El resumen es la técnica de condensar información considerable en una forma compacta y significativa, y constituye la piedra angular de la comunicación eficiente en nuestra era rica en información. En un mundo lleno de datos, resumir textos largos en resúmenes breves ahorra tiempo y ayuda a tomar decisiones informadas. El resumen condensa el contenido, ahorra tiempo y mejora la claridad al presentar la información de manera concisa y coherente. El resumen es invaluable para la toma de decisiones y la gestión de grandes volúmenes de contenido.
Los métodos de resumen tienen una amplia gama de aplicaciones que sirven para diversos propósitos, tales como:
- Agregación de noticias – Agregación de noticias Implica resumir artículos de noticias en un boletín para la industria de los medios.
- Resumen de documentos legales – Resumen de documentos legales ayuda a los profesionales legales a extraer información legal clave de documentos extensos como términos, condiciones y contratos.
- Investigación académica – El resumen anota, indexa, condensa y simplifica información importante de artículos académicos.
- Curación de contenido para blogs y sitios web. – Puede crear resúmenes de contenido atractivos y originales para los lectores, especialmente en marketing.
- Informes financieros y análisis de mercado. – Puedes extraer conocimientos financieros a partir de informes y crear resúmenes ejecutivos para presentaciones de inversores en la industria financiera
Con los avances en el procesamiento del lenguaje natural (PNL), los modelos de lenguaje y la inteligencia artificial generativa, resumir textos de diferente extensión se ha vuelto más accesible. Herramientas como LangChain, combinado con un modelo de lenguaje grande (LLM) impulsado por lecho rocoso del amazonas or JumpStart de Amazon SageMaker, simplifica el proceso de implementación.
Esta publicación profundiza en las siguientes técnicas de resumen:
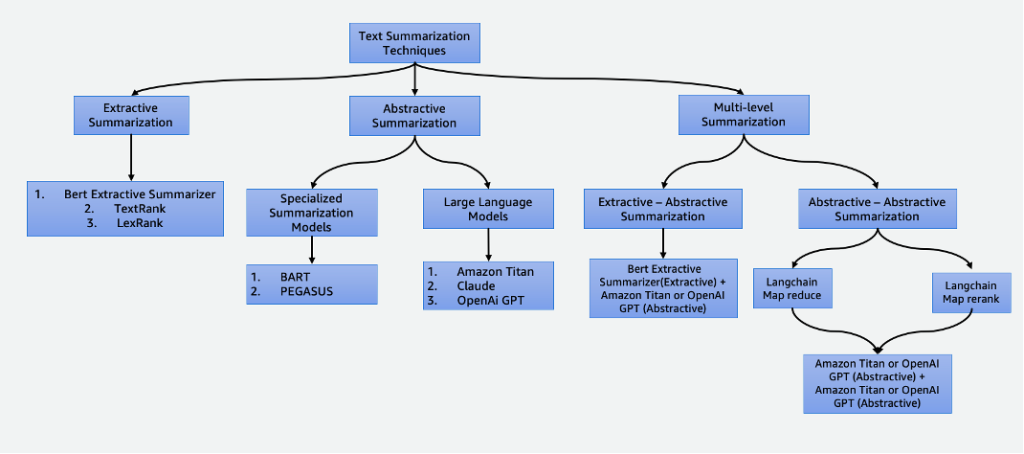
- Resumen extractivo utilizando el resumidor extractivo BERT
- Resumen abstractivo utilizando modelos de resumen especializados y LLM
- Dos técnicas de resumen de varios niveles:
- Resumen extractivo-abstractivo utilizando la estrategia de resumen de contenido extractivo-abstractivo (EACSS)
- Resumen abstracto-abstracto utilizando Map Reduce y Map ReRank
El ejemplo de código completo se encuentra en el Repositorio GitHub. Usted puede lanzar esta solución in Estudio Amazon SageMaker.
Haga clic aquí para abrir la consola de AWS y seguir adelante.
