Introducción
¿Alguna vez te has preguntado qué tan bueno sería chatear con un video? Como blogger, a menudo me aburre ver un video de una hora para encontrar información relevante. A veces se siente como un trabajo mirar un video para obtener información útil. Entonces, construí un chatbot que te permite chatear con videos de YouTube o cualquier video. Esto fue posible gracias a GPT-3.5-turbo, Langchain, ChromaDB, Whisper y Gradio. Entonces, en este artículo, haré un recorrido por el código para construir un chatbot funcional para videos de YouTube con Langchain.
OBJETIVOS DE APRENDIZAJE
- Cree la interfaz web usando Gradio
- Maneje videos de YouTube y extraiga datos textuales de ellos usando Whisper
- Procesar y formatear textos apropiadamente
- Crear incrustaciones de datos de texto
- Configurar Chroma DB para almacenar datos
- Inicialice una cadena de conversación Langchain con OpenAI chatGPT, ChromaDB y la función de incrustaciones
- Finalmente, consultar y transmitir respuestas al chatbot de Gradio
Antes de llegar a la parte de codificación, familiaricémonos con las herramientas y tecnologías que utilizaremos.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Tabla de contenidos.
cadena larga
Langchain es una herramienta de código abierto escrita en Python que hace que los modelos de lenguaje grandes sean conscientes y agentes. Entonces, ¿qué significa eso? La mayoría de los LLM disponibles comercialmente, como GPT-3.5 y GPT-4, tienen un límite en los datos en los que se entrenan. Por ejemplo, ChatGPT solo puede responder preguntas que ya ha visto. Se desconoce cualquier cosa posterior a septiembre de 2021. Este es el problema central que resuelve Langchain. Ya sea un documento de Word o cualquier PDF personal, podemos enviar los datos a un LLM y obtener una respuesta similar a la humana. Tiene envoltorios para herramientas como Vector DB, modelos de Chat y funciones de incrustación, lo que facilita la creación de una aplicación de IA utilizando solo Langchain.
Langchain también nos permite crear agentes: bots LLM. Estos agentes autónomos se pueden configurar para múltiples tareas, incluido el análisis de datos, consultas SQL e incluso la escritura de códigos básicos. Hay muchas cosas que podemos automatizar usando estos agentes. Esto es útil ya que podemos externalizar el trabajo de conocimiento de bajo nivel a un LLM, ahorrándonos tiempo y energía.
En este proyecto, utilizaremos las herramientas de Langchain para crear una aplicación de chat para videos. Para obtener más información sobre Langchain, visite su sitio oficial.
Susurro
Susurro es otra progenie de OpenAI. Es un modelo de voz a texto de propósito general que puede convertir audio o videos en texto. Está entrenado en una gran cantidad de audio diverso para realizar traducción multilingüe, reconocimiento de voz y clasificación.
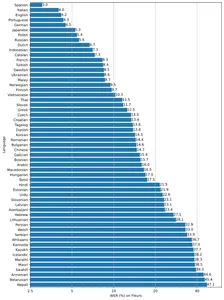
El modelo está disponible en cinco tamaños diferentes, pequeño, base, mediano, pequeño y grande, con ventajas y desventajas de velocidad y precisión. El rendimiento de los modelos también depende del idioma. La siguiente figura muestra un desglose de WER (tasa de error de palabras) por idiomas del conjunto de datos de Fleur utilizando el modelo grande v2.
Bases de datos vectoriales
La mayoría de los algoritmos de aprendizaje automático no pueden procesar datos no estructurados sin procesar, como imágenes, audio, video y textos. Deben convertirse en matrices de incrustaciones vectoriales. Estas incrustaciones de vectores representan dichos datos en un plano multidimensional. Para obtener incrustaciones, necesitamos modelos de aprendizaje profundo altamente eficientes capaces de capturar el significado semántico de los datos. Esto es muy importante para hacer cualquier aplicación de IA. Para almacenar y consultar estos datos, necesitamos bases de datos capaces de manejarlos de manera efectiva. Esto resultó en la creación de bases de datos especializadas llamadas bases de datos vectoriales. Hay múltiples bases de datos de código abierto. Chroma, Milvus, Weaviate y FAISS son algunos de los más populares.
