ZOO Digital Proporciona servicios multimedia y de localización de extremo a extremo para adaptar contenido original de películas y televisión a diferentes idiomas, regiones y culturas. Facilita la globalización para los mejores creadores de contenido del mundo. Con la confianza de los nombres más importantes del entretenimiento, ZOO Digital ofrece servicios multimedia y de localización de alta calidad a escala, incluidos doblaje, subtitulado, secuencias de comandos y cumplimiento.
Los flujos de trabajo de localización típicos requieren un registro manual del hablante, en el que un flujo de audio se segmenta en función de la identidad del hablante. Este proceso, que requiere mucho tiempo, debe completarse antes de poder doblar el contenido a otro idioma. Con métodos manuales, un episodio de 30 minutos puede tardar entre 1 y 3 horas en localizarse. A través de la automatización, ZOO Digital pretende lograr la localización en menos de 30 minutos.
En esta publicación, analizamos la implementación de modelos escalables de aprendizaje automático (ML) para registrar el contenido multimedia utilizando Amazon SageMaker, con un enfoque en la susurrox modelo.
Antecedentes
La visión de ZOO Digital es proporcionar una entrega más rápida de contenido localizado. Este objetivo se ve obstaculizado por la naturaleza manualmente intensiva del ejercicio, agravada por la pequeña fuerza laboral de personas capacitadas que pueden localizar contenido manualmente. ZOO Digital trabaja con más de 11,000 autónomos y localizó más de 600 millones de palabras solo en 2022. Sin embargo, la oferta de personal capacitado está siendo superada por la creciente demanda de contenido, lo que requiere automatización para ayudar con los flujos de trabajo de localización.
Con el objetivo de acelerar la localización de flujos de trabajo de contenido a través del aprendizaje automático, ZOO Digital contrató AWS Prototyping, un programa de inversión de AWS para crear conjuntamente cargas de trabajo con los clientes. El compromiso se centró en ofrecer una solución funcional para el proceso de localización, al mismo tiempo que brindaba capacitación práctica a los desarrolladores de ZOO Digital sobre SageMaker. Amazon Transcribey Traductor de Amazon.
Desafío del cliente
Después de transcribir un título (una película o un episodio de una serie de televisión), se deben asignar oradores a cada segmento del discurso para que puedan asignarse correctamente a los locutores elegidos para interpretar a los personajes. Este proceso se llama diario del hablante. ZOO Digital enfrenta el desafío de registrar contenido a escala y al mismo tiempo ser económicamente viable.
Resumen de la solución
En este prototipo, almacenamos los archivos multimedia originales en un lugar específico. Servicio de almacenamiento simple de Amazon (Amazon S3) cubo. Este depósito de S3 se configuró para emitir un evento cuando se detectan nuevos archivos dentro de él, lo que desencadena una AWS Lambda función. Para obtener instrucciones sobre cómo configurar este disparador, consulte el tutorial Uso de un disparador de Amazon S3 para invocar una función Lambda. Posteriormente, la función Lambda invocó el punto final de SageMaker para realizar inferencias utilizando el Cliente Boto3 SageMaker Runtime.
El susurrox modelo, basado en El susurro de OpenAI, realiza transcripciones y registro diario de activos de medios. Está construido sobre el Susurro más rápido reimplementación, que ofrece una transcripción hasta cuatro veces más rápida con una alineación mejorada de la marca de tiempo a nivel de palabra en comparación con Whisper. Además, introduce el registro de los hablantes, que no estaba presente en el modelo original de Whisper. WhisperX utiliza el modelo Whisper para las transcripciones, el Wav2Vec2 modelo para mejorar la alineación de la marca de tiempo (garantizando la sincronización del texto transcrito con marcas de tiempo de audio), y el nota de pian modelo de diarización. FFmpeg se utiliza para cargar audio desde medios de origen y admite varios formatos de medios. La arquitectura del modelo transparente y modular permite flexibilidad, porque cada componente del modelo se puede intercambiar según sea necesario en el futuro. Sin embargo, es esencial tener en cuenta que WhisperX carece de funciones de administración completas y no es un producto de nivel empresarial. Sin mantenimiento y soporte, es posible que no sea adecuado para la implementación en producción.
