Hoy, nos complace anunciar la capacidad de ajustar los modelos Code Llama mediante Meta utilizando JumpStart de Amazon SageMaker. La familia Code Llama de modelos de lenguaje grandes (LLM) es una colección de modelos de generación de código previamente entrenados y ajustados que varían en escala de 7 mil millones a 70 mil millones de parámetros. Los modelos de Code Llama ajustados brindan mayor precisión y explicabilidad que los modelos básicos de Code Llama, como se evidencia en sus pruebas contra evaluación humana y conjuntos de datos MBPP. Puede ajustar e implementar modelos de Code Llama con SageMaker JumpStart usando el Estudio Amazon SageMaker UI con unos pocos clics o usando el SDK de SageMaker Python. El ajuste fino de los modelos Llama se basa en los scripts proporcionados en el Repositorio de GitHub de recetas de llamas de Meta utilizando técnicas de cuantificación PyTorch FSDP, PEFT/LoRA e Int8.
En esta publicación, explicamos cómo ajustar los modelos previamente entrenados de Code Llama a través de SageMaker JumpStart a través de una experiencia de UI y SDK con un solo clic disponible a continuación. Repositorio GitHub.
¿Qué es SageMaker JumpStart?
Con SageMaker JumpStart, los profesionales del aprendizaje automático (ML) pueden elegir entre una amplia selección de modelos básicos disponibles públicamente. Los profesionales del aprendizaje automático pueden implementar modelos básicos en sitios dedicados. Amazon SageMaker instancias de un entorno de red aislado y personalice los modelos con SageMaker para el entrenamiento y la implementación de modelos.
¿Qué es el Código Llama?
Code Llama es una versión especializada en código de llamas 2 que se creó entrenando aún más a Llama 2 en sus conjuntos de datos específicos de código y muestreando más datos de ese mismo conjunto de datos durante más tiempo. Code Llama presenta capacidades de codificación mejoradas. Puede generar código y lenguaje natural sobre el código, tanto a partir de indicaciones de código como de lenguaje natural (por ejemplo, "Escríbame una función que genere la secuencia de Fibonacci"). También puede usarlo para completar y depurar código. Es compatible con muchos de los lenguajes de programación más populares que se utilizan en la actualidad, incluidos Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash y más.
Por qué ajustar los modelos de Code Llama
Metapublicado puntos de referencia de rendimiento de Code Llama en HumanEval y MBPP para lenguajes de codificación comunes como Python, Java y JavaScript. El rendimiento de los modelos Code Llama Python en HumanEval demostró un rendimiento variable en diferentes lenguajes de codificación y tareas que van desde el 38 % en el modelo 7B Python hasta el 57 % en los modelos 70B Python. Además, los modelos Code Llama ajustados en el lenguaje de programación SQL han mostrado mejores resultados, como se evidencia en los puntos de referencia de evaluación de SQL. Estos puntos de referencia publicados destacan los beneficios potenciales de ajustar los modelos de Code Llama, lo que permite un mejor rendimiento, personalización y adaptación a dominios y tareas de codificación específicos.
Ajuste fino sin código a través de la interfaz de usuario de SageMaker Studio
Para comenzar a ajustar sus modelos de Llama usando SageMaker Studio, complete los siguientes pasos:
- En la consola de SageMaker Studio, elija Buen inicio en el panel de navegación.
Encontrará listados de más de 350 modelos que van desde modelos de código abierto hasta modelos propietarios.
- Busca modelos de Code Llama.

Si no ve los modelos de Code Llama, puede actualizar su versión de SageMaker Studio apagándolo y reiniciándolo. Para obtener más información sobre las actualizaciones de versión, consulte Cierre y actualice las aplicaciones de Studio. También puede encontrar otras variantes de modelos eligiendo Explora todos los modelos de generación de código o buscando Code Llama en el cuadro de búsqueda.