Otra USP de las tiendas de vectores es que podemos realizar operaciones de búsqueda de alta velocidad en datos no estructurados. Una vez que obtengamos las incrustaciones, podemos usarlas para agrupar, buscar, ordenar y clasificar. Como los puntos de datos están en un espacio vectorial, podemos calcular la distancia entre ellos para saber cuán estrechamente relacionados están. Se utilizan varios algoritmos como similitud de coseno, distancia euclidiana, KNN y ANN (vecino más cercano aproximado) para encontrar puntos de datos similares.
Usaremos Chroma tienda de vectores: una base de datos de vectores de código abierto. Chroma también tiene integración Langchain, que será muy útil.
Gradio
El cuarto jinete de nuestra aplicación Gradio es una biblioteca de código abierto para compartir fácilmente modelos de aprendizaje automático. También puede ayudar a crear aplicaciones web de demostración con sus componentes y eventos con Python.
Si no está familiarizado con Gradio y Langchain, lea los siguientes artículos antes de continuar.
Ahora comencemos a construirlo.
Configurar entorno de desarrollo
Para configurar el entorno de desarrollo, cree un Python ambiente virtual o cree un entorno de desarrollo local con Docker.
Ahora instala todas estas dependencias
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314 Importar bibliotecas
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, List
Crear interfaz web
Usaremos Gradio Block y componentes para construir el front-end de nuestra aplicación. Entonces, así es como puedes hacer la interfaz. Siéntase libre de personalizar como mejor le parezca.
with gr.Blocks() as demo: with gr.Row(): # with gr.Group(): with gr.Column(scale=0.70): api_key = gr.Textbox(placeholder='Enter OpenAI API key', show_label=False, interactive=True).style(container=False) with gr.Column(scale=0.15): change_api_key = gr.Button('Change Key') with gr.Column(scale=0.15): remove_key = gr.Button('Remove Key') with gr.Row(): with gr.Column(): chatbot = gr.Chatbot(value=[]).style(height=650) query = gr.Textbox(placeholder='Enter query here', show_label=False).style(container=False) with gr.Column(): video = gr.Video(interactive=True,) start_video = gr.Button('Initiate Transcription') gr.HTML('OR') yt_link = gr.Textbox(placeholder='Paste a YouTube link here', show_label=False).style(container=False) yt_video = gr.HTML(label=True) start_ytvideo = gr.Button('Initiate Transcription') gr.HTML('Please reset the app after being done with the app to remove resources') reset = gr.Button('Reset App') if __name__ == "__main__": demo.launch() La interfaz aparecerá así

Aquí, tenemos un cuadro de texto que toma la clave OpenAI como entrada. Y también dos claves para cambiar la clave API y eliminar la clave. También tenemos una interfaz de usuario de chat a la izquierda y un cuadro para renderizar videos locales a la derecha. Inmediatamente debajo del cuadro de video, tenemos un cuadro que solicita un enlace de YouTube y botones que dicen "Iniciar transcripción".
Eventos Gradio
Ahora definiremos eventos para que la aplicación sea interactiva. Agregue los siguientes códigos al final de gr.Blocks().
start_video.click(fn=lambda :(pause, update_yt), outputs=[start2, yt_video]).then( fn=embed_video, inputs=, outputs=).success( fn=lambda:resume, outputs=[start2]) start_ytvideo.click(fn=lambda :(pause, update_video), outputs=[start1,video]).then( fn=embed_yt, inputs=[yt_link], outputs = [yt_video, chatbot]).success( fn=lambda:resume, outputs=[start1]) query.submit(fn=add_text, inputs=[chatbot, query], outputs=[chatbot]).success( fn=QuestionAnswer, inputs=[chatbot,query,yt_link,video], outputs=[chatbot,query]) api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key) remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- iniciar_video: Al hacer clic, se activará el proceso de obtención de textos del video y se creará una cadena de conversación.
- start_ytvideo: Al hacer clic, hará lo mismo, pero ahora desde el video de YouTube, y cuando se complete, mostrará el video de YouTube justo debajo.
- consulta: Responsable de transmitir la respuesta de LLM a la interfaz de usuario del chat.
El resto de los eventos son para manejar la clave API y restablecer la aplicación.
Hemos definido los eventos pero no hemos definido las funciones responsables de desencadenar eventos.
Backend
Para no hacerlo complicado y desordenado, describiremos los procesos con los que trataremos en el backend.
- Manejar claves API.
- Manejar el video subido.
- Transcribe videos para obtener textos.
- Crea fragmentos a partir de textos de video.
- Crear incrustaciones a partir de textos.
