El volumen de datos generados a nivel mundial continúa aumentando, desde juegos, comercio minorista y finanzas hasta manufactura, atención médica y viajes. Las organizaciones buscan más formas de utilizar rápidamente el flujo constante de datos para innovar para sus empresas y clientes. Tienen que capturar, procesar, analizar y cargar los datos de manera confiable en una infinidad de almacenes de datos, todo en tiempo real.
Apache Kafka es una opción popular para estas necesidades de transmisión en tiempo real. Sin embargo, puede resultar complicado configurar un clúster de Kafka junto con otros componentes de procesamiento de datos que se escalan automáticamente según las necesidades de su aplicación. Corre el riesgo de no aprovisionar suficiente para el tráfico pico, lo que puede provocar tiempo de inactividad, o de aprovisionar demasiado para la carga base, lo que genera desperdicio. AWS ofrece múltiples servicios sin servidor como Streaming administrado por Amazon para Apache Kafka (Amazon MSK), Manguera de datos de Amazon, Amazon DynamoDBy AWS Lambda que escala automáticamente dependiendo de sus necesidades.
En esta publicación, explicamos cómo puede utilizar algunos de estos servicios, incluido MSK sin servidor, para crear una plataforma de datos sin servidor que satisfaga sus necesidades en tiempo real.
Resumen de la solución
Imaginemos un escenario. Usted es responsable de administrar miles de módems para un proveedor de servicios de Internet implementados en múltiples geografías. Quiere monitorear la calidad de la conectividad del módem, lo que tiene un impacto significativo en la productividad y satisfacción del cliente. Su implementación incluye diferentes módems que deben monitorearse y mantenerse para garantizar un tiempo de inactividad mínimo. Cada dispositivo transmite miles de registros de 1 KB por segundo, como el uso de la CPU, el uso de la memoria, las alarmas y el estado de la conexión. Quiere acceso en tiempo real a estos datos para poder monitorear el rendimiento en tiempo real y detectar y mitigar problemas rápidamente. También necesita acceso a más largo plazo a estos datos para que los modelos de aprendizaje automático (ML) ejecuten evaluaciones de mantenimiento predictivo, encuentren oportunidades de optimización y pronostiquen la demanda.
Los clientes que recopilan los datos en el sitio están escritos en Python y pueden enviar todos los datos como temas de Apache Kafka a Amazon MSK. Para el acceso a datos en tiempo real y de baja latencia de su aplicación, puede utilizar Lambda y DynamoDB. Para el almacenamiento de datos a largo plazo, puede utilizar el servicio de conector administrado sin servidor Manguera de datos de Amazon para enviar datos a su lago de datos.
El siguiente diagrama muestra cómo puede crear esta aplicación sin servidor de un extremo a otro.
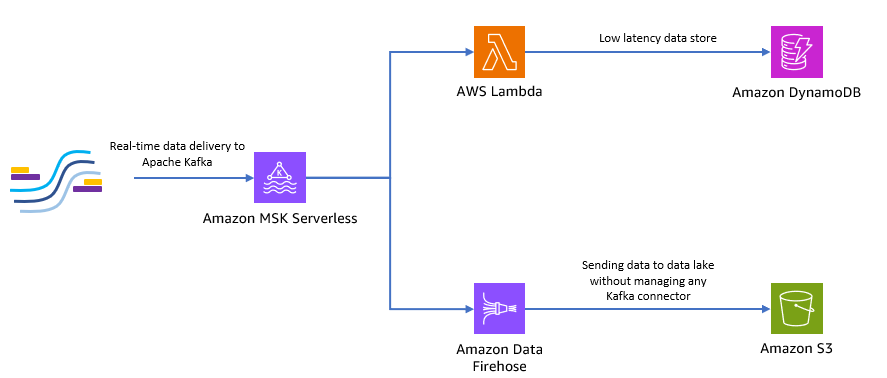
Sigamos los pasos de las siguientes secciones para implementar esta arquitectura.
