Servicio de base de datos relacional de Amazon (Amazon RDS) para MySQL Integración de ETL cero con Desplazamiento al rojo de Amazon fue anunció en vista previa en AWS re:Invent 2023 para Amazon RDS para MySQL versión 8.0.28 o superior. En esta publicación, brindamos orientación paso a paso sobre cómo comenzar con análisis operativos casi en tiempo real utilizando esta función. Esta publicación es una continuación de la serie zero-ETL que comenzó con Guía de introducción para análisis operativos casi en tiempo real mediante la integración zero-ETL de Amazon Aurora con Amazon Redshift.
Desafios
Hoy en día, los clientes de todas las industrias buscan utilizar los datos para su ventaja competitiva y aumentar los ingresos y la participación del cliente mediante la implementación de casos de uso de análisis casi en tiempo real, como estrategias de personalización, detección de fraude, monitoreo de inventario y muchos más. Existen dos enfoques amplios para analizar datos operativos para estos casos de uso:
- Analice los datos in situ en la base de datos operativa (como réplicas de lectura, consultas federadas y aceleradores de análisis)
- Mueva los datos a un almacén de datos optimizado para ejecutar consultas específicas de casos de uso, como un almacén de datos.
La integración de ETL cero se centra en simplificar el último enfoque.
El proceso de extracción, transformación y carga (ETL) ha sido un patrón común para mover datos de una base de datos operativa a un almacén de datos analíticos. ELT es donde los datos extraídos se cargan tal cual en el destino primero y luego se transforman. Los oleoductos ETL y ELT pueden ser costosos de construir y complejos de administrar. Con múltiples puntos de contacto, los errores intermitentes en los procesos de ETL y ELT pueden provocar grandes retrasos, dejando las aplicaciones de almacenamiento de datos con datos obsoletos o faltantes, lo que conduce aún más a la pérdida de oportunidades comerciales.
Alternativamente, las soluciones que analizan datos in situ pueden funcionar muy bien para acelerar consultas en una única base de datos, pero dichas soluciones no pueden agregar datos de múltiples bases de datos operativas para clientes que necesitan ejecutar análisis unificados.
Cero-ETL
A diferencia de los sistemas tradicionales donde los datos están aislados en una base de datos y el usuario tiene que hacer un equilibrio entre análisis unificado y rendimiento, los ingenieros de datos ahora pueden replicar datos de múltiples bases de datos RDS para MySQL en un único almacén de datos Redshift para obtener información integral muchas aplicaciones o particiones. Las actualizaciones de las bases de datos transaccionales se propagan automática y continuamente a Amazon Redshift para que los ingenieros de datos tengan la información más reciente casi en tiempo real. No hay infraestructura que administrar y la integración se puede ampliar y reducir automáticamente según el volumen de datos.
En AWS, hemos hecho progresos constantes para llevar nuestra visión de cero ETL a la vida. Actualmente, las siguientes fuentes son compatibles con integraciones de ETL cero:
Cuando crea una integración ETL cero para Amazon Redshift, continúa pagando por el uso de la base de datos de origen subyacente y de la base de datos de destino de Redshift. Referirse a Costos de integración Zero-ETL (vista previa) para más información.
Con la integración ETL cero con Amazon Redshift, la integración replica datos de la base de datos de origen en el almacén de datos de destino. Los datos están disponibles en Amazon Redshift en cuestión de segundos, lo que le permite utilizar las funciones de análisis de Amazon Redshift y capacidades como el intercambio de datos, la optimización autónoma de la carga de trabajo, el escalado de simultaneidad, el aprendizaje automático y mucho más. Puede continuar con el procesamiento de su transacción en Amazon RDS o Aurora amazónica y al mismo tiempo utiliza Amazon Redshift para cargas de trabajo de análisis, como informes y paneles.
El siguiente diagrama ilustra esta arquitectura.
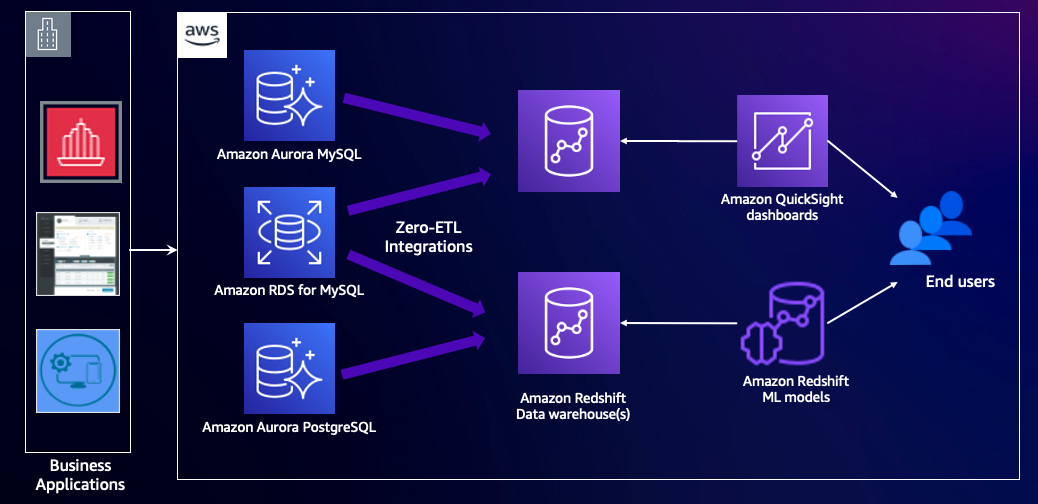
Resumen de la solución
Consideremos TICKET, un sitio web ficticio donde los usuarios compran y venden entradas online para eventos deportivos, espectáculos y conciertos. Los datos transaccionales de este sitio web se cargan en una base de datos de Amazon RDS para MySQL 8.0.28 (o versión superior). Los analistas de negocios de la compañía quieren generar métricas para identificar el movimiento de entradas a lo largo del tiempo, las tasas de éxito de los vendedores y los eventos, lugares y temporadas más vendidos. Les gustaría obtener estas métricas casi en tiempo real mediante una integración ETL cero.
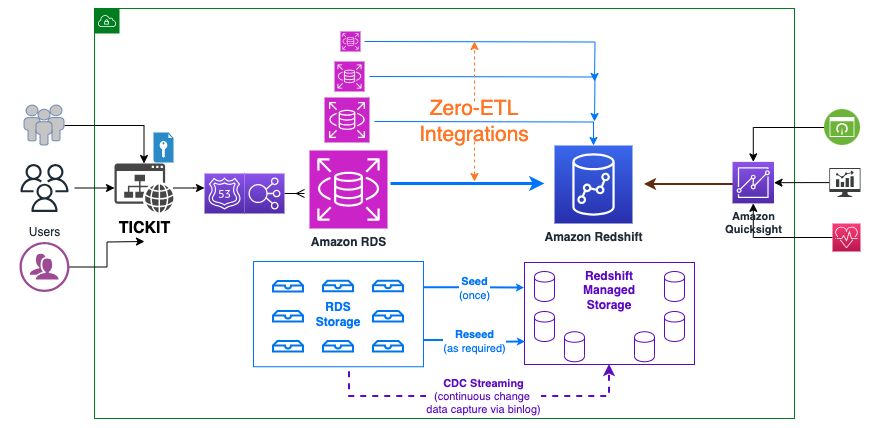
La integración se configura entre Amazon RDS para MySQL (origen) y Amazon Redshift (destino). Los datos transaccionales del origen se actualizan casi en tiempo real en el destino, que procesa consultas analíticas.
Puede utilizar la opción sin servidor o un clúster RA3 cifrado para Amazon Redshift. Para esta publicación, utilizamos una base de datos RDS aprovisionada y un almacén de datos aprovisionado por Redshift.
El siguiente diagrama ilustra la arquitectura de alto nivel.
Los siguientes son los pasos necesarios para configurar la integración ETL cero. Estos pasos se pueden realizar automáticamente mediante el asistente de ETL cero, pero será necesario reiniciar si el asistente cambia la configuración de Amazon RDS o Amazon Redshift. Puede realizar estos pasos manualmente, si aún no está configurado, y realizar los reinicios según le convenga. Para obtener las guías completas de introducción, consulte Trabajar con integraciones de Amazon RDS zero-ETL con Amazon Redshift (versión preliminar) y Trabajar con integraciones de ETL cero.
- Configure el origen de RDS para MySQL con un grupo de parámetros de base de datos personalizado.
- Configure el clúster de Redshift para habilitar identificadores que distingan entre mayúsculas y minúsculas.
- Configure los permisos necesarios.
- Cree la integración de ETL cero.
- Cree una base de datos a partir de la integración en Amazon Redshift.
Configure el origen de RDS para MySQL con un grupo de parámetros de base de datos personalizado
Para crear una base de datos RDS para MySQL, complete los siguientes pasos:
- En la consola de Amazon RDS, cree un grupo de parámetros de base de datos llamado
zero-etl-custom-pg.
La integración Zero-ETL funciona mediante el uso de registros binarios (binlogs) generados por la base de datos MySQL. Para habilitar binlogs en Amazon RDS para MySQL, se debe habilitar un conjunto específico de parámetros.