- Almacene incrustaciones de vectores en la tienda de vectores de ChromaDB.
- Cree una cadena de recuperación conversacional con Langchain.
- Envía documentos relevantes al modelo de chat de OpenAI (gpt-3.5-turbo).
- Obtén la respuesta y transmítela en la interfaz de usuario del chat.
Haremos todas estas cosas junto con un manejo de algunas excepciones.
Defina algunas variables de entorno.
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0 enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set', interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None) update_yt = gr.HTML.update(value=None) Manejar claves API
Cuando un usuario envía una clave, se establece como la variable de entorno, y también deshabilitaremos el cuadro de texto para que no ingrese más información. Al presionar la tecla de cambio, volverá a ser mutable. Al hacer clic en Eliminar clave, se eliminará la clave.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box
def enable_api_box(): return enable_box
def remove_key_box(): os.environ['OPENAI_API_KEY'] = '' return remove_boxManejar Vídeos
A continuación, nos ocuparemos de los videos subidos y los enlaces de YouTube. Tendremos dos funciones diferentes tratando cada caso. Para los enlaces de YouTube, crearemos un enlace incrustado de iframe. Para cada caso, llamaremos a otra función hacer_cadena() responsable de crear cadenas.
Estas funciones se activan cuando alguien carga un video o proporciona un enlace de YouTube y presiona el botón de transcripción.
def embed_yt(yt_link: str): # This function embeds a YouTube video into the page. # Check if the YouTube link is valid. if not yt_link: raise gr.Error('Paste a YouTube link') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Set the global variable `call_to_load_video` to 0. # This is used to keep track of how many times the function has been called. call_to_load_video = 0 # Create a chain using the YouTube link. make_chain(url=yt_link) # Get the URL of the YouTube video. url = yt_link.replace('watch?v=', '/embed/') # Create the HTML code for the embedded YouTube video. embed_html = f"""<iframe width="750" height="315" src="{url}" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>""" # Return the HTML code and an empty list. return embed_html, [] def embed_video(video=str | None): # This function embeds a video into the page. # Check if the video is valid. if not video: raise gr.Error('Upload a Video') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Create a chain using the video. make_chain(video=video) # Return the video and an empty list. return video, []Crear cadena
Este es uno de los pasos más importantes de todos. Esto implica crear una tienda de vectores Chroma y una cadena Langchain. Usaremos una cadena de recuperación conversacional para nuestro caso de uso. Usaremos incrustaciones de OpenAI, pero para implementaciones reales, use cualquier modelo de incrustación gratuito como codificadores de oraciones Huggingface, etc.
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None): global chain, run_once_flag # Check if a YouTube link or video is provided if not url and not video: raise gr.Error('Please provide a YouTube link or Upload a video') if not run_once_flag: run_once_flag = True # Get the title from the YouTube link or video title = get_title(url, video).replace(' ','-') # Process the text from the video grouped_texts, time_list = process_text(url=url) if url else process_text(video=video) # Convert time_list to metadata format time_list = [{'source': str(t.time())} for t in time_list] # Create vector stores from the processed texts with metadata vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test', embedding=OpenAIEmbeddings(), metadatas=time_list) # Create a ConversationalRetrievalChain from the vector stores chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0), retriever= vector_stores.as_retriever( search_kwargs={"k": 5}), return_source_documents=True) return chain
- Obtenga textos y metadatos de la URL de YouTube o del archivo de video.
- Cree una tienda de vectores Chroma a partir de textos y metadatos.
- Cree una cadena usando OpenAI gpt-3.5-turbo y la tienda de vectores croma.
- Cadena de retorno.
Textos de proceso
En este paso, dividiremos adecuadamente los textos de los videos y también crearemos el objeto de metadatos que usamos en el proceso de creación de cadenas anterior.