Tipos de resúmenes
Existen varias técnicas para resumir texto, que a grandes rasgos se clasifican en dos enfoques principales: extractiva y abstractivo resumen. Además, las metodologías de resumen multinivel incorporan una serie de pasos que combinan técnicas extractivas y abstractivas. Estos enfoques multinivel son ventajosos cuando se trata de textos con tokens más largos que el límite de un LLM, lo que permite comprender narrativas complejas.
Resumen extractivo
El resumen extractivo es una técnica utilizada en PNL y análisis de texto para crear un resumen extrayendo oraciones clave. En lugar de generar nuevas oraciones o contenido como en el resumen abstractivo, el resumen extractivo se basa en identificar y extraer las partes más relevantes e informativas del texto original para crear una versión condensada.
El resumen extractivo, aunque es ventajoso para preservar el contenido original y garantizar una alta legibilidad al extraer directamente oraciones importantes del texto fuente, tiene limitaciones. Carece de creatividad, es incapaz de generar oraciones novedosas y puede pasar por alto detalles matizados, lo que podría perder información importante. Además, puede producir resúmenes extensos, que a veces abruman a los lectores con información excesiva y no deseada. Existen muchas técnicas de resumen extractivo, como Rango de texto y LexRank. En esta publicación, nos centramos en el resumidor extractivo BERT.
Resumidor extractivo de BERT
El Resumidor extractivo de BERT es un tipo de modelo de resumen extractivo que utiliza el modelo de lenguaje BERT para extraer las oraciones más importantes de un texto. BERTI es un modelo de lenguaje previamente entrenado que se puede ajustar para una variedad de tareas, incluido el resumen de texto. Funciona incorporando primero las oraciones en el texto usando BERT. Esto produce una representación vectorial para cada oración que captura su significado y contexto. Luego, el modelo utiliza un algoritmo de agrupamiento para agrupar las oraciones en grupos. Las oraciones más cercanas al centro de cada grupo se seleccionan para formar el resumen.
En comparación con los LLM, la ventaja del resumidor extractivo BERT es que es relativamente sencillo entrenar e implementar el modelo y es más explicable. La desventaja es que el resumen no es creativo y no genera oraciones. Solo selecciona oraciones del texto original. Esto limita su capacidad para resumir textos complejos o matizados.
Resumen abstracto
El resumen abstractivo es una técnica utilizada en PNL y análisis de texto para crear un resumen que va más allá de la mera extracción de oraciones o frases del texto fuente. En lugar de seleccionar y reorganizar el contenido existente, el resumen abstractivo genera nuevas oraciones o frases que capturan el significado central y las ideas principales del texto original en una forma más condensada y coherente. Este enfoque requiere que el modelo comprenda el contenido del texto y lo exprese de una manera que no necesariamente está presente en el material fuente.
Modelos de resumen especializados
Estos modelos de lenguaje natural previamente entrenados, como BART y PEGASUS, están diseñados específicamente para tareas de resumen de texto. Emplean arquitecturas de codificador-decodificador y tienen parámetros más pequeños en comparación con sus contrapartes. Este tamaño reducido permite un fácil ajuste e implementación en instancias más pequeñas. Sin embargo, es importante tener en cuenta que estos modelos de resumen también vienen con tamaños de tokens de entrada y salida más pequeños. A diferencia de sus homólogos de propósito más general, estos modelos están diseñados exclusivamente para tareas de resumen. Como resultado, la entrada requerida para estos modelos es únicamente el texto que debe resumirse.
Grandes modelos de idiomas
A modelo de lenguaje grande se refiere a cualquier modelo que se somete a entrenamiento en conjuntos de datos extensos y diversos, generalmente a través de aprendizaje autosupervisado a gran escala, y que es capaz de ajustarse para adaptarse a una amplia gama de tareas posteriores específicas. Estos modelos tienen un tamaño de parámetro más grande y funcionan mejor en las tareas. En particular, presentan tamaños de token de entrada sustancialmente más grandes, algunos van hasta 100,000, como el de Anthropic Claude. Para utilizar uno de estos modelos, AWS ofrece el servicio totalmente administrado Amazon Bedrock. Si necesita más control sobre el ciclo de vida del desarrollo del modelo, puede implementar LLM a través de SageMaker.
