
Imagen por editor
Has escuchado de Andrej Karpathy? Es un reconocido científico informático e investigador de inteligencia artificial conocido por su trabajo sobre aprendizaje profundo y redes neuronales. Desempeñó un papel clave en el desarrollo de ChatGPT en OpenAI y anteriormente fue director sénior de IA en Tesla. Incluso antes de eso, diseñó y fue el instructor principal de la primera clase de aprendizaje profundo. Stanford – CS 231n: Redes neuronales convolucionales para el reconocimiento visual. La clase se convirtió en una de las más grandes de Stanford y pasó de 150 inscritos en 2015 a 750 estudiantes en 2017. Recomiendo encarecidamente a cualquier persona interesada en el aprendizaje profundo que vea esto en YouTube. No entraré en más detalles sobre él y centraremos nuestra atención en una de sus charlas más populares en YouTube que cruzó 1.4 millones de visitas "Introducción a los modelos de lenguaje grandes". Esta charla es una introducción práctica a los LLM y es una visita obligada para cualquier persona interesada en los LLM.
He proporcionado un resumen conciso de esta charla. Si esto despierta su interés, le recomiendo encarecidamente que consulte las diapositivas y el enlace de YouTube que se proporcionarán al final de este artículo.
Esta charla proporciona una introducción completa a los LLM, sus capacidades y los riesgos potenciales asociados con su uso. Se ha dividido en 3 partes principales que son las siguientes:
Parte 1: LLM

Diapositivas de Andrej Karpathy
Los LLM están capacitados en un gran corpus de texto para generar respuestas similares a las humanas. En esta parte, Andrej analiza específicamente el modelo Llama 2-70b. Es uno de los LLM más grandes con 70 mil millones de parámetros. El modelo consta de dos componentes principales: el archivo de parámetros y el archivo de ejecución. El archivo de parámetros es un archivo binario grande que contiene los pesos y sesgos del modelo. Estos pesos y sesgos son esencialmente el "conocimiento" que el modelo ha aprendido durante el entrenamiento. El archivo de ejecución es un fragmento de código que se utiliza para cargar el archivo de parámetros y ejecutar el modelo. El proceso de formación del modelo se puede dividir en las dos etapas siguientes:
1. Entrenamiento previo
Esto implica recopilar una gran cantidad de texto, alrededor de 10 terabytes, de Internet y luego usar un clúster de GPU para entrenar el modelo con estos datos. El resultado del proceso de formación es un modelo base que es la compresión con pérdidas de Internet. Es capaz de generar texto coherente y relevante pero no responder preguntas directamente.
2. Ajuste
El modelo previamente entrenado se entrena adicionalmente en un conjunto de datos de alta calidad para hacerlo más útil. Esto da como resultado un modelo asistente. Andrej también menciona una tercera etapa de ajuste, que implica el uso de etiquetas de comparación. En lugar de generar respuestas desde cero, el modelo recibe múltiples respuestas candidatas y se le pide que elija la mejor. Esto puede ser más fácil y eficiente que generar respuestas y puede mejorar aún más el rendimiento del modelo. Este proceso se llama aprendizaje reforzado a partir de retroalimentación humana (RLHF).
Parte 2: Futuro de los LLM
Diapositivas de Andrej Karpathy
Mientras se analiza el futuro de los grandes modelos de lenguaje y sus capacidades, se analizan los siguientes puntos clave:
1. Ley de escala
El rendimiento del modelo se correlaciona con dos variables: la cantidad de parámetros y la cantidad de texto de entrenamiento. Los modelos más grandes entrenados con más datos tienden a lograr un mejor rendimiento.
2. Uso de herramientas
Los LLM como ChatGPT pueden utilizar herramientas como un navegador, una calculadora y bibliotecas de Python para realizar tareas que de otro modo serían desafiantes o imposibles para el modelo por sí solo.
3. Pensamiento del sistema uno y del sistema dos en los LLM
Actualmente, los LLM emplean predominantemente el pensamiento del sistema uno: rápido, instintivo y basado en patrones. Sin embargo, existe interés en desarrollar LLM capaces de participar en el pensamiento del sistema dos: más lento, racional y que requiere un esfuerzo consciente.
