En el mundo acelerado de hoy, el concepto de paciencia como virtud parece estar desapareciendo, ya que la gente ya no quiere esperar por nada. Si Netflix tarda demasiado en cargarse o el Lyft más cercano está demasiado lejos, los usuarios cambian rápidamente a opciones alternativas. La demanda de resultados instantáneos no se limita a los servicios de consumo como transmisión de video y viajes compartidos; se extiende al reino de análisis de datos, particularmente al atender a los usuarios a escala y flujos de trabajo de toma de decisiones automatizados. La capacidad de proporcionar información oportuna, tomar decisiones informadas y emprender acciones inmediatas basadas en datos en tiempo real es cada vez más crucial. Empresas como Confluent, Target y muchas otras son líderes de la industria porque aprovechan los análisis en tiempo real y las arquitecturas de datos que facilitan las operaciones basadas en análisis. Esta capacidad les permite mantenerse a la vanguardia en sus respectivas industrias.
Esta publicación de blog profundiza en el concepto de análisis en tiempo real para arquitectos de datos que están comenzando a explorar patrones de diseño, brindando información sobre su definición y los bloques de construcción preferidos y la arquitectura de datos comúnmente empleada en este dominio.
¿Qué constituye exactamente el análisis en tiempo real?
Los análisis en tiempo real se caracterizan por dos cualidades fundamentales: datos actualizados e información rápida. Se emplean en aplicaciones sensibles al tiempo donde la velocidad a la que los nuevos eventos se transforman en información práctica es cuestión de segundos.
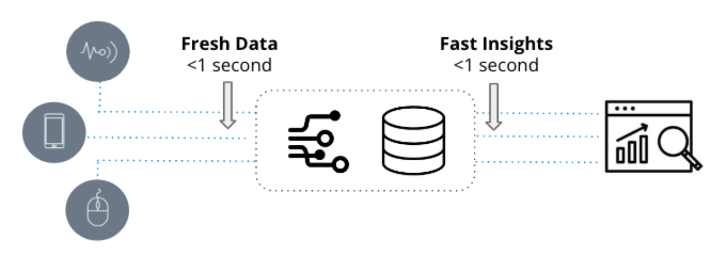
Por otro lado, la analítica tradicional, comúnmente conocida como inteligencia empresarial , se refieren a representaciones estáticas de datos comerciales utilizados principalmente para informar objetivos. Estos análisis se basan en almacenes de datos como Snowflake y Amazon Redshift y se visualizan a través de herramientas de inteligencia comercial como Tableau o PowerBI.
A diferencia de los análisis tradicionales, que se basan en datos históricos que pueden tener días o semanas de antigüedad, los análisis en tiempo real aprovechan datos nuevos y se emplean en flujos de trabajo operativos que requieren respuestas rápidas a consultas potencialmente complejas.

Por ejemplo, considere a un ejecutivo de la cadena de suministro que busca tendencias históricas en los cambios de inventario mensuales. En este escenario, el análisis tradicional es la opción ideal, ya que el ejecutivo puede darse el lujo de esperar unos minutos más para que se procese el informe. Por otro lado, un equipo de operaciones de seguridad tiene como objetivo detectar y diagnosticar anomalías en el tráfico de la red. Aquí es donde entra en juego el análisis en tiempo real, ya que el equipo de SecOps requiere un análisis rápido de miles a millones de entradas de registro en tiempo real en intervalos de subsegundos para identificar patrones e investigar comportamientos anormales.
¿Es significativa la elección de la arquitectura?
Muchos proveedores de bases de datos afirman ser adecuados para el análisis en tiempo real y tienen algunas capacidades en ese sentido. Por ejemplo, considere el escenario de monitoreo del clima, donde las lecturas de temperatura deben tomarse muestras cada segundo de miles de estaciones meteorológicas, y las consultas involucran alertas basadas en umbrales y análisis de tendencias. SingleStore, InfluxDB, MongoDB e incluso PostgreSQL pueden manejar esto con facilidad. Al crear una API push para enviar las métricas directamente a la base de datos y ejecutar una consulta simple, se pueden lograr análisis en tiempo real.
Entonces, ¿cuándo aumenta la complejidad del análisis en tiempo real? En el ejemplo mencionado, el conjunto de datos es relativamente pequeño y los análisis involucrados son simples. Con solo un evento de temperatura generado por segundo y una consulta SELECT sencilla con una instrucción WHERE para recuperar los eventos más recientes, se requiere una potencia de procesamiento mínima, lo que lo hace manejable para cualquier serie temporal o base de datos OLTP.
Los verdaderos desafíos surgen y las bases de datos llegan a sus límites cuando aumenta el volumen de eventos ingeridos, las consultas se vuelven más complejas con numerosas dimensiones y los conjuntos de datos alcanzan terabytes o incluso petabytes de tamaño. Si bien Apache Cassandra a menudo se considera para la ingesta de alto rendimiento, es posible que su rendimiento analítico no cumpla con las expectativas. En los casos en que el caso de uso de análisis requiera unir múltiples fuentes de datos en tiempo real a escala, se deben explorar soluciones alternativas.