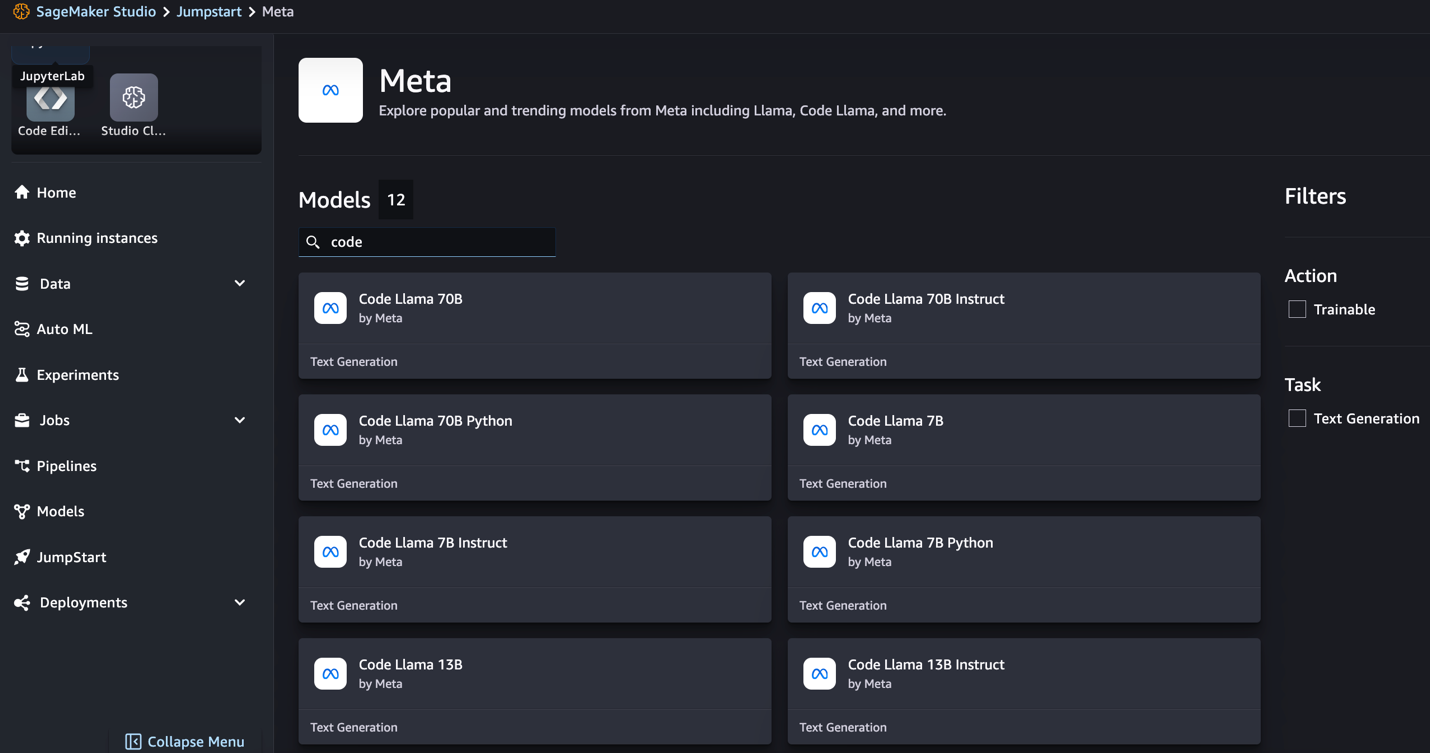
SageMaker JumpStart actualmente admite el ajuste de instrucciones para los modelos Code Llama. La siguiente captura de pantalla muestra la página de ajuste del modelo Code Llama 2 70B.
- Ubicación del conjunto de datos de entrenamiento, puedes señalar el Servicio de almacenamiento simple de Amazon (Amazon S3) depósito que contiene los conjuntos de datos de entrenamiento y validación para realizar ajustes.
- Establezca su configuración de implementación, hiperparámetros y configuraciones de seguridad para realizar ajustes.
- Elige Entrenar para iniciar el trabajo de ajuste en una instancia de SageMaker ML.