- Establezca la siguiente configuración de parámetros de clúster binlog:
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
Además, asegúrese de que el binlog_row_value_options El parámetro no está configurado en PARTIAL_JSON. De forma predeterminada, este parámetro no está configurado.
- Elige Bases de datos en el panel de navegación, luego elija Crear base de datos.
- Versión del motor, escoger MySQL 8.0.28 (o mas alto).

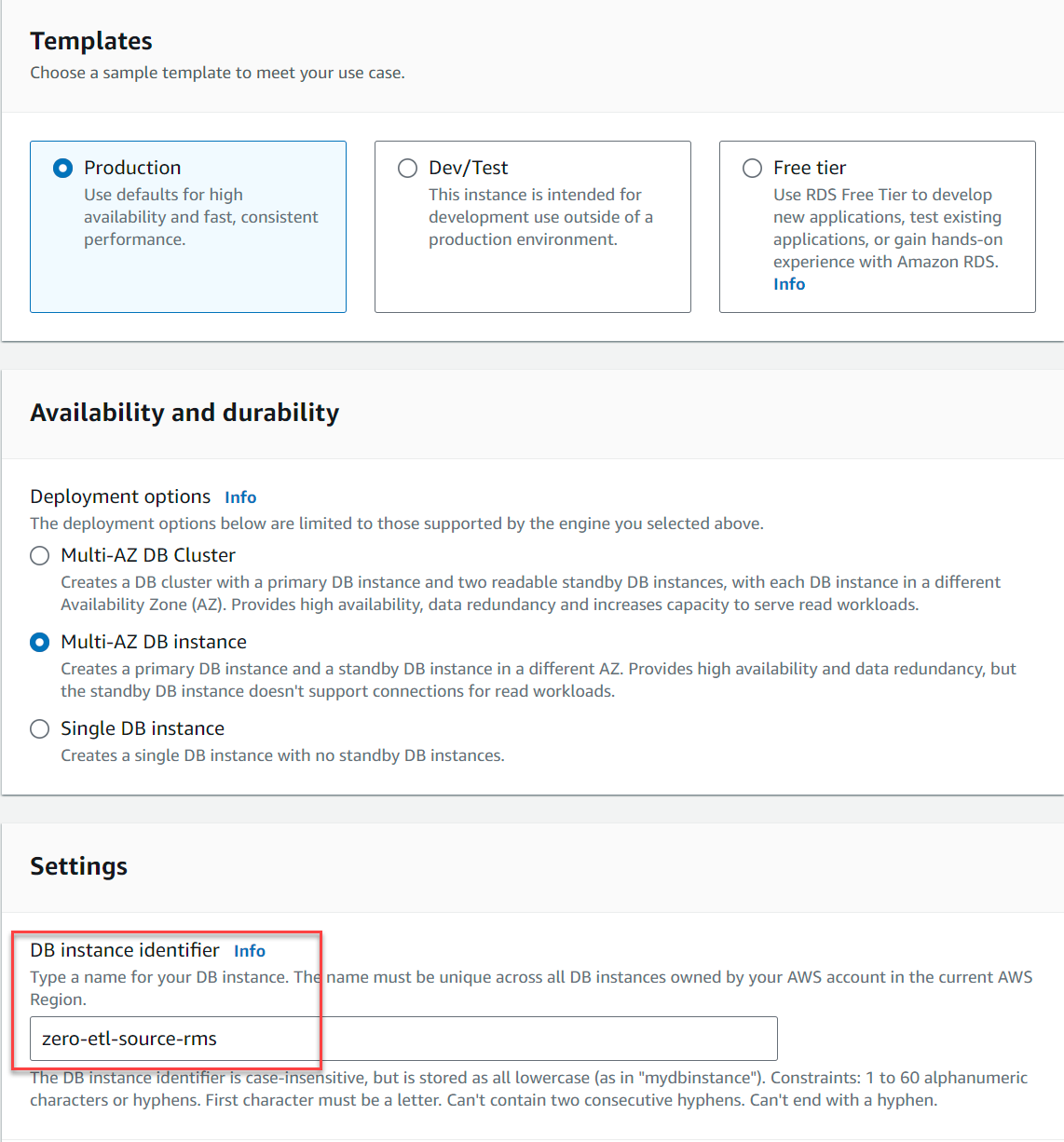
- Plantillas, seleccione Producción.
- Disponibilidad y durabilidad, seleccione cualquiera Instancia de base de datos multi-AZ or Instancia de base de datos única (Los clústeres de base de datos Multi-AZ no son compatibles al momento de escribir este artículo).
- identificador de instancia de base de datos, introduzca
zero-etl-source-rms.
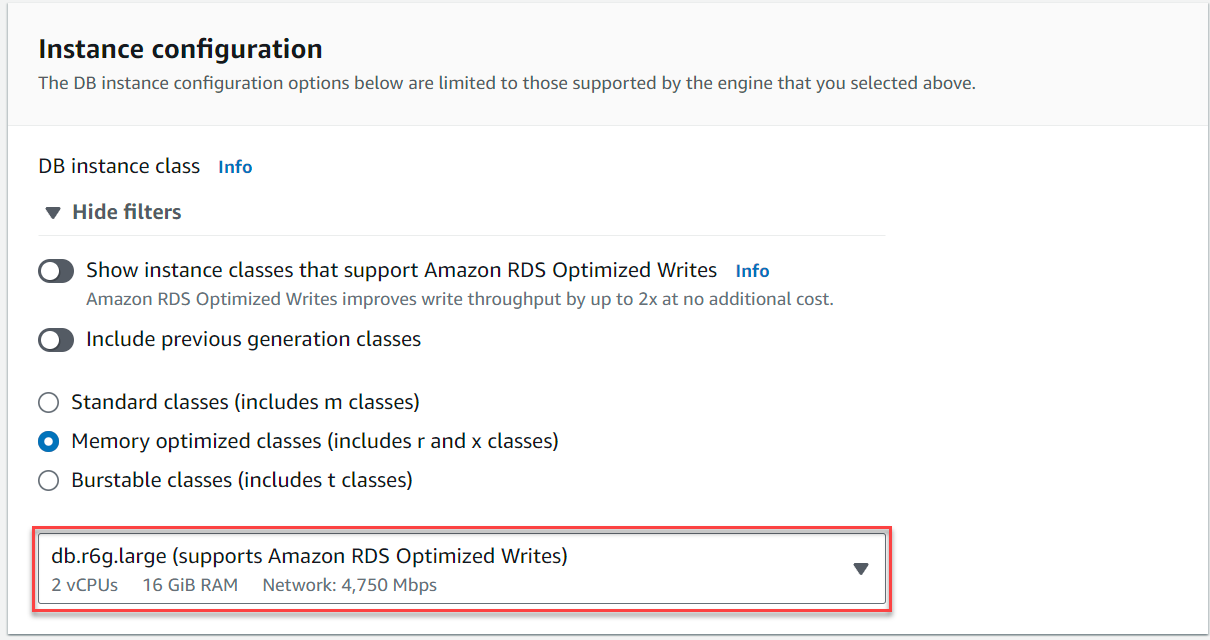
- under Configuración de instancia, seleccione Clases optimizadas para memoria y elige la instancia
db.r6g.large, que debería ser suficiente para el caso de uso de TICKIT.
- under Configuración adicional, Para Grupo de parámetros de clúster de base de datos, elija el grupo de parámetros que creó anteriormente (
zero-etl-custom-pg).
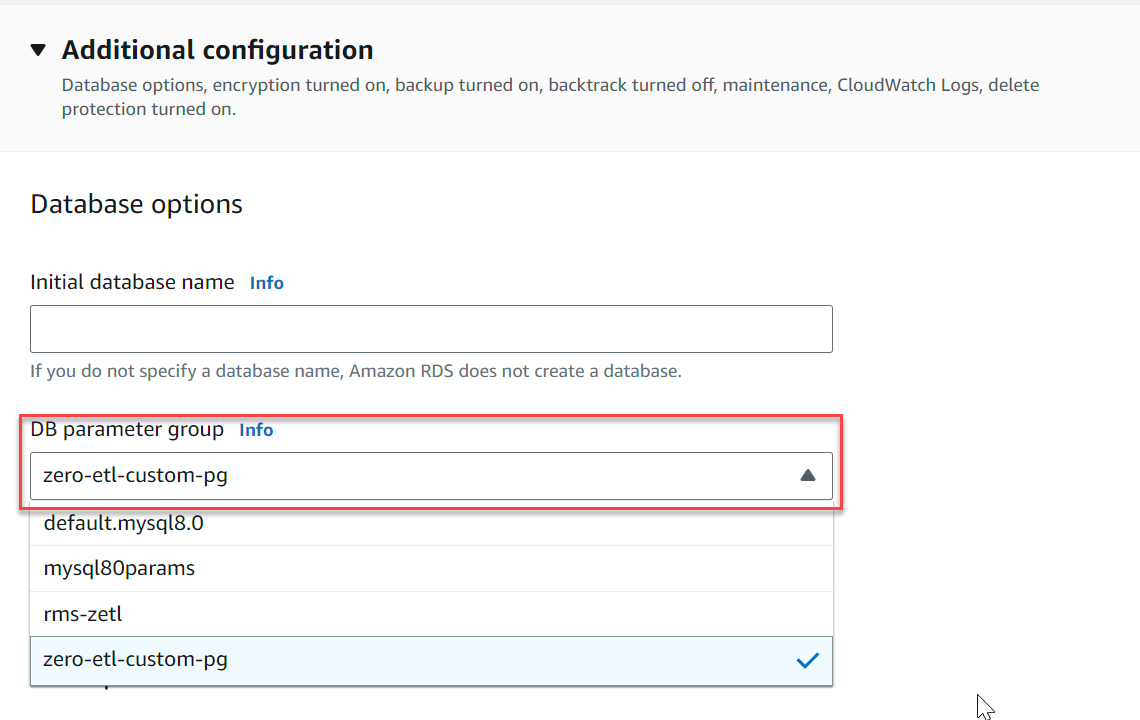
- Elige Crear base de datos.