Dada su naturaleza versátil, estos modelos requieren instrucciones de tareas específicas proporcionadas a través de texto de entrada, una práctica conocida como pronta ingenieria. Este proceso creativo produce distintos resultados según el tipo de modelo y el texto de entrada. La efectividad tanto del desempeño del modelo como de la calidad de las indicaciones influyen significativamente en la calidad final de los resultados del modelo. A continuación se ofrecen algunos consejos cuando la ingeniería solicita un resumen:
- Incluye el texto para resumir. – Introduzca el texto que debe resumirse. Esto sirve como material fuente para el resumen.
- Definir la tarea – Declarar claramente que el objetivo es el resumen del texto. Por ejemplo, "Resuma el siguiente texto: [ingrese el texto]".
- Proporcionar contexto – Ofrecer una breve introducción o contexto para el texto dado que necesita ser resumido. Esto ayuda al modelo a comprender el contenido y el contexto. Por ejemplo, "Le proporcionamos el siguiente artículo sobre la inteligencia artificial y su papel en la atención sanitaria: [texto de entrada]".
- Solicitar el resumen – Solicitar al modelo que genere un resumen del texto proporcionado. Sea claro sobre la extensión o el formato deseado del resumen. Por ejemplo, "Genere un resumen conciso del artículo proporcionado sobre Inteligencia artificial y su papel en la atención médica: [texto de entrada]".
- Establecer restricciones o pautas de longitud – Opcionalmente, guíe la longitud del resumen especificando el número de palabras, el número de oraciones o el límite de caracteres que desee. Por ejemplo, "Genere un resumen que no tenga más de 50 palabras: [ingrese el texto]".
La ingeniería rápida eficaz es fundamental para garantizar que los resúmenes generados sean precisos, relevantes y estén alineados con la tarea de resumen prevista. Refine el mensaje para obtener un resultado de resumen óptimo con experimentos e iteraciones. Una vez que haya establecido la efectividad de las indicaciones, puede reutilizarlas con el uso de plantillas de solicitud.
Resumen multinivel
Los resúmenes extractivos y abstractivos son útiles para textos más cortos. Sin embargo, cuando el texto de entrada excede el límite máximo de tokens del modelo, se hace necesario un resumen de varios niveles. El resumen multinivel implica una combinación de varias técnicas de resumen, como métodos extractivos y abstractivos, para condensar de manera efectiva textos más largos mediante la aplicación de múltiples capas de procesos de resumen. En esta sección, analizamos dos técnicas de resumen de múltiples niveles: resumen extractivo-abstractivo y resumen abstractivo-abstractivo.
Resumen extractivo-abstracto
El resumen extractivo-abstracto funciona generando primero un resumen extractivo del texto. Luego utiliza un sistema de resumen abstractivo para refinar el resumen extractivo, haciéndolo más conciso e informativo. Esto mejora la precisión al proporcionar resúmenes más informativos en comparación con los métodos extractivos por sí solos.
Estrategia de resumen de contenido extractivo-abstracto
La técnica EACSS combina los puntos fuertes de dos técnicas poderosas: el resumidor extractivo BERT para la fase extractiva y los LLM para la fase abstractiva, como se ilustra en el siguiente diagrama.