En esta colaboración, implementamos y evaluamos WhisperX en SageMaker, utilizando un punto final de inferencia asincrónica para albergar el modelo. Los puntos finales asíncronos de SageMaker admiten tamaños de carga de hasta 1 GB e incorporan funciones de escalado automático que mitigan de manera eficiente los picos de tráfico y ahorran costos durante las horas de menor actividad. Los puntos finales asincrónicos son particularmente adecuados para procesar archivos grandes, como películas y series de televisión en nuestro caso de uso.
El siguiente diagrama ilustra los elementos centrales de los experimentos que realizamos en esta colaboración.

En las siguientes secciones, profundizamos en los detalles de la implementación del modelo WhisperX en SageMaker y evaluamos el rendimiento de la diarioización.
Descarga el modelo y sus componentes.
WhisperX es un sistema que incluye múltiples modelos de transcripción, alineación forzada y diarioización. Para que SageMaker funcione sin problemas sin la necesidad de buscar artefactos del modelo durante la inferencia, es esencial descargar previamente todos los artefactos del modelo. Luego, estos artefactos se cargan en el contenedor de publicación de SageMaker durante el inicio. Debido a que no se puede acceder directamente a estos modelos, ofrecemos descripciones y códigos de muestra de la fuente de WhisperX, brindando instrucciones sobre cómo descargar el modelo y sus componentes.
WhisperX utiliza seis modelos:
La mayoría de estos modelos se pueden obtener de Abrazando la cara usando la biblioteca huggingface_hub. Usamos lo siguiente download_hf_model() función para recuperar estos artefactos del modelo. Se requiere un token de acceso de Hugging Face, generado después de aceptar los acuerdos de usuario para los siguientes modelos de pyannote:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
El modelo VAD se obtiene de Amazon S3 y el modelo Wav2Vec2 se recupera del módulo torchaudio.pipelines. Según el siguiente código, podemos recuperar todos los artefactos de los modelos, incluidos los de Hugging Face, y guardarlos en el directorio del modelo local especificado:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Seleccione el contenedor de aprendizaje profundo de AWS apropiado para servir el modelo
Después de guardar los artefactos del modelo utilizando el código de muestra anterior, puede elegir elementos prediseñados. Contenedores de aprendizaje profundo de AWS (DLC) de los siguientes Repositorio GitHub. Al seleccionar la imagen de Docker, considere las siguientes configuraciones: marco (Hugging Face), tarea (inferencia), versión de Python y hardware (por ejemplo, GPU). Recomendamos utilizar la siguiente imagen: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Esta imagen tiene todos los paquetes del sistema necesarios preinstalados, como ffmpeg. Recuerde reemplazar [REGION] con la región de AWS que está utilizando.
Para otros paquetes de Python requeridos, cree un requirements.txt archivo con una lista de paquetes y sus versiones. Estos paquetes se instalarán cuando se cree el DLC de AWS. Los siguientes son los paquetes adicionales necesarios para alojar el modelo WhisperX en SageMaker:
Cree un script de inferencia para cargar los modelos y ejecutar la inferencia.
A continuación, creamos un personalizado. inference.py script para describir cómo se cargan el modelo WhisperX y sus componentes en el contenedor y cómo se debe ejecutar el proceso de inferencia. El script contiene dos funciones: model_fn y transform_fn. model_fn Se invoca la función para cargar los modelos desde sus respectivas ubicaciones. Posteriormente estos modelos se pasan al transform_fn funcionan durante la inferencia, donde se realizan los procesos de transcripción, alineación y diarización. El siguiente es un ejemplo de código para inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Dentro del directorio del modelo, junto al requirements.txt archivo, garantizar la presencia de inference.py en un subdirectorio de código. El models El directorio debería parecerse al siguiente:
Crear un tarball de los modelos.