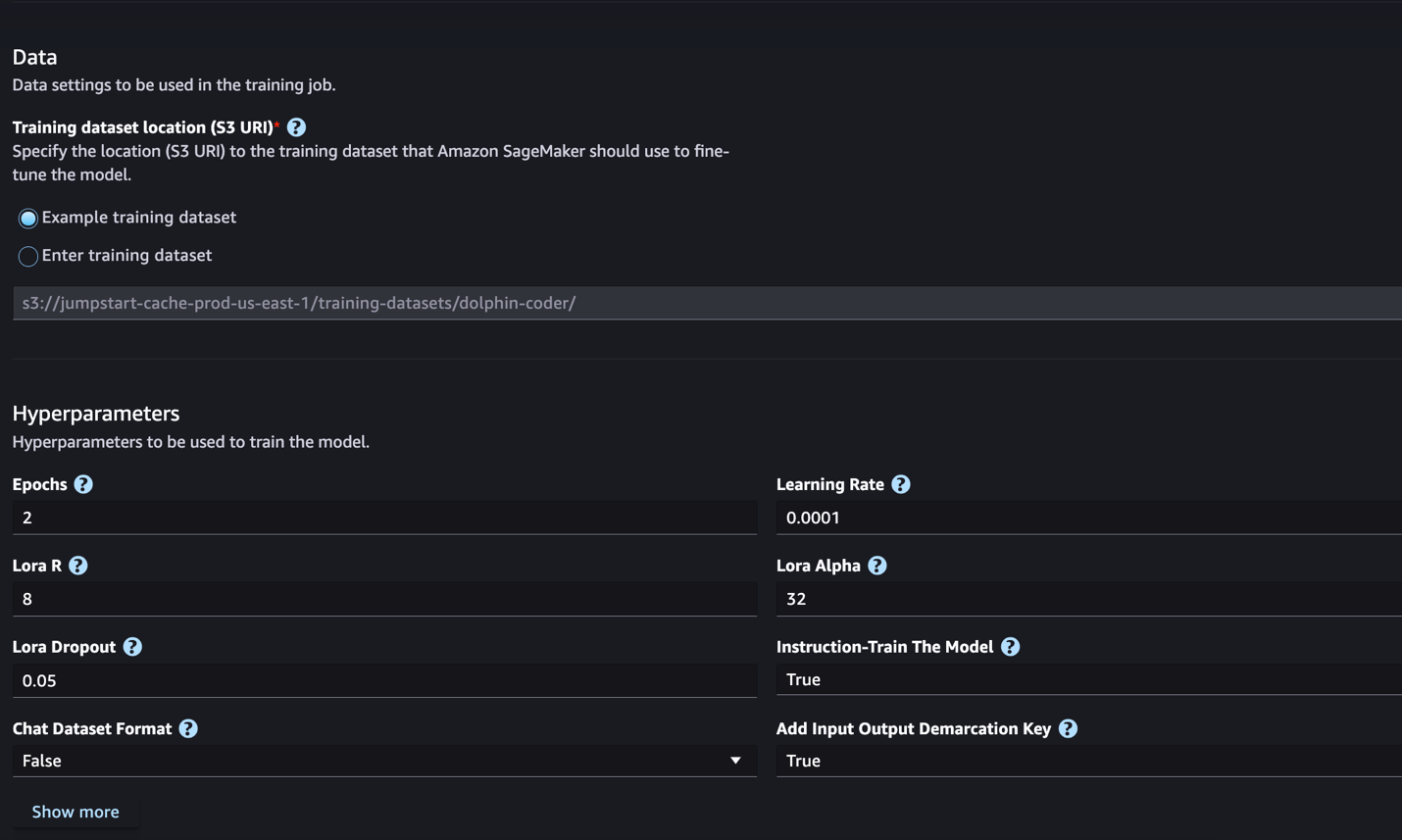
En la siguiente sección analizamos el formato del conjunto de datos que necesita para prepararse para el ajuste de instrucciones.
- Una vez que el modelo esté ajustado, puede implementarlo usando la página del modelo en SageMaker JumpStart.
La opción para implementar el modelo ajustado aparecerá cuando finalice el ajuste, como se muestra en la siguiente captura de pantalla.