En un par de minutos, debería activar una base de datos RDS para MySQL como fuente para la integración ETL cero.
Configurar el destino de Redshift
Después de crear su clúster de base de datos de origen, debe crear y configurar un almacén de datos de destino en Amazon Redshift. El almacén de datos debe cumplir los siguientes requisitos:
- Usando un tipo de nodo RA3 (
ra3.16xlarge,ra3.4xlargeora3.xlplus) o Amazon Redshift sin servidor - Cifrado (si se utiliza un clúster aprovisionado)
Para nuestro caso de uso, cree un clúster de Redshift completando los siguientes pasos:
- En la consola de Amazon Redshift, elija Configuraciones y luego elige Gestión de cargas de trabajo.
- En la sección del grupo de parámetros, elija Crear.
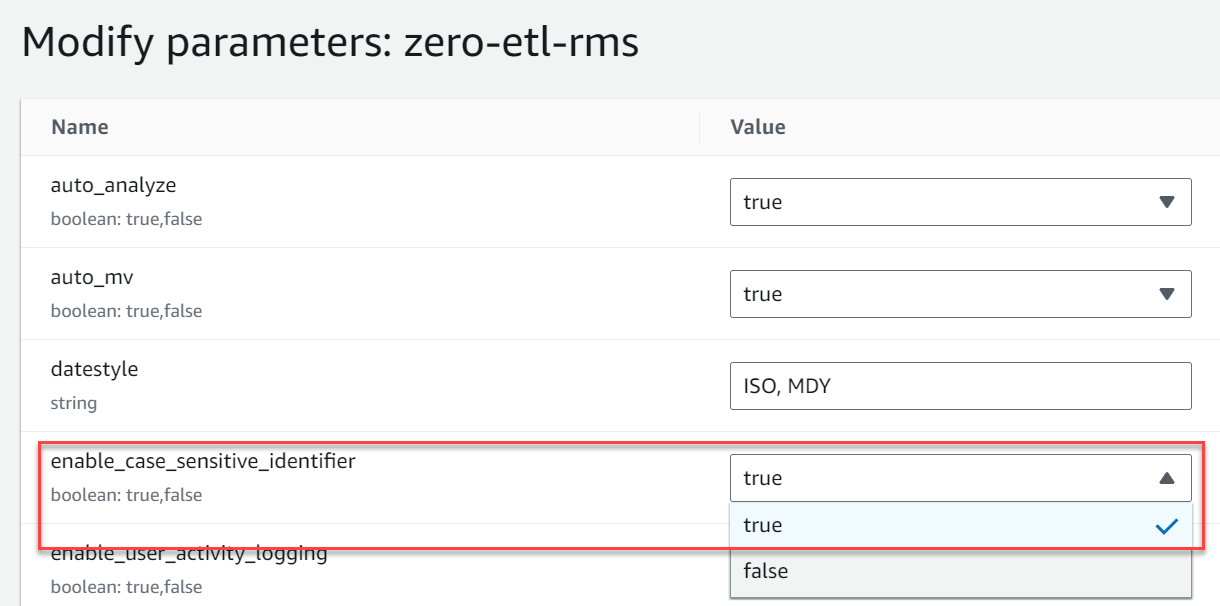
- Cree un nuevo grupo de parámetros llamado
zero-etl-rms. - Elige Editar parámetros y cambia el valor de
enable_case_sensitive_identifieraTrue. - Elige Guardar.
También puedes utilizar la Interfaz de línea de comandos de AWS (CLI de AWS) comando grupo de trabajo de actualización para Redshift sin servidor:
- Elige Panel de control de clústeres aprovisionados.
En la parte superior de la ventana de su consola, verá un Pruebe las nuevas funciones de Amazon Redshift en versión preliminar bandera.
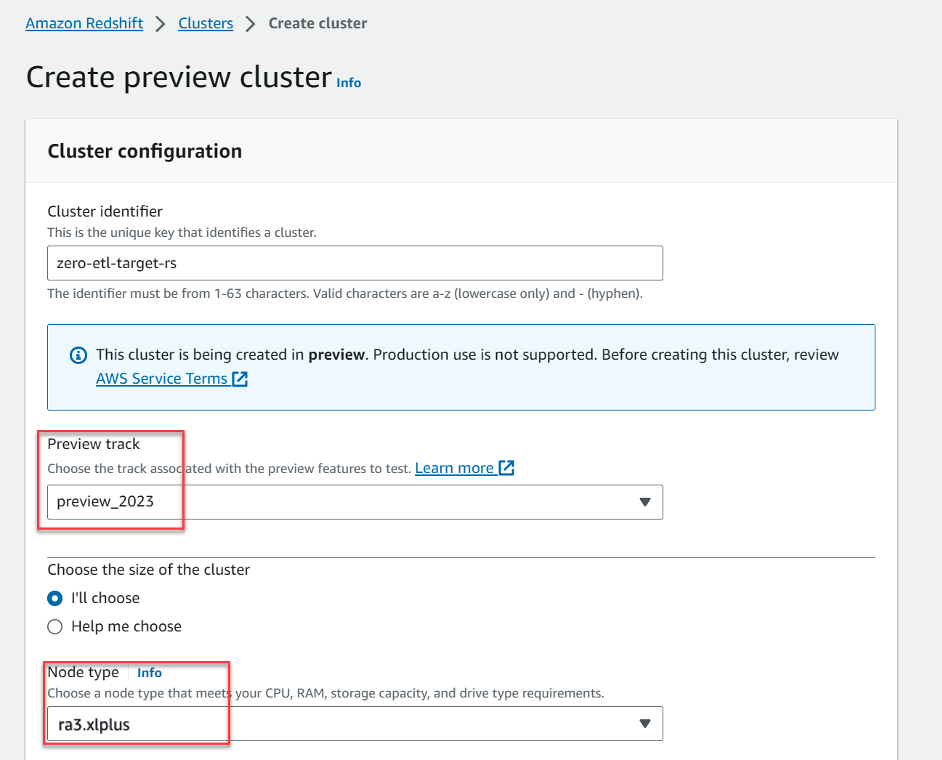
- Elige Crear clúster de vista previa.

- Vista previa de la pista, eligió
preview_2023. - Tipo de nodo, elija uno de los tipos de nodos admitidos (para esta publicación, usamos
ra3.xlplus).
- under Configuraciones adicionales, expandir Configuraciones de base de datos.
- Grupos de parámetros, escoger
zero-etl-rms. - Cifrado, seleccione Utilice el servicio de administración de claves de AWS.
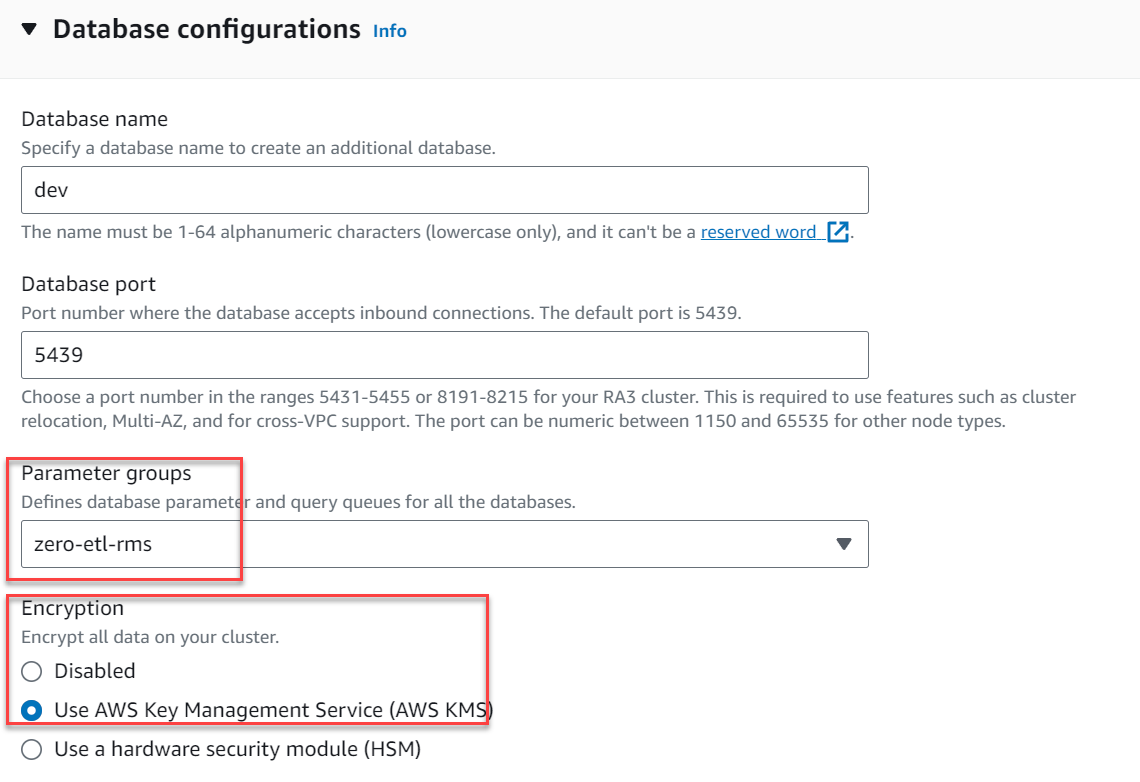
- Elige Crear clúster.