Después de crear los modelos y los directorios de código, puede utilizar las siguientes líneas de comando para comprimir el modelo en un tarball (archivo .tar.gz) y cargarlo en Amazon S3. Al momento de escribir este artículo, utilizando el modelo Large V2 de susurro más rápido, el archivo tar resultante que representa el modelo SageMaker tiene un tamaño de 3 GB. Para obtener más información, consulte Patrones de hospedaje de modelos en Amazon SageMaker, Parte 2: Introducción a la implementación de modelos en tiempo real en SageMaker.
Cree un modelo de SageMaker e implemente un punto final con un predictor asincrónico
Ahora puede crear el modelo de SageMaker, la configuración del punto final y el punto final asíncrono con Predictor asíncrono usando el modelo tarball creado en el paso anterior. Para obtener instrucciones, consulte Crear un punto final de inferencia asincrónica.
Evaluar el desempeño de la diarización
Para evaluar el desempeño de la diarioización del modelo WhisperX en varios escenarios, seleccionamos tres episodios cada uno de dos títulos en inglés: un título dramático que consta de episodios de 30 minutos y un título documental que consta de episodios de 45 minutos. Utilizamos el conjunto de herramientas de métricas de pyannote, pyannote.métricas, para calcular el tasa de error de registro (DER). En la evaluación, las transcripciones transcritas y registradas manualmente proporcionadas por ZOO sirvieron como base de verdad.
Definimos el DER de la siguiente manera:
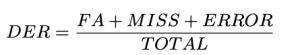
Total es la duración del vídeo de verdad fundamental. FA (Falsa alarma) es la longitud de los segmentos que se consideran discurso en las predicciones, pero no en la verdad sobre el terreno. Perder es la longitud de los segmentos que se consideran discurso en la verdad fundamental, pero no en la predicción. Error, También llamado Confusión, es la longitud de los segmentos que se asignan a diferentes hablantes en predicción y verdad fundamental. Todas las unidades se miden en segundos. Los valores típicos de DER pueden variar según la aplicación específica, el conjunto de datos y la calidad del sistema de diarioización. Tenga en cuenta que DER puede ser mayor que 1.0. Un DER más bajo es mejor.
Para poder calcular el DER de un medio, se requiere una diarioización de la verdad básica, así como los resultados transcritos y diarios de WhisperX. Estos deben analizarse y dar como resultado listas de tuplas que contienen una etiqueta de orador, una hora de inicio del segmento de voz y una hora de finalización del segmento de voz para cada segmento de voz en los medios. No es necesario que las etiquetas de los oradores coincidan entre los diarios de WhisperX y la verdad sobre el terreno. Los resultados se basan principalmente en el tiempo de los segmentos. pyannote.metrics toma estas tuplas de diarizaciones de verdad fundamental y diarizaciones de salida (a las que se hace referencia en la documentación de pyannote.metrics como referencia y hipótesis) para calcular el DER. La siguiente tabla resume nuestros resultados.
| Tipo de vídeo | DER | Correcto | Perder | Error | Falsa alarma |
| Drama | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Documental | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Normal | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Estos resultados revelan una diferencia de rendimiento significativa entre los títulos de drama y documental, y el modelo logra resultados notablemente mejores (utilizando DER como métrica agregada) para los episodios de drama en comparación con el título de documental. Un análisis más detallado de los títulos proporciona información sobre los factores potenciales que contribuyen a esta brecha de desempeño. Un factor clave podría ser la frecuente presencia de música de fondo superpuesta con el discurso en el título del documental. Aunque el preprocesamiento de medios para mejorar la precisión de la diarioización, como eliminar el ruido de fondo para aislar el habla, estaba más allá del alcance de este prototipo, abre vías para trabajos futuros que potencialmente podrían mejorar el rendimiento de WhisperX.