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]: global call_to_load_video if call_to_load_video == 0: print('yes') # Call the process_video function based on the given video or URL result = process_video(url=url) if url else process_video(video=video) call_to_load_video += 1 texts, start_time_list = [], [] # Extract text and start time from each segment in the result for res in result['segments']: start = res['start'] text = res['text'] start_time = dt.datetime.fromtimestamp(start) start_time_formatted = start_time.strftime("%H:%M:%S") texts.append(''.join(text)) start_time_list.append(start_time_formatted) texts_with_timestamps = dict(zip(texts, start_time_list)) # Convert the timestamp strings to datetime objects formatted_texts = { text: dt.datetime.strptime(str(timestamp), '%H:%M:%S') for text, timestamp in texts_with_timestamps.items() } grouped_texts = [] current_group = '' time_list = [list(formatted_texts.values())[0]] previous_time = None time_difference = dt.timedelta(seconds=30) # Group texts based on time difference for text, timestamp in formatted_texts.items(): if previous_time is None or timestamp - previous_time <= time_difference: current_group += text else: grouped_texts.append(current_group) time_list.append(timestamp) current_group = text previous_time = time_list[-1] # Append the last group of texts if current_group: grouped_texts.append(current_group) return grouped_texts, time_list
- La función process_text toma una URL o una ruta de video. Luego, este video se transcribe en la función process_video y obtenemos los textos finales.
- Luego obtenemos la hora de inicio de cada oración (de Whisper) y las agrupamos en 30 segundos.
- Finalmente devolvemos los textos agrupados y la hora de inicio de cada grupo.
Procesar vídeo
En este paso, transcribimos archivos de video o audio y obtenemos textos. Usaremos el modelo base Whisper para la transcripción.
def process_video(video=None, url=None) -> dict[str, str | list]: if url: file_dir = load_video(url) else: file_dir = video print('Transcribing Video with whisper base model') model = whisper.load_model("base") result = model.transcribe(file_dir) return resultPara los videos de YouTube, como no podemos procesarlos directamente, tendremos que manejarlos por separado. Usaremos una biblioteca llamada Pytube para descargar el audio o video del video de YouTube. Entonces, así es como puedes hacerlo.
def load_video(url: str) -> str: # This function downloads a YouTube video and returns the path to the downloaded file. # Create a YouTube object for the given URL. yt = YouTube(url) # Get the target directory. target_dir = os.path.join('/tmp', 'Youtube') # If the target directory does not exist, create it. if not os.path.exists(target_dir): os.mkdir(target_dir) # Get the audio stream of the video. stream = yt.streams.get_audio_only() # Download the audio stream to the target directory. print('----DOWNLOADING AUDIO FILE----') stream.download(output_path=target_dir) # Get the path of the downloaded file. path = target_dir + '/' + yt.title + '.mp4' # Return the path of the downloaded file. return path
- Cree un objeto de YouTube para la URL dada.
- Crear una ruta de directorio de destino temporal
- Compruebe si existe la ruta, de lo contrario, cree el directorio.
- Descarga el audio del archivo.
- Obtener el directorio de ruta del video
Este fue el proceso de abajo hacia arriba desde obtener textos de videos hasta crear la cadena. Ahora, todo lo que queda es configurar el chatbot.
Configurar chatbot
Todo lo que necesitamos ahora es enviarle una consulta y un chat_history para obtener nuestras respuestas. Por lo tanto, definiremos una función que solo se activa cuando se envía una consulta.
def add_text(history, text): if not text: raise gr.Error('enter text') history = history + [(text,'')] return history def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]: # This function answers a question using a chain of models. # Check if a YouTube link or a local video file is provided. if video and url: # Raise an error if both a YouTube link and a local video file are provided. raise gr.Error('Upload a video or a YouTube link, not both') elif not url and not video: # Raise an error if no input is provided. raise gr.Error('Provide a YouTube link or Upload a video') # Get the result of processing the video. result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) # Add the question and answer to the chat history. chat_history += [(query, result["answer"])] # For each character in the answer, append it to the last element of the history. for char in result['answer']: history[-1][-1] += char yield history, ''
Proporcionamos el historial de chat con la consulta para mantener el contexto de la conversación. Finalmente, transmitimos la respuesta al chatbot. Y no olvide definir la funcionalidad de reinicio para restablecer todos los valores.
Entonces, esto fue todo. Ahora, inicie su aplicación y comience a chatear con videos.
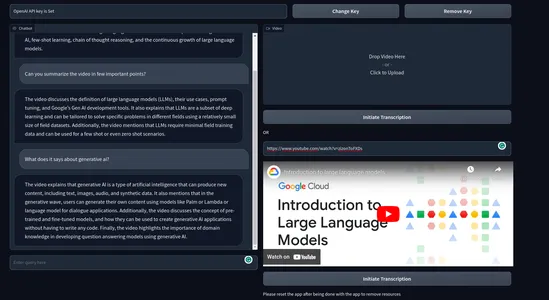
Así es como se ve el producto final.