Cree un clúster Kafka sin servidor en Amazon MSK
Usamos Amazon MSK para ingerir datos de telemetría en tiempo real desde módems. Crear un clúster Kafka sin servidor es sencillo en Amazon MSK. Sólo toma unos minutos usar el Consola de administración de AWS o SDK de AWS. Para utilizar la consola, consulte Introducción al uso de clústeres sin servidor de MSK. Creas un clúster sin servidor, Gestión de identidades y accesos de AWS (IAM) y máquina cliente.
Crear un tema de Kafka usando Python
Cuando su clúster y su máquina cliente estén listos, conecte SSH a su máquina cliente e instale Kafka Python y la biblioteca MSK IAM para Python.
- Ejecute los siguientes comandos para instalar Kafka Python y el Biblioteca MSK IAM:
- Crea un nuevo archivo llamado
createTopic.py. - Copie el siguiente código en este archivo, reemplazando el
bootstrap_serversyregioninformación con los detalles de su clúster. Para obtener instrucciones sobre cómo recuperar elbootstrap_serversinformación para su clúster MSK, consulte Obtención de los agentes de arranque para un clúster de Amazon MSK.
- Ejecute el
createTopic.pyscript para crear un nuevo tema de Kafka llamadomytopicen su clúster sin servidor:
Producir registros usando Python
Generemos algunos datos de telemetría del módem de muestra.
- Crea un nuevo archivo llamado
kafkaDataGen.py. - Copie el siguiente código en este archivo, actualizando el
BROKERSyregioninformación con los detalles de su cluster:
- Ejecute el
kafkaDataGen.pypara generar continuamente datos aleatorios y publicarlos en el tema de Kafka especificado:
Almacenar eventos en Amazon S3
Ahora almacena todos los datos del evento sin procesar en un Servicio de almacenamiento simple de Amazon (Amazon S3) lago de datos para análisis. Puede utilizar los mismos datos para entrenar modelos de ML. El integración con Amazon Data Firehose permite a Amazon MSK cargar datos sin problemas desde sus clústeres de Apache Kafka en un lago de datos de S3. Complete los siguientes pasos para transmitir datos continuamente desde Kafka a Amazon S3, eliminando la necesidad de crear o administrar sus propias aplicaciones de conector:
- En la consola de Amazon S3, cree un nuevo depósito. También puede utilizar un depósito existente.
- Cree una nueva carpeta en su depósito S3 llamada
streamingDataLake. - En la consola de Amazon MSK, elija su clúster MSK Serverless.
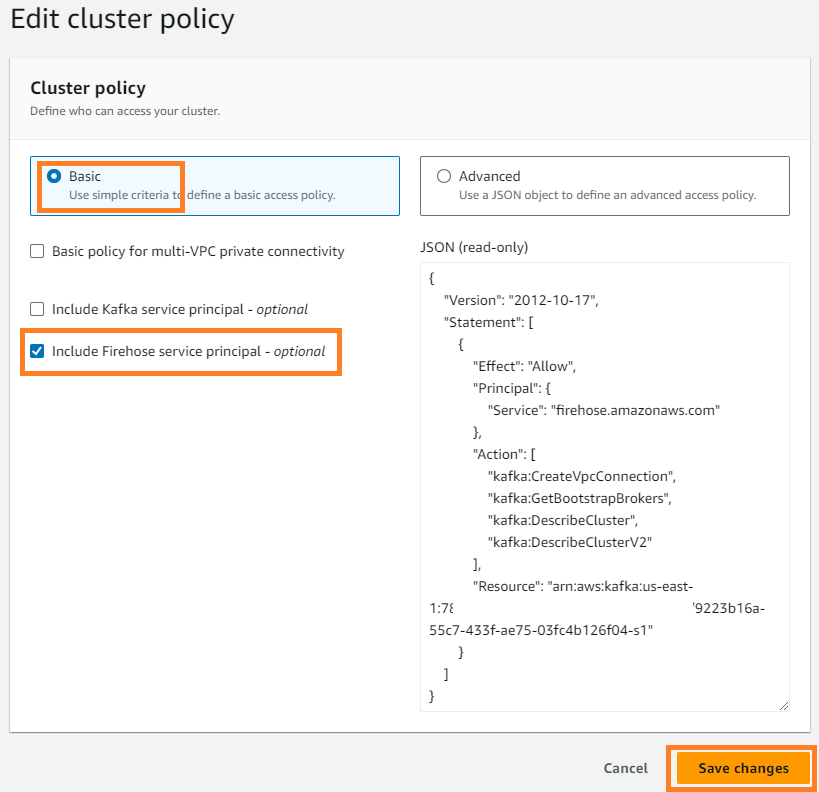
- En Acciones menú, seleccione Editar política de clúster.