El grupo debería convertirse Disponible En unos pocos minutos.

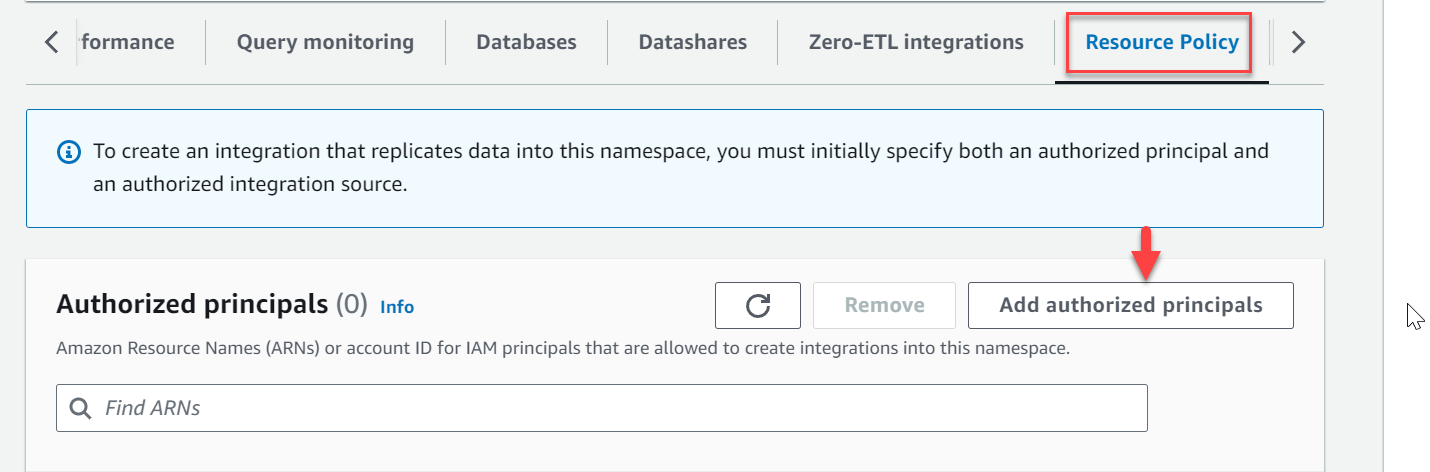
- Navegar al espacio de nombres
zero-etl-target-rs-nsY elige la Política de recursos . - Elige Agregar principales autorizados.
- Introduzca el nombre de recurso de Amazon (ARN) del usuario o rol de AWS, o el ID de la cuenta de AWS (principales de IAM) que pueden crear integraciones.
Un ID de cuenta se almacena como un ARN con usuario raíz.
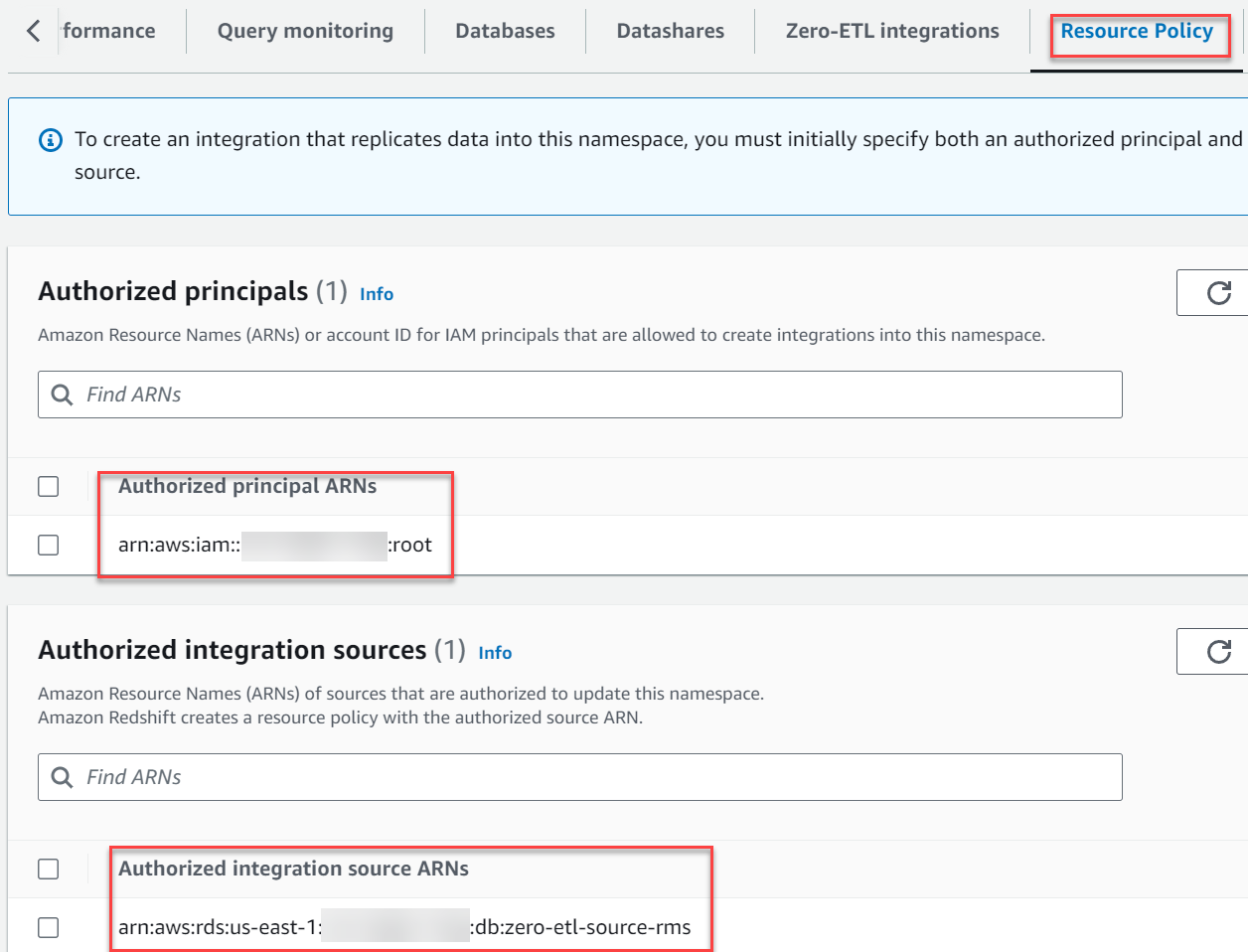
- En Fuentes de integración autorizadas sección, elija Agregar fuente de integración autorizada para agregar el ARN de la instancia de base de datos de RDS para MySQL que es la fuente de datos para la integración de ETL cero.
Puede encontrar este valor yendo a la consola de Amazon RDS y navegando hasta el Configuración pestaña del zero-etl-source-rms Instancia de base de datos.

Su política de recursos debería parecerse a la siguiente captura de pantalla.
Configurar los permisos necesarios
Para crear una integración de ETL cero, su usuario o función debe tener un adjunto política basada en la identidad con el apropiado Gestión de identidades y accesos de AWS (IAM) permisos. El propietario de una cuenta de AWS puede configurar los permisos requeridos para usuarios o roles que pueden crear integraciones sin ETL. La política de ejemplo permite al principal asociado realizar las siguientes acciones:
- Cree integraciones sin ETL para la instancia de base de datos RDS de origen para MySQL.
- Ver y eliminar todas las integraciones de cero ETL.
- Cree integraciones entrantes en el almacén de datos de destino. Este permiso no es necesario si la misma cuenta es propietaria del almacén de datos de Redshift y esta cuenta es una entidad principal autorizada para ese almacén de datos. Tenga en cuenta también que Amazon Redshift tiene un formato de ARN diferente para clústeres aprovisionados y sin servidor:
- Aprovisionado –
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Sin servidor –
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Aprovisionado –
Complete los siguientes pasos para configurar los permisos:
- En la consola de IAM, elija Políticas internas en el panel de navegación.
- Elige Crear política.
- Cree una nueva política llamada
rds-integrationsusando el siguiente JSON (reemplaceregionyaccount-idcon sus valores reales):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Adjunte la política que creó a sus permisos de rol o usuario de IAM.