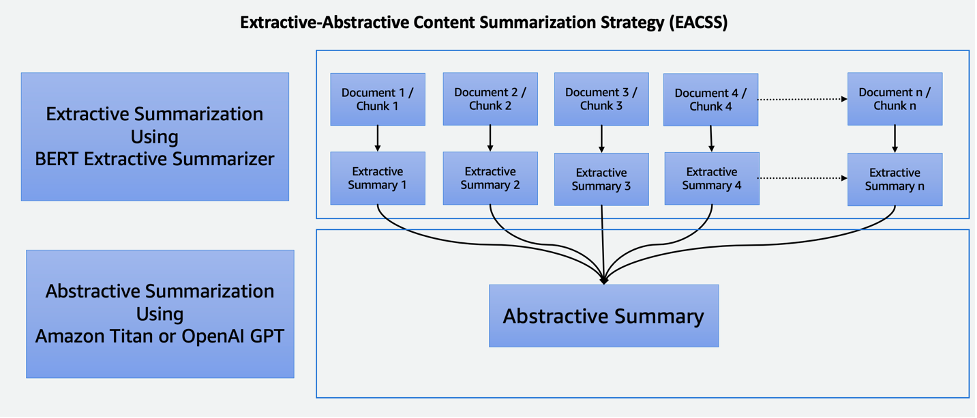
EACSS ofrece varias ventajas, incluida la preservación de información crucial, una mejor legibilidad y adaptabilidad. Sin embargo, implementar EACSS es computacionalmente costoso y complejo. Existe el riesgo de una posible pérdida de información y la calidad del resumen depende en gran medida del rendimiento de los modelos subyacentes, lo que hace que la selección y el ajuste cuidadosos del modelo sean esenciales para lograr resultados óptimos. La implementación incluye los siguientes pasos:
- El primer paso es dividir el documento grande, como un libro, en secciones más pequeñas, o trozos. Estos fragmentos se definen como oraciones, párrafos o incluso capítulos, según la granularidad deseada para el resumen.
- Para la fase extractiva, empleamos el resumidor extractivo BERT. Este componente funciona incorporando las oraciones dentro de cada fragmento y luego empleando un algoritmo de agrupamiento para identificar las oraciones más cercanas a los centroides del grupo. Este paso extractivo ayuda a preservar el contenido más importante y relevante de cada fragmento.
- Habiendo generado resúmenes extractivos para cada fragmento, pasamos a la fase de resumen abstractivo. Aquí, utilizamos LLM conocidos por su capacidad para generar resúmenes coherentes y contextualmente relevantes. Estos modelos toman los resúmenes extraídos como entrada y producen resúmenes abstractivos que capturan la esencia del documento original al tiempo que garantizan legibilidad y coherencia.
Al combinar técnicas de resumen extractivas y abstractivas, este enfoque ofrece una manera eficiente y completa de resumir documentos extensos, como libros. Garantiza que se extraiga información importante y al mismo tiempo permite la generación de resúmenes concisos y legibles por humanos, lo que la convierte en una herramienta valiosa para diversas aplicaciones en el ámbito del resumen de documentos.
Resumen abstracto-abstracto
El resumen abstractivo-abstractivo es un enfoque en el que se utilizan métodos abstractivos tanto para extraer como para generar resúmenes. Ofrece ventajas notables, que incluyen legibilidad mejorada, coherencia y flexibilidad para ajustar la longitud y los detalles del resumen. Destaca en la generación de lenguaje, permitiendo parafrasear y evitar redundancias. Sin embargo, existen inconvenientes. Por ejemplo, es computacionalmente costoso y requiere muchos recursos, y su calidad depende en gran medida de la efectividad de los modelos subyacentes, que, si no están bien entrenados o son versátiles, pueden afectar la calidad de los resúmenes generados. La selección de modelos es crucial para mitigar estos desafíos y garantizar resúmenes abstractivos de alta calidad. Para el resumen abstracto-abstracto, analizamos dos estrategias: Map Reduce y Map ReRank.
Reducción de mapas usando LangChain
Este proceso de dos pasos comprende un Paso de mapa y paso de reducción, como se ilustra en el siguiente diagrama. Esta técnica le permite resumir una entrada que es más larga que el límite de token de entrada del modelo.