Vídeo de demostración:
[Contenido incrustado]
Casos de uso de la vida real
Una aplicación que permite al usuario final chatear con cualquier video o audio puede tener una amplia gama de casos de uso. Estos son algunos de los casos de uso de la vida real de este chatbot.
- Educación: Los estudiantes a menudo pasan por videoconferencias de horas de duración. Este chatbot puede ayudar a los estudiantes a aprender de los videos de conferencias y extraer información útil rápidamente, ahorrando tiempo y energía. Esto mejorará significativamente la experiencia de aprendizaje.
- Legal: Los profesionales del derecho a menudo pasan por largos procedimientos legales y declaraciones para analizar el caso, preparar documentos, investigar o monitorear el cumplimiento. Un chatbot como este puede contribuir en gran medida a ordenar tales tareas.
- Resumen del contenido: Esta aplicación puede analizar contenido de video y generar versiones de texto resumidas. Esto le permite al usuario captar los aspectos más destacados del video sin verlo por completo.
- Interacción con el cliente: Las marcas pueden incorporar una función de video chatbot para sus productos o servicios. Esto puede ser útil para las empresas que venden productos o servicios costosos o que requieren mucha explicación.
- Traducción de vídeos: Podemos traducir el corpus de texto a otros idiomas. Esto puede facilitar la comunicación entre idiomas, el aprendizaje de idiomas o la accesibilidad para hablantes no nativos.
Estos son algunos de los posibles casos de uso que se me ocurren. Puede haber aplicaciones mucho más útiles de un chatbot para videos.
Conclusión
Entonces, se trataba de crear una aplicación web de demostración funcional para un chatbot para videos. Cubrimos muchos conceptos a lo largo del artículo. Estos son los puntos clave del artículo.
- Aprendimos sobre Langchain, una herramienta popular para crear aplicaciones de IA con facilidad.
- Whisper es un potente modelo de voz a texto de OpenAI. Un modelo de código abierto que puede convertir audio y videos a texto.
- Aprendimos cómo las bases de datos vectoriales facilitan el almacenamiento y la consulta efectivos de incrustaciones de vectores.
- Creamos una aplicación web completamente funcional desde cero utilizando los modelos Langchain, Chroma y OpenAI.
- También discutimos posibles casos de uso en la vida real de nuestro chatbot.
Esto fue todo, espero que les haya gustado, y consideren seguirme en Twitter para más cosas relacionadas con el desarrollo.
Repositorio de GitHub: sunilkumardash9/chatgpt-para-videos. Si encuentra esto útil, haga ⭐ el repositorio.
Preguntas frecuentes
R. LangChain es un marco de código abierto que simplifica la creación de aplicaciones utilizando modelos de lenguaje grandes. Se puede usar para una variedad de tareas, incluidos chatbots, análisis de documentos, análisis de código, respuesta a preguntas y tareas generativas.
R. Las cadenas son una secuencia de pasos que se ejecutan en orden. Se utilizan para definir una tarea o proceso específico. Por ejemplo, una cadena podría usarse para resumir un documento, responder una pregunta o generar un texto creativo.
Los agentes son más complejos que las cadenas. Pueden tomar decisiones sobre qué pasos ejecutar y también pueden aprender de sus experiencias. Los agentes a menudo se usan para tareas que requieren mucha creatividad o razonamiento, por ejemplo, análisis de datos y generación de código.
A. 1. Acción: Los agentes de acción deciden qué acción tomar y ejecutan esa acción paso a paso. Son más convencionales y adecuados para pequeñas tareas.
2. Los agentes de planificación y ejecución primero deciden un plan de acción a tomar y luego ejecutan esas acciones una a la vez. Son más complejos y adecuados para tareas que requieren más planificación y flexibilidad.
R. Langchain es capaz de integrar LLM y modelos de chat. Los LLM son modelos que toman una entrada de cadena y devuelven una respuesta de cadena. Los modelos de chat toman una lista de mensajes de chat como entrada y emiten un mensaje de chat.
R. Sí, Lagchain es una herramienta de código abierto y de uso gratuito, pero la mayoría de las operaciones requerirán una clave API de OpenAI que genera cargos.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.
Relacionado:
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Automoción / vehículos eléctricos, Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- Desplazamientos de bloque. Modernización de la propiedad de compensaciones ambientales. Accede Aquí.
- Fuente: https://www.analyticsvidhya.com/blog/2023/06/build-a-chatgpt-for-youtube-videos-with-langchain/