Crear la integración de ETL cero
Para crear la integración de ETL cero, complete los siguientes pasos:
- En la consola de Amazon RDS, elija Integraciones de ETL cero en el panel de navegación.
- Elige Cree una integración sin ETL.

- Identificador de integración, introduzca un nombre, por ejemplo
zero-etl-demo.
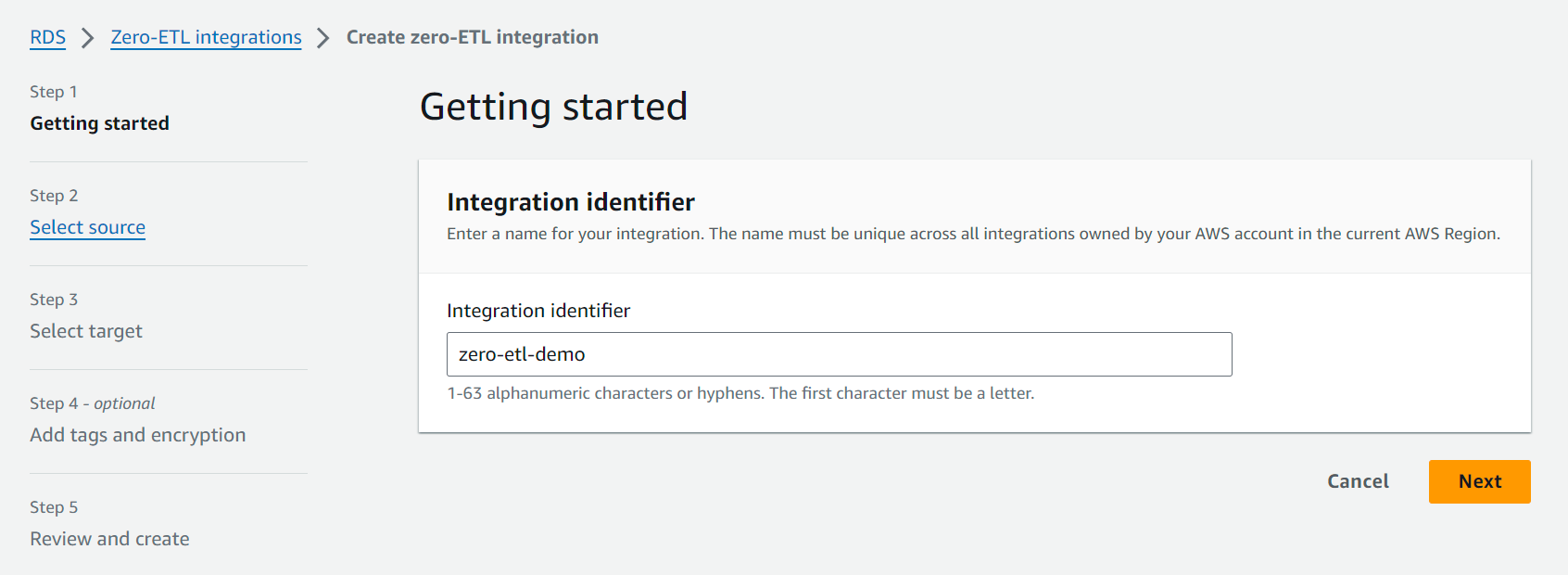
- Base de datos de origen, escoger Explorar bases de datos RDS y elija el clúster de origen
zero-etl-source-rms. - Elige Siguiente.

- under Target, Para Almacén de datos de Amazon Redshift, escoger Explorar los almacenes de datos de Redshift y elija el almacén de datos Redshift (
zero-etl-target-rs). - Elige Siguiente.
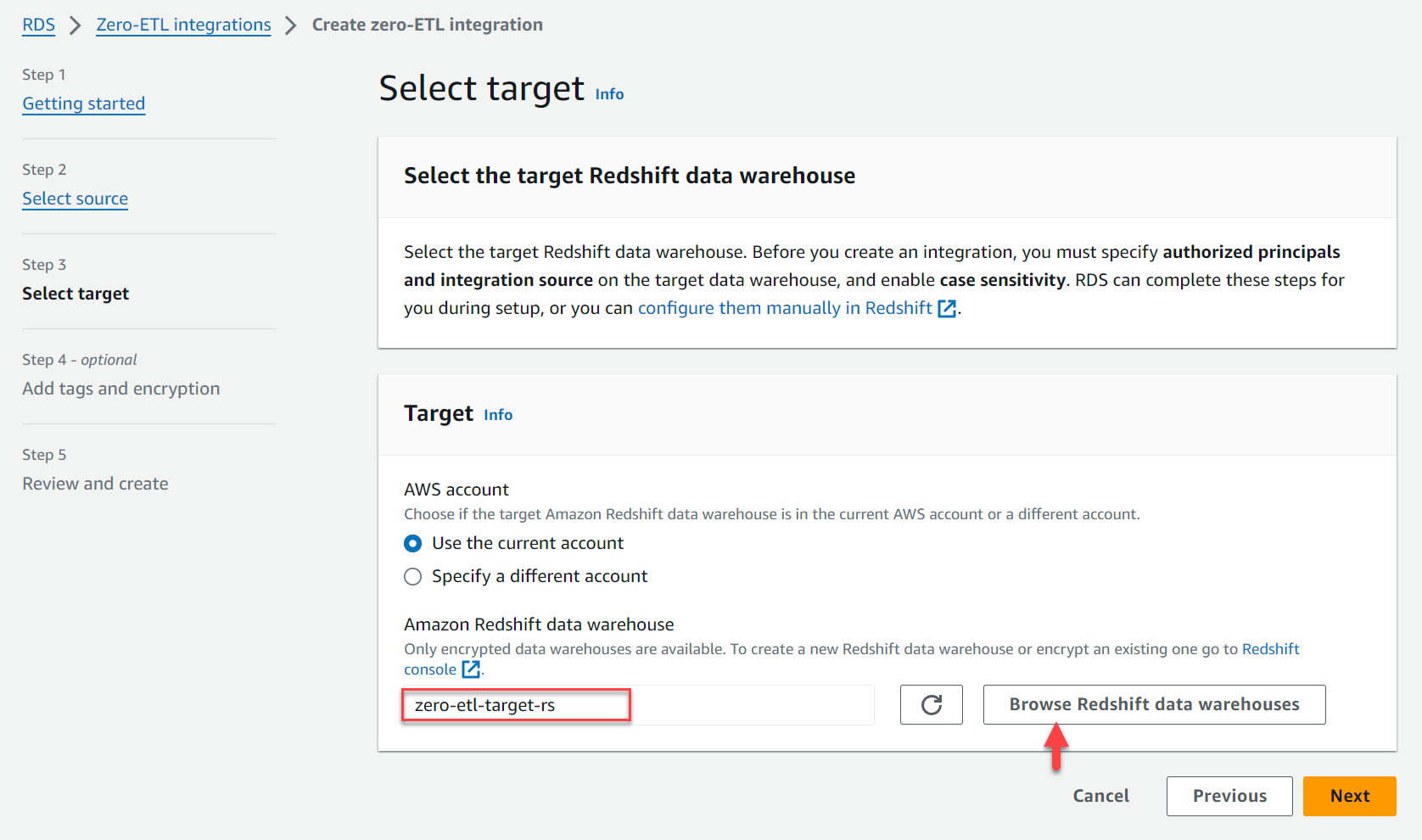
- Agregue etiquetas y cifrado, si corresponde.
- Elige Siguiente.
- Verifique el nombre de la integración, el origen, el destino y otras configuraciones.
- Elige Cree una integración sin ETL.
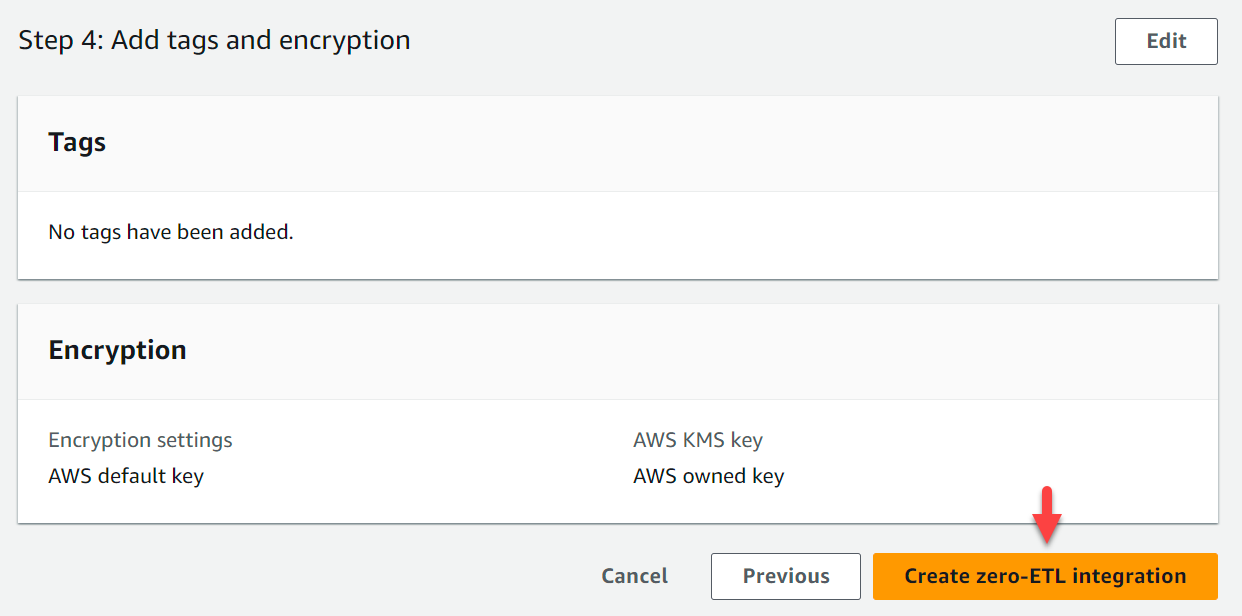
Puede elegir la integración para ver los detalles y monitorear su progreso. El estado tardó unos 30 minutos en cambiar de Creamos a Active.