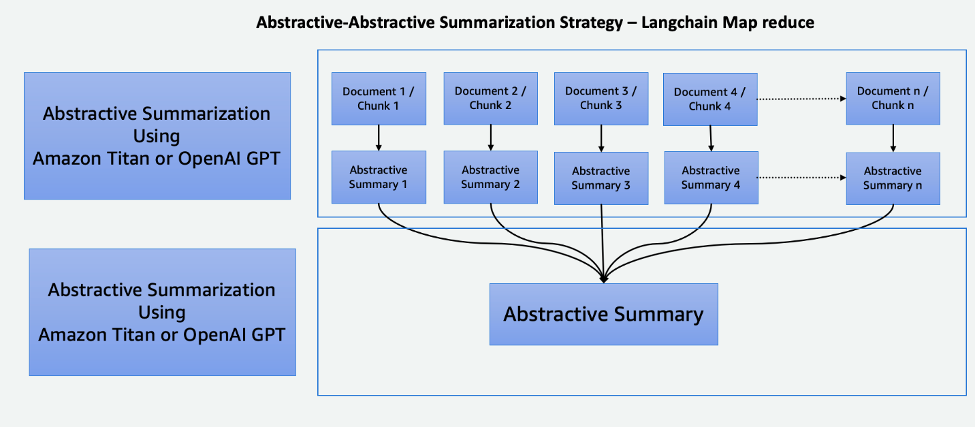
El proceso consta de tres pasos principales:
- Los corpus se dividen en partes más pequeñas que se ajustan al límite de tokens del LLM.
- Usamos un paso de Mapa para aplicar individualmente una cadena LLM que extrae toda la información importante de cada pasaje y su resultado se utiliza como un nuevo pasaje. Dependiendo del tamaño y la estructura de los corpus, estos podrían ser en forma de temas generales o resúmenes breves.
- El paso Reducir combina los pasajes de salida del paso Mapa o un Paso Reducir de modo que se ajuste al límite del token y lo introduzca en el LLM. Este proceso se repite hasta que el resultado final sea un pasaje singular.
La ventaja de utilizar esta técnica es que es altamente escalable y paralelizable. Todo el procesamiento en cada paso es independiente entre sí, lo que aprovecha los sistemas distribuidos o servicios sin servidor y un menor tiempo de cómputo.
Mapear ReRank usando LangChain
Esta cadena ejecuta un mensaje inicial en cada documento que no solo intenta completar una tarea sino que también otorga una puntuación de cuán seguro está en su respuesta. Se devuelve la respuesta con la puntuación más alta.
Esta técnica es muy similar a Map Reduce pero con la ventaja de requerir menos llamadas generales, lo que agiliza el proceso de resumen. Sin embargo, su limitación radica en su incapacidad para fusionar información en varios documentos. Esta restricción lo hace más efectivo en escenarios donde se espera una respuesta única y directa de un documento singular, lo que lo hace menos adecuado para tareas de recuperación de información más complejas o multifacéticas que involucran múltiples fuentes. Es esencial una consideración cuidadosa del contexto y la naturaleza de los datos para determinar si este método es apropiado para necesidades de resumen específicas.
Cohere ReRank utiliza un sistema de reclasificación basado en semántica que contextualiza el significado de la consulta de un usuario más allá de la relevancia de las palabras clave. Se utiliza con sistemas de almacenamiento de vectores, así como con motores de búsqueda basados en palabras clave, lo que le otorga flexibilidad.
Comparación de técnicas de resumen
Cada técnica de resumen tiene sus propias ventajas y desventajas únicas:
- El resumen extractivo preserva el contenido original y garantiza una alta legibilidad, pero carece de creatividad y puede producir resúmenes extensos.
- Los resúmenes abstractivos, si bien ofrecen creatividad y generan resúmenes concisos y fluidos, conllevan el riesgo de modificaciones involuntarias del contenido, desafíos en la precisión del lenguaje y un desarrollo que requiere muchos recursos.
- El resumen extractivo-abstracto de varios niveles resume eficazmente documentos grandes y proporciona una mayor flexibilidad para ajustar la parte extractiva de los modelos. Sin embargo, es costoso, requiere mucho tiempo y carece de paralelización, lo que dificulta el ajuste de parámetros.