- Seleccione Incluir director de servicio de Firehose y elige Guardar los cambios.
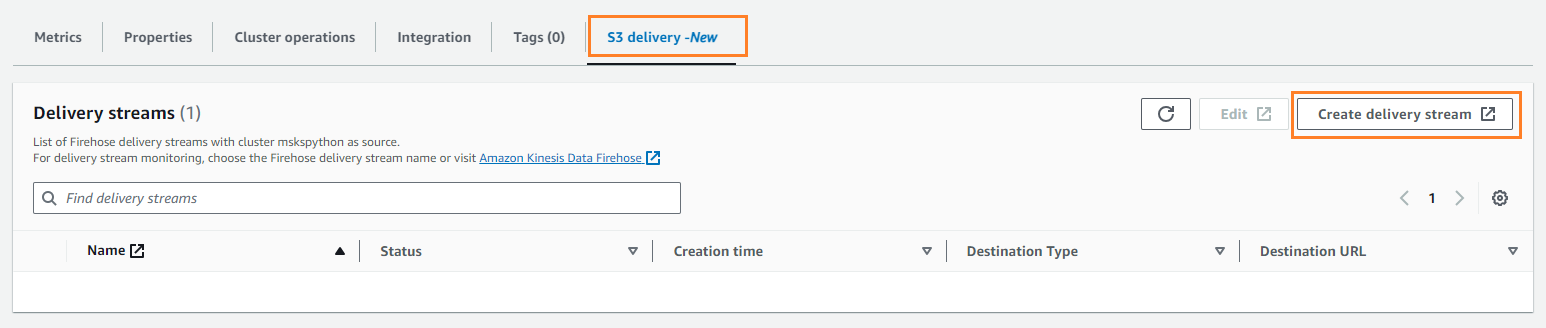
- En Entrega S3 pestaña, elegir Crear flujo de entrega.
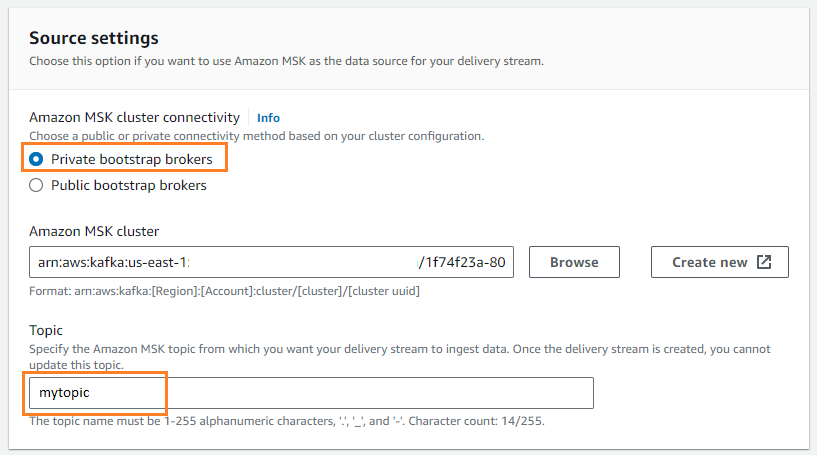
- Fuente, escoger Amazon MSK.
- Destino, escoger Amazon S3.

- Conectividad del clúster de Amazon MSK, seleccione Corredores de arranque privados.
- Tema, ingresa un nombre de tema (para esta publicación,
mytopic).
- Cucharón S3, escoger Explorar y elija su cubo S3.
- Participar
streamingDataLakecomo prefijo de depósito S3. - Participar
streamingDataLakeErrcomo prefijo de salida de error del depósito S3.