Ajuste a través del SDK de SageMaker Python
En esta sección, demostramos cómo ajustar los modelos de Code LIama utilizando el SDK de Python de SageMaker en un conjunto de datos con formato de instrucciones. Específicamente, el modelo está ajustado para un conjunto de tareas de procesamiento del lenguaje natural (PNL) descritas mediante instrucciones. Esto ayuda a mejorar el rendimiento del modelo para tareas invisibles con indicaciones de disparo cero.
Complete los siguientes pasos para completar su trabajo de ajuste. Puede obtener el código de ajuste completo en Repositorio GitHub.
Primero, veamos el formato del conjunto de datos requerido para el ajuste de instrucciones. Los datos de entrenamiento deben tener el formato de líneas JSON (.jsonl), donde cada línea es un diccionario que representa una muestra de datos. Todos los datos de entrenamiento deben estar en una sola carpeta. Sin embargo, se puede guardar en varios archivos .jsonl. El siguiente es un ejemplo en formato de líneas JSON:
La carpeta de formación puede contener un template.json archivo que describe los formatos de entrada y salida. La siguiente es una plantilla de ejemplo:
Para coincidir con la plantilla, cada muestra en los archivos de líneas JSON debe incluir system_prompt, questiony response campos. En esta demostración utilizamos el Conjunto de datos de Dolphin Coder de Abrazando la cara.
Después de preparar el conjunto de datos y cargarlo en el depósito de S3, puede comenzar a realizar ajustes utilizando el siguiente código:
Puede implementar el modelo ajustado directamente desde el estimador, como se muestra en el siguiente código. Para más detalles, consulte el cuaderno en el Repositorio GitHub.
Técnicas de ajuste
Los modelos de idiomas como Llama tienen un tamaño de más de 10 GB o incluso 100 GB. Para ajustar modelos tan grandes se requieren instancias con una memoria CUDA significativamente alta. Además, el entrenamiento de estos modelos puede resultar muy lento debido al tamaño del modelo. Por lo tanto, para un ajuste fino eficiente, utilizamos las siguientes optimizaciones:
- Adaptación de bajo rango (LoRA) – Este es un tipo de ajuste fino eficiente de parámetros (PEFT) para un ajuste fino eficiente de modelos grandes. Con este método, congelas todo el modelo y solo agregas un pequeño conjunto de parámetros o capas ajustables al modelo. Por ejemplo, en lugar de entrenar los 7 mil millones de parámetros para Llama 2 7B, puedes ajustar menos del 1% de los parámetros. Esto ayuda a reducir significativamente el requisito de memoria porque solo necesita almacenar gradientes, estados del optimizador y otra información relacionada con el entrenamiento para solo el 1% de los parámetros. Además, esto ayuda a reducir el tiempo de formación y el coste. Para obtener más detalles sobre este método, consulte LoRA: Adaptación de bajo rango de modelos de lenguaje grande.
- Cuantización Int8 – Incluso con optimizaciones como LoRA, modelos como Llama 70B siguen siendo demasiado grandes para entrenar. Para disminuir la huella de memoria durante el entrenamiento, puede utilizar la cuantificación Int8 durante el entrenamiento. La cuantificación normalmente reduce la precisión de los tipos de datos de punto flotante. Aunque esto reduce la memoria necesaria para almacenar los pesos de los modelos, degrada el rendimiento debido a la pérdida de información. La cuantificación Int8 utiliza sólo un cuarto de precisión, pero no provoca una degradación del rendimiento porque no simplemente elimina los bits. Redondea los datos de un tipo a otro. Para obtener más información sobre la cuantización Int8, consulte LLM.int8(): Multiplicación de matrices de 8 bits para transformadores a escala.
- Datos paralelos completamente fragmentados (FSDP) – Este es un tipo de algoritmo de entrenamiento de datos paralelos que fragmenta los parámetros del modelo entre trabajadores de datos paralelos y, opcionalmente, puede descargar parte del cálculo de entrenamiento a las CPU. Aunque los parámetros están divididos en diferentes GPU, el cálculo de cada microlote es local para el trabajador de la GPU. Fragmenta los parámetros de manera más uniforme y logra un rendimiento optimizado mediante la superposición de la comunicación y el cálculo durante el entrenamiento.