El tiempo variará según el tamaño de su conjunto de datos en la fuente.
Crear una base de datos a partir de la integración en Amazon Redshift
Para crear su base de datos a partir de la integración ETL cero, complete los siguientes pasos:
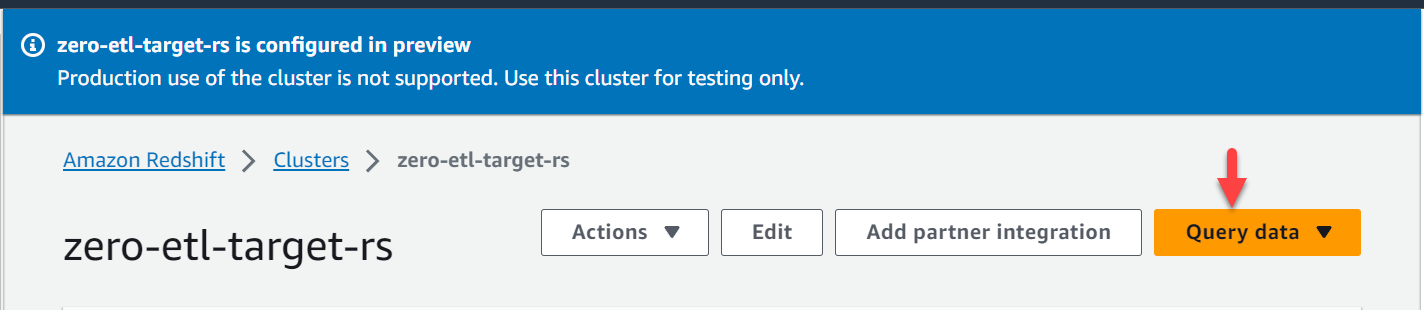
- En la consola de Amazon Redshift, elija Clusters en el panel de navegación.
- Abra la
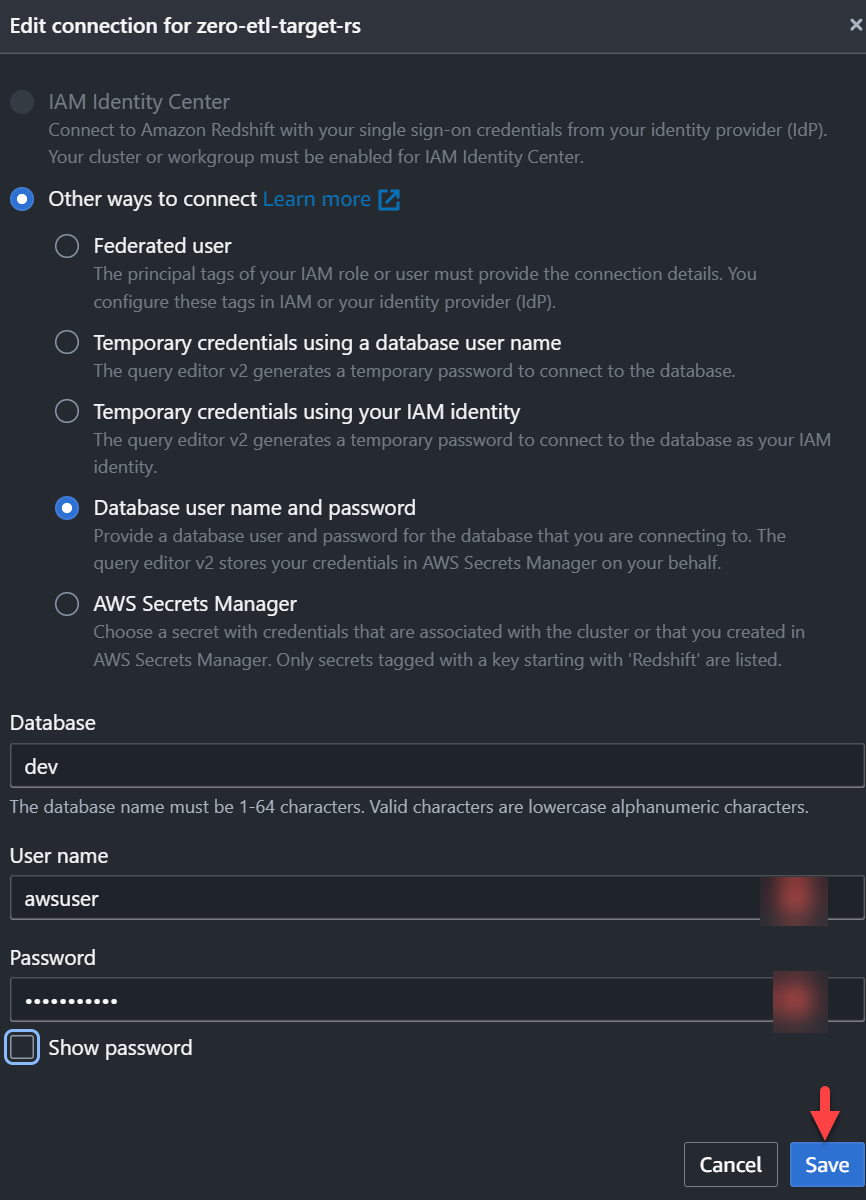
zero-etl-target-rsracimo. - Elige Consultar datos para abrir el editor de consultas v2.
- Conéctese al almacén de datos de Redshift eligiendo Guardar.
- Obtener el
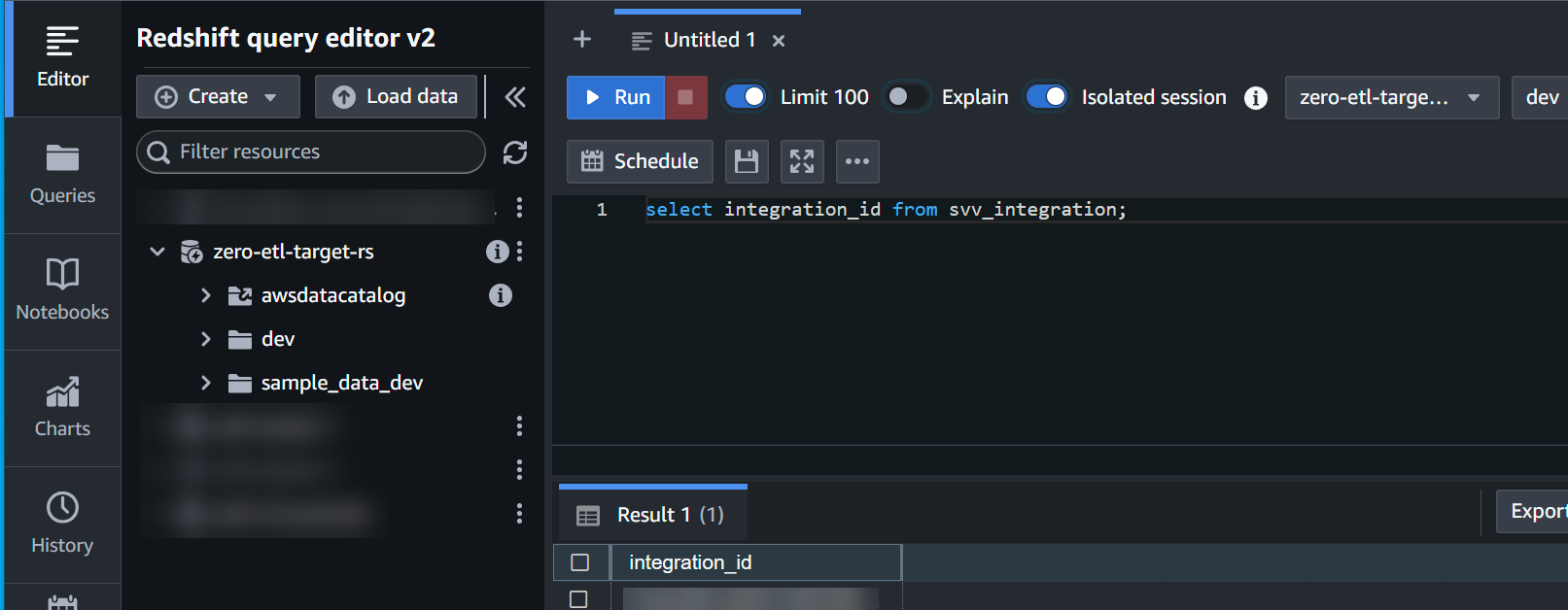
integration_iddel desplegablesvv_integrationtabla del sistema:
select integration_id from svv_integration; -- copy this result, use in the next sql
- Ingrese al
integration_iddel paso anterior para crear una nueva base de datos a partir de la integración:
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
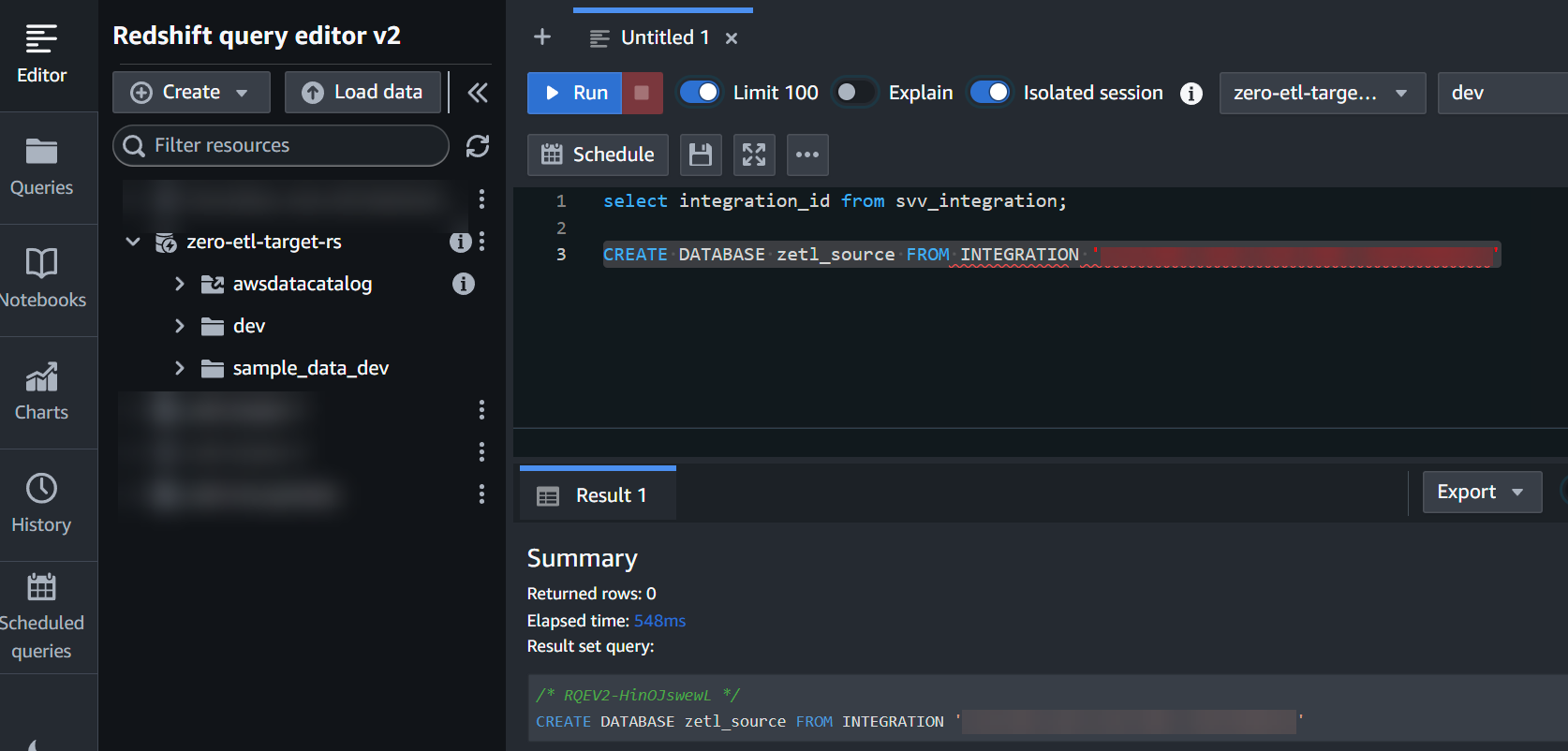
La integración ahora está completa y una instantánea completa del origen se reflejará tal como está en el destino. Los cambios en curso se sincronizarán casi en tiempo real.
Analice los datos transaccionales casi en tiempo real
Ahora podemos ejecutar análisis en los datos operativos de TICKIT.
Rellene los datos de TICKIT de origen
Para completar los datos de origen, complete los siguientes pasos:
- Copie los archivos de datos de entrada CSV en un directorio local. El siguiente es un comando de ejemplo:
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
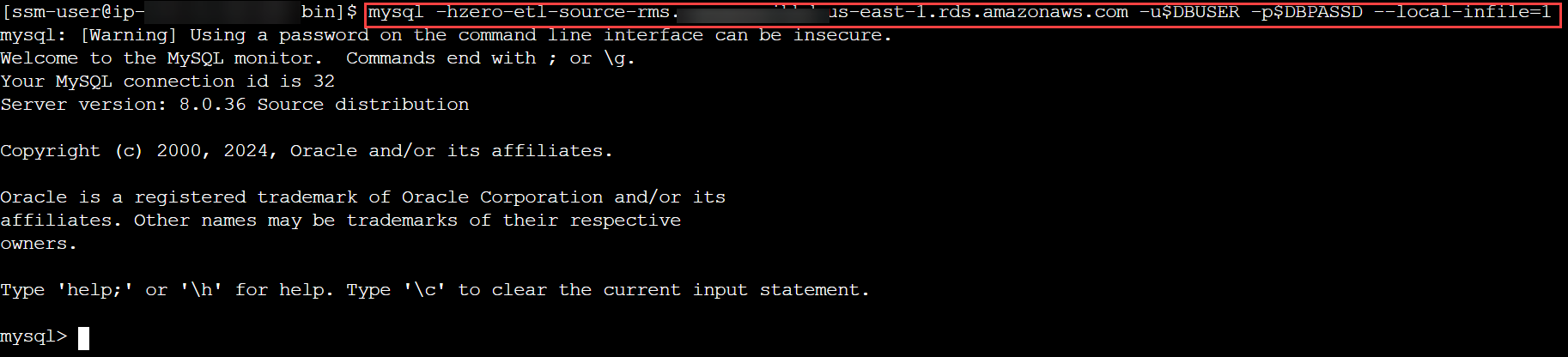
- Conéctese a su clúster RDS para MySQL y cree una base de datos o esquema para el modelo de datos TICKIT, verifique que las tablas en ese esquema tengan una clave principal e inicie el proceso de carga:
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Use la siguiente Comandos CREAR TABLA.
- Cargue los datos de los archivos locales usando el comando LOAD DATA.
Lo siguiente es un ejemplo. Tenga en cuenta que el archivo CSV de entrada se divide en varios archivos. Este comando debe ejecutarse para cada archivo si desea cargar todos los datos. Para fines de demostración, una carga de datos parcial también debería funcionar.

Analizar los datos de TICKIT de origen en el destino
En la consola de Amazon Redshift, abra el editor de consultas v2 utilizando la base de datos que creó como parte de la configuración de integración. Utilice el siguiente código para validar la actividad inicial o CDC:

Ahora puede aplicar su lógica empresarial para transformaciones directamente en los datos que se han replicado en el almacén de datos. También puede utilizar técnicas de optimización del rendimiento, como crear una vista materializada de Redshift que una las tablas replicadas y otras tablas locales para mejorar el rendimiento de las consultas analíticas.
Monitoreo
Puede consultar las siguientes vistas y tablas del sistema en Amazon Redshift para obtener información sobre sus integraciones de ETL cero con Amazon Redshift:
Para ver las métricas relacionadas con la integración publicadas en Reloj en la nube de Amazon, abra la consola de Amazon Redshift. Elegir Integraciones de ETL cero en el panel de navegación y elija la integración para mostrar métricas de actividad.
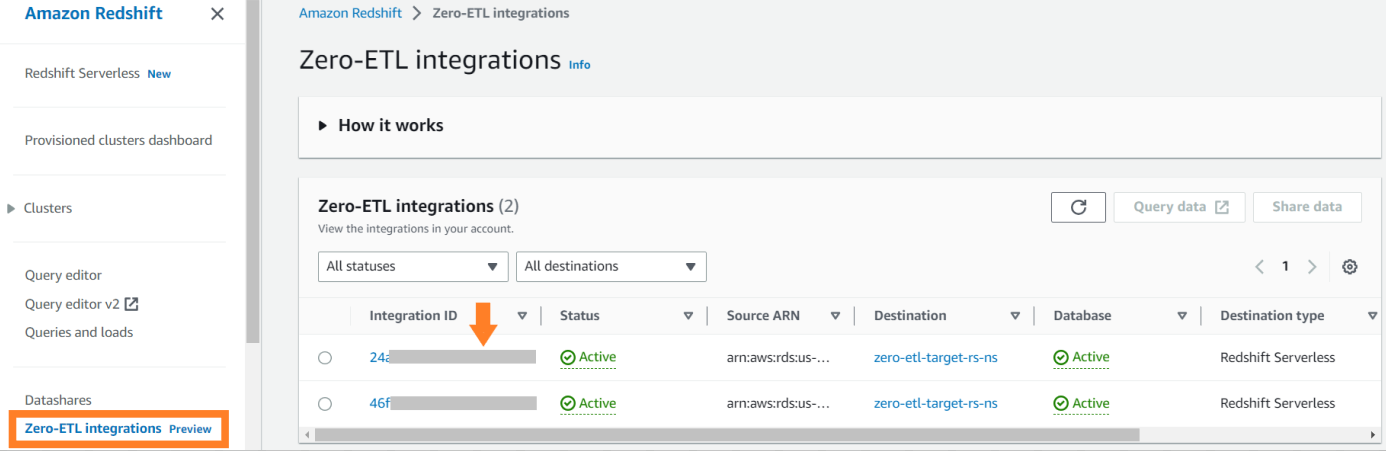
Las métricas disponibles en la consola de Amazon Redshift son métricas de integración y estadísticas de tablas, y las estadísticas de las tablas proporcionan detalles de cada tabla replicada desde Amazon RDS para MySQL a Amazon Redshift.