- El resumen abstracto-abstracto de varios niveles también resume eficazmente documentos grandes y destaca por su mayor legibilidad y coherencia. Sin embargo, es computacionalmente costoso y requiere muchos recursos, y depende en gran medida de la efectividad de los modelos subyacentes.
La selección cuidadosa del modelo es crucial para mitigar los desafíos y garantizar resúmenes abstractivos de alta calidad en este enfoque. La siguiente tabla resume las capacidades para cada tipo de resumen.
| Aspecto | Resumen extractivo | Resumen abstracto | Resumen multinivel |
| Genere resúmenes creativos y atractivos | No | Sí | Sí |
| Preservar el contenido original | Sí | No | No |
| Equilibrar la preservación de la información y la creatividad. | No | Sí | Sí |
| Adecuado para texto breve y objetivo (la longitud del texto de entrada es menor que los tokens máximos del modelo) | Sí | Sí | No |
| Eficaz para documentos más largos y complejos, como libros (la longitud del texto de entrada es mayor que los tokens máximos del modelo) | No | No | Sí |
| Combina extracción y generación de contenidos. | No | No | Sí |
Las técnicas de resumen multinivel son adecuadas para documentos largos y complejos donde la longitud del texto de entrada excede el límite simbólico del modelo. La siguiente tabla compara estas técnicas.
| Tecnologia | Ventajas | Desventajas |
| EACSS (extractivo-abstracto) | Preserva información crucial, brinda la capacidad de ajustar la parte extractiva de los modelos. | Computacionalmente costoso, posible pérdida de información y carece de paralelización. |
| Reducir mapa (abstracto-abstracto) | Escalable y paralelizable, con menos tiempo de cómputo. La mejor técnica para generar resúmenes creativos y concisos. | Proceso intensivo en memoria. |
| Map ReRank (abstracto-abstracto) | Resumen simplificado con clasificación basada en semántica. | Fusión de información limitada. |
Consejos a la hora de resumir texto
Considere las siguientes mejores prácticas al resumir el texto:
- Tenga en cuenta el tamaño total del token – Esté preparado para dividir el texto si excede los límites simbólicos del modelo o emplear múltiples niveles de resumen cuando utilice LLM.
- Tenga en cuenta los tipos y la cantidad de fuentes de datos. – Combinar información de múltiples fuentes puede requerir transformaciones, una organización clara y estrategias de integración. Cosas de LangChain tiene integración en una amplia variedad de fuentes de datos y tipos de documentos. Simplifica el proceso de combinar texto de diferentes documentos y fuentes de datos con el uso de esta técnica.
- Tenga en cuenta la especialización del modelo. – Algunos modelos pueden sobresalir en ciertos tipos de contenido pero tener dificultades con otros. Es posible que existan modelos ajustados que se adapten mejor a su dominio de texto.
- Utilice resúmenes de varios niveles para grandes cuerpos de texto – Para los textos que exceden los límites de tokens, considere un enfoque de resumen de varios niveles. Comience con un resumen de alto nivel para capturar las ideas principales y luego resuma progresivamente las subsecciones o capítulos para obtener información más detallada.
- Resumir texto por temas – Este enfoque ayuda a mantener un flujo lógico y reducir la pérdida de información, y prioriza la retención de información crucial. Si está utilizando LLM, cree indicaciones claras y específicas que guíen al modelo para resumir un tema en particular en lugar de todo el cuerpo del texto.
Conclusión
El resumen es una herramienta vital en nuestra era rica en información, que permite destilar eficientemente información extensa en formas concisas y significativas. Desempeña un papel fundamental en varios ámbitos y ofrece numerosas ventajas. El resumen ahorra tiempo al transmitir rápidamente contenido esencial de documentos extensos, ayuda a la toma de decisiones al extraer información crítica y mejora la comprensión en la educación y la curación de contenido.