Aquí hay algunos factores a considerar que ayudarán a determinar las especificaciones necesarias para la arquitectura adecuada:
- ¿Está trabajando con eventos altos por segundo, de miles a millones?
- ¿Es importante minimizar la latencia entre los eventos creados y cuando se pueden consultar?
- ¿Su conjunto de datos total es grande y no solo unos pocos GB?
- ¿Qué tan importante es el rendimiento de las consultas: subsegundos o minutos por consulta?
- ¿Qué tan complicadas son las consultas, exportar algunas filas o agregaciones a gran escala?
- ¿Es importante evitar el tiempo de inactividad del flujo de datos y el motor de análisis?
- ¿Está intentando unirse a varios flujos de eventos para su análisis?
- ¿Necesita colocar datos en tiempo real en contexto con datos históricos?
- ¿Anticipa muchas consultas simultáneas?
Si alguno de estos aspectos es relevante, analicemos las características de la arquitectura ideal.
Bloques de construcción
El análisis en tiempo real requiere algo más que una base de datos competente. Comienza con la necesidad de establecer conexiones, transmitir y manejar datos en tiempo real, lo que nos lleva al elemento fundamental inicial: la transmisión de eventos.
1. Transmisión de eventos
En situaciones en las que el tiempo real es de suma importancia, las canalizaciones de datos convencionales basadas en lotes tienden a llegar demasiado tarde, lo que da lugar a la aparición de colas de mensajería. En el pasado, la entrega de mensajes dependía de herramientas como ActiveMQ, RabbitMQ y TIBCO. Sin embargo, el enfoque contemporáneo implica la transmisión de eventos con tecnologías como Apache Kafka y Amazon Kinesis.
Apache Kafka y Amazon Kinesis abordan las limitaciones de escalabilidad que a menudo se encuentran con las colas de mensajería tradicionales, potenciando los mecanismos de publicación/suscripción de alto rendimiento para recopilar y distribuir eficientemente grandes flujos de datos de eventos de diversas fuentes (denominados productores en la terminología de Amazon) a varios destinos ( denominados consumidores en la terminología de Amazon) en tiempo real.
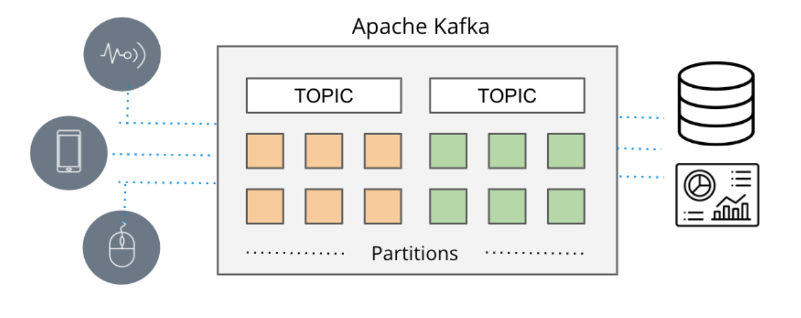
Estos sistemas adquieren sin problemas datos en tiempo real de una variedad de fuentes, como bases de datos, sensores y servicios en la nube, encapsulándolos como flujos de eventos y facilitando su transmisión a otras aplicaciones, bases de datos y servicios.
Dada su impresionante escalabilidad (como lo demuestra el soporte de Apache Kafka de más de siete billones de mensajes por día en LinkedIn) y la capacidad de acomodar numerosas fuentes de datos simultáneas, la transmisión de eventos se ha convertido en el mecanismo predominante para entregar datos en tiempo real en las aplicaciones.
Ahora que tenemos la capacidad de capturar datos en tiempo real, el siguiente paso es explorar cómo podemos analizarlos en tiempo real.
2. Base de datos de análisis en tiempo real
El análisis en tiempo real requiere una base de datos especializada que pueda aprovechar al máximo la transmisión de datos de Apache Kafka y Amazon Kinesis, proporcionando información en tiempo real. Apache Druida es precisamente esa base de datos.
Apache Druid se ha convertido en la base de datos preferida para aplicaciones de análisis en tiempo real debido a su alto rendimiento y capacidad para manejar datos de transmisión. Con su soporte para la ingestión de flujo real y el procesamiento eficiente de grandes volúmenes de datos en marcos de tiempo de menos de un segundo, incluso bajo cargas pesadas, Apache Druid sobresale en la entrega de información rápida sobre datos nuevos. Su perfecta integración con Apache Kafka y Amazon Kinesis consolida aún más su posición como la opción preferida para el análisis en tiempo real.
Al elegir una base de datos de análisis para la transmisión de datos, las consideraciones como la escala, la latencia y la calidad de los datos son cruciales. La capacidad de manejar la transmisión de eventos a gran escala, ingerir y correlacionar múltiples temas de Kafka o fragmentos de Kinesis, admitir la ingesta basada en eventos y garantizar la integridad de los datos durante las interrupciones son requisitos clave. Apache Druid no solo cumple con estos criterios, sino que va más allá para cumplir con estas expectativas y proporcionar capacidades adicionales.