La siguiente tabla resume los detalles de cada modelo con diferentes configuraciones.
| Modelo | Configuración predeterminada | LORA + FSDP | LORA + Sin FSDP | Cuantización Int8 + LORA + Sin FSDP |
| Código Llama 2 7B | LORA + FSDP | Sí | Sí | Sí |
| Código Llama 2 13B | LORA + FSDP | Sí | Sí | Sí |
| Código Llama 2 34B | INT8 + LORA + SIN FSDP | No | No | Sí |
| Código Llama 2 70B | INT8 + LORA + SIN FSDP | No | No | Sí |
El ajuste fino de los modelos Llama se basa en scripts proporcionados por lo siguiente Repositorio GitHub.
Hiperparámetros admitidos para el entrenamiento
El ajuste fino de Code Llama 2 admite una serie de hiperparámetros, cada uno de los cuales puede afectar los requisitos de memoria, la velocidad de entrenamiento y el rendimiento del modelo ajustado:
- época – El número de pasadas que realiza el algoritmo de ajuste fino a través del conjunto de datos de entrenamiento. Debe ser un número entero mayor que 1. El valor predeterminado es 5.
- tasa de aprendizaje – La velocidad a la que se actualizan los pesos del modelo después de trabajar en cada lote de ejemplos de entrenamiento. Debe ser un valor flotante positivo mayor que 0. El valor predeterminado es 1e-4.
- instrucción_afinada – Si se debe entrenar el modelo mediante instrucciones o no. Debe ser
TrueorFalse. El valor predeterminado esFalse. - por_dispositivo_tren_batch_size – El tamaño del lote por núcleo de GPU/CPU para entrenamiento. Debe ser un número entero positivo. El valor predeterminado es 4.
- per_device_eval_batch_size – El tamaño del lote por núcleo de GPU/CPU para evaluación. Debe ser un número entero positivo. El valor predeterminado es 1.
- max_train_samples – Para fines de depuración o capacitación más rápida, trunque la cantidad de ejemplos de capacitación a este valor. El valor -1 significa utilizar todas las muestras de entrenamiento. Debe ser un número entero positivo o -1. El valor predeterminado es -1.
- max_val_samples – Para fines de depuración o capacitación más rápida, trunque el número de ejemplos de validación a este valor. El valor -1 significa utilizar todas las muestras de validación. Debe ser un número entero positivo o -1. El valor predeterminado es -1.
- longitud_entrada_max – Longitud máxima total de la secuencia de entrada después de la tokenización. Las secuencias más largas se truncarán. Si -1,
max_input_lengthse establece en el mínimo de 1024 y la longitud máxima del modelo definida por el tokenizador. Si se establece en un valor positivo,max_input_lengthse establece en el mínimo del valor proporcionado y elmodel_max_lengthdefinido por el tokenizador. Debe ser un número entero positivo o -1. El valor predeterminado es -1. - relación_división_validación – Si el canal de validación es
none, la proporción de la división de validación del tren a partir de los datos del tren debe estar entre 0 y 1. El valor predeterminado es 0.2. - tren_datos_split_seed – Si los datos de validación no están presentes, esto corrige la división aleatoria de los datos de entrenamiento de entrada en los datos de entrenamiento y validación utilizados por el algoritmo. Debe ser un entero. El valor predeterminado es 0.
- preprocesamiento_num_trabajadores – El número de procesos que se utilizarán para el preprocesamiento. Si
None, el proceso principal se utiliza para el preprocesamiento. El valor predeterminado esNone. - lora_r – Lora R. Debe ser un número entero positivo. El valor predeterminado es 8.
- lora_alfa – Lora Alfa. Debe ser un número entero positivo. El valor predeterminado es 32
- lora_dropout – Lora Abandono. debe ser un valor flotante positivo entre 0 y 1. El valor predeterminado es 0.05.