Esta publicación proporcionó una descripción general completa de varias técnicas de resumen, incluidos los enfoques extractivos, abstractivos y multinivel. Con herramientas como LangChain y modelos de lenguaje, puede aprovechar el poder del resumen para agilizar la comunicación, mejorar la toma de decisiones y desbloquear todo el potencial de vastos repositorios de información. La tabla comparativa de esta publicación puede ayudarlo a identificar las técnicas de resumen más adecuadas para sus proyectos. Además, los consejos compartidos en la publicación sirven como pautas valiosas para evitar errores repetitivos al experimentar con LLM para resumir textos. Estos consejos prácticos le permitirán aplicar los conocimientos adquiridos, garantizando un resumen exitoso y eficiente de los proyectos.
Referencias
Sobre los autores
 Nick Biso es ingeniero de aprendizaje automático en AWS Professional Services. Resuelve complejos desafíos organizativos y técnicos utilizando la ciencia y la ingeniería de datos. Además, crea e implementa modelos de IA/ML en la nube de AWS. Su pasión se extiende a su propensión a viajar y diversas experiencias culturales.
Nick Biso es ingeniero de aprendizaje automático en AWS Professional Services. Resuelve complejos desafíos organizativos y técnicos utilizando la ciencia y la ingeniería de datos. Además, crea e implementa modelos de IA/ML en la nube de AWS. Su pasión se extiende a su propensión a viajar y diversas experiencias culturales.
 Suhas chowdary Jonnalagadda es científico de datos en AWS Global Services. Le apasiona ayudar a los clientes empresariales a resolver sus problemas más complejos con el poder de la IA/ML. Ha ayudado a clientes a transformar sus soluciones comerciales en diversas industrias, incluidas finanzas, atención médica, banca, comercio electrónico, medios, publicidad y marketing.
Suhas chowdary Jonnalagadda es científico de datos en AWS Global Services. Le apasiona ayudar a los clientes empresariales a resolver sus problemas más complejos con el poder de la IA/ML. Ha ayudado a clientes a transformar sus soluciones comerciales en diversas industrias, incluidas finanzas, atención médica, banca, comercio electrónico, medios, publicidad y marketing.
 Sala atigrada es un arquitecto principal de la nube/asesor técnico estratégico con amplia experiencia en la migración de clientes y la modernización de sus cargas de trabajo y servicios de aplicaciones a AWS. Con más de 25 años de experiencia en desarrollo y arquitectura de software, es reconocida por su capacidad de profundización, así como por ganarse hábilmente la confianza de clientes y socios para diseñar arquitecturas y soluciones en múltiples pilas de tecnología y proveedores de nube.
Sala atigrada es un arquitecto principal de la nube/asesor técnico estratégico con amplia experiencia en la migración de clientes y la modernización de sus cargas de trabajo y servicios de aplicaciones a AWS. Con más de 25 años de experiencia en desarrollo y arquitectura de software, es reconocida por su capacidad de profundización, así como por ganarse hábilmente la confianza de clientes y socios para diseñar arquitecturas y soluciones en múltiples pilas de tecnología y proveedores de nube.
 Shyam Desai es ingeniero de nube para servicios de big data y aprendizaje automático en AWS. Brinda soporte a aplicaciones y clientes de big data a nivel empresarial utilizando una combinación de experiencia en ingeniería de software con ciencia de datos. Tiene amplio conocimiento en visión por computadora y aplicaciones de imágenes para inteligencia artificial, así como aplicaciones biomédicas y bioinformáticas.
Shyam Desai es ingeniero de nube para servicios de big data y aprendizaje automático en AWS. Brinda soporte a aplicaciones y clientes de big data a nivel empresarial utilizando una combinación de experiencia en ingeniería de software con ciencia de datos. Tiene amplio conocimiento en visión por computadora y aplicaciones de imágenes para inteligencia artificial, así como aplicaciones biomédicas y bioinformáticas.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/techniques-for-automatic-summarization-of-documents-using-language-models/