Las métricas de integración contienen recuentos de éxitos y errores de replicación de tablas y detalles de retraso.
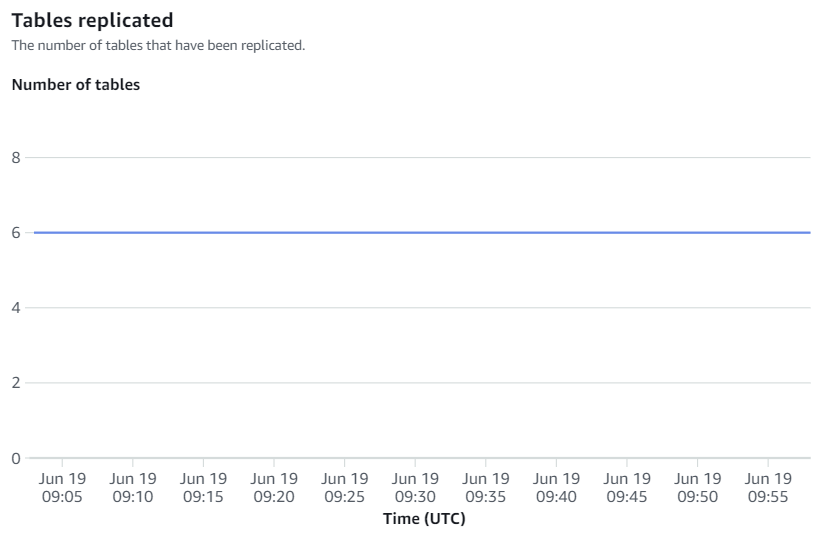
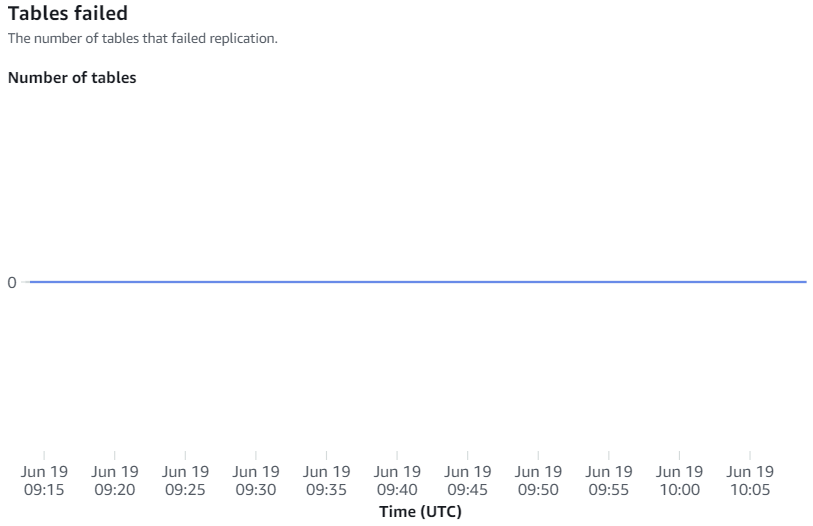
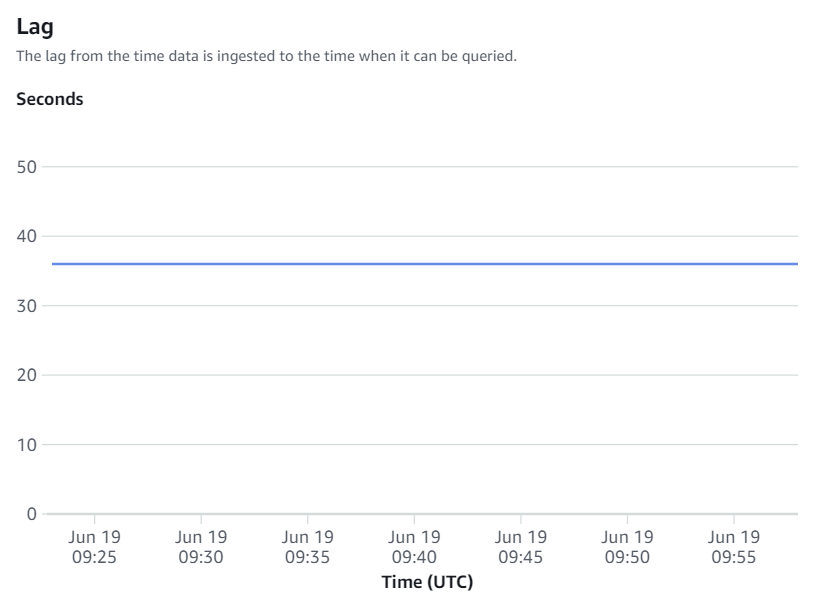
Resincronizaciones manuales
La integración de ETL cero iniciará automáticamente una resincronización si el estado de sincronización de una tabla muestra un error o se requiere resincronización. Pero en caso de que falle la resincronización automática, puede iniciar una resincronización con granularidad a nivel de tabla:
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
Una tabla puede entrar en un estado fallido por varios motivos:
- La clave principal fue eliminada de la tabla. En tales casos, debe volver a agregar la clave principal y ejecutar el comando ALTER mencionado anteriormente.
- Se encuentra un valor no válido durante la replicación o se agrega una nueva columna a la tabla con un tipo de datos no admitido. En tales casos, debe eliminar la columna con el tipo de datos no admitido y ejecutar el comando ALTER mencionado anteriormente.
- Un error interno, en casos excepcionales, puede provocar un fallo en la tabla. El comando ALTER debería solucionarlo.
Limpiar
Cuando elimina una integración de ETL cero, sus datos transaccionales no se eliminan del RDS de origen ni de las bases de datos de Redshift de destino, pero Amazon RDS no envía ningún cambio nuevo a Amazon Redshift.
Para eliminar una integración de ETL cero, complete los siguientes pasos:
- En la consola de Amazon RDS, elija Integraciones de ETL cero en el panel de navegación.
- Seleccione la integración de ETL cero que desea eliminar y elija Borrar.
- Para confirmar la eliminación, seleccione Borrar.

Conclusión
En esta publicación, le mostramos cómo configurar una integración ETL cero desde Amazon RDS para MySQL a Amazon Redshift. Esto minimiza la necesidad de mantener canales de datos complejos y permite análisis casi en tiempo real de datos operativos y transaccionales.
Para obtener más información sobre la integración zero-ETL de Amazon RDS con Amazon Redshift, consulte Trabajar con integraciones de Amazon RDS zero-ETL con Amazon Redshift (versión preliminar).
Acerca de los autores
 Milind Oke es un arquitecto senior de soluciones especializado en Redshift que ha trabajado en Amazon Web Services durante tres años. Es un asociado de SA certificado por AWS, especialista en seguridad y especialista en análisis, con sede en Queens, Nueva York.
Milind Oke es un arquitecto senior de soluciones especializado en Redshift que ha trabajado en Amazon Web Services durante tres años. Es un asociado de SA certificado por AWS, especialista en seguridad y especialista en análisis, con sede en Queens, Nueva York.
 Aditya Samant es un veterano de la industria de bases de datos relacionales con más de dos décadas de experiencia trabajando con bases de datos comerciales y de código abierto. Actualmente trabaja en Amazon Web Services como Arquitecto Principal de Soluciones Especialistas en Bases de Datos. En su puesto, dedica tiempo a trabajar con clientes diseñando arquitecturas nativas de la nube escalables, seguras y robustas. Aditya trabaja en estrecha colaboración con los equipos de servicio y colabora en el diseño y entrega de nuevas funciones para las bases de datos administradas de Amazon.
Aditya Samant es un veterano de la industria de bases de datos relacionales con más de dos décadas de experiencia trabajando con bases de datos comerciales y de código abierto. Actualmente trabaja en Amazon Web Services como Arquitecto Principal de Soluciones Especialistas en Bases de Datos. En su puesto, dedica tiempo a trabajar con clientes diseñando arquitecturas nativas de la nube escalables, seguras y robustas. Aditya trabaja en estrecha colaboración con los equipos de servicio y colabora en el diseño y entrega de nuevas funciones para las bases de datos administradas de Amazon.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