- int8_cuantización - Si
True, el modelo se carga con precisión de 8 bits para entrenamiento. El valor predeterminado para 7B y 13B esFalse. El valor predeterminado para 70B esTrue. - habilitar_fsdp – Si es Verdadero, el entrenamiento utiliza FSDP. El valor predeterminado para 7B y 13B es Verdadero. El valor predeterminado para 70B es Falso. Tenga en cuenta que
int8_quantizationno es compatible con FSDP.
Al elegir los hiperparámetros, considere lo siguiente:
- Fijar
int8_quantization=TrueDisminuye la necesidad de memoria y conduce a un entrenamiento más rápido. - Decreciente
per_device_train_batch_sizeymax_input_lengthreduce el requisito de memoria y, por lo tanto, se puede ejecutar en instancias más pequeñas. Sin embargo, establecer valores muy bajos puede aumentar el tiempo de entrenamiento. - Si no estás usando la cuantización Int8 (
int8_quantization=False), utilice FSDP (enable_fsdp=True) para un entrenamiento más rápido y eficiente.
Tipos de instancias admitidas para capacitación
La siguiente tabla resume los tipos de instancias admitidos para entrenar diferentes modelos.
| Modelo | Tipo de instancia predeterminado | Tipos de instancias admitidas |
| Código Llama 2 7B | ml.g5.12xgrande |
ml.g5.12xgrande, ml.g5.24xgrande, ml.g5.48xgrande, ml.p3dn.24xgrande, ml.g4dn.12xgrande |
| Código Llama 2 13B | ml.g5.12xgrande |
ml.g5.24xgrande, ml.g5.48xgrande, ml.p3dn.24xgrande, ml.g4dn.12xgrande |
| Código Llama 2 70B | ml.g5.48xgrande |
ml.g5.48xgrande ml.p4d.24xgrande |
Al elegir el tipo de instancia, considere lo siguiente:
- Las instancias G5 brindan la capacitación más eficiente entre los tipos de instancias admitidos. Por lo tanto, si tienes instancias G5 disponibles, debes usarlas.
- El tiempo de entrenamiento depende en gran medida de la cantidad de GPU y de la memoria CUDA disponible. Por lo tanto, el entrenamiento en instancias con la misma cantidad de GPU (por ejemplo, ml.g5.2xlarge y ml.g5.4xlarge) es aproximadamente el mismo. Por lo tanto, puede utilizar la instancia más económica para entrenar (ml.g5.2xlarge).
- Cuando se utilizan instancias p3, el entrenamiento se realizará con una precisión de 32 bits porque bfloat16 no es compatible con estas instancias. Por lo tanto, el trabajo de entrenamiento consumirá el doble de memoria CUDA cuando se entrena en instancias p3 en comparación con instancias g5.
Para conocer el costo de la capacitación por instancia, consulte Instancias de Amazon EC2 G5.
Evaluación
La evaluación es un paso importante para valorar el rendimiento de los modelos ajustados. Presentamos evaluaciones tanto cualitativas como cuantitativas para mostrar la mejora de los modelos ajustados con respecto a los no ajustados. En la evaluación cualitativa, mostramos una respuesta de ejemplo de modelos tanto ajustados como no ajustados. En la evaluación cuantitativa utilizamos evaluación humana, un conjunto de pruebas desarrollado por OpenAI para generar código Python para probar la capacidad de producir resultados correctos y precisos. El repositorio HumanEval está bajo licencia MIT. Ajustamos las variantes de Python de todos los modelos de Code LIama en diferentes tamaños (Code LIama Python 7B, 13B, 34B y 70B en el Conjunto de datos de Dolphin Coder), y presentar los resultados de la evaluación en las siguientes secciones.
Evaluación cualitativa
Con su modelo ajustado implementado, puede comenzar a usar el punto final para generar código. En el siguiente ejemplo, presentamos respuestas de las variantes base y mejorada de Code LIama 34B Python en una muestra de prueba en el Conjunto de datos de Dolphin Coder:
El modelo Code Llama ajustado, además de proporcionar el código para la consulta anterior, genera una explicación detallada del enfoque y un pseudocódigo.