- Elige Crear flujo de entrega.
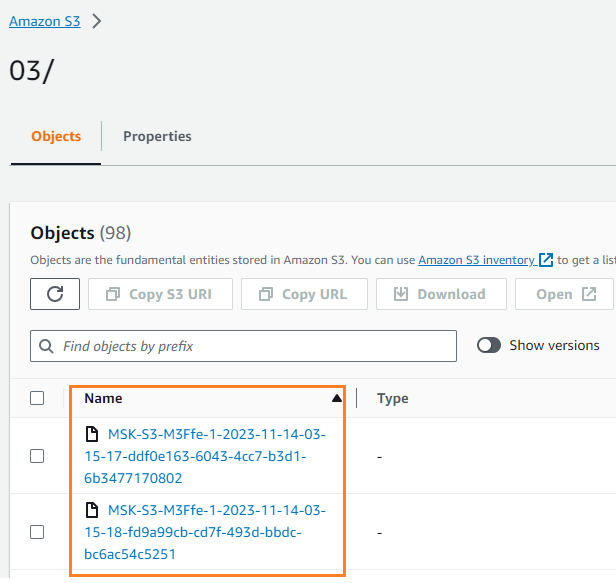
Puede verificar que los datos se escribieron en su depósito S3. Deberías ver que el streamingDataLake Se creó el directorio y los archivos se almacenan en particiones.
Almacenar eventos en DynamoDB
Para el último paso, almacena los datos del módem más recientes en DynamoDB. Esto permite que la aplicación cliente acceda al estado del módem e interactúe con el módem de forma remota desde cualquier lugar, con baja latencia y alta disponibilidad. Lambda funciona perfectamente con Amazon MSK. Lambda sondea internamente nuevos mensajes desde el origen del evento y luego invoca sincrónicamente la función Lambda de destino. Lambda lee los mensajes en lotes y los proporciona a su función como una carga útil de evento.
Primero creemos una tabla en DynamoDB. Referirse a Permisos de la API de DynamoDB: referencia de acciones, recursos y condiciones para verificar que su máquina cliente tenga los permisos necesarios.
- Crea un nuevo archivo llamado
createTable.py. - Copie el siguiente código en el archivo, actualizando el
region:
- Ejecute el
createTable.pyscript para crear una tabla llamadadevice_statusen DynamoDB:
Ahora configuremos la función Lambda.
- En la consola Lambda, elija Clave en el panel de navegación.
- Elige Crear función.
- Seleccione Autor desde cero.
- Nombre de la función¸ ingrese un nombre (por ejemplo,
my-notification-kafka). - Runtime, escoger 3.11 Python.
- Permisos, seleccione Use un rol existente y elige un rol con permisos para leer desde su cluster.
- Crea la función.
En la página de configuración de la función Lambda, ahora puede configurar fuentes, destinos y el código de su aplicación.
- Elige Agregar disparador.
- Configuración de disparo, introduzca
MSKpara configurar Amazon MSK como desencadenador de la función fuente de Lambda. - Clúster MSK, introduzca
myCluster. - Deseleccionar Activar gatillo, porque aún no ha configurado su función Lambda.
- Tamaño del lote, introduzca
100. - Posición inicial, escoger Últimos.
- Nombre del tema¸ ingrese un nombre (por ejemplo,
mytopic). - Elige Añada.
- En la página de detalles de la función Lambda, en el Código pestaña, ingrese el siguiente código:
- Implemente la función Lambda.
- En Configuración pestaña, elegir Editar para editar el disparador.
