciones con estado de Apache Flink simplifica la creación de aplicaciones distribuidas basadas en eventos con estado. Puede recibir los eventos de un flujo de datos de Kinesis de entrada y enrutar el flujo resultante a un flujo de datos de salida. Puede crear un clúster de funciones con estado con Apache Flink según la lógica empresarial de su aplicación.
- Instantánea de estado en Amazon S3 – Puede almacenar la instantánea del estado en Amazon S3 para su seguimiento.
- Flujos de salida – Los flujos de salida se pueden consumir a través de funciones remotas de Lambda a través del protocolo HTTP/gRPC a través de API Gateway.
- Funciones remotas Lambda – Las funciones Lambda pueden actuar como microservicios para diversas aplicaciones y lógica empresarial para servir aplicaciones empresariales y aplicaciones móviles.
Para saber cómo otros clientes crearon sus microservicios basados en eventos con Kinesis Data Streams, consulte lo siguiente:
Consideraciones clave y mejores prácticas
Las siguientes son consideraciones y mejores prácticas a tener en cuenta:
- El descubrimiento de datos debería ser el primer paso en la creación de aplicaciones modernas de transmisión de datos. Debe definir el valor comercial y luego identificar las fuentes de datos de transmisión y las personas de los usuarios para lograr los resultados comerciales deseados.
- Elija su herramienta de ingesta de datos de transmisión según su fuente de datos de transmisión. Por ejemplo, puedes utilizar el SDK de Kinesis para ingerir datos de transmisión a través de API, el Biblioteca de productores de Kinesis para crear productores de streaming de alto rendimiento y larga duración, un agente de kinesis para recopilar un conjunto de archivos e ingerirlos en Kinesis Data Streams, DMS de AWS para casos de uso de transmisión de CDC, y Núcleo de AWS IoT para ingerir datos de dispositivos IoT en Kinesis Data Streams. Puede ingerir datos de transmisión directamente en Amazon Redshift para crear aplicaciones de transmisión de baja latencia. También puede utilizar bibliotecas de terceros como Apache Spark y Apache Kafka para ingerir datos de streaming en Kinesis Data Streams.
- Debe elegir sus servicios de procesamiento de datos de transmisión en función de su caso de uso específico y sus requisitos comerciales. Por ejemplo, puede utilizar Amazon Kinesis Managed Service para Apache Flink para casos de uso de transmisión avanzada con múltiples destinos de transmisión y procesamiento de transmisión con estado complejo o si desea monitorear métricas comerciales en tiempo real (por ejemplo, cada hora). Lambda es bueno para el procesamiento sin estado y basado en eventos. Puedes usar EMR de Amazon para el procesamiento de datos en streaming para utilizar sus marcos de big data de código abierto favoritos. AWS Glue es bueno para el procesamiento de datos de transmisión casi en tiempo real para casos de uso como la transmisión ETL.
- El modo bajo demanda de Kinesis Data Streams se cobra según el uso y aumenta automáticamente la capacidad de recursos, por lo que es bueno para cargas de trabajo de transmisión intensas y mantenimiento con manos libres. El modo aprovisionado se cobra según la capacidad y requiere una gestión proactiva de la capacidad, por lo que es bueno para cargas de trabajo de streaming predecibles.
- Puede utilizar el Calculadora compartida de Kinesis para calcular la cantidad de fragmentos necesarios para el modo aprovisionado. No necesita preocuparse por los fragmentos con el modo bajo demanda.
- Al otorgar permisos, usted decide quién obtiene qué permisos para qué recursos de Kinesis Data Streams. Habilita acciones específicas que desea permitir en esos recursos. Por lo tanto, debe otorgar sólo los permisos necesarios para realizar una tarea. También puede cifrar los datos en reposo mediante una clave administrada por el cliente (CMK) de KMS.
- solicite actualizar el periodo de retención a través de la consola de Kinesis Data Streams o mediante el Incrementar el período de retención de flujo y del Disminuir el período de retención de flujo operaciones basadas en sus casos de uso específicos.
- Compatibilidad con Kinesis Data Streams resharding. La API recomendada para esta función es ActualizarShardCount, que le permite modificar la cantidad de fragmentos en su transmisión para adaptarse a los cambios en la velocidad del flujo de datos a través de la transmisión. Las API de resharding (Split y Merge) se utilizan normalmente para manejar fragmentos activos.
Conclusión
Esta publicación demostró varios patrones arquitectónicos para crear aplicaciones de transmisión de baja latencia con Kinesis Data Streams. Puede crear sus propias aplicaciones de vaporización de baja latencia con Kinesis Data Streams utilizando la información de esta publicación.
Para patrones arquitectónicos detallados, consulte los siguientes recursos:
Si desea crear una visión y una estrategia de datos, consulte el Todo basado en datos de AWS (D2E) programa.
Acerca de los autores
 Raghavarao Sodabathina es arquitecto principal de soluciones en AWS y se centra en análisis de datos, IA/ML y seguridad en la nube. Se relaciona con los clientes para crear soluciones innovadoras que aborden los problemas comerciales de los clientes y aceleren la adopción de los servicios de AWS. En su tiempo libre, Raghavarao disfruta pasar tiempo con su familia, leer libros y ver películas.
Raghavarao Sodabathina es arquitecto principal de soluciones en AWS y se centra en análisis de datos, IA/ML y seguridad en la nube. Se relaciona con los clientes para crear soluciones innovadoras que aborden los problemas comerciales de los clientes y aceleren la adopción de los servicios de AWS. En su tiempo libre, Raghavarao disfruta pasar tiempo con su familia, leer libros y ver películas.
 colgar zuo es gerente sénior de productos en el equipo de Amazon Kinesis Data Streams en Amazon Web Services. Le apasiona desarrollar experiencias de productos intuitivas que resuelvan problemas complejos de los clientes y les permitan alcanzar sus objetivos comerciales.
colgar zuo es gerente sénior de productos en el equipo de Amazon Kinesis Data Streams en Amazon Web Services. Le apasiona desarrollar experiencias de productos intuitivas que resuelvan problemas complejos de los clientes y les permitan alcanzar sus objetivos comerciales.
 Shwetha Radhakrishnan Es arquitecto de soluciones para AWS con enfoque en análisis de datos. Ha estado creando soluciones que impulsan la adopción de la nube y ayudan a las organizaciones a tomar decisiones basadas en datos dentro del sector público. Fuera del trabajo, le encanta bailar, pasar tiempo con amigos y familiares y viajar.
Shwetha Radhakrishnan Es arquitecto de soluciones para AWS con enfoque en análisis de datos. Ha estado creando soluciones que impulsan la adopción de la nube y ayudan a las organizaciones a tomar decisiones basadas en datos dentro del sector público. Fuera del trabajo, le encanta bailar, pasar tiempo con amigos y familiares y viajar.
 bretaña ly es arquitecto de soluciones en AWS. Se centra en ayudar a los clientes empresariales en su proceso de adopción y modernización de la nube y tiene interés en el campo de la seguridad y el análisis. Fuera del trabajo, le encanta pasar tiempo con su perro y jugar al pickleball.
bretaña ly es arquitecto de soluciones en AWS. Se centra en ayudar a los clientes empresariales en su proceso de adopción y modernización de la nube y tiene interés en el campo de la seguridad y el análisis. Fuera del trabajo, le encanta pasar tiempo con su perro y jugar al pickleball.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/