Conclusión
En esta publicación, exploramos la asociación de colaboración entre AWS y ZOO Digital, empleando técnicas de aprendizaje automático con SageMaker y el modelo WhisperX para mejorar el flujo de trabajo de registro. El equipo de AWS desempeñó un papel fundamental al ayudar a ZOO a crear prototipos, evaluar y comprender la implementación efectiva de modelos de aprendizaje automático personalizados, diseñados específicamente para la diarización. Esto incluyó la incorporación de escalado automático para escalabilidad usando SageMaker.
Aprovechar la IA para la digitalización generará ahorros sustanciales tanto en costos como en tiempo al generar contenido localizado para ZOO. Al ayudar a los transcriptores a crear e identificar hablantes de manera rápida y precisa, esta tecnología aborda la naturaleza de la tarea que tradicionalmente consume mucho tiempo y es propensa a errores. El proceso convencional a menudo implica múltiples pasadas por el vídeo y pasos adicionales de control de calidad para minimizar los errores. La adopción de la IA para la diarioización permite un enfoque más específico y eficiente, aumentando así la productividad en un plazo más corto.
Hemos descrito los pasos clave para implementar el modelo WhisperX en el punto final asíncrono de SageMaker y le animamos a que lo pruebe usted mismo utilizando el código proporcionado. Para obtener más información sobre los servicios y la tecnología de ZOO Digital, visite Sitio oficial de ZOO Digital. Para obtener detalles sobre la implementación del modelo OpenAI Whisper en SageMaker y varias opciones de inferencia, consulte Aloje el modelo Whisper en Amazon SageMaker: explorando opciones de inferencia. No dudes en compartir tus pensamientos en los comentarios.
Acerca de los autores
 Ying Hou, doctorado, es arquitecto de creación de prototipos de aprendizaje automático en AWS. Sus principales áreas de interés abarcan el aprendizaje profundo, con especial atención en GenAI, visión por computadora, PNL y predicción de datos de series temporales. En su tiempo libre, disfruta pasar momentos de calidad con su familia, sumergirse en novelas y hacer senderismo en los parques nacionales del Reino Unido.
Ying Hou, doctorado, es arquitecto de creación de prototipos de aprendizaje automático en AWS. Sus principales áreas de interés abarcan el aprendizaje profundo, con especial atención en GenAI, visión por computadora, PNL y predicción de datos de series temporales. En su tiempo libre, disfruta pasar momentos de calidad con su familia, sumergirse en novelas y hacer senderismo en los parques nacionales del Reino Unido.
 Ethan Cumberland es ingeniero de investigación de IA en ZOO Digital, donde trabaja en el uso de la IA y el aprendizaje automático como tecnologías de asistencia para mejorar los flujos de trabajo en el habla, el lenguaje y la localización. Tiene experiencia en ingeniería de software e investigación en el ámbito de la seguridad y la vigilancia, enfocándose en extraer información estructurada de la web y aprovechar modelos de aprendizaje automático de código abierto para analizar y enriquecer los datos recopilados.
Ethan Cumberland es ingeniero de investigación de IA en ZOO Digital, donde trabaja en el uso de la IA y el aprendizaje automático como tecnologías de asistencia para mejorar los flujos de trabajo en el habla, el lenguaje y la localización. Tiene experiencia en ingeniería de software e investigación en el ámbito de la seguridad y la vigilancia, enfocándose en extraer información estructurada de la web y aprovechar modelos de aprendizaje automático de código abierto para analizar y enriquecer los datos recopilados.
 Gaurav Kaila dirige el equipo de creación de prototipos de AWS para el Reino Unido e Irlanda. Su equipo trabaja con clientes de diversas industrias para idear y desarrollar conjuntamente cargas de trabajo críticas para el negocio con el mandato de acelerar la adopción de los servicios de AWS.
Gaurav Kaila dirige el equipo de creación de prototipos de AWS para el Reino Unido e Irlanda. Su equipo trabaja con clientes de diversas industrias para idear y desarrollar conjuntamente cargas de trabajo críticas para el negocio con el mandato de acelerar la adopción de los servicios de AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