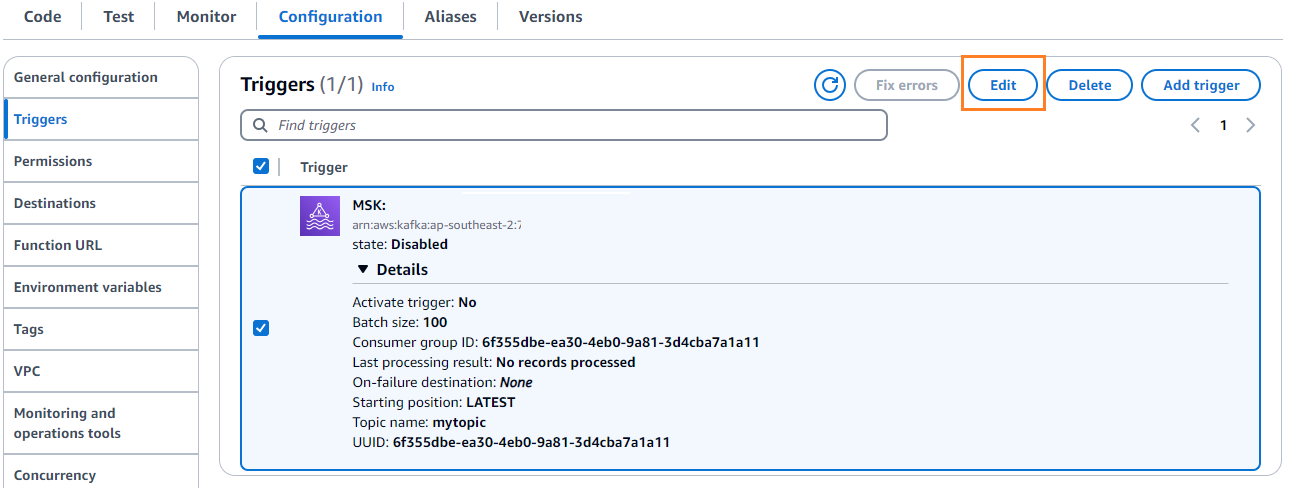
- Seleccione el disparador, luego elija Guardar.
- En la consola DynamoDB, elija Explorar elementos en el panel de navegación.
- Selecciona la mesa
device_status.
Verá que Lambda está escribiendo eventos generados en el tema de Kafka en DynamoDB.

Resumen
Los canales de transmisión de datos son fundamentales para crear aplicaciones en tiempo real. Sin embargo, configurar y gestionar la infraestructura puede resultar desalentador. En esta publicación, explicamos cómo crear una canalización de transmisión sin servidor en AWS utilizando Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose y otros servicios. Los beneficios clave son la ausencia de servidores que administrar, la escalabilidad automática de la infraestructura y un modelo de pago por uso que utiliza servicios totalmente administrados.
¿Listo para construir su propio canal en tiempo real? Comience hoy con una cuenta de AWS gratuita. Con el poder de la tecnología sin servidor, puede concentrarse en la lógica de su aplicación mientras AWS se encarga del trabajo pesado indiferenciado. ¡Construyamos algo increíble en AWS!
Acerca de los autores
 Masudur Rahaman Sayem es Arquitecto de datos de transmisión en AWS. Trabaja con clientes de AWS en todo el mundo para diseñar y crear arquitecturas de transmisión de datos para resolver problemas comerciales del mundo real. Se especializa en la optimización de soluciones que utilizan servicios de transmisión de datos y NoSQL. Sayem es un apasionado de la computación distribuida.
Masudur Rahaman Sayem es Arquitecto de datos de transmisión en AWS. Trabaja con clientes de AWS en todo el mundo para diseñar y crear arquitecturas de transmisión de datos para resolver problemas comerciales del mundo real. Se especializa en la optimización de soluciones que utilizan servicios de transmisión de datos y NoSQL. Sayem es un apasionado de la computación distribuida.
 Michael Oguike es gerente de producto de Amazon MSK. Le apasiona utilizar datos para descubrir conocimientos que impulsen la acción. Le gusta ayudar a clientes de una amplia gama de industrias a mejorar sus negocios mediante la transmisión de datos. A Michael también le encanta aprender sobre ciencias del comportamiento y psicología a través de libros y podcasts.
Michael Oguike es gerente de producto de Amazon MSK. Le apasiona utilizar datos para descubrir conocimientos que impulsen la acción. Le gusta ayudar a clientes de una amplia gama de industrias a mejorar sus negocios mediante la transmisión de datos. A Michael también le encanta aprender sobre ciencias del comportamiento y psicología a través de libros y podcasts.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