Respuesta no ajustada de Code Llama 34b Python:
Respuesta afinada de Code Llama 34B Python
Verdad fundamental
Curiosamente, nuestra versión mejorada de Code Llama 34B Python proporciona una solución dinámica basada en programación para la subcadena palindrómica más larga, que es diferente de la solución proporcionada en la verdad fundamental del ejemplo de prueba seleccionado. Nuestro modelo ajustado razona y explica en detalle la solución basada en programación dinámica. Por otro lado, el modelo no ajustado alucina resultados potenciales justo después de la print declaración (que se muestra en la celda de la izquierda) porque la salida axyzzyx no es el palíndromo más largo de la cadena dada. En términos de complejidad temporal, la solución de programación dinámica es generalmente mejor que el enfoque inicial. La solución de programación dinámica tiene una complejidad temporal de O(n^2), donde n es la longitud de la cadena de entrada. Esto es más eficiente que la solución inicial del modelo no ajustado, que también tenía una complejidad de tiempo cuadrática de O(n^2) pero con un enfoque menos optimizado.
¡Esto parece prometedor! Recuerde, solo ajustamos la variante Code LIama Python con el 10% del Conjunto de datos de Dolphin Coder. ¡Hay mucho más por explorar!
A pesar de las instrucciones detalladas en la respuesta, aún necesitamos examinar la exactitud del código Python proporcionado en la solución. A continuación, utilizamos un marco de evaluación llamado Evaluación humana ejecutar pruebas de integración en la respuesta generada por Code LIama para examinar sistemáticamente su calidad.
Evaluación cuantitativa con HumanEval
HumanEval es un instrumento de evaluación para evaluar las capacidades de resolución de problemas de un LLM en problemas de codificación basados en Python, como se describe en el documento. Evaluación de modelos de lenguaje grandes entrenados en código. Específicamente, consta de 164 problemas de programación originales basados en Python que evalúan la capacidad de un modelo de lenguaje para generar código basado en información proporcionada como firma de función, cadena de documentación, cuerpo y pruebas unitarias.
Para cada pregunta de programación basada en Python, la enviamos a un modelo Code LIama implementado en un punto final de SageMaker para obtener k respuestas. A continuación, ejecutamos cada una de las k respuestas en las pruebas de integración en el repositorio de HumanEval. Si alguna respuesta de las k respuestas pasa las pruebas de integración, contamos que el caso de prueba fue exitoso; de lo contrario, falló. Luego repetimos el proceso para calcular la proporción de casos exitosos como puntaje de evaluación final llamado pass@k. Siguiendo la práctica estándar, establecemos k en 1 en nuestra evaluación, para generar solo una respuesta por pregunta y probar si pasa la prueba de integración.
El siguiente es un código de muestra para usar el repositorio HumanEval. Puede acceder al conjunto de datos y generar una única respuesta utilizando un punto final de SageMaker. Para más detalles, consulte el cuaderno en el Repositorio GitHub.
La siguiente tabla muestra las mejoras de los modelos ajustados de Code LIama Python con respecto a los modelos no ajustados en diferentes tamaños de modelo. Para garantizar la corrección, también implementamos los modelos Code LIama no ajustados en los puntos finales de SageMaker y ejecutamos evaluaciones Human Eval. El pasar @ 1 Los números (la primera fila de la siguiente tabla) coinciden con los números informados en el Trabajo de investigación de Code Llama. Los parámetros de inferencia se establecen consistentemente como "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Como podemos ver en los resultados, todas las variantes ajustadas de Code LIama Python muestran una mejora significativa con respecto a los modelos no ajustados. En particular, Code LIama Python 70B supera al modelo no ajustado en aproximadamente un 12%.
| . | Pitón 7B | Pitón 13B | 34B | Pitón 34B | Pitón 70B |
| Rendimiento del modelo previamente entrenado (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Rendimiento del modelo ajustado (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Ahora puede intentar ajustar los modelos de Code LIama en su propio conjunto de datos.