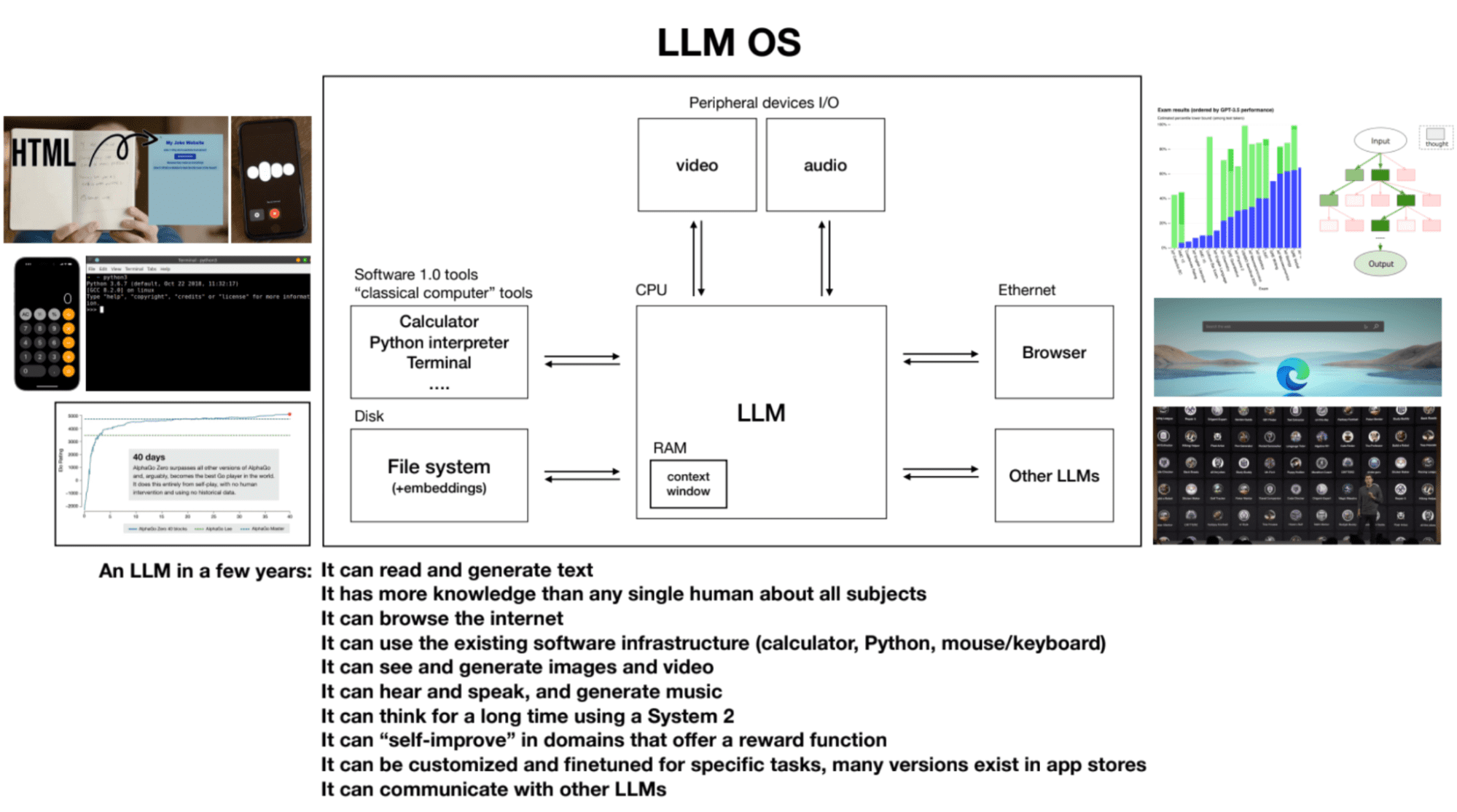
4. LLM SO
Los LLM pueden considerarse como el proceso central de un sistema operativo emergente. Pueden leer y generar texto, tener amplios conocimientos sobre diversos temas, navegar por Internet o consultar archivos locales, utilizar la infraestructura de software existente, generar imágenes y vídeos, oír, hablar y pensar durante períodos prolongados utilizando el sistema 2. La ventana contextual de un LLM es análogo a la RAM en una computadora, y el proceso del kernel intenta paginar información relevante dentro y fuera de su ventana de contexto para realizar tareas.
Parte 3: Seguridad de los LLM

Diapositivas de Andrej Karpathy
Andrej destaca los esfuerzos de investigación en curso para abordar los desafíos de seguridad asociados con los LLM. Se analizan los siguientes ataques:
1. Fuga de la cárcel
Intenta eludir las medidas de seguridad en los LLM para extraer información dañina o inapropiada. Los ejemplos incluyen juegos de roles para engañar al modelo y manipular respuestas usando secuencias optimizadas de palabras o imágenes.
2. Inyección inmediata
Implica inyectar nuevas instrucciones o indicaciones en un LLM para manipular sus respuestas. Los atacantes pueden ocultar instrucciones dentro de imágenes o páginas web, lo que lleva a la inclusión de contenido no relacionado o dañino en las respuestas del modelo.
3. Envenenamiento de datos/ataque de puerta trasera/ataque de agente durmiente
Implica entrenar un modelo de lenguaje grande con datos maliciosos o manipulados que contienen frases desencadenantes. Cuando el modelo encuentra la frase desencadenante, puede manipularse para realizar acciones indeseables o proporcionar predicciones incorrectas.
Puedes ver el vídeo completo en YouTube haciendo clic a continuación:
[contenido incrustado][contenido incrustado]
Diapositivas: Haga clic aquí
Si es nuevo en los LLM y busca recursos para iniciar su viaje, ¡esta lista completa es un excelente lugar para comenzar! Contiene cursos básicos y específicos de LLM que lo ayudarán a construir una base sólida. Además, si está interesado en una experiencia de aprendizaje más estructurada, Maxime Labonne lanzó recientemente su curso LLM con tres pistas diferentes para elegir según sus necesidades y nivel de experiencia. Aquí están los enlaces a ambos recursos para su comodidad:
- Una lista completa de recursos para dominar modelos de lenguaje grandes por Kanwal Mehreen
- Curso de modelo de lenguaje grande de Maxime Labonne
Kanwal Mehreen es un aspirante a desarrollador de software con un gran interés en la ciencia de datos y las aplicaciones de IA en medicina. Kanwal fue seleccionado como Google Generation Scholar 2022 para la región APAC. A Kanwal le encanta compartir conocimientos técnicos escribiendo artículos sobre temas de actualidad y le apasiona mejorar la representación de las mujeres en la industria tecnológica.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://www.kdnuggets.com/unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy?utm_source=rss&utm_medium=rss&utm_campaign=unlock-the-secrets-of-llms-in-a-60-minute-with-andrej-karpathy