Druid fue diseñado a propósito para sobresalir en la ingestión rápida y la consulta en tiempo real de los eventos a medida que llegan. Tiene un enfoque único para la transmisión de datos, incorporando eventos de forma individual en lugar de depender de archivos de datos por lotes secuenciales para simular una transmisión. Esto elimina la necesidad de conectores a Kafka o Kinesis. Además, Druid asegura Calidad de los Datos al admitir la semántica exactamente una vez, garantizando la integridad y precisión de los datos ingeridos.
Al igual que Apache Kafka, Apache Druid fue diseñado específicamente para manejar datos de eventos a escala de Internet. Su arquitectura basada en servicios permite la escalabilidad independiente de la ingestión y el procesamiento de consultas, lo que lo hace capaz de escalar casi infinitamente. Al mapear las tareas de ingesta con las particiones de Kafka, Druid escala sin problemas junto con los clústeres de Kafka, lo que garantiza un procesamiento de datos eficiente y paralelo.
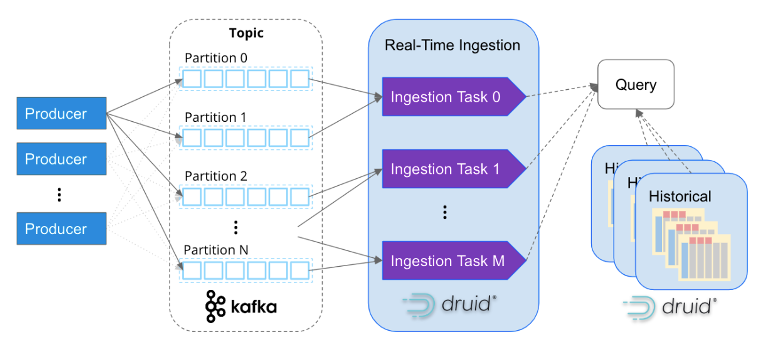
Cada vez es más común que las empresas incorporen millones de eventos por segundo en Apache Druid. Por ejemplo, Confluent, los creadores de Kafka, construyeron su plataforma de observabilidad usando Druid e ingiere con éxito más de cinco millones de eventos por segundo de Kafka. Esto muestra la escalabilidad y las capacidades de alto rendimiento de Druid en el manejo de volúmenes de eventos masivos.
Sin embargo, el análisis en tiempo real va más allá de tener acceso a datos en tiempo real. Para obtener información sobre patrones y comportamientos, también es esencial correlacionar datos históricos. Apache Druid sobresale en este sentido, como se muestra en el diagrama anterior, al admitir sin problemas el análisis histórico y en tiempo real a través de una sola consulta SQL. Druid administra de manera eficiente grandes volúmenes de datos, incluso hasta petabytes, en segundo plano, lo que permite un análisis integral e integrado en diferentes períodos de tiempo.
Cuando se juntan todas las piezas, surge una arquitectura de datos altamente escalable para análisis en tiempo real. Esta arquitectura es la opción preferida de miles de arquitectos de datos cuando requieren alta escalabilidad, baja latencia y la capacidad de realizar agregaciones complejas en datos en tiempo real. Al aprovechar la transmisión de eventos con Apache Kafka o Amazon Kinesis, combinado con el poder de Apache Druid para un análisis histórico y en tiempo real eficiente, las organizaciones pueden obtener información sólida y completa de sus datos.
Estudio de caso: garantizar una experiencia de visualización de primer nivel: el enfoque de Netflix
El análisis en tiempo real es un componente fundamental en la búsqueda incansable de Netflix de brindar una experiencia excepcional a más de 200 millones de usuarios, que en conjunto consumen 250 millones de horas de contenido al día. Con una aplicación de observabilidad diseñada para el monitoreo en tiempo real, Netflix supervisa de manera efectiva más de 300 millones de dispositivos para garantizar un rendimiento óptimo y la satisfacción del cliente.

Al aprovechar los registros en tiempo real generados por los dispositivos de reproducción, que se transmiten sin problemas a través de Apache Kafka y se incorporan evento por evento en Apache Druid, Netflix obtiene información valiosa y mediciones cuantificables sobre el rendimiento de los dispositivos de los usuarios durante las actividades de navegación y reproducción.
Con un rendimiento asombroso de más de dos millones de eventos por segundo y consultas ultrarrápidas en fracciones de segundo realizadas en un conjunto de datos masivo de 1.5 billones de filas, los ingenieros de Netflix poseen la capacidad de identificar e investigar con precisión anomalías dentro de su infraestructura, actividad de punto final y flujo de contenido. .
Desbloquee información en tiempo real con Apache Druid, Apache Kafka y Amazon Kinesis
Si está interesado en crear soluciones de análisis en tiempo real, le recomiendo que explore Apache Druid junto con Apache Kafka y Amazon Kinesis.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.dataversity.net/architecting-real-time-analytics-for-speed-and-scale/