Limpiar
Si decide que ya no desea mantener el punto final de SageMaker en ejecución, puede eliminarlo usando AWS SDK para Python (Boto3), Interfaz de línea de comandos de AWS (AWS CLI) o la consola de SageMaker. Para más información, ver Eliminar puntos finales y recursos. Además, puede cerrar los recursos de SageMaker Studio que ya no son necesarios.
Conclusión
En esta publicación, analizamos el ajuste de los modelos Code Llama 2 de Meta usando SageMaker JumpStart. Mostramos que puede usar la consola SageMaker JumpStart en SageMaker Studio o el SDK de SageMaker Python para ajustar e implementar estos modelos. También analizamos la técnica de ajuste, los tipos de instancias y los hiperparámetros admitidos. Además, describimos recomendaciones para una capacitación optimizada basadas en varias pruebas que realizamos. Como podemos ver en estos resultados del ajuste de tres modelos en dos conjuntos de datos, el ajuste mejora el resumen en comparación con los modelos no ajustados. Como siguiente paso, puede intentar ajustar estos modelos en su propio conjunto de datos utilizando el código proporcionado en el repositorio de GitHub para probar y comparar los resultados para sus casos de uso.
Acerca de los autores
 Dra. Xin Huang es un científico senior aplicado para los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado muchos artículos en conferencias ACL, ICDM, KDD y Royal Statistical Society: Serie A.
Dra. Xin Huang es un científico senior aplicado para los algoritmos integrados de Amazon SageMaker JumpStart y Amazon SageMaker. Se centra en el desarrollo de algoritmos escalables de aprendizaje automático. Sus intereses de investigación se encuentran en el área del procesamiento del lenguaje natural, el aprendizaje profundo explicable en datos tabulares y el análisis sólido de la agrupación de espacio-tiempo no paramétrica. Ha publicado muchos artículos en conferencias ACL, ICDM, KDD y Royal Statistical Society: Serie A.
 Vishaal Yalamanchali es un arquitecto de soluciones de inicio que trabaja con empresas de vehículos autónomos, robótica y IA generativa en etapa inicial. Vishaal trabaja con sus clientes para ofrecer soluciones de aprendizaje automático de vanguardia y está personalmente interesado en el aprendizaje por refuerzo, la evaluación de LLM y la generación de código. Antes de AWS, Vishaal estudió en la UCI y se centró en bioinformática y sistemas inteligentes.
Vishaal Yalamanchali es un arquitecto de soluciones de inicio que trabaja con empresas de vehículos autónomos, robótica y IA generativa en etapa inicial. Vishaal trabaja con sus clientes para ofrecer soluciones de aprendizaje automático de vanguardia y está personalmente interesado en el aprendizaje por refuerzo, la evaluación de LLM y la generación de código. Antes de AWS, Vishaal estudió en la UCI y se centró en bioinformática y sistemas inteligentes.
 Meenakshisundaram Thandavarayan Trabaja para AWS como especialista en IA/ML. Le apasiona diseñar, crear y promover experiencias de análisis y datos centradas en el ser humano. Meena se centra en el desarrollo de sistemas sostenibles que ofrezcan ventajas competitivas y mensurables para los clientes estratégicos de AWS. Meena es conectora y pensadora del diseño, y se esfuerza por impulsar a las empresas hacia nuevas formas de trabajar a través de la innovación, la incubación y la democratización.
Meenakshisundaram Thandavarayan Trabaja para AWS como especialista en IA/ML. Le apasiona diseñar, crear y promover experiencias de análisis y datos centradas en el ser humano. Meena se centra en el desarrollo de sistemas sostenibles que ofrezcan ventajas competitivas y mensurables para los clientes estratégicos de AWS. Meena es conectora y pensadora del diseño, y se esfuerza por impulsar a las empresas hacia nuevas formas de trabajar a través de la innovación, la incubación y la democratización.
 Dr. Ashish Khetan es científico senior aplicado con algoritmos integrados de Amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado muchos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
Dr. Ashish Khetan es científico senior aplicado con algoritmos integrados de Amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado muchos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

